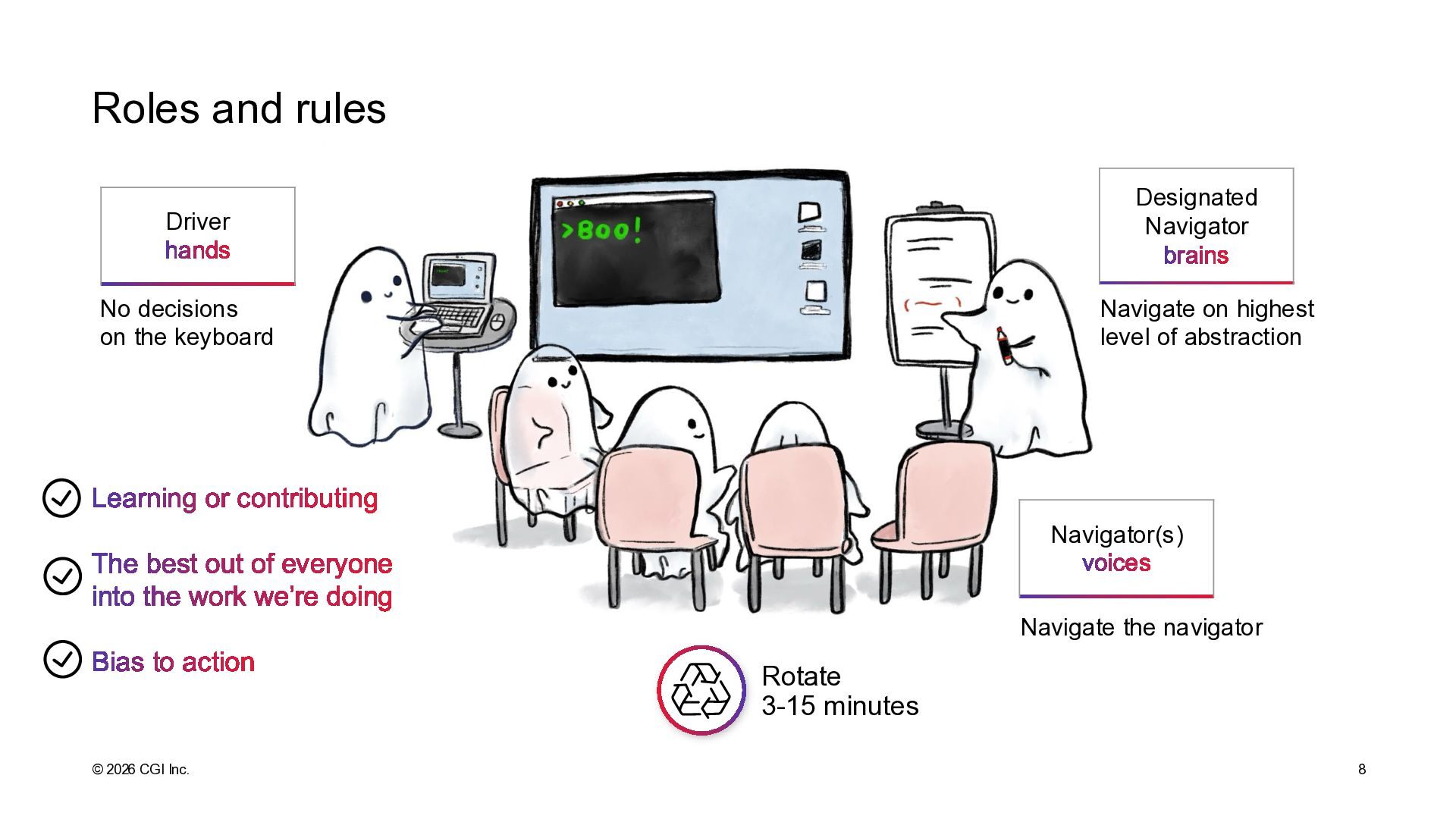
testing) approach In Ensemble programming, we connect the software creation work the team does through a single computer the whole team shares. All ideas flow through someone else’s hands, and get reviewed and improved through continuous, structured collaboration.
Navigator(s) voices No decisions on the keyboard Navigate on highest level of abstraction Navigate the navigator Learning or contributing The best out of everyone into the work we’re doing Bias to action Rotate 3-15 minutes Roles and rules
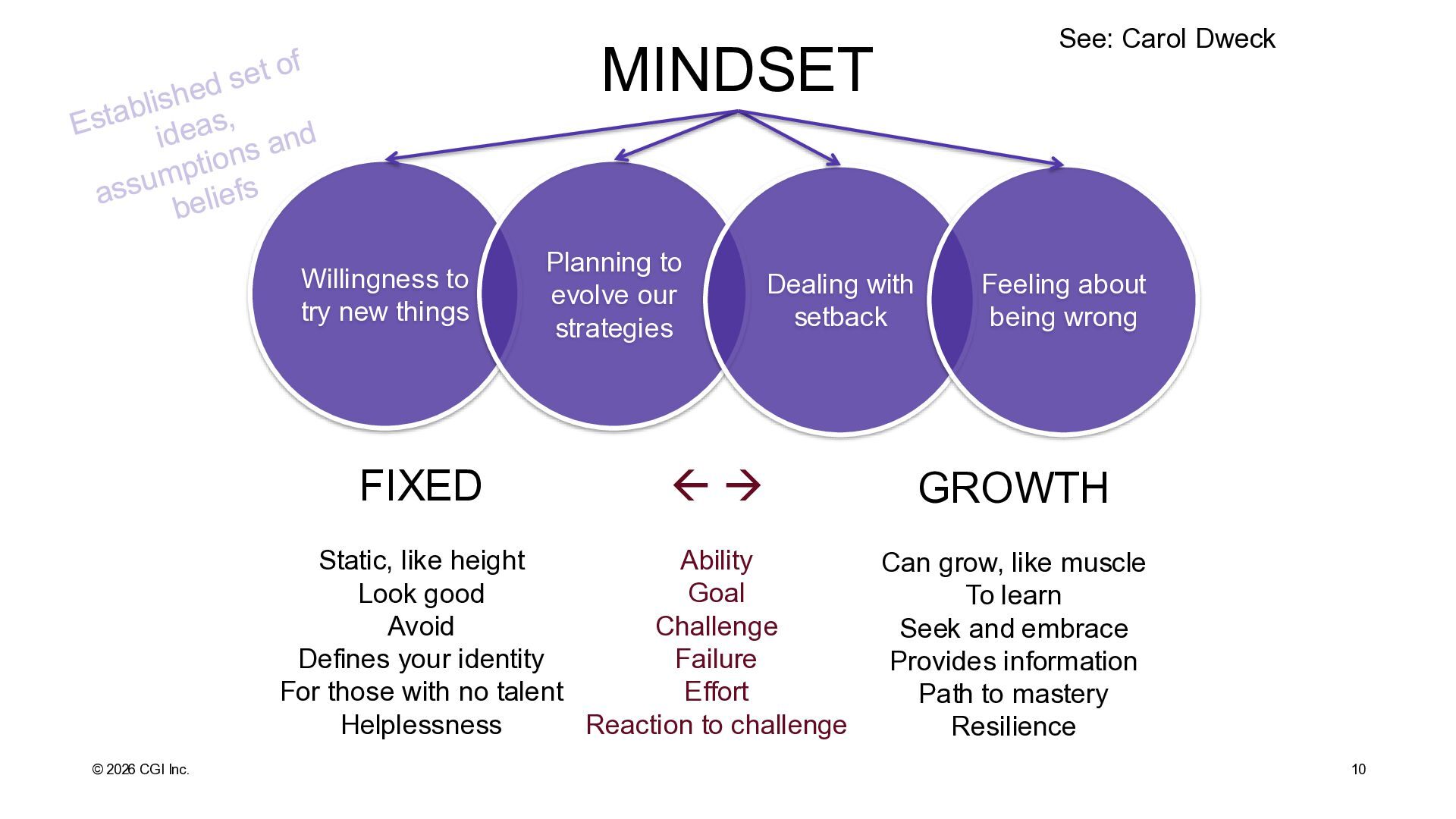
Planning to evolve our strategies Dealing with setback Feeling about being wrong MINDSET See: Carol Dweck FIXED Static, like height Look good Avoid Defines your identity For those with no talent Helplessness GROWTH Can grow, like muscle To learn Seek and embrace Provides information Path to mastery Resilience → Ability Goal Challenge Failure Effort Reaction to challenge
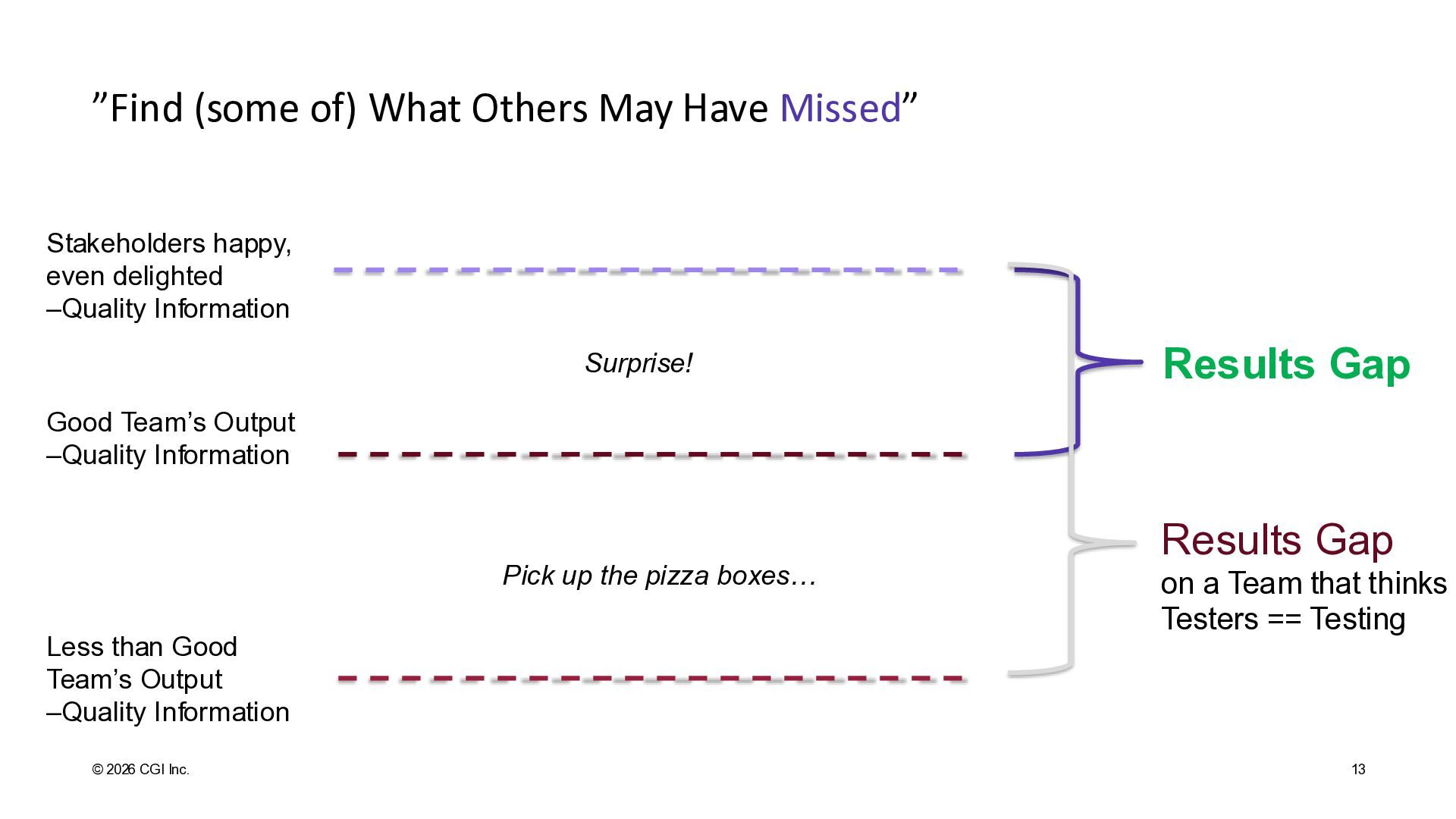
Information Good Team’s Output –Quality Information Less than Good Team’s Output –Quality Information Results Gap Surprise! Results Gap on a Team that thinks Testers == Testing Pick up the pizza boxes… ”Find (some of) What Others May Have Missed”
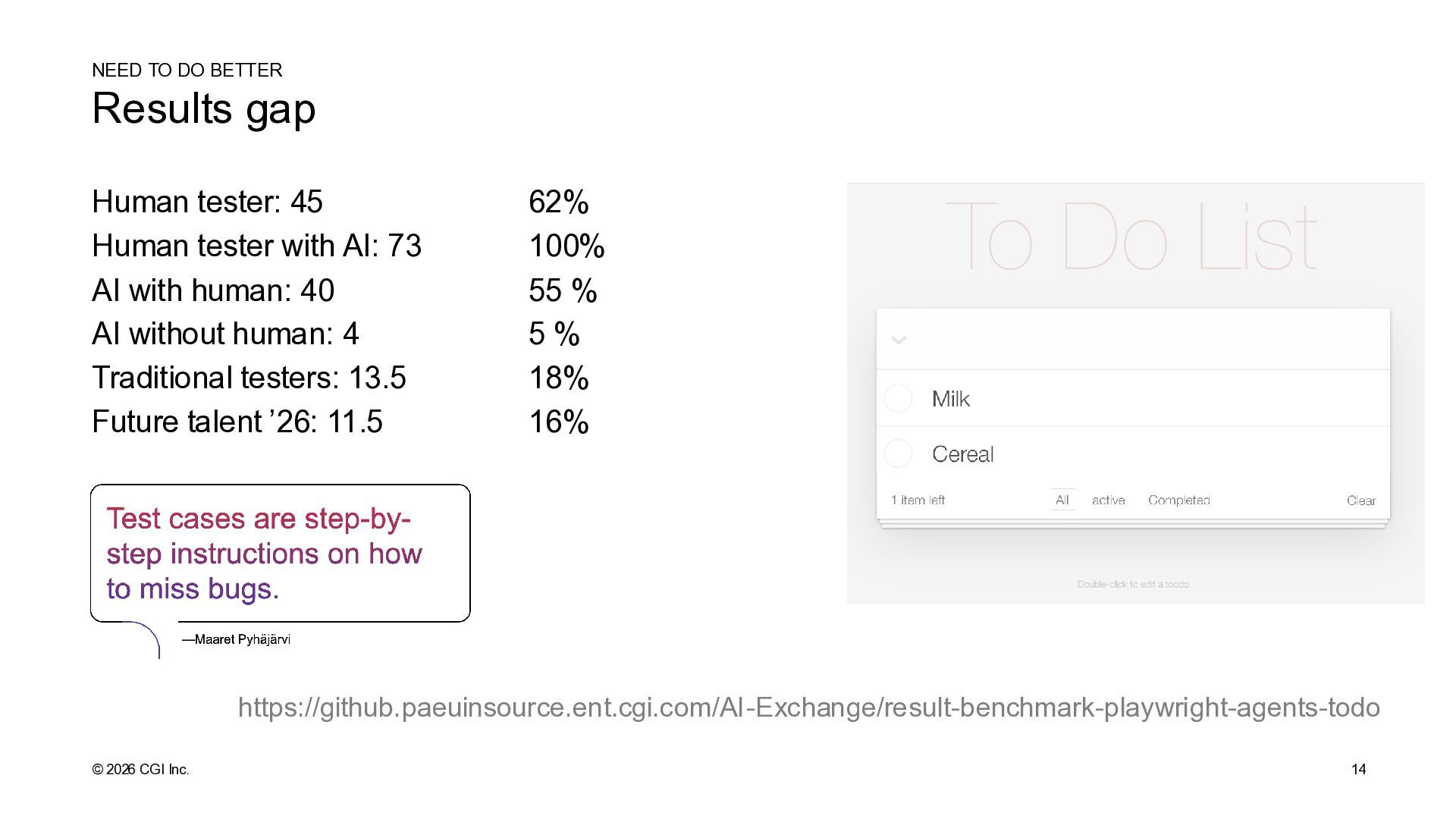
BETTER Human tester: 45 62% Human tester with AI: 73 100% AI with human: 40 55 % AI without human: 4 5 % Traditional testers: 13.5 18% Future talent ’26: 11.5 16% https://github.paeuinsource.ent.cgi.com/AI-Exchange/result-benchmark-playwright-agents-todo
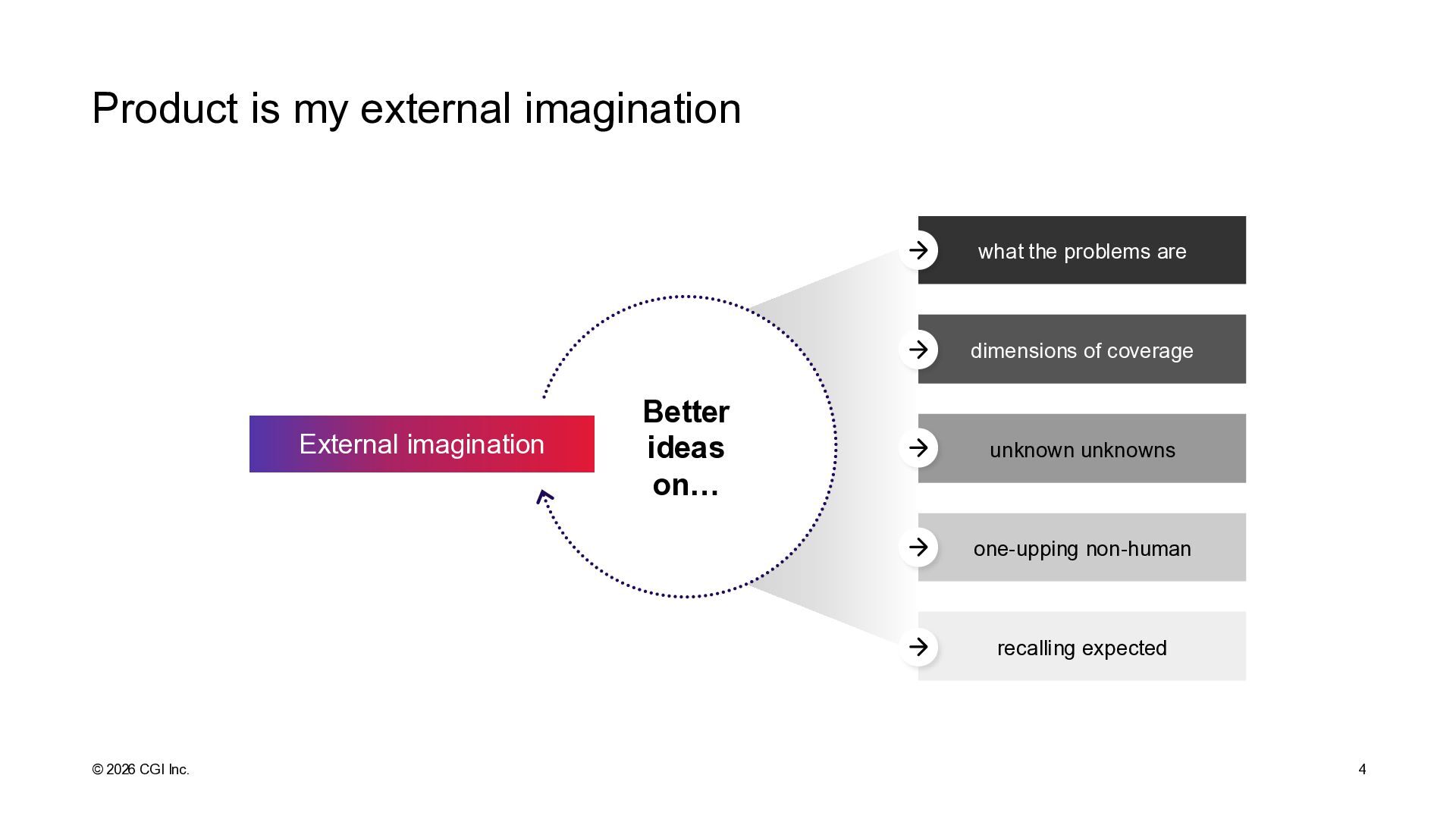
EXAMPLE WOULD BE GOOD, RIGHT ABOUT HERE What we did: Started with a repo with application code Tested remote control by creating list of participants while doing introductions Generated a list of features by access to code Generated a list of bugs (11) by access to code Installed playwright and playwright agents Generated a list of bugs (21) by access to the UI Combined the two lists of bugs to identify overlap Generated test cases with playwright agents Compared the list of features to test cases for coverage analysis Automated a failing test for bug number 3 Fixed the bug by requesting a fix for bug number 3 Run the test automation to see it passing Refactored the automated tests to POM While doing all this, very meta, learning testing and tools by testing: Learned to discuss our intent and options Discussed why Selenium WebDriver BiDi and Vibium is comparable (but better) than Playwright and Playwright agents Discussed availability of MCPs as way of extending what we could get it to do Discovered and named a lot of the GitHub Copilot functionality from model selection, to GitHub Copilot Agent Mode to Playwright agents, to context window and premium request consumption Discussed how the experience with contemporary exploratory testing is very different to what participants had learned to expect from exploratory testing AI as externa l imagin ation a nd task expansio n Intentionally bug-filled test target by Christine Pinto
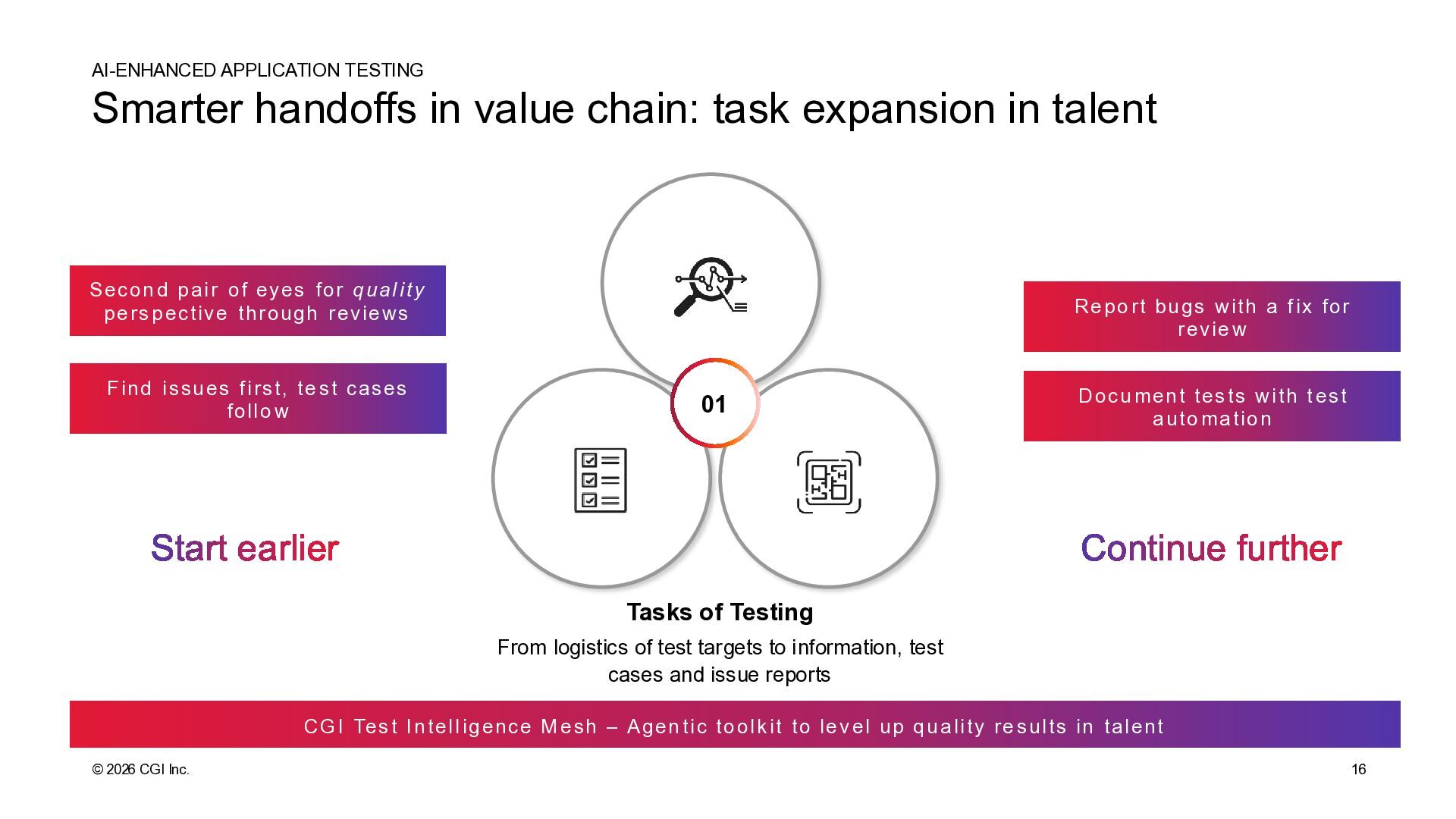
task expansion in talent AI-ENHANCED APPLICATION TESTING 01 Tasks of Testing From logistics of test targets to information, test cases and issue reports Docu ment tes ts with t est auto mation Repo rt bugs with a f ix for revie w Secon d pair of eyes for qual ity pers pective through reviews Find issues f irst, te st cases follo w Start earlier Continue further CGI Tes t Intell igence M esh – Agen tic toolk it to lev el up qu ality re sults in talent
Founded in 1976, CGI is among the largest IT and business consulting services firms in the world. We are insights-driven and outcomes-focused to help accelerate returns on your investments. Across hundreds of locations worldwide, we provide comprehensive, scalable and sustainable IT and business consulting services that are informed globally and delivered locally. cgi.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}