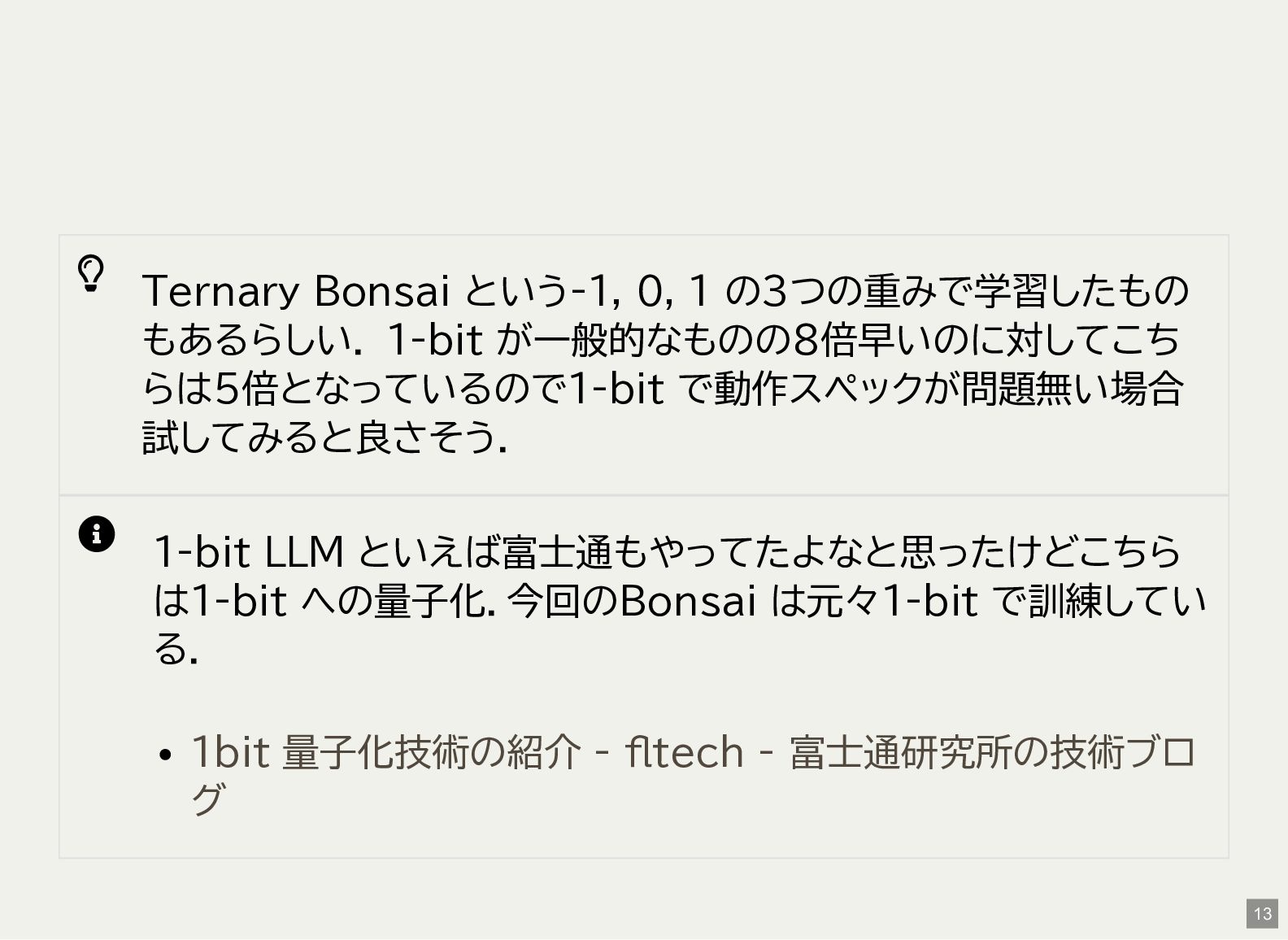
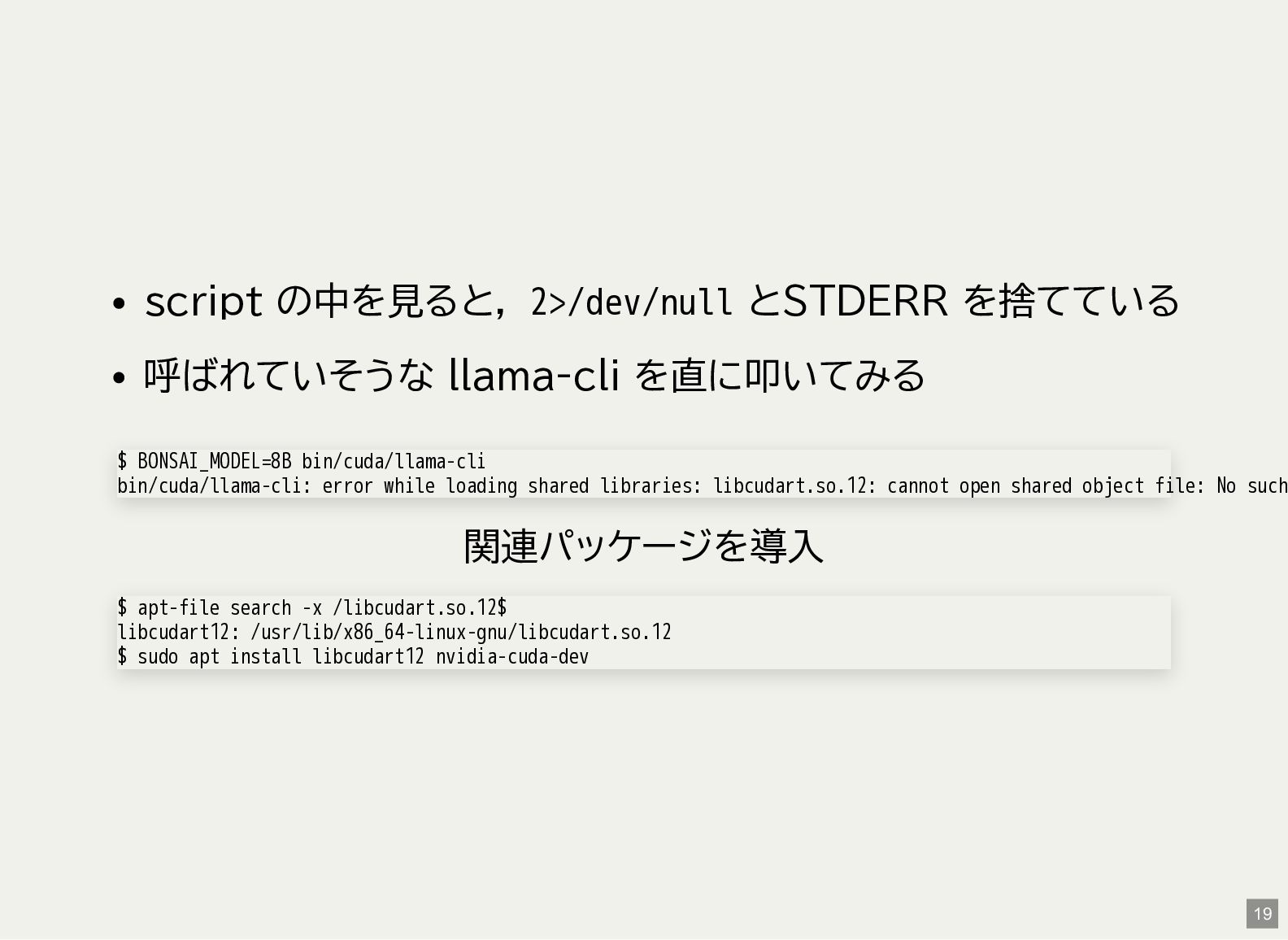
-c 4096 としてみても変わらず $ BONSAI_MODEL=8B ./scripts/run_llama.sh -p "What is the capital of France?" [OK] Model: models/gguf/8B/Bonsai-8B.gguf [OK] Binary: /home/matoken/src/Bonsai-demo/bin/cuda/llama-cli [OK] Using -c 0 (auto-fit to available memory) [WARN] Auto-fit not supported, falling back to -c 8192 1 2 18
> What is the capital of France? The capital of France is **Paris**. It is also the largest city in France and the country's political, economic, a [ Prompt: 0.0 t/s | Generation: 0.0 t/s ] 20
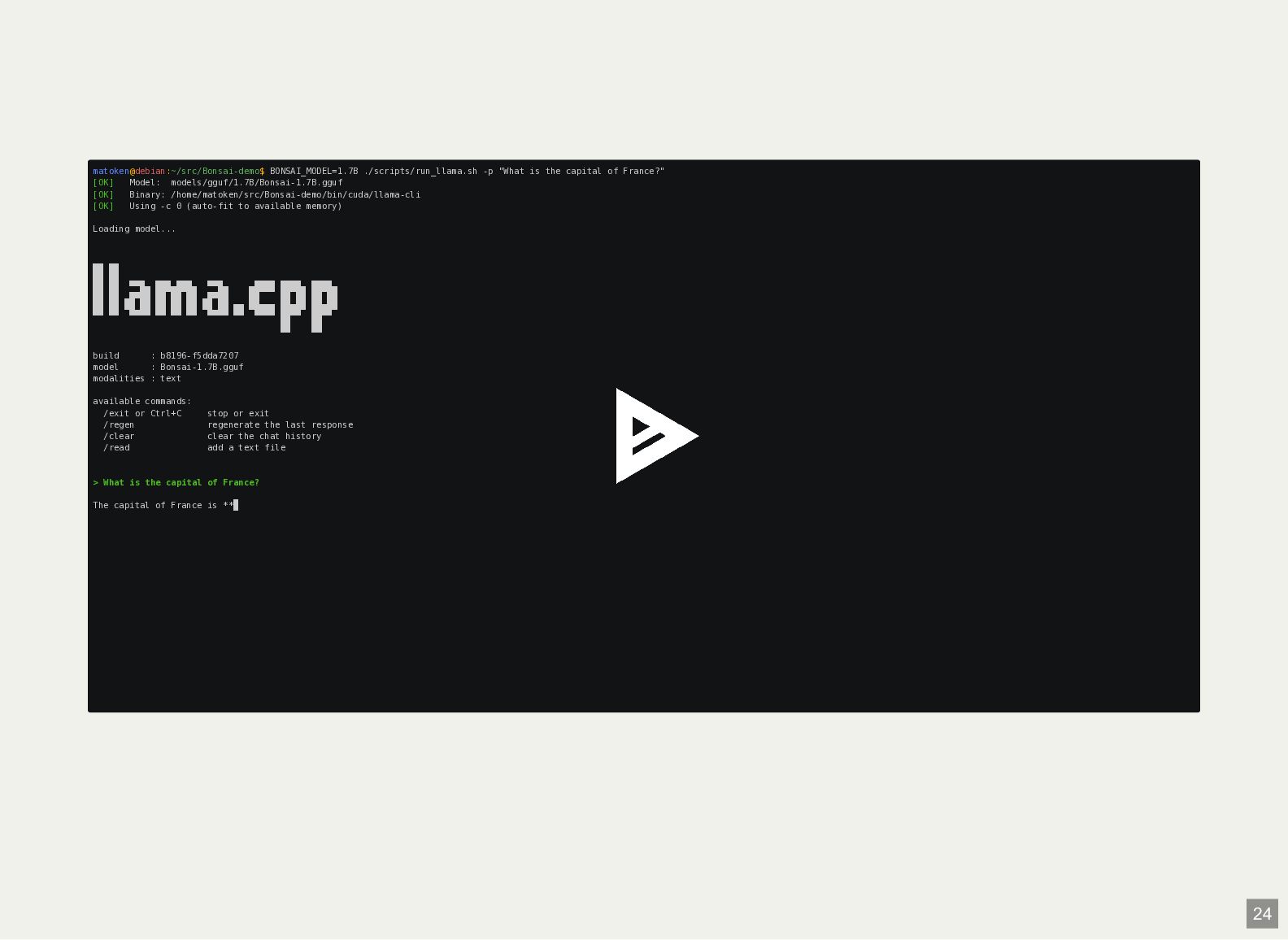
is the capital of France?" [OK] Model: models/gguf/1.7B/Bonsai-1.7B.gguf [OK] Binary: /home/matoken/src/Bonsai-demo/bin/cuda/llama-cli [OK] Using -c 0 (auto-fit to available memory) Loading model... build : b8196-f5dda7207 model : Bonsai-1.7B.gguf modalities : text available commands: /exit or Ctrl+C stop or exit /regen regenerate the last response /clear clear the chat history /read add a text file > What is the capital of France? The capital of France is ** 24
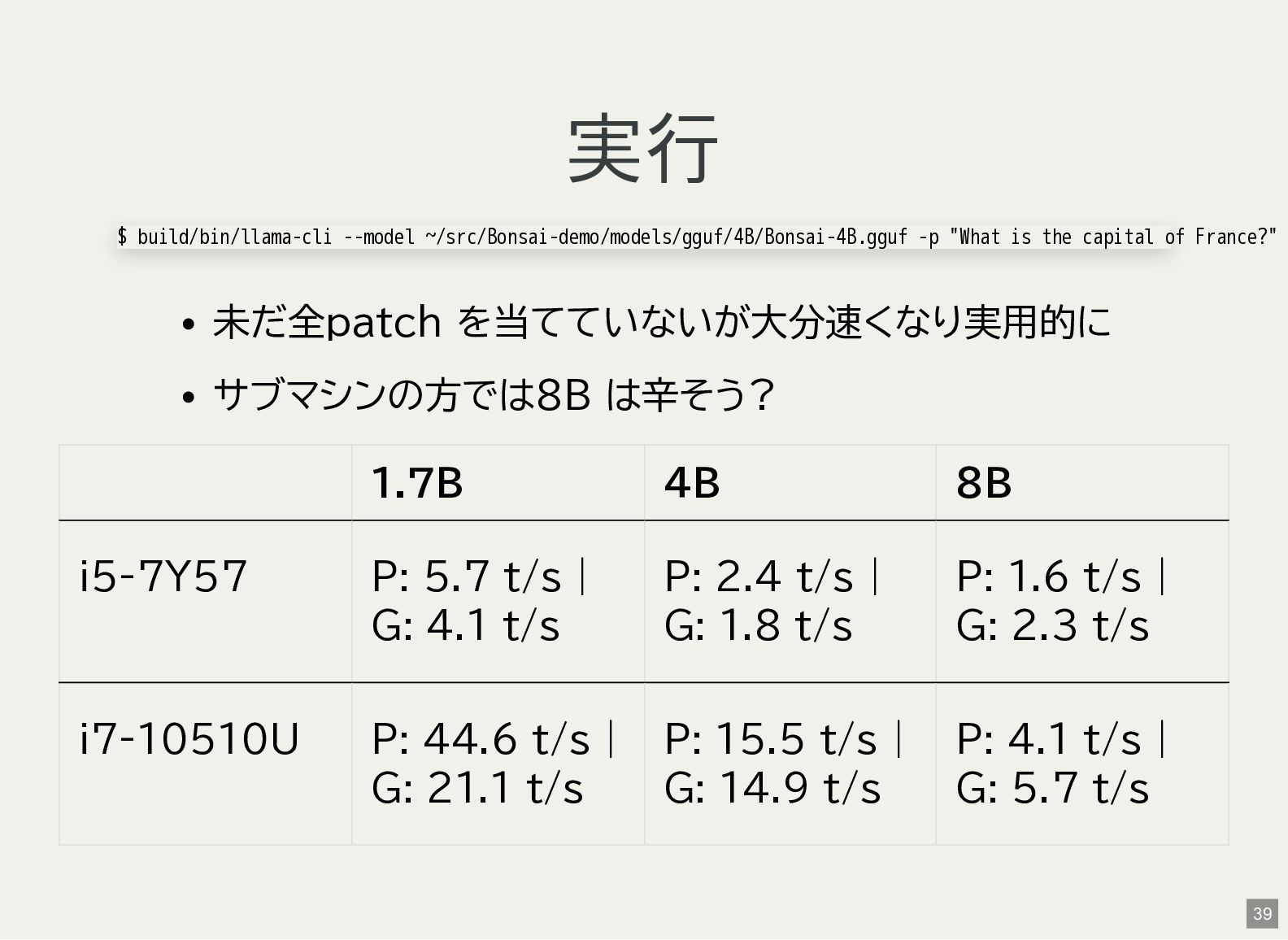
は無いので良くて50倍くらい?それでも大分使いやすくな りそう And on cpu the x86 version is not optimized so expected to be slow, with AVX should be 50-100x faster see this PR: https://github.com/PrismML- Eng/llama.cpp/pulls $ grep -m1 -o 'avx[^ ]*' /proc/cpuinfo avx avx2 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
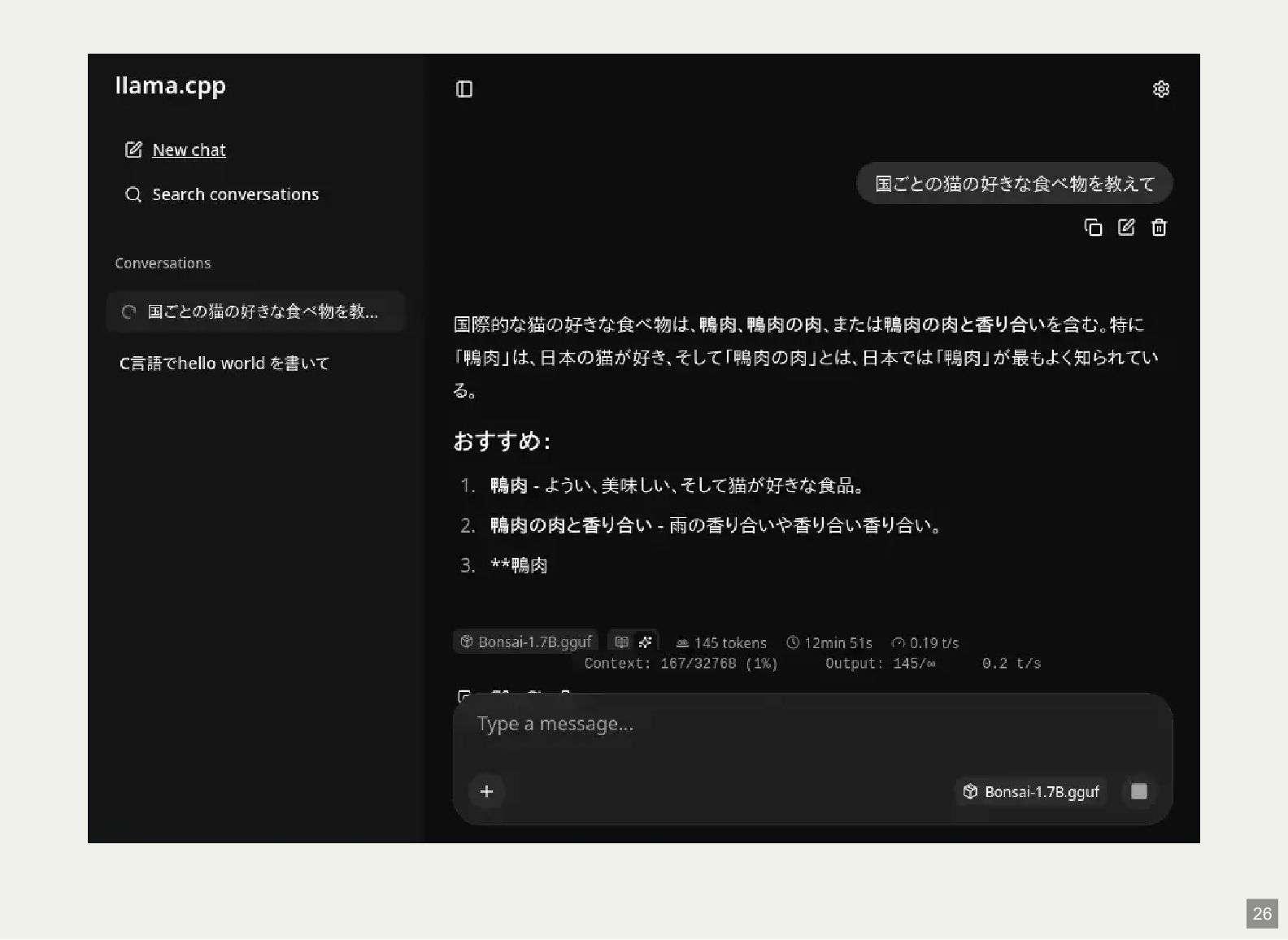{kind=link}
{kind=link}
{kind=link}
{kind=link}
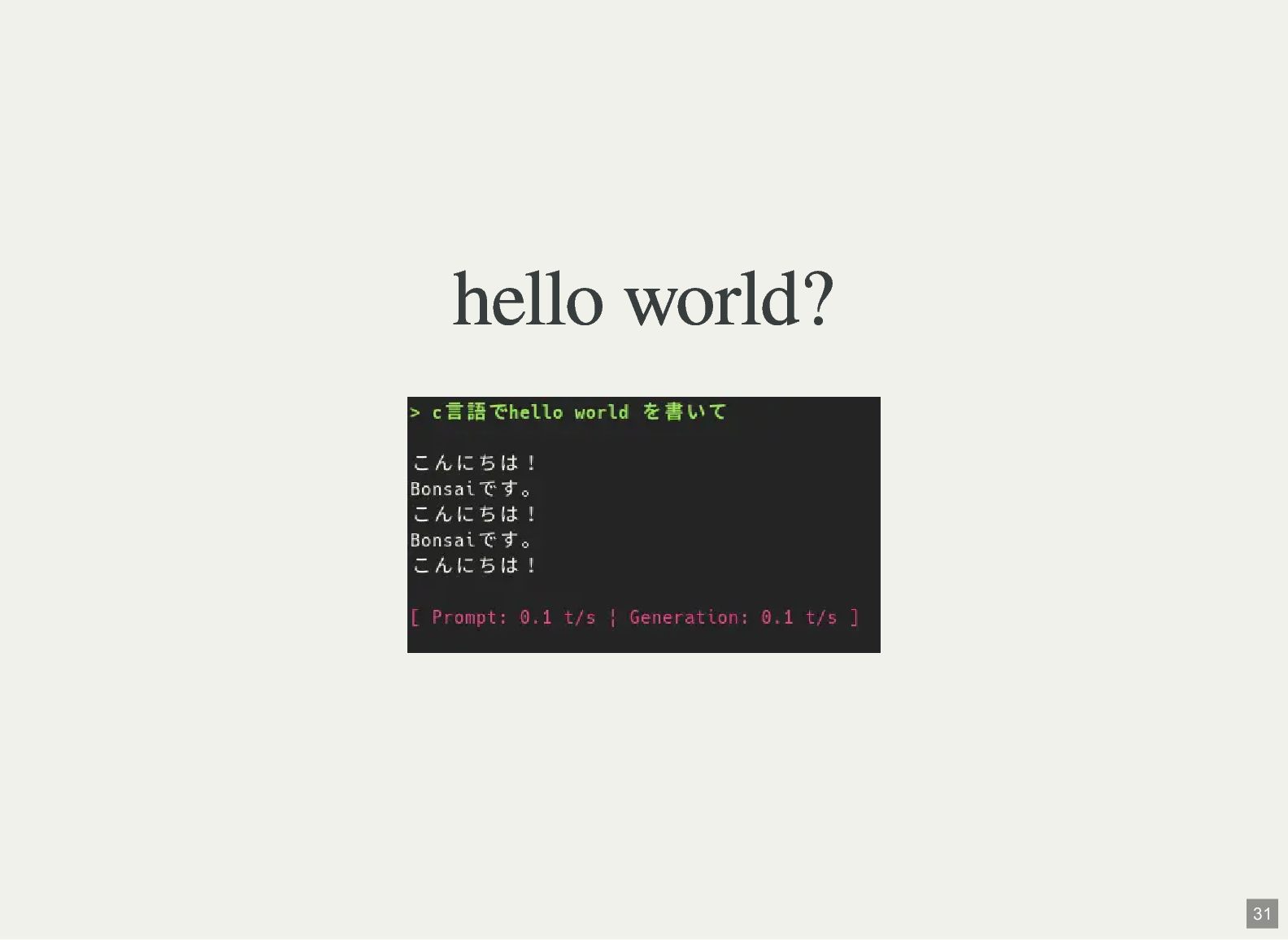{kind=link}
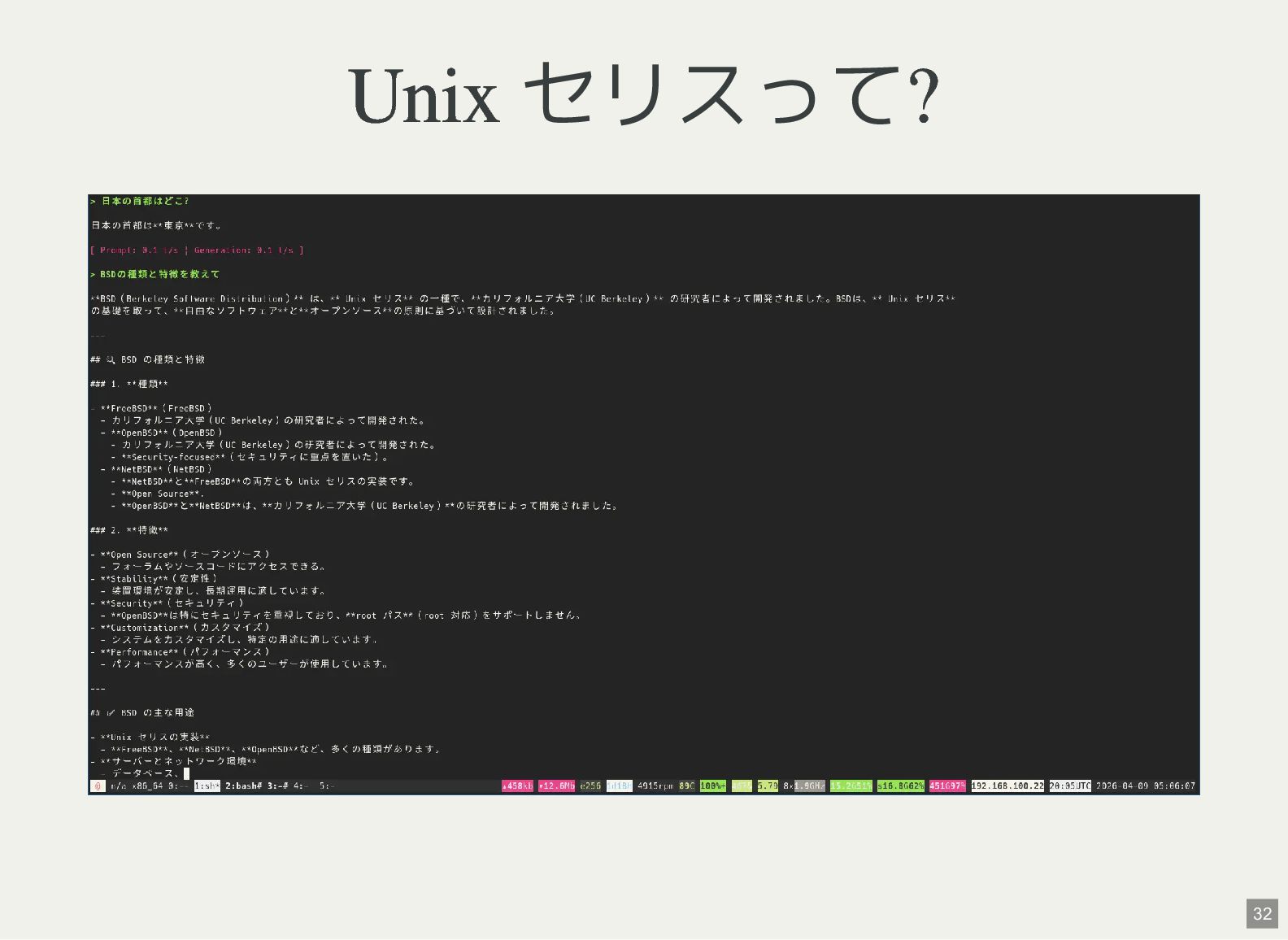{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}