A talk given as a guest lecture for Ulster University MSc in Ethical and Responsible AI. The talk discusses (non-technical) considerations on how to balance model complexity with interpretability.
Geometry, Statistics, Sampling Theory (Monte Carlo Methods) Postdoc in Statistics/Statistical learning at University of Waterloo (Canada) and Illinois Institute of Technology (USA) Lecturer of Statistics at University of St Andrews Teaching ‘Statistical Machine Learning’ and ‘Machine Learning for Data Analysis’ Statistical consulting for start-ups across the UK and Ireland. 3
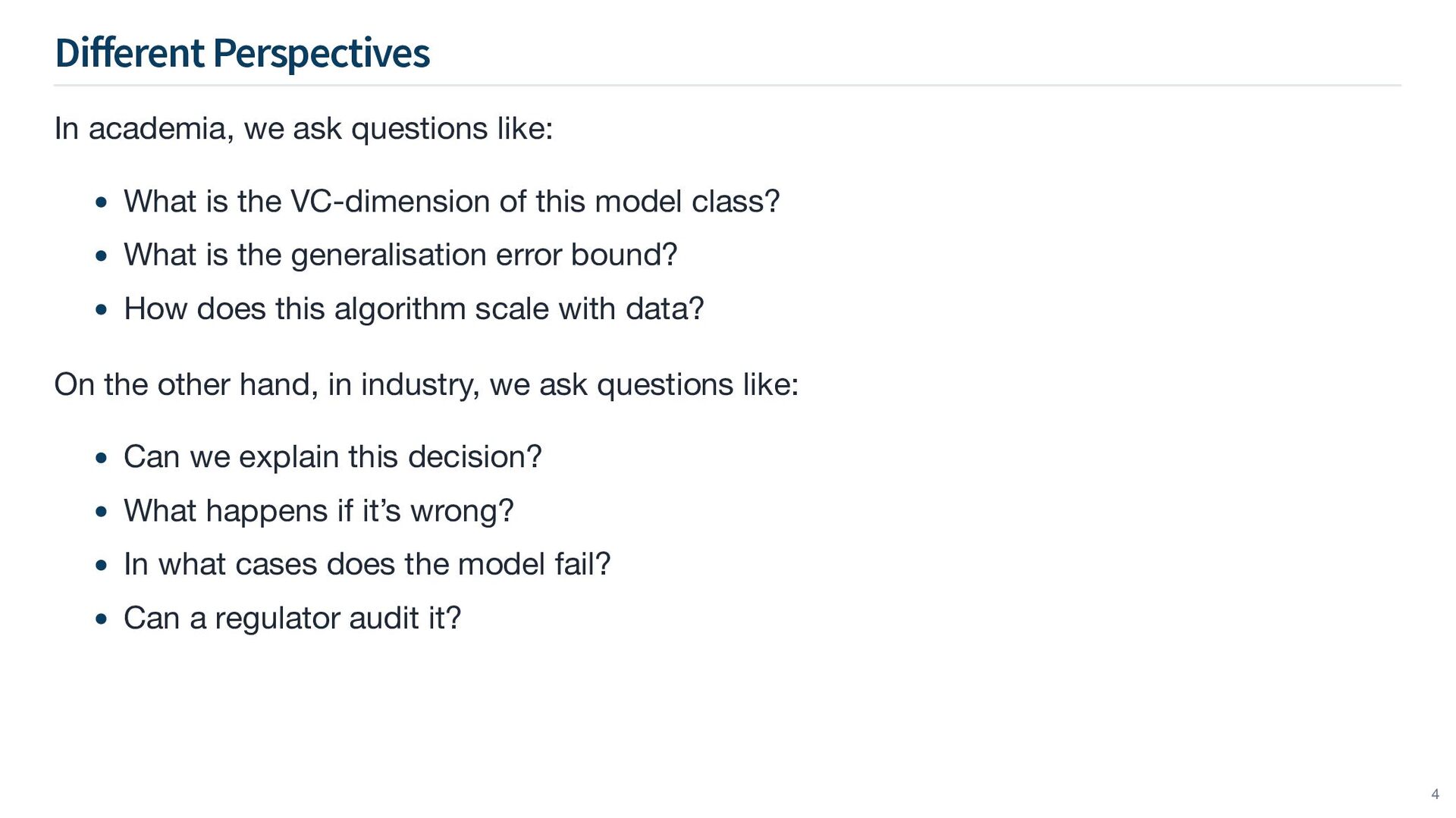
other hand, in industry, we ask questions like: What is the VC-dimension of this model class? What is the generalisation error bound? How does this algorithm scale with data? Can we explain this decision? What happens if it’s wrong? In what cases does the model fail? Can a regulator audit it? 4
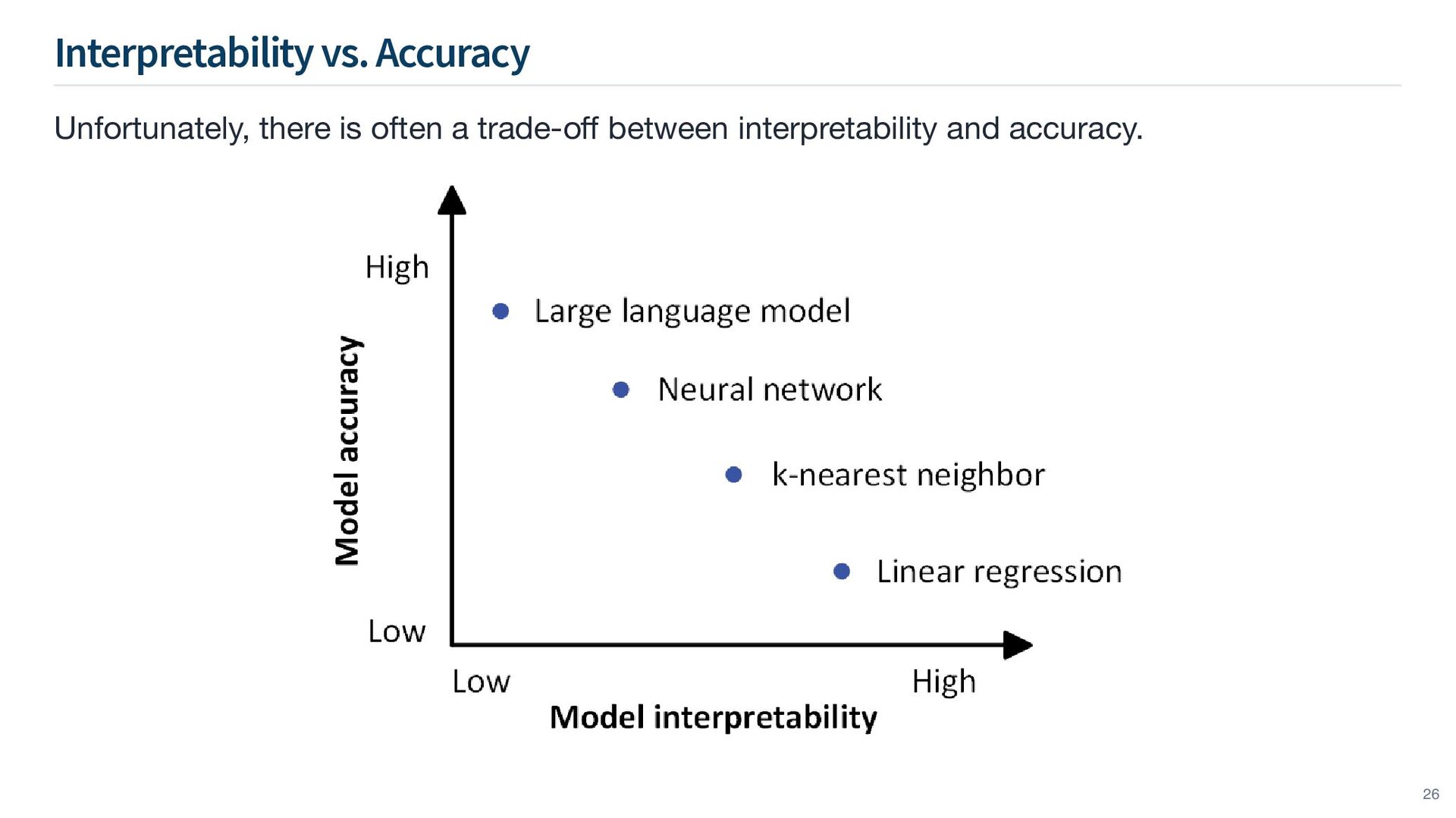
terms of: These are all important issues. Today, I’ll focus on responsible AI through model design. Specifically: Data privacy Bias-in-data mitigation Transparency Regulation and governance (e.g., EU AI Act) choosing interpretable models choosing “the correct” model matching the model complexity to the problem 5
we want to find a function such that We assume: {(xi , yi )} N i=1 f for all f(xi ) ≈ yi i generalises well to new data, i.e. for new . f f(X) ≈ Y (X, Y ) The training data are sampled from some distribution , representative of the real world. D Future data are drawn from the same distribution . D There exists some stable and predictable relationship between and that we can learn. X Y 8
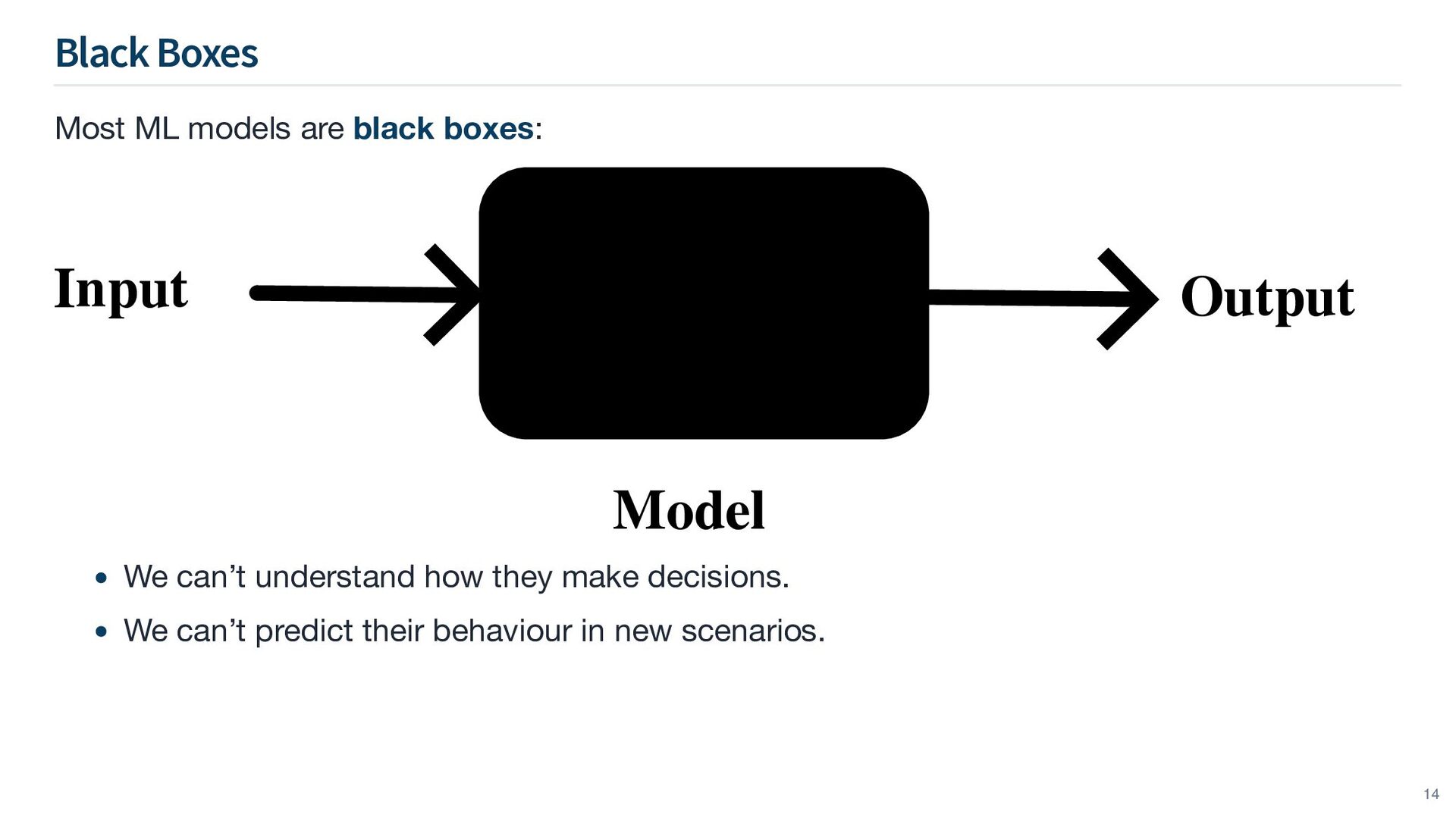
need not consider just pure accuracy performance, but also interpretability when designing and deploying machine learning models. Data Problems Data are often biased and unrepresentative models learn and perpetuate bias. ⇒ Models are deployed in dynamic environments data distribution changes quickly model degradation ⇒ D ⇒ Data noise little to no relationship between and . ⇒ X Y Model Problems Overfitting to training data poor generalisation. ⇒ Models deployed in high-stakes scenarios need for transparency for auditability. ⇒ 9
Their current solution for a process is manual, takes one day and has 30% error rate. You work on it, and come up with 3 possible ML alternative solutions. Which is the best? Scenario 1. Process takes 30 mins with error rate 1%. ZERO interpretability. 2. Process takes 1 hour with error rate 20%. Some interpretability. 3. Process takes one day with error rate 20%. Good interpretability. 10
US courts to predict the likelihood that a defendant would reoffend. What we should learn: COMPAS Algorithm Found to be biased against African American defendants. The model, nor the training data, was ever released for independent audit. Most likely not a cause with the model, but due to bias within training data. Lack of transparency or peer review can lead to unfair outcomes. 11
an AI recruiting tool to automate the hiring process. What we should learn: Amazon’s AI Recruiting Tool Found to be biased against women—traditionally more male applicants and employees in tech roles. Ultimately, the tool was scrapped. Again, bias in training data can lead to biased outcomes. 12
to predict house prices and automatically purchase homes at scale. What we should learn: Zillow’s ‘Zestimate’ Home Valuation Tool The pricing models systematically mispredicted market movements. The company overpaid for thousands of homes. Zillow shut down the entire division and laid off 25% of its workforce Do not make important decisions (e.g., take large financial positions) automatically based on model output without human oversight. 13
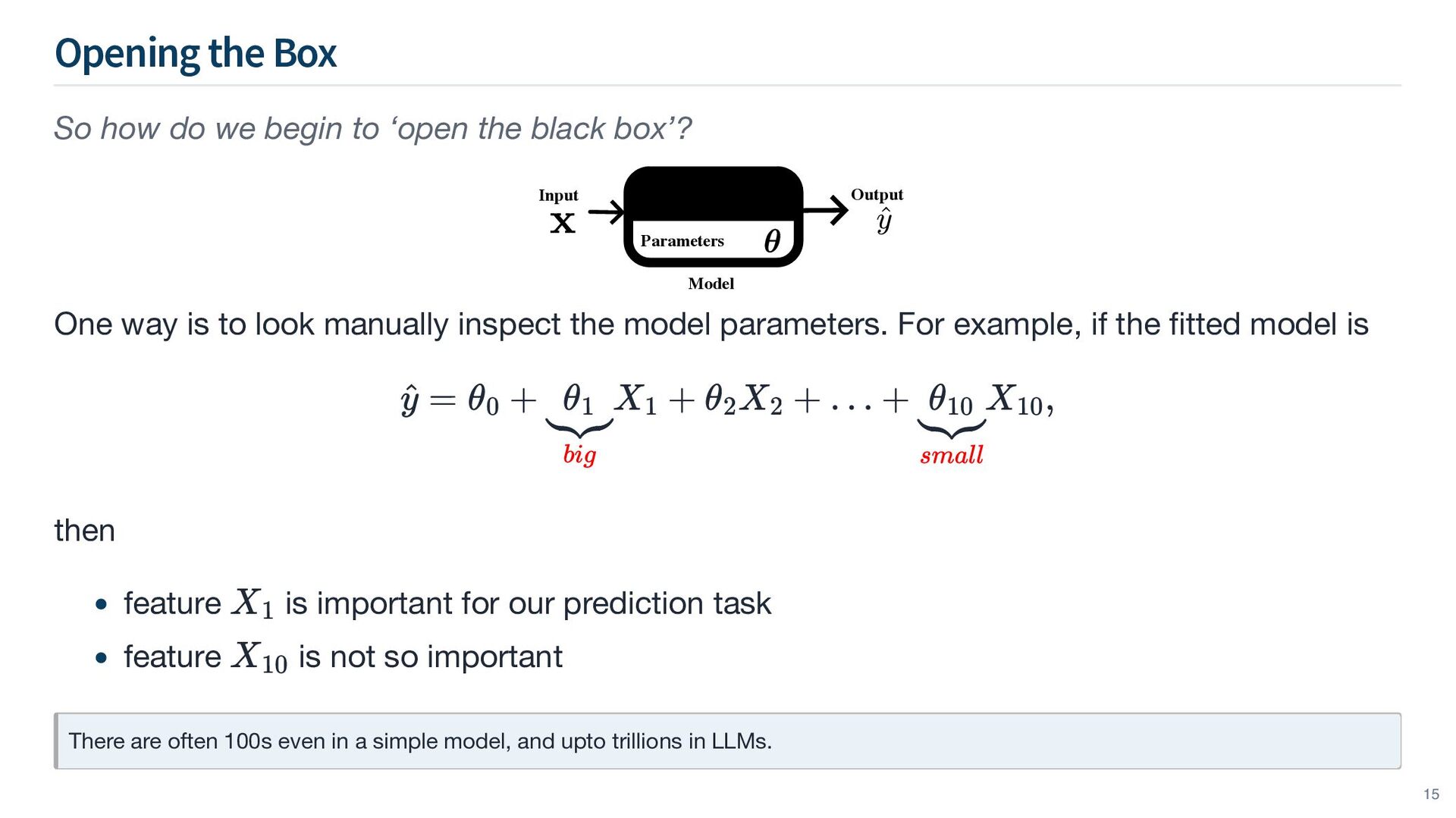
the black box’? One way is to look manually inspect the model parameters. For example, if the fitted model is then There are often 100s even in a simple model, and upto trillions in LLMs. Model Output Input Parameters ^ y = θ0 + θ1 big X1 + θ2 X2 + … + θ10 small X10 , feature is important for our prediction task X1 feature is not so important X10 15
Choose a white box model In this case, we can determine feature importance and trace model decision making Choose a small model Among other things, we can prevent model overfitting and therefore improve model generalisation 16
the decision-making process can be inspected and understood by humans. White box models are definitely less common than black box. However, they do exist. For example, a decision tree is a white box model. 19
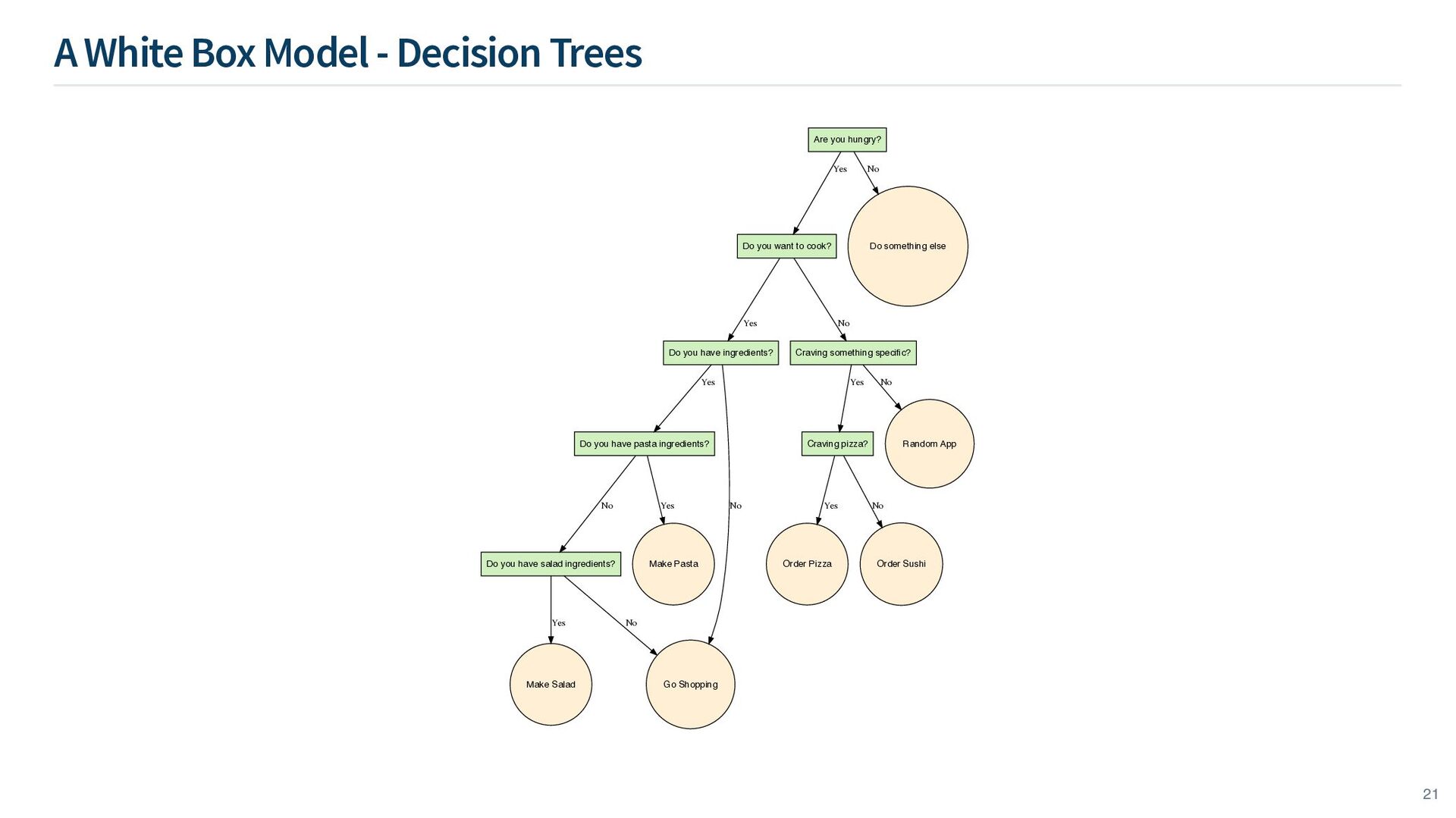
often comes after a series of yes/no answers to questions. For example, deciding what to do for dinner tonight might involve a series of questions: Depending on your binary “yes/no” answers to these questions, you might end up with different decisions for dinner. “Are you hungry?” “Do you want to cook?” “Do you have ingredients?” “Craving something specific?” “Craving pizza?” etc. 20
Do you want to cook? Yes Do something else No Do you have ingredients? Yes Craving something specific? No Do you have pasta ingredients? Yes Go Shopping No Do you have salad ingredients? No Make Pasta Yes Make Salad Yes No Craving pizza? Yes Random App No Order Pizza Yes Order Sushi No 21
methods are a family of supervised learning algorithms that model a response variable by recursively partitioning the data into subsets and fitting a simple model (usually a constant) within each subset. A decision tree is composed of: nodes either decision nodes or terminating leaves branches represent possible outcomes of the decision nodes 22
the Auto dataset, which contains information about different cars, including their miles per gallon (mpg), number of cylinders, horsepower, weight, etc. What are the most important features for determining high or low mpg? 23
are not always the best performing models. They can: Thus, many trees are often used in an ensemble (such as in random forests or boosted trees) to improve performance. Let’s look at random forests. be prone to overfitting; and may not capture complex relationships in the data 24
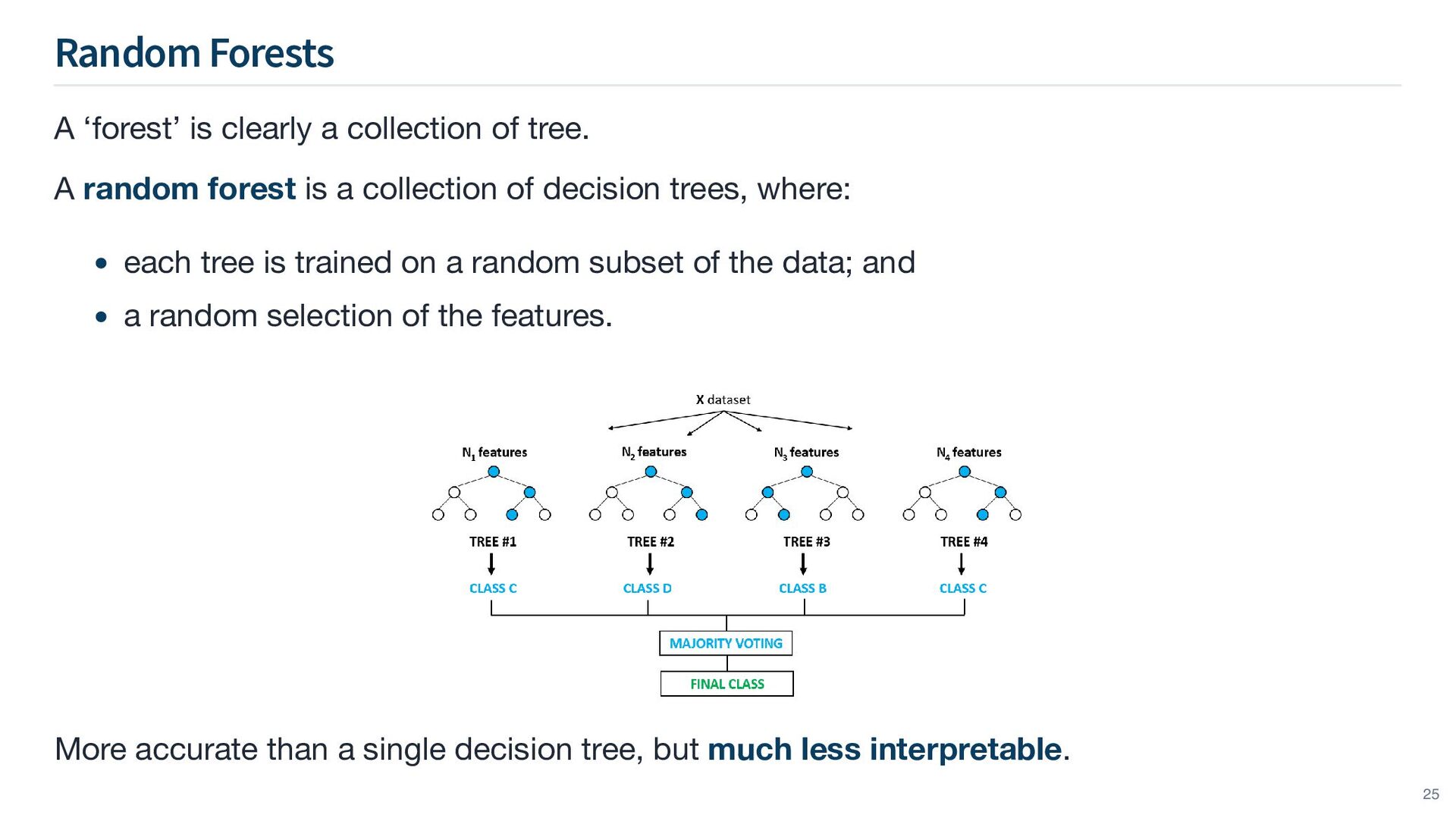
A random forest is a collection of decision trees, where: More accurate than a single decision tree, but much less interpretable. each tree is trained on a random subset of the data; and a random selection of the features. 25
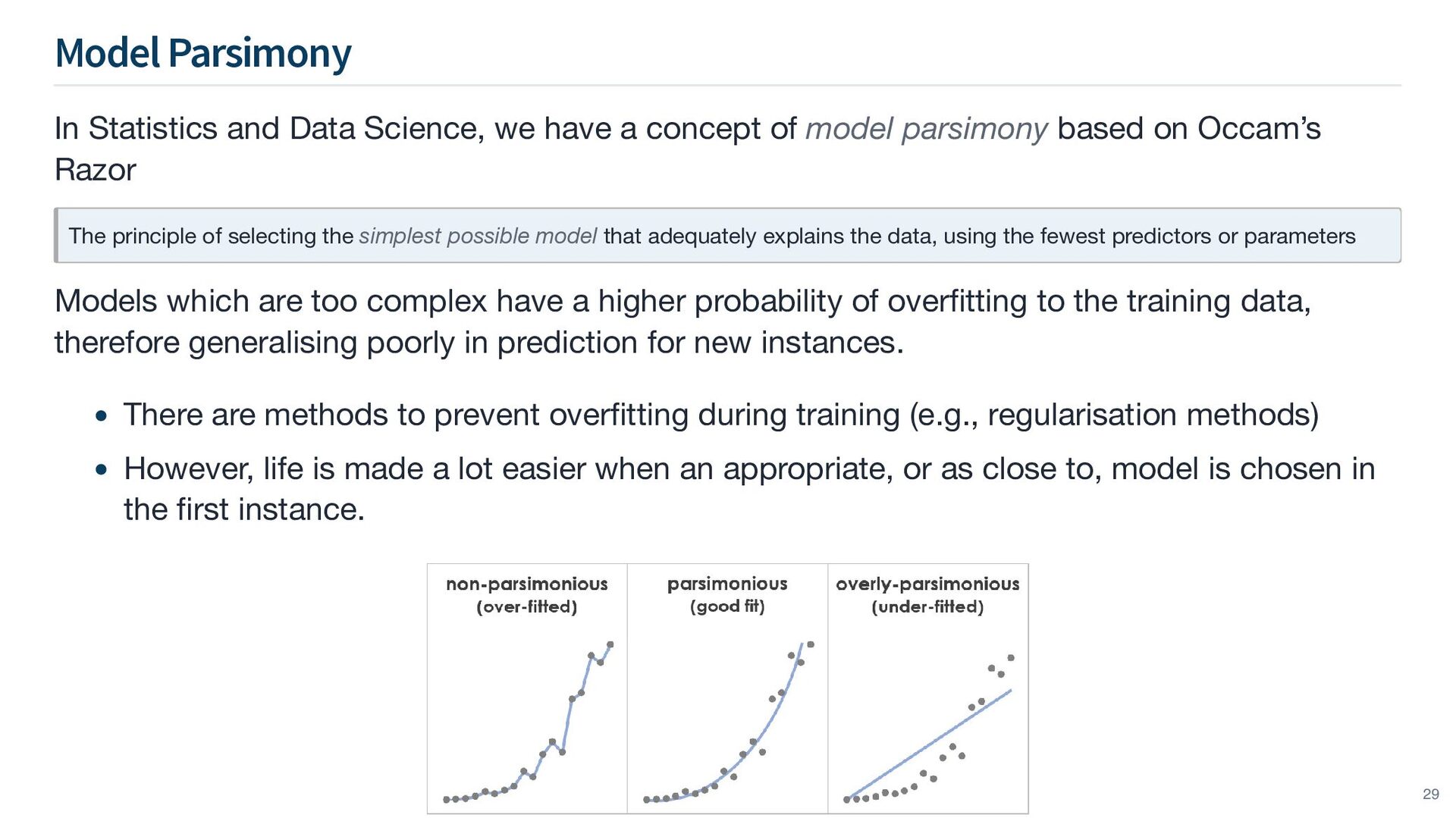
concept of model parsimony based on Occam’s Razor The principle of selecting the simplest possible model that adequately explains the data, using the fewest predictors or parameters Models which are too complex have a higher probability of overfitting to the training data, therefore generalising poorly in prediction for new instances. There are methods to prevent overfitting during training (e.g., regularisation methods) However, life is made a lot easier when an appropriate, or as close to, model is chosen in the first instance. 29
learning has moved toward increasingly large models. Put simply, many applications require complex models to attempt to capture complex relationships. But bigger models are not always better. In many real-world applications: Billions or even trillions of parameters Trained on enormous datasets Require specialised hardware and data centres the task is narrow and well-defined the data are domain-specific the model must run locally or in real time 30
smaller specialised models. Large Models Examples: Small Models Examples: Billions–trillions of parameters Trained on vast internet-scale data Hosted in large data centres General-purpose capability LLMS (e.g., ChatGPT and Gemini – 1T parameters) Diffusion models for images (e.g., HunyuanImage – 500B parameters) Millions–billions of parameters Trained on task-specific data Can run locally or on-device Designed for one particular task DistilGPT Small Vision models (YOLO) 31
toward smaller, specialised models. Cost Training and operating very large models is extremely expensive. Energy consumption Large data centres require enormous energy resources. Data privacy Sensitive data often cannot leave an organisation. Regulation Laws such as the EU AI Act emphasise data sovereignty. Reliability Smaller models trained on narrow tasks often hallucinate less. 32
used in real-world systems. Examples include: In many of these cases, a large general-purpose model is unnecessary. Legal document analysis small language models summarising contracts locally Environmental monitoring tiny vision models on drones detecting pests or waste Medical imaging compact neural networks assisting radiologists in real time Education lightweight AI tutors providing personalised learning 33
focus on regulation, governance and ethics frameworks. Responsible AI also happens at the model design level. Choices about: all influence how safe and trustworthy an AI system becomes. model complexity interpretability management of training data deployment environment 34
choices. An important one should be building the correct model for the task. Thank you. Real-world machine learning rarely satisfies ideal assumptions. Black-box models can create risks in high-stakes applications. White-box models provide interpretability. We often could settle for a grey box, to balance complexity and interpretability Small, specialised models often provide practical and safer solutions. 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}