Google hanno deciso di implementare internamente delle soluzioni che avessero come caratteristica principale la scalabilità orizzontale Le implementazioni dei due giganti del web hanno dato il via ad un piccolo esercito di database “alternativi” (chiamati poi NOSQL)
Distribuito Open-source Scalabile orizzontalmente In accordo con la definizione data su http://nosql-database.org/ Inteso come modello di trattamento del dato Deve essere scalabile “by design” Supporto?
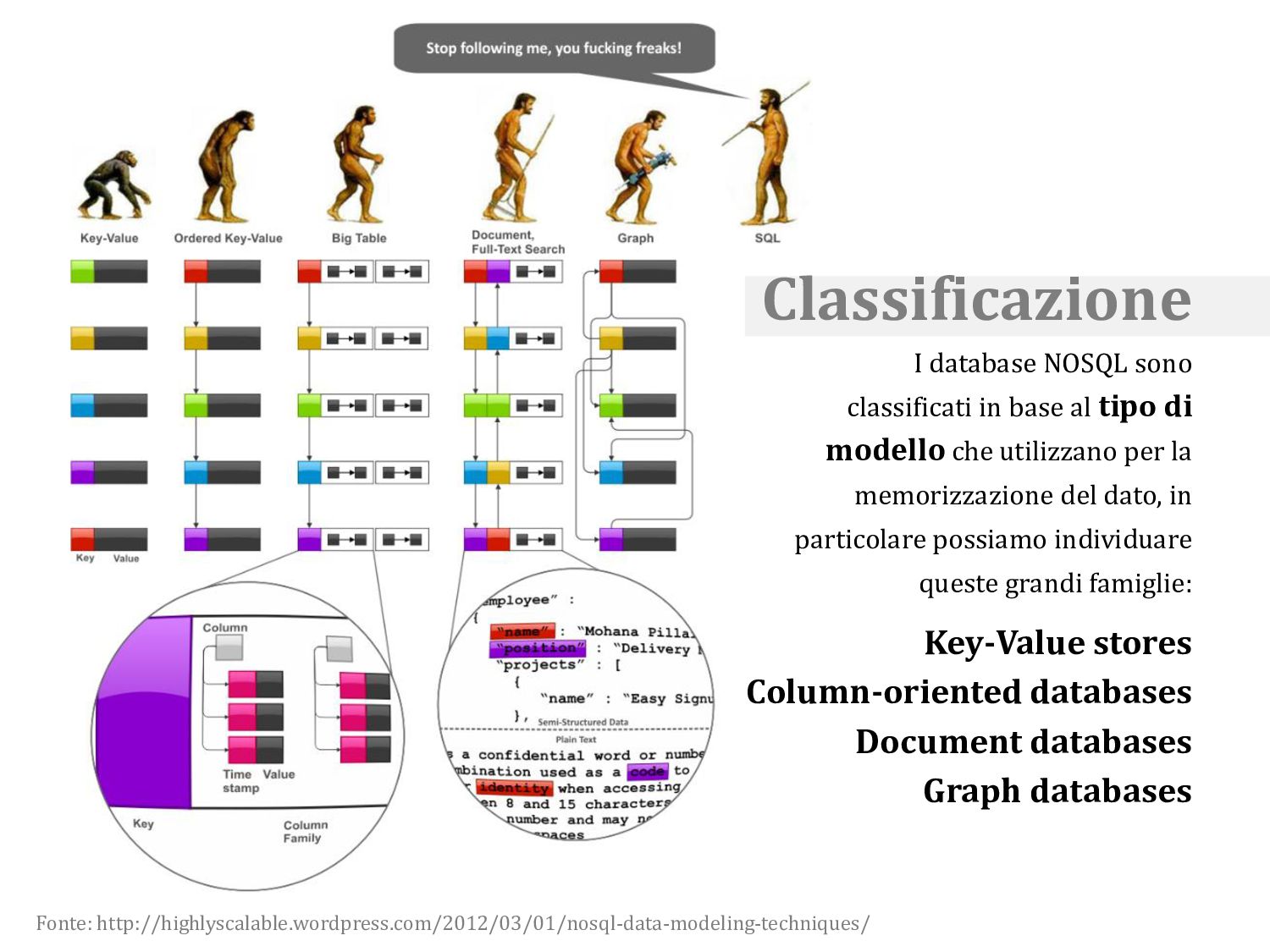
modello che utilizzano per la memorizzazione del dato, in particolare possiamo individuare queste grandi famiglie: Key-Value stores Column-oriented databases Document databases Graph databases Classificazione Fonte: http://highlyscalable.wordpress.com/2012/03/01/nosql-data-modeling-techniques/
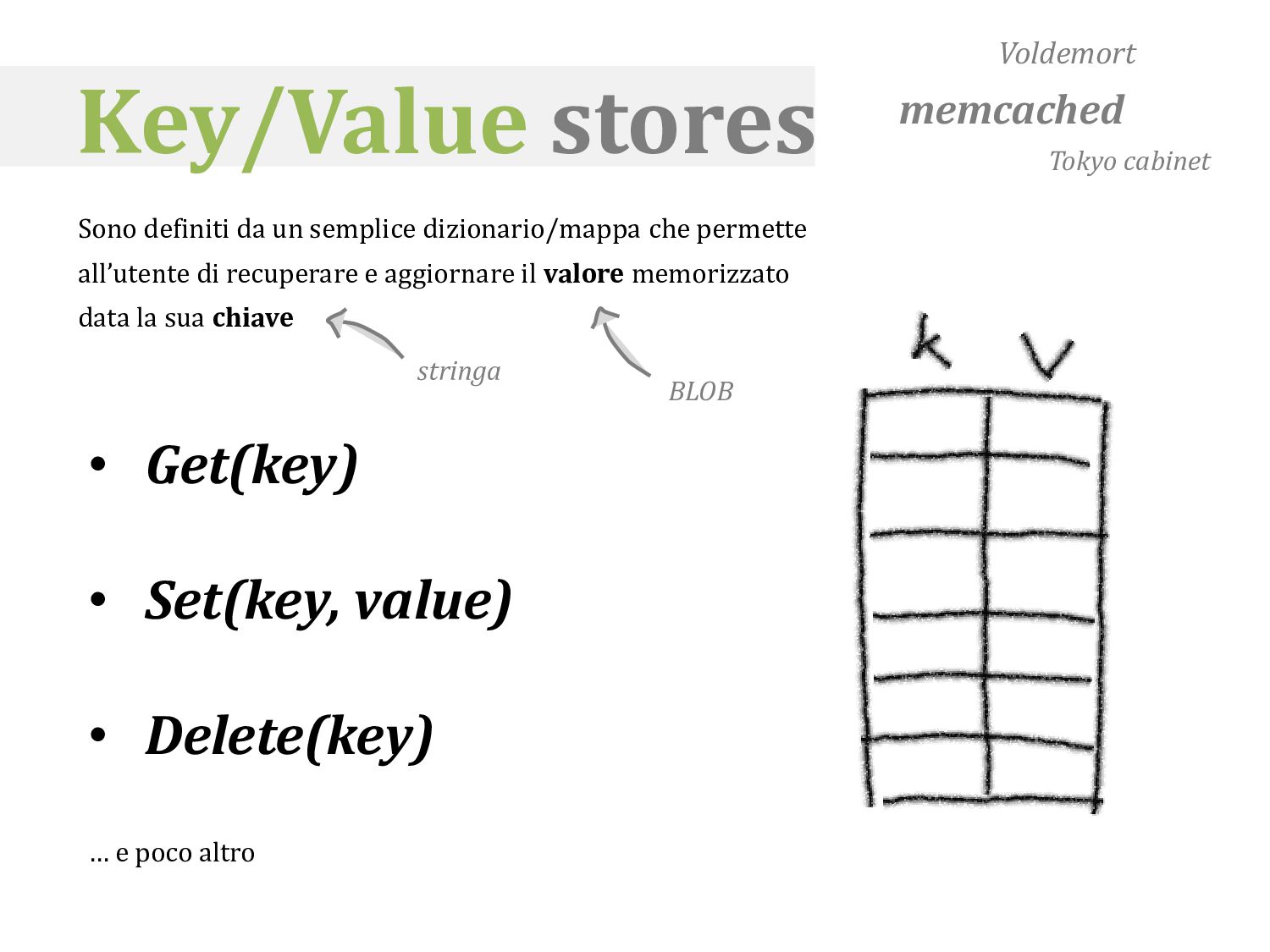
semplice dizionario/mappa che permette all’utente di recuperare e aggiornare il valore memorizzato data la sua chiave • Get(key) • Set(key, value) • Delete(key) … e poco altro BLOB stringa
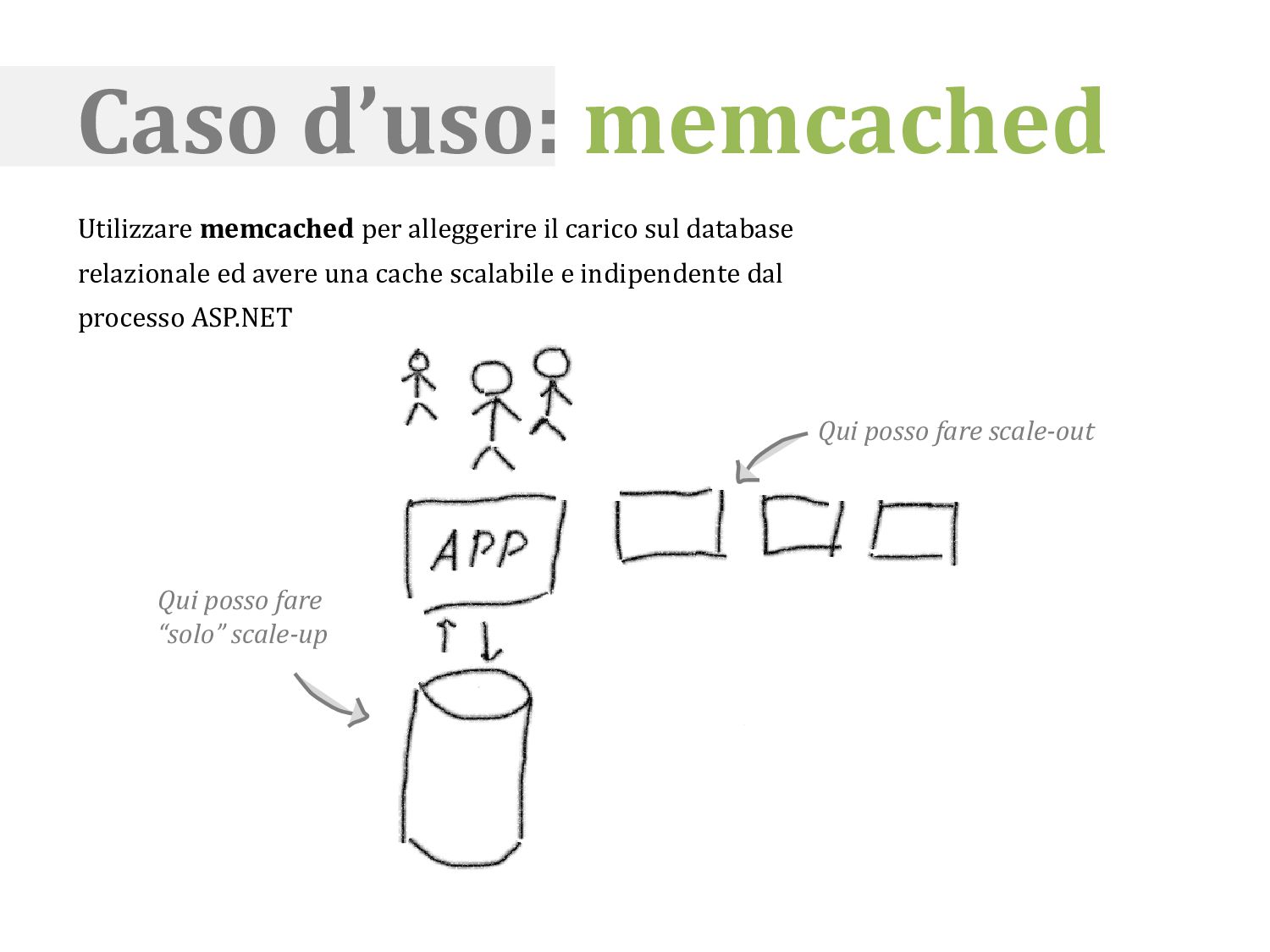
database relazionale ed avere una cache scalabile e indipendente dal processo ASP.NET 1 2 Con l’aiuto di memcached posso fare scale-out anche con i dati, ma in memoria Se non trovo il valore lo recupero dal database (2) Qui posso fare scale-out Qui posso fare “solo” scale-up Facebook's fork of memcached can do ~200k QPS
documenti. Un documento può contenere informazioni annidate ed ha un formato riconosciuto (JSON, XML, etc.) che permette poi al server di eseguire delle query sui dati. A differenza delle tabelle di un relazionale però è schema-free nel senso che non deve sottostare ad uno schema ben preciso. Posso avere documenti di una stessa tipologia con campi diversi e posso aggiungere nuovi campi senza compromettere i documenti esistenti. MongoDB
una fitta rete di connessioni e la modellano sotto forma di nodi e rami di un grafo. Ai nodi come ai singoli rami vengono associate le informazioni attraverso Key-Value store. Se togliamo le relazioni (i rami) assomigliano a tutti gli effetti ad un database documentale. Per le query che soddisfano il modello gerarchico i tempi di esecuzione possono essere 1.000 volte più veloci rispetto agli altri database. Sones Allegro Graph recommends
riga bensì per colonna. L’ovvietà dell’affermazione si può spiegare meglio con un esempio: Amazon SimpleDB Hadoop / HBase 1,Smith,Joe,40000; 2,Jones,Mary,50000; 3,Johnson,Cathy,44000; 1,2,3; Smith,Jones,Johnson; Joe,Mary,Cathy; 40000,50000,44000; Row-oriented Column-oriented
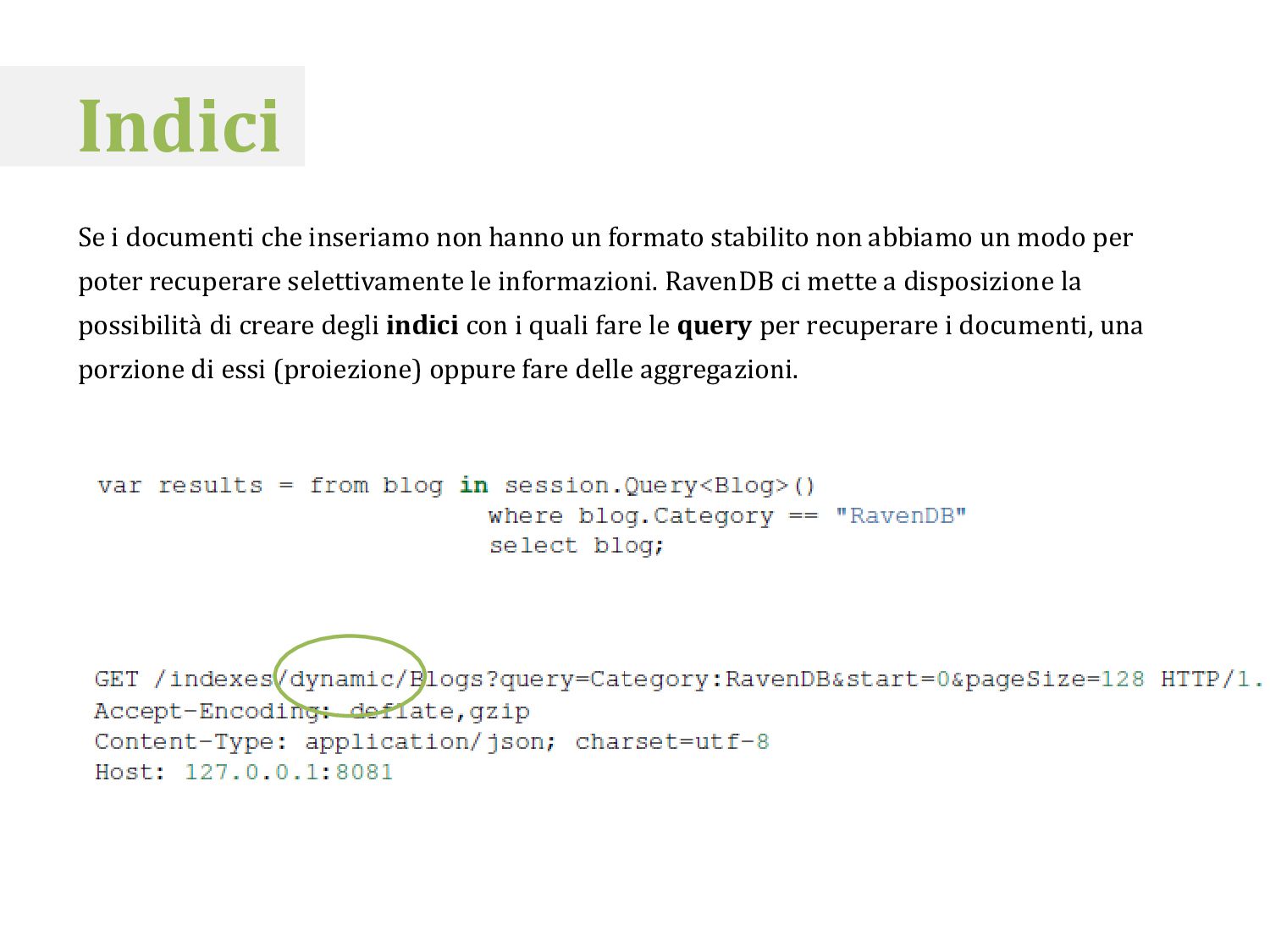
stabilito non abbiamo un modo per poter recuperare selettivamente le informazioni. RavenDB ci mette a disposizione la possibilità di creare degli indici con i quali fare le query per recuperare i documenti, una porzione di essi (proiezione) oppure fare delle aggregazioni.
per quella interrogazione RavenDB ne crea uno temporaneo. Se lo chiamo più volte diventa persistente. Premessa: tutte le query devono usare un indice E’ la funzione usata da RavenDB per estrarre le informazioni da memorizzare insieme all’indice. in Lucene.NET Quando chiamo la query le informazioni precedentemente memorizzate mi vengono ritornate come risultato.
non viene fatta nello stesso momento della query, ma viene fatta in un thread in background che parte quando viene aggiunto un nuovo dato oppure ne viene modificato uno esistente. Questo comportamento ha due immediate conseguenze: • Le query sono molto veloci • Le query possono ritornare dati non aggiornati (staleness) Posso sempre verificare se il risultato della query ha tornato dati non aggiornati: oppure posso specificare alla query quanto può attendere (oppure fino a quando attendere):
applicato ad un elevato numero di dati distribuiti. La sua applicazione è giustificata dal fatto che abbiamo la necessità di eseguire un group by in più step ognuno dei quali da eseguire su macchine differenti. Ci consente di fare delle aggregazioni
documentali, si sposa perfettamente con la metodologia del Domain Driven Design in quanto assume che l’informazione minima da salvare, ovvero il documento, rappresenti un aggregato. L’aggregato è una unità logica indipendente che contiene tutte le informazioni necessarie per definire un contesto applicativo. Ad esempio il singolo post con l’autore, i commenti, le categorie e i tag. ORM No Impedance Mismatch!
ma mi stai forse dicendo che lo stesso autore devo salvarlo in ogni documento che contiene un suo post? Esatto! Nell’aggregato devo mettere solo una versione denormalizzata che contenga per quanto possibile solo le informazioni strettamente necessarie che verranno modificate raramente. Ma così ho una forte duplicazione dei dati, e se poi mi servirà fare un update?
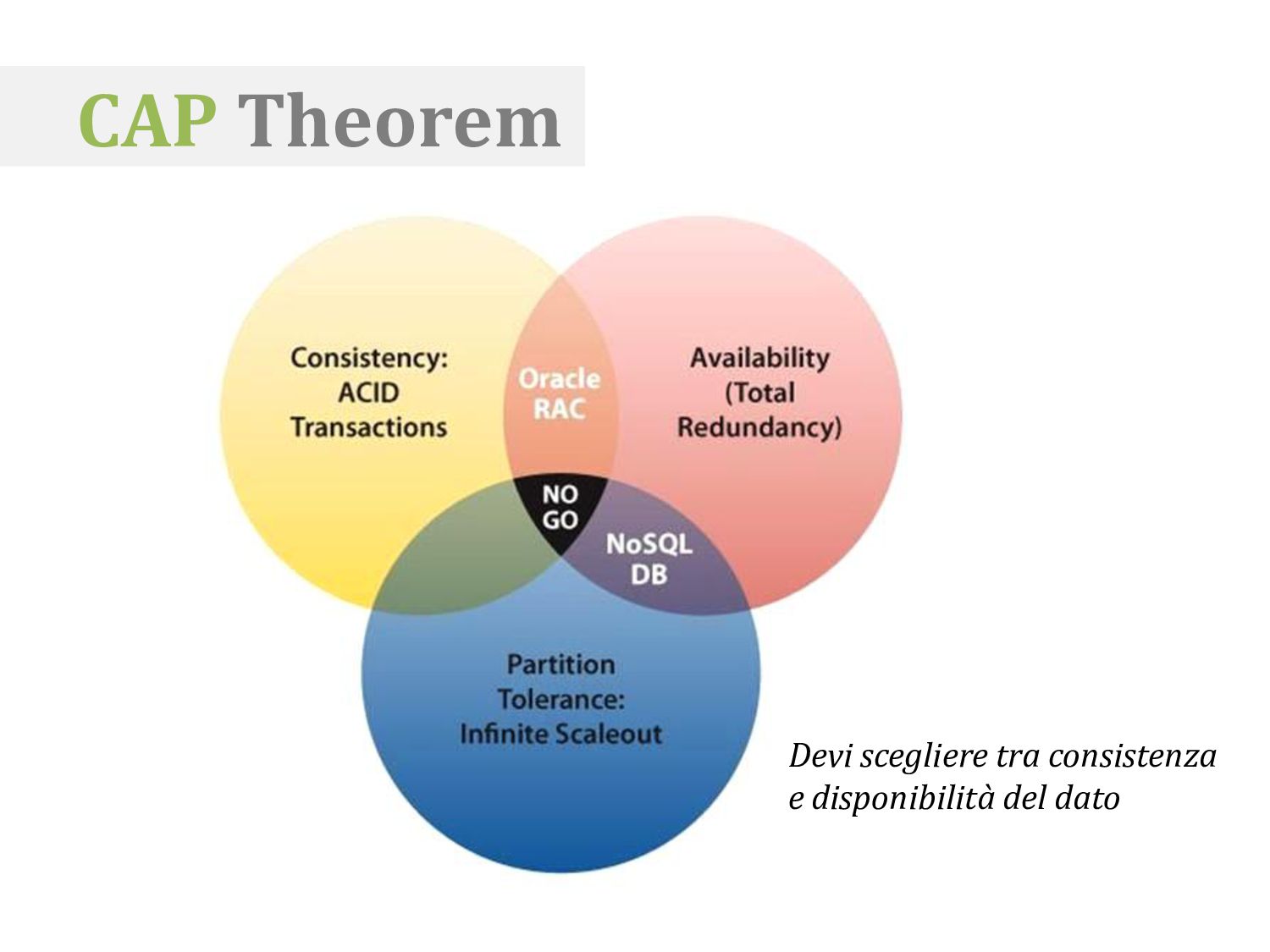
garantendo transazionalità a scapito delle performance e della scalabilità orizzontale Favorisco la replicazione per aumentare la scalabilità orizzontale e la disponibilità del dato a scapito della consistenza Atomicity, Consistency, Isolation, Durability Basic Available, Soft-state, Eventual consistency
da: • Tipo di dati da memorizzare • Richieste in termini di scalabilità • Natura del tipo di interrogazioni che devo fare sui dati • Esigenze o vincoli in termini di consistenza
al trattamento dei dati SQL e NOSQL possono convivere occupandosi di aspetti diversi ed essere sfruttati al massimo per quelle che sono le loro caratteristiche e peculiarità (polyglot persistance) Alcuni prodotti NOSQL non sono ancora maturi per giustificarne un impiego a livello enterprise In alcune circostanze è meglio approfondire gli strumenti in possesso perché potrebbe risiedere nella scarsa conoscenza di essi il collo di bottiglia che stiamo cercando di superare
- Christof Strauch NoSQL Data Modeling Techniques Availability & Consistency Scalable SQL and NoSQL Data Stores - Rick Cattell Highly Connected Data Models in NOSQL Stores Introduzione e concetti base Casi d’uso ed esempi What the heck are you actually using NoSQL for? 35+ Use Cases for Choosing Your Next NoSQL Database What Should I Do? Choosing SQL, NoSQL or Both for Scalable Web Applications Social networks in the database: using a graph database Stack Overflow Architecture NOSQL Overview, Neo4j Intro And Production Example (QCon London 2010)
Aker Humor SQL vs NOSQL NoSQL vs. RDBMS: Let the flames begin! Fighting The NoSQL Mindset, Though This Isn't an anti-NoSQL Piece RavenDB RavenDB overview MVC – Get RavenDB up and running in 5 minutes using Ninject RavenDB Documentation Using RavenDB and ASP.NET MVC 4 to create a Twitter Clone Chirpy Document Databases Compared: CouchDB, MongoDB, RavenDB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You MANUEL SCAPOLAN website: www.manuelscapolan.it twitter: manuelscapolan e-mail: [email protected]](https://files.speakerdeck.com/presentations/61612a75f4b343fc8930c625c372a3c0/slide_37.jpg){kind=link}