Talk, held at the conference "Integrating inferences about our past - New findings and current issues in the peopling of the Pacific and SouthEast Asia" (2015-06-22/23, Max Planck Institute for the Science of Human History, Jena),
of Linguistic Reconstruction Johann-Mattis List DFG research fellow Centre des recherches linguistiques sur l’Asie Orientale Team Adaptation, Integration, Reticulation, Evolution EHESS and UPMC, Paris 2015-06-22 1 / 20
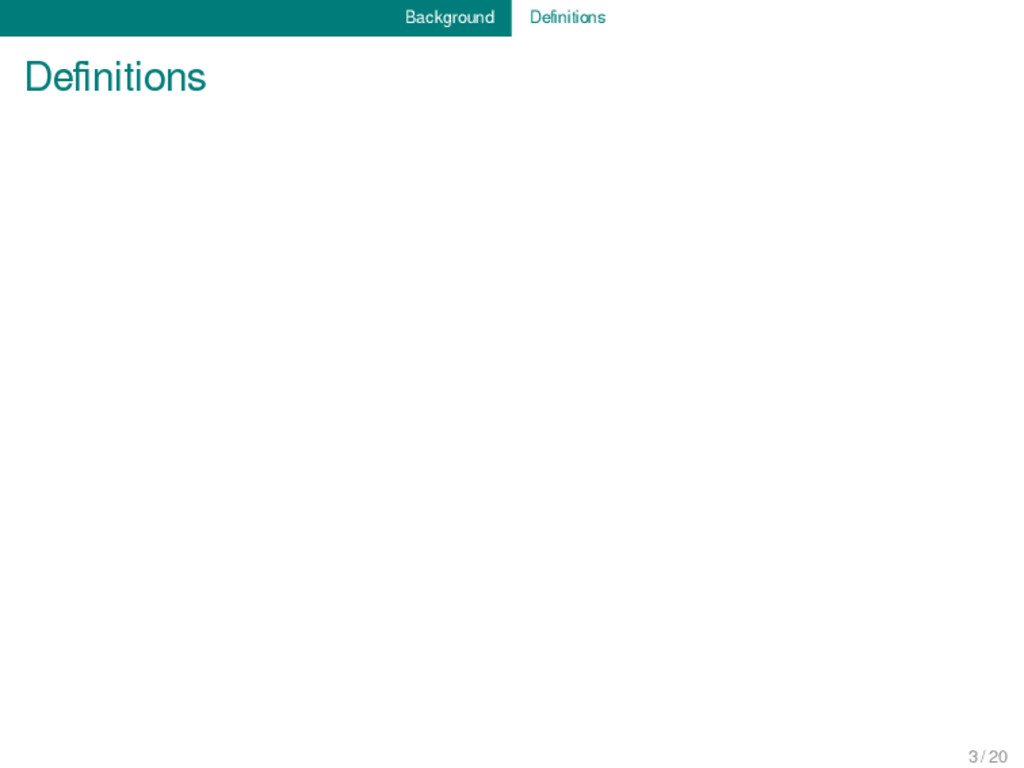
technique for studying the development of languages by performing a feature-by-feature comparison of two or more languages with common descent from a shared ancestor, as opposed to the method of internal reconstruction, which analyses the internal development of a single language over time. Wikipedia s.v. "Comparative Method" The method of comparing languages to determine whether and how they have developed from a common ancestor. The items compared are lexical and grammatical units, and the aim is to discover correspondences relating sounds in two or more di�erent languages, which are so numerous and so regular, across sets of units with similar meanings, that no other explanation is reasonable. Oxford Dictionary of Linguistics (Matthews 1997) The comparative is both the earliest and the most important of the methods of reconstruction. Most of the major insights into the prehistory of languages have been gained by the applications of this method, and most reconstructions have been based on it. Fox (1995) The Comparative Method is the central tool in historical linguistics for historical reconstruction and also classifying languages. A classi�cation done with the Comparative Method is called a genetic classi�cation. The result is that languages are arranged in language family trees. This means that languages are classi�ed according to their genealogical relationships2 and are interpreted as being in relation of child- or sisterhood to other languages. Such a way of classifying entities is called phylogenetic classi�cation in biology; a classi�cation by genealogical relationships. Fleischhauer (2009) The method of comparatistics today is generally known under the not very well-chosen term "comparative-historical method". It constitutes a huge complex of abstract and concrete procedures for the investigation of the history of related languages which genetically go back to some unofrom tradition of the past. Klimov (1990), my translation → comparative linguistics, reconstruction Routledge Dictionary of Language and Linguistics (Bussmann 1996) 3 / 20
comparative method is a bunch of techniques that are commonly used by historical linguists in order to reconstruct the history of languages and language families. 3 / 20
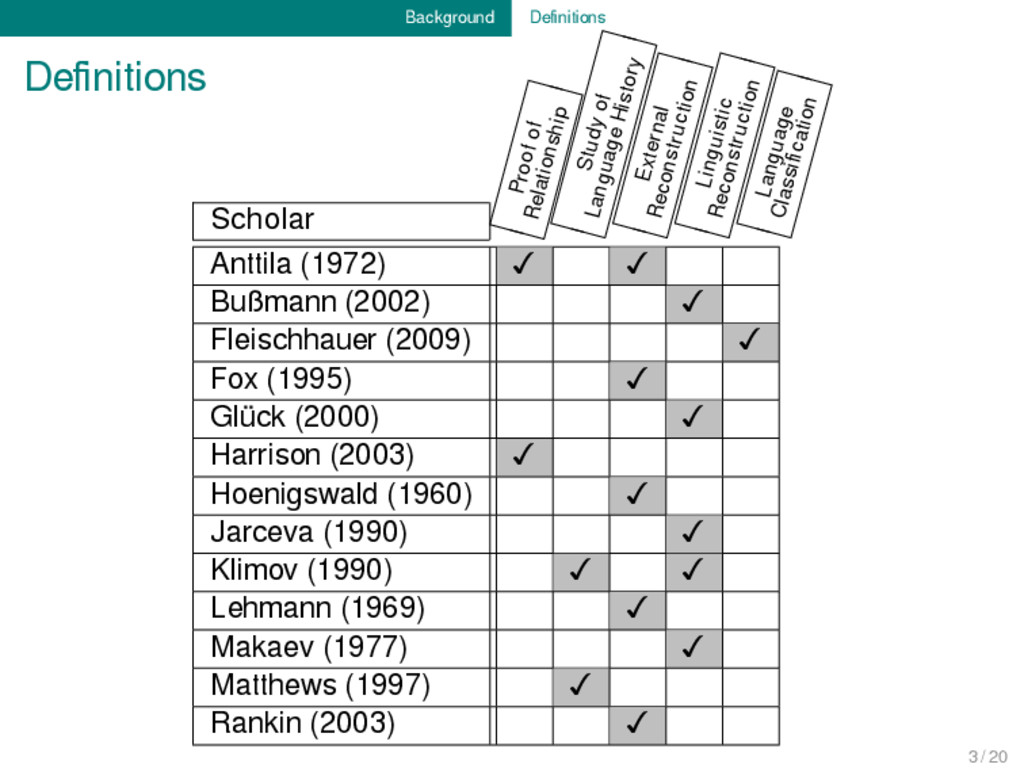
Determine on the strength of diagnostic evidence that a set of languages are genetically related, that is, that they constitute a ‘family’; 2. Collect putative cognate sets for the family (both morphological paradigms and lexical items). 3. Work out the sound correspondences from the cognate sets, putting ‘irregular’ cognate sets on one side; 4. Reconstruct the protolanguage of the family as follows: a Reconstruct the protophonology from the sound correspondences worked out in (3), using conventional wisdom regarding the directions of sound changes. b Reconstruct protomorphemes (both morphological paradigms and lexical items) from the cognate sets collected in (2), using the protophonology reconstructed in (4a). 5. Establish innovations (phonological, lexical, semantic, morphological, morpho- syntactic) shared by groups of languages within the family relative to the recon- structed protolanguage. 6. Tabulate the innovations established in (5) to arrive at an internal classification of the family, a ‘family tree’. 7. Construct an etymological dictionary, tracing borrowings, semantic change, and so forth, for the lexicon of the family (or of one language of the family). 4 / 20
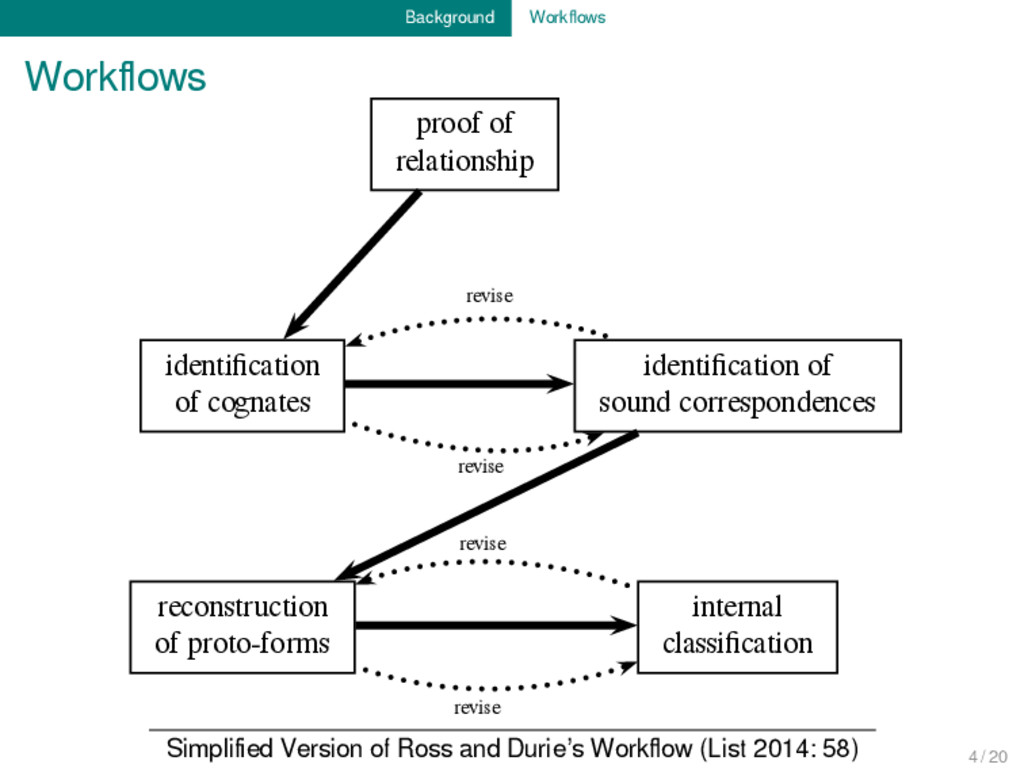
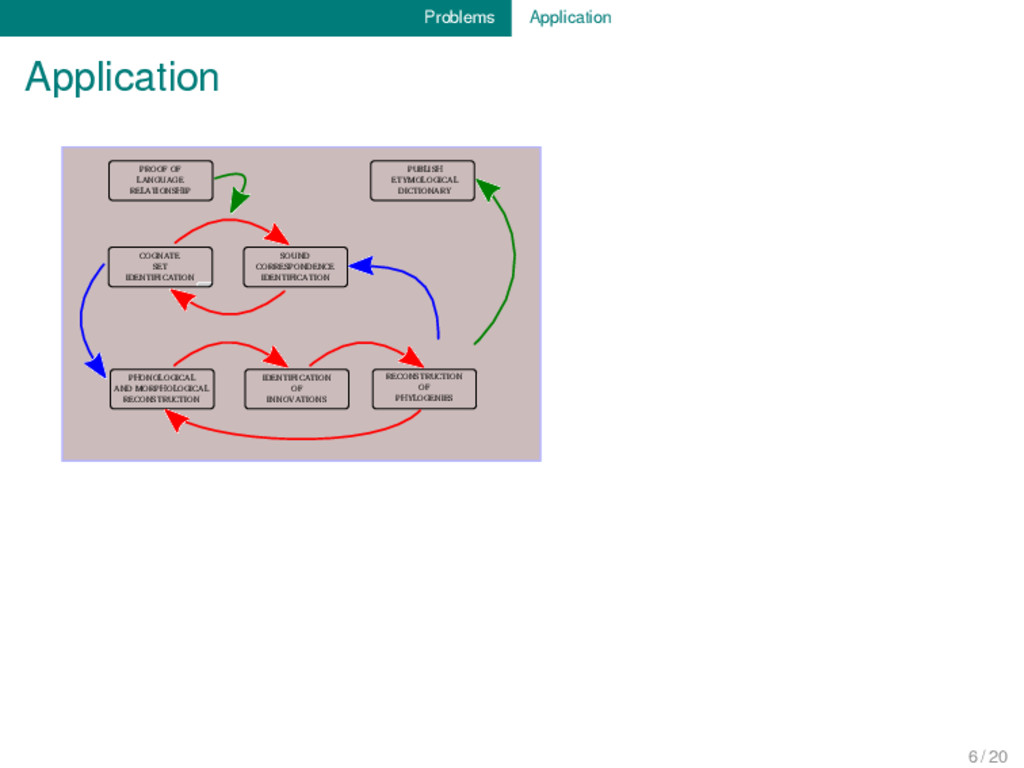
RECONSTRUCTION OF PHYLOGENIES PUBLISH ETYMOLOGICAL DICTIONARY PROOF OF LANGUAGE RELATIONSHIP SOUND CORRESPONDENCE IDENTIFICATION COGNATE SET IDENTIFICATION Tentative Visualization of the Workflow by Ross and Durie (1996: 6f) 4 / 20
of sound correspondences reconstruction of proto-forms internal classification revise revise revise revise Simplified Version of Ross and Durie’s Workflow (List 2014: 58) 4 / 20
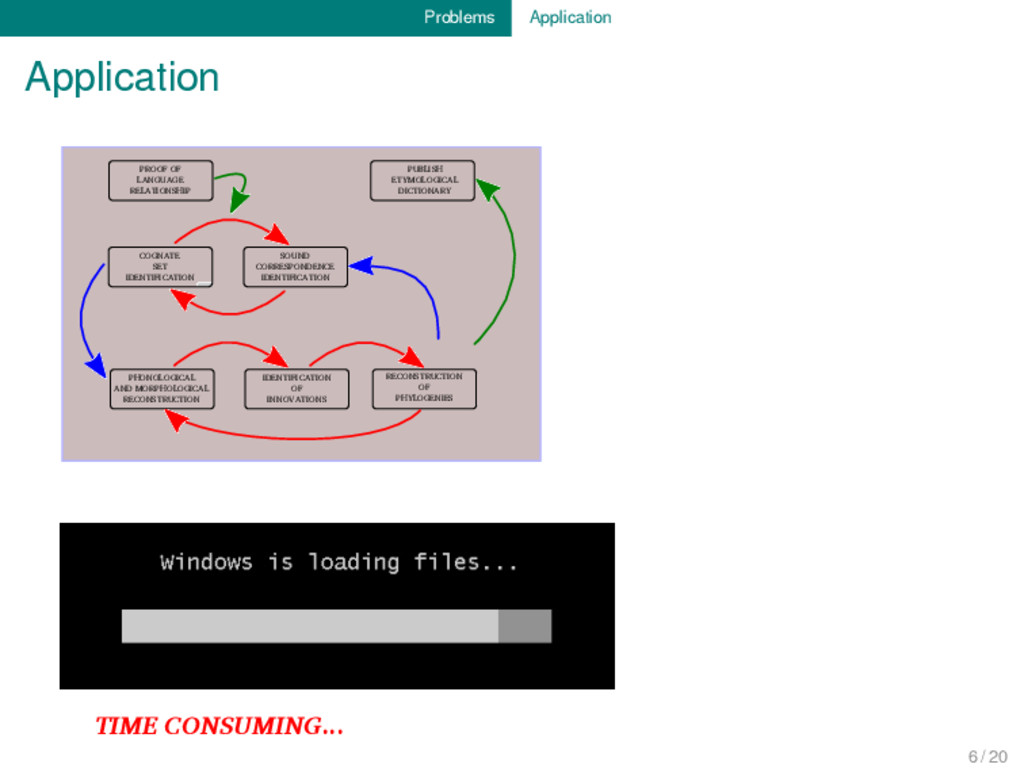
RECONSTRUCTION OF PHYLOGENIES PUBLISH ETYMOLOGICAL DICTIONARY PROOF OF LANGUAGE RELATIONSHIP SOUND CORRESPONDENCE IDENTIFICATION COGNATE SET IDENTIFICATION 6 / 20
RECONSTRUCTION OF PHYLOGENIES PUBLISH ETYMOLOGICAL DICTIONARY PROOF OF LANGUAGE RELATIONSHIP SOUND CORRESPONDENCE IDENTIFICATION COGNATE SET IDENTIFICATION TIME CONSUMING... 6 / 20
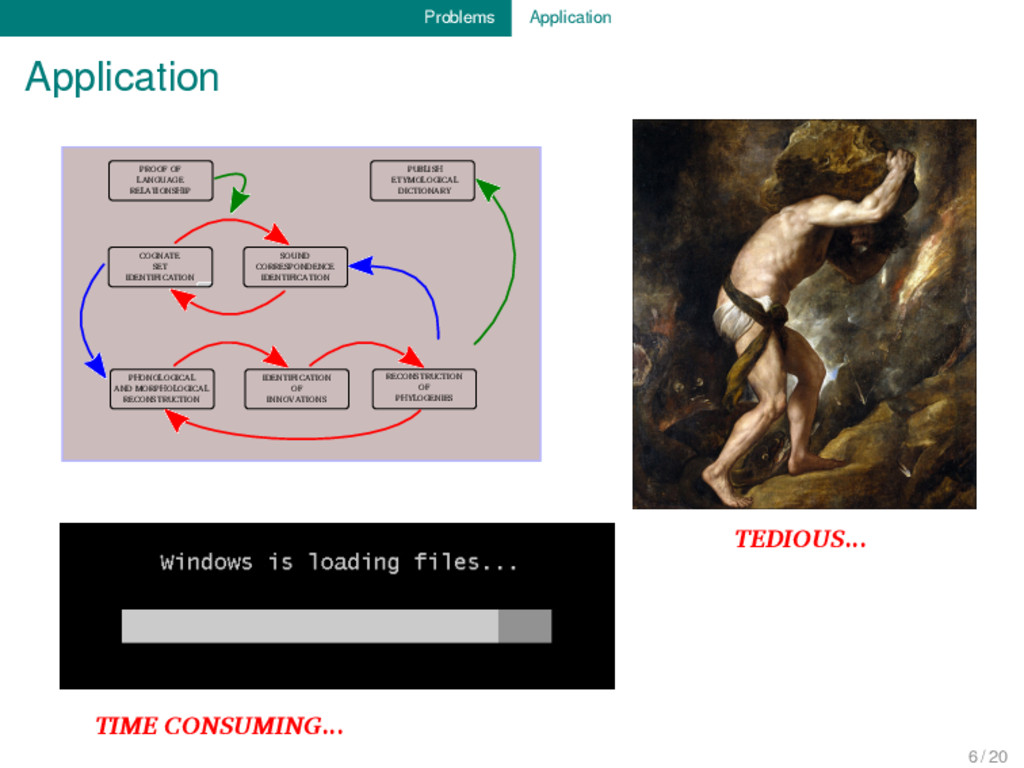
RECONSTRUCTION OF PHYLOGENIES PUBLISH ETYMOLOGICAL DICTIONARY PROOF OF LANGUAGE RELATIONSHIP SOUND CORRESPONDENCE IDENTIFICATION COGNATE SET IDENTIFICATION TIME CONSUMING... TEDIOUS... 6 / 20
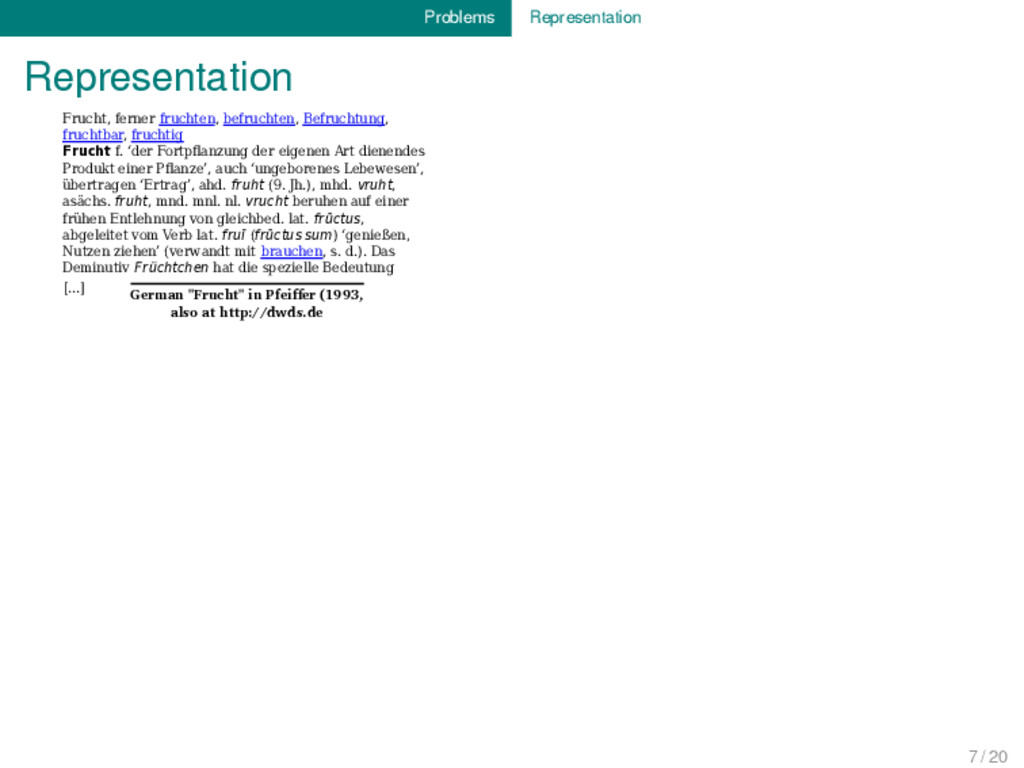
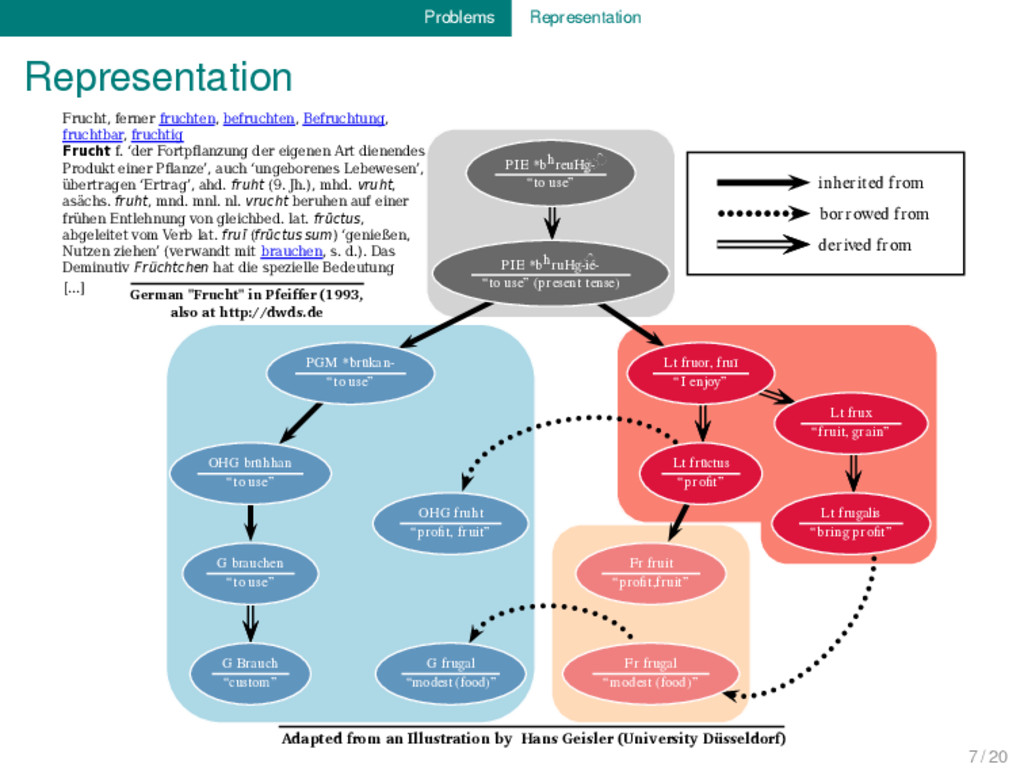
Frucht f. ‘der Fortpflanzung der eigenen Art dienendes Produkt einer Pflanze’, auch ‘ungeborenes Lebewesen’, übertragen ‘Ertrag’, ahd. fruht (9. Jh.), mhd. vruht, asächs. fruht, mnd. mnl. nl. vrucht beruhen auf einer frühen Entlehnung von gleichbed. lat. frūctus, abgeleitet vom Verb lat. fruī (frūctus sum) ‘genießen, Nutzen ziehen’ (verwandt mit brauchen, s. d.). Das Deminutiv Früchtchen hat die spezielle Bedeutung [...] German "Frucht" in Pfei�er (1993, also at http://dwds.de) 7 / 20
Frucht f. ‘der Fortpflanzung der eigenen Art dienendes Produkt einer Pflanze’, auch ‘ungeborenes Lebewesen’, übertragen ‘Ertrag’, ahd. fruht (9. Jh.), mhd. vruht, asächs. fruht, mnd. mnl. nl. vrucht beruhen auf einer frühen Entlehnung von gleichbed. lat. frūctus, abgeleitet vom Verb lat. fruī (frūctus sum) ‘genießen, Nutzen ziehen’ (verwandt mit brauchen, s. d.). Das Deminutiv Früchtchen hat die spezielle Bedeutung [...] German "Frucht" in Pfei�er (1993, also at http://dwds.de 7 / 20
Frucht f. ‘der Fortpflanzung der eigenen Art dienendes Produkt einer Pflanze’, auch ‘ungeborenes Lebewesen’, übertragen ‘Ertrag’, ahd. fruht (9. Jh.), mhd. vruht, asächs. fruht, mnd. mnl. nl. vrucht beruhen auf einer frühen Entlehnung von gleichbed. lat. frūctus, abgeleitet vom Verb lat. fruī (frūctus sum) ‘genießen, Nutzen ziehen’ (verwandt mit brauchen, s. d.). Das Deminutiv Früchtchen hat die spezielle Bedeutung [...] inherited from borrowed from derived from PIE *bhreu◌◌̯ Hg◌ ◌ ̑ - “to use” PIE *bhruHg◌ ◌ ̑ -ié- “to use” (present tense) PGM *ƀrūkan- “to use” OHG brūhhan “to use” G brauchen “to use” G Brauch “custom” OHG fruht “profit, fruit” G frugal “modest (food)” Fr fruit “profit,fruit” Fr frugal “modest (food)” Lt fruor, fruī “I enjoy” Lt frūctus “profit” Lt frux “fruit, grain” Lt frugalis “bring profit” Adapted from an Illustration by Hans Geisler (University Düsseldorf) German "Frucht" in Pfei�er (1993, also at http://dwds.de 7 / 20
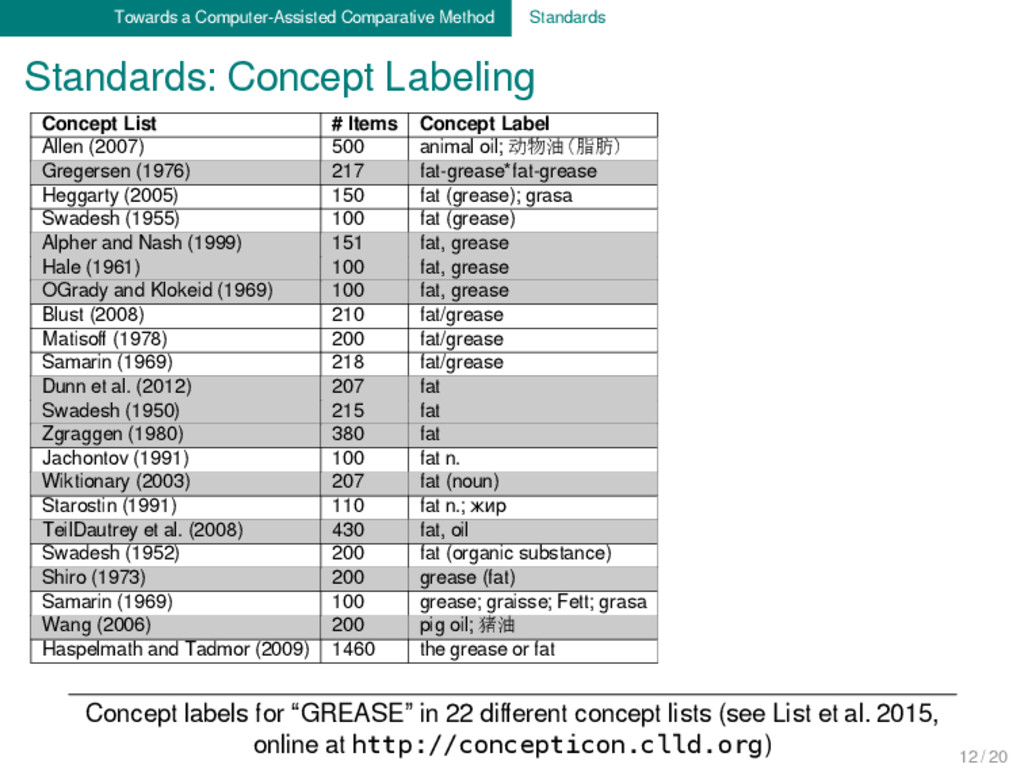
form” (impossible to search it efficiently) no standardized phonetic representations no standardized glosses for meanings no standardized names or abbreviations for language and dialect names no standardized representation of sound correspondences no standardized assignment of cognate sets and borrowings ... 8 / 20
on many points in historical linguistics, be it the number of laryngeals, the position of Baltic and Slavic, or whether a given word was borrowed or not. We know well that no two etymological dictionaries for the sa- me language or language families are completely identical. Unfortunately, we lack a rigorous check to which degree ex- perts actually agree or disagree in their judgments. We also lack methods for evaluation which would help us to show to which degree a given hypothesis (a reconstruction, a family tree, or an etymology) corresponds with our linguistic data. 9 / 20
knowledge - can juggle with multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE 11 / 20
knowledge - can juggle with multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE 11 / 20
knowledge - can juggle with multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE COMPUTER-ASSISTED LANGUAGE COMPARISON 11 / 20
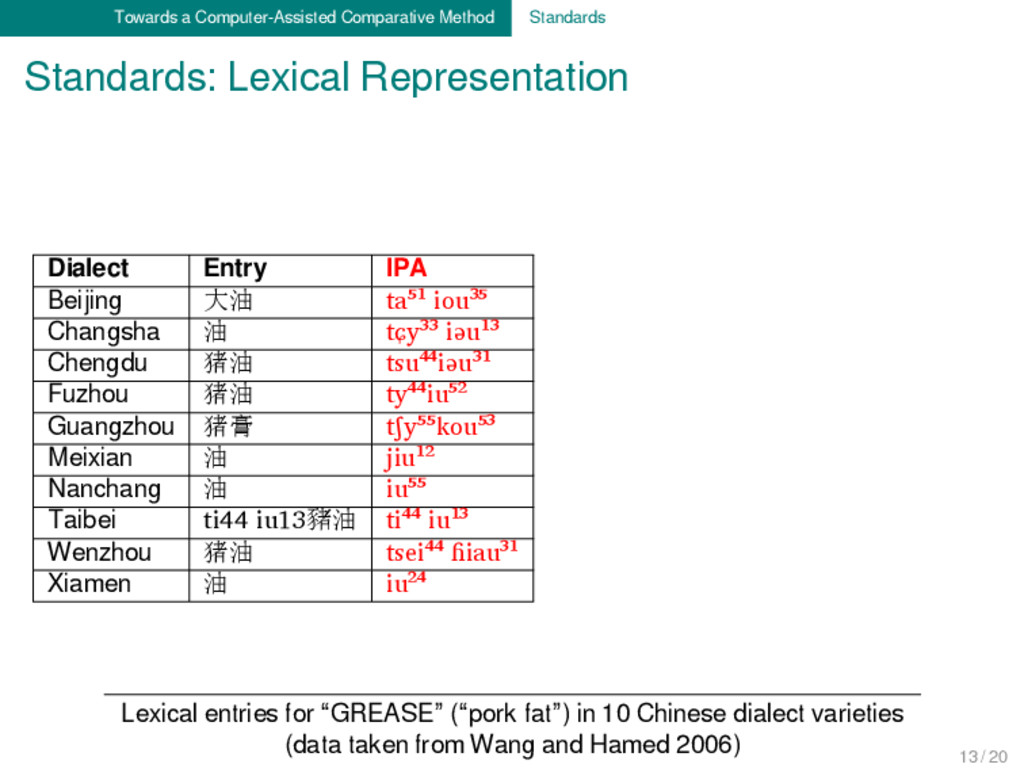
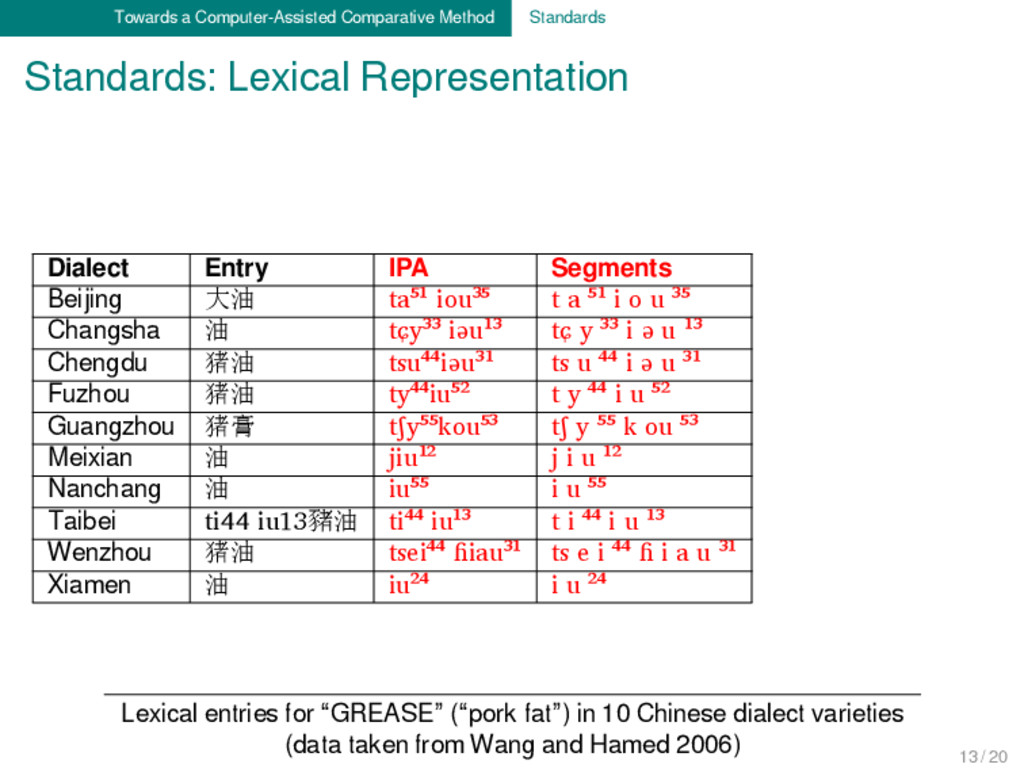
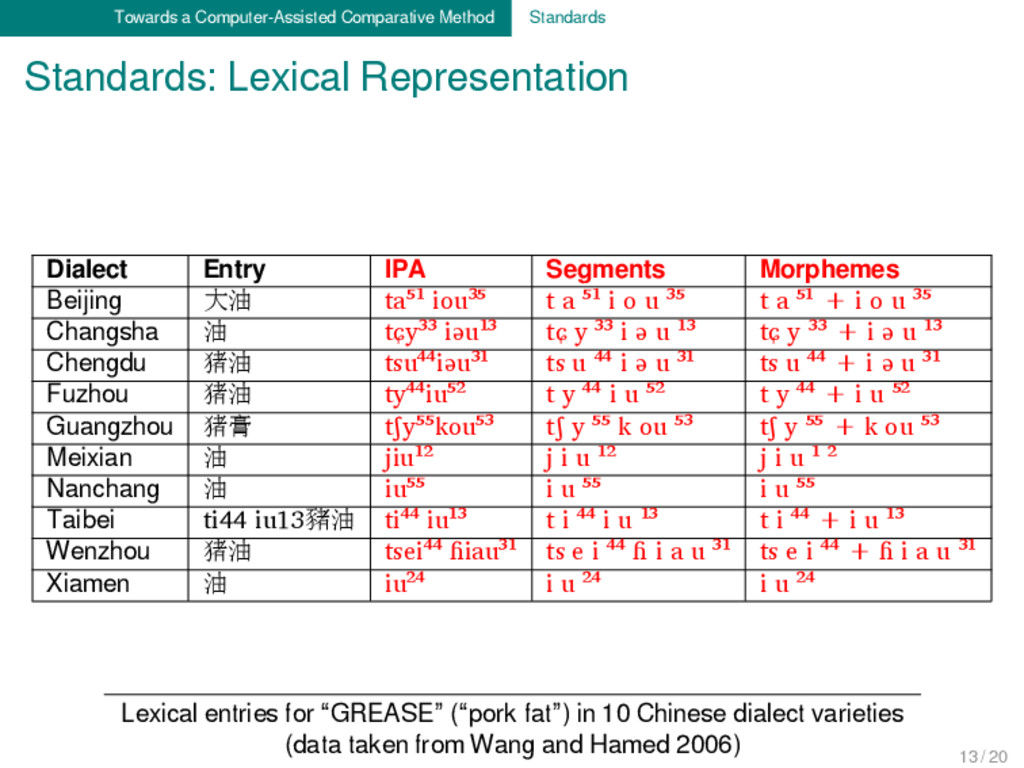
Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i +⁴⁴ ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ Lexical entries for “GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) 13 / 20
entries for “GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i ⁴⁴ + ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 13 / 20
entries for “GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i +⁴⁴ ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 13 / 20
entries for “GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i ⁴⁴ + ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 13 / 20
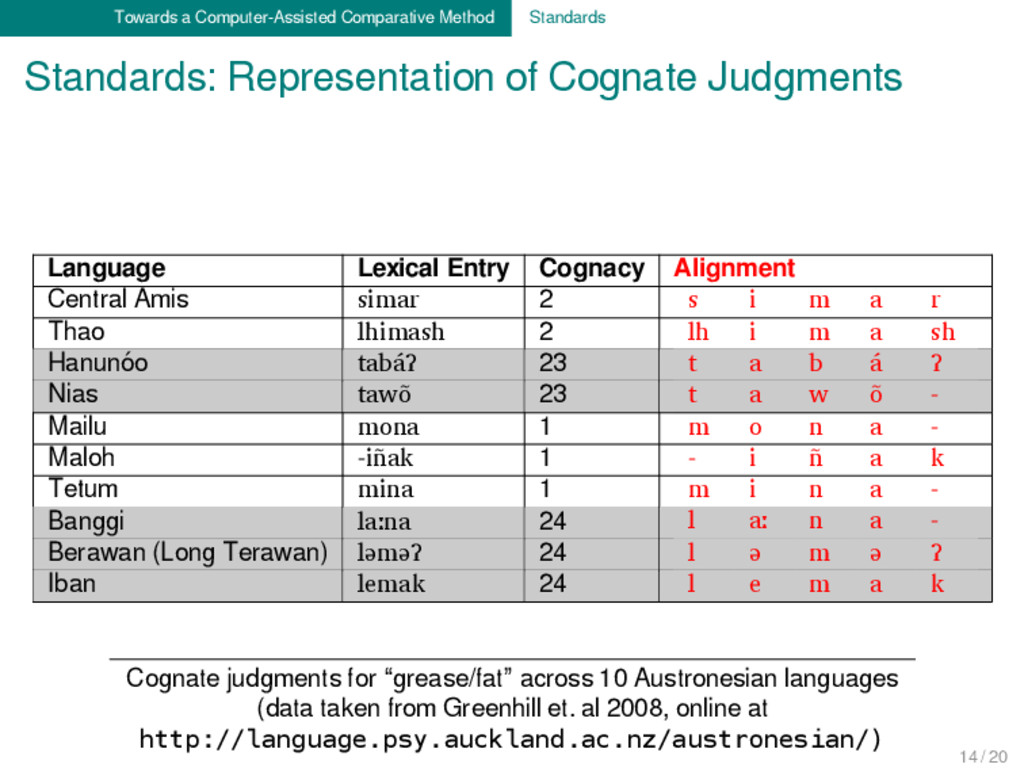
Judgments Language Lexical Entry Cognacy Alignment Central Amis simar 2 s i m a r Thao lhimash 2 lh i m a sh Hanunóo tabáʔ 23 t a b á ʔ Nias tawõ 23 t a w õ - Mailu mona 1 m o n a - Maloh -iñak 1 - i ñ a k Tetum mina 1 m i n a - Banggi laːna 24 l aː n a - Berawan (Long Terawan) ləməʔ 24 l ə m ə ʔ Iban lemak 24 l e m a k Cognate judgments for “grease/fat” across 10 Austronesian languages (data taken from Greenhill et. al 2008, online at http://language.psy.auckland.ac.nz/austronesian/) 14 / 20
Judgments Cognate judgments for “grease/fat” across 10 Austronesian languages (data taken from Greenhill et. al 2008, online at http://language.psy.auckland.ac.nz/austronesian/) Language Lexical Entry Cognacy Alignment Central Amis simar 2 s i m a r Thao lhimash 2 lh i m a sh Hanunóo tabáʔ 23 t a b á ʔ Nias tawõ 23 t a w õ - Mailu mona 1 m o n a - Maloh -iñak 1 - i ñ a k Tetum mina 1 m i n a - Banggi laːna 24 l aː n a - Berawan (Long Terawan) ləməʔ 24 l ə m ə ʔ Iban lemak 24 l e m a k 14 / 20
WORDLIST STANDARD The Jena Wordlist Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray 15 / 20
Jena Wordlist Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray JENA WORDLIST STANDARD DEFINE STANDARDS FOR - Wordlists - Cognate Sets - Alignments PROVIDE TOOLS FOR - Data Validation - Data Exchange - Data Enrichment 15 / 20
Jena Wordlist Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray JENA WORDLIST STANDARD arbitrarité Glottolog http://glottolog.clld.org Phoible http://phoible.clld.org CONCEPTICON http://concepticon.clld.org [ˈfɔi.bł] INTEGRATE EXISTING STANDARDS 15 / 20
Jena Wordlist Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray PROVIDE TOOLS FOR EDITING AND ANALYSIS LingPy http://lingpy.org TSV EDICTOR http://tsv.lingpy.org JENA WORDLIST STANDARD 15 / 20
Jena Wordlist Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray JENA WORDLIST STANDARD LexiBank - Cross-Linguistic Database of Lexical Cognate Sets PhonoBank - Cross-Linguistic Database of Regular Sound Change Patterns USE THE STANDARD TO BUILD NEW DATABASES 15 / 20
VERY, VERY LONG TITLE Semantic Tagging Segmentation Cognate Detection Alignment Analysis Linguistic Reconstruction Phylogenetic Reconstruction HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] RAW DATA HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] WORDLIST DATA HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] TOKENS, MORPHEMES HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] COGNATE SETS HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] SOUND CORRESPON- DENCES HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] PROTO- FORMS HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] PHYLO- GENIES PROVIDES AUTOMATIC ANALYSES REVISES AUTOMATIC ANALYSES A possible computer-assisted, iterative workflow with automatic and manual components. 16 / 20
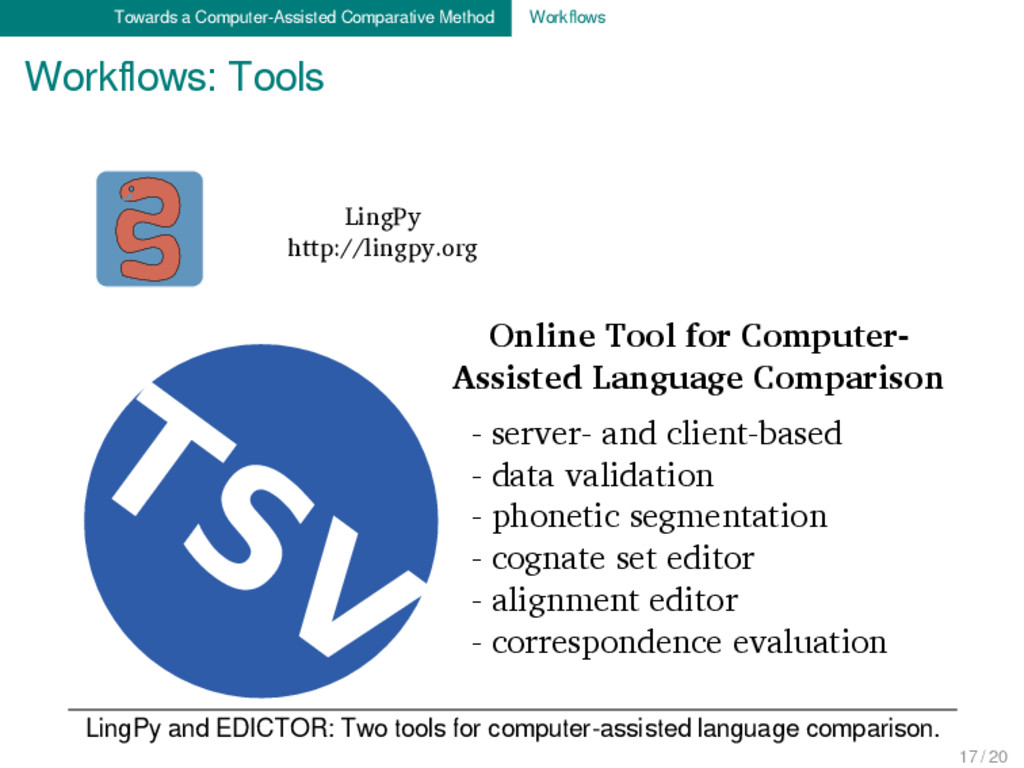
EDICTOR: Two tools for computer-assisted language comparison. TSV LingPy http://lingpy.org Online Tool for Computer- Assisted Language Comparison - server- and client-based - data validation - phonetic segmentation - cognate set editor - alignment editor - correspondence evaluation 17 / 20
of Tukano Languages (with T. Chacon) 15 Tukano languages 140 concepts cognate sets are aligned with proposed reconstructions Reconstruction of Burmish Languages (with N. Hill) 8 Burmish languages about 500 concepts cognate sets were determined automatically and are currently being reviewd by the expert Lexical Homology Database of Sino-Tibetan Languages (with L. Sagart and G. Jacques) more than 50 Sino-Tibetan languages about 240 concepts data is currently being assembled 18 / 20
PP VERY, VERY LO NG TI TLE Modeling of Morphological Change morphological change is not systematic (as opposed to sound change) morphological differences in cognate sets distort the alignments Modeling of Semantic Change semantic shift is not systematic but has general tendencies we need to incorporate known tendencies in our analyses Modeling of Irregular Sound Change irregular or sporadic sound change is problematic for reconstruction we need to find ways to incorporate our uncertainty in our alignments 19 / 20
phylogeny of the Austronesian and many other language families. Unfortunately, the current practice of data presentation makes it dif- ficult to compare and test these hypotheses. If we want to gain new insights into the past of our lan- guages, we need to find ways to integrate both the knowledge which experts have been accu- mulating over centuries and the new computa- tional tools which help to organize, analyze and integrate this knowledge. 20 / 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}