Batura, Vladimir Ivanov, Veronika Sarkisyan, Elena Tutubalina, and Ivan Smurov ABBYY, Russia Moscow Institute of Physics and Technology, Russia National Research University Higher School of Economics, Russia Novosibirsk State University, Russia Innopolis University, Russia Kazan Federal University, Russia Lomonosov Moscow State University RuREBus-2020 Shared Task:
well researched NLP tasks • Scores obtained on standard academic corpora (such as CoNLL-03 and SemEval-2010 task 8) by SOTA systems are high and in many cases are close to human performance • Given these considerations some representatives of academia claim that NER and RE are essentially “solved tasks” • NER and RE are widely used by business, but the performance is typically much lower than reported on academic corpora • One can assume that the reason for this is that academic corpora have some major differences from industrial and thus it is reasonable to create a business-oriented corpus and test modern methods on it. Our motivation 2
and industrial corpora: • Academic baselines typically consist of well-written news or biography texts • Business case texts are usually domain-specific(e. g. legal) texts that can contain less than perfect language or other irregularities. • Entities in academia are usually compact and well-defined • Entities in industry are often much more loose, spanning for many words and with less than clear borders. Academic corpora v. s. industrial 3
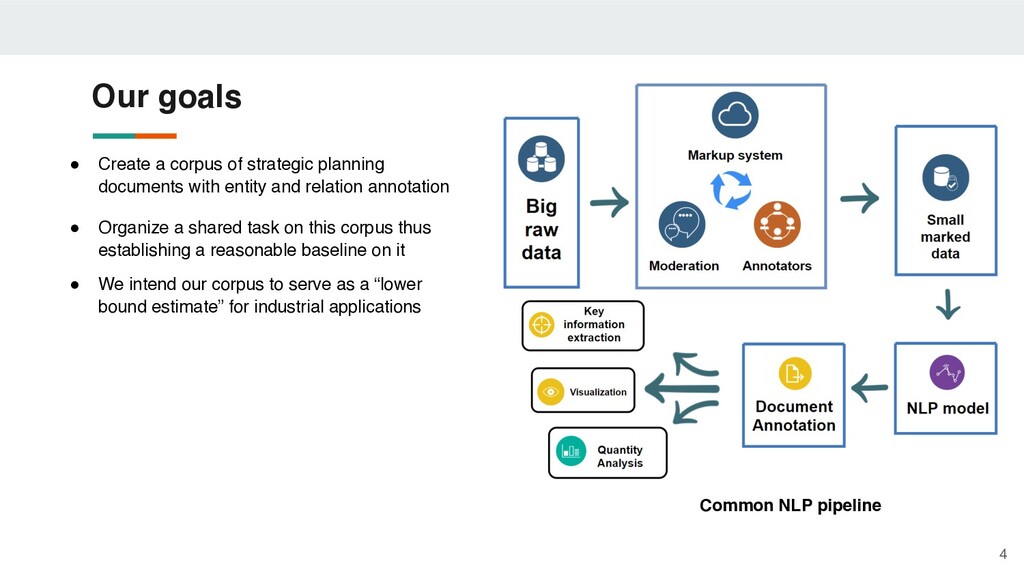
and relation annotation • Organize a shared task on this corpus thus establishing a reasonable baseline on it • We intend our corpus to serve as a “lower bound estimate” for industrial applications 4 Our goals Common NLP pipeline
real-world scenario as possible. To do this we allowed several features, often frown upon in academia (to our best knowledge ignored by our participants): • We did not restrict participations for open-source systems exclusively • We allowed participants to create additional markup, provided they report it and send us markup created by them • We provided a large corpus of unmarked texts of same domain Business-like features 5
documents per year. The overall collection contains more than 30 thousand documents with the following features: • uniformity of texts: documents have the same domain, purpose, very similar style and size; • shared scope: documents mention various types of economic and social entities and relations at different levels of management; • fixed modalities: a fixed list of modalities in documents that cover current state of the economy or society (problems), as well as plans for future (actions, tasks, etc.) Strategic planning documents 6
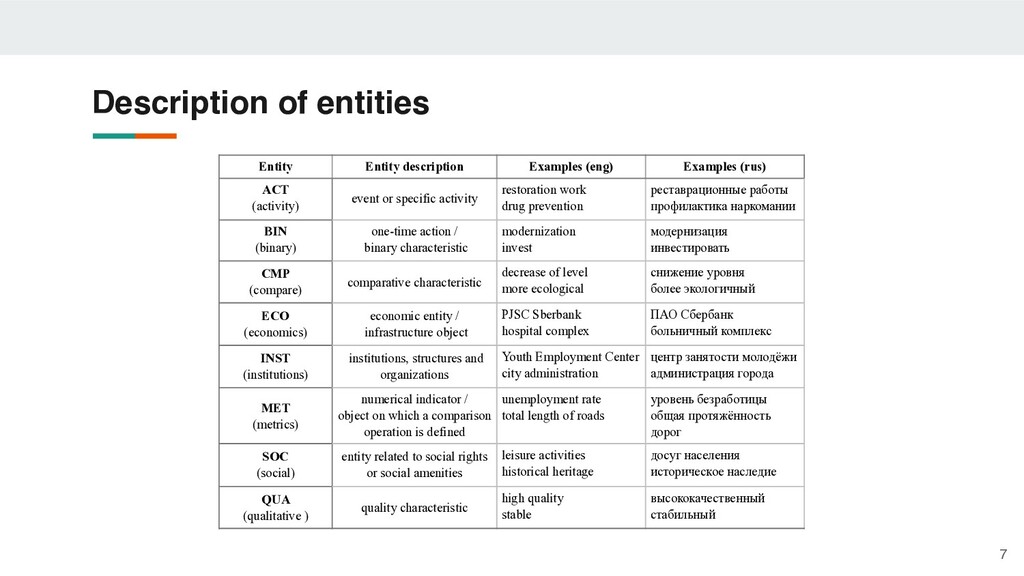
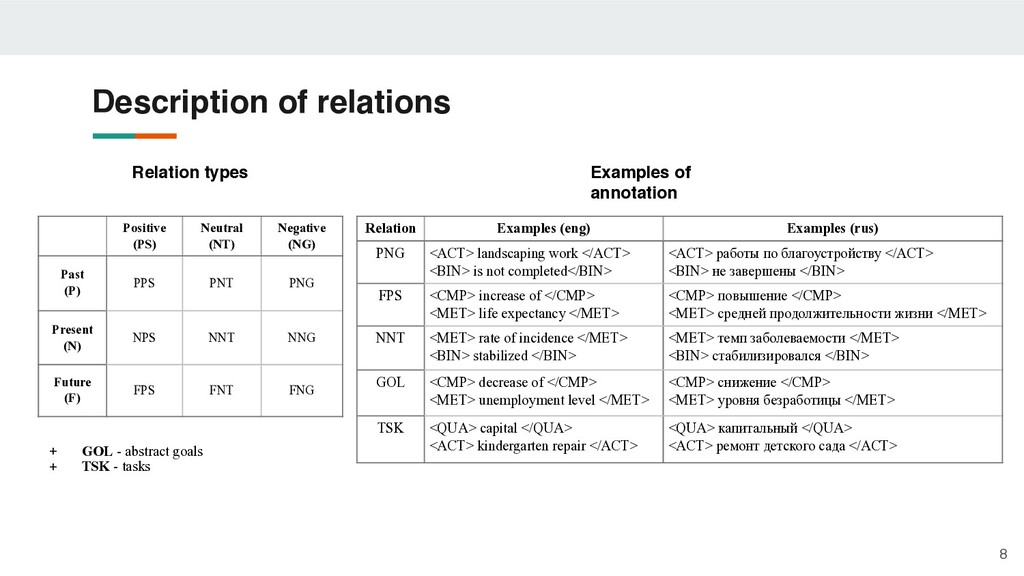
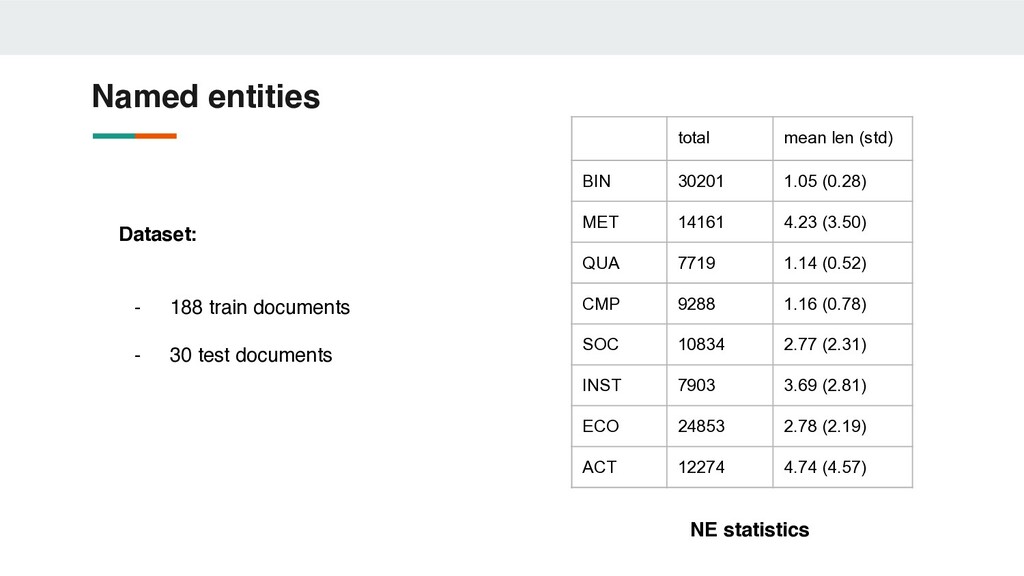
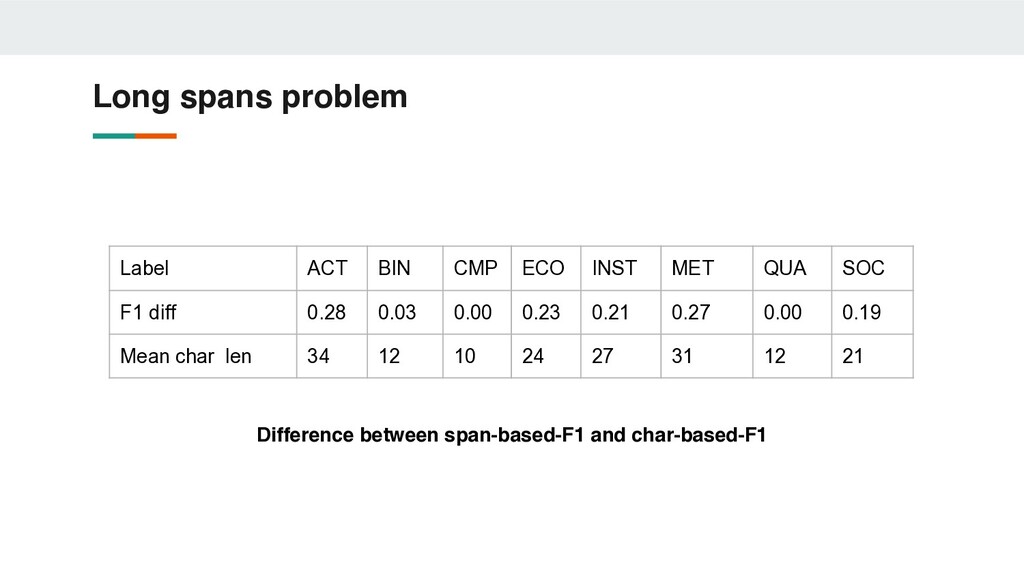
(rus) ACT (activity) event or specific activity restoration work drug prevention реставрационные работы профилактика наркомании BIN (binary) one-time action / binary characteristic modernization invest модернизация инвестировать CMP (compare) comparative characteristic decrease of level more ecological снижение уровня более экологичный ECO (economics) economic entity / infrastructure object PJSC Sberbank hospital complex ПАО Сбербанк больничный комплекс INST (institutions) institutions, structures and organizations Youth Employment Center city administration центр занятости молодёжи администрация города MET (metrics) numerical indicator / object on which a comparison operation is defined unemployment rate total length of roads уровень безработицы общая протяжённость дорог SOC (social) entity related to social rights or social amenities leisure activities historical heritage досуг населения историческое наследие QUA (qualitative ) quality characteristic high quality stable высококачественный стабильный
motivation was to create a showcase scenario for non- traditional entities and relation • However we believe that our markup can be useful for analysis of e- government documents • See our article “So What's the Plan? Mining Strategic Planning Document” at DTSG for details
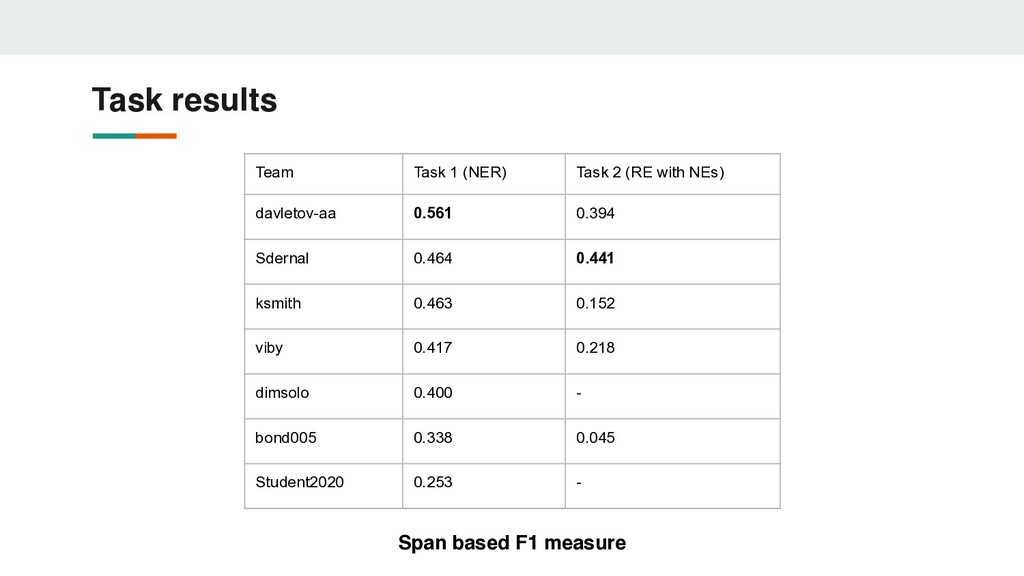
Expected: char spans with labels Evaluation: micro span-based F1 1. Relation Extraction with given Named Entities Given: NEs spans Expected: relations in format (class, head span idx, tail span idx) Evaluation: micro F1 measure 1. End-to-end Relation Extraction Given: raw text files Expected: NEs & relations in format (class, head idx, tail idx) Evaluation: micro F1 measure
Henning Wachsmuth, Rostislav Petrov, and Preslav Nakov. SemEval-2020 task 11: Detection of propaganda techniques in news articles. In Proceedings of the 14th International Workshop on Semantic Evaluation, SemEval 2020, Barcelona, Spain, September 2020.
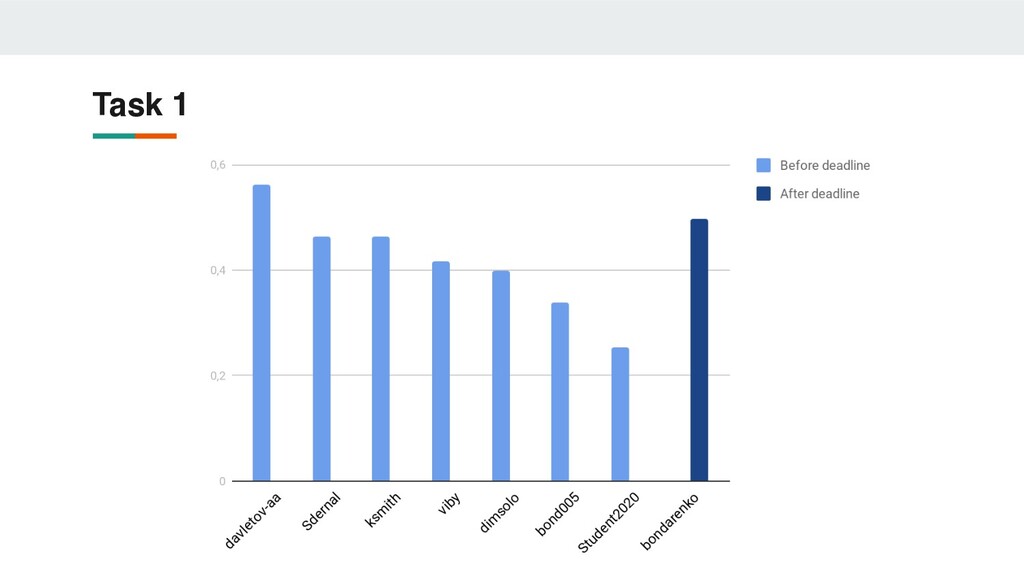
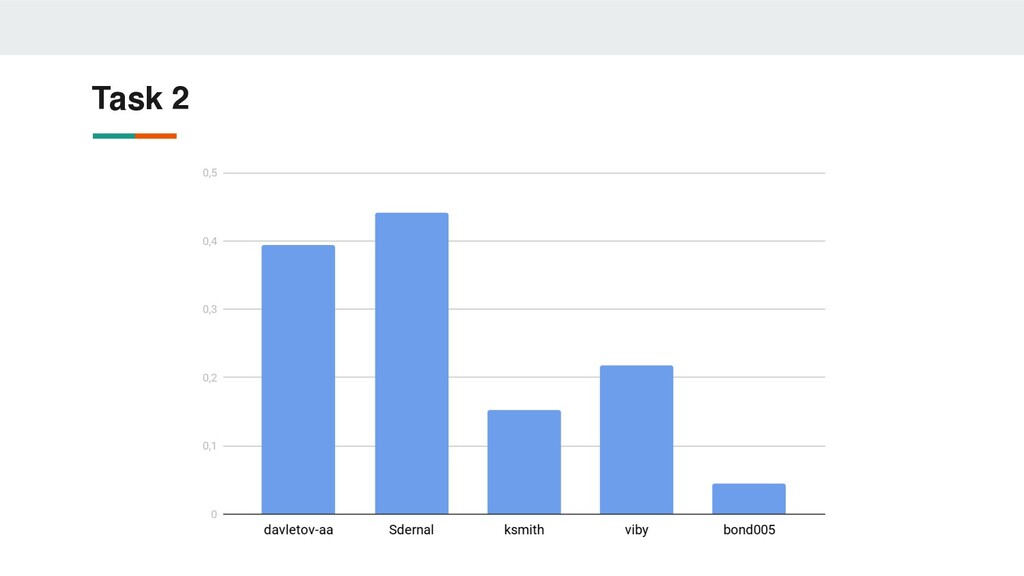
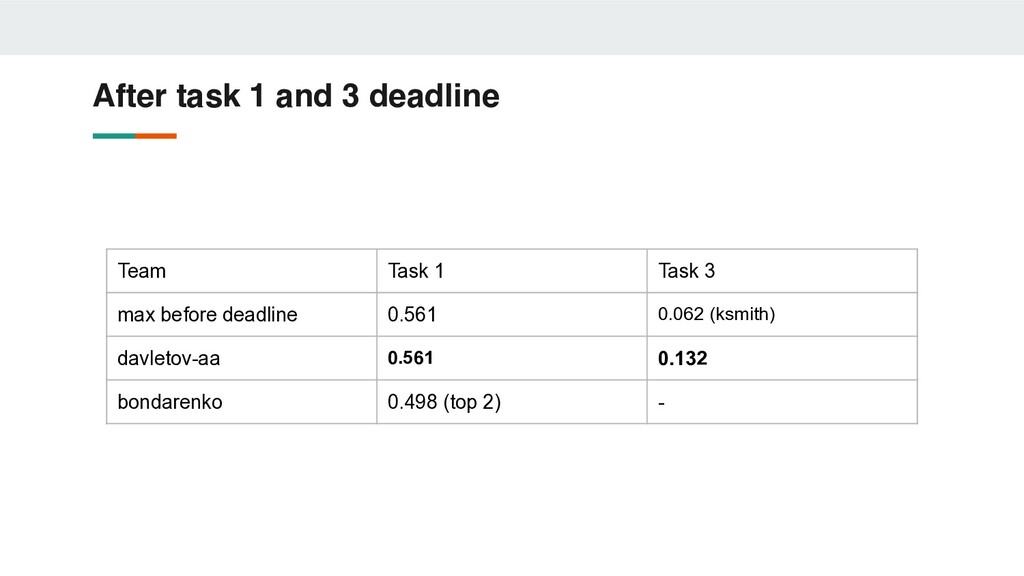
RE • We presented large raw text corpus for this domain • Proposed dataset represents worst-case industrial application scenario • Shared task results demonstrate that dataset could be treated as testing ground for industrial applications of NER and RE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}