unsupervised learning. • This Network generalizes the GCN approach to use trainable aggregation functions (beyond simple convolutions). • It can classify the category of unseen nodes in evolving information graphs and generalize to completely unseen graphs. 2
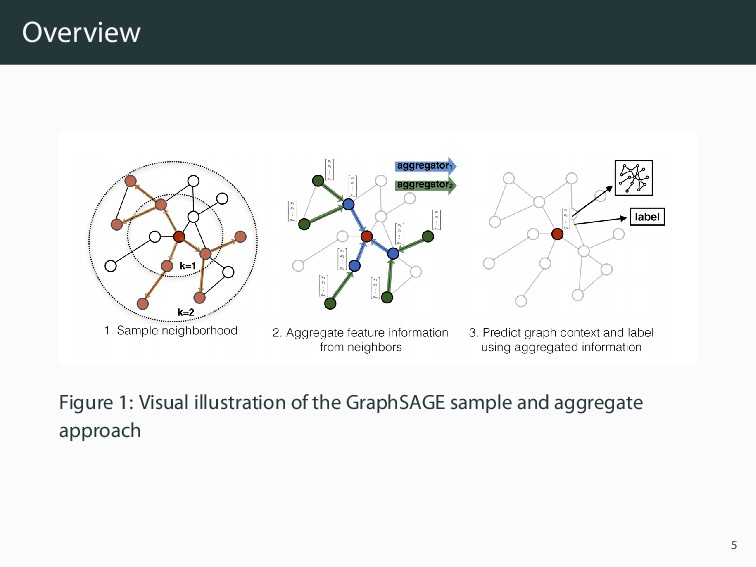
Input: depth K Input: weight matrices Wk, ∀k ∈ {1, . . . , K} Input: neighborhood function N : v → 2V Output: Vector representations zv for all v ∈ V h0 v ← xv, ∀v ∈ V for k = 1 . . . K do for v ∈ V do hk N(v) ← AGGREGATEk({hk−1 u , ∀u ∈ N(v)}) hk v ← σ(Wk · CONCAT(hk−1 v , hk N(v) )) end hk v ← hk v/||hk v||2, ∀v ∈ V end zv ← hK v , ∀v ∈ V 6
from the set {u ∈ V : (u, v) ∈ E}, and selects different uniform samples at each iteration, k. Using this sampling, the per-batch space and time complexity is fixed at O( ∏K i=1 Si) (in this case, K = 2 and S1 · S2 ≤ 500); otherwise O(|V|). 7
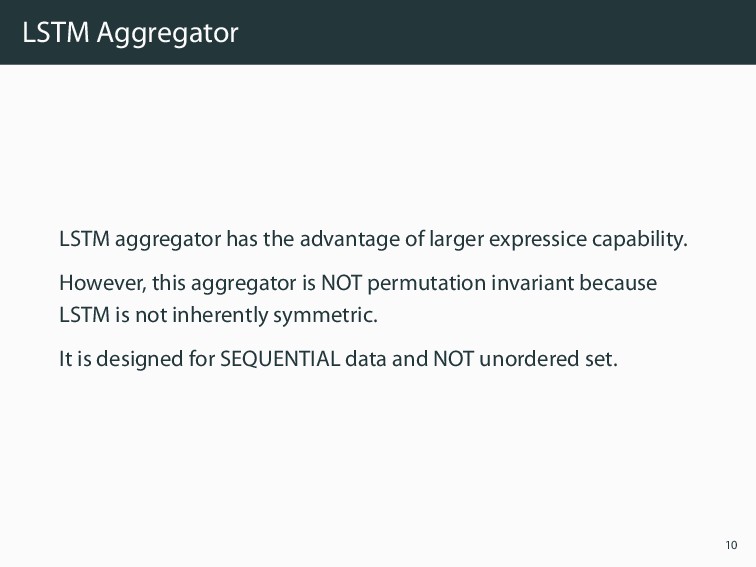
arbitrarily ordered node neighborhood feature sets, an aggregator function would be symmetric and trainable and high representational capacity. In this paper, 3 aggregators were proposed. • Mean aggregator • LSTM aggregator • Pooling aggregator 8
the vector. It is nearly equivalent to the convolutional propagation rule used in the transductive GCN. (Kipf+) Inductive variant of the GCN can be derived by replacing aggregator and concat operator with the following. hk v ← σ(W · MEAN({hk−1 v } ∪ {hk−1 u , ∀u ∈ N(v)} It does not perform the concatenation operation which is viewed as skip connection. 9
capability. However, this aggregator is NOT permutation invariant because LSTM is not inherently symmetric. It is designed for SEQUENTIAL data and NOT unordered set. 10
∈ N(v)}) Pooling aggregator is symmetric and trainable. MLP can be thought of as a set of functions that compute features for each of the node representations in the neighbor set. By applying the max-pooling operator, the model effectively captures different aspects of the neighborhood set. 11
log(σ(z⊤ u zv)) − Q · Evn∼Pn(v) log(σ(−z⊤ u zvn )) This encourages nearby nodes to have similar representations and enforces that the representations of disparate nodes are highly distinct. Reference Distributed Representations of Words and Phrases and their Compositionaliy, Tomas Mikolov+, 2013 https://arxiv.org/abs/1310.4546 12
categories. • Reddit dataset Predict which community different Reddit posts belong to. These tasks are classifying nodes in evolving information graphs. It is especially relevant to high-throughput production systems, which constantly encounters unseen data. 13
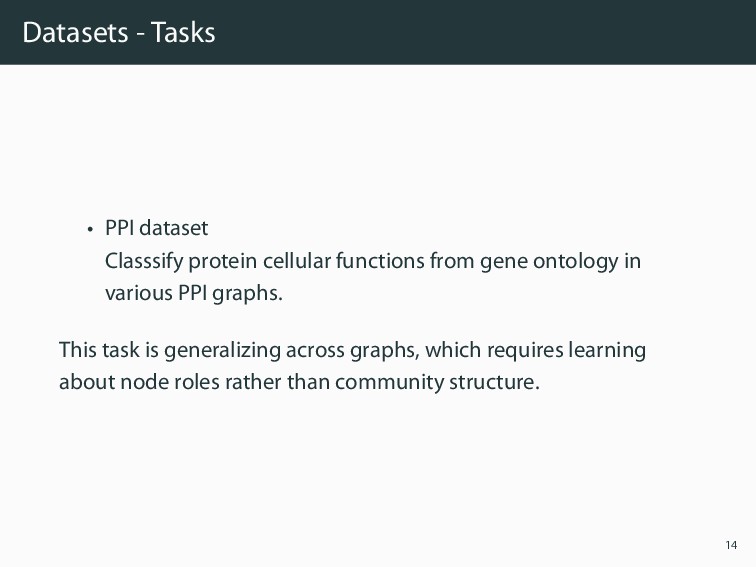
from gene ontology in various PPI graphs. This task is generalizing across graphs, which requires learning about node roles rather than community structure. 14
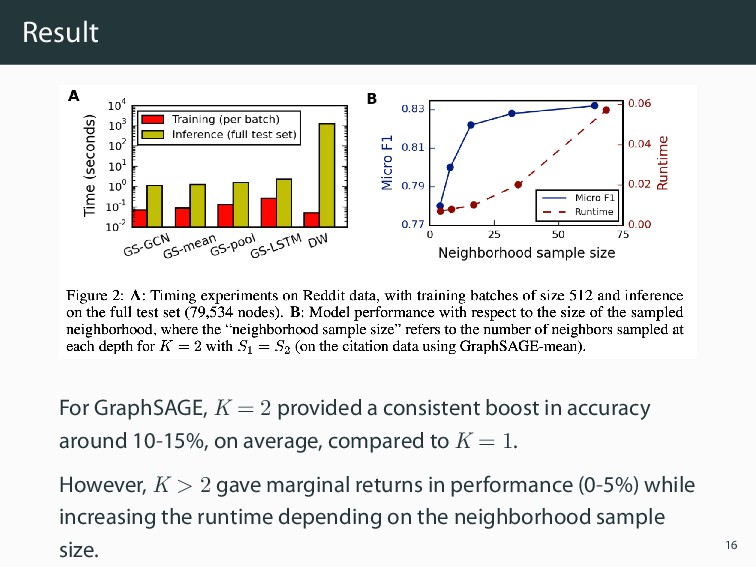
in accuracy around 10-15%, on average, compared to K = 1. However, K > 2 gave marginal returns in performance (0-5%) while increasing the runtime depending on the neighborhood sample size. 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}