wc -l 162 $ apt-cache search tesseract | grep ^tesseract-ocr- | grep -E "Japanese|English" tesseract-ocr-eng - tesseract-ocr language files for English tesseract-ocr-enm - tesseract-ocr language files for English, Middle (1100-1500) tesseract-ocr-jpn - tesseract-ocr language files for Japanese tesseract-ocr-jpn-vert - tesseract-ocr language files for Japanese (vertical) tesseract-ocr-script-jpan - tesseract-ocr data for Japanese script tesseract-ocr-script-jpan-vert - tesseract-ocr data for Japanese (vertical) script $ sudo apt install tesseract-ocr tesseract-ocr-eng tesseract-ocr-enm tesseract-ocr-jpn \ tesseract-ocr-jpn-vert tesseract-ocr-script-jpan tesseract-ocr-script-jpan-vert \ gimagereader 5 / 15
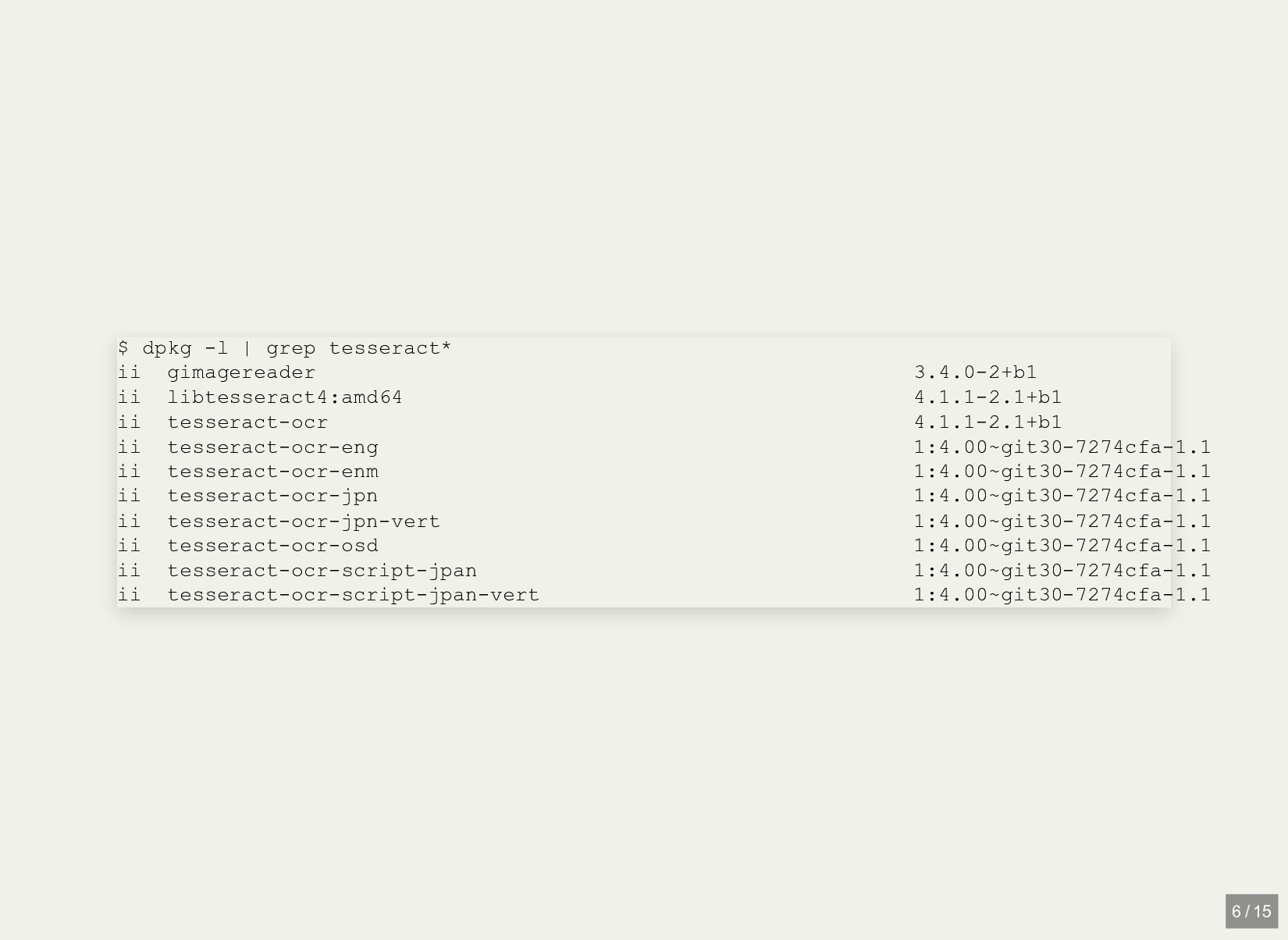
libtesseract4:amd64 4.1.1-2.1+b1 ii tesseract-ocr 4.1.1-2.1+b1 ii tesseract-ocr-eng 1:4.00~git30-7274cfa-1.1 ii tesseract-ocr-enm 1:4.00~git30-7274cfa-1.1 ii tesseract-ocr-jpn 1:4.00~git30-7274cfa-1.1 ii tesseract-ocr-jpn-vert 1:4.00~git30-7274cfa-1.1 ii tesseract-ocr-osd 1:4.00~git30-7274cfa-1.1 ii tesseract-ocr-script-jpan 1:4.00~git30-7274cfa-1.1 ii tesseract-ocr-script-jpan-vert 1:4.00~git30-7274cfa-1.1 6 / 15
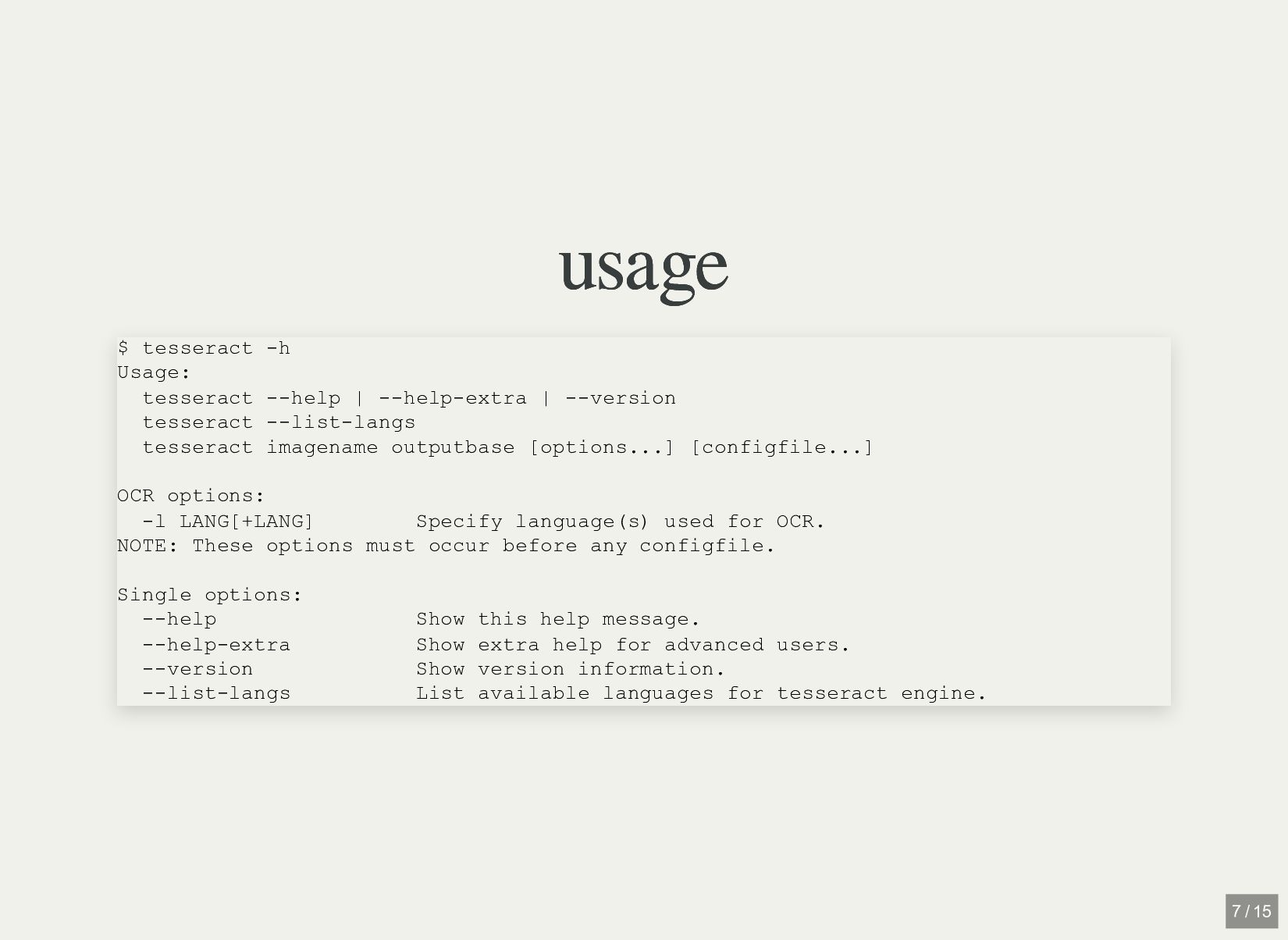
| --version tesseract --list-langs tesseract imagename outputbase [options...] [configfile...] OCR options: -l LANG[+LANG] Specify language(s) used for OCR. NOTE: These options must occur before any configfile. Single options: --help Show this help message. --help-extra Show extra help for advanced users. --version Show version information. --list-langs List available languages for tesseract engine. 7 / 15
![OCRで画像文字を OCRで画像文字を 文字データに 文字データに Kenichiro Matohara(matoken) <[email protected]> 1 / 15](https://files.speakerdeck.com/presentations/66fdf9a4f28e472eb36d121b7edb0aa9/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}