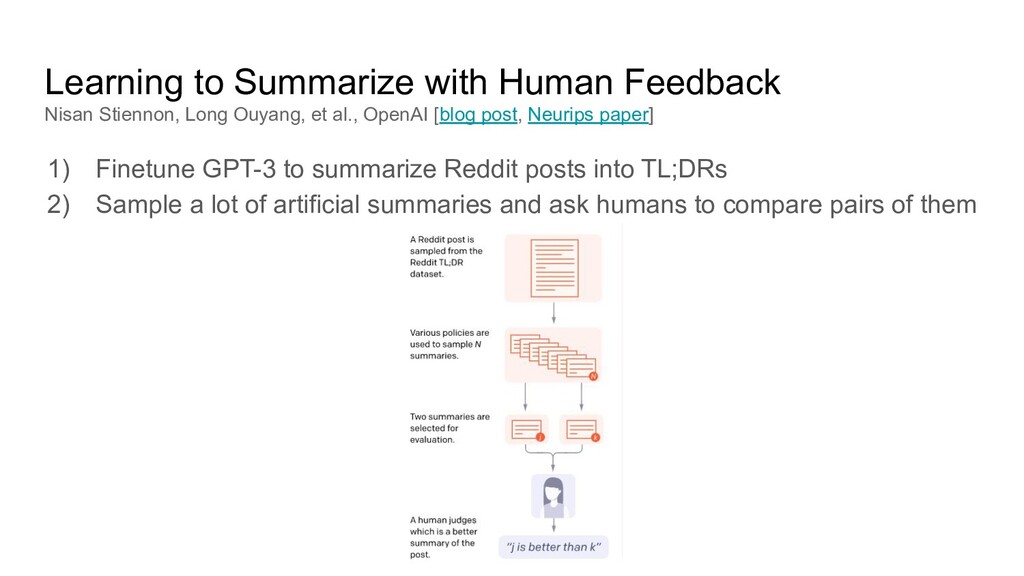
et al., OpenAI [blog post, Neurips paper] 1) Finetune GPT-3 to summarize Reddit posts into TL;DRs 2) Sample a lot of artificial summaries and ask humans to compare pairs of them
summarize Reddit posts into TL;DRs 2) Sample a lot of artificial summaries and ask humans to compare pairs of them 3) Train a neural net (reward model) to predict human labels
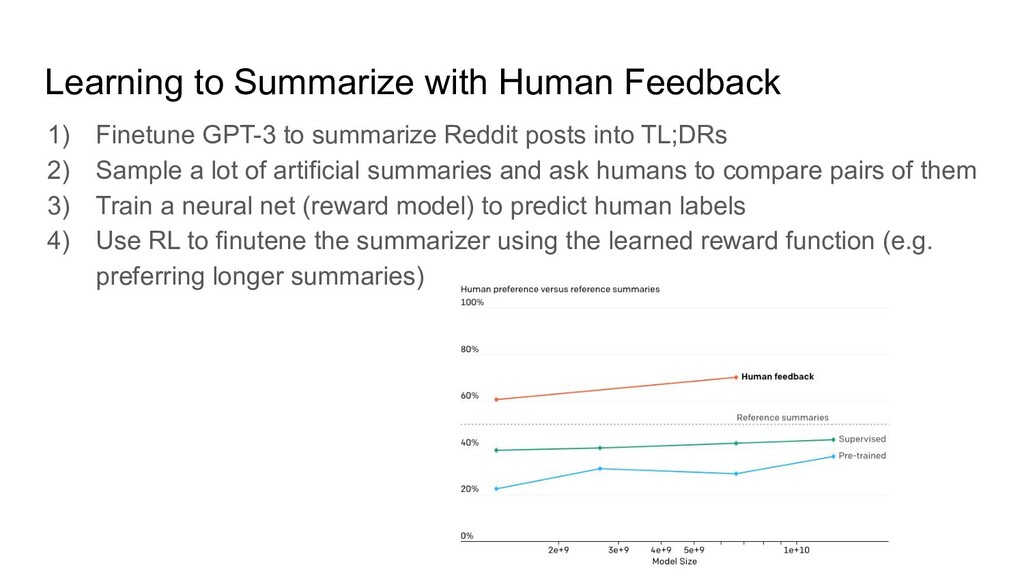
summarize Reddit posts into TL;DRs 2) Sample a lot of artificial summaries and ask humans to compare pairs of them 3) Train a neural net (reward model) to predict human labels 4) Use RL to finutene the summarizer using the learned reward function (e.g. preferring longer summaries)
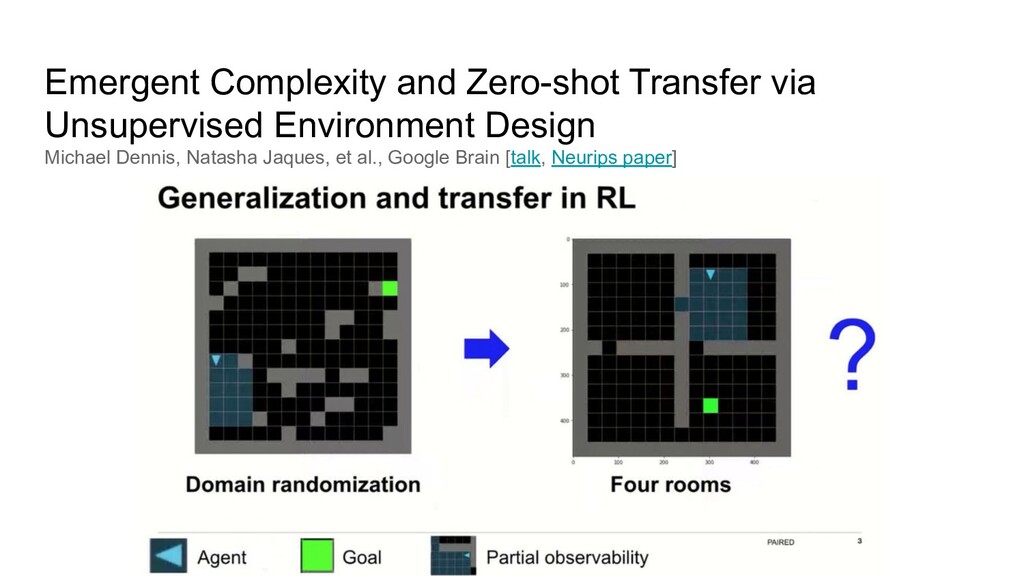
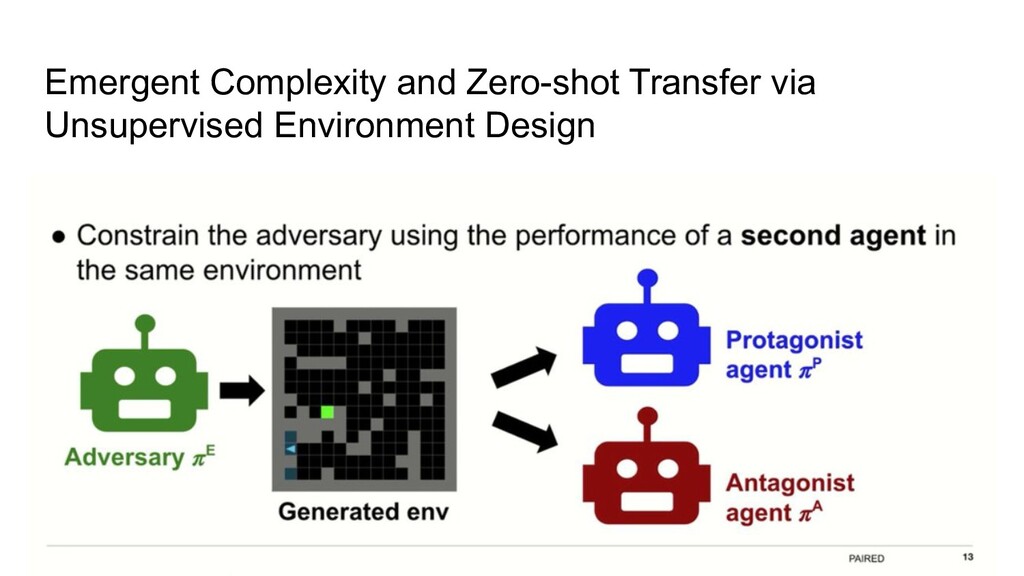
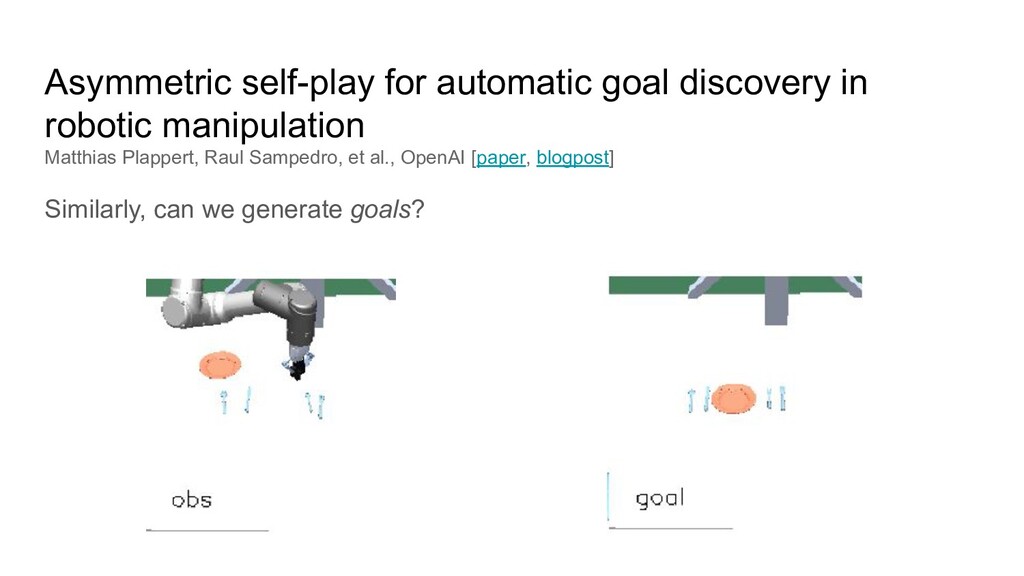
can we generate goals? Alice end-state = goal for Bob Bob’s reward to reach the same state (preferably faster than Alice) Alice reward is to make Bob fail
can we generate goals? Alice end-state = goal for Bob Bob’s reward to reach the same state (preferably faster than Alice) Alice reward is to make Bob fail Additionally, Bob can cheat and look into how Alice did it
Pablo Sprechmann, et al., DeepMind [ICLR paper] How exploration usually works 1. A separate network tells you how novel your current state it. 2. Add “novelty” to your reward: 3. Push beta to 0 with time to start exploiting.
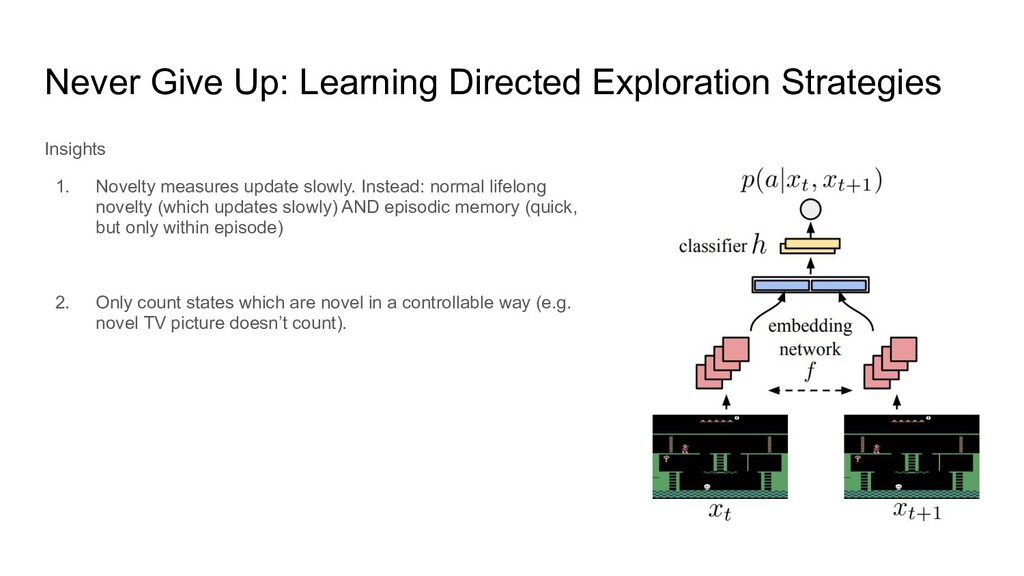
measures update slowly. Instead: normal lifelong novelty (which updates slowly) AND episodic memory (quick, but only within episode) 2. Only count states which are novel in a controllable way (e.g. novel TV picture doesn’t count). 3. Don’t stop exploring when you get better. Instead, have separate exploration and exploitation policies and run all in parallel.
measures update slowly. Instead: normal lifelong novelty (which updates slowly) AND episodic memory (quick, but only within episode) 2. Only count states which are novel in a controllable way (e.g. novel TV picture doesn’t count). 3. Don’t stop exploring when you get better. Instead, have separate exploration and exploitation policies and run all in parallel.
measures update slowly. Instead: normal lifelong novelty (which updates slowly) AND episodic memory (quick, but only within episode) 2. Only count states which are novel in a controllable way (e.g. novel TV picture doesn’t count). 3. Don’t stop exploring when you get better. Instead, have separate exploration and exploitation policies and run all in parallel.
DeepMind [Neurips paper] Use RL to discover an RL algorithm (e.g. something like PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true
DeepMind [Neurips paper] Use RL to discover an RL algorithm (e.g. something like PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory
PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory b. Update , where Discovering Reinforcement Learning Algorithms Junhyuk Oh, Matteo Hessel, et al., DeepMind [Neurips paper] Discounted return (“how good did the episode end”)
PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory b. Update , where Discovering Reinforcement Learning Algorithms Junhyuk Oh, Matteo Hessel, et al., DeepMind [Neurips paper] future is bad it’s obvious that the future will be bad don’t encourage / penalize taken action [image source] crashed
PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory b. Update , where Discovering Reinforcement Learning Algorithms Junhyuk Oh, Matteo Hessel, et al., DeepMind [Neurips paper] not crashed future is ok it’s obvious that the future will be bad the action avoided forecasted crash, awesome
DeepMind [Neurips paper] Use RL to discover an RL algorithm (e.g. something like PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory b. Update , where c. Update by doing a gradient step on , where
algorithm (e.g. something like PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory b. Update , where c. Update by doing a gradient step on , where Keep Learn
algorithm (e.g. something like PPO) automatically Recap of a simple RL algorithm 1. Initialize parameters of policy and of value function 2. While true a. Run policy in the episode and collect a trajectory b. Update , where c. Update by doing a gradient step on , where Keep Learn and
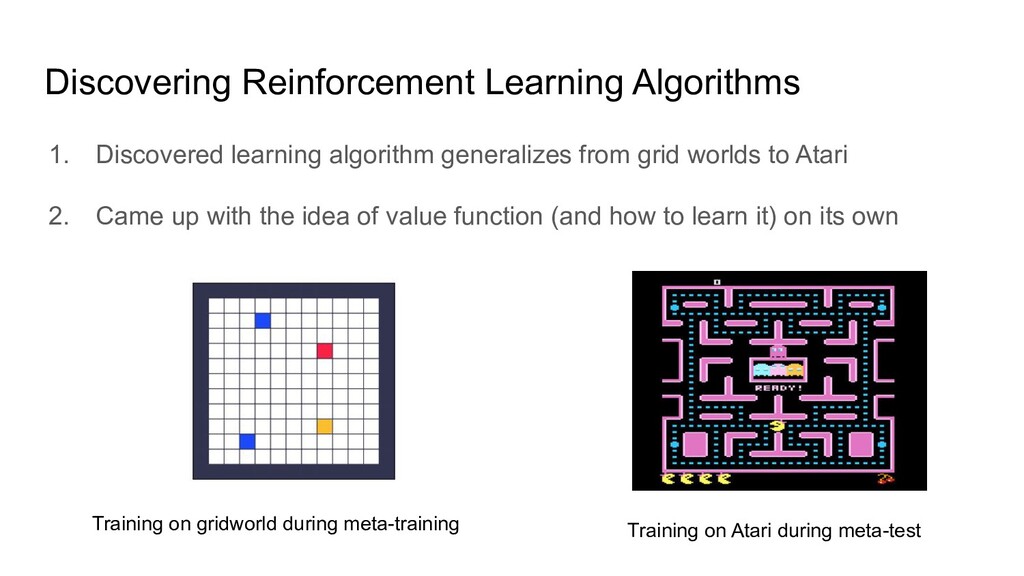
grid worlds to Atari 2. Came up with the idea of value function (and how to learn it) on its own Training on gridworld during meta-training Training on Atari during meta-test
drive cars or control datacenter cooling systems? The old recipe is too dangerous and slow: 1) Try random stuff (“drive randomly”) 2) Reinforce the stuff that worked better (“try to not repeat actions that led to crashes”)
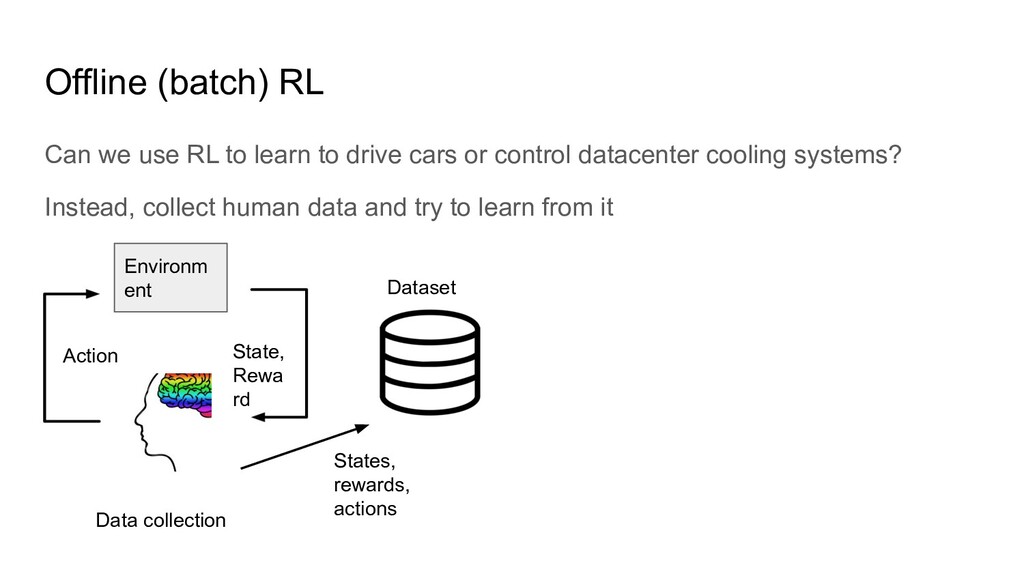
drive cars or control datacenter cooling systems? Instead, collect human data and try to learn from it Environm ent State, Rewa rd Action Dataset Data collection States, rewards, actions
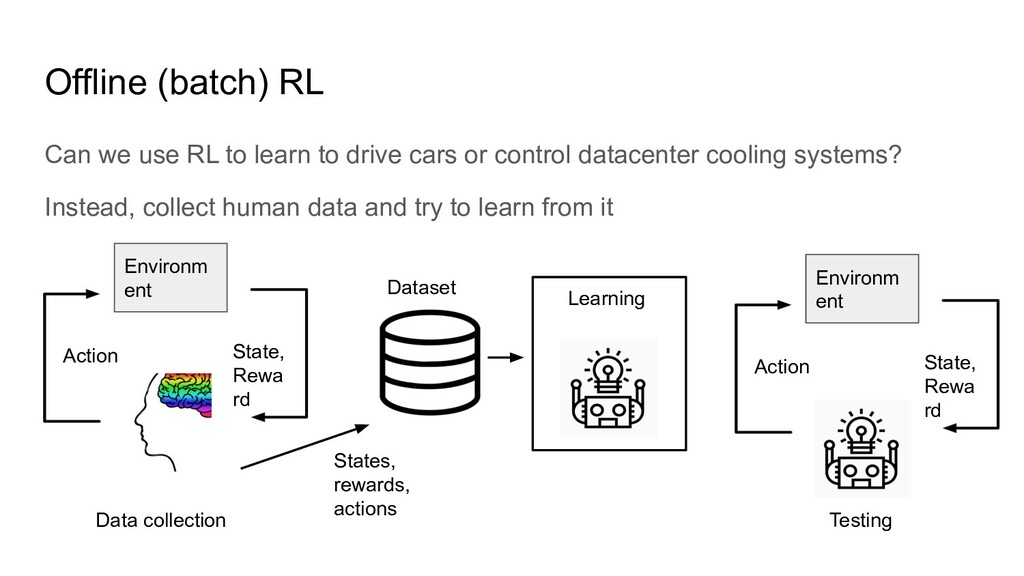
drive cars or control datacenter cooling systems? Instead, collect human data and try to learn from it Environm ent State, Rewa rd Action Dataset Data collection States, rewards, actions Learning
drive cars or control datacenter cooling systems? Instead, collect human data and try to learn from it Environm ent State, Rewa rd Action Environm ent State, Rewa rd Action Dataset Data collection States, rewards, actions Learning Testing
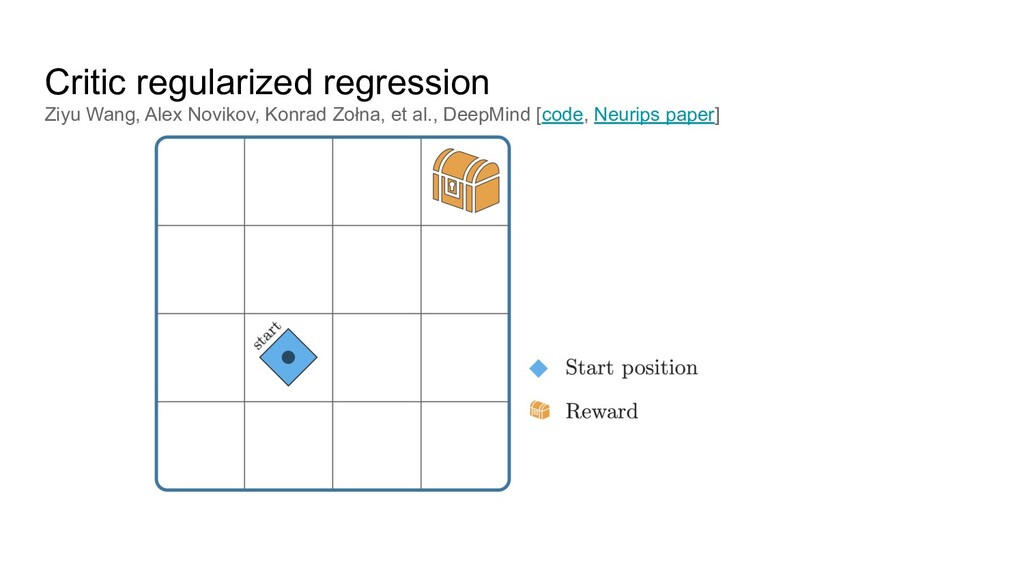
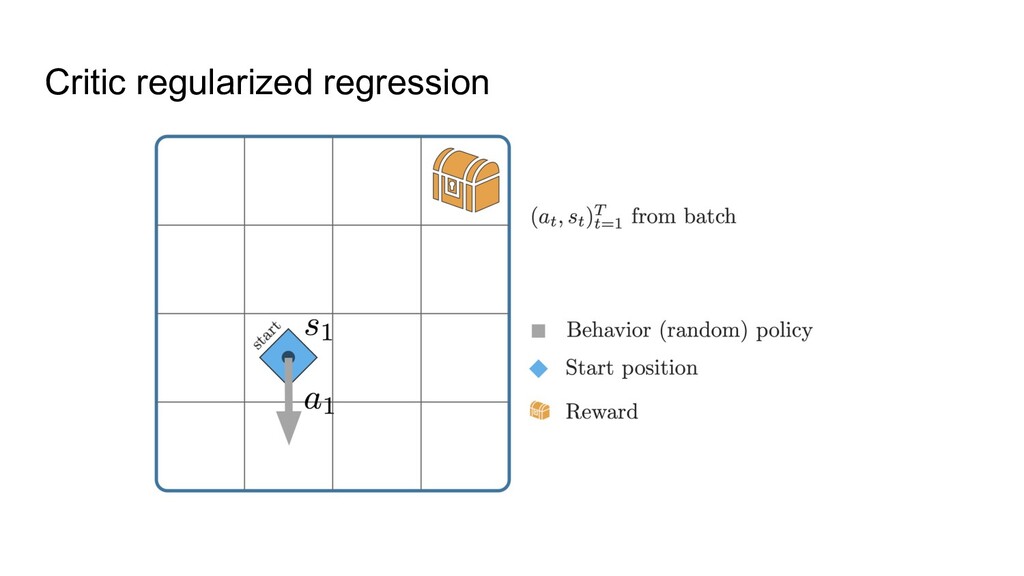
(safer; no need for collecting billions of frames) 2. (But of course there is no need to apply offline RL to e.g. Atari) 3. Cheaper research (no need for 10k CPUs per run, since data is prerecorded) 4. Existing datasets and code examples to get started 5. Some unique challenges compared to classic RL 6. More low hanging fruits :)
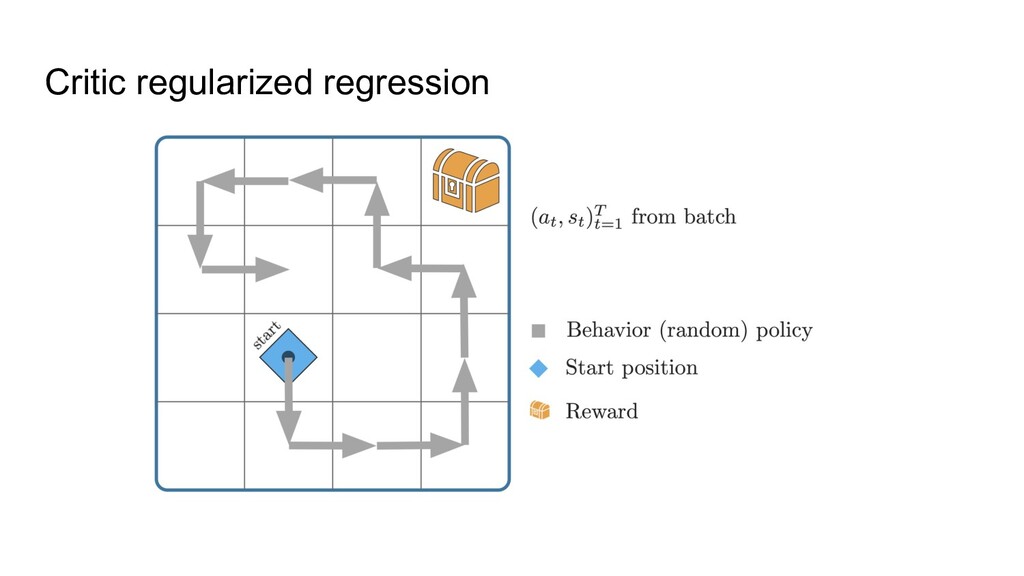
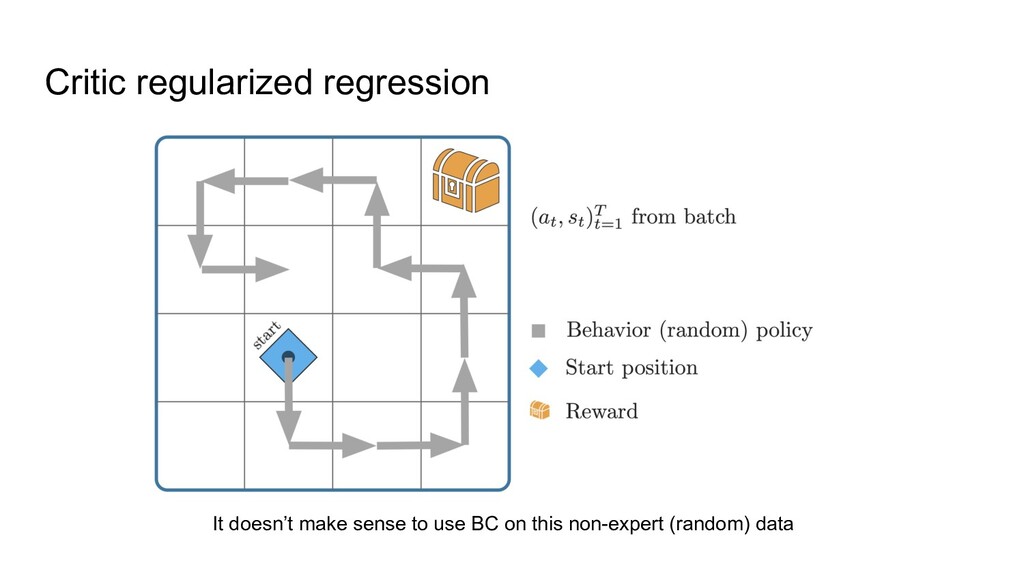
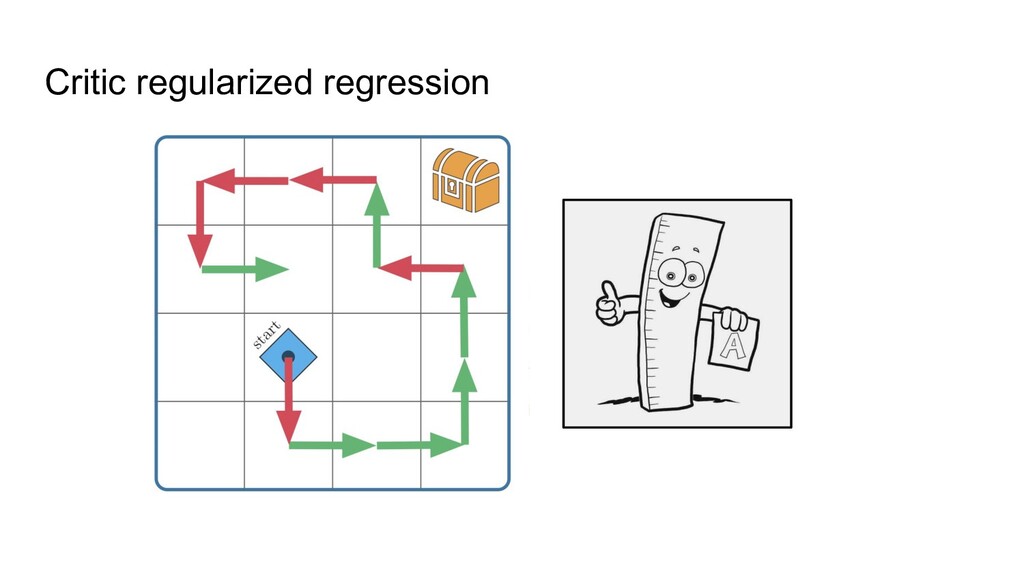
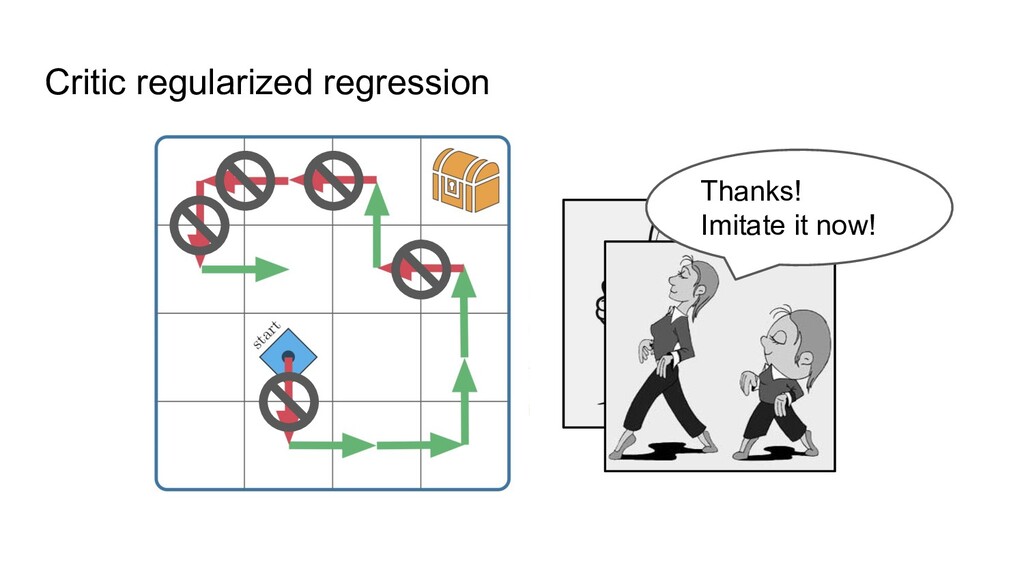
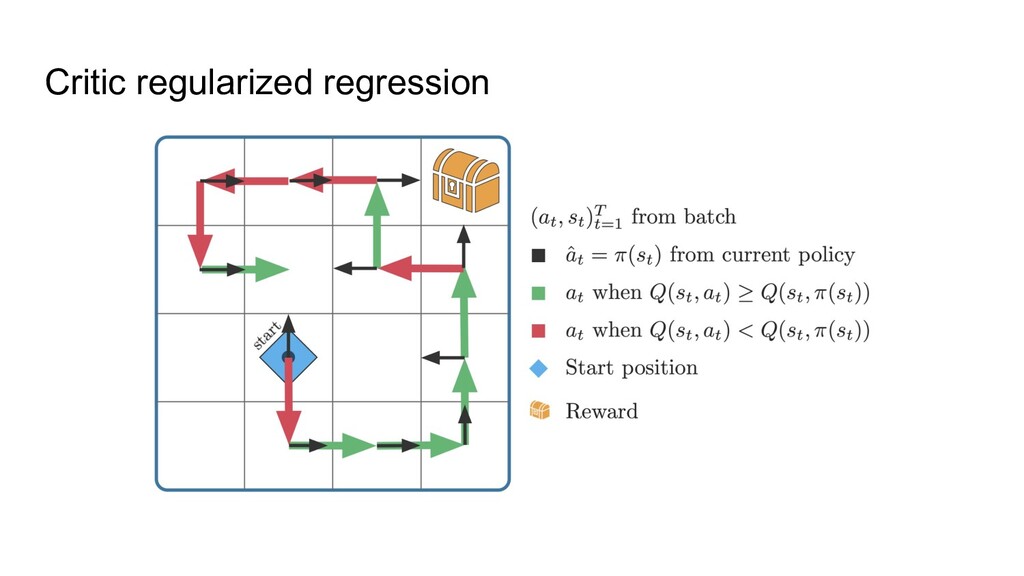
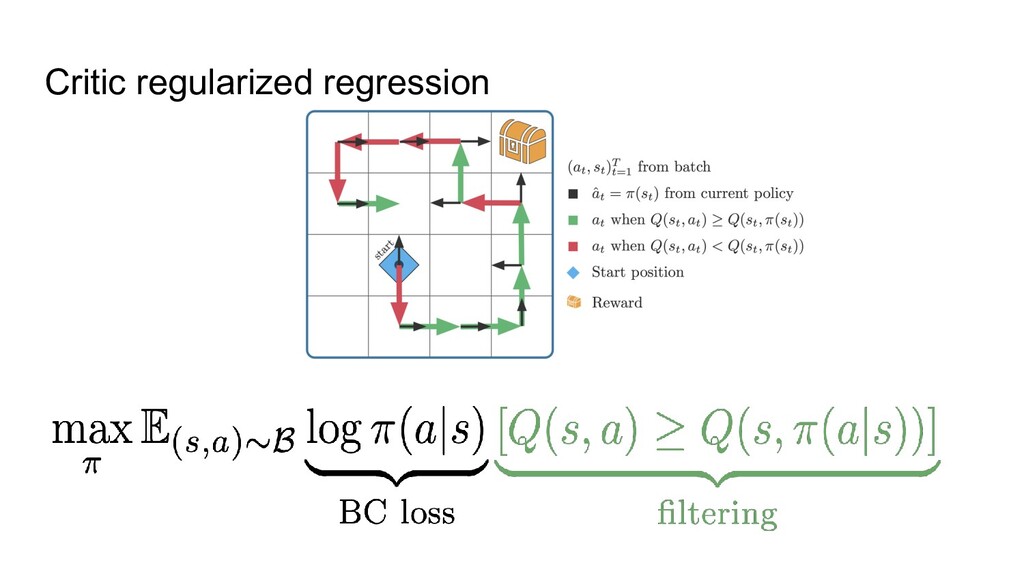
train a neural net to predict actions from states via supervised learning ◦ Only works when all data is of high quality, i.e. BC can’t do better than the data. 2. Just apply classic RL -- will that work? ◦ Not well, because of overestimating some actions: classic RL can randomly think that something not presented in the data (“drive into wall”) is worth a try. Most offline RL methods are thus focusing on avoiding the overestimation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}