CloudNative Days Tokyo 2021
Track C 2021/11/05 15:20-15:40
中級者 Operation / Monitoring / Logging
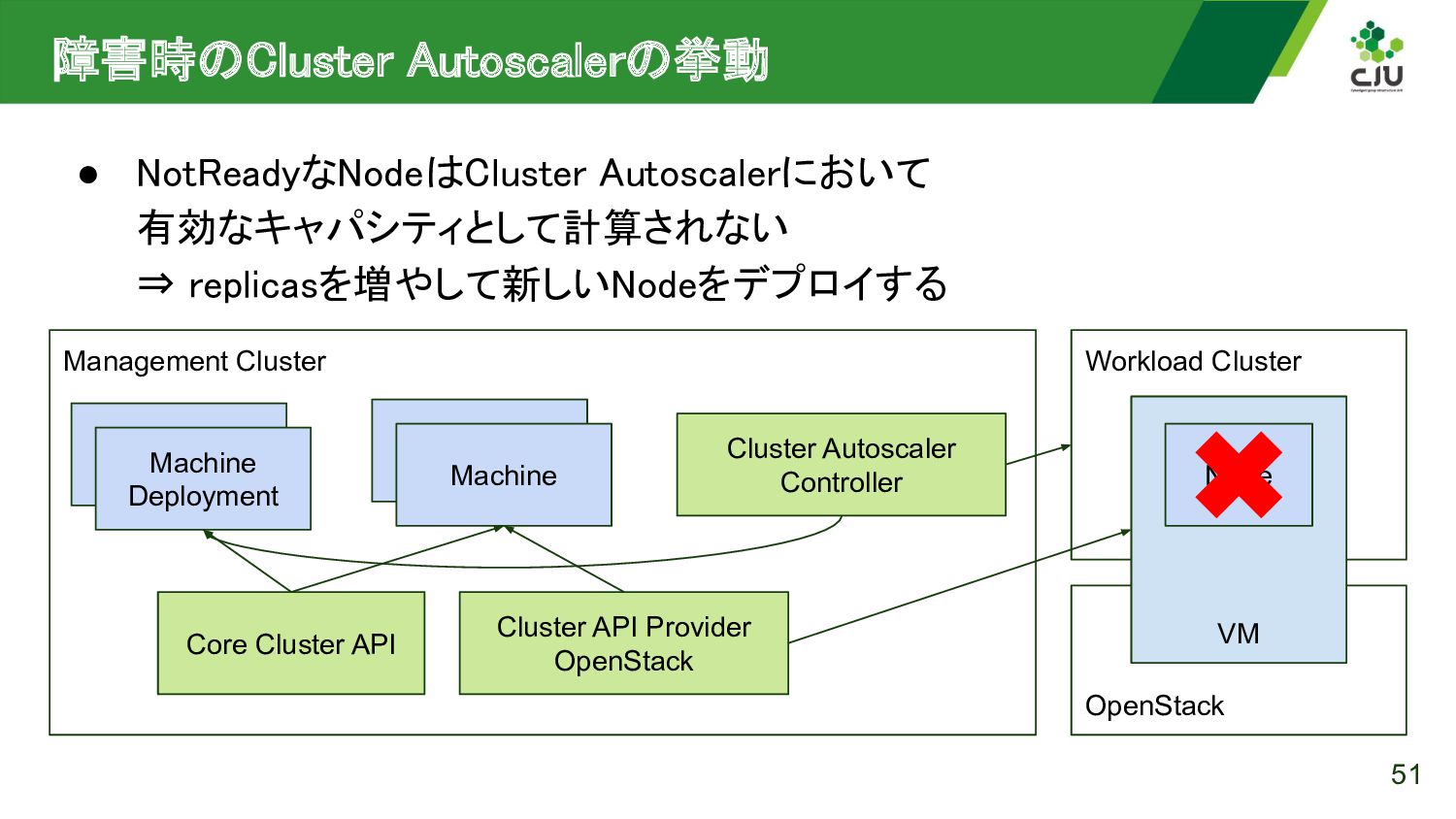
CyberAgentではプライベートクラウド上で多数のKubernetesクラスタが稼働しており、ノードの自動修復機能を実装することで運用コストを削減しました。本発表では、似たような自動修復を実現したいオンプレミスKubernetesの運用者にむけて、KubernetesにおけるノードのNotReadyの定義から、OverlayFSで実現した再起動でディスクの変更が揮発する仕組みまで紹介します。
{kind=link}
{kind=link}
{kind=link}
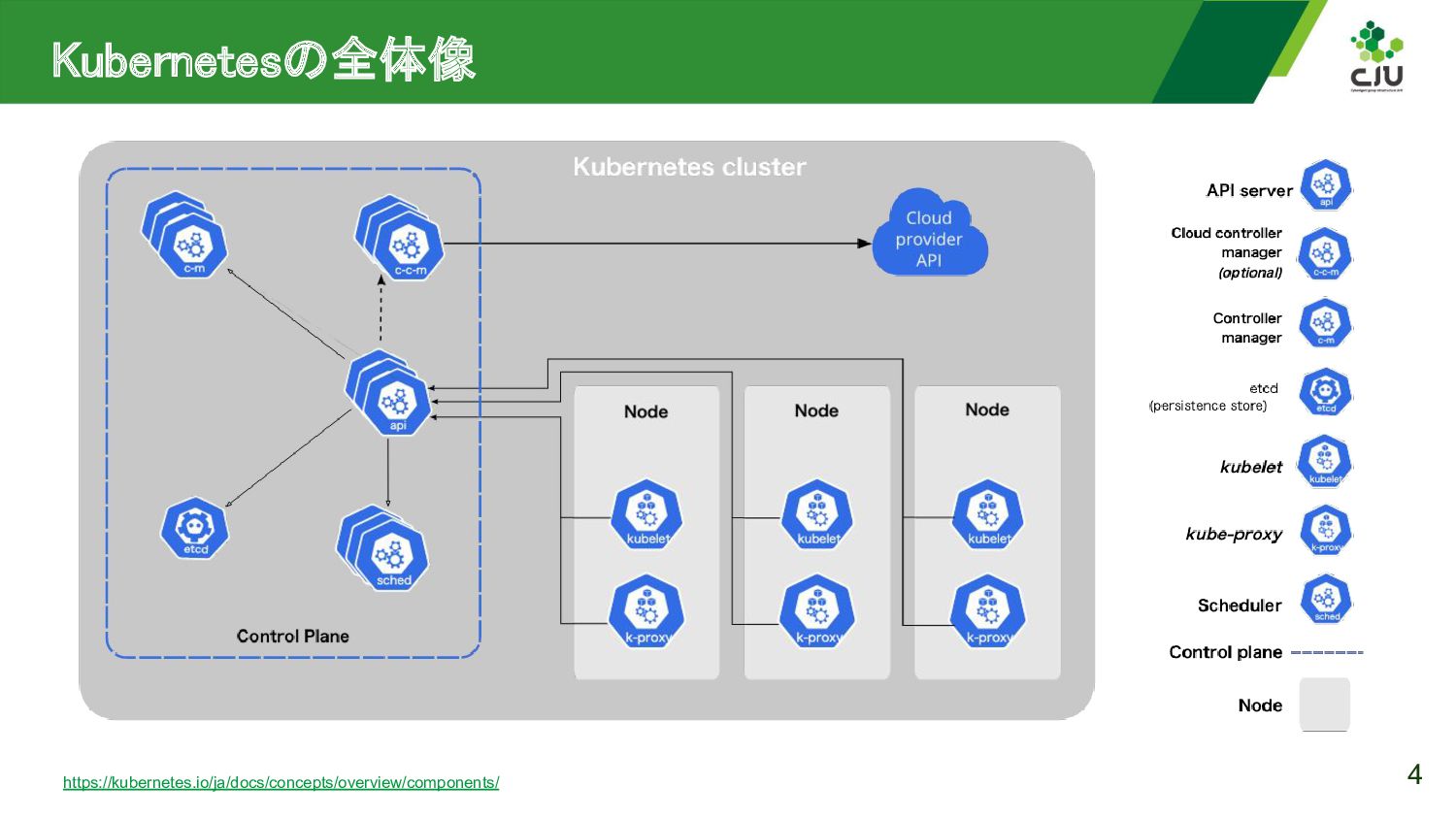{kind=link}
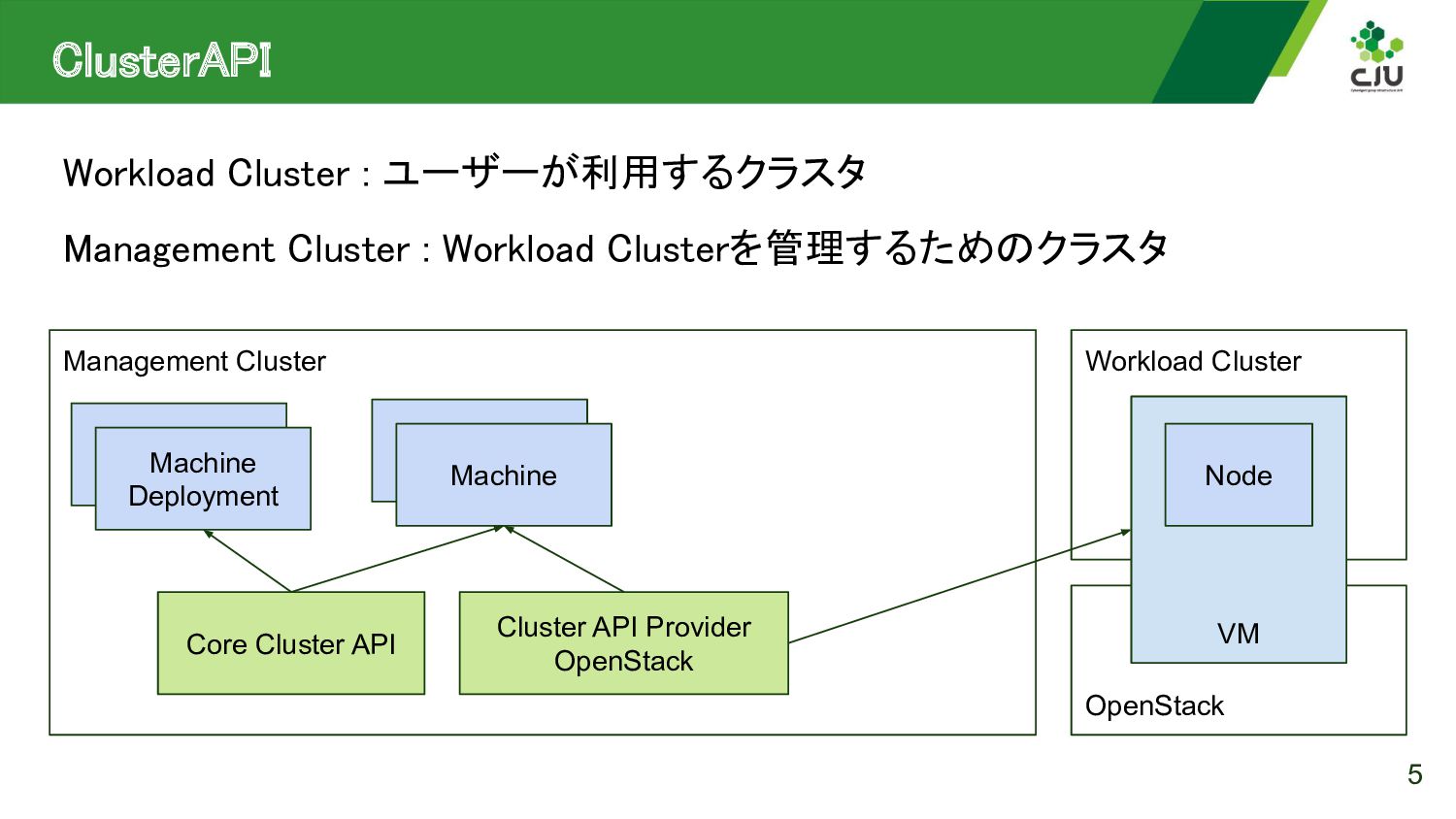{kind=link}
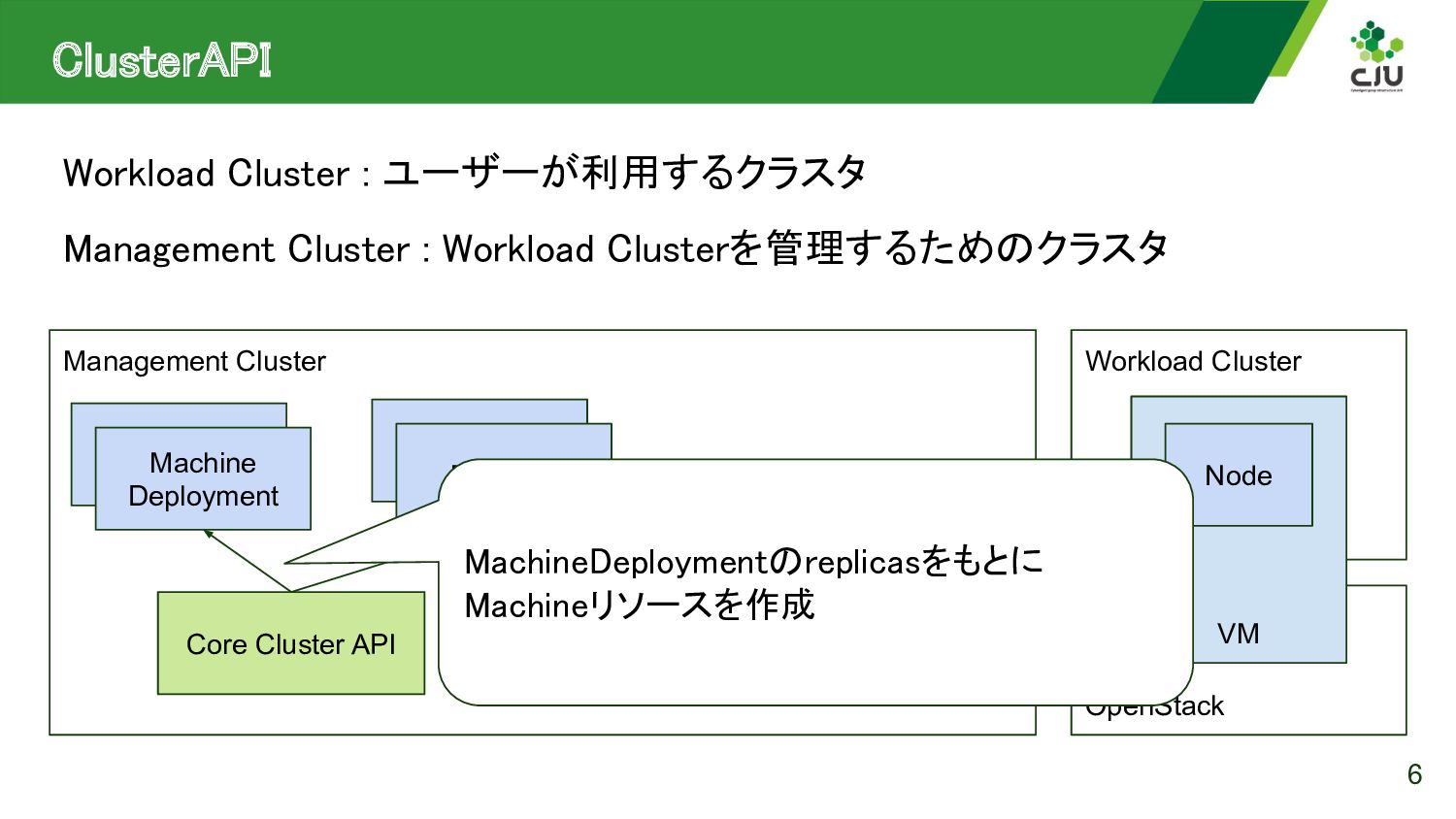{kind=link}
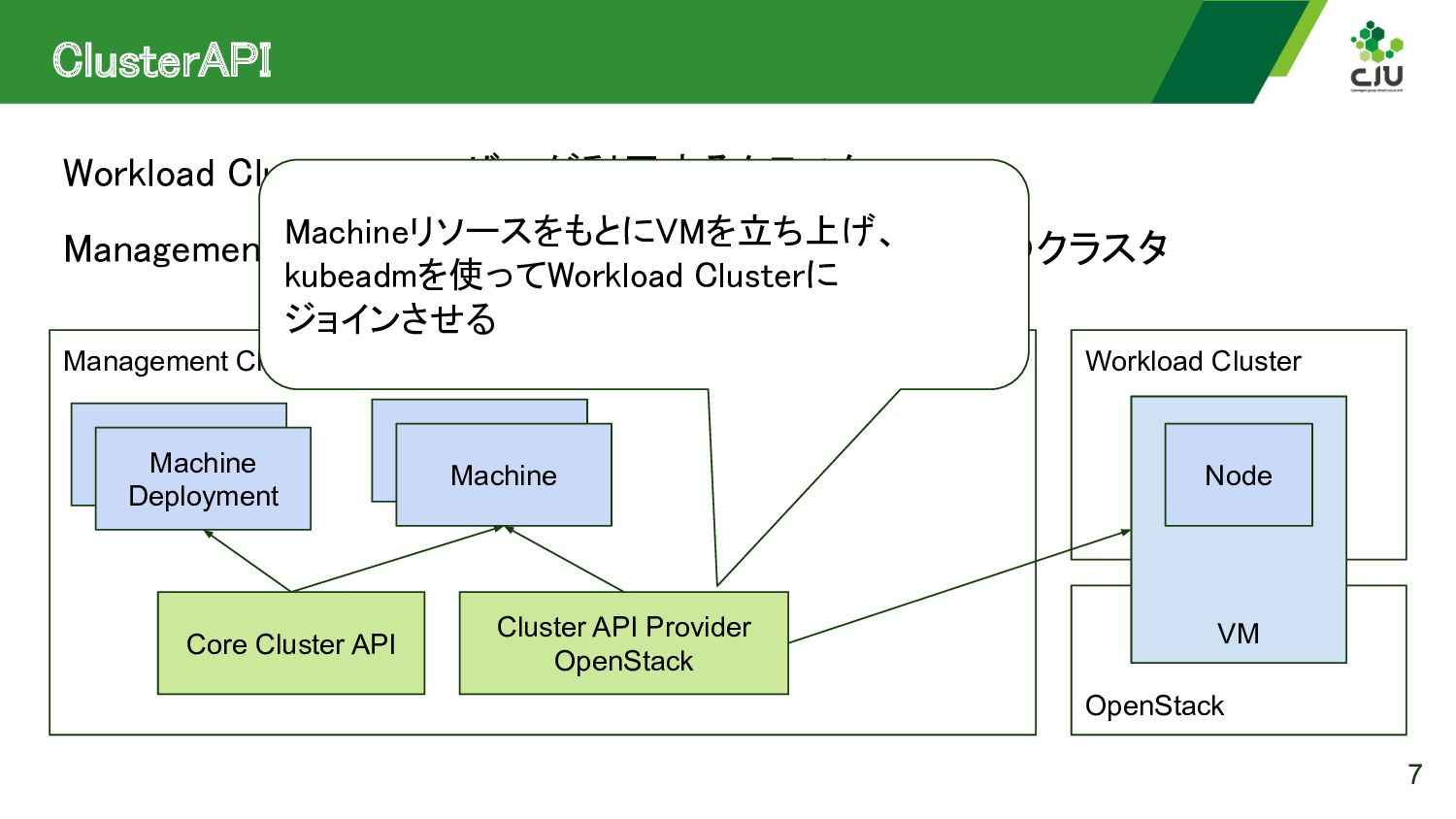{kind=link}
{kind=link}
{kind=link}
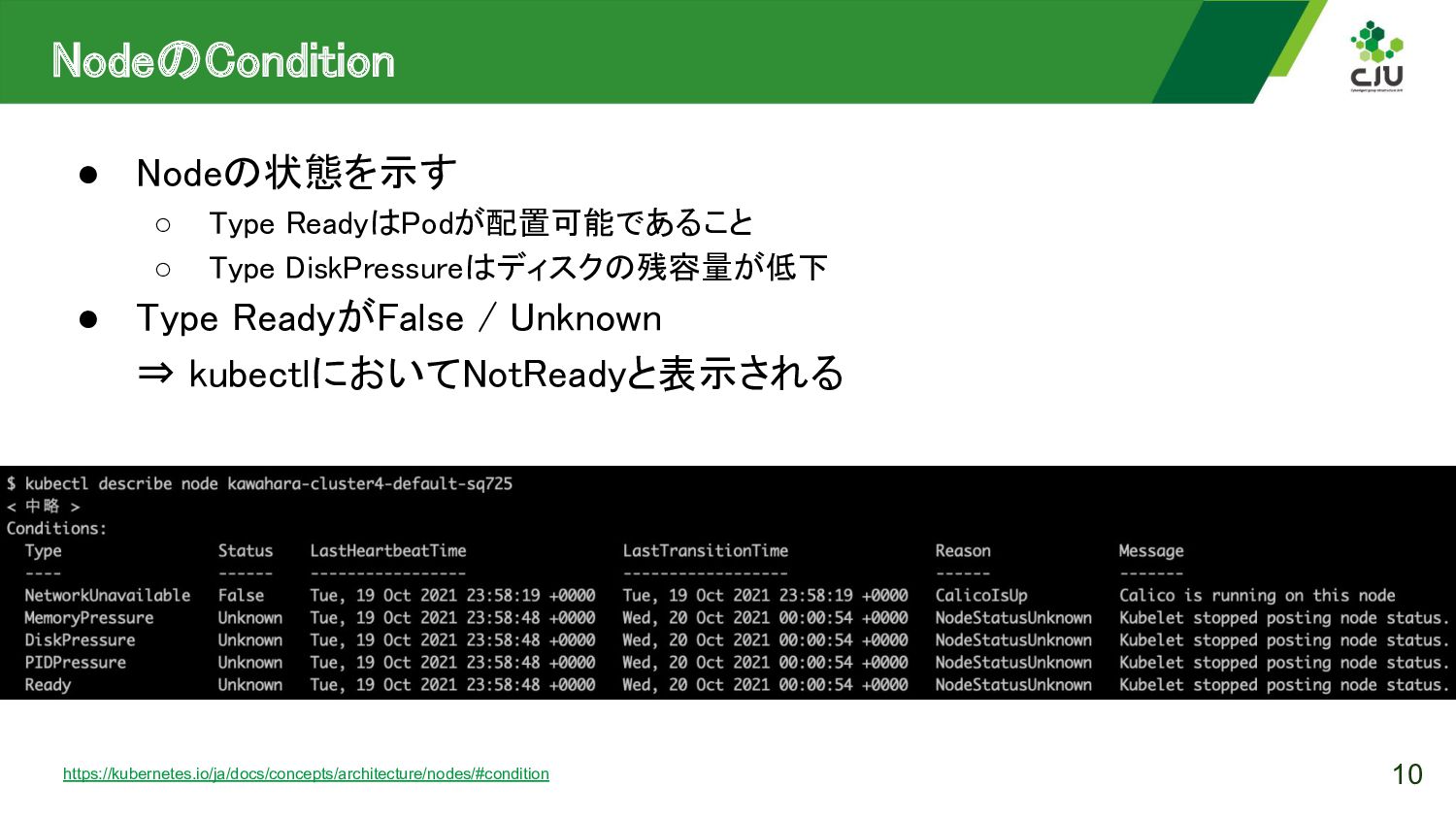{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
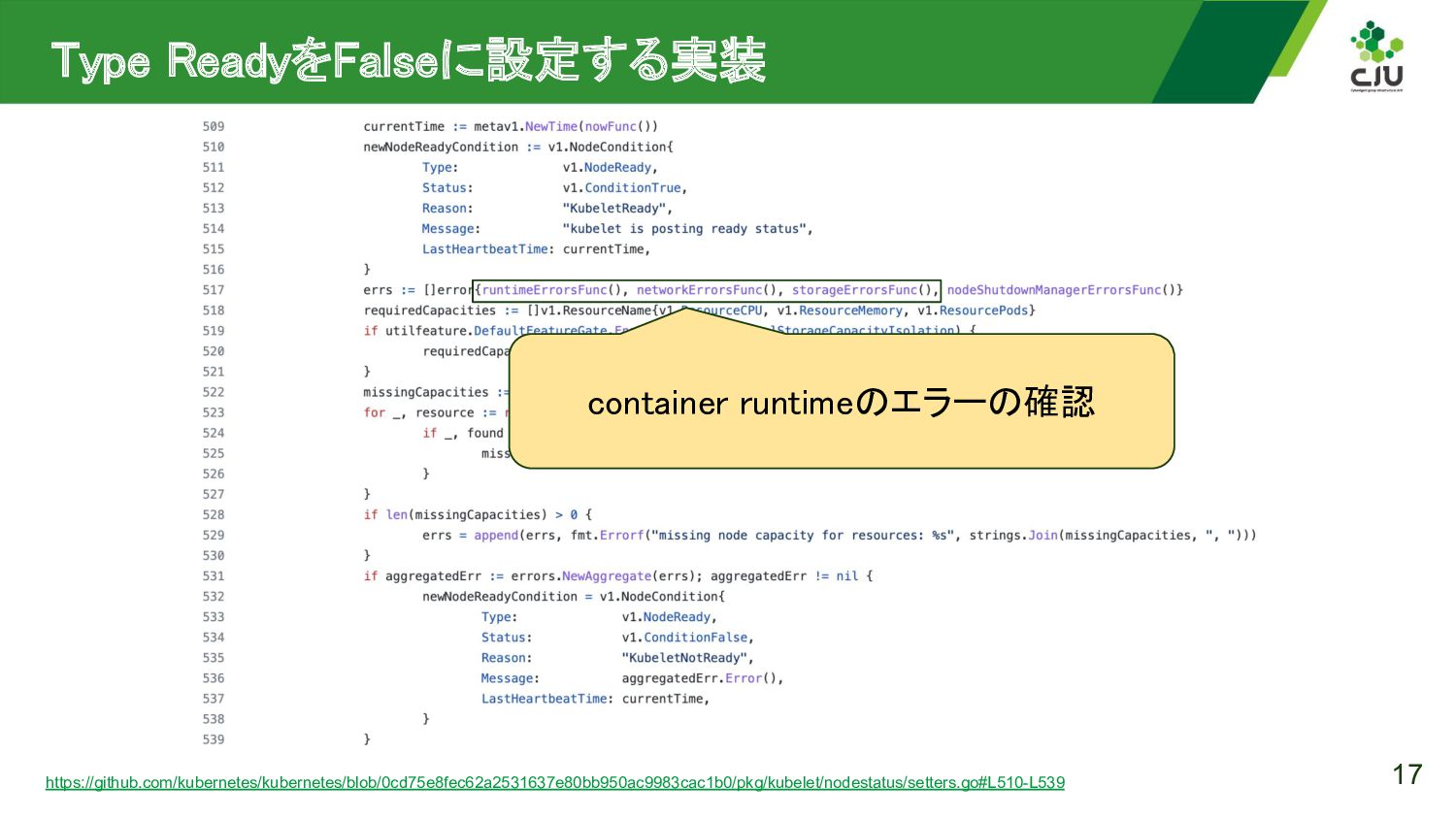{kind=link}
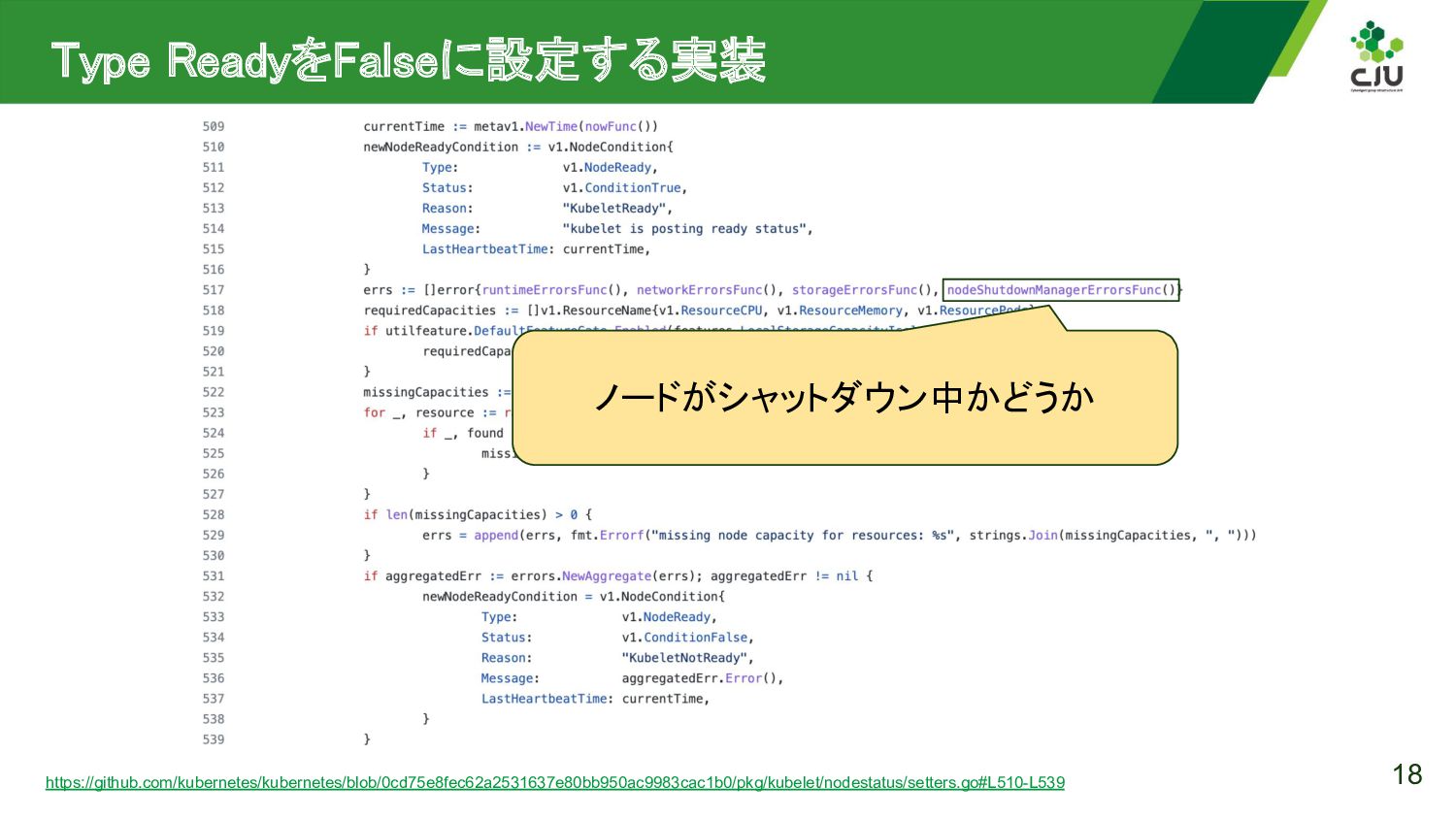{kind=link}
{kind=link}
{kind=link}
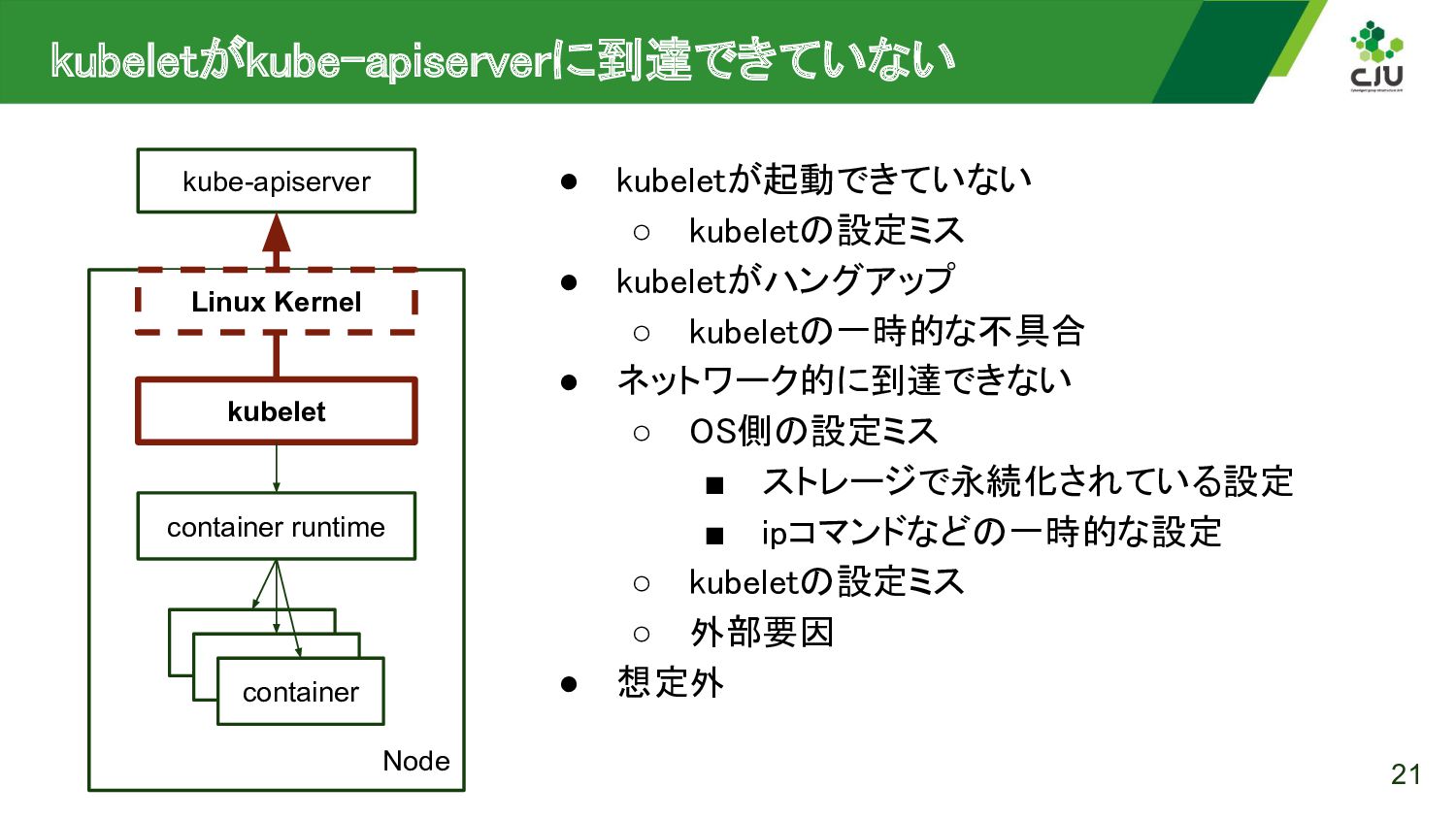{kind=link}
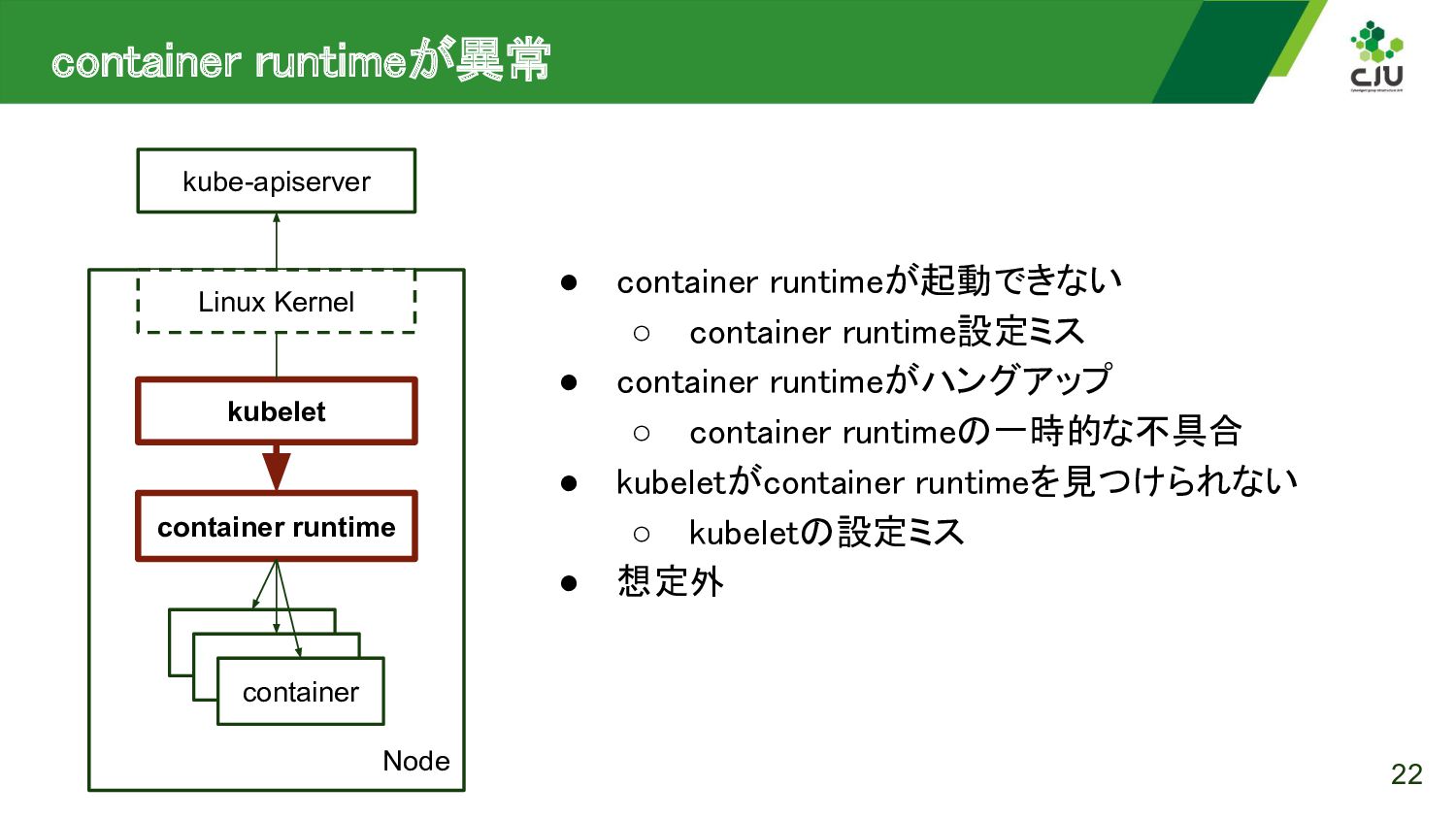{kind=link}
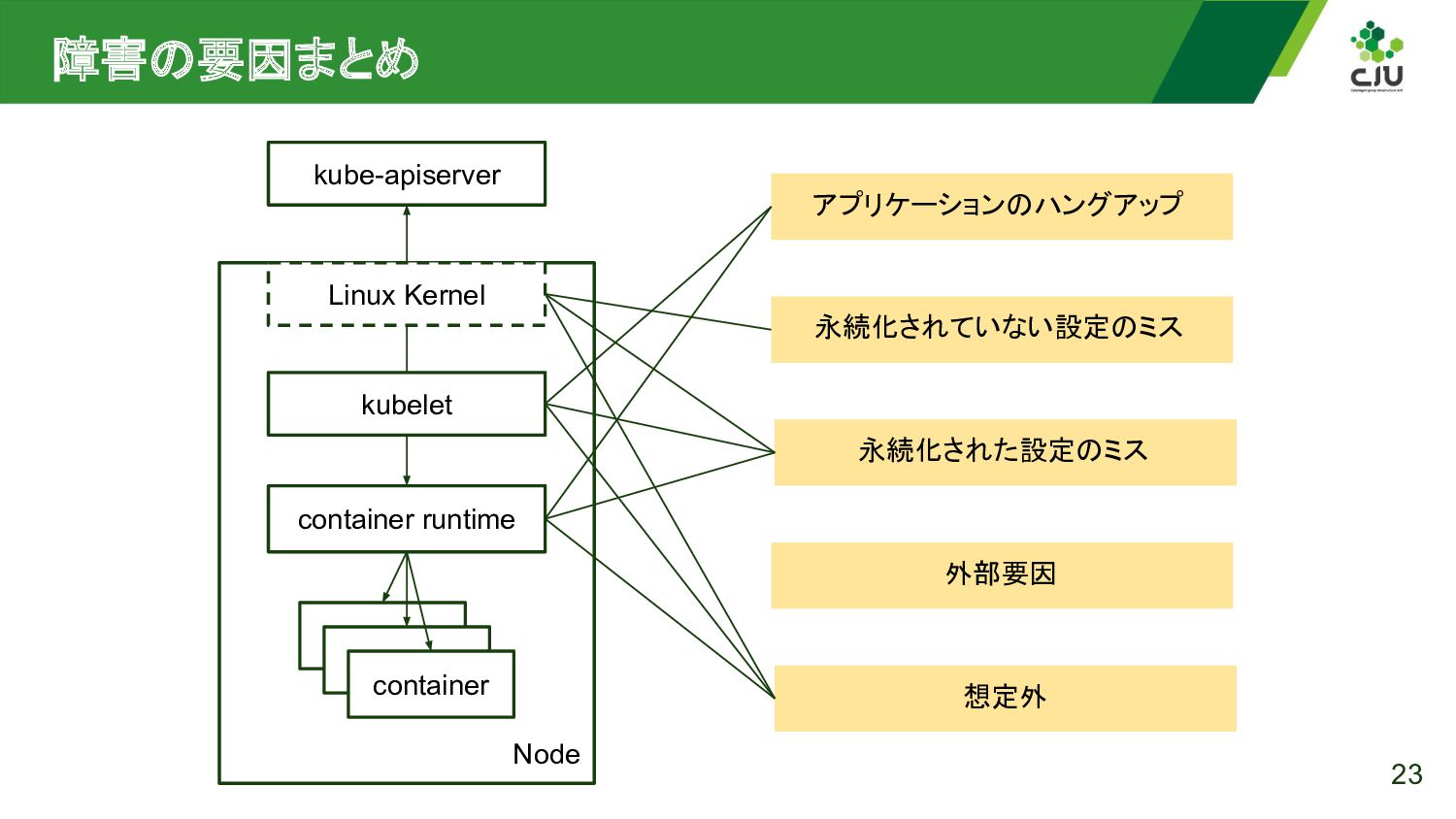{kind=link}
{kind=link}
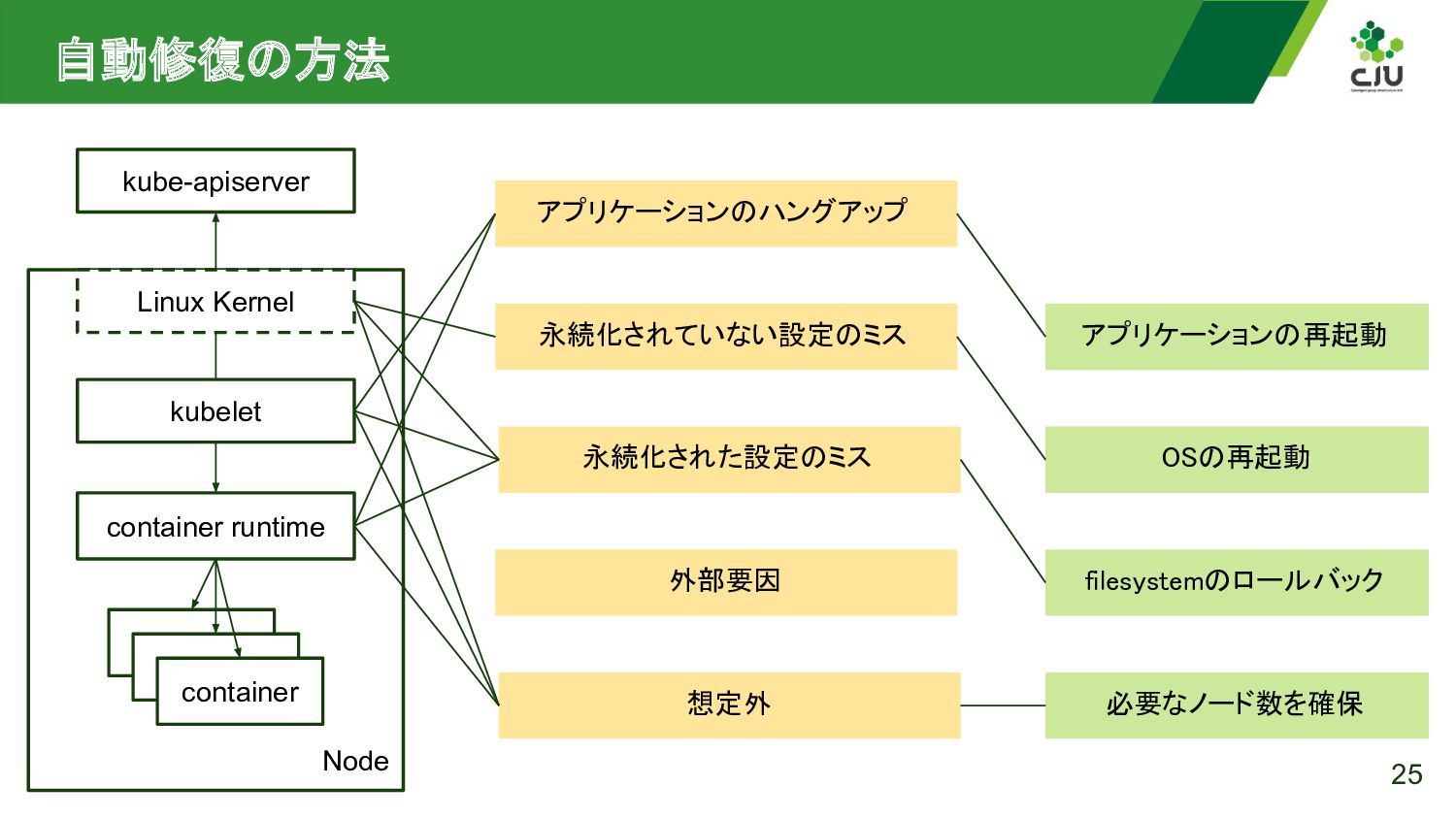{kind=link}
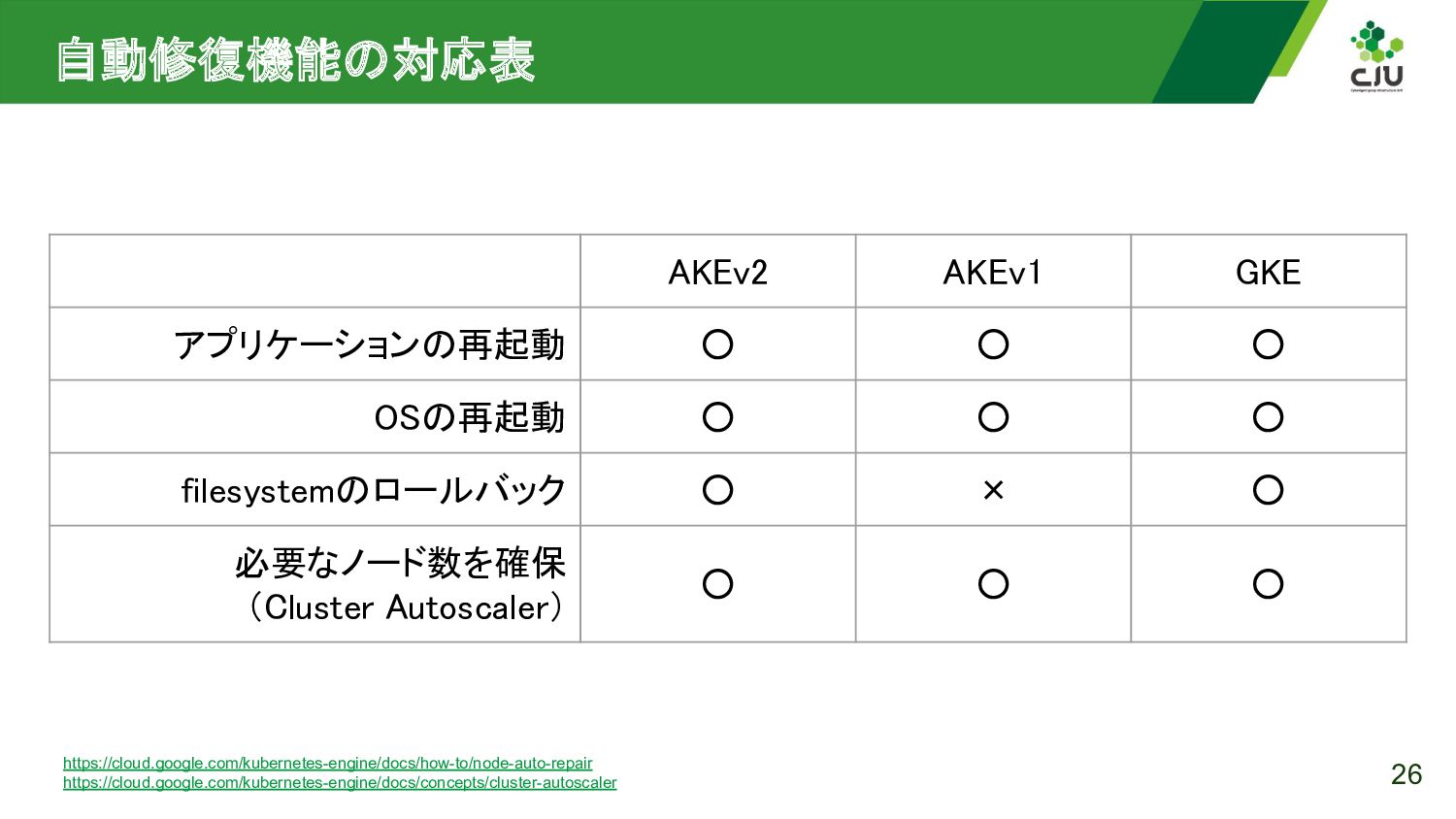{kind=link}
{kind=link}
{kind=link}
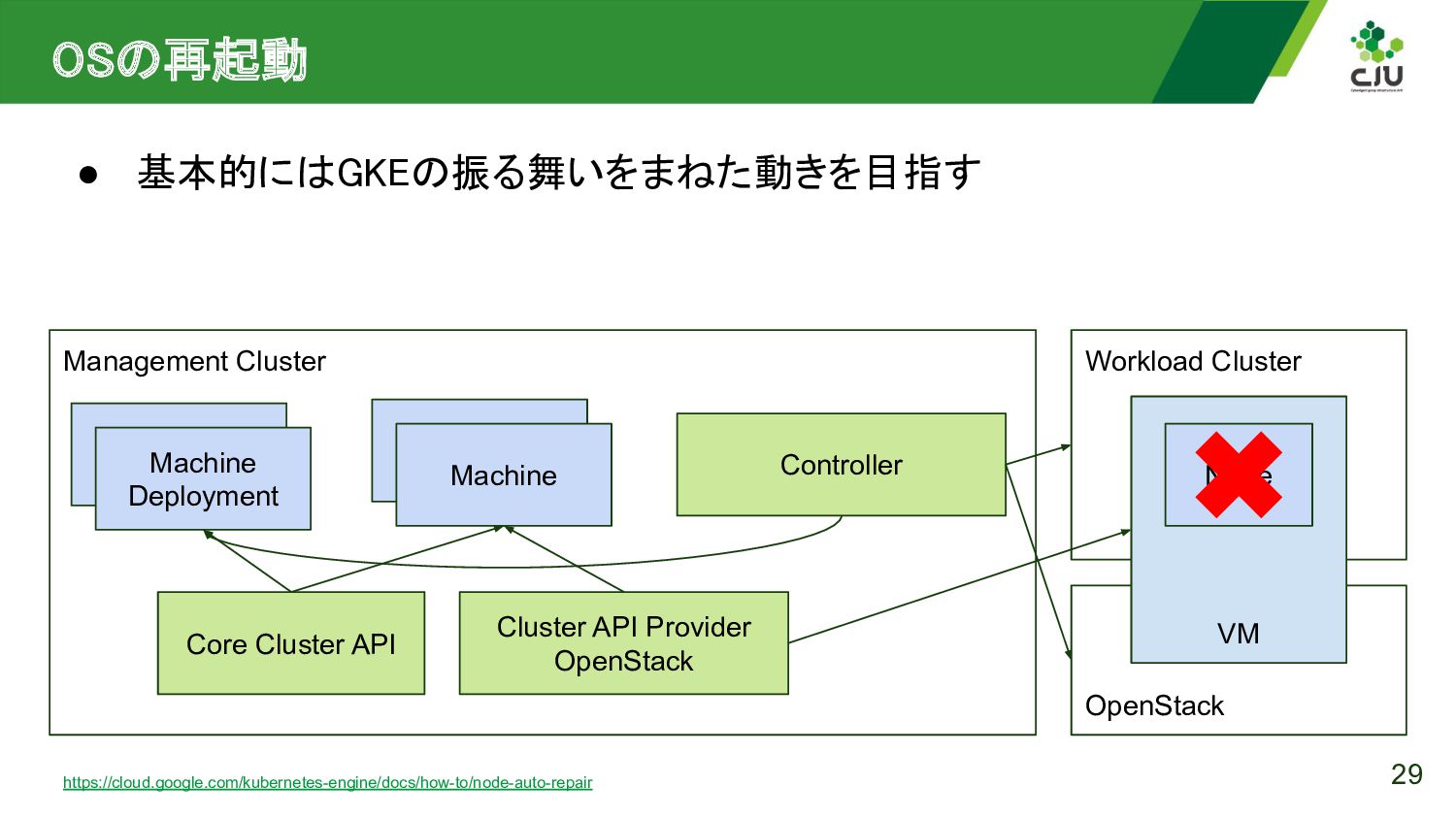{kind=link}
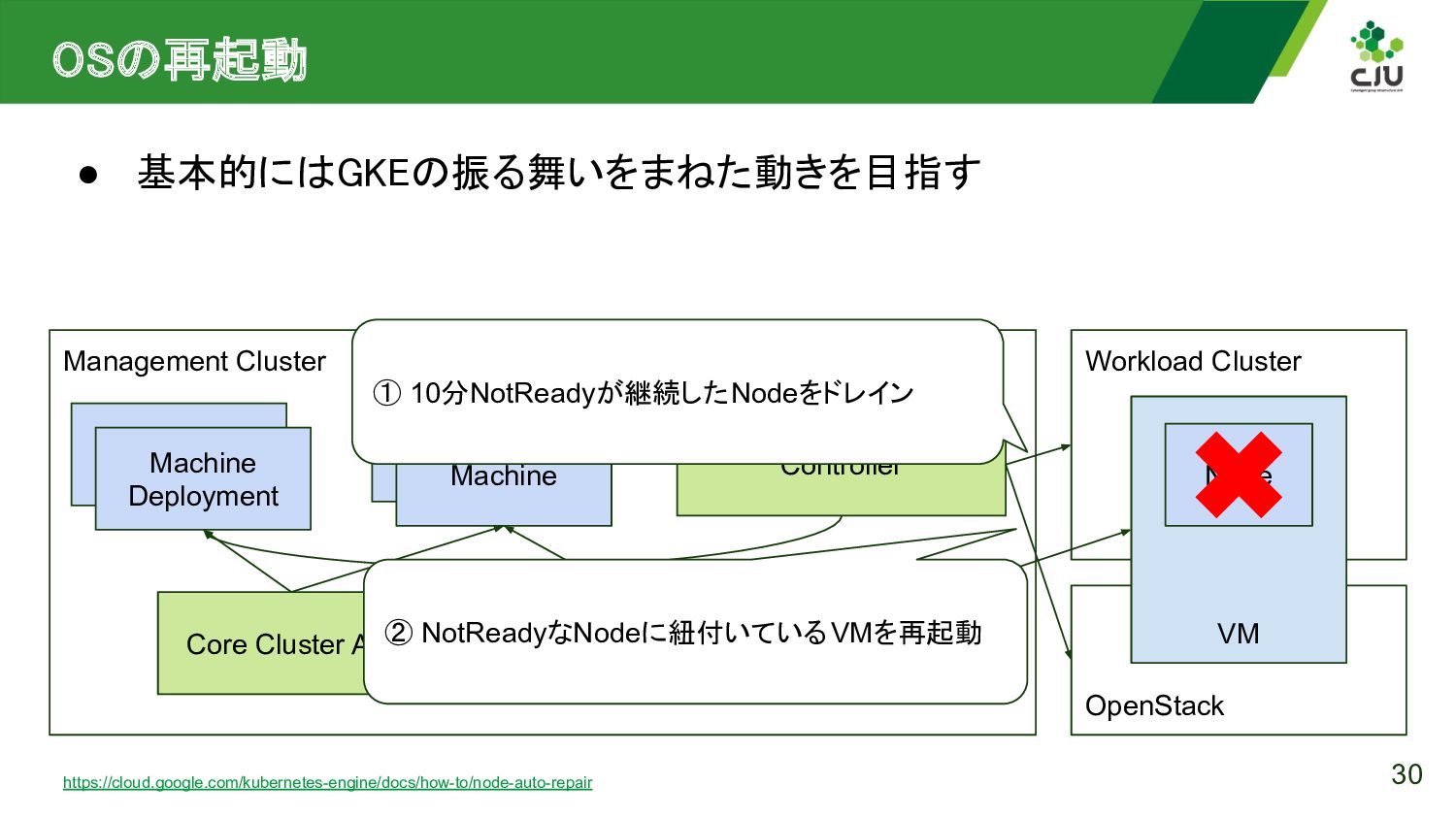{kind=link}
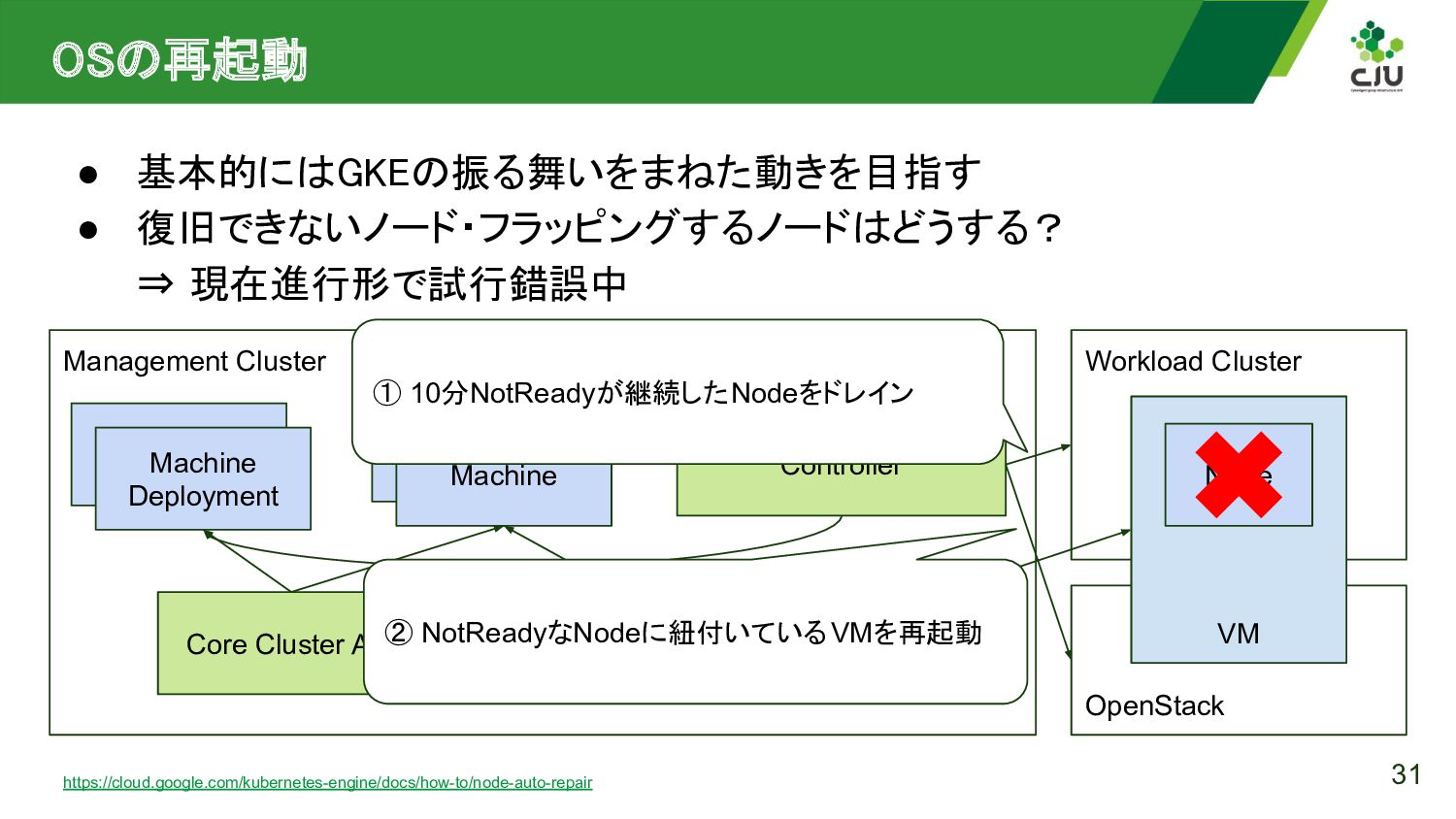{kind=link}
{kind=link}
{kind=link}
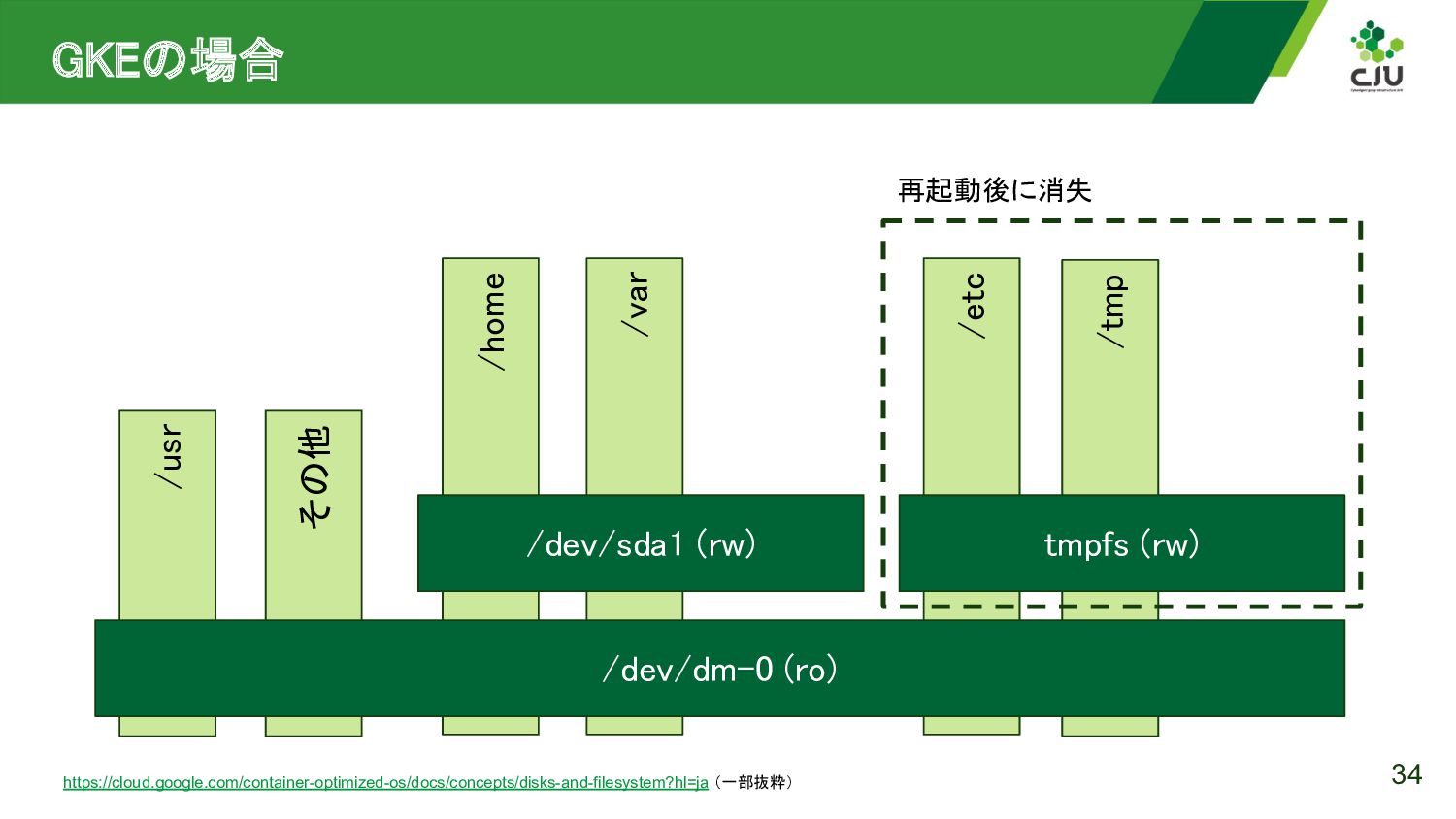{kind=link}
{kind=link}
{kind=link}
{kind=link}
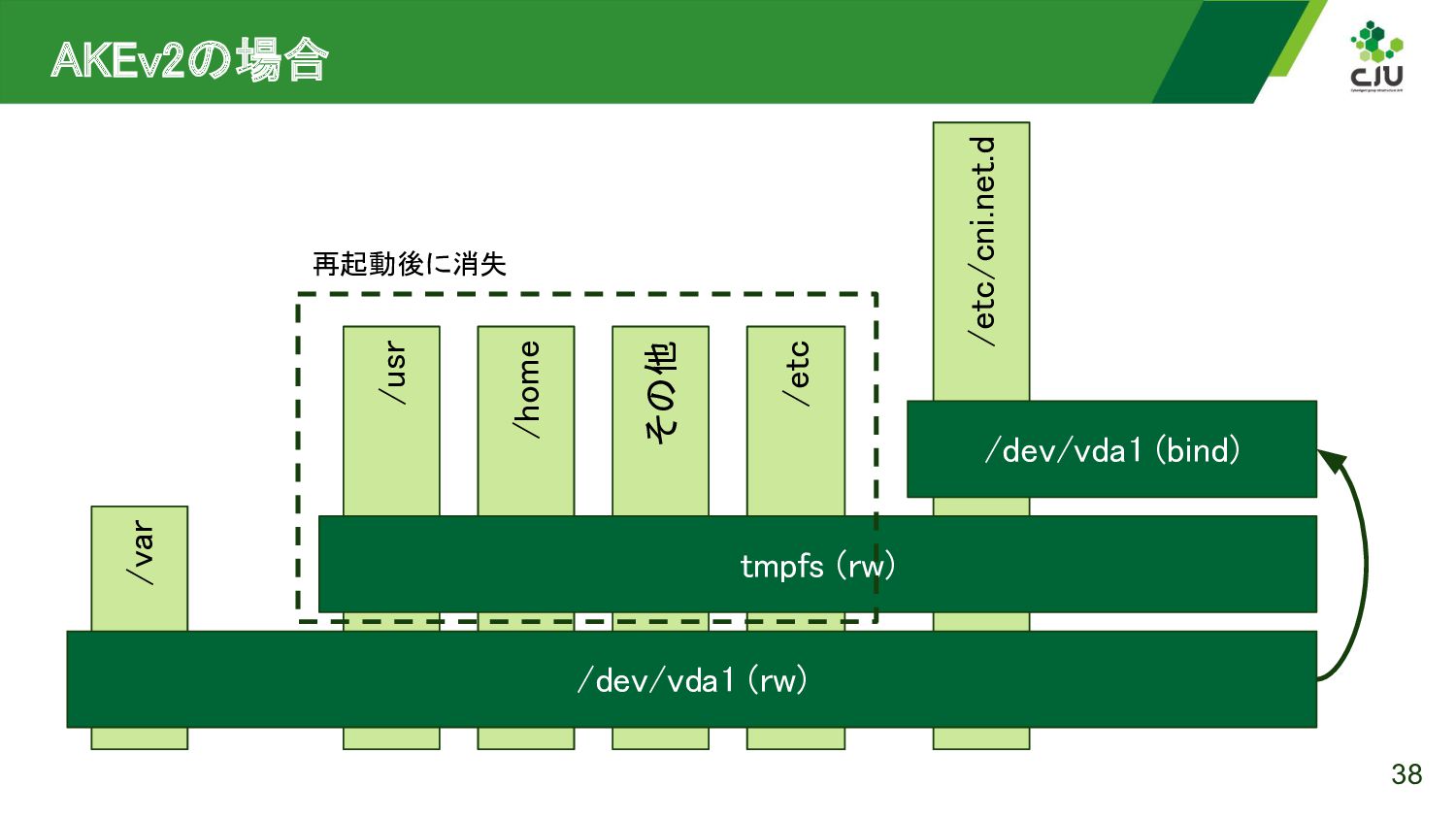{kind=link}
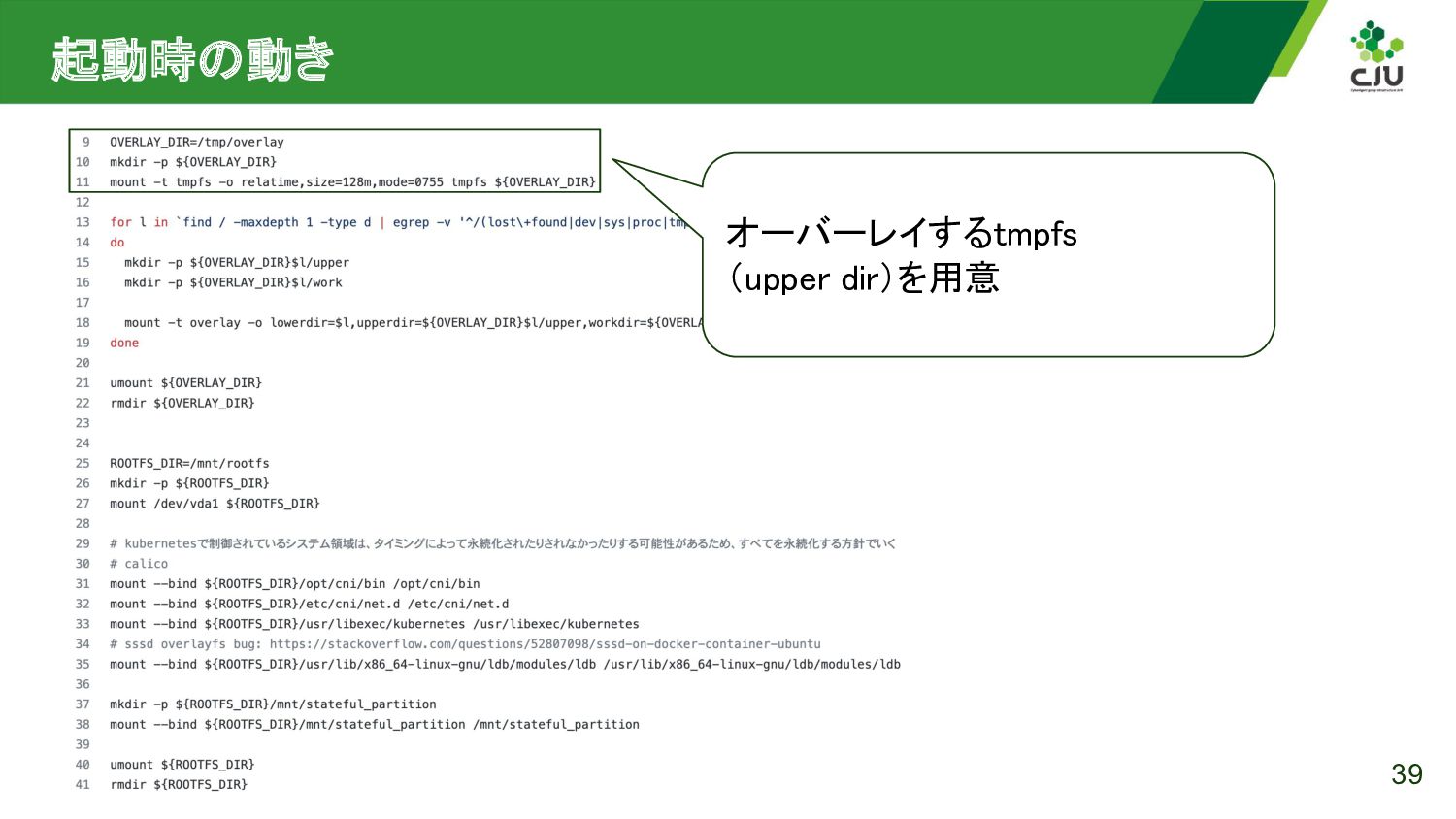{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
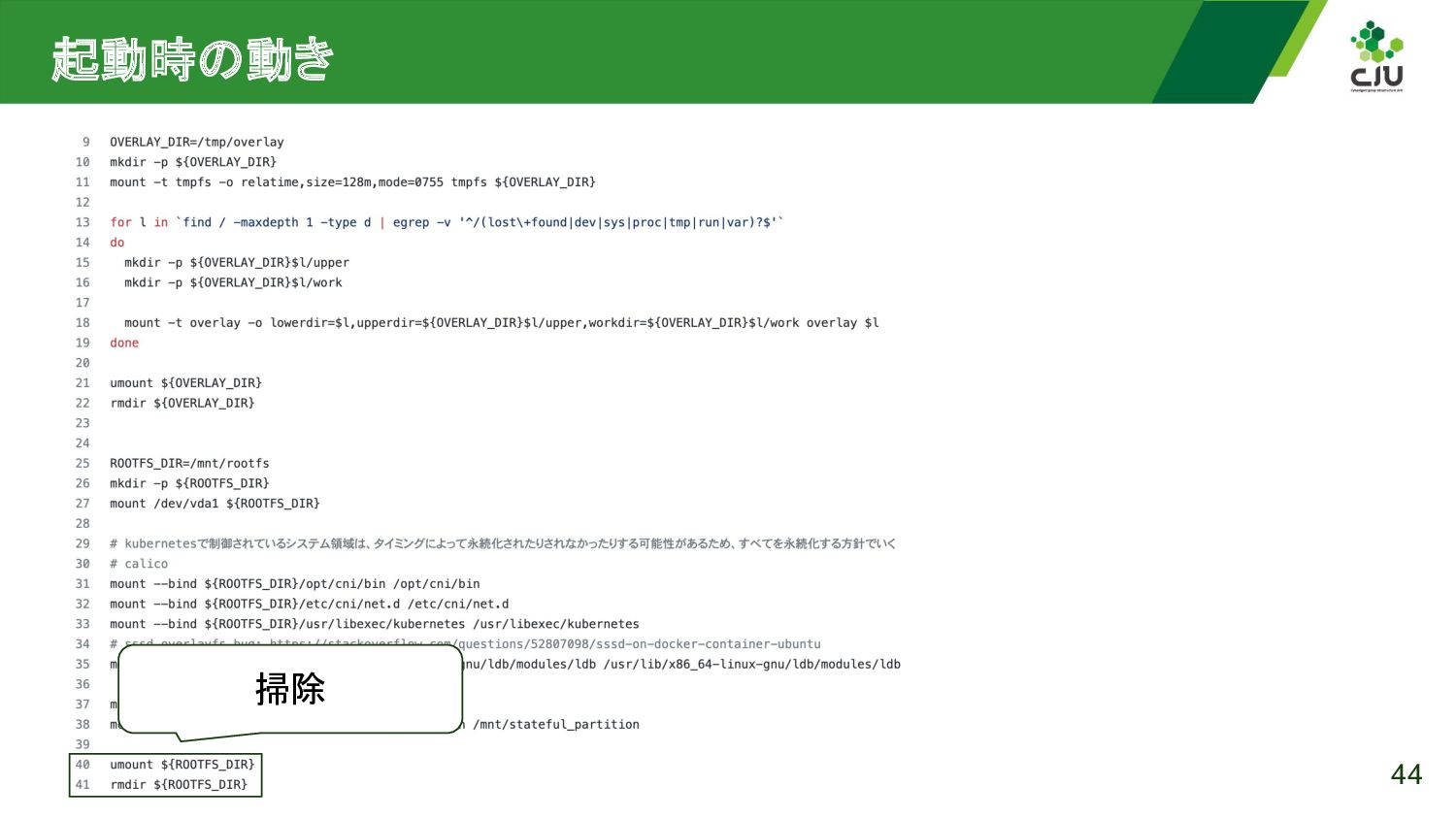{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
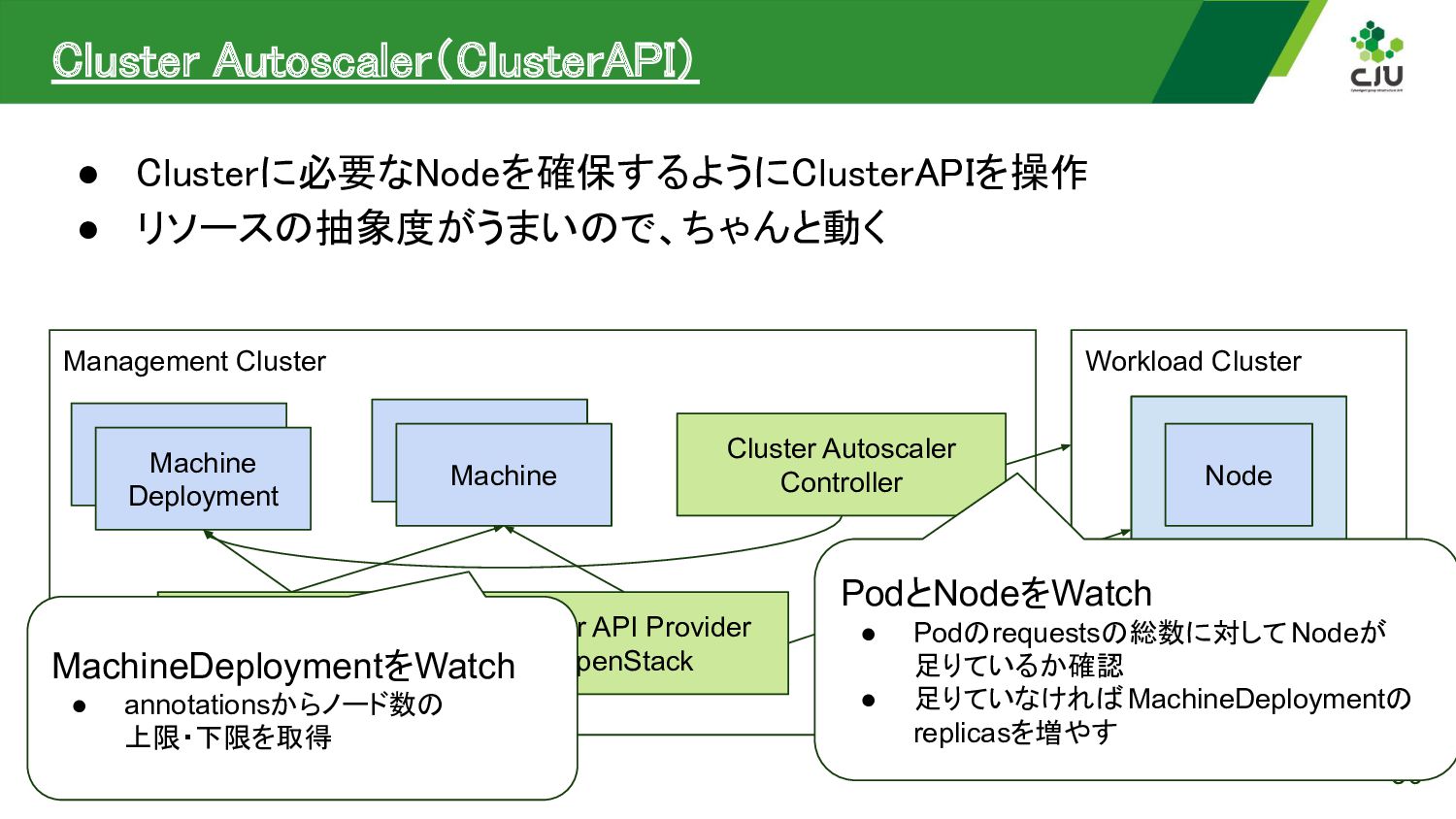{kind=link}
{kind=link}
{kind=link}