world, we gain invaluable insights • into the past of the languages spoken in the world • into the history of ancestral populations • into human prehistory in general
in the world • we need to prove that two or more languages are genetically related by • identifying elements they have inherited from their common ancestors
words and morphemes) • we can calculate phylogenetic trees and networks, • we can reconstruct the words in the unattested ancestral languages, and • we can try to learn more about these language families (when they existed, how they developed, etc.)
languages in the world necessitate the use of automatic methods for language comparison, but unfortunately • available methods work well on small language families with moderate time depths, • but they completely fail when it comes to the detection of words which are only partially cognate
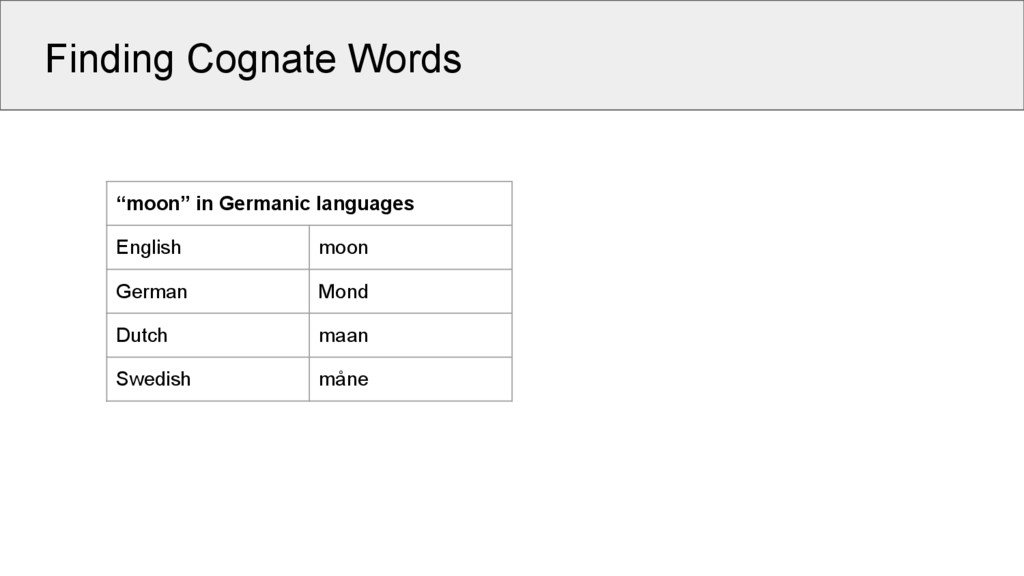
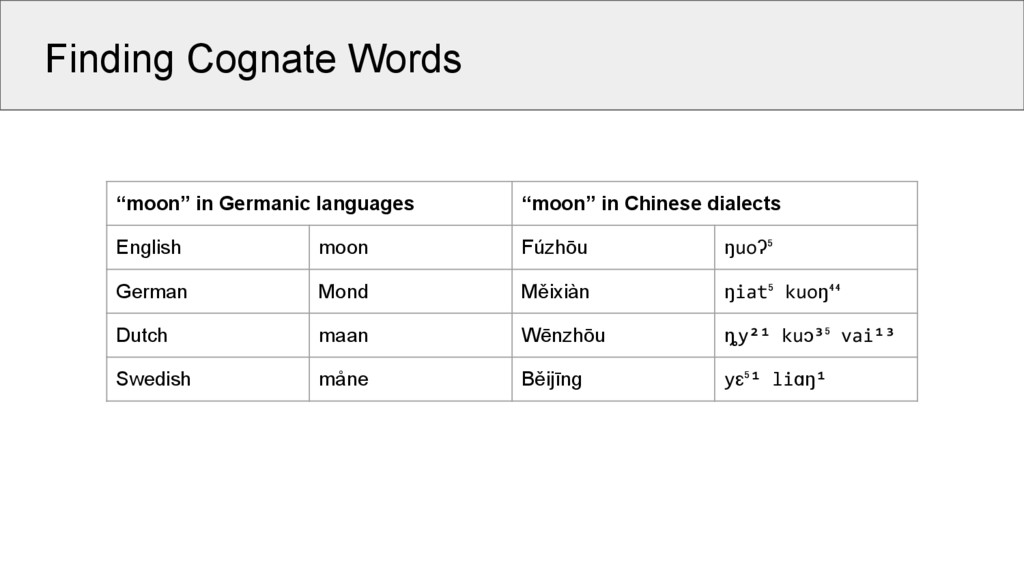
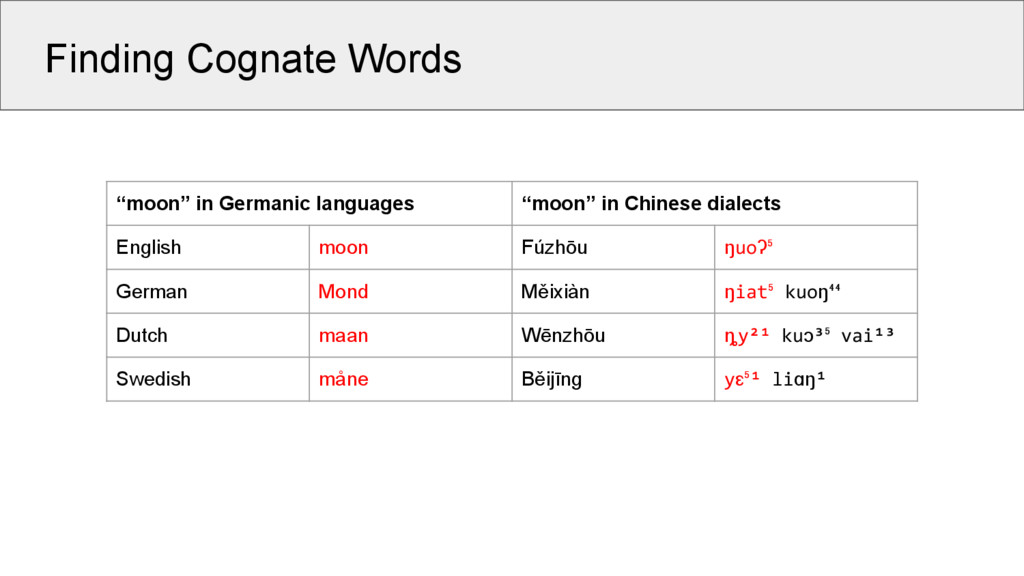
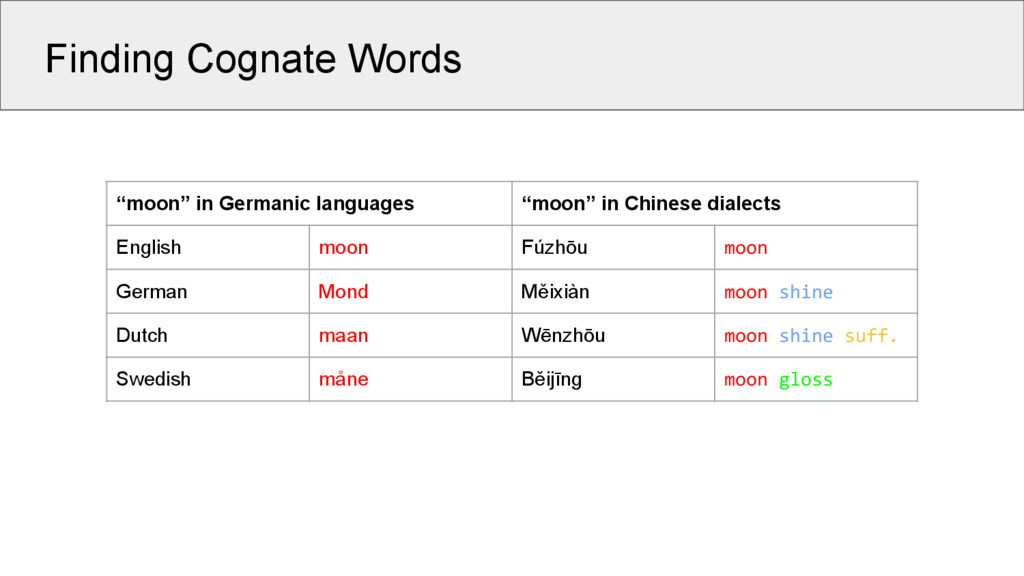
dialects English moon Fúzhōu moon German Mond Měixiàn moon shine Dutch maan Wēnzhōu moon shine suff. Swedish måne Běijīng moon gloss So far, no algorithm can detect these shared similarities across words in language families like Sino-Tibetan, Austro-Asiatic, Tai-Kadai, etc.
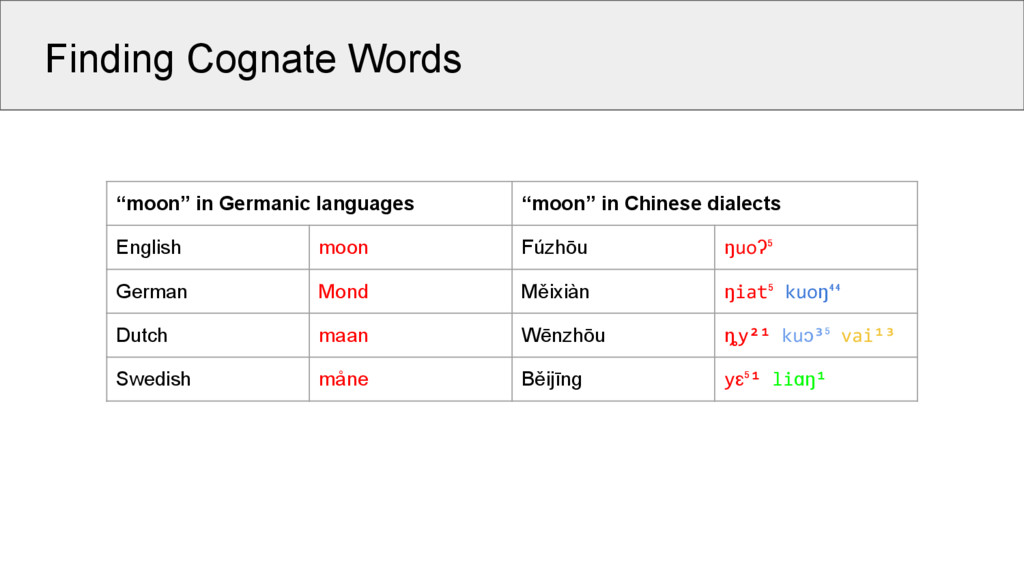
dialects English moon ? Fúzhōu moon ? German Mond ? Měixiàn moon shine ? Dutch maan ? Wēnzhōu moon shine suff. ? Swedish måne ? Běijīng moon gloss ? But not only are our algorithms not capable of detecting the structures: We also have huge problems to actually use this information in phylogenetic tree reconstruction and related tasks.
dialects English moon 1 Fúzhōu moon ? German Mond 1 Měixiàn moon shine ? Dutch maan 1 Wēnzhōu moon shine suff. ? Swedish måne 1 Běijīng moon gloss ? But not only are our algorithms not capable of detecting the structures: We also have huge problems to actually use this information in phylogenetic tree reconstruction and related tasks.
dialects English moon 1 Fúzhōu moon 1 German Mond 1 Měixiàn moon shine 1 Dutch maan 1 Wēnzhōu moon shine suff. 1 Swedish måne 1 Běijīng moon gloss 1 Most algorithms require binary (yes/no) cognate decisions as input. But given the data for Chinese dialects, should we 1. label them all as cognate words, as they share one element? 2. label them all as different, as their strings all differ? loose coding of partial cognates
dialects English moon 1 Fúzhōu moon 1 German Mond 1 Měixiàn moon shine 2 Dutch maan 1 Wēnzhōu moon shine suff. 3 Swedish måne 1 Běijīng moon gloss 4 Most algorithms require binary (yes/no) cognate decisions as input. But given the data for Chinese dialects, should we 1. label them all as cognate words, as they share one element? 2. label them all as different, as their strings all differ? strict coding of partial cognates
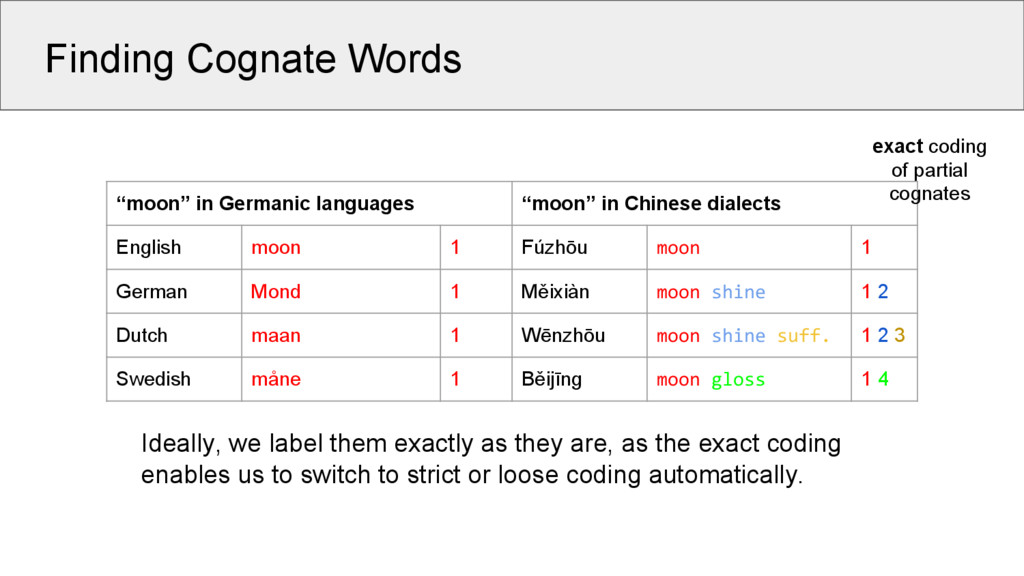
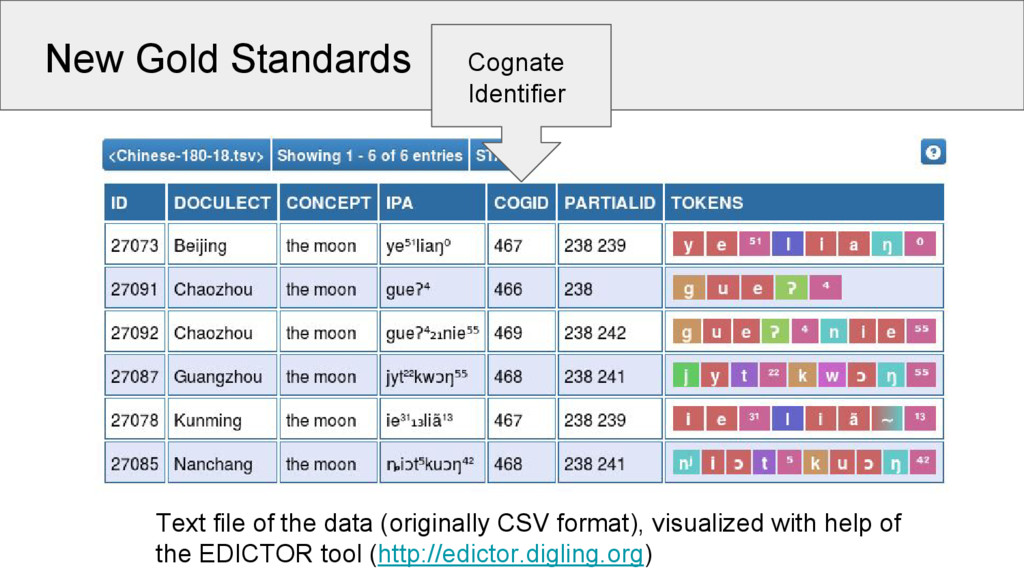
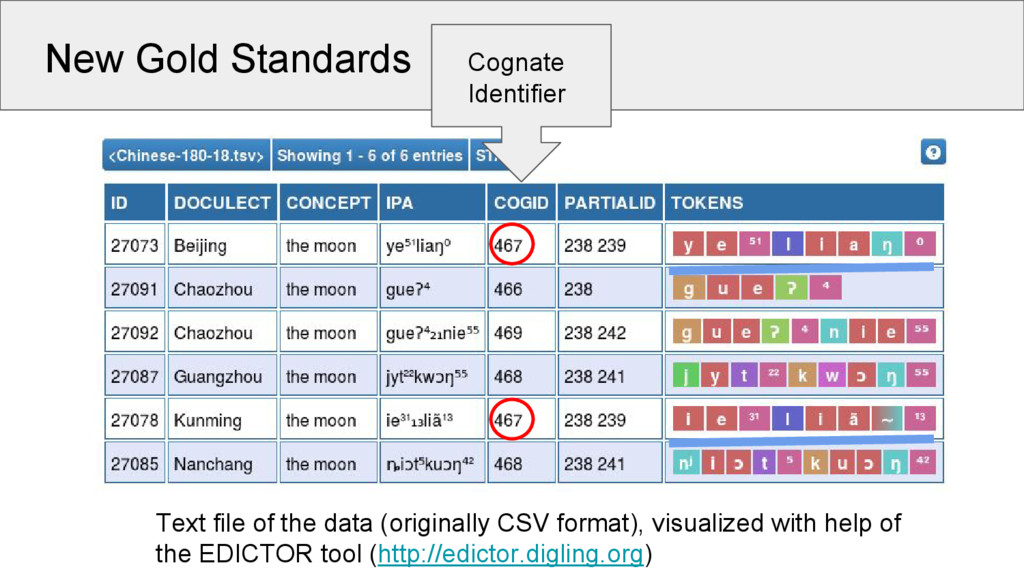
dialects English moon 1 Fúzhōu moon 1 German Mond 1 Měixiàn moon shine 1 2 Dutch maan 1 Wēnzhōu moon shine suff. 1 2 3 Swedish måne 1 Běijīng moon gloss 1 4 Ideally, we label them exactly as they are, as the exact coding enables us to switch to strict or loose coding automatically. exact coding of partial cognates
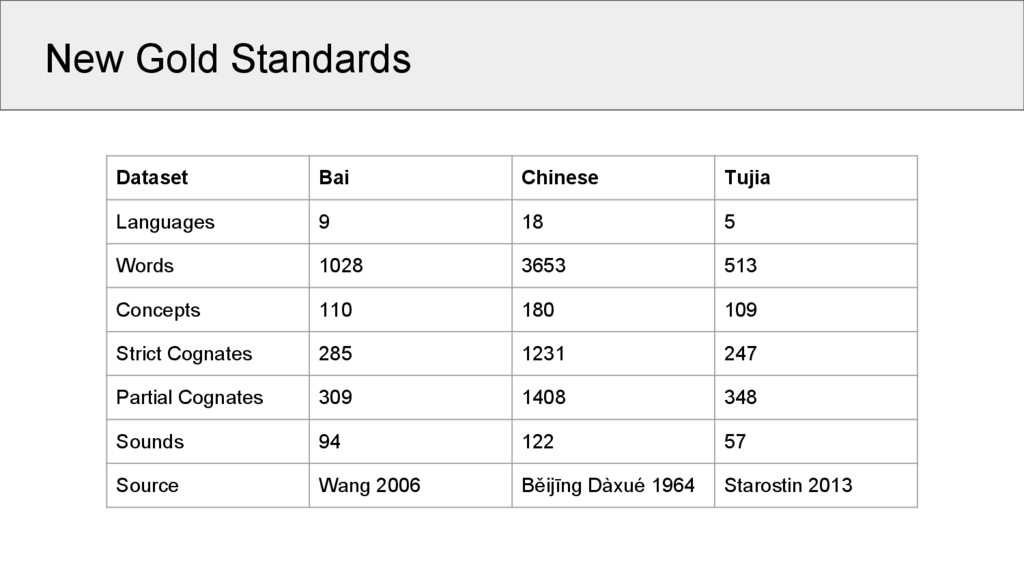
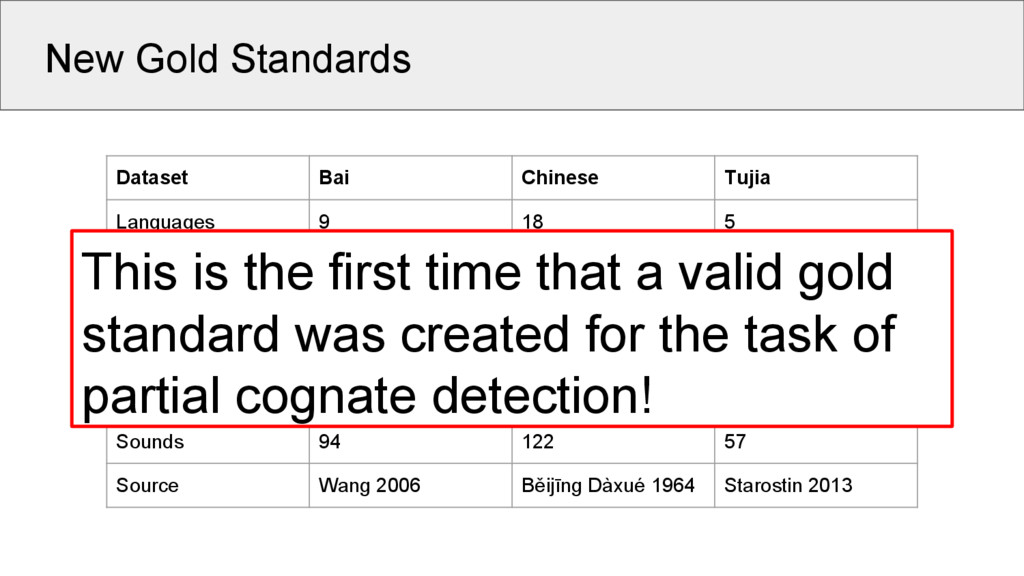
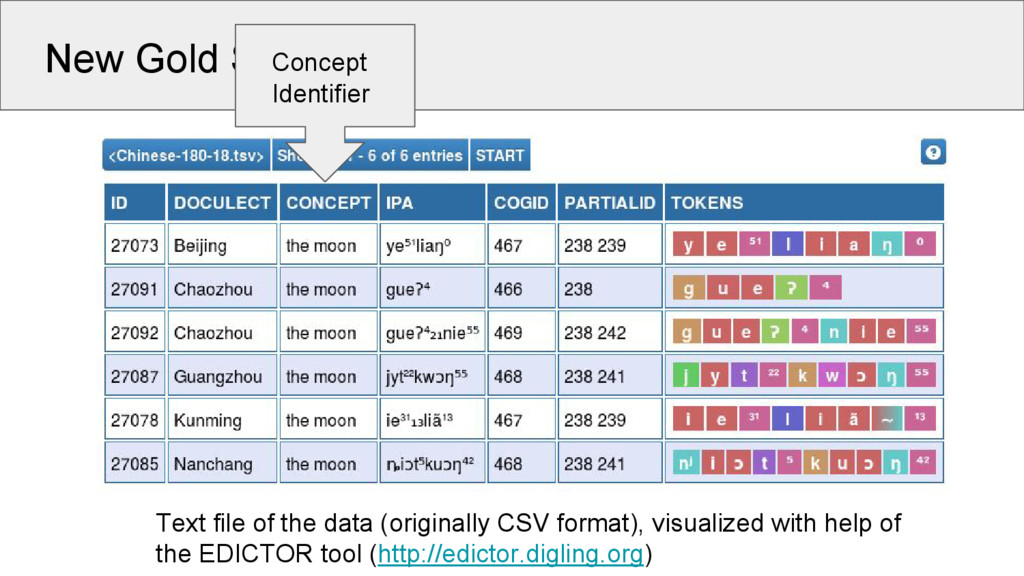
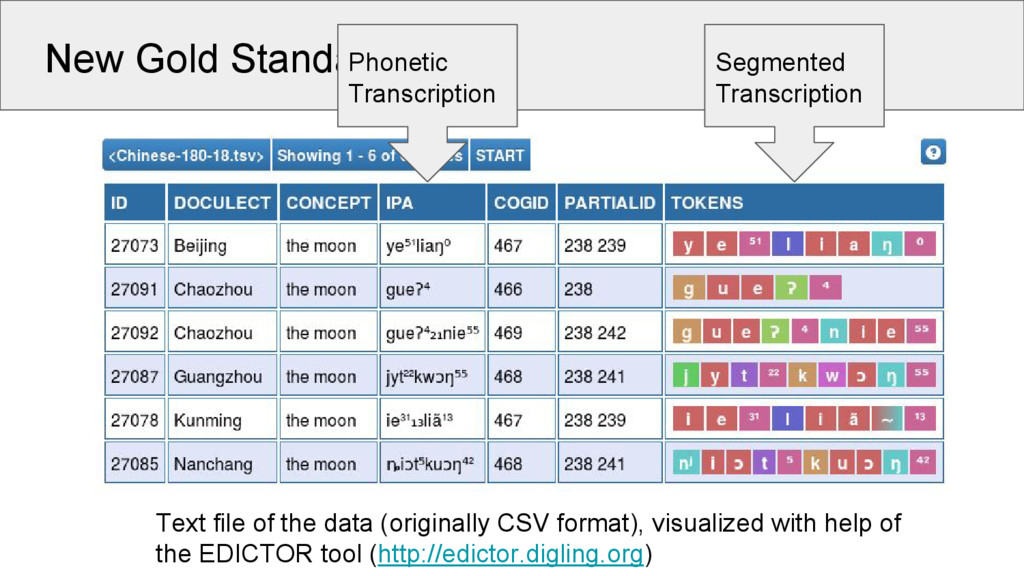
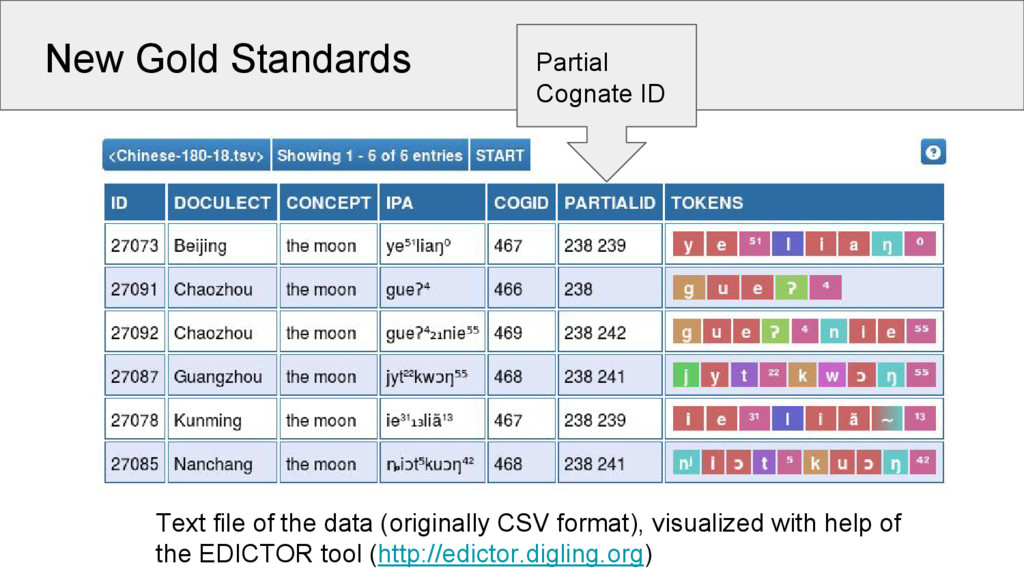
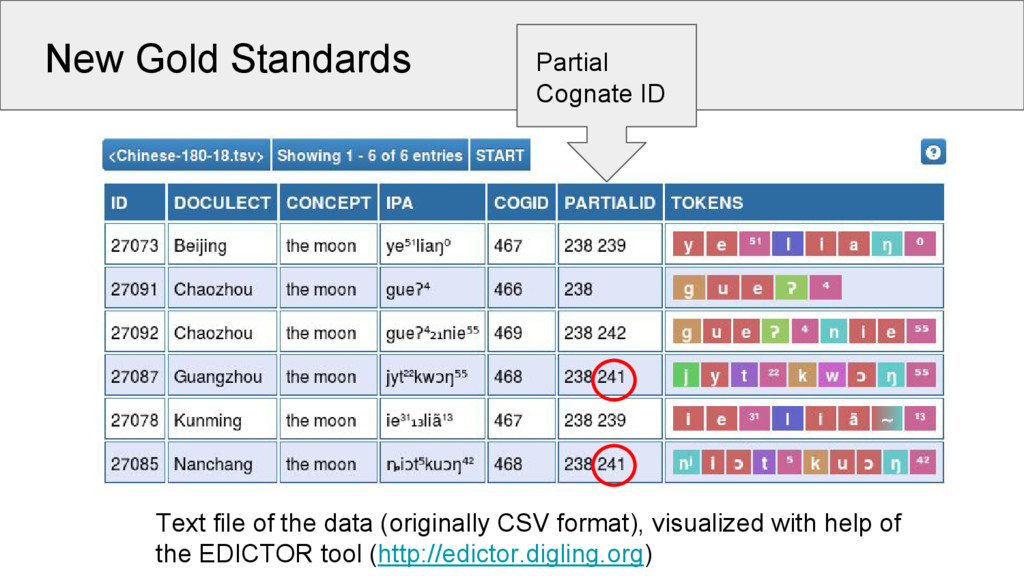
5 Words 1028 3653 513 Concepts 110 180 109 Strict Cognates 285 1231 247 Partial Cognates 309 1408 348 Sounds 94 122 57 Source Wang 2006 Běijīng Dàxué 1964 Starostin 2013 This is the first time that a valid gold standard was created for the task of partial cognate detection!
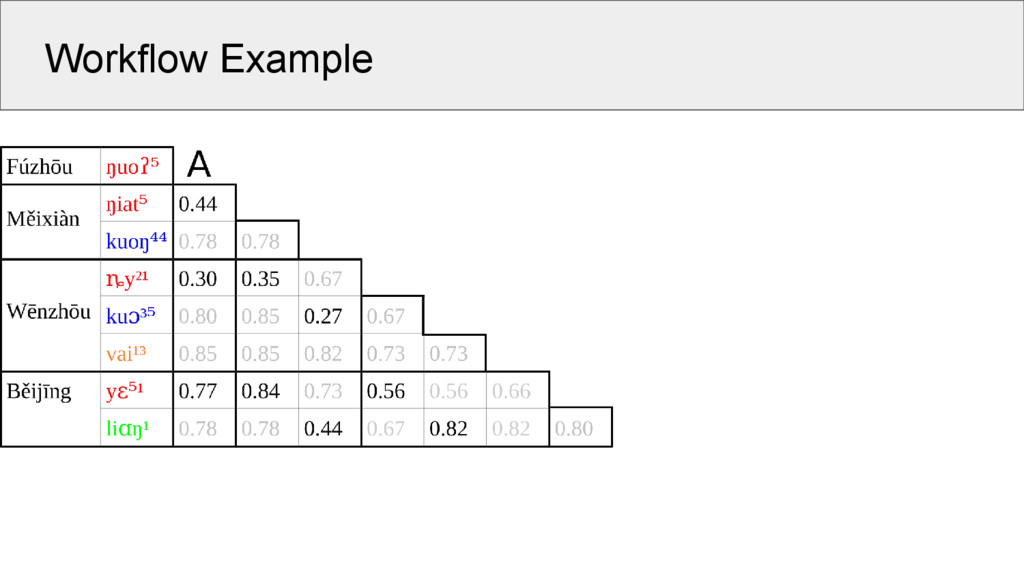
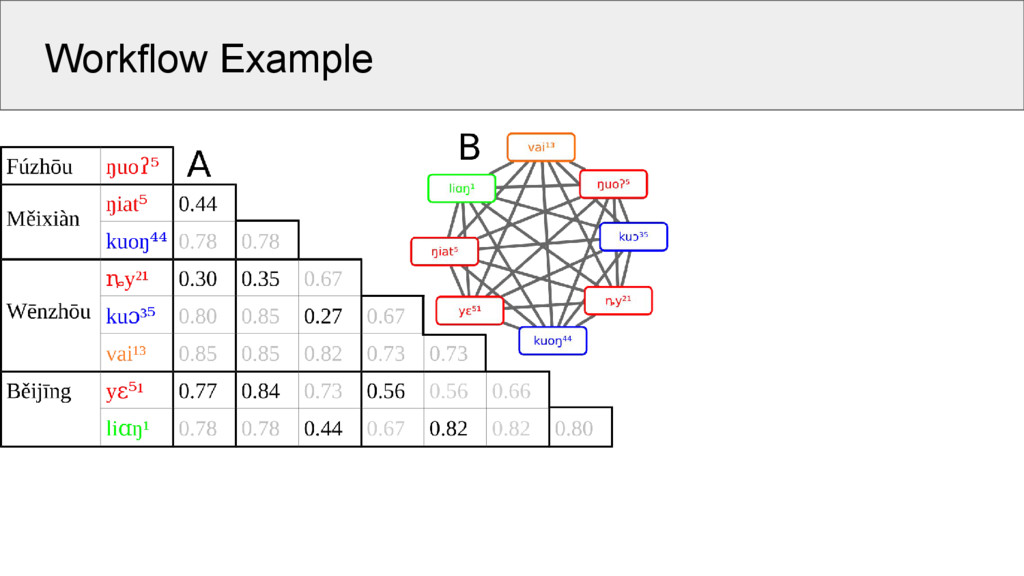
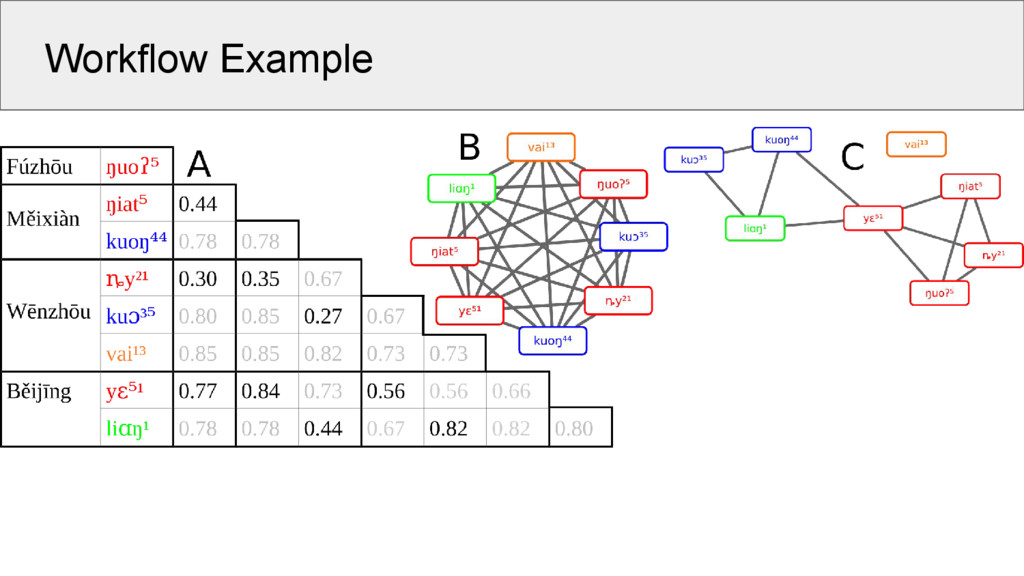
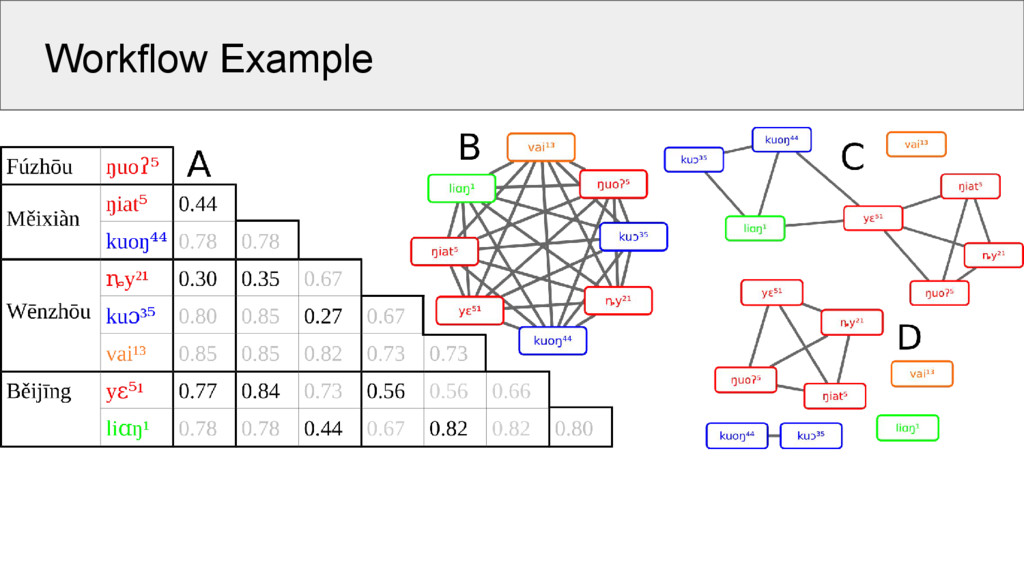
all words in the same meaning slot in a wordlist 2. create a similarity network in which nodes represent morphemes and edges represent similarities between the morphemes 3. use an algorithm for network partitioning to cluster the nodes of the network into groups of cognate morphemes
on the strings that are compared only b. any further information, like recurring similarities of sounds (sound correspondences) are ignored 2. language-specific measures a. previously identified regularities between languages are used to create a scoring function b. alignment algorithms use the scoring function to evaluate word similarity
(List 2012a & 2014) 2. Language-specific measures • LexStat algorithm (List 2012b & 2014) All algorithms are implemented as part of the LingPy software package (http://lingpy.org, List and Forkel 2016, version 2.5).
tools for exploratory data analysis (Méheust et al. 2016, Corel et al. 2016) • sequences (gene sequences in biology, words in linguistics) represent nodes in a network • weighted edges represent similarities between the nodes
a. draw no edges between morphemes in the same word b. in each word pair, link each morpheme only to one other morpheme (choose the most similar pair) c. only draw edges whose similarity exceeds a certain threshold
and Michener 1958) which terminates when a user-defined threshold is reached 2. Markov Clustering (van Dongen 2000) uses techniques for matrix multiplication to inflate and expand the edge weights in a given network 3. Infomap (Rosvall and Bergstrom 2008) was designed for community detection in complex networks and uses random walks to partition a network into communities
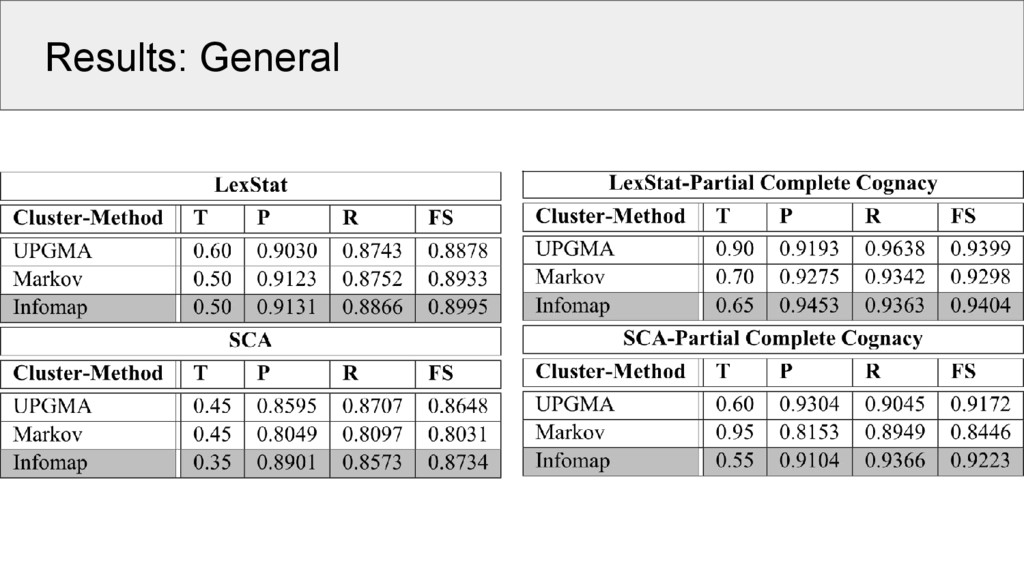
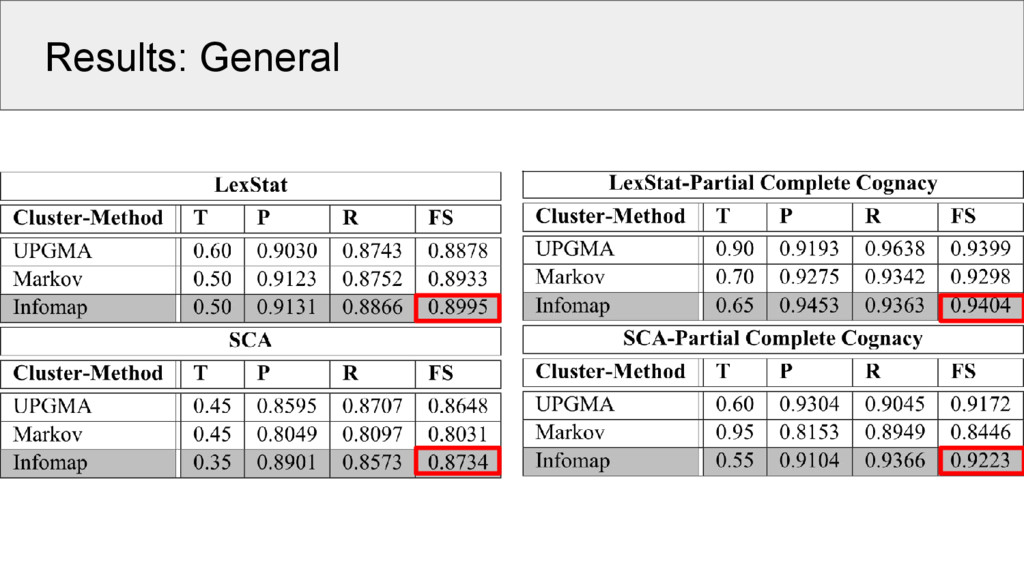
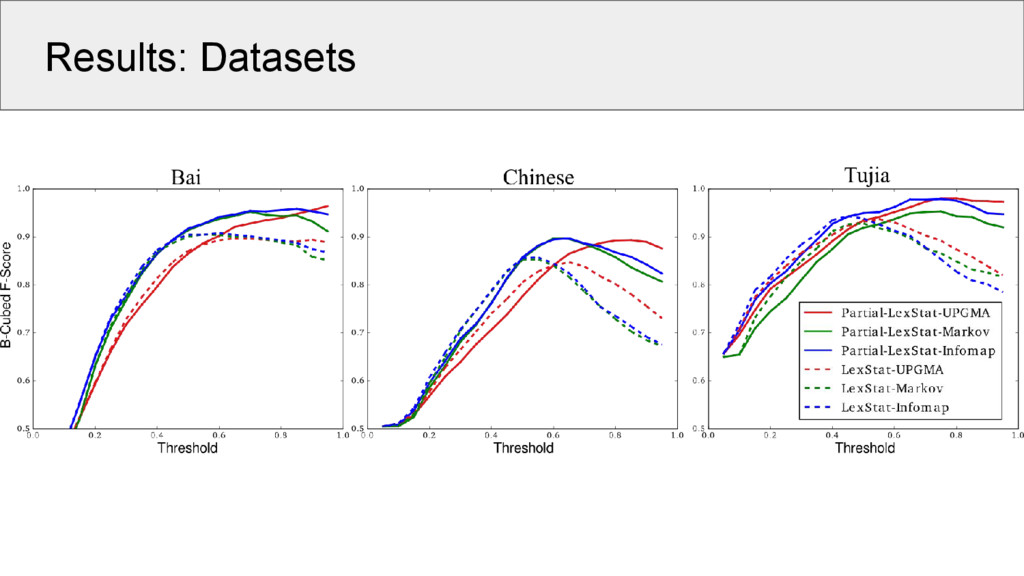
since our gold-standard data is too small to split it into test and training set, we carried out an exhaustive evaluation with a large range of thresholds varying between 0.05 and 0.95 in steps of 0.05 • B-Cubed scores (Bagga and Baldwin 1998) were used as evaluation measure, since they have been shown to yield sensible results (Hauer and Kondrak 2011)
cognate detection (SCA and LexStat) against their refined variants sensitive for partial cognates (SCA-Partial, LexStat-Partial) • since SCA and LexStat yield full cognate judgments, we need to convert the partial (exact) cognate judgments to full cognate accounts, using the criterion of full identity (strict encoding as shown before) • we tested also the accuracy of SCA-Partial and LexStat-Partial on partial cognacy, but cannot compare these scores with other algorithms
the LingPy library (Version 2.5, List and Forkel (2016), http://lingpy.org). The igraph software package (Csárdi and Nepusz 2006) is needed to apply the Infomap algorithm.
detection of partial cognates in multilingual word lists • further improvements are needed • we should test on additional datasets (new language families) and increase our data (testing and training) • our approach can be easily adjusted to employ different string similarity measures or partitioning algorithms: let’s try and see whether alternative measures can improve upon our current version
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}