[PL] (SegFault) Nie ma nic prostszego niż napisanie wolnego regexpa
Slajdy z prezentacji podczas SegFault Łódź 2018.
W prezentacji: o tym, jak działają silniki regexpów, jak to wpływa na czas działania regexpa. Oraz o tym, co złego może się stać, jeśli nie dbamy o wydajność regexpów.
OD WYDAJNOŚĆ REGEXPÓW, OD WYDAJNOŚĆ REGEXPÓW, DLACZEGO JA POWINIENEM? DLACZEGO JA POWINIENEM? <input id="operation" pattern='(\d+[+-]?)+='> https://regex-performance.github.io/input.html
Ruby, Java, mongodb, elastic search automatyczne przygotowanie tekstu do tłumaczeń DDD, software that matters, agile dzielenie się wiedzą: Rzeszów Ruby User Group ( ) Politechnika Rzeszowska rrug.pl
<br>") Pattern p = Pattern.compile("<.*>"); Matcher m = p.matcher("text <br>"); boolean b = m.matches(); var pattern = /<.*>/; var results = re.exec("text <br>");
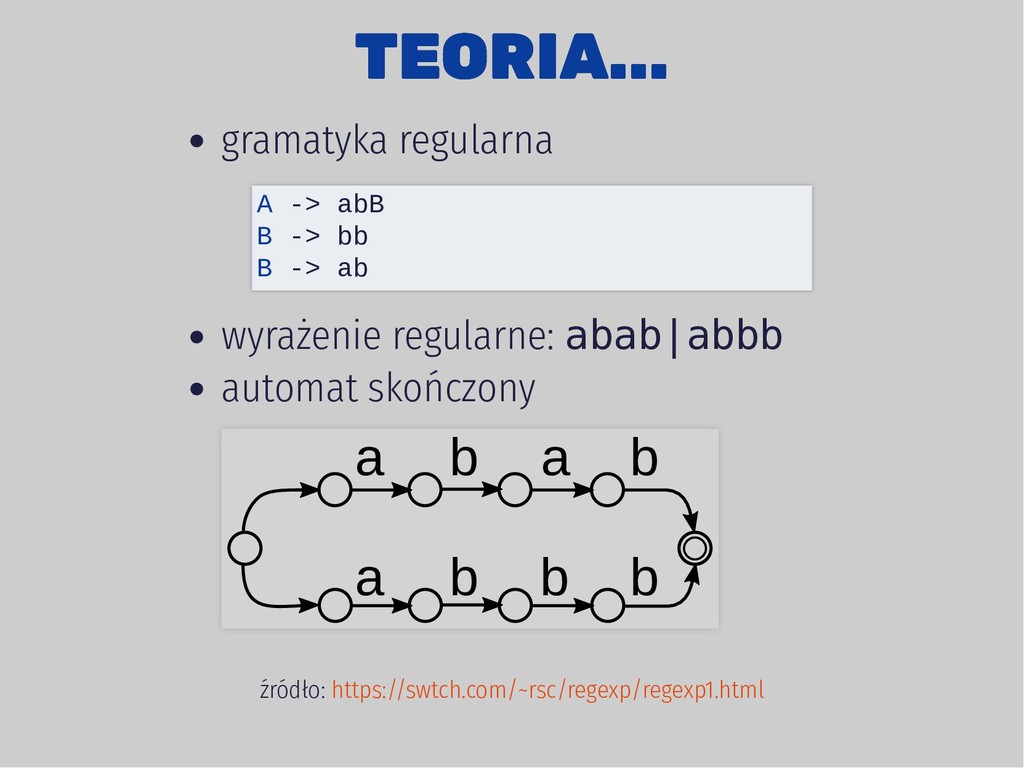
Thompson 1968, 400 linii w C grep, awk, sed, go oparte na DFA 2. Regex-directed Larry Wall, perl, 1987 Perl-Compatible Regular Expressions (JavaScript, Ruby, .Net,...) oparte na NFA
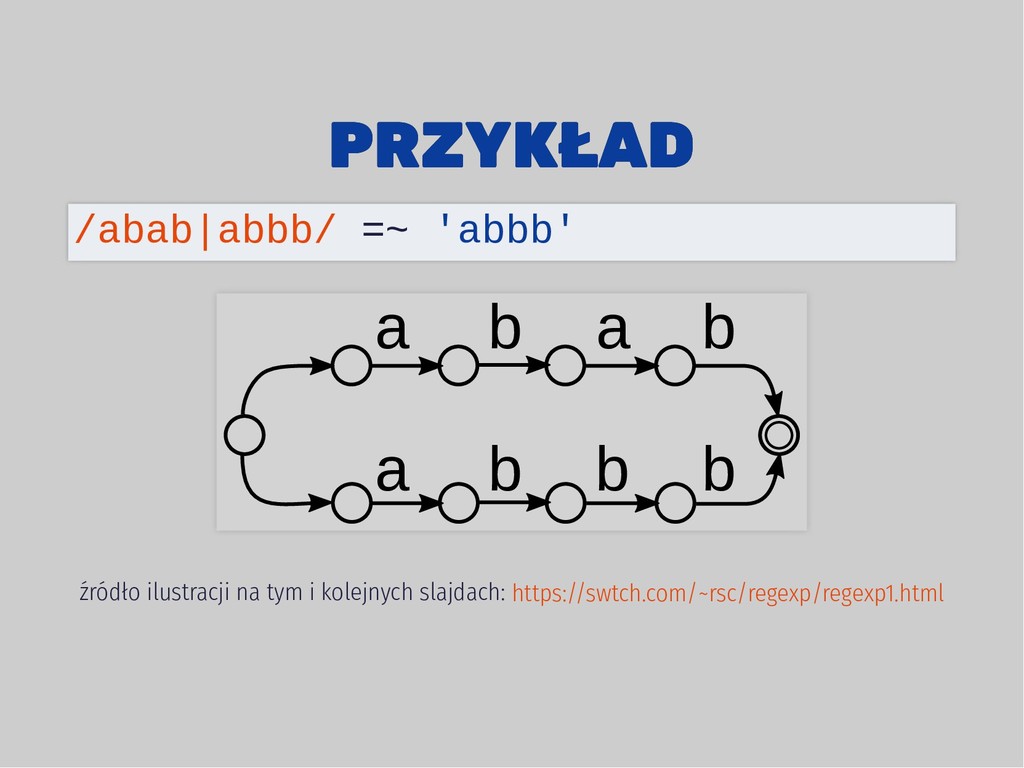
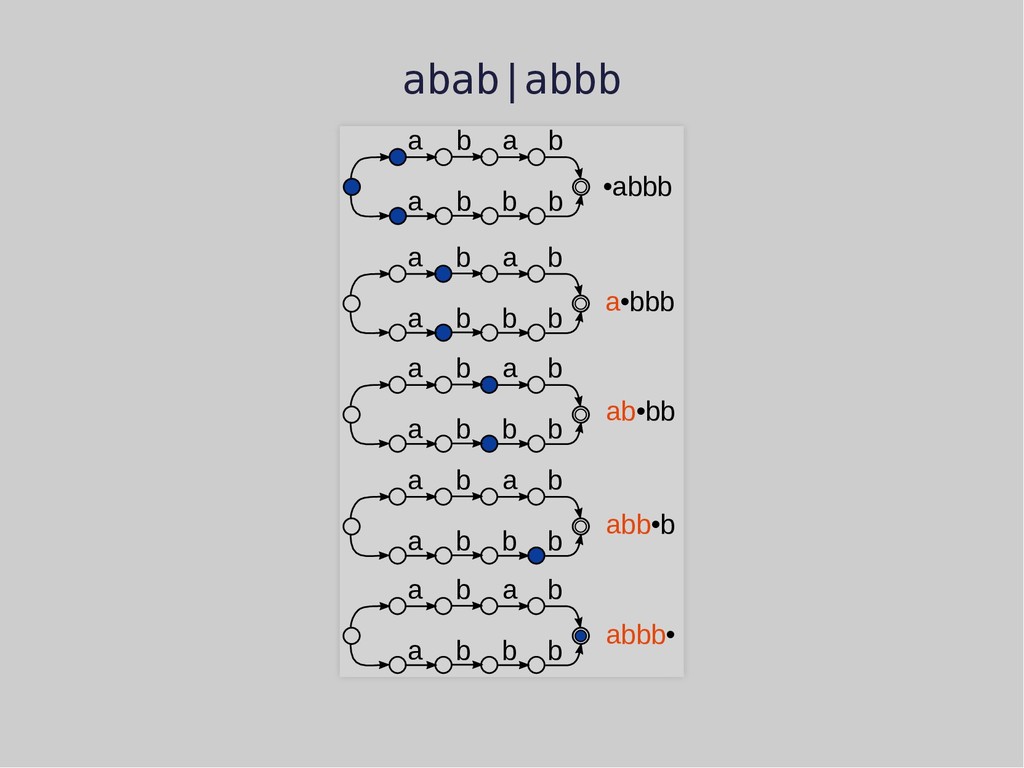
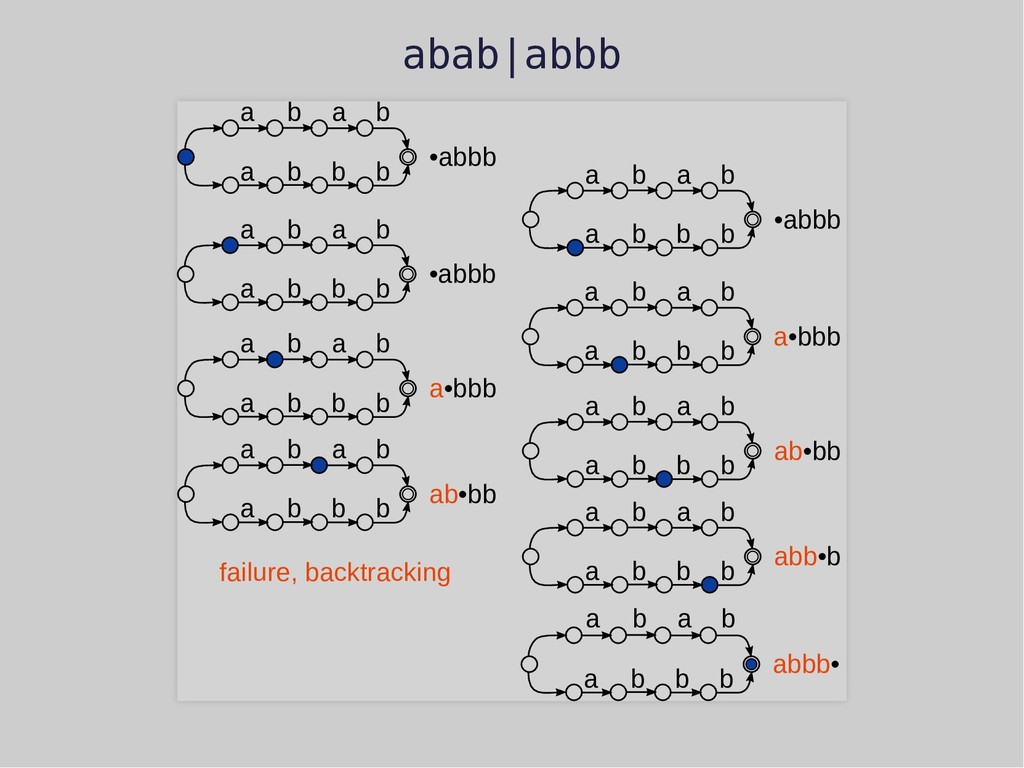
a b a a b b b b •abbb a b a a b b b b a•bbb a b a a b b b b ab•bb a b a a b b b b •abbb a b a a b b b b a•bbb a b a a b b b b ab•bb a b a a b b b b abb•b a b a a b b b b abbb• failure, backtracking
regexp text " => "<br/>" # so far so good /<.*>/=~"<abbr> regexp text </abbr>" => "<abbr> regexp text </abbr>" #hmmm... /<[^>]*>/=~"<abbr> regexp text </abbr>" => "<abbr>" # great! /<.*?>/=~"<abbr> regexp text </abbr>" => "<abbr>" # great!
wydajność zależna od długości nadmiarowo znalezionego tekstu leniwe .*? .+? - wydajność zależna od długości szukanego tekstu testy pozytywne: szukany string w różnych miejscach tekstu testy negatywne: napis bardzo podobny do szukanego
być prostszego? # liczba # 1, 3243, 4323 pattern = /\d+/ # liczba z częścią dziesiętną i minusem # -1, 1, 32.32, -2.2324 pattern = /-?(\d+(\.\d+)?/ # liczba z częścią dziesiętną (kropka albo przecinek) # -23,23 4323.23 pattern = /-?(\d+([.,]\d+)?)/
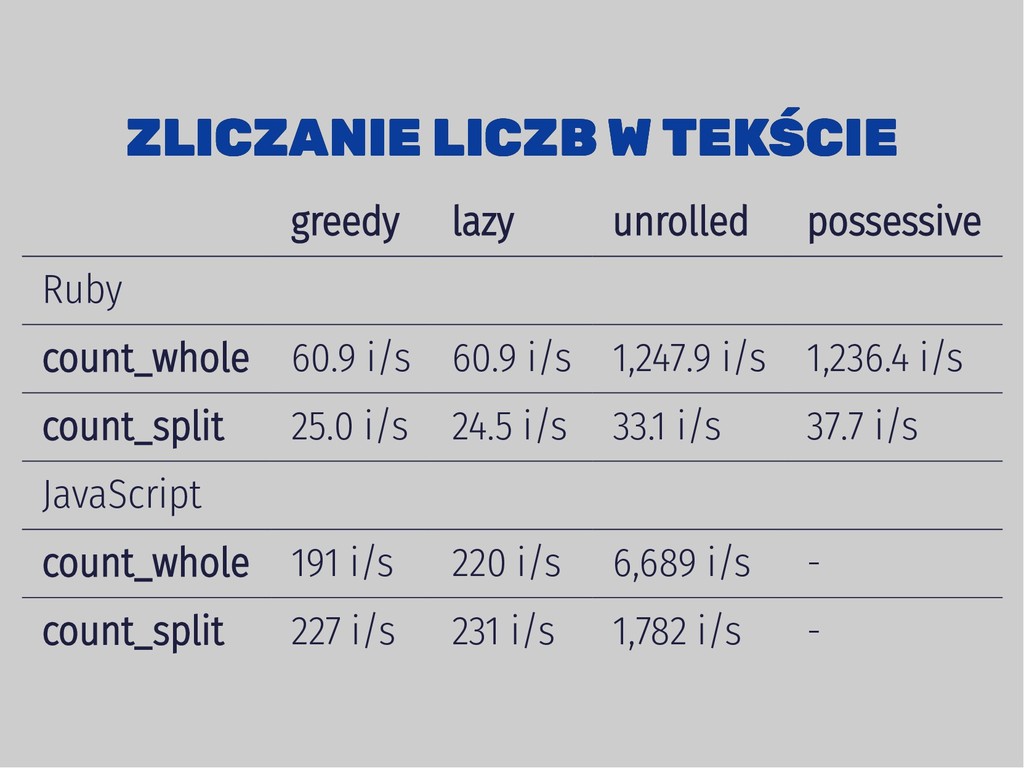
/(-?\d+([,.]\d+)*)/ possessive = /(-?(\d++[,.]?)++)/ string = "..." # ~11000 chars def count_whole(string, regex) # count how many times regex is matched on a string end def count_split(string, regex) { # split string to words, # then check which word is a number end
¡Hola! → Salut ! # Ruby # Źródła funkcji ::Typography.to_html_french # Wstaw cienką spację przed znaki interpunkcyjne text.gsub(/(\s|)+([!?;]+(\s|\z))/, ' \2\3') # Dane # <-58 spacji -> GET /wp-login.php HTTP/1.1 69 GET /show.aspx HTTP/1.1 15 klient Discourse, opisane przez Sama Saffrona
(języki programowania) nie zawsze idą w parze każdy silnik jest inny - sprawdzaj, jak działa Twój główne problemy: nachodzące się zakresy lub alternatywy, zagnieżdżone powtórzenia testy: poprawny, niepoprawny, prawie poprawny napis, różne konfiguracje
narrative are the twin goals of correctness and then efficiency (...) the aim of developing only “good enough software” — software that is neither correct nor efficient — but is good enough for its context of use, is also a postmodern approach. Noble, Biddle. Postmodern Prospects for Conceptual Modelling. 2006
i kolejne części (1-4) podziękowania dla kszubrycht http://www.rexegg.com https://www.regular-expressions.info https://regex101.com/ Russ Cox aplikacja testowa - oryginał OWASP ReDoS Loggly: 5 techniquess Loggly: regexes bad better... Katafrakt: Regular expression how do they work?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DZIAŁANIA ARYTMETYCZNE DZIAŁANIA ARYTMETYCZNE 320-12= 430- 32+1= /\d+[-+]\d+=/ # v1.0](https://files.speakerdeck.com/presentations/3f0f4a007d4a45249ad8854192915ec0/slide_26.jpg){kind=link}
![COPY-PASTING COPY-PASTING (email validation) , Java Classname RegExLib, id=1757 ^([a-zA-Z0-9])(([\-.]|[_]+)?](https://files.speakerdeck.com/presentations/3f0f4a007d4a45249ad8854192915ec0/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TESTY TESTY greedy = /(-?(\d+[,.]?)+)/ lazy = /(-?(\d+?[,.]?)+?)/ unrolled =](https://files.speakerdeck.com/presentations/3f0f4a007d4a45249ad8854192915ec0/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DOBRE PRAKTYKI DOBRE PRAKTYKI .* => [^X]* .*? => [^X]*](https://files.speakerdeck.com/presentations/3f0f4a007d4a45249ad8854192915ec0/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}