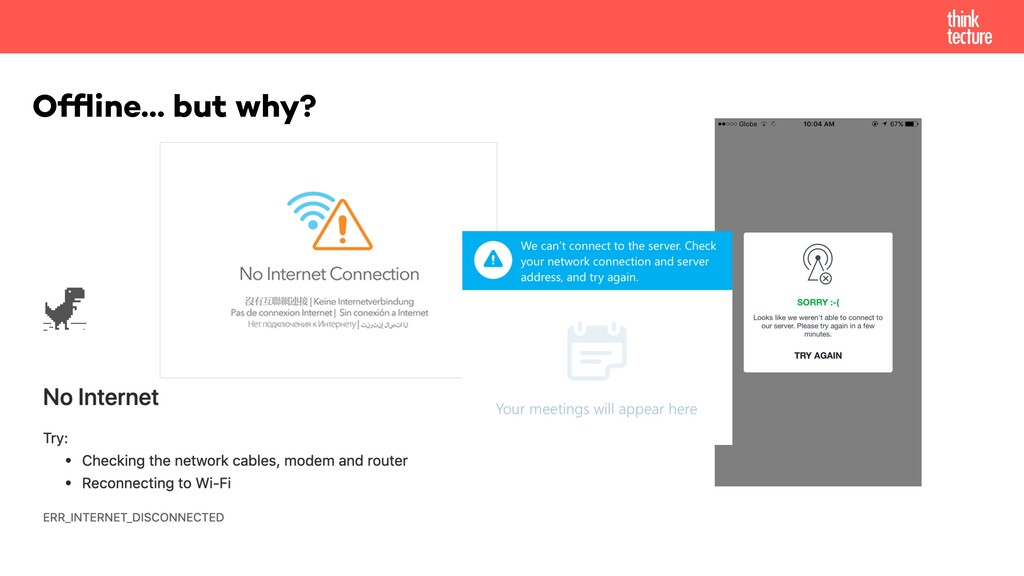
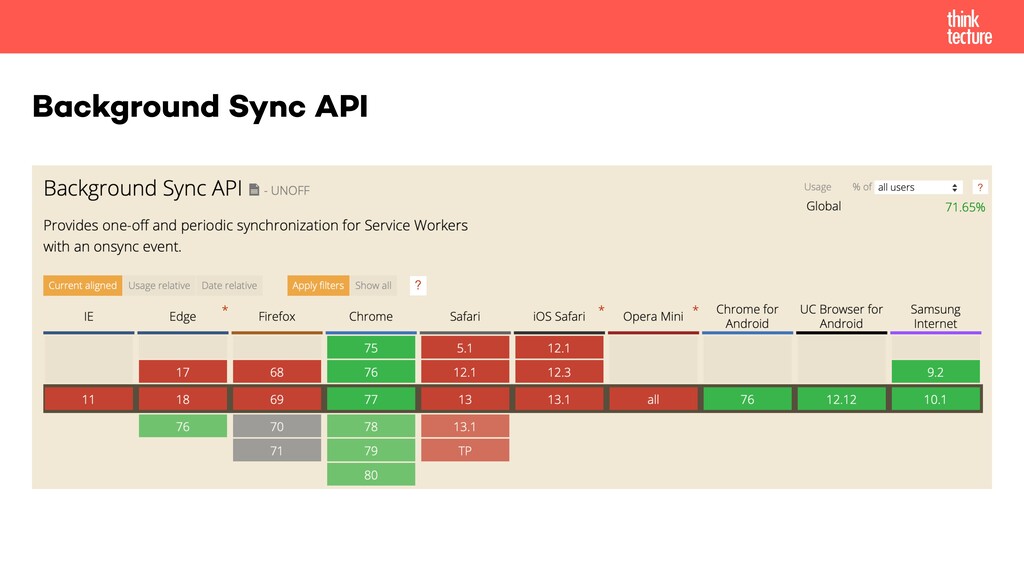
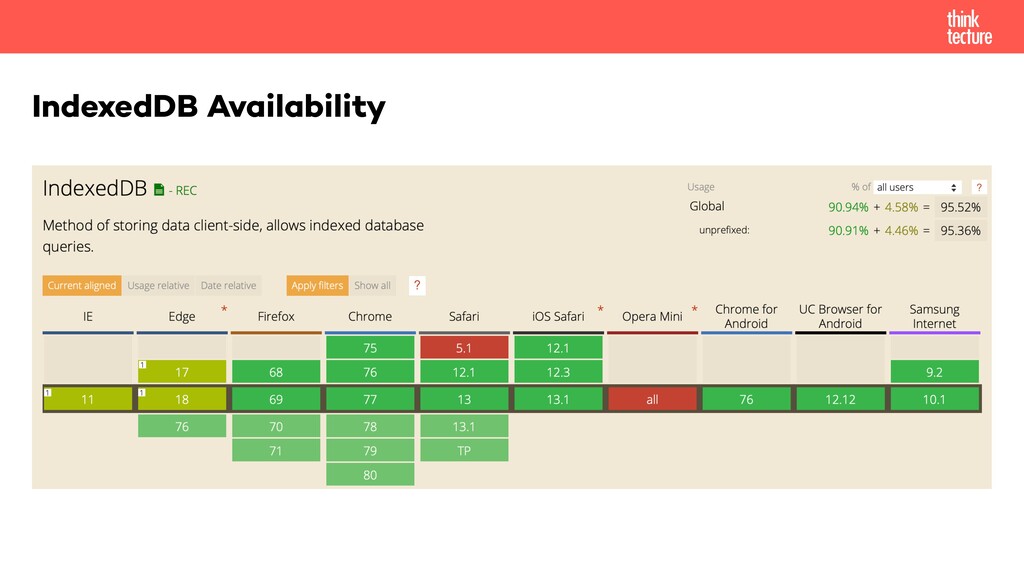
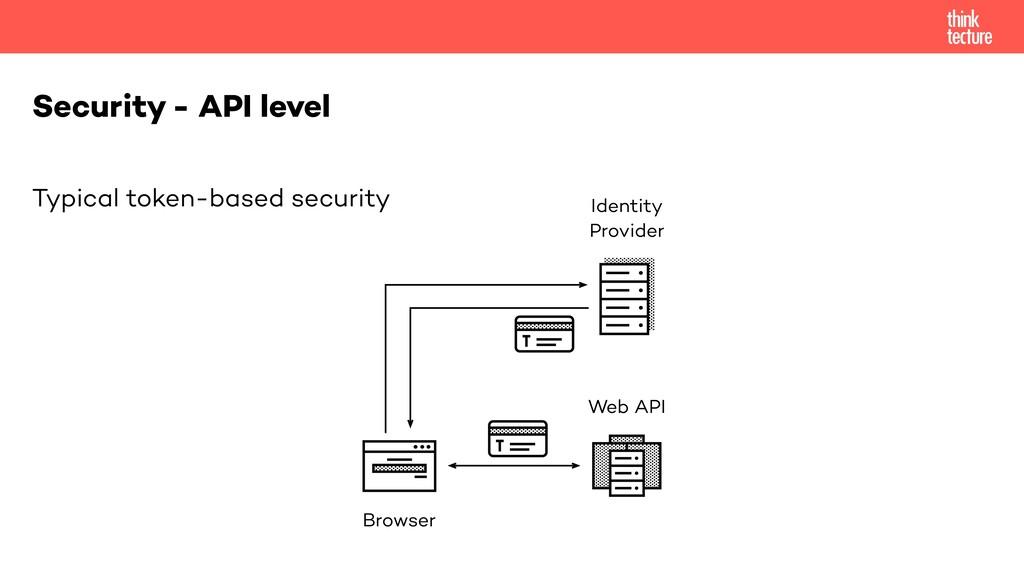
"Keine Internetverbindung" – ein Satz, den wir alle aus vielen Apps kennen, sei es Desktopanwendung oder Smartphone App. Oftmals sind die Clients auf dem jeweiligen Zielgerät installiert, bedienen sich aber einer externen Datenquelle, bspw. in Form eines HTTP APIs. Wie man sein Backend um eine offline-fähige Architektur erweitert, um es bspw. von einer SPA/PWA nutzen zu können, zeigen Thomas Hilzendegen und Manuel Rauber von Thinktecture in diesem Workshop. Denn bei einer offline-fähigen Implementierung sind nicht nur Lese-, sondern vor allem auch Schreibzugriffe wichtig. Sprich, die Daten müssen in beide Richtungen synchronisiert werden können, sobald die Internetverbindung wiederhergestellt wurde. Allgemein werden Themen im API Design, u.a. Synchronisationsstrategien von Anwendungs- und großen Binärdaten, Konfliktmanagement oder Datenbankarchitektur – sowohl für neue als auch bestehende Anwendungen – diskutiert. Am Beispiel einer PWA mit einem Backend in Java als auch in .NET Core werden Client und Server zur Umsetzung der besprochenen Konzepte und Patterns gezeigt.
GitHub: https://github.com/thinktecture/thinktecture-boardist
{kind=link}
![Thomas Hilzendegen Speakers Manuel Rauber [email protected] @hilzendegent [email protected] @manuelrauber https://manuel-rauber.com](https://files.speakerdeck.com/presentations/65aa28853e774778b7228dfbe22ab299/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}