Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OpenTalks.AI - Дмитрий Пагин, Ускорение сверточ...
Search
opentalks2
February 04, 2021
Business
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OpenTalks.AI - Дмитрий Пагин, Ускорение сверточных сетей с помощью квантизации. Quantization aware training.
opentalks2
February 04, 2021
More Decks by opentalks2
See All by opentalks2
OpenTalks.AI - Сергей Терехов, Тензорная машина ассоциативного вывода
opentalks2
0
410
OpenTalks.AI - Максим Милков, Оптимизация бизнес-процессов и документооборота с использованием NLP технологий Бизнес-кейс: Цифровой аудитор
opentalks2
0
430
OpenTalks.AI - Анна Серебряникова, Влияние технологий ИИ на развитие машиночитаемого документооборота в России
opentalks2
0
350
OpenTalks.AI - Илья Жариков, Optimization of neural networks and their development
opentalks2
0
420
OpenTalks.AI - Никита Андриянов, Анализ эффективности распознавания образов на нестандартных типах изображений на примере радиолокационных изображений местности и рентгеновских снимков багажа и ручной клади
opentalks2
0
360
OpenTalks.AI - Сергей Алямкин, AutoDL или как сократить затраты на разработку и использование в проде нейронных сетей
opentalks2
0
500
Никитин.pdf
opentalks2
0
350
OpenTalks.AI - Александр Петюшко, Исследование устойчивости сверточных нейросетей на примере систем детекции и распознавания лиц
opentalks2
0
470
OpenTalks.AI - Сергей Лукашкин, Как ИИ повлиял на бизнес в 2020 году
opentalks2
0
390
Other Decks in Business
See All in Business
SalesforceとTableauコミュニティを横断して感じたこと(Osaka Dreamin)
leafyoh
0
100
エムスリーキャリア Work Support採用資料 / M3C Work Support
m3c
0
14k
Algomatic | 会社紹介資料
algomatic
PRO
2
150k
AIネイティブな組織を問い直す
smiyawaki0820
12
4.8k
川下り型キャリア感できのこってきた 35歳子育て世帯の葛藤
ikasumiwt
0
260
プロシェアリング白書2026_PROSHARING_REPORT_2026
circulation
0
190
AWS Summit Taipei 2026: Decomposing Ontology and Agentic AI - Using Amazon Bedrock to Bring Living Water to Manufacturing ERP
dwchiang
0
200
株式会社アフェクター会社説明資料(中途/技術職向け)
affectorsaiyo
0
320
株式会社Lightblue CompanyDeck
shun1taniguchi
0
1.4k
マルチプロダクト時代のPMM-Discoveryから0→1、Expansionまで フェーズで変わる期待役割とアサインの設計図
sasaguchi
0
340
[OptQC]Company_introduction_JP
optqc_recruit
0
160
株式会社ユビレジ_採用ピッチ資料 / Ubiregi_CompanyProfile
ubiregi_saiyo
1
11k
Featured
See All Featured
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Statistics for Hackers
jakevdp
799
230k
Building Adaptive Systems
keathley
44
3.1k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
830
ラッコキーワード サービス紹介資料
rakko
1
3.9M
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Transcript
Ускорение сверточных сетей с помощью квантизации. Quantization aware training. Dmitriy
Pagin, ML and CV developer
Задача
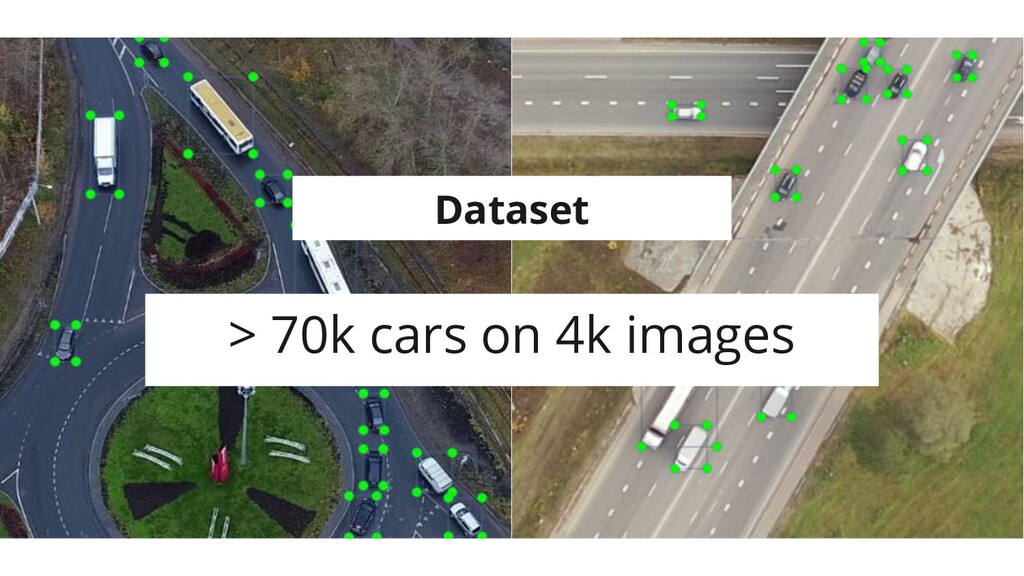
Задача • Детектировать и трекать автомобили с камер и дронов
Условия • Облачная обработка с клиентского приложения • Видеокарты среднего
сегмента - RTX 2060/2080 • Требуется минимум 30 fps скорости обработки
Сложности • Высокая скорость • Маленькие размеры (~10px)
> 70k cars on 4k images Dataset
Baseline 10 fps из коробки на FullHD фреймах
10 fps -> 12 fps -> 40 fps -> ???
OpenTalksAI 2020 pruning физичность данных
Как сделать быстрее?
Методы • Quantization • Quantization aware training
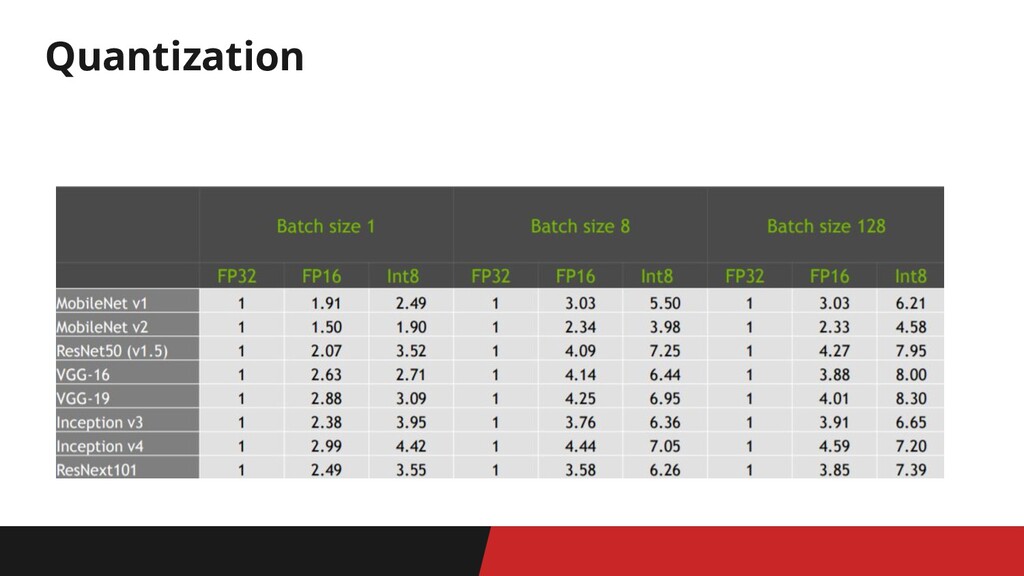
Quantization
Quantization Quantization - приведение весов и вычислений к типам меньшей
точности с целью ускорения инференса и уменьшения размера сети
Quantization
Quantization По умолчанию - float32 • float16 - округление •
int8 - округление + нормирование (256! значений) • int4 … • binary ...
Quantization
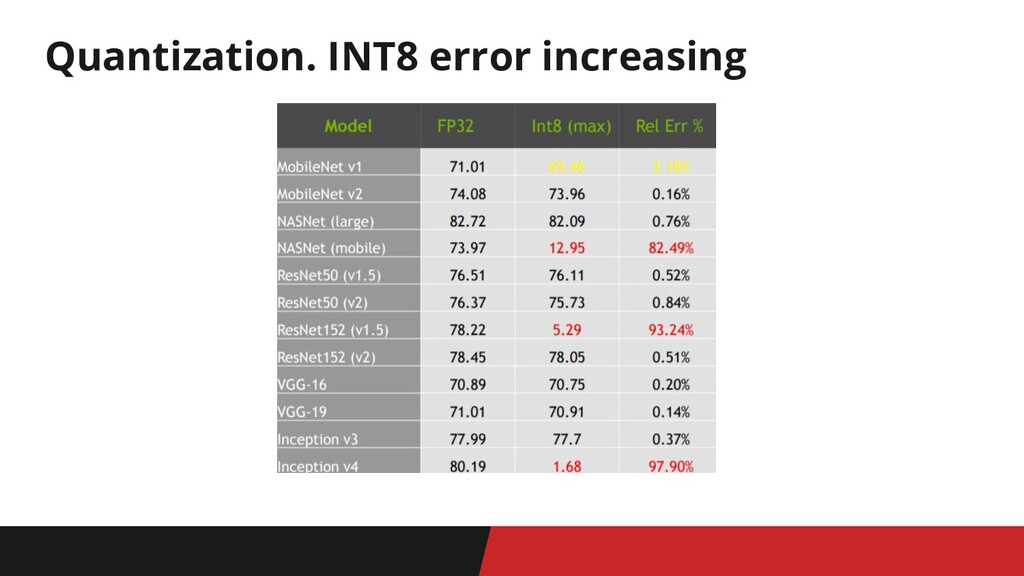
Quantization. INT8 error increasing
Мы поверили • low-precision инференс в float16 даёт бесплатное(?) 2-кратное
ускорение • low-precision инференс в int8 может ускорить до 4 раз, но часто ведет к западению метрик
FPS: +100% (40 fps -> 80 fps) mAP75: -1.2% (0.95
-> 0.938) Мы попробовали
Мы попробовали Сложный ролик с тенями Добор датасета Дообучение Тест
и замена модели
float32 float16 Мы попробовали
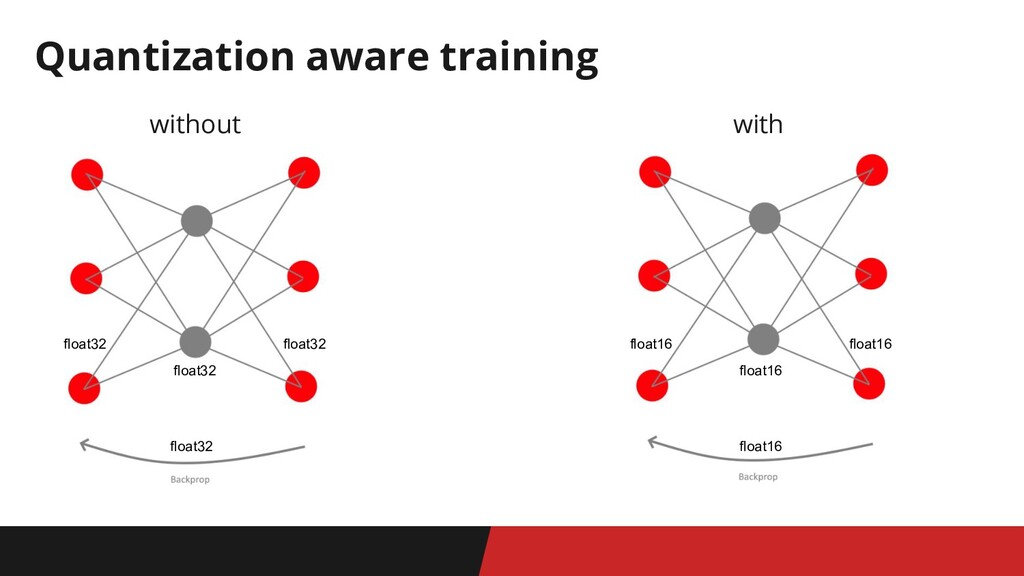
Quantization Aware Training
float32 float16 Потеря “нежных” фич: • тени • ночные ролики
• авто с прицепами Quantization aware training. Зачем?
float32 float16 Ухудшение для маленьких объектов: S (дисперсия координат для
объектов < 100px в ширину) = 5.1 px Quantization aware training. Зачем?
without Quantization aware training with float32 float32 float32 float32 float16
float16 float16 float16
Quantization aware training benefits • гарантированное сохранение метрик при TensorRT
float16 inference • 2x уменьшение размера модели • “gradient clipping” регуляризация -> лучшее обобщение
Quantization aware training Сложный ролик с тенями Добор датасета Quantization
aware дообучение Тест и замена модели
float32 float16 Quantization aware training
FPS: +100% (40 fps -> 80 fps) mAP75: -0.2% (0.95
-> 0.948)
Итоги • TensorRT low-precision must have -> 2x ускорение •
TensorRT low-precision лучше использовать после quantization aware training
10 fps -> 12 fps -> 40 fps -> 80
fps OpenTalksAI 2020 pruning физичность данных quantization
None
Thanks! Questions?
[email protected]
+7 952 335 65 70
Appendix. Examples
Appendix. Examples
Appendix. Examples
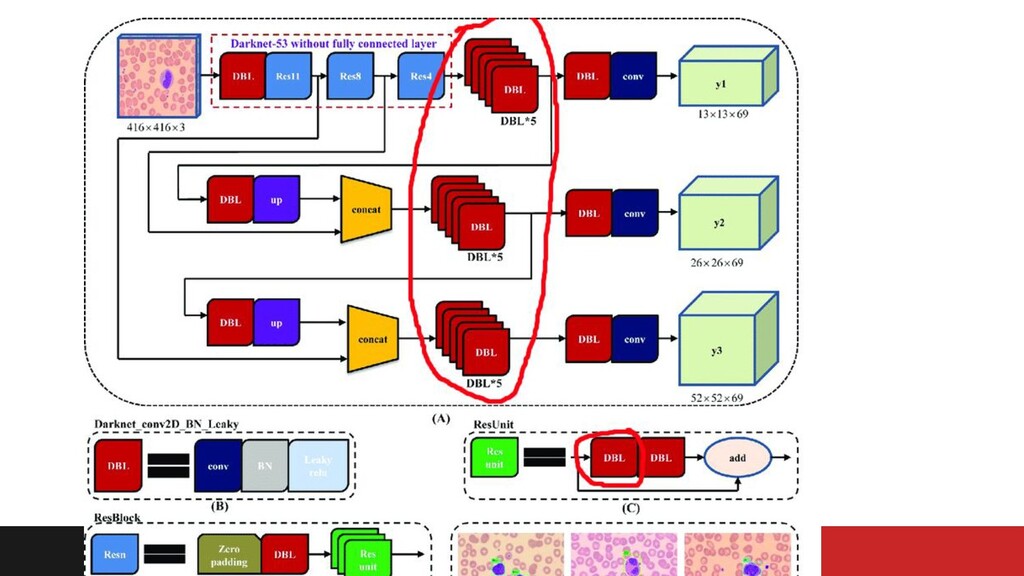
Learning and Fine-tuning - 608x608 px - batchSize = 3
- custom augmenters - Radam optimizer (instead warmup + reduce LR) - Hard negative mining for trucks
None
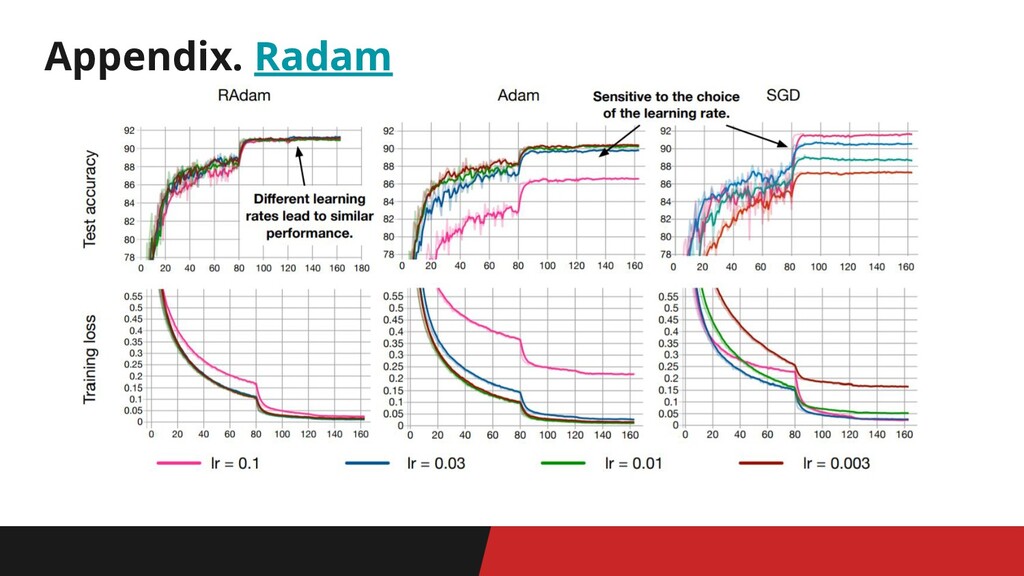
Appendix. Radam
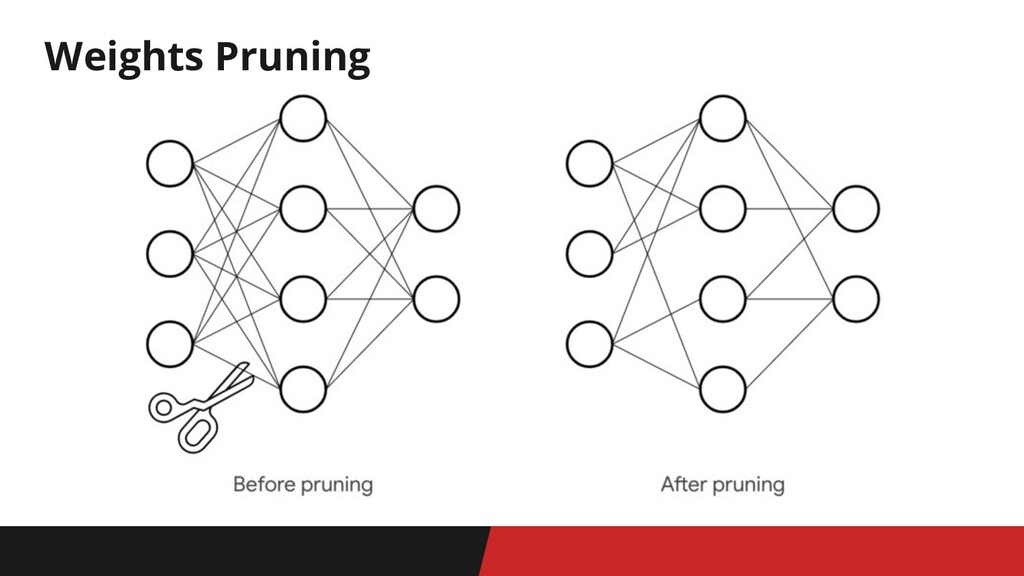
Weights Pruning Pruning - уменьшение размера обученной сети без потери
точности путем удаления слабых узлов
Weights Pruning
Weights Pruning
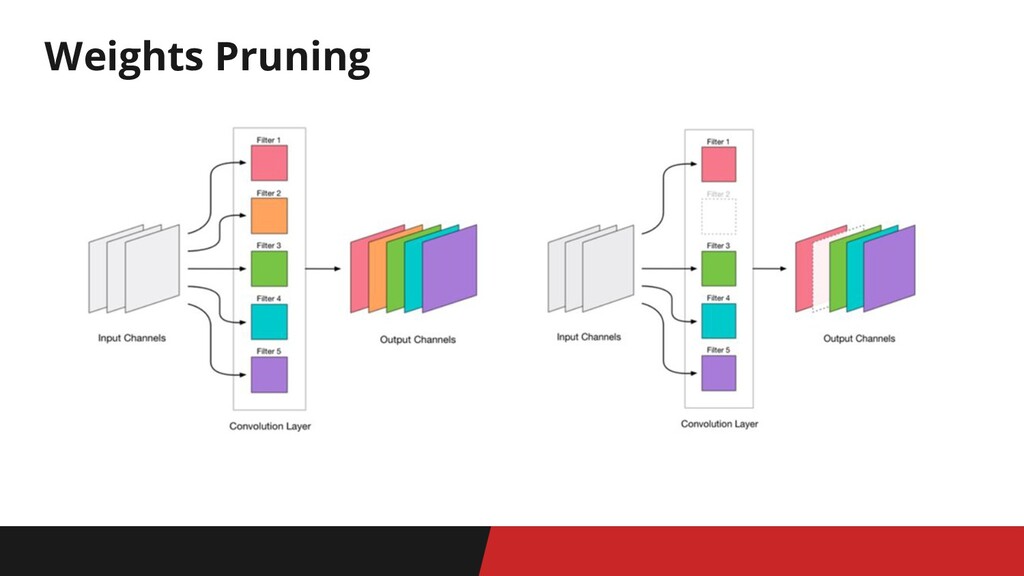
Weights Pruning. Convs masking 1. Маскируем i-ую свертку 2. Прогоняем
тестовый датасет и запоминаем метрику 3. Повторяем шаг 1 для всех сверток end: удаляем свертки, которые слабо влияют на итоговую метрику для средних и больших моделей ДОЛГО
Weights Pruning. Low magnitude Гипотеза - свертки с малыми значениями
весов, вносят малый вклад в итоговое принятие решения 5 -3 1 1 1 2 3 1 -4 0 1 -1 1 1 0 0 1 -1
Weights Pruning. Low magnitude Гипотеза - свертки с малыми значениями
весов, вносят малый вклад в итоговое принятие решения 5 -3 1 1 1 2 3 1 -4 0 1 -1 1 1 0 0 1 -1
Weights Pruning. Цикл
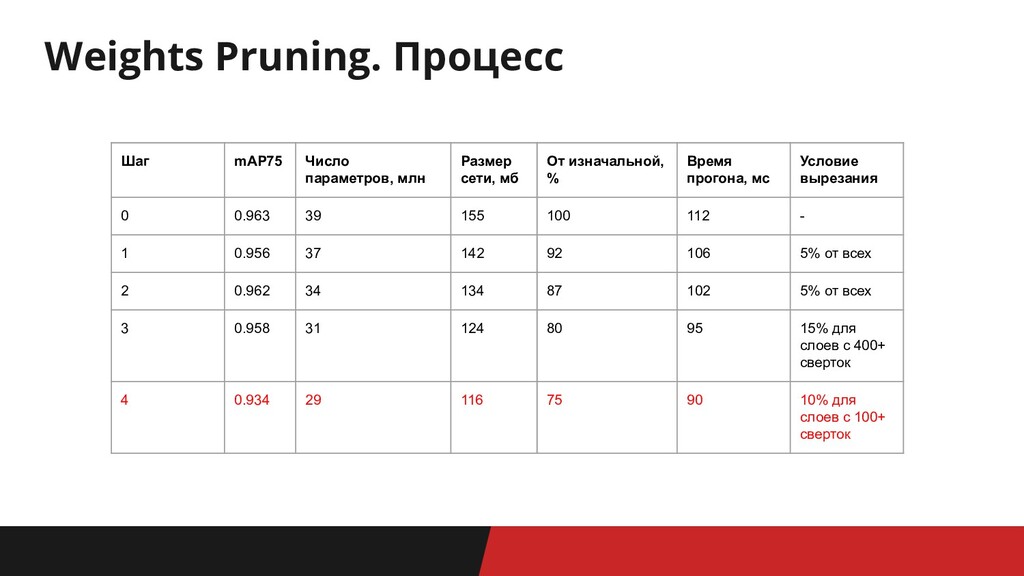
Weights Pruning. Процесс Шаг mAP75 Число параметров, млн Размер сети,
мб От изначальной, % Время прогона, мс Условие вырезания 0 0.963 39 155 100 112 - 1 0.956 37 142 92 106 5% от всех 2 0.962 34 134 87 102 5% от всех 3 0.958 31 124 80 95 15% для слоев с 400+ сверток 4 0.934 29 116 75 90 10% для слоев с 100+ сверток
Weights Pruning -25% convs = size: 155 mb mAp: 0.963
inf: 112 ms size: 124 mb mAp: 0.958 inf: 90 ms Inference: +15% mAP75: -0,5%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Questions? [email protected] +7 952 335 65 70](https://files.speakerdeck.com/presentations/e467bc6303ab4c0198ce7918d86c4ed9/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}