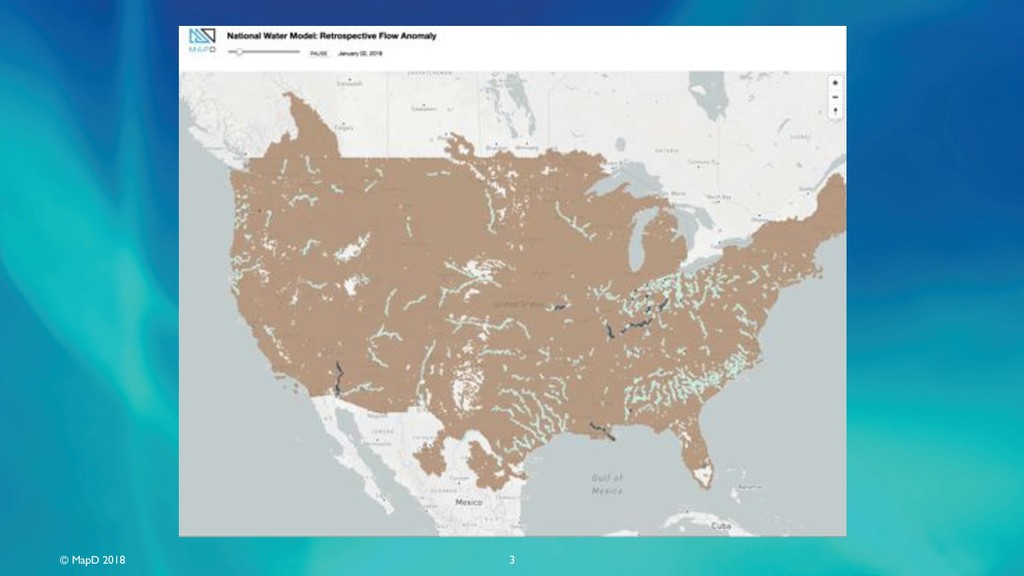
The increasing availability of large-scale cloud computing resources has enabled large-scale environmental predictive models such as the National Water Model (NWM) to be run essentially continuously. Such models generate so many predictions that the output alone presents a big data computing challenge to interact with and learn from.
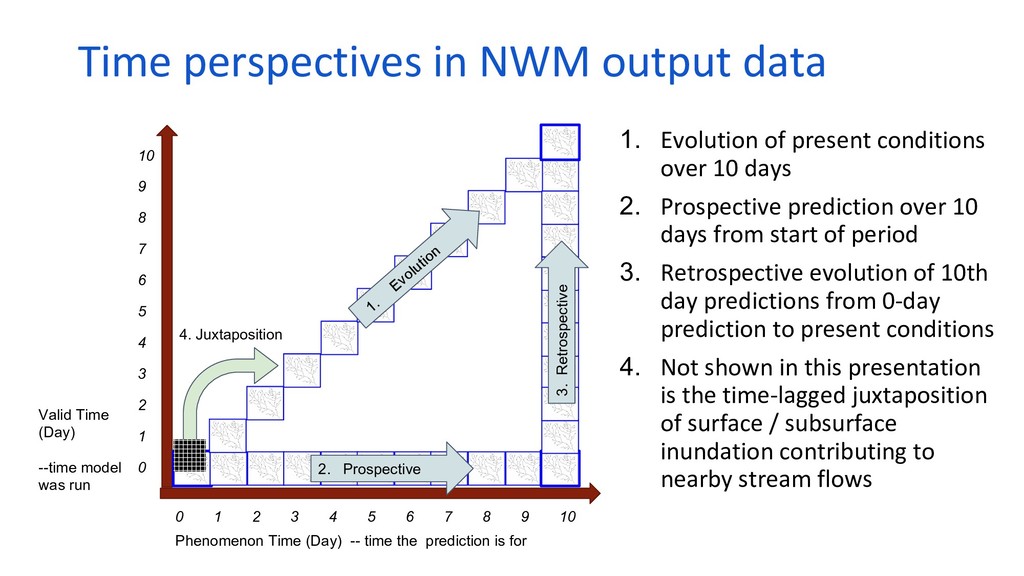
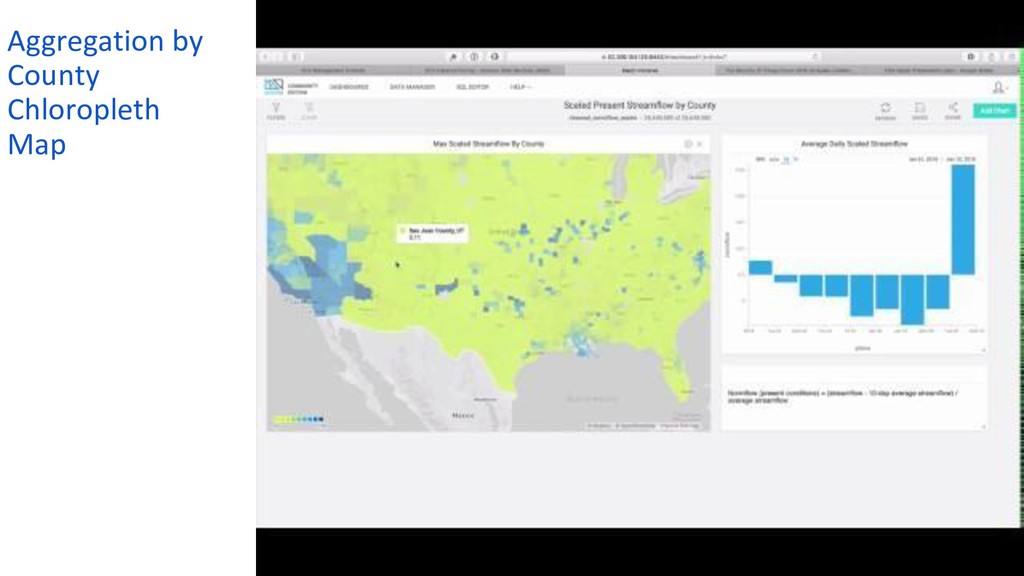
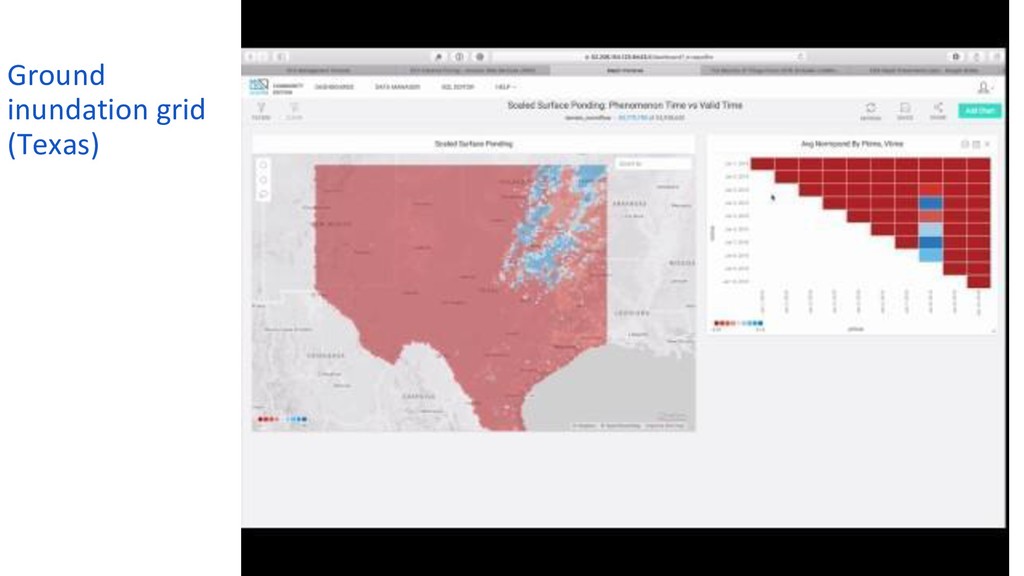
Researchers at the Harvard Center for Geographic Analysis are working with the open-source, GPU-powered database MapD to provide true interactive access to NWM predictions for stream flow and ground saturation across the entire continental US and from present conditions to 18 days in the future. Predictions can be viewed prospectively, “how will conditions change going forward?” as well as retrospectively, “how did condition predictions evolve up to any given present?”. Water conditions can also be tracked in space and time together as storms move across the country.
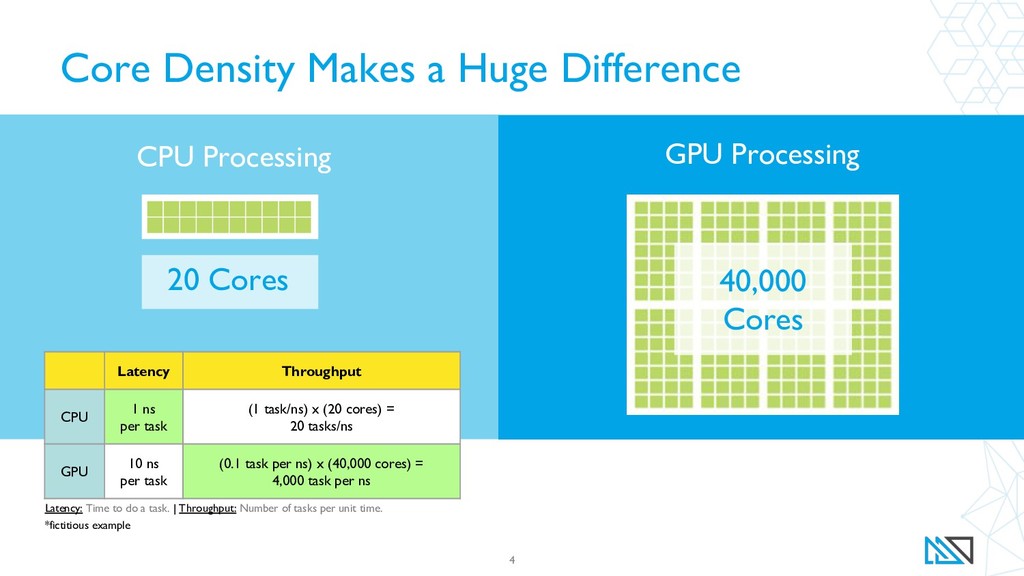
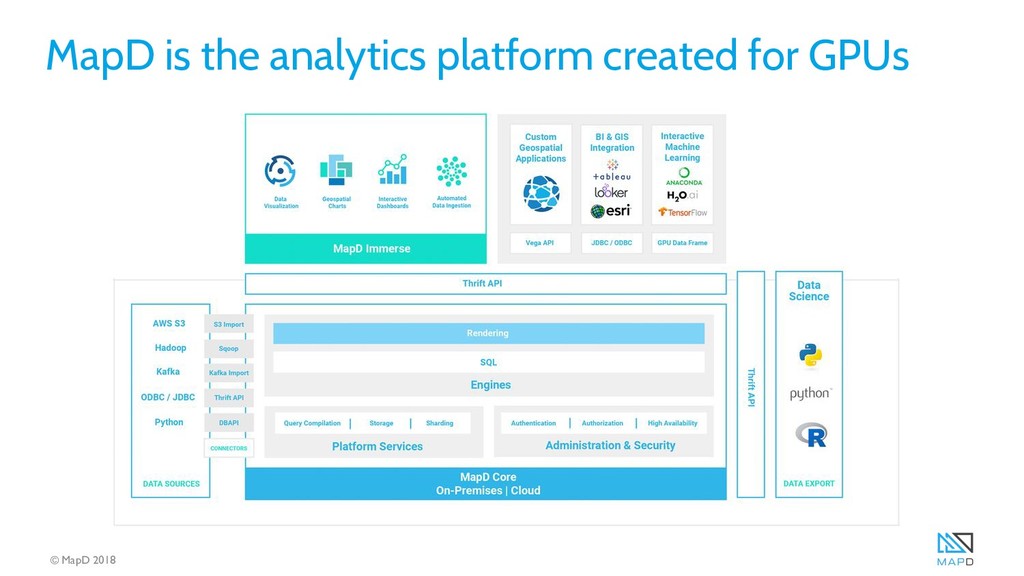
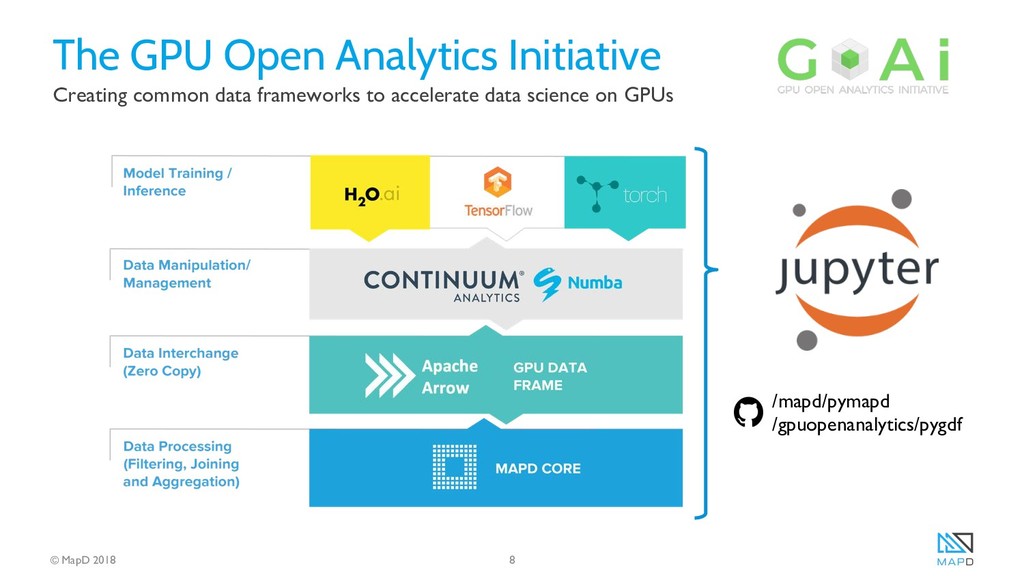
The speed and flexibility of the GPU analytics platform allows questions such as “how did the stream flow prediction error change over time?" to be answered quickly with SQL queries, and facilitates joining in additional data such as the location of bridges and other vulnerable infrastructure, all with relatively low-cost computing resources. MapD and other open-source high-performance geospatial computing tools have the potential to greatly broaden access to the full benefits of large-scale environmental models being deployed today.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}