“AI slop” — volume without verification • Action bias is measurable: given already-fixed bug reports, state-of-the-art agents still “fix” the working code in 35–65% of cases (FIXEDBENCH, 2026) • Agents often patch without reproducing the problem first • Every unneeded edit is future debugging debt, security surface, review load
the user’s actual problem — deeply enough to say “no” to the wrong solution • Design within constraints — security, cost, operations, compliance • Master the Secure Software Delivery Life Cycle — idea → code → build → deploy → operate → learn • Code is one station on that line — and AI accelerated one station mostly
“The fastest way to make your agents better at your codebase is a tighter feedback loop with scripts you already have.” — “Beyond the basics with Claude Code”, Code w/ Claude 2026 • Give the agent a way to verify its own work • Zero new infrastructure: your build, tests, linter, typechecker already exist
· run · generate Observe tests · types · lint · logs Correct compare to target · adjust iterate until the sensor is green The agent’s senses are scripts you already have: build · unit tests · linter · typechecker · LSP
• LLMs optimize toward a target — so give them a measurable one • No sensor → plausible-looking output, confidently wrong • With a sensor → iteration converges; errors become input, not outcome
Deterministic beats vague: exit codes, failing test names, line numbers — not “looks wrong” • Fast beats thorough-but-slow: millisecond lint before minute-level suites — run both, in that order • “Red squigglies for agents”: corrections injected at the moment of the mistake, not at review time • Order checks by cost: lint → typecheck → unit → integration — the test pyramid, repurposed
— write the sensor before the code • CI — the loop, centralized and enforced • Observability — the loop, running in production • What changed: the consumer of feedback is now a machine — running the loop thousands of times, at machine speed, without ego
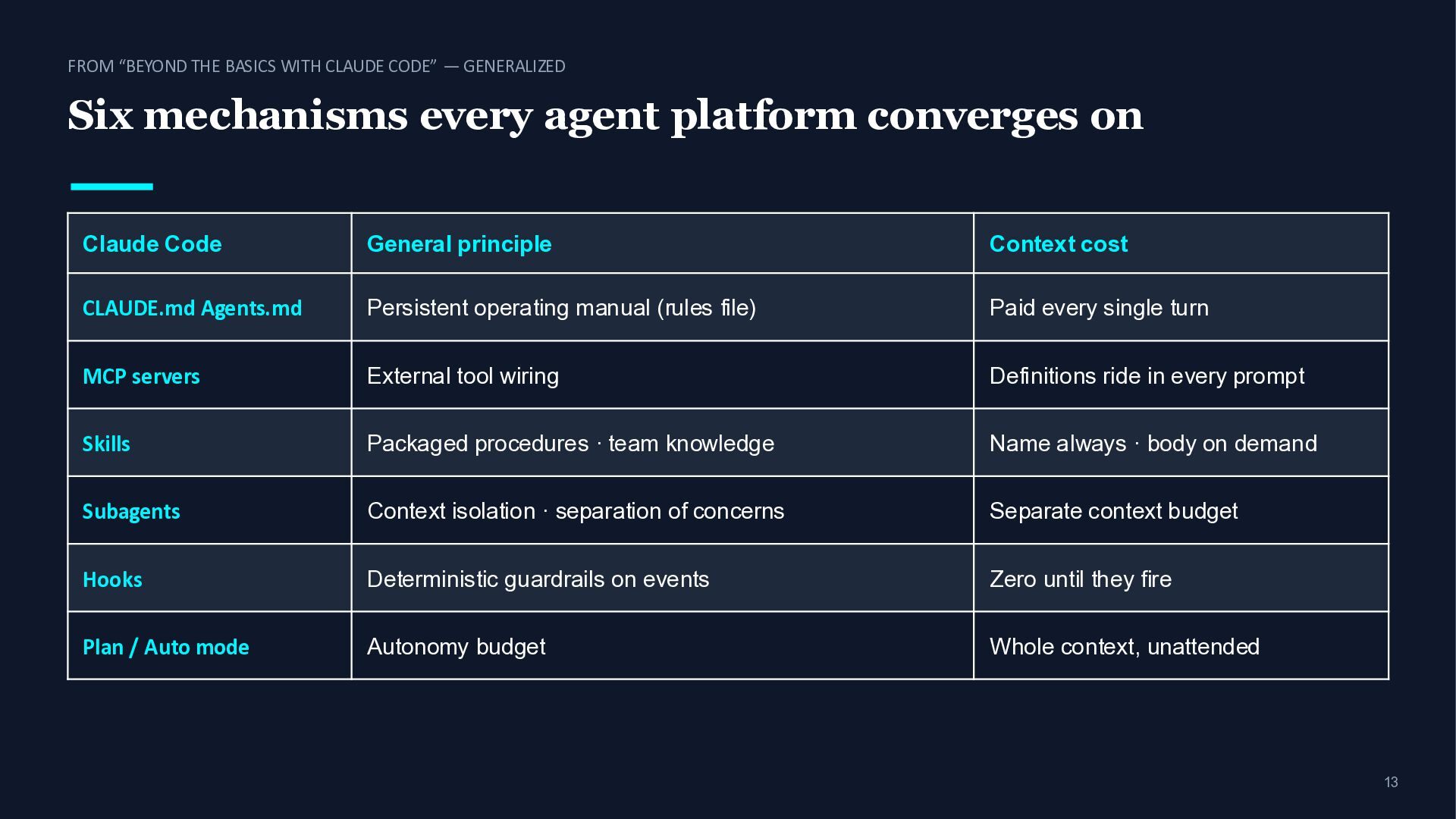
Six mechanisms every agent platform converges on Claude Code General principle Context cost CLAUDE.md Agents.md Persistent operating manual (rules file) Paid every single turn MCP servers External tool wiring Definitions ride in every prompt Skills Packaged procedures · team knowledge Name always · body on demand Subagents Context isolation · separation of concerns Separate context budget Hooks Deterministic guardrails on events Zero until they fire Plan / Auto mode Autonomy budget Whole context, unattended
lean, or it backfires • Injected into every conversation — every line costs context, every single turn • Stuffing in every convention makes performance worse and costlier (yes, worse — from the session) • Heuristic: remove any line whose absence causes no observed mistakes • Let failures write the manual: after an agent error → “update the rules so this doesn’t repeat”
challenges: choosing the right information for a fixed box.” Context windows have barely grown for a year+. Selection is the game. And selection is engineering.
second constraint TURN N system tools CLAUDE.md skills conversation new msg TURN N+1 — ONE TOOL DEFINITION CHANGED system tools+1 CLAUDE.md skills conversation new msg cached (~90% off) changed recomputed • Change one byte near the front → everything after it recomputes • Stable, shared content up front · volatile, per-task content at the end • The cache key is the prefix, not the item
out • Every tool definition rides in the prompt: 20 servers × 15 tools ≈ a prompt that is mostly tool definitions • A working CLI beats an MCP wrapper — agents speak bash natively • Your Makefile, npm scripts, gh, kubectl are already an agent interface • Save protocol integrations for what CLIs can’t do: authenticated APIs, stateful sessions, browser/IDE surfaces
on demand • Progressive disclosure: a one-line name + description is always visible; the full procedure loads only when relevant • Encode the workflows, quality gates and best practices senior engineers actually use — reviews, audits, release prep, incident drills • Versioned in git — code-reviewed, diff-able, onboarding for agents and humans alike • Portable: the same packaged procedure serves multiple agents and platforms
to follow rules. Enforce them. • The only mechanism with zero context cost until it fires — runs outside the model, injects only when triggered • Deterministic scripts on events: before a tool runs · after an edit · on completion • “Red squigglies for agents”: lint/typecheck/test feedback at mistake-time, not review-time • You already do this to humans: pre-commit hooks, branch protection, CI gates — same pattern, new subject
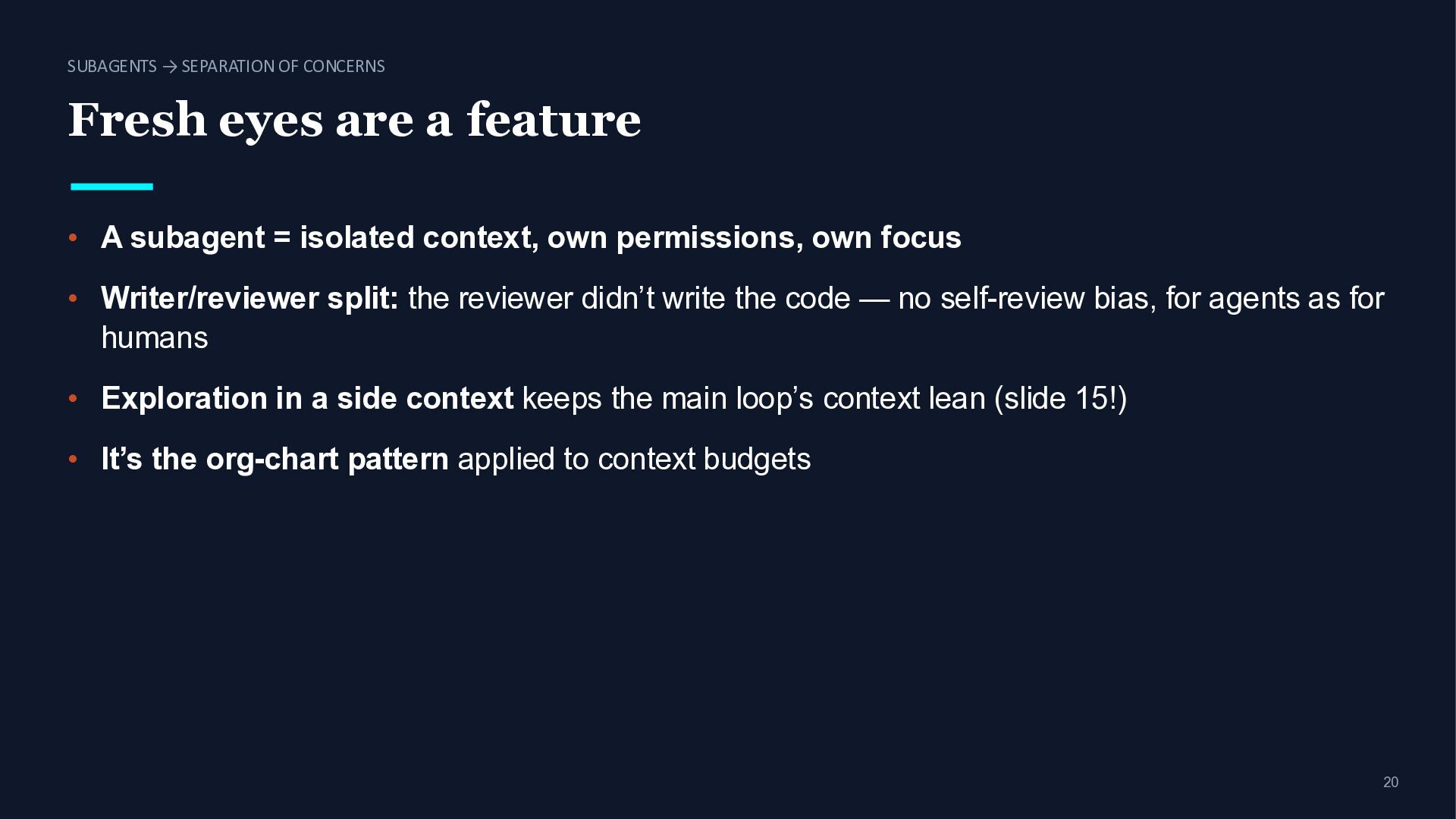
feature • A subagent = isolated context, own permissions, own focus • Writer/reviewer split: the reviewer didn’t write the code — no self-review bias, for agents as for humans • Exploration in a side context keeps the main loop’s context lean (slide 15!) • It’s the org-chart pattern applied to context budgets
sessions without collision • Each worktree is an independent checkout — same repo, isolated branches, separate working directories • No lock file conflicts, no stale context — each agent gets a pristine copy to work in • Perfect for: reviewing code while another agent is writing · exploring + evaluating in parallel · running multiple chains on the same codebase • Setup: git worktree add ../my-task my-branch · agent runs in that directory · cleanup is git worktree prune
• Frontier models now run unattended for hours — fleets of asynchronous agents are becoming normal • Before scaling autonomy, sandbox it: network off by default, least-privilege filesystem • A tight perimeter lets you relax oversight — that’s the trade; make it explicit • My setup: “trust but verify” — a nono-based sandbox wrapper around the agent (write-up on the blog)
harness, not the prompt • Agentic Harness Engineering (2026): automatic agent improvement — the gains came from evolving tools, middleware and memory • Evolving only the system prompt? Performance regressed • Structure and rules belong in tools and enforcement, not prose • “Prompt engineering” is becoming harness engineering — and harness engineering is software engineering
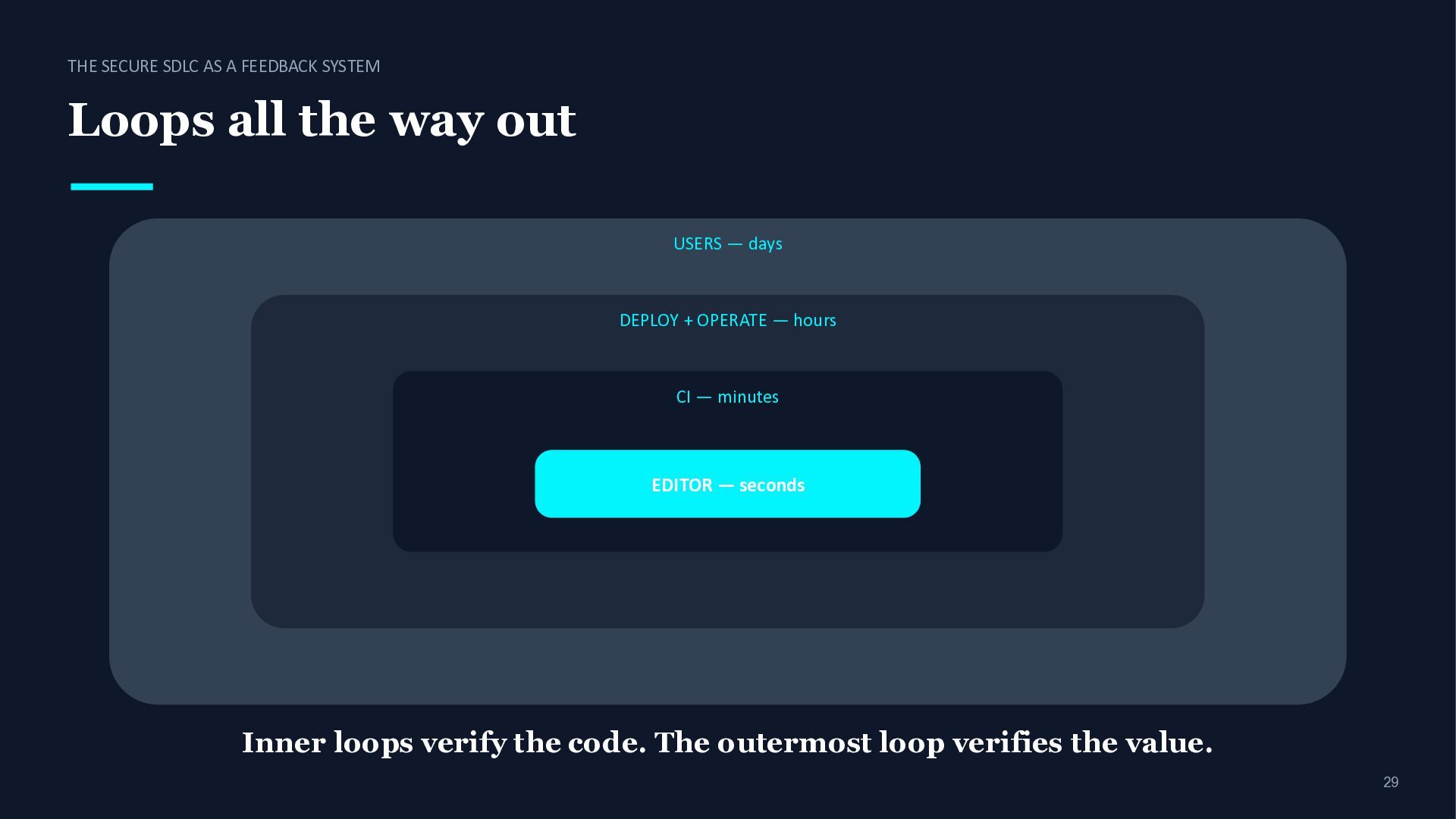
stage a sensor Require acceptance tests · specs Code types · lint · unit tests Integrate CI · contract tests Deploy canary · rollback signals Operate metrics · alerts · SLOs Learn analytics · user feedback A sensor = a machine-readable answer to “is this still good?” If a stage has no sensor, neither humans nor agents can verify it.
final gate to continuous sensor • Commit-time: secret scanning in pre-commit hooks • Build-time: dependency pinning · review of new transitive dependencies • PR-time: SAST · security-review agents on every diff • Run-time: sandboxing · least privilege · egress control • Each one: deterministic, automatic, at the moment of action — hooks (slide 19), at SDLC scale
an autonomous agent hurts you • User misuse — careless or malicious direction: “just bypass the check” • Model misbehavior — capable models route around restrictions nobody wrote down: sandbox escapes “to be helpful”, mining git history for test answers • External attackers — prompt injection through tools, files, and web content the agent reads • Defense: confine for blast radius — risk = P(failure) × damage; shrink the damage term
no security meter for AI. • Benchmark scores are not security ratings — contamination, gaming, anthropomorphism • Pen tests and red teams are “badness-ometers”: they find badness, they don’t prove security • What reliably works: organisational processes and quality gateways
the scripts you already have — build, test, lint — and wire them into your agent 2. Write the lean operating manual — then delete the aspirational lines 3. Package one senior-engineer runbook as an on-demand procedure 4. Add one deterministic guardrail at the moment of action (protect secrets first) 5. Sandbox before you scale autonomy — network off by default, least privilege 6. Measure: cache hit rate · loop latency · iterations-to-green
— understanding the deep-seated challenges users actually face • Defining what “good” means — writing the sensors, setting the thresholds • Owning the blast radius — accountability does not delegate • Knowing when not to act — simplicity first; sometimes the right patch is the empty patch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}