tasks, datasets, domain and etc. in acceptable time; • Save human and computing resources during development by automating search and speeding up the evaluation of results. Model optimization • Deep neural network should be on smartphones, smart watches, smart fridges and etc. • Support of low-bit processors should be provided; • Real-time apps require fast inference; • Neural networks are overparameterized; • Large models outperform small models; • DNN has poor generalization ability.
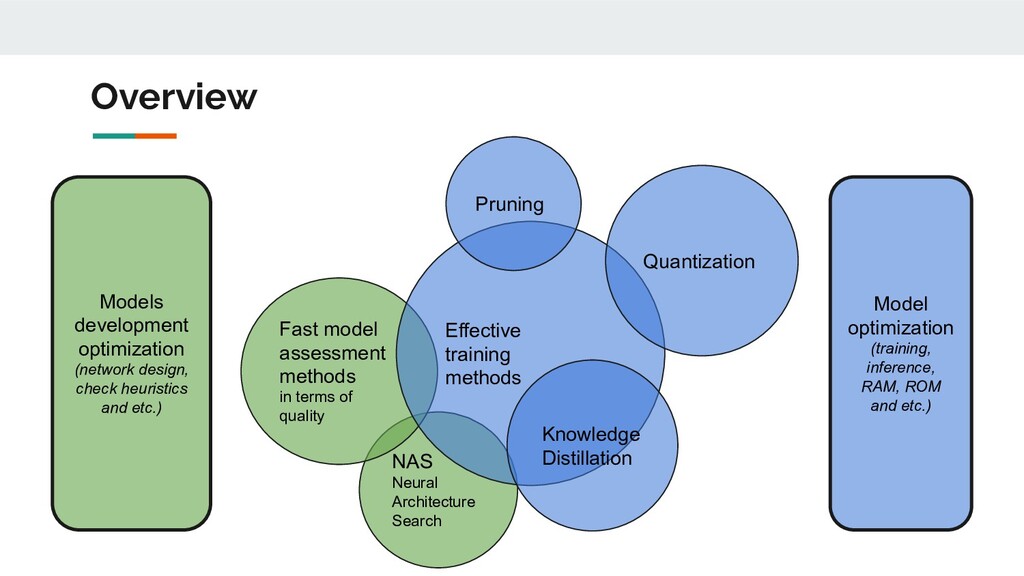
Model optimization (training, inference, RAM, ROM and etc.) NAS Neural Architecture Search Fast model assessment methods in terms of quality Effective training methods Quantization Knowledge Distillation Pruning
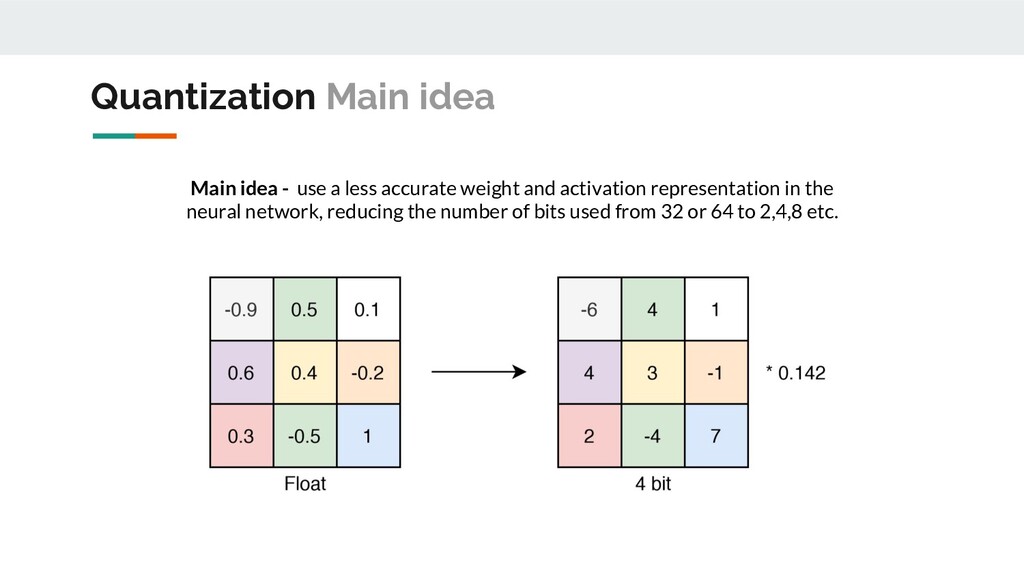
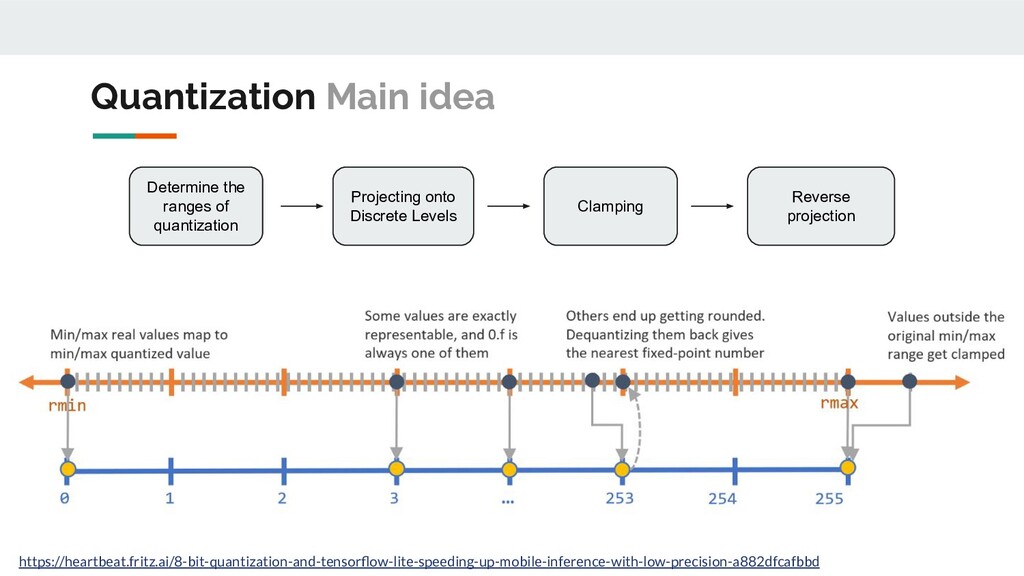
Reverse projection https://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd Quantization Main idea
papers. Model: ResNet-18. Dataset: ImageNet. The minimum drop in accuracy for each number of bits is highlighted in green. Weight and activations are quantized with equal number of bits, expect the first and last layers for most methods. It is hard to compare different methods due to wide variety quantization settings (w/a bits). For some methods the complete quantization pipeline is unclear. Correctness: LINEAR SYMMETRIC QUANTIZATION OF NEURAL NETWORKS FOR LOW-PRECISION INTEGER HARDWARE
Portability to mobile devices and low-bit processors • The latest methods allows for not losing accuracy on certain tasks • Good at classification problems, img-to-img problems are understudied • Lots of research with unrealizable quantization schemes • Large networks with more aggressive quantization are often better than small networks with soft quantization • Trend - aware-training quantization Quantization Outcomes
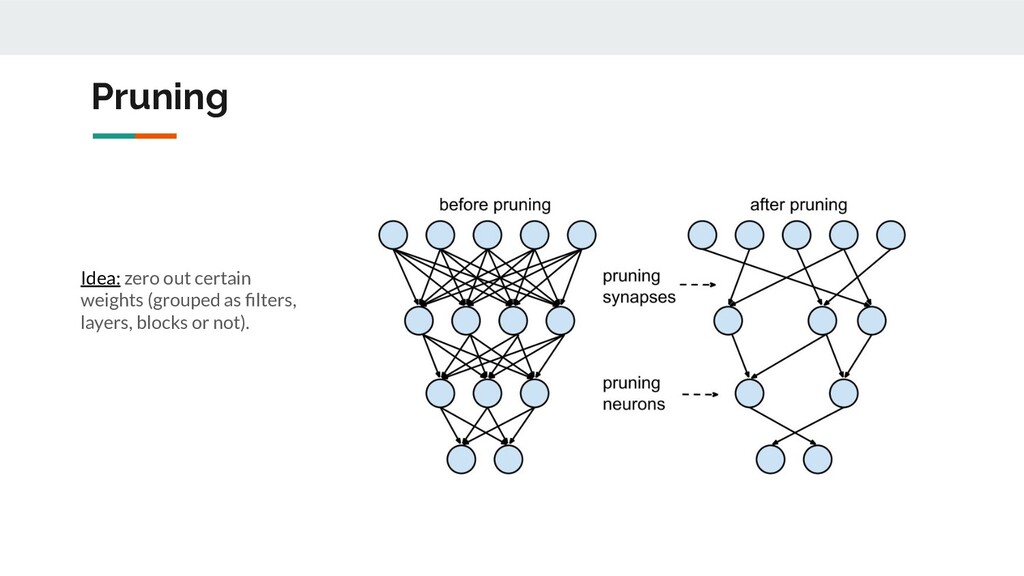
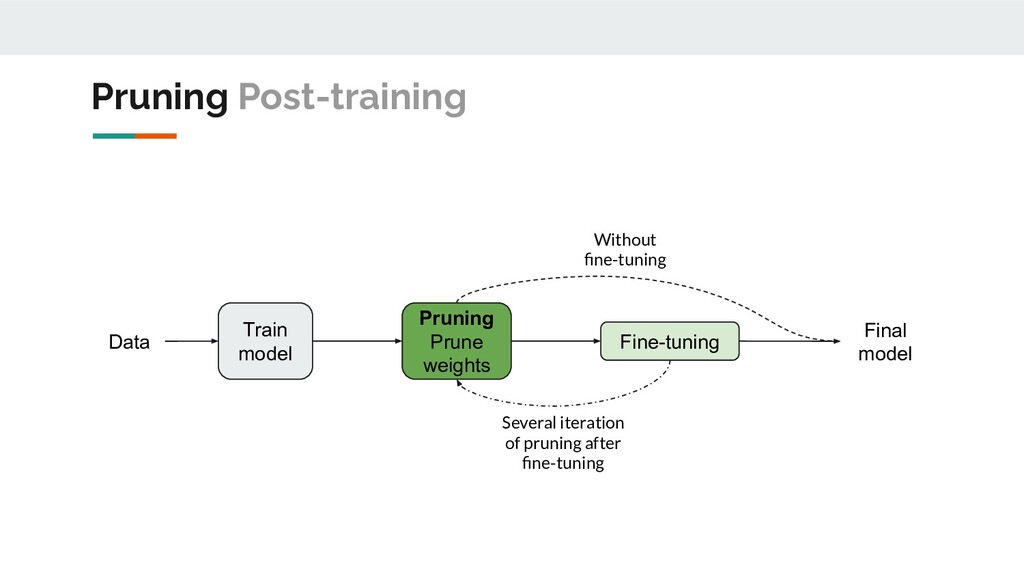
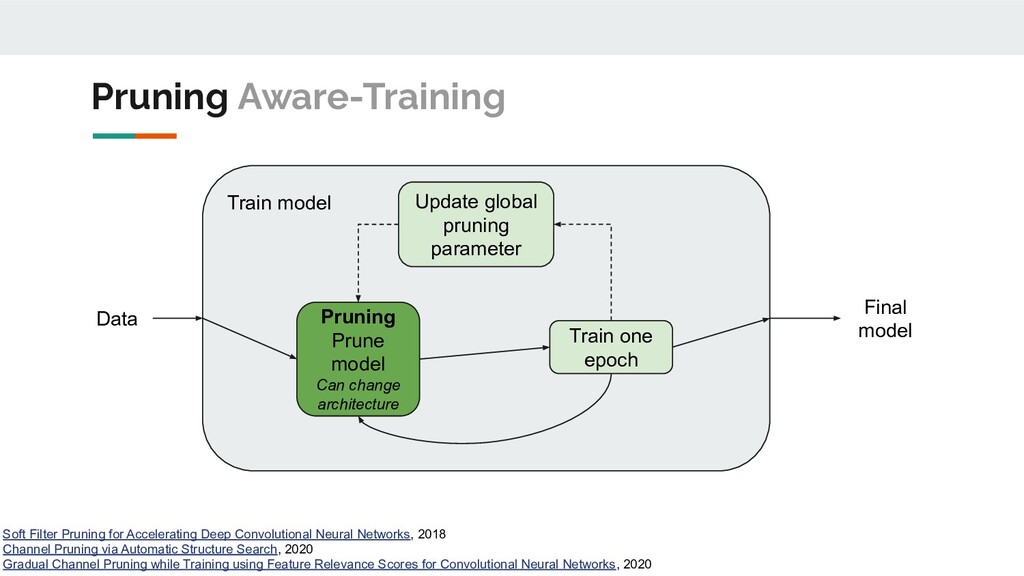
following characteristics: • Automation possibility: manual or fully automatic; • Fine tuning necessity: no fine-tuning, post-training, whole training process; • Structured or unstructured; • Global pruning or per-layer pruning (training and ranking); • Target scope: ◦ filter-level; ◦ block-level; ◦ model-specific; ◦ problem-specific; ◦ platform-specific. A lot of heuristics. Poor generalization ability. Good compression ⇎ Speed-up Pruning
Networks, 2018 Channel Pruning via Automatic Structure Search, 2020 Gradual Channel Pruning while Training using Feature Relevance Scores for Convolutional Neural Networks, 2020 Train model Final model Data Pruning Prune model Can change architecture Train one epoch Update global pruning parameter
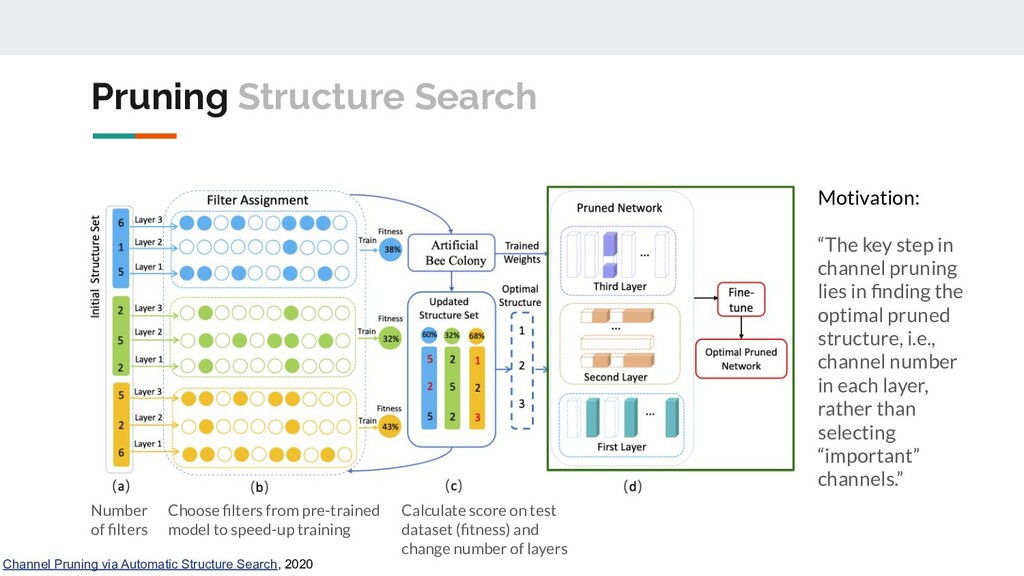
Motivation: “The key step in channel pruning lies in finding the optimal pruned structure, i.e., channel number in each layer, rather than selecting “important” channels.” Number of filters Choose filters from pre-trained model to speed-up training Calculate score on test dataset (fitness) and change number of layers
problem. • Fine-tuning is critically important (in img-to-img problems, for example). • Pruning speed-ups NN if it changes architecture parameters. • Pruning should be considered as effective method of NN architecture hyperparameters tuning. NAS in the space = neighbourhood of original model • The more variable the output space, the more variability the network should provide. Good quality in image classification ⇏ Good quality in image segmentation and etc.
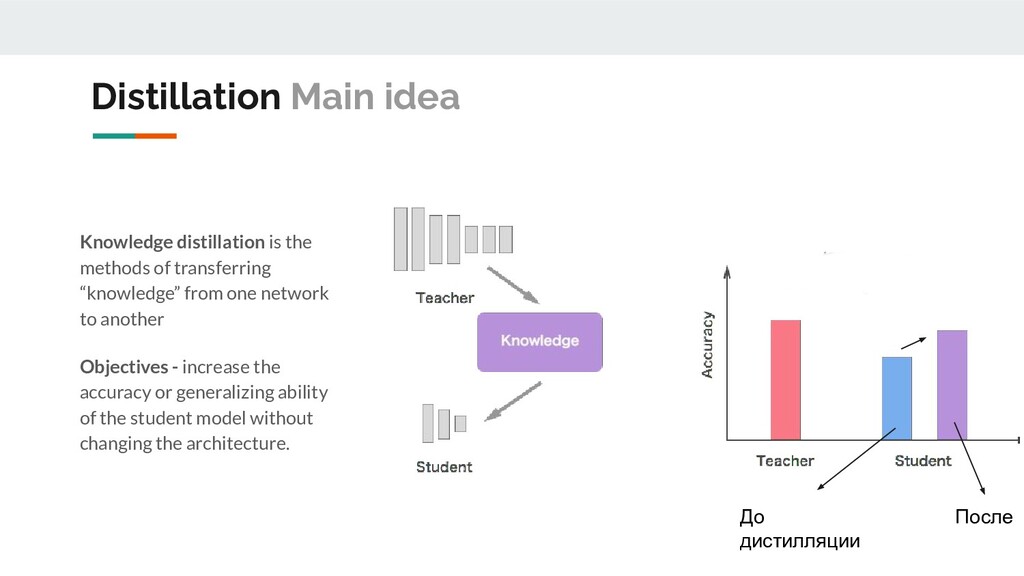
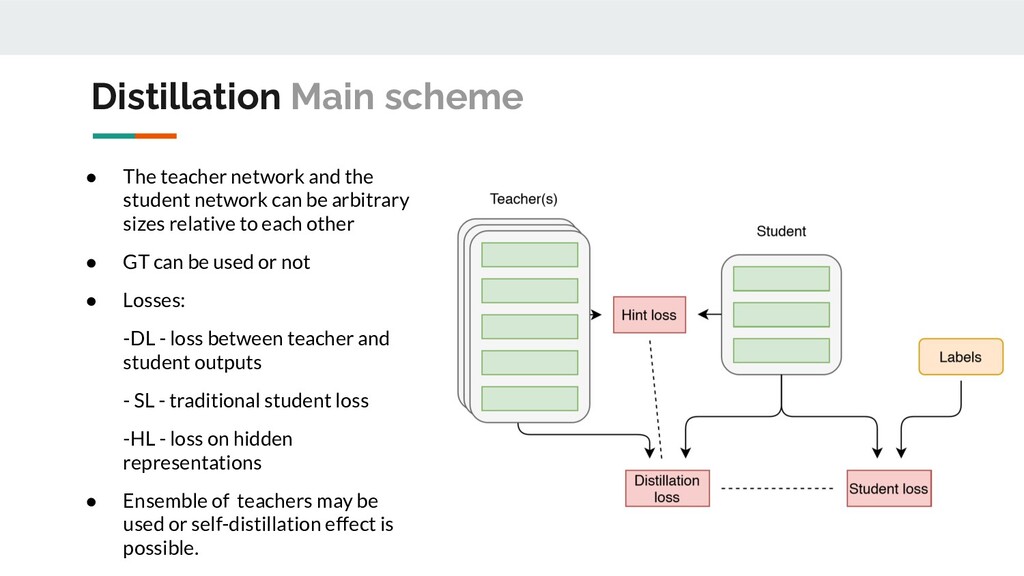
network to another Objectives - increase the accuracy or generalizing ability of the student model without changing the architecture. До дистилляции После Distillation Main idea
arbitrary sizes relative to each other • GT can be used or not • Losses: -DL - loss between teacher and student outputs - SL - traditional student loss -HL - loss on hidden representations • Ensemble of teachers may be used or self-distillation effect is possible. Distillation Main scheme
retraining networks in the absence of initial training data • It is used as an auxiliary operation in many tasks. • Accelerates student network convergence Distillation Outcomes
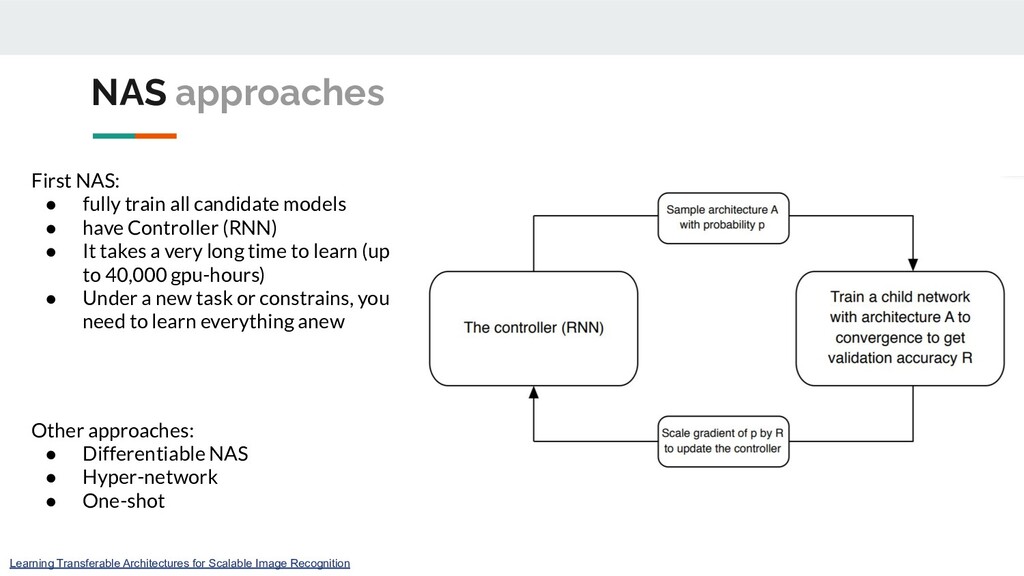
• have Controller (RNN) • It takes a very long time to learn (up to 40,000 gpu-hours) • Under a new task or constrains, you need to learn everything anew Other approaches: • Differentiable NAS • Hyper-network • One-shot Learning Transferable Architectures for Scalable Image Recognition
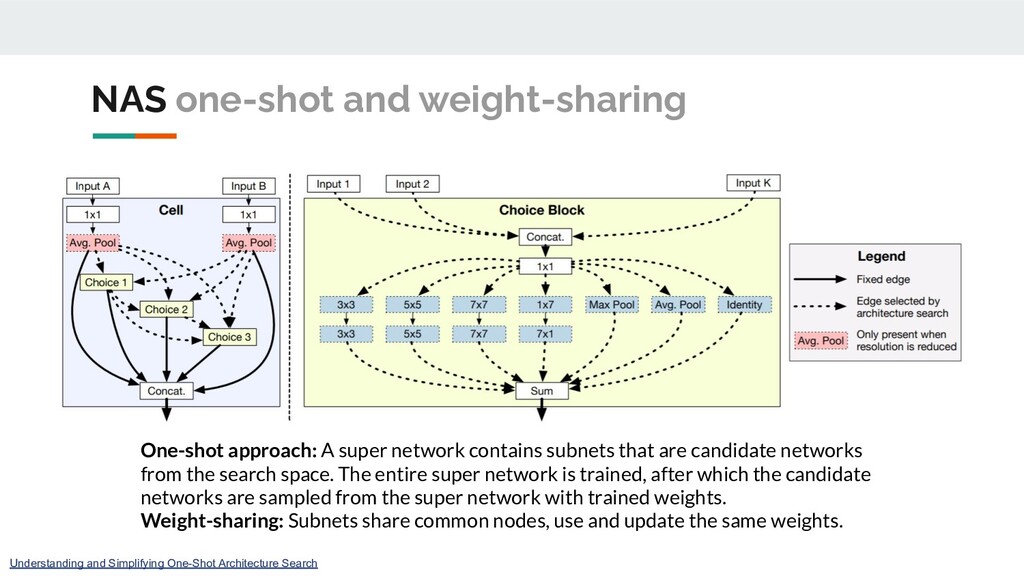
subnets that are candidate networks from the search space. The entire super network is trained, after which the candidate networks are sampled from the super network with trained weights. Weight-sharing: Subnets share common nodes, use and update the same weights. Understanding and Simplifying One-Shot Architecture Search
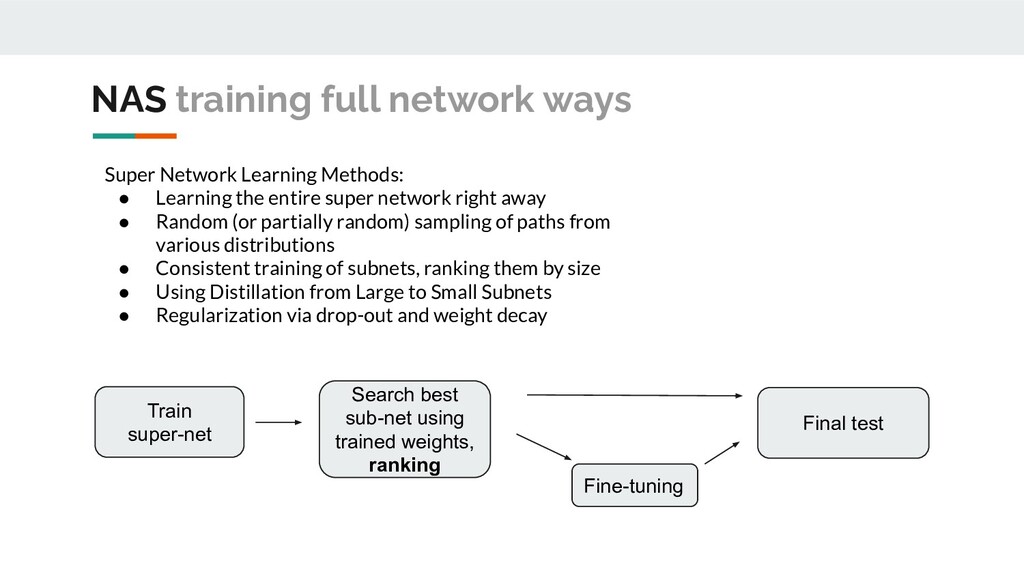
Learning the entire super network right away • Random (or partially random) sampling of paths from various distributions • Consistent training of subnets, ranking them by size • Using Distillation from Large to Small Subnets • Regularization via drop-out and weight decay Train super-net Search best sub-net using trained weights, ranking Fine-tuning Final test
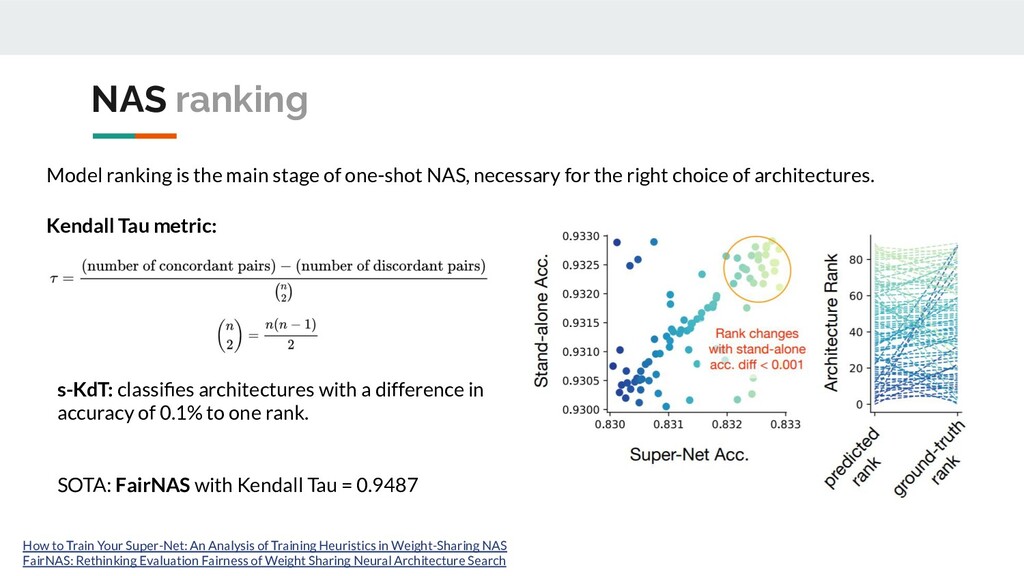
NAS, necessary for the right choice of architectures. How to Train Your Super-Net: An Analysis of Training Heuristics in Weight-Sharing NAS FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search SOTA: FairNAS with Kendall Tau = 0.9487 Kendall Tau metric: s-KdT: classifies architectures with a difference in accuracy of 0.1% to one rank.
not require fine-tuning or retraining • 40,000 gpu-hours → 4 - 200 gpu-hours • Allow you to evaluate many architectures and choose the best models according to existing restrictions and for specific tasks • One training - many ready-made models • Model ranking is an important step in one-shot NAS
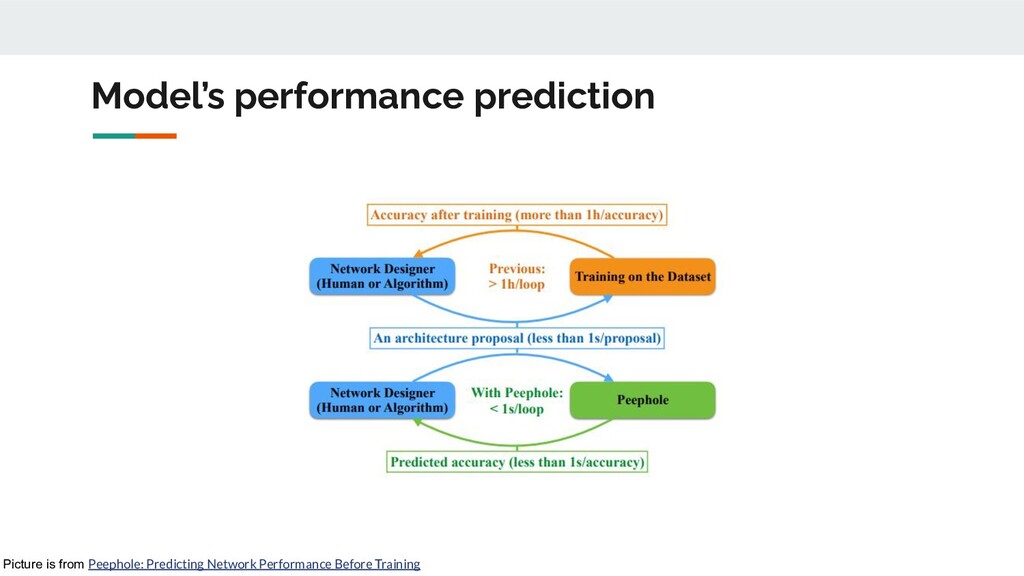
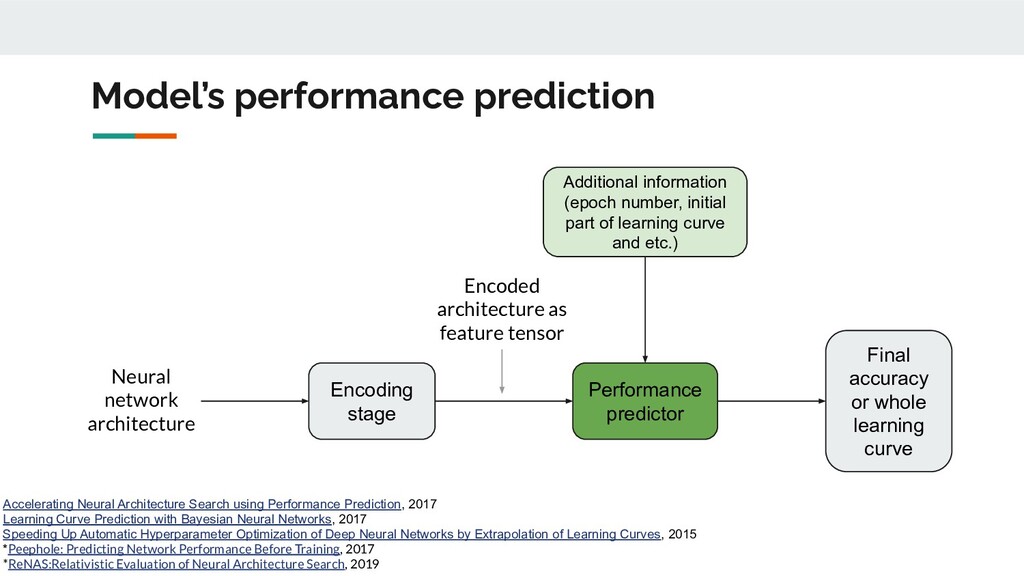
as feature tensor Performance predictor Final accuracy or whole learning curve Additional information (epoch number, initial part of learning curve and etc.) Accelerating Neural Architecture Search using Performance Prediction, 2017 Learning Curve Prediction with Bayesian Neural Networks, 2017 Speeding Up Automatic Hyperparameter Optimization of Deep Neural Networks by Extrapolation of Learning Curves, 2015 *Peephole: Predicting Network Performance Before Training, 2017 *ReNAS:Relativistic Evaluation of Neural Architecture Search, 2019
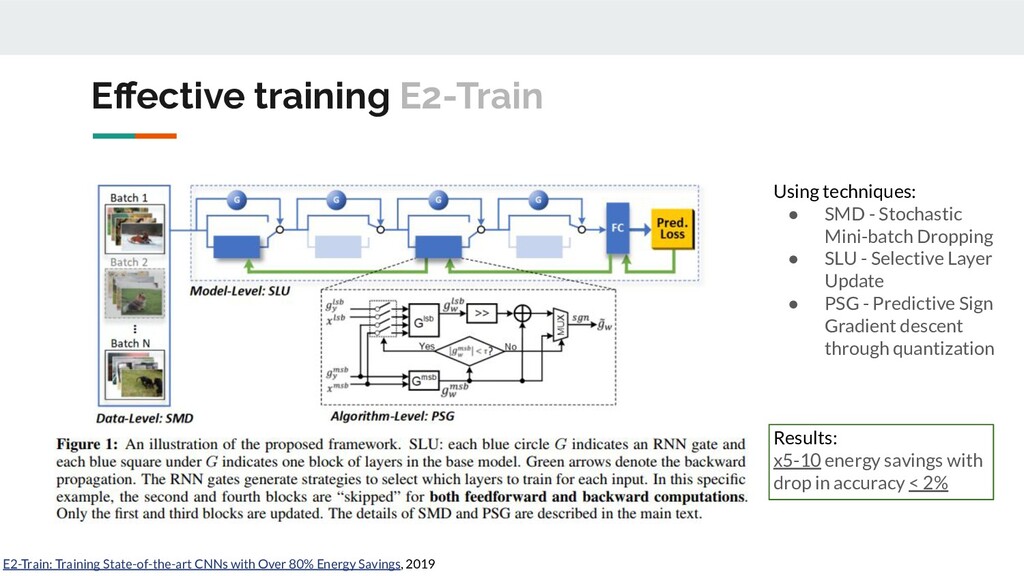
• different sampling strategies [2] ◦ drop-and-pick; ◦ samples importance estimation; ◦ batch formation procedures and etc.); • convergence boosting [3] ◦ gradient approximation (for example, using only gradient sign); ◦ removing gradients which are close to zero; ◦ different learning rate schedulers; ◦ modification of standard optimizers and etc; • modification of standard layers (BN, dropout and etc) [4]; • various training schemes (dynamically skip a subset of layers and etc.) [5]; • decomposition, pruning, quantization. Effective training [1] Data Proxy Generation for Fast and Efficient Neural Architecture Search, 2019 [2] Cheng et al.; Peng et al.; Zhang et al.; Weinstein et al.; Alsadi et al. [3] Ye et al.; Han et al.; Mostafa et al.; Dutta et al.; Wang et al.; Georgakopoulos et al.; Liu et al. [4] Collins et al.; Hiroshi Inoue; Yuan et al. [5] E2-Train: Training State-of-the-art CNNs with Over 80% Energy Savings, 2019
powerful method for specific hardware (low-bit processors) good choice for complex overparameterized models used both as a compression method and as an auxiliary method in various tasks another level of models tuning (problem-level) allow to significantly reduce the time resources needed for choosing a model can be potentially applied to any models and tasks without significant drop in final accuracy
Neural Networks, 2020 Bit Efficient Quantization for Deep Neural Networks, 2019 Data-Free Quantization Through Weight Equalization and Bias Correction, 2019 Gradient ℓ1 Regularization for Quantization Robustness, 2020 Kernel Quantization for Efficient Network Compression, 2020 *Learned Step Size Quantization, 2019 Linear Symmetric Quantization of Neural Networks for Low-precision Integer Hardware, 2020 *Loss Aware Post-training Quantization, 2020 Low-bit Quantization of Neural Networks for Efficient Inference, 2019 *LSQ+: Improving low-bit quantization through learnable offsets and better initialization, 2020 Post-training 4-bit quantization of convolution networks for rapid-deployment, 2019 Post-Training Piecewise Linear Quantization for Deep Neural Networks, 2020 *Quantization Networks, 2019 *Relaxed Quantization for Discretized Neural Networks, 2020 * indicates the most promising approaches for quantization in our opinion
*CUP: Cluster Pruning for Compressing Deep Neural Networks, 2019 Deep Network Pruning for Object Detection, 2019 Pruning Filters for Efficient ConvNets, 2017 What is the State of Neural Network Pruning?, 2020 Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks, 2018 ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression, 2017 Rethinking the Value of Network Pruning, 2019 *Gradual Channel Pruning while Training using Feature Relevance Scores for Convolutional Neural Networks, 2020 *Channel Pruning via Automatic Structure Search, 2020 Cluster Pruning: An Efficient Filter Pruning Method for Edge AI Vision Applications, 2020 * indicates the most promising approaches for pruning in our opinion
Heterogeneous Knowledge Among Peer-to-Peer Teammates: A Model Distillation Approach, 2020 *Knowledge Distillation for Incremental Learning in Semantic Segmentation, 2020 *Search to Distill: Pearls are Everywhere but not the Eyes , 2019 Similarity-Preserving Knowledge Distillation, 2019 Towards Understanding Knowledge Distillation, 2019 *Born-Again Neural Networks, 2018 Learning from Noisy Labels with Distillation, 2017 Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons, 2018 Learning Deep Representations with Probabilistic Knowledge Transfer , 2019 *The Deep Weight Prior , 2019 Correlation Congruence for Knowledge Distillation, 2019 * indicates the most promising approaches for knowledge distillation in our opinion
Single-Stage Models, 2020 *FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search, 2020 How to Train Your Super-Net: An Analysis of Training Heuristics in Weight-Sharing NAS, 2020 *MixPath: A Unified Approach for One-shot Neural Architecture Search, 2020 *Once-for-All: Train One Network and Specialize it for Efficient Deployment, 2020 *SCARLET-NAS: Bridging the Gap between Stability and Scalability in Weight-sharing Neural Architecture Search , 2020 Single Path One-Shot Neural Architecture Search with Uniform Sampling, 2019 Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours, 2019 Understanding and Simplifying One-Shot Architecture Search, 2018 SMASH: One-Shot Model Architecture Search through HyperNetworks, 2017 ReNAS: Relativistic Evaluation of Neural Architecture Search , 2019 PROXYLESSNAS: Direct Neural Architecture Search on Target Task and Hardware, 2019 One-Shot Neural Architecture Search via Self-Evaluated Template Network, 2019 NAS-Bench-101: Towards Reproducible Neural Architecture Search, 2019 Efficient Neural Architecture Search via Parameter Sharing, 2018 Data Proxy Generation for Fast and Efficient Neural Architecture Search, 2019 DARTS: Differentiable Architecture Search, 2019 Learning Transferable Architectures for Scalable Image Recognition, 2018 * indicates the most promising approaches in our opinion
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Methods comprises the following techniques: • proxy datasets creation [1];](https://files.speakerdeck.com/presentations/a78d91a6490e4efe872682e3720f0246/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
![Thank you for your attention Ilia Zharikov e-mail: [email protected] ods](https://files.speakerdeck.com/presentations/a78d91a6490e4efe872682e3720f0246/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}