Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
インデックスのパフォーマンス調べてみた
Search
matumoto
October 15, 2022
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
インデックスのパフォーマンス調べてみた
2022/10月に行われた大LTでの発表資料です
イベントページはこちら
https://zli.connpass.com/event/261496/
matumoto
October 15, 2022
More Decks by matumoto
See All by matumoto
Go標準パッケージのI/O処理をながめる
matumoto
0
430
testingを眺める
matumoto
1
210
sync/v2 プロポーザルの 背景と sync.Pool について
matumoto
0
780
Goトランザクション処理
matumoto
1
85
いまいちどスライスの 挙動を見直してみる
matumoto
0
410
Go1.22のリリース予定の機能を見る
matumoto
0
89
GoのUnderlying typeについて
matumoto
0
230
Typed-nilについて
matumoto
0
380
GoのType Setsという概念
matumoto
0
56
Other Decks in Technology
See All in Technology
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
380
CIで使うClaude
iwatatomoya
0
250
Claude Codeとハーネスについて考えてみる
oikon48
18
9.4k
SRE Lounge Hiroshimaへの招待
grimoh
0
640
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
360
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
11
7.1k
DatabricksにおけるMCPソリューション
taka_aki
1
240
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
0
150
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.1k
世界、断片、モデル。そして理解
ardbeg1958
1
110
公式ドキュメントの歩き方etc
coco_se
0
100
Featured
See All Featured
New Earth Scene 8
popppiees
3
2.4k
For a Future-Friendly Web
brad_frost
183
10k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Bash Introduction
62gerente
615
220k
How to Ace a Technical Interview
jacobian
281
24k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Paper Plane (Part 1)
katiecoart
PRO
0
9.6k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Transcript
インデックスの パフォーマンス 調べてみた matumoto
自己紹介 • ハンドルネーム:matumoto • 本名:松本響輝 • 学年:28期 • 趣味:イカᔦꙬᔨ •
やってきた技術: ◦ ゲーム作り ◦ フロントエンド ◦ AtCoder 水💧 • Twitter:@matumoto_1234
インデックスについて
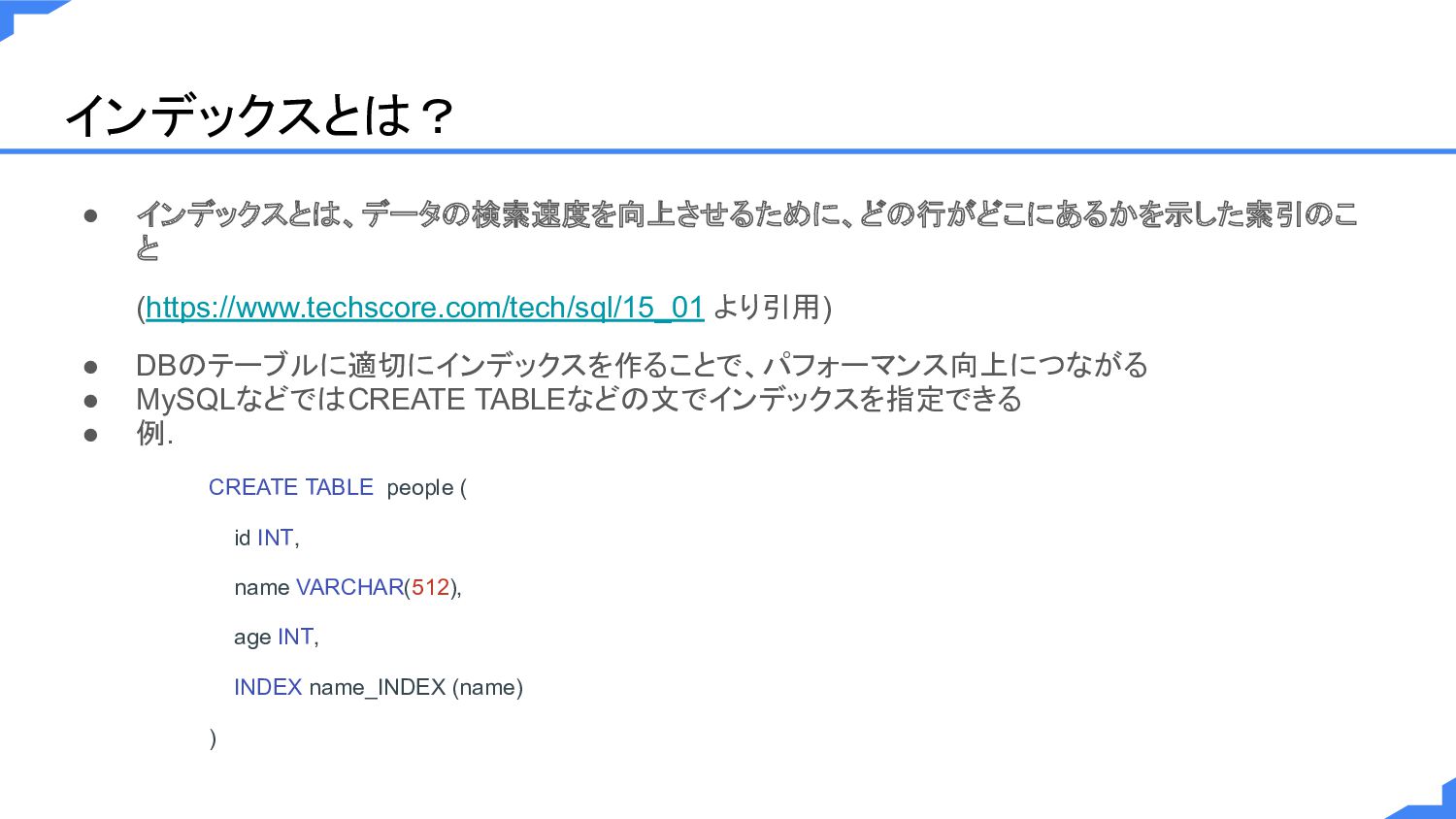
インデックスとは? • インデックスとは、データの検索速度を向上させるために、どの行がどこにあるかを示した索引のこ と (https://www.techscore.com/tech/sql/15_01 より引用) • DBのテーブルに適切にインデックスを作ることで、パフォーマンス向上につながる • MySQLなどではCREATE
TABLEなどの文でインデックスを指定できる • 例. CREATE TABLE people ( id INT, name VARCHAR(512), age INT, INDEX name_INDEX (name) )
インデックスがどう使われるのか? • クエリに対応して、インデックスが自動で使われる • 例. ◦ peopleという名前の、こんなテーブルがあったとする id name age
1 matumoto 20 2 Aizu Taro 256 • SELECT id FROM people WHERE name = 'matumoto' というような、nameカラムに対しての検索クエリが きたとき、name_INDEXが使われる • SELECT idFROM people WHERE age = 20 というような、ageカラムに対しての検索クエリがきたらイン デックスは使われず、テーブル全体がそのまま読み込まれる
インデックスのパフォーマンス • インデックスは基本的に、ユニーク(重複がない)なもののほうがパフォーマンスが良い ◦ 例. PRIMARY KEYに基づくインデックスやUNIQUE制約のついたインデックスなど →なぜパフォーマンスが良いのか?(本題) →後述
インデックスの内部構造
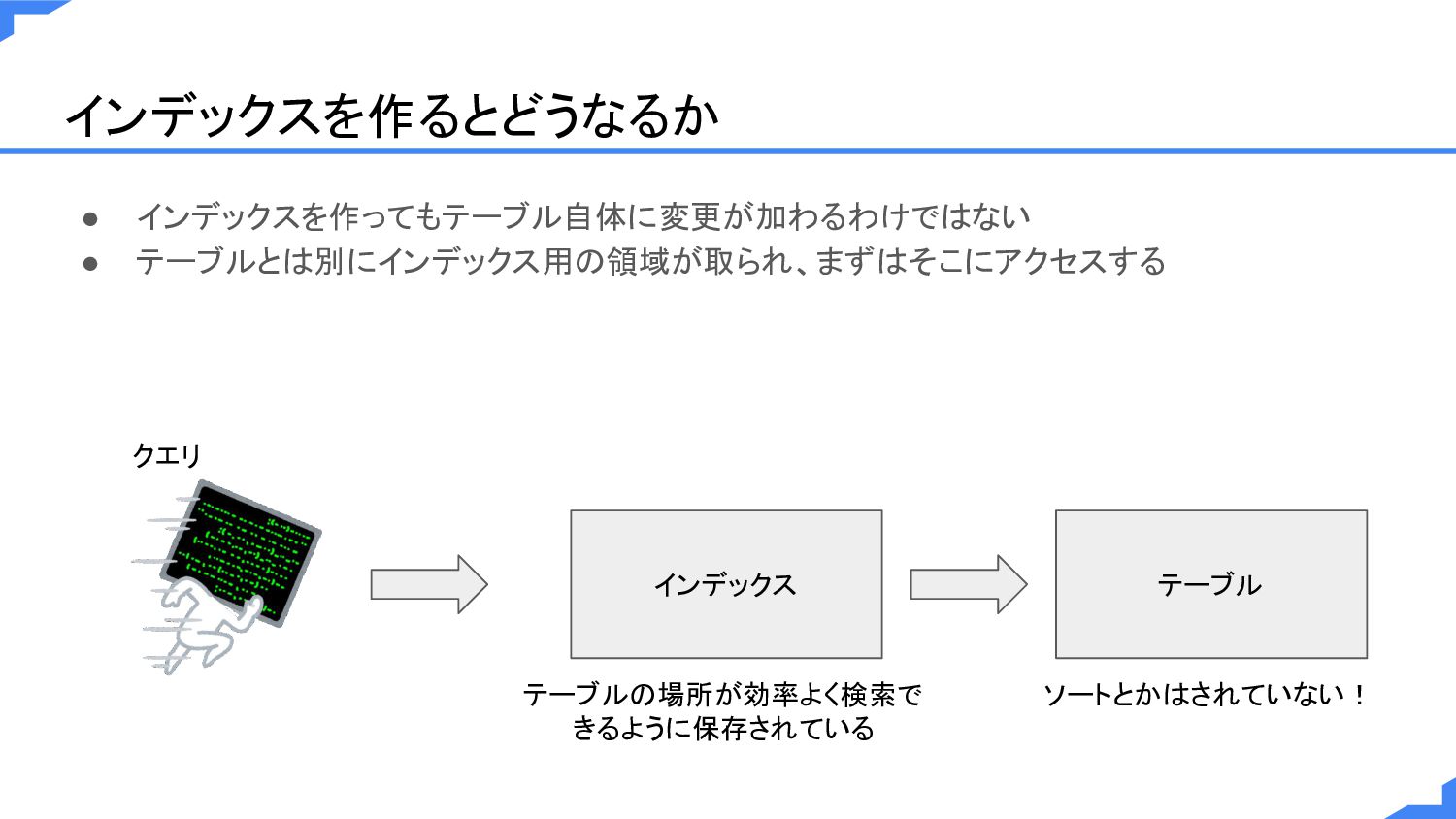
インデックスを作るとどうなるか • インデックスを作ってもテーブル自体に変更が加わるわけではない • テーブルとは別にインデックス用の領域が取られ、まずはそこにアクセスする テーブル インデックス クエリ ソートとかはされていない! テーブルの場所が効率よく検索で
きるように保存されている
インデックスはどうなっているか • B-treeというようなデータ構造がよく使われている ◦ 厳密にはB+treeや、B*treeという改良版が使われることが多い
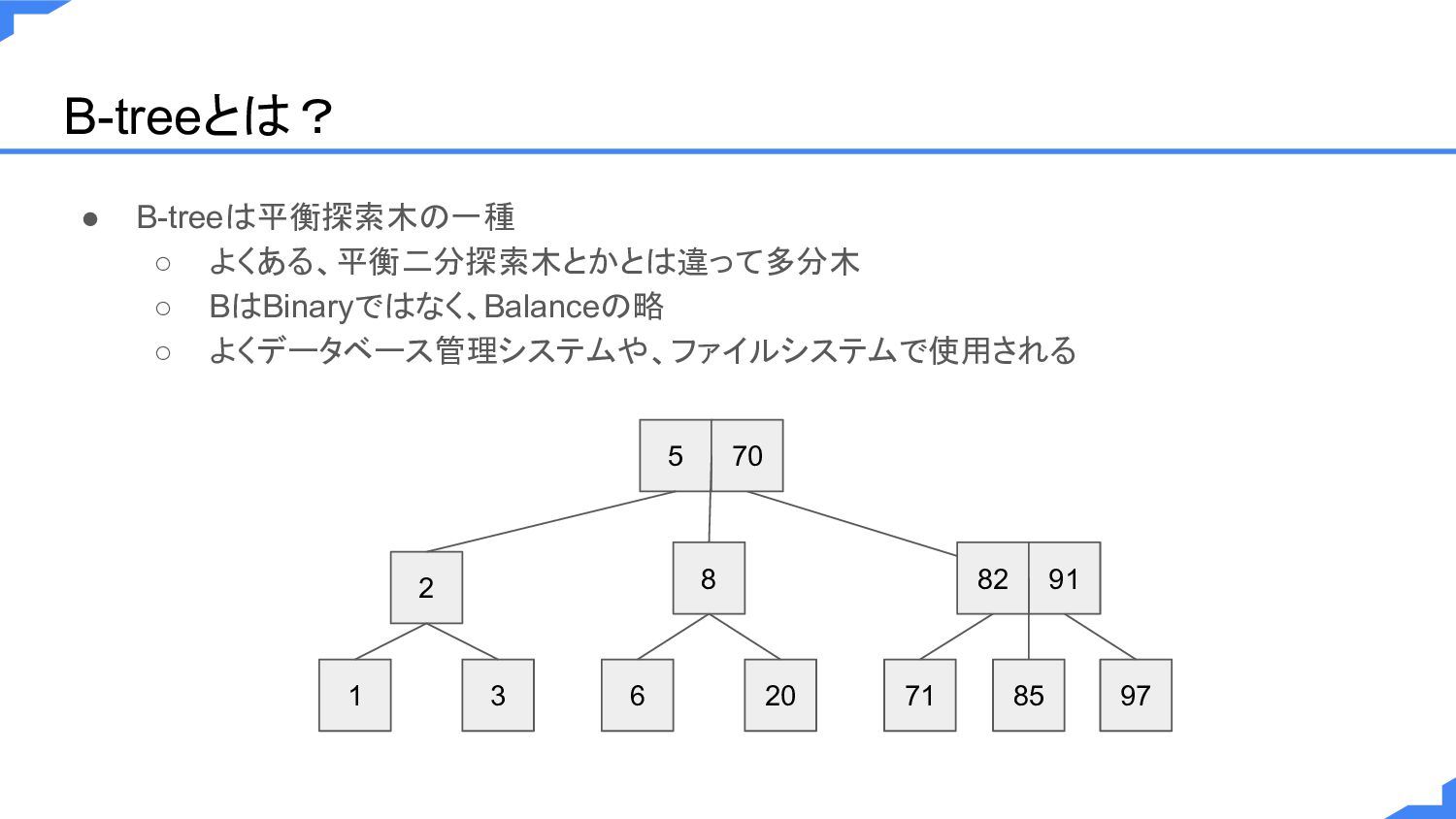
B-treeとは? • B-treeは平衡探索木の一種 ◦ よくある、平衡二分探索木とかとは違って多分木 ◦ BはBinaryではなく、Balanceの略 ◦ よくデータベース管理システムや、ファイルシステムで使用される 5
70 2 1 3 8 6 20 82 91 71 85 97
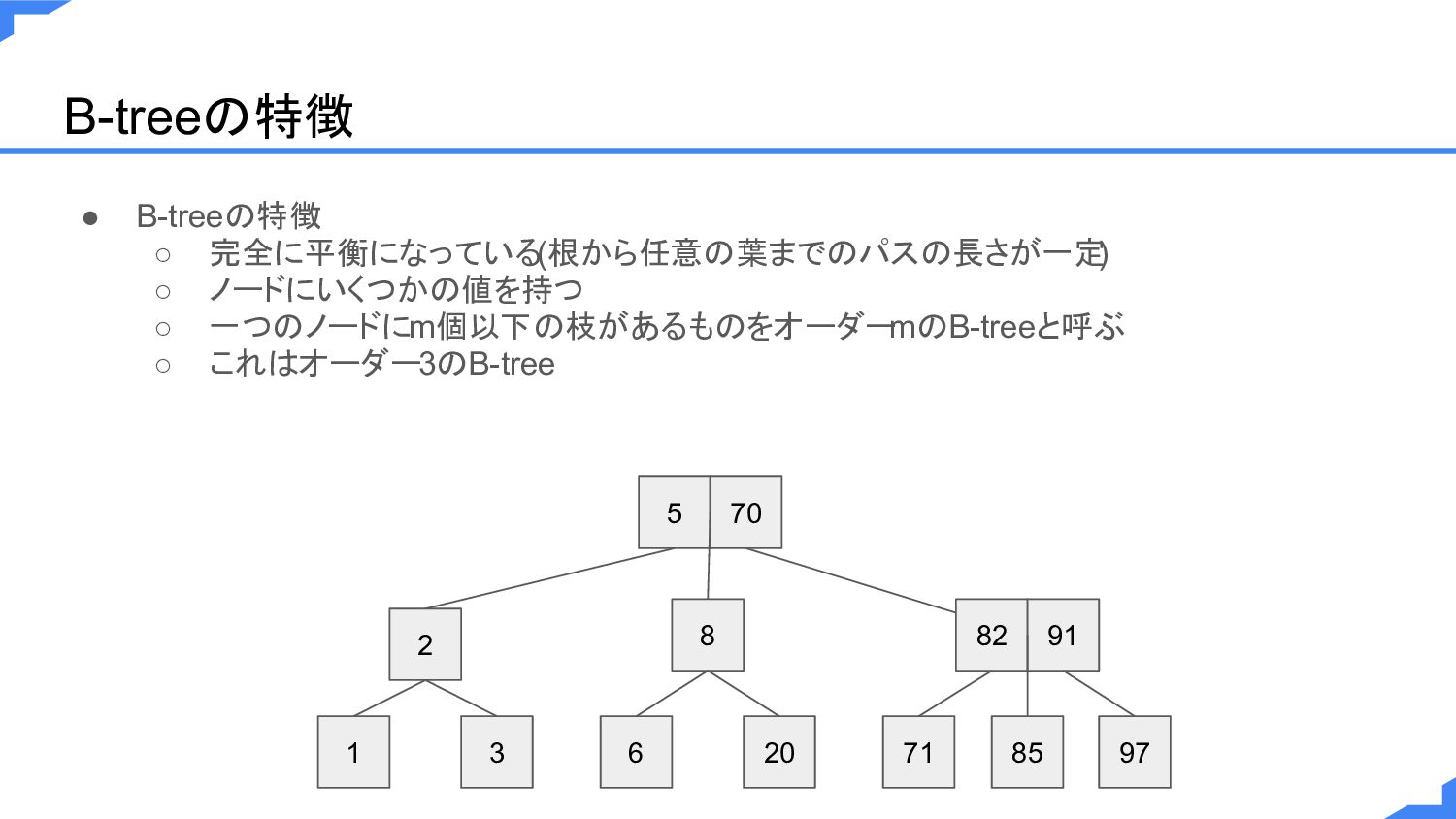
B-treeの特徴 • B-treeの特徴 ◦ 完全に平衡になっている(根から任意の葉までのパスの長さが一定 ) ◦ ノードにいくつかの値を持つ ◦ 一つのノードにm個以下の枝があるものをオーダー
mのB-treeと呼ぶ ◦ これはオーダー3のB-tree 5 70 2 1 3 8 6 20 82 91 71 85 97
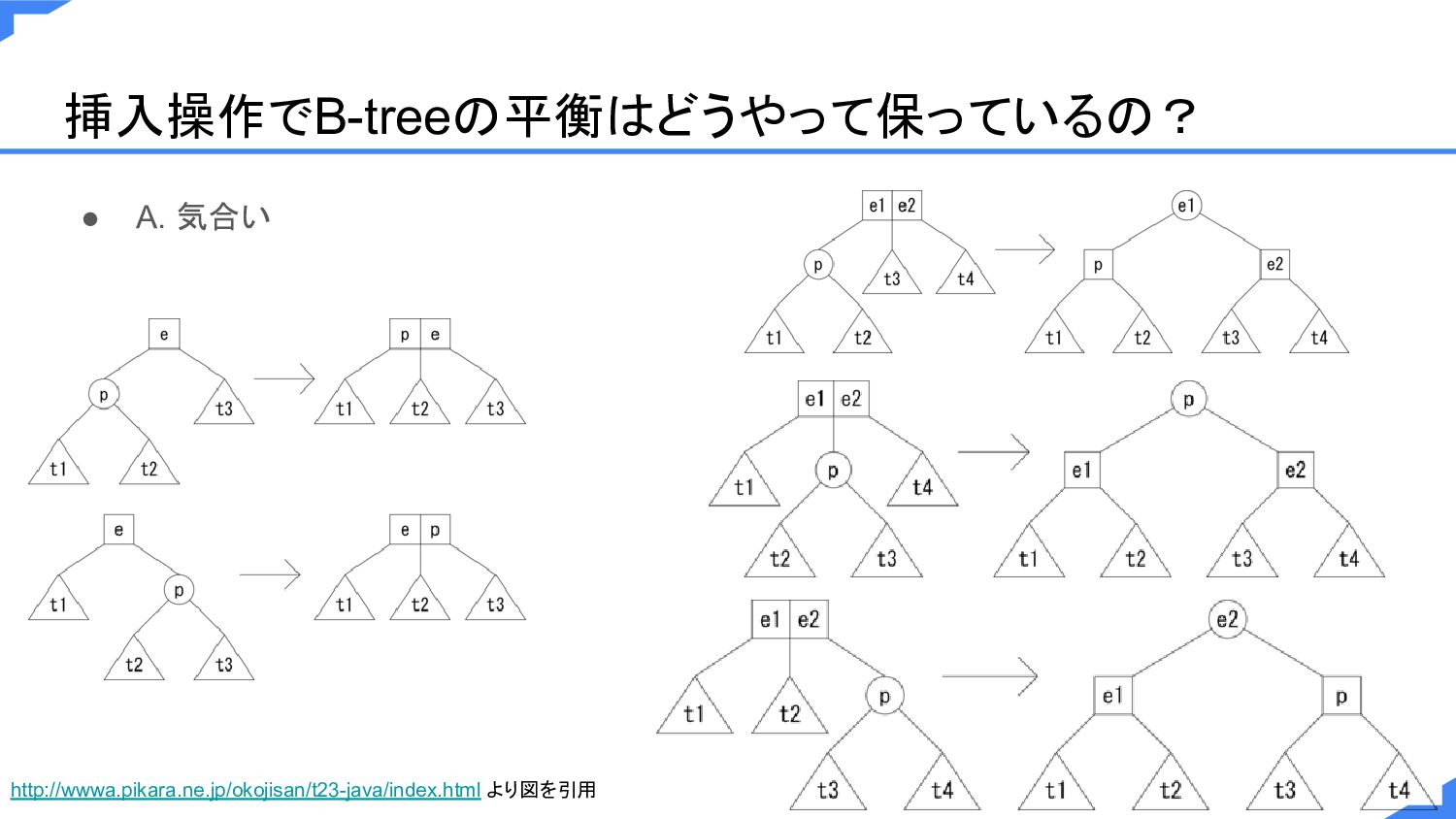
挿入操作でB-treeの平衡はどうやって保っているの? • A. 気合い http://wwwa.pikara.ne.jp/okojisan/t23-java/index.html より図を引用
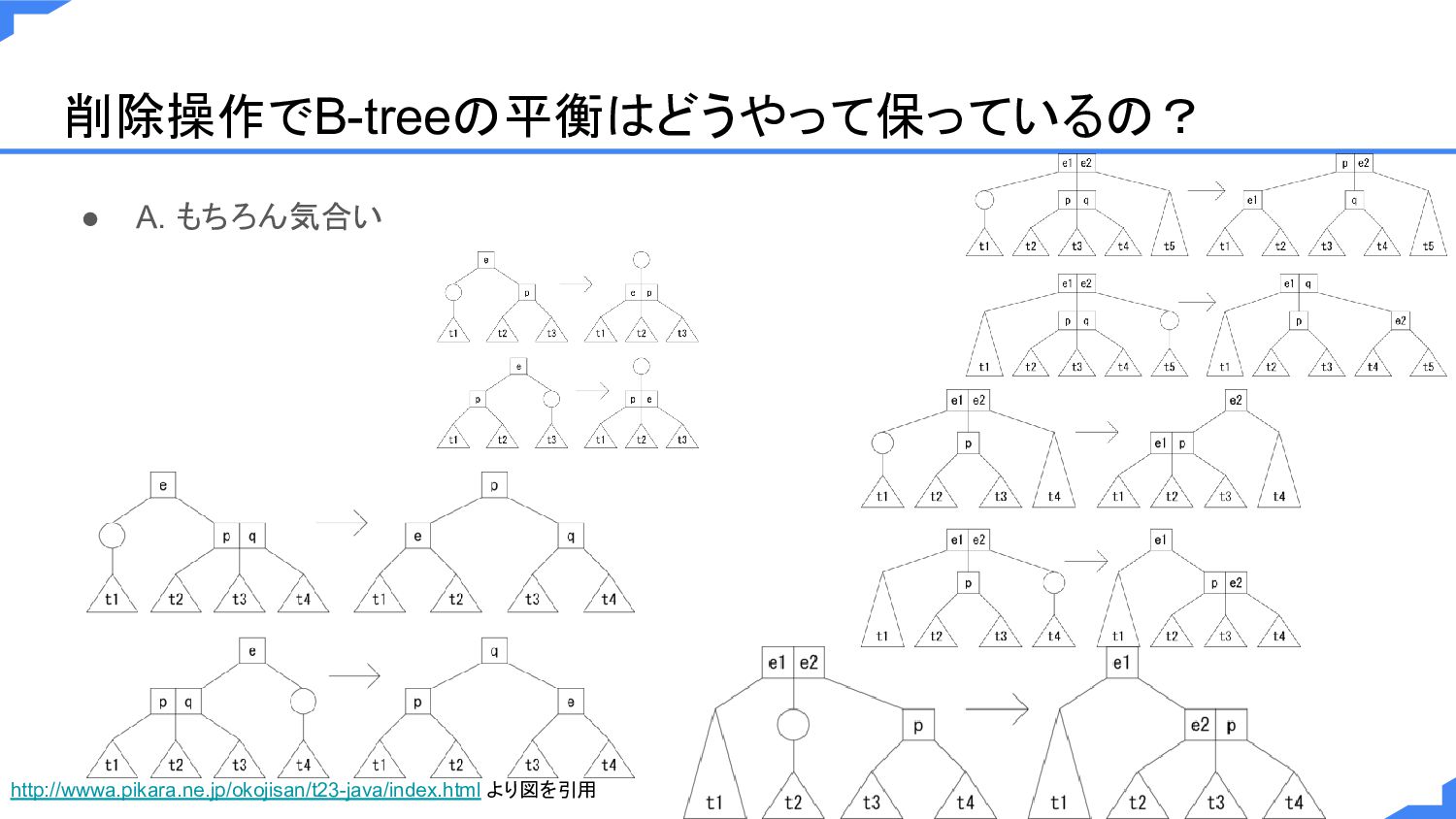
削除操作でB-treeの平衡はどうやって保っているの? • A. もちろん気合い http://wwwa.pikara.ne.jp/okojisan/t23-java/index.html より図を引用
B-treeの計算量 • B-treeの計算量 ◦ nを要素数とする ◦ 挿入:O(log n) ◦ 削除:O(log
n) ◦ 検索:O(log n) • AVL木や、赤黒木といった平衡二分探索木より速い? ◦ そんなことはなくて、遅い ◦ オーダーmのB-treeのノードを辿るときにO(m)回の値比較を行うので遅い ◦ データベース管理システムなどで使われるのは、「枝を辿るコスト」 >「値比較のコスト」な ため
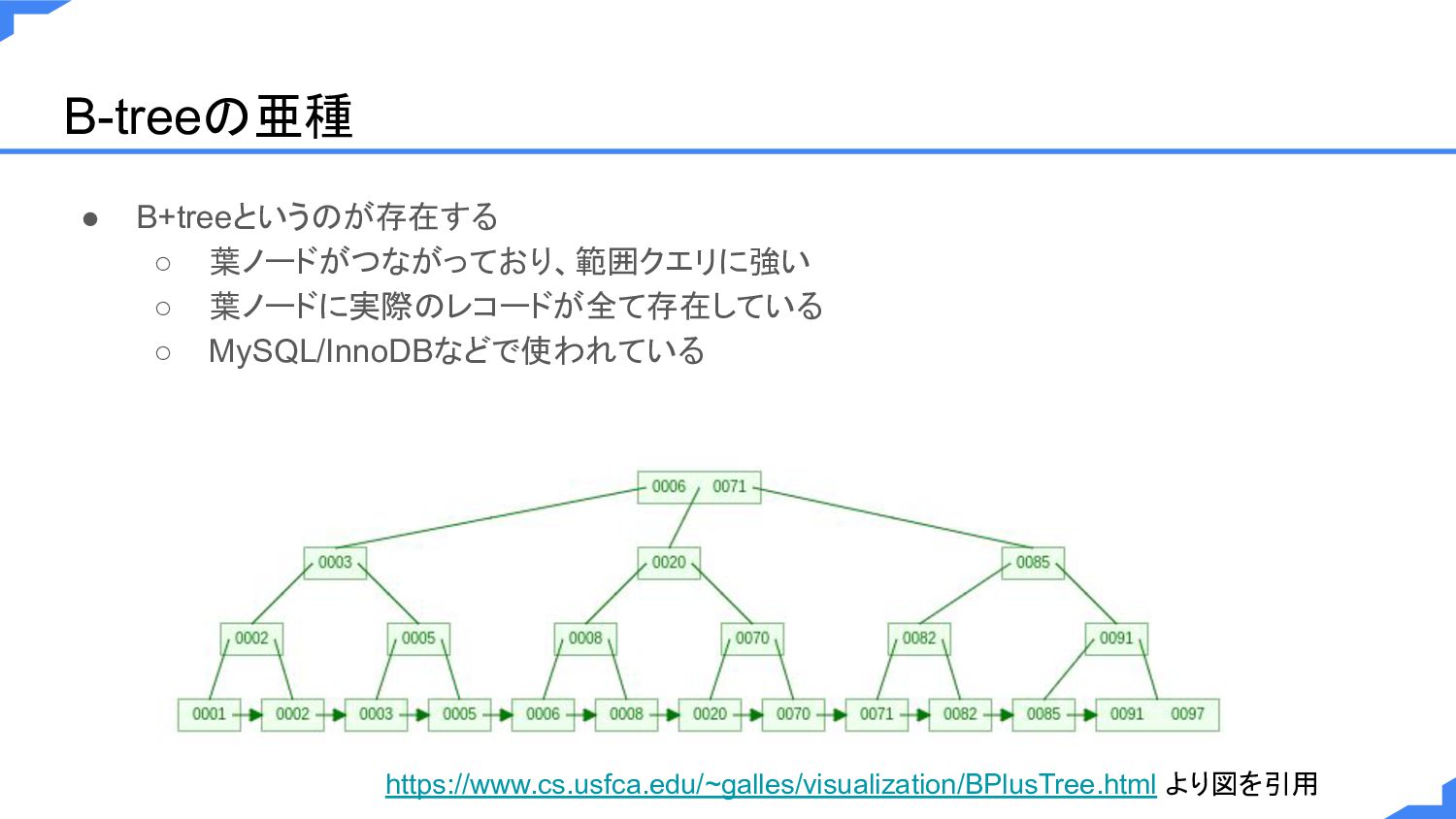
B-treeの亜種 • B+treeというのが存在する ◦ 葉ノードがつながっており、範囲クエリに強い ◦ 葉ノードに実際のレコードが全て存在している ◦ MySQL/InnoDBなどで使われている https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
より図を引用
インデックスの パフォーマンス
インデックスのパフォーマンス • SQLクエリをEXPLAINすると表示される「type」 • 主なものとしては、以下がある ◦ const:PRIMARY KEYのインデックスやUNIQUEインデックスを使う。最速 ◦ eq_ref:JOINのときにPRIMARY
KEYのインデックスやUNIQUEインデックスを使う ◦ ref:ユニークでないインデックスを使ったときの等価検索など ◦ range:インデックスを用いた範囲検索 (0 <= key <= 10を満たすkeyを検索するなど) ◦ index:フルインデックススキャン。インデックス全体を見る ◦ all:フルテーブルスキャン。インデックスが使用されていない • なぜユニークだと早くなる傾向にあるのか?
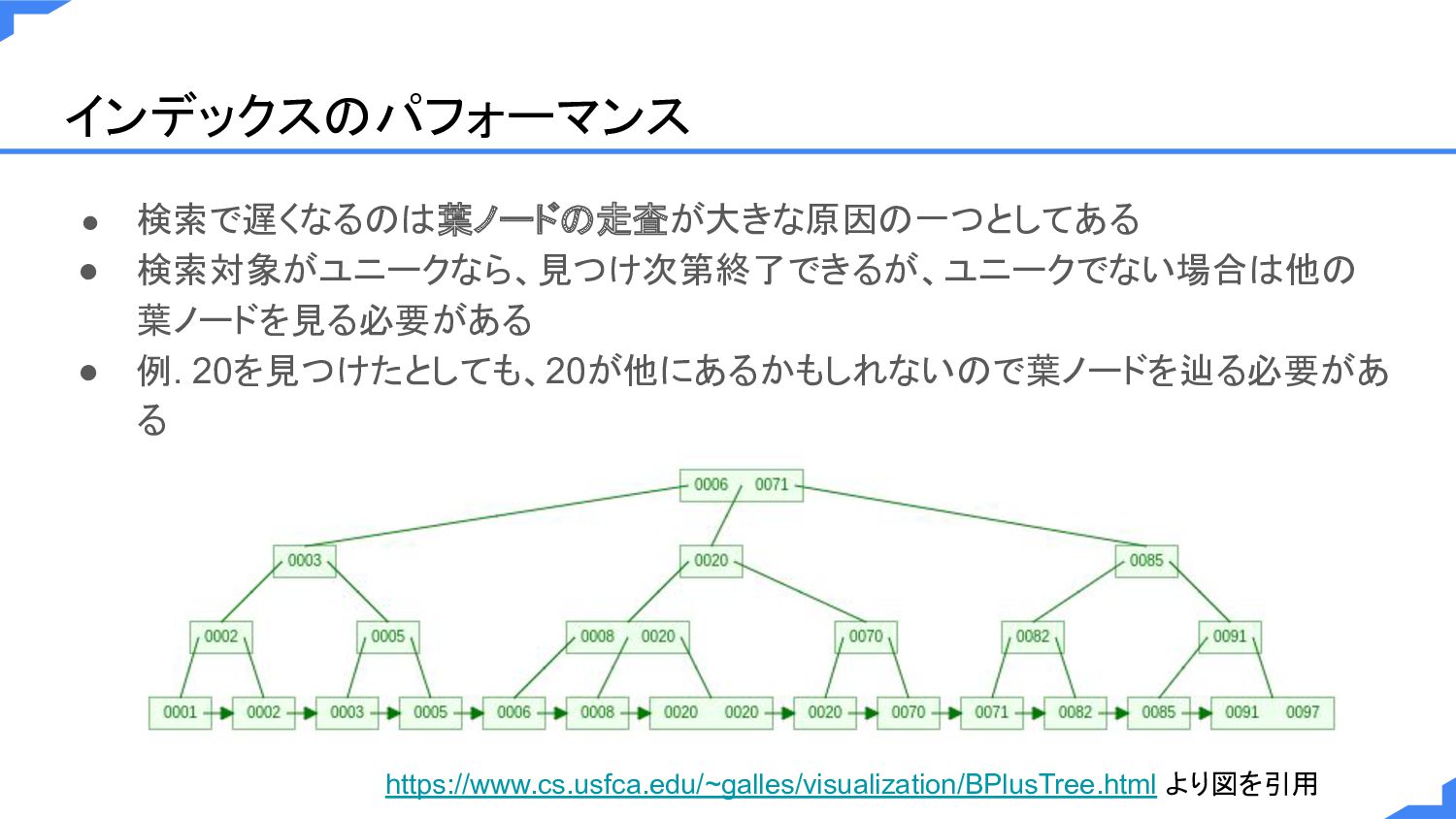
インデックスのパフォーマンス • 検索で遅くなるのは葉ノードの走査が大きな原因の一つとしてある • 検索対象がユニークなら、見つけ次第終了できるが、ユニークでない場合は他の 葉ノードを見る必要がある • 例. 20を見つけたとしても、20が他にあるかもしれないので葉ノードを辿る必要があ る
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html より図を引用
まとめ
まとめ • インデックスの内部構造はB-treeがベースになっていることが多くて、計算量は だ いたい O(log n) ◦ 範囲クエリでk個の要素がみつかるときは、 O(log
n + k) 程度
ご静聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}