(Zipf, 1936) – Predictability in context (Piantadosi, Tily, & Gibson, 2011; Mahowald et al., 2013) Accounts appealing to meaning – Not considered because language thought to be arbitrary (Saussure, 1916)
use, and through transmission, ultimately shape language structure. (Christiansen & Chater, 2008; in press) Language use timescale (minutes) Language change timescale (many years) t
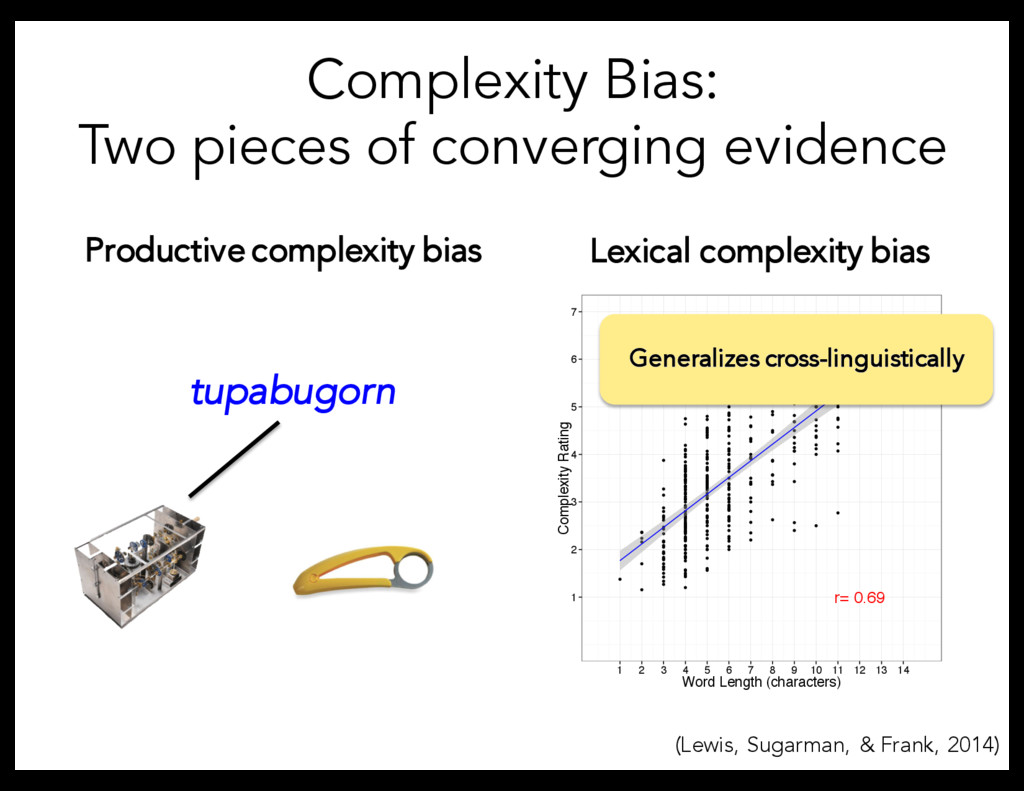
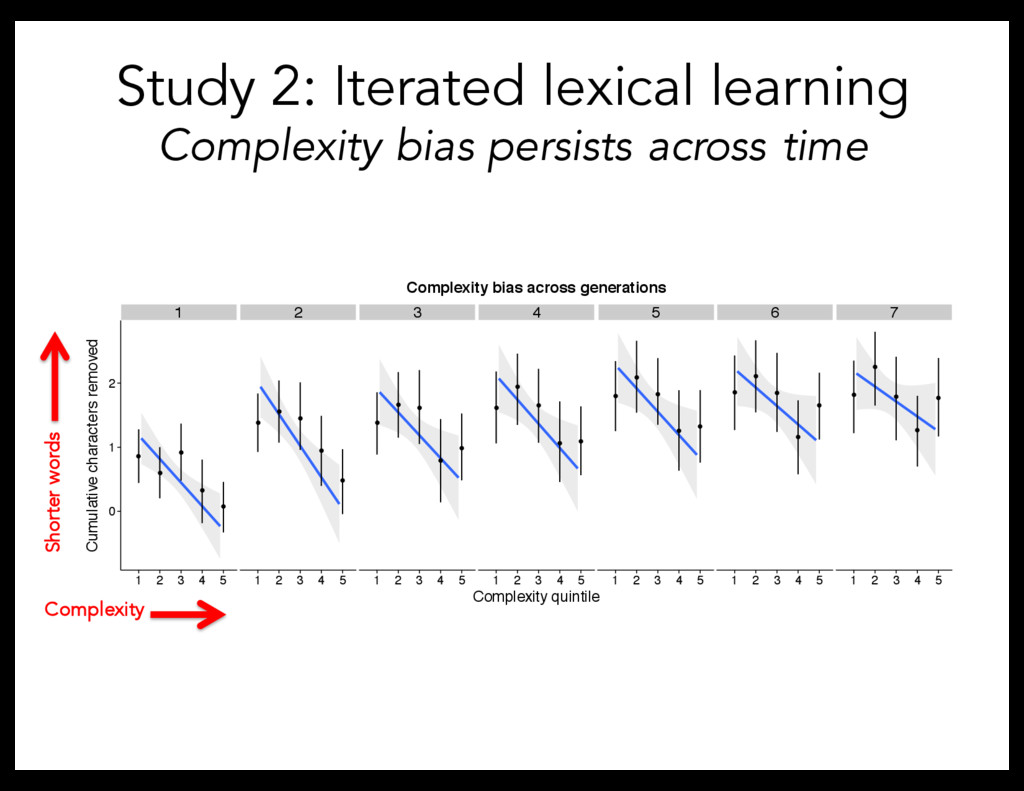
individual speakers over time leads to the same regularity emerging in the structure of the lexicon through memory errors. Productive complexity bias Lexical complexity bias r= 0.69 1 2 3 4 5 6 7 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Word Length (characters) Complexity Rating
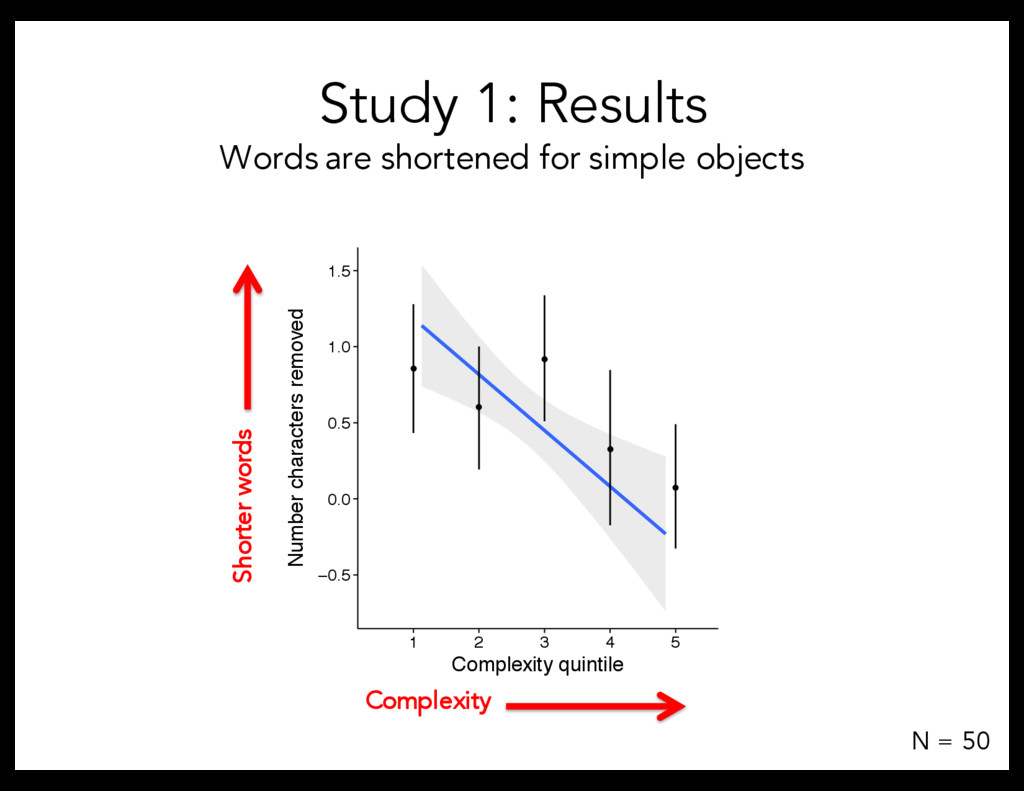
5, 7, 9, 11 characters ([CV]+C syllables) – Objects: 2 from each complexity quintile Complexity bias: Shorten words for simple objects, lengthen words for complex objects ninop nin ninop ninopen
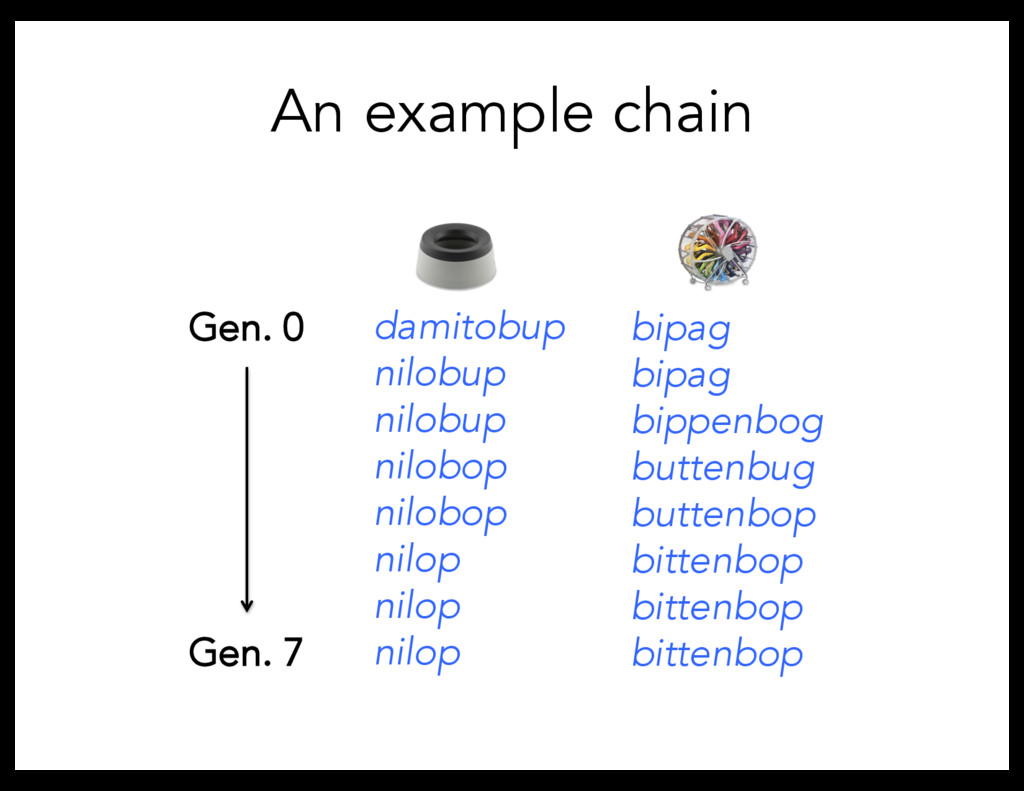
method for simulating language change (e.g., Kirby, Cornish, & Smith, 2008) Gave the labels generated by participants to a new set of participants Iterated for total of 7 generations 50 participants/generation
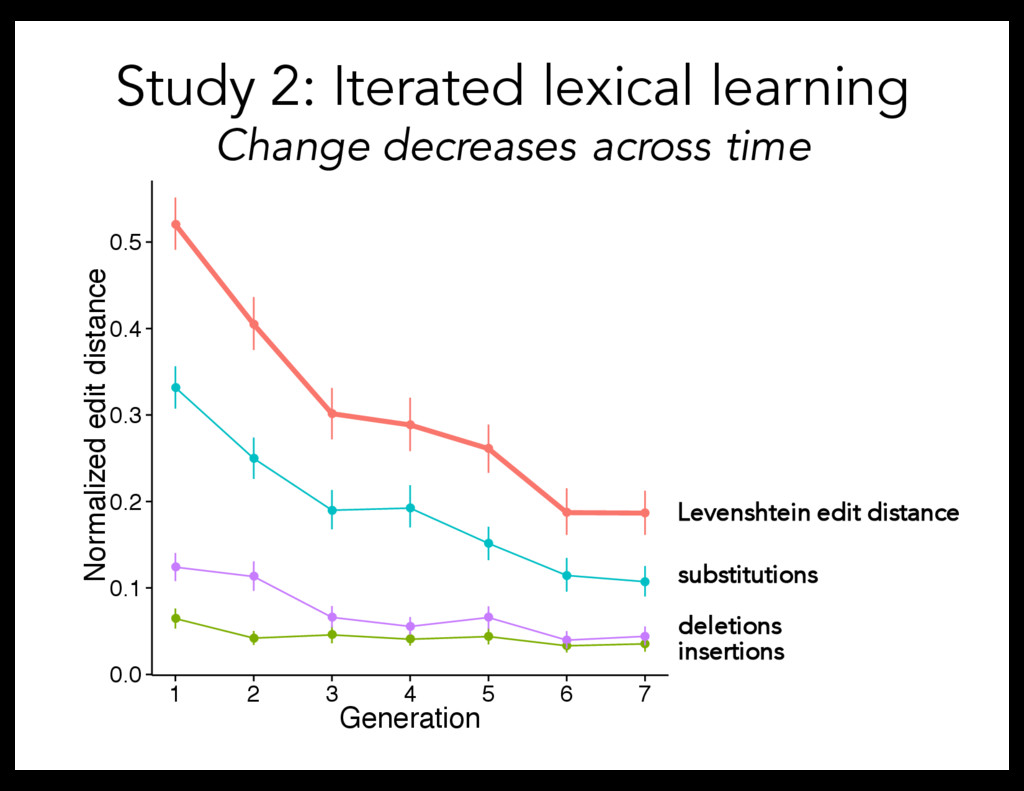
minimum number of character edits necessary to transform one string to another can à cat [1] can à calculator [8] Normalized edit distance: distance between actual vs. guessed word, normalized by length of longest
change system – Chains with greater cross-generational change in lexical forms tend to show an increase in complexity bias over time. – When errors are made, consistent with complexity bias Pressure to simplify suppresses complexity bias – Because task not communicative, insufficient pressure against compression But, why doesn’t it strengthen?
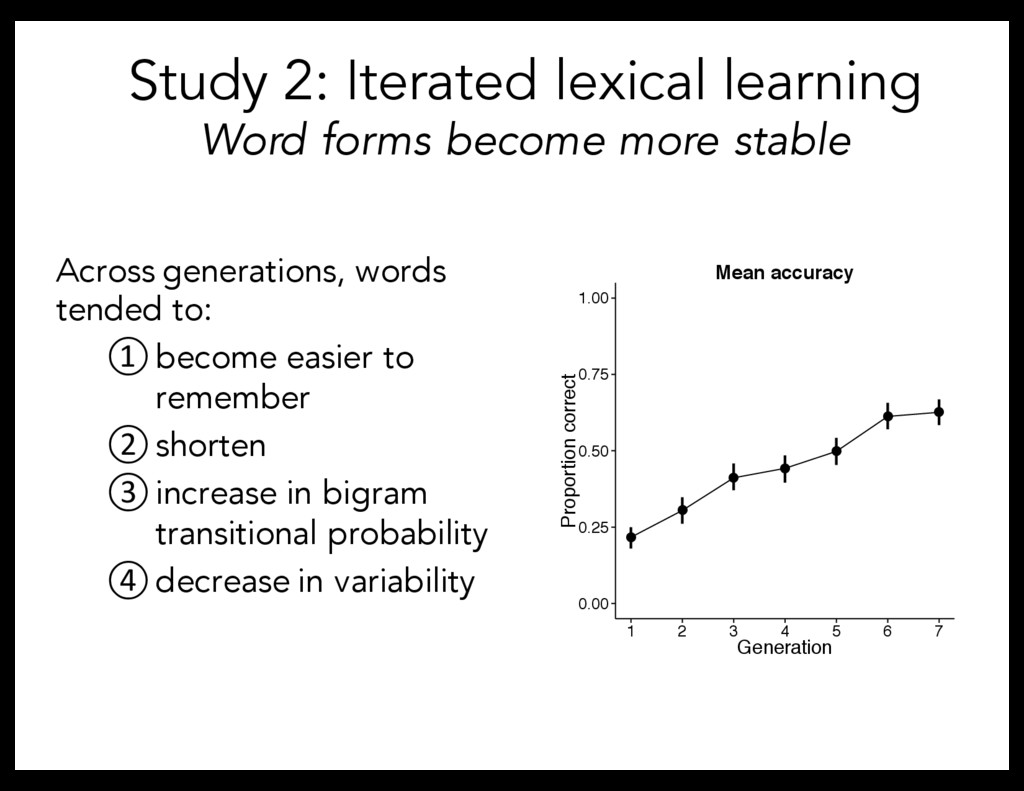
problem of linkage In an iterated learning paradigm, find: – Language becomes more stable over time – Memory errors lead to complexity bias – Change in bias may be related to memory demands and listener pressures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}