version • Data model and architecture • Integrations, problems and improvements The NoSQL version • Data model and architecture • Performance boost • The bad and the ugly Conclusions • Personal thoughts • Questions Content A success story? • Orchestration framework • Possible solutions
largest telecommunications company in the world § Operations in Europe (7 countries), the United States and Latin America (15 countries) • Telefonica Digital § Web and mobile digital contents and services division • Product Development and Innovation unit § Formerly Telefonica R&D § Product & service development, platforms development, research, technology strategy, user experience and deployment & operation § Around 70 different on going projects at all time. 01
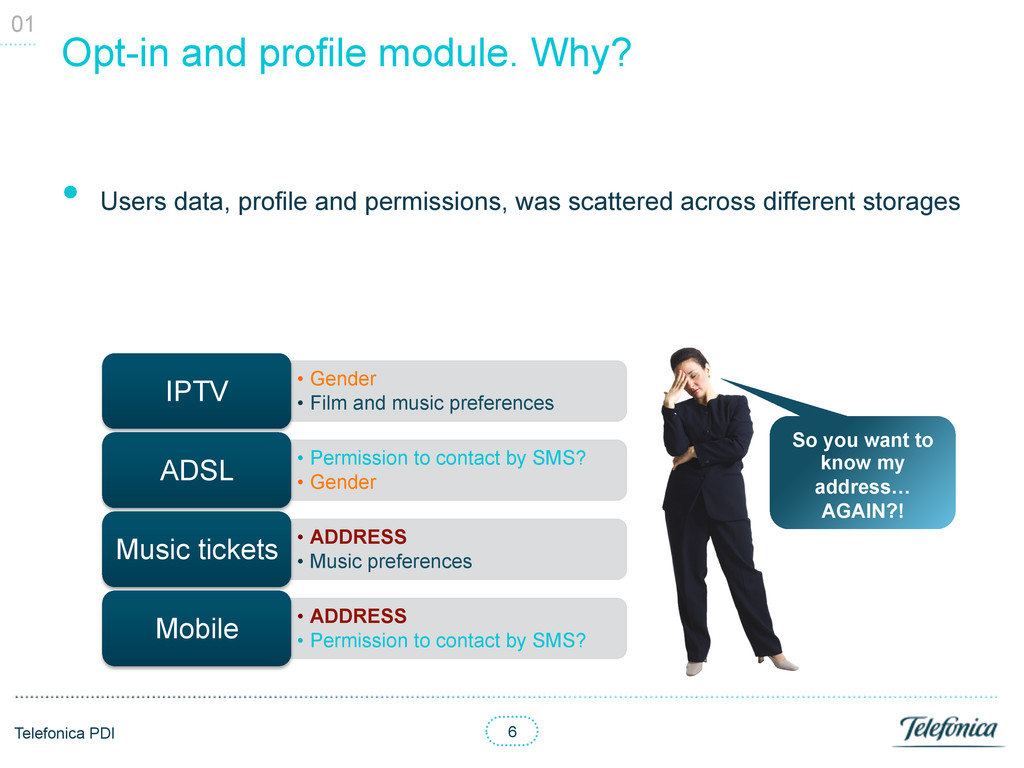
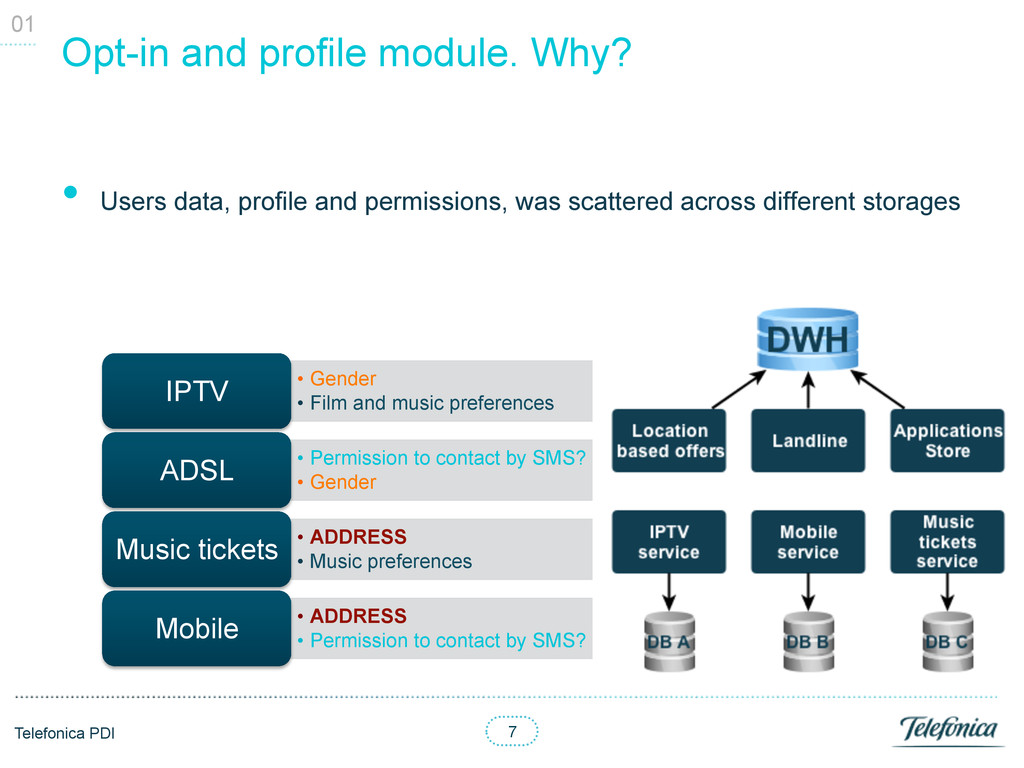
data, profile and permissions, was scattered across different storages 01 • Gender • Film and music preferences IPTV • Permission to contact by SMS? • Gender ADSL • ADDRESS • Music preferences Music tickets • ADDRESS • Permission to contact by SMS? Mobile So you want to know my address… AGAIN?!
data, profile and permissions, was scattered across different storages 01 • Gender • Film and music preferences IPTV • Permission to contact by SMS? • Gender ADSL • ADDRESS • Music preferences Music tickets • ADDRESS • Permission to contact by SMS? Mobile
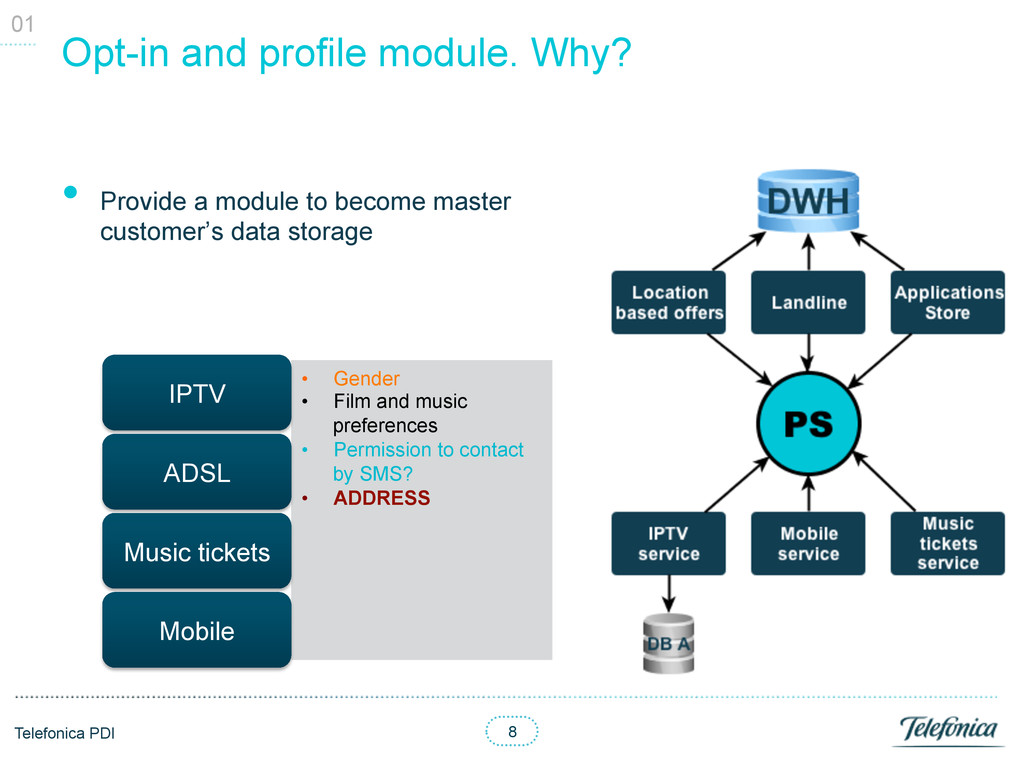
a module to become master customer’s data storage 01 • Gender • Film and music preferences • Permission to contact by SMS? • ADDRESS IPTV ADSL Music tickets Mobile
"call_center", "service_id": ”music_tickets", "name": ”music.pop", "value": ”yes", "update_date": "2010-03-12T10:39:32Z" }, { "update_source": "call_center", "service_id": "ADSL", "name": "profile.address", "value": "13 Rue del Percebe, ático 2a", "update_date": "2010-03-12T10:39:32Z" }, { "update_source": "call_center", "service_id": "ADSL", "name": "contact.sms", "value": true, "update_date": "2010-03-12T10:39:32Z" } ] PS auth user which set that value Timestamp of actual value Service “owner” of the attributes 01
rue del percebe, ático 2a | true ... D|ADSL|1235|1|2010-08-29T12:45:23|call_center|&|& ... I|ADSL|8910|1|2010-08-29T12:45:23|call_center| | false ... H|music_tickets|service_user_id|0|update_date|update_source | music.pop | music.rock ... I|ADSL|1234|0|2010-08-29T12:45:23|call_center| true | true ... I|ADSL|8910|0|2010-08-29T12:45:23|call_center| true | false ... F|4 PS auth user which set that value Timestamp of actual value Service “owner” of the attributes 01
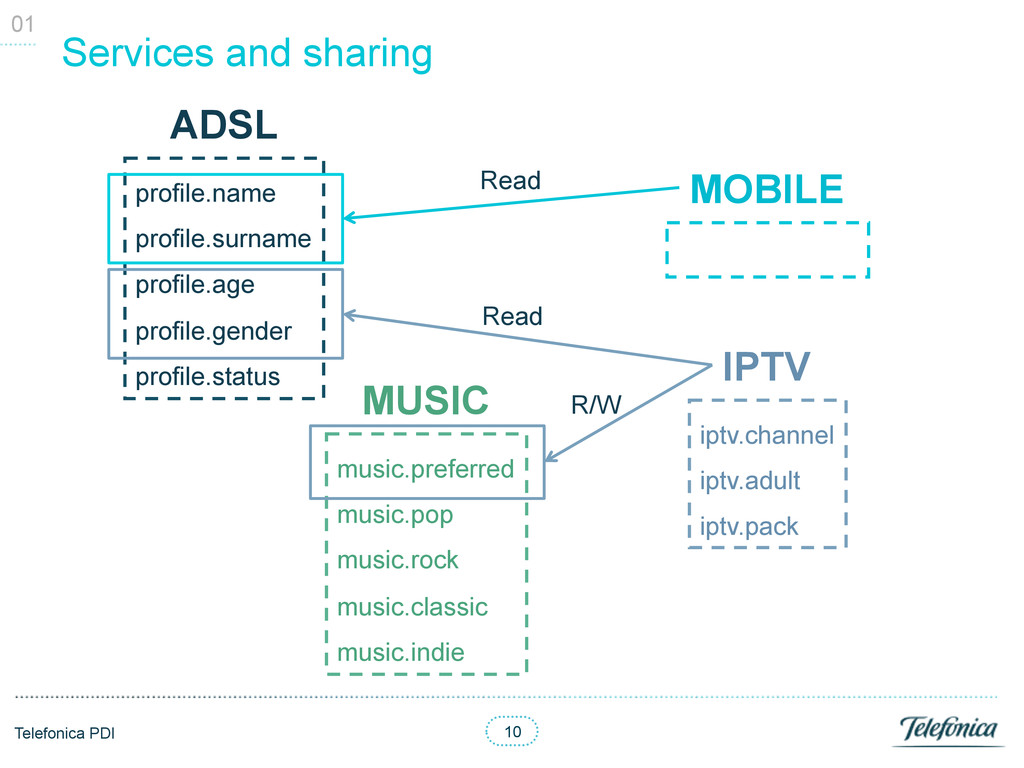
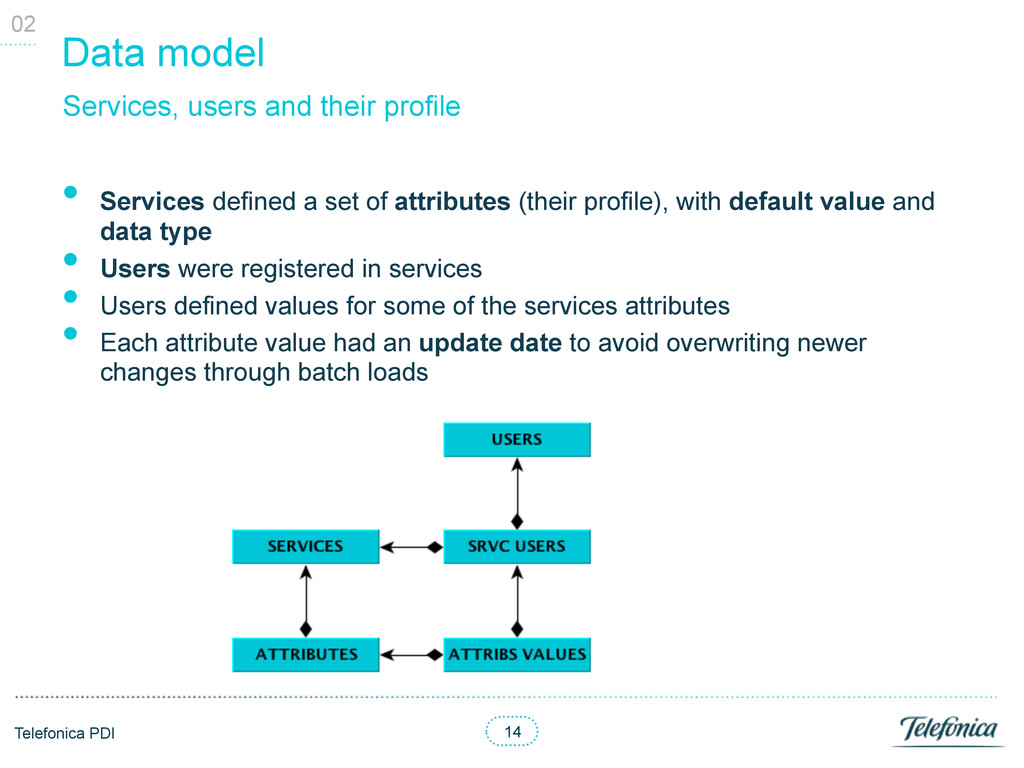
of attributes (their profile), with default value and data type • Users were registered in services • Users defined values for some of the services attributes • Each attribute value had an update date to avoid overwriting newer changes through batch loads Services, users and their profile 02
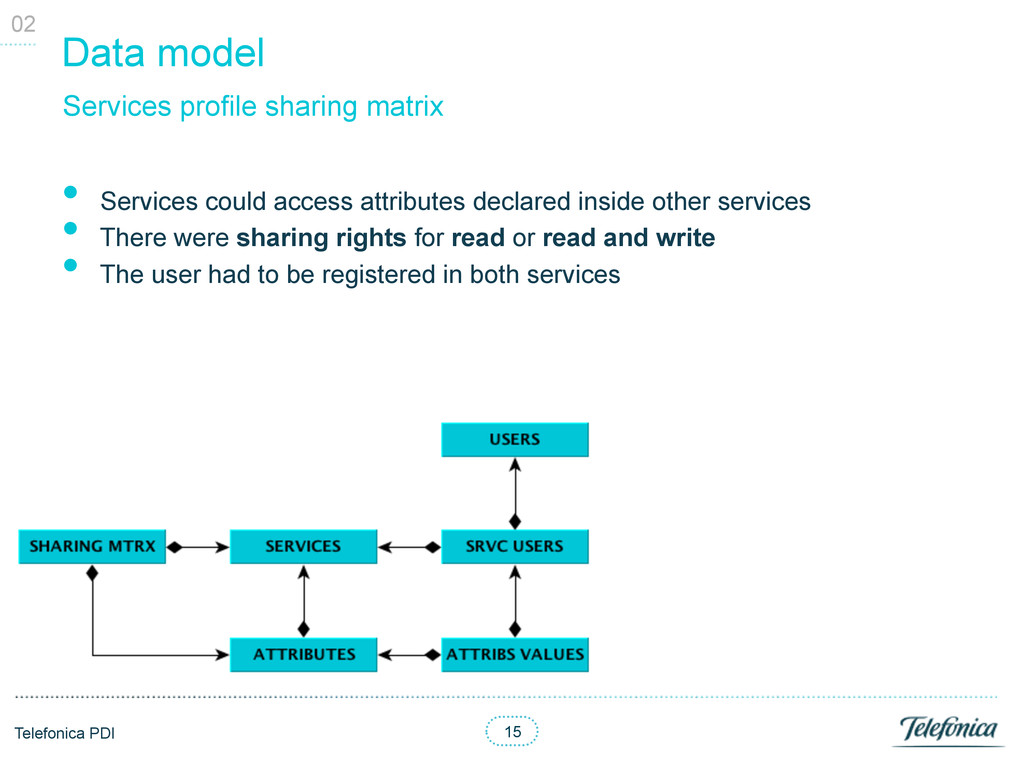
declared inside other services • There were sharing rights for read or read and write • The user had to be registered in both services Services profile sharing matrix 02
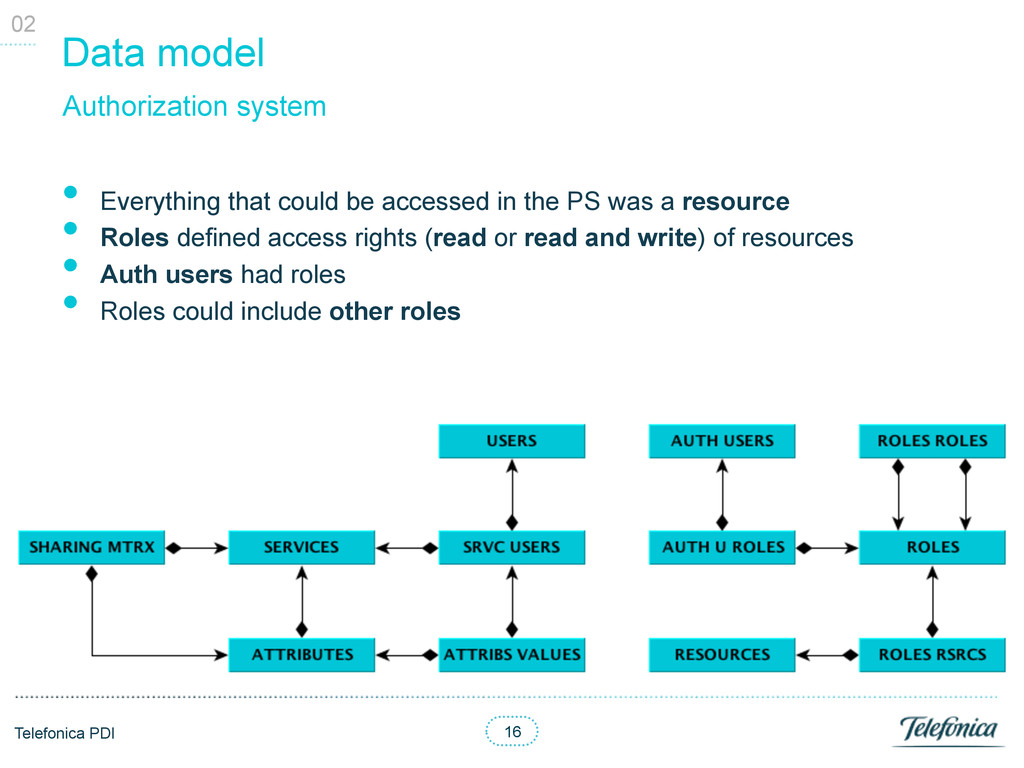
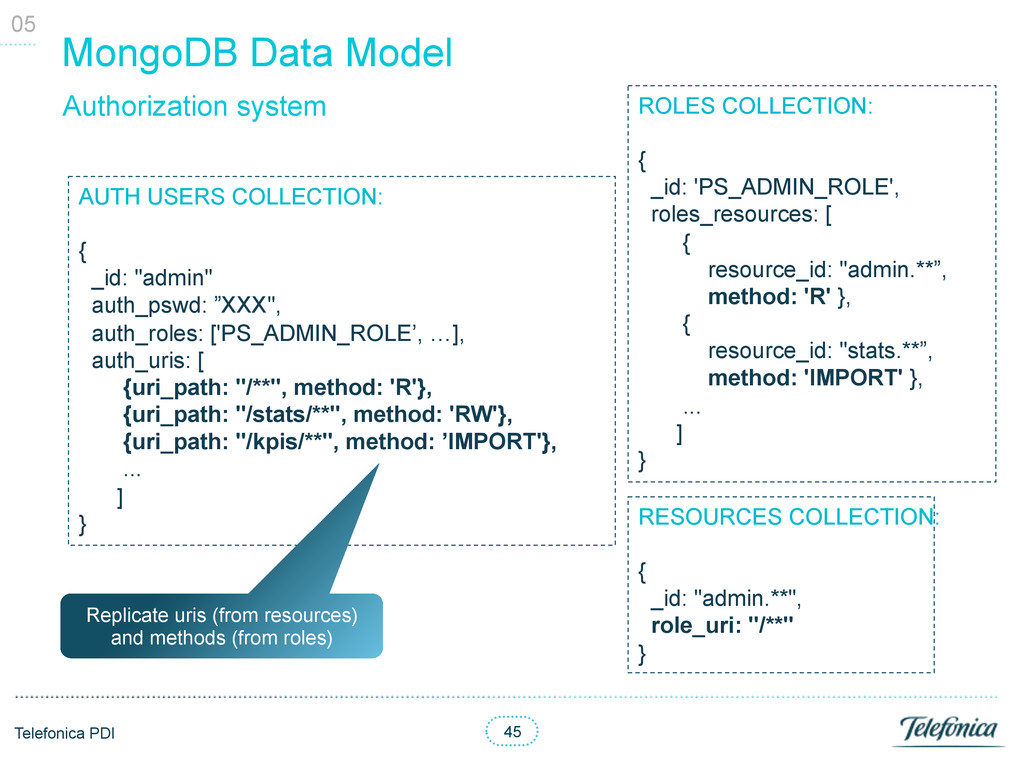
accessed in the PS was a resource • Roles defined access rights (read or read and write) of resources • Auth users had roles • Roles could include other roles Authorization system 02
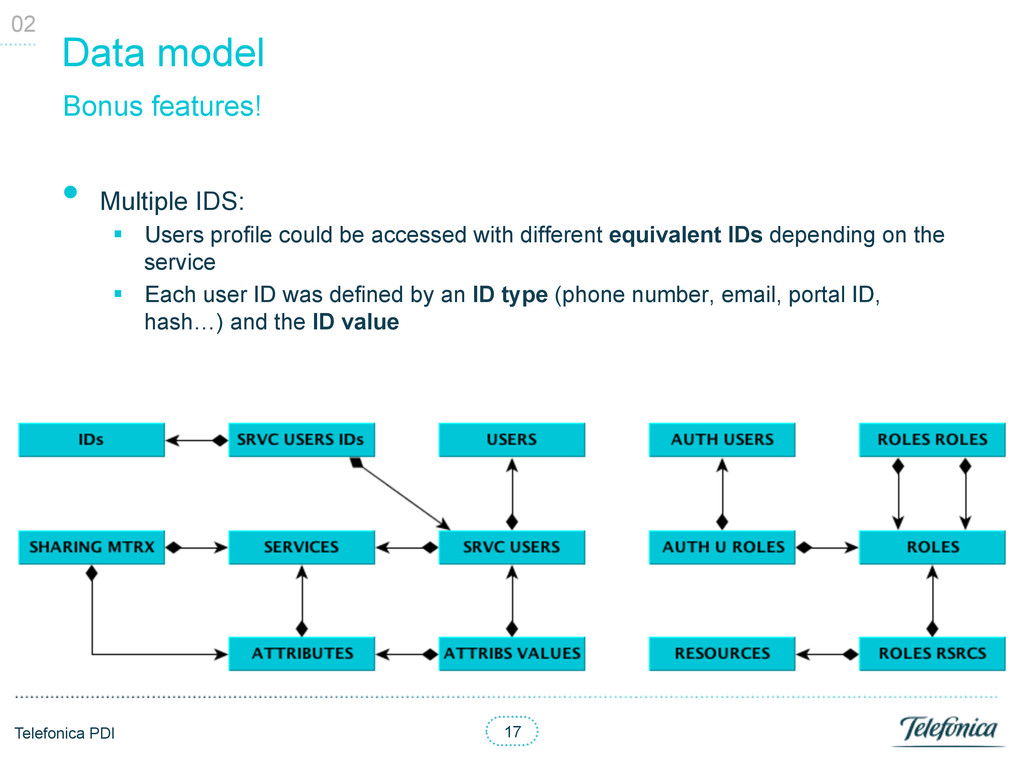
profile could be accessed with different equivalent IDs depending on the service § Each user ID was defined by an ID type (phone number, email, portal ID, hash…) and the ID value Bonus features! 02
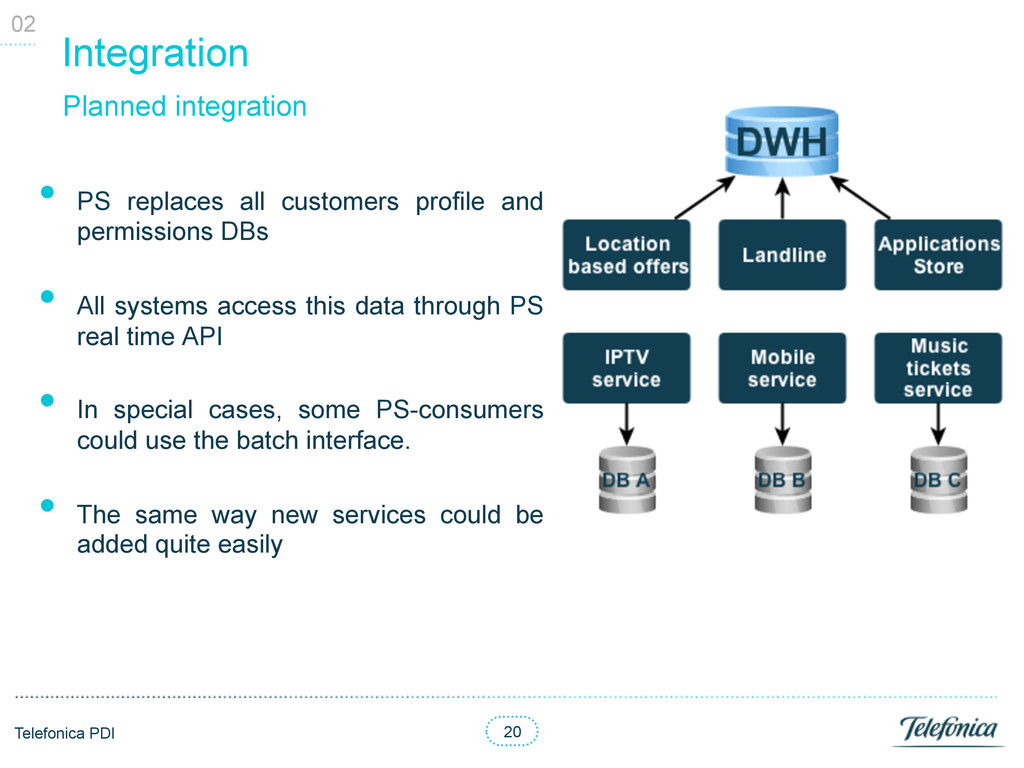
and permissions DBs • All systems access this data through PS real time API • In special cases, some PS-consumers could use the batch interface. • The same way new services could be added quite easily Planned integration 02
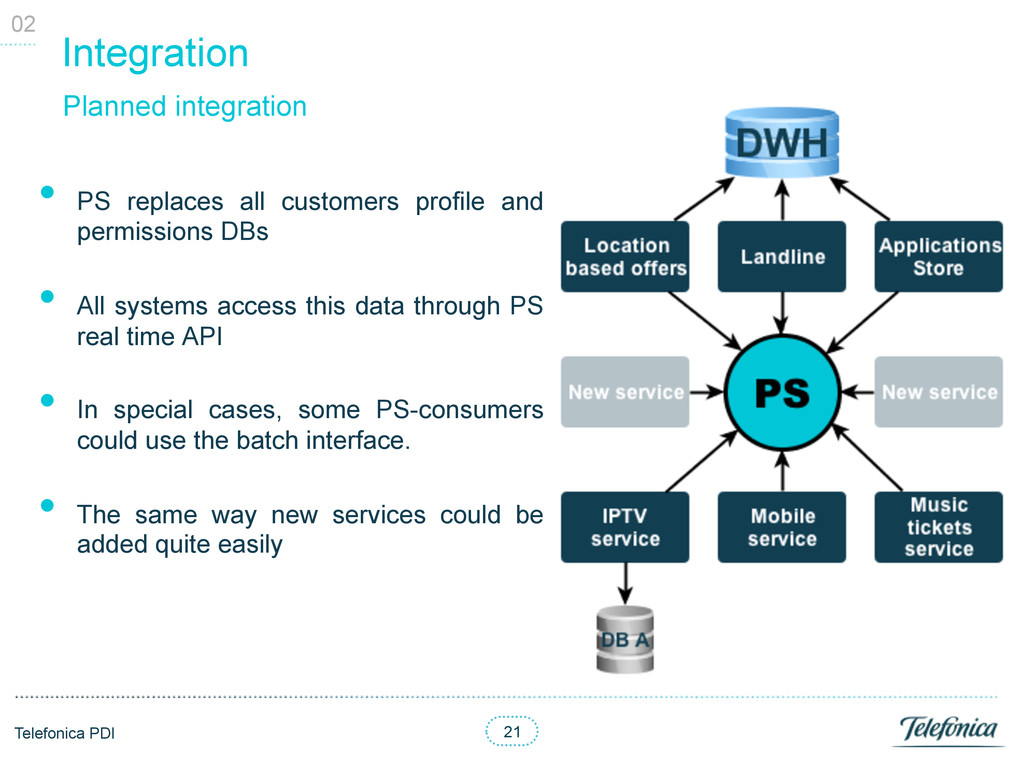
and permissions DBs • All systems access this data through PS real time API • In special cases, some PS-consumers could use the batch interface. • The same way new services could be added quite easily Planned integration 02
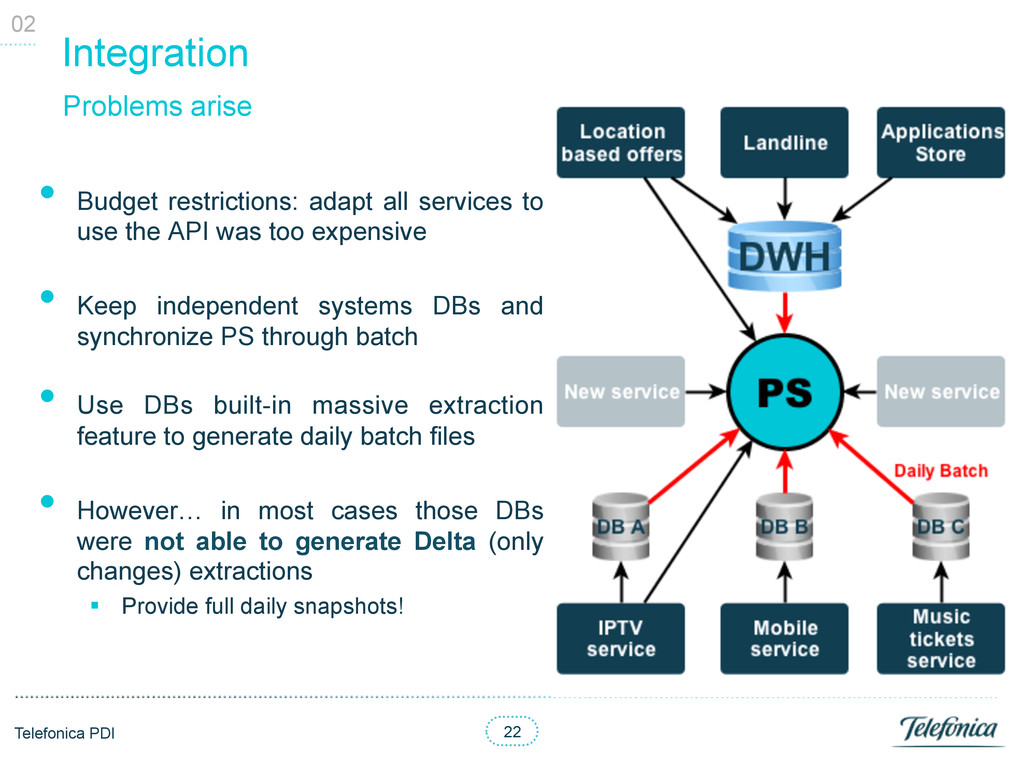
to use the API was too expensive • Keep independent systems DBs and synchronize PS through batch • Use DBs built-in massive extraction feature to generate daily batch files • However… in most cases those DBs were not able to generate Delta (only changes) extractions § Provide full daily snapshots! Problems arise 02
§ Validate authen,ca,on and authoriza,on § Verify user, service and a6ribute existence § Check equivalent IDs § Validate sharing matrix rights § Validate values data type § Check the update date of the exis,ng values 03 Batch processes
in BE servers § Validate format, services and attributes existence and values data types § Generate intermediate file with structure like target DB table • Load intermediate file (Oracle’s SQL*Loader) to a temporal table • Switch DB to “deferred writing”, storing all incoming modifications • Merge temporal table and final table, checking values update date • Replace old users attributes values table with merge result • Apply deferred writing operations 03 New DB-based batch loading process
table with format similar to final batch file. Two loops over users attributes values table required: § Select format of the table; number and order of columns / attributes § Fill the new table • Loop the whole temporal table for final formatting (empty fields…) • From batch side loop across the whole table (SELECT * FROM …) • Write each retrieved row as a line in the resulting file 03 New batch extraction process
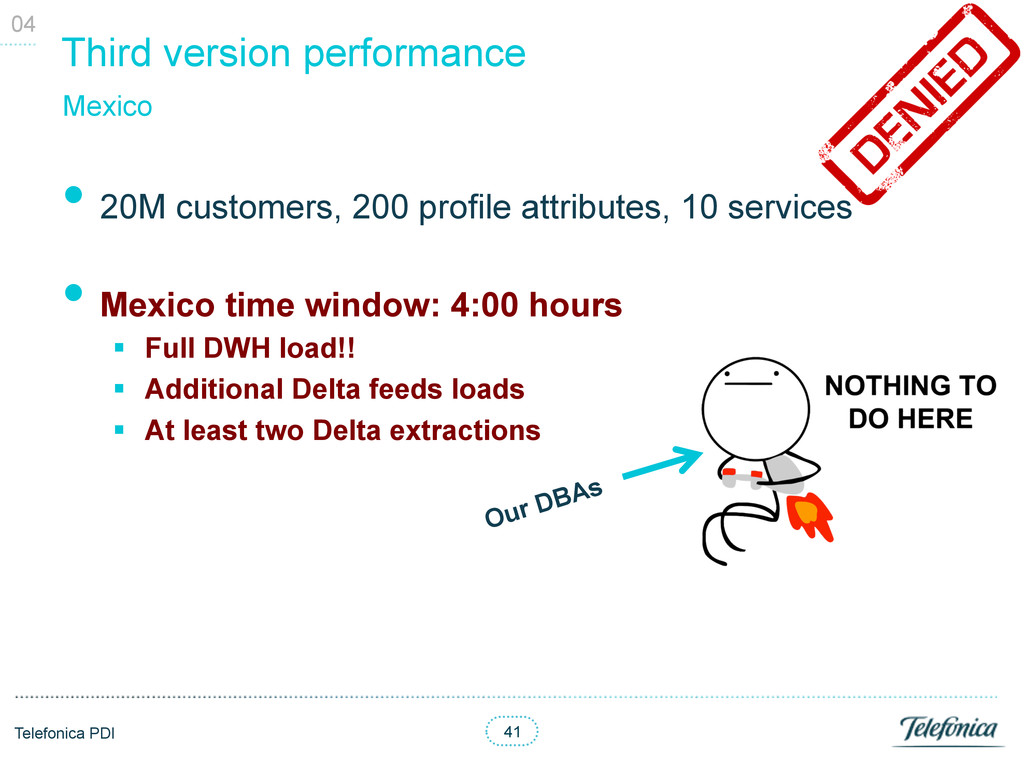
profile attributes, 6 services • Sizes § Tables + indexes size: 65Gb § 30% of the size were indexes § Temporal tables size increases almost exponentially: 15Gb and above § Intermediate file size: from 700Mb to 7Gb • Batch § Full DWH customer’s profile import: 2:30 hours § Delta extractions: 1:00 hour § Loads performance worsened quickly (almost exp): 6:00 hours § Extractions performance proportional to data size § Concurrent batch processes may halt the DB • API: § Response time with average traffic: 80ms § Response time while loading was unpredictable: >300ms 03 Ireland
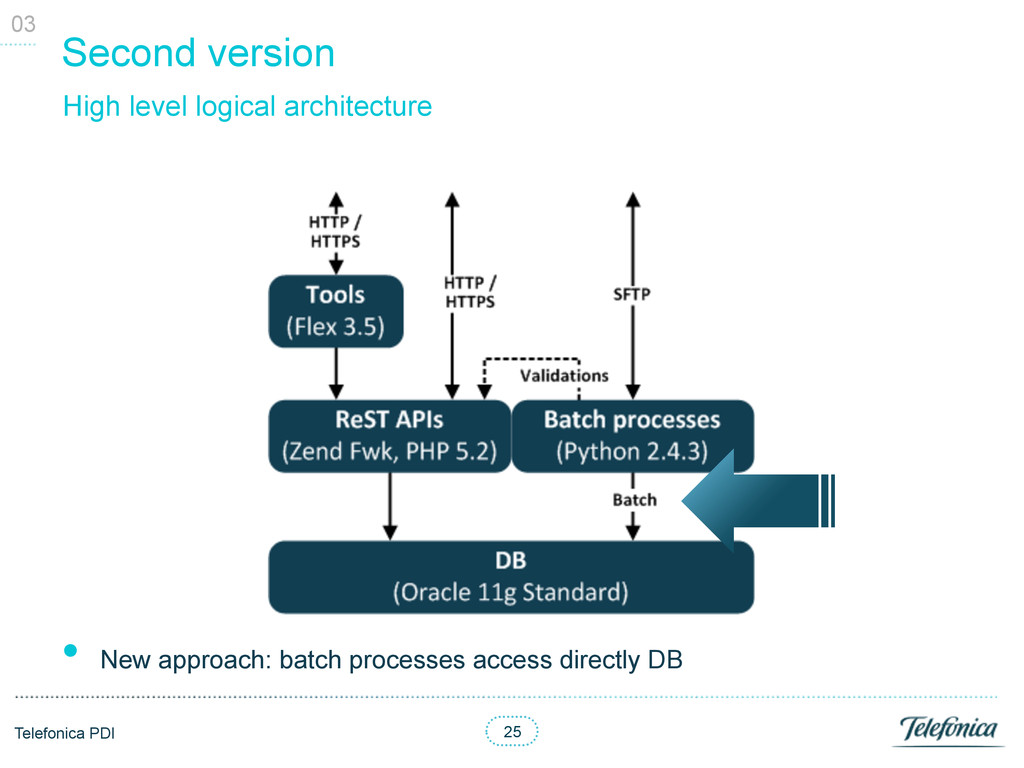
batch file in BE servers § Just validate format § No intermediate file needed! • Load validated file (Oracle’s SQL*Loader) to a temporal table • Loop the temporal table merging the values into final table, checking values update date and data types § Use several concurrent writing jobs • Store results on real table, no need to replace! • No “deferred writing”! 04 New (second) DB-based batch loading process
temporal output table. § Use several concurrent writing jobs § We achieved a speed-up of between 1.5 and 2 • Loop the whole temporal table for final formatting (empty fields…) • Download and write lines directly inside Oracle’s sqlplus • No SELECT * FROM … query from Batch side! 04 Enhancements to extraction process
• 25M customers, 150 profile attributes, 15 services • Sizes § Tables + indexes size: 700Gb § 40% of the size were indexes • Batch § Two Delta imports: < 2:00 hours § Two Delta extractions: < 2:00 hours § Loads and extractions performance proportional to data size • API: § Response time with average traffic: 90ms 04 United Kingdom
04 Ireland 3rd version 2nd version DB size 65Gb + 15Gb (temp) 65Gb + > 15Gb Full DWH load 1:10 hours 2:30 hours Three Delta exports 2:15 hours 3:00 hours Batch stability Stable, linear Unstable, exponential API response time 110ms 110ms API while loading 400ms Unpredictable United Kingdom 3rd version DB size 700Gb Two Delta loads < 2:00 hours Three Delta exports < 2:00 hours API response time 90ms
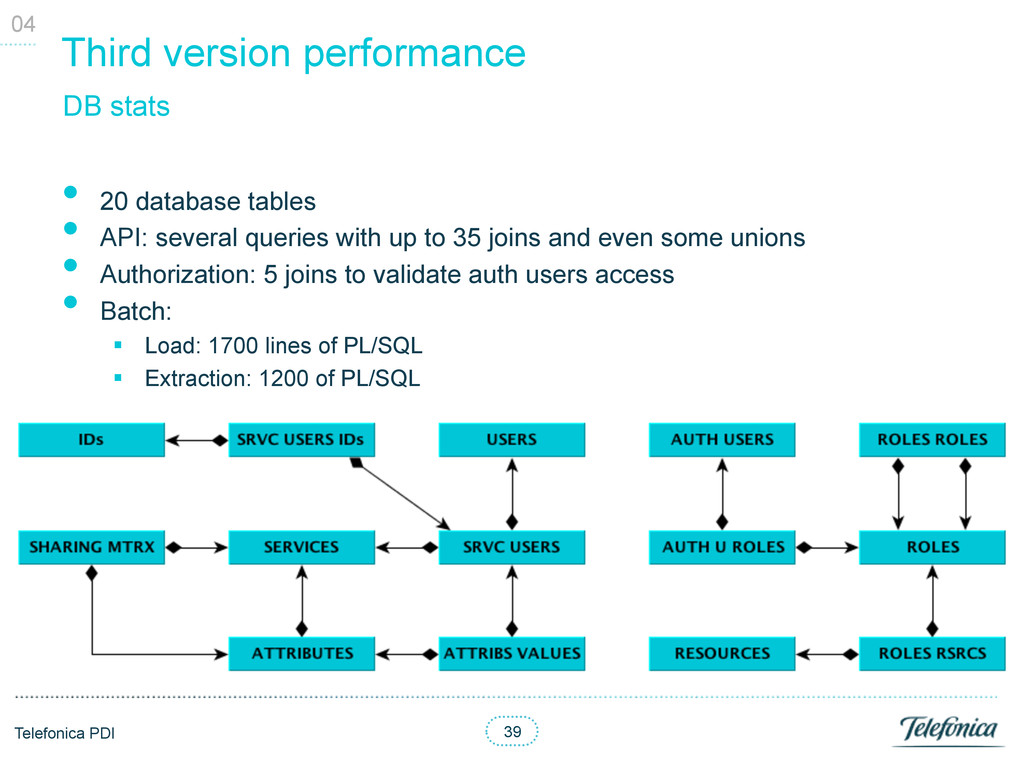
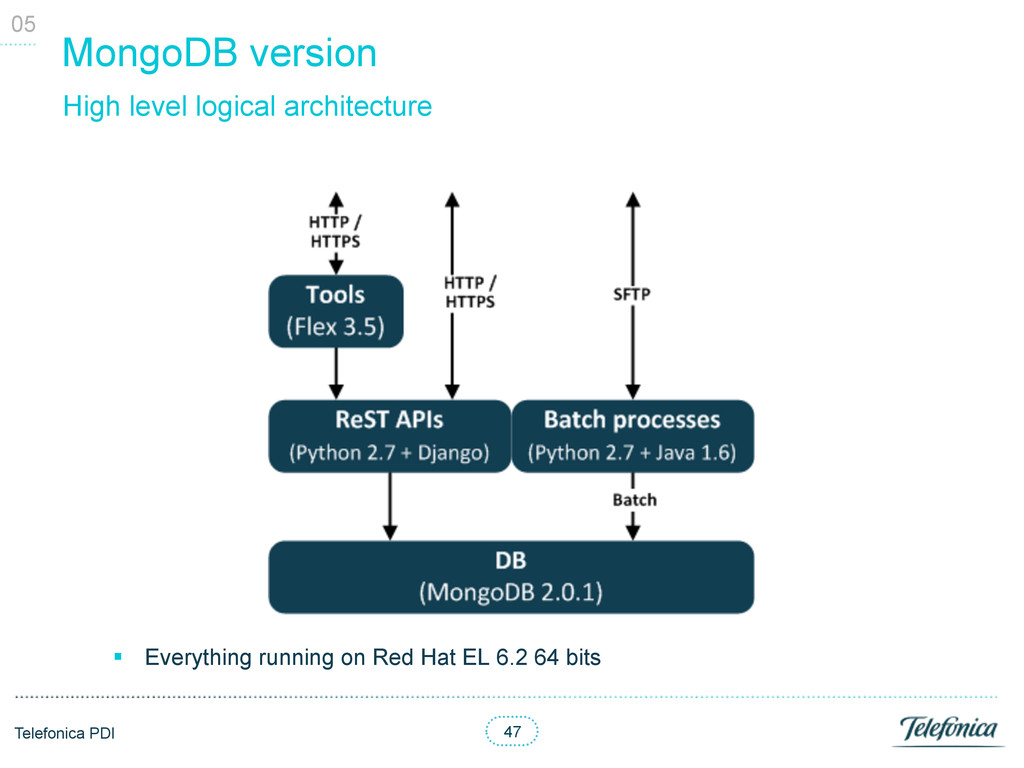
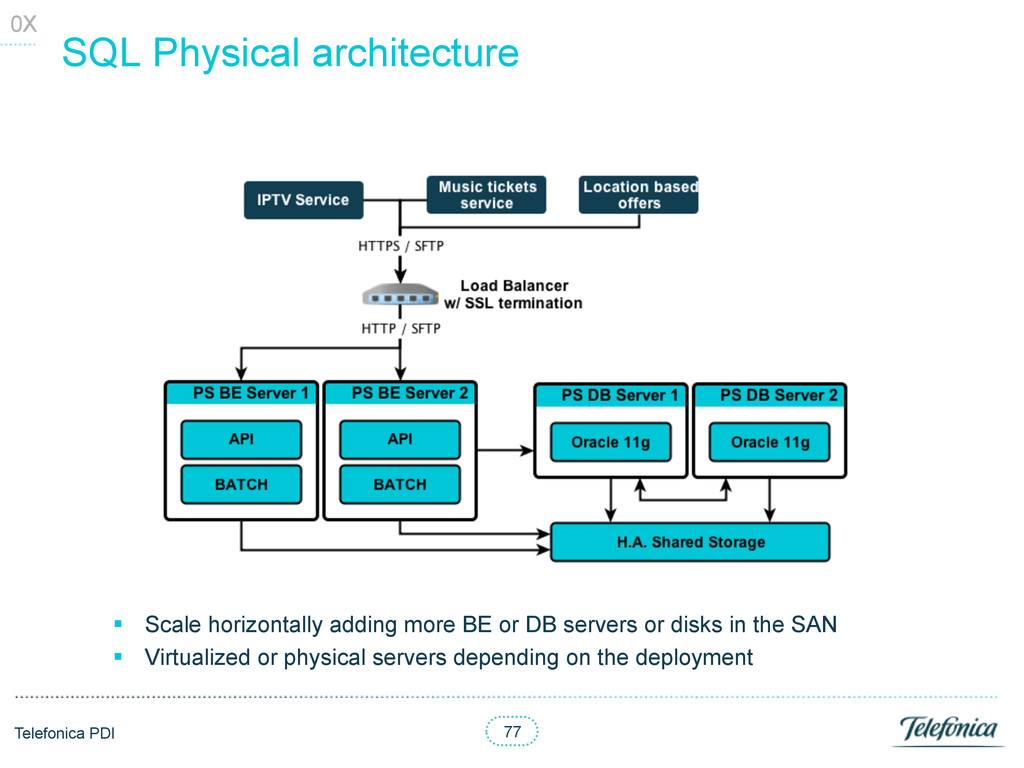
• API: several queries with up to 35 joins and even some unions • Authorization: 5 joins to validate auth users access • Batch: § Load: 1700 lines of PL/SQL § Extraction: 1200 of PL/SQL 04 DB stats
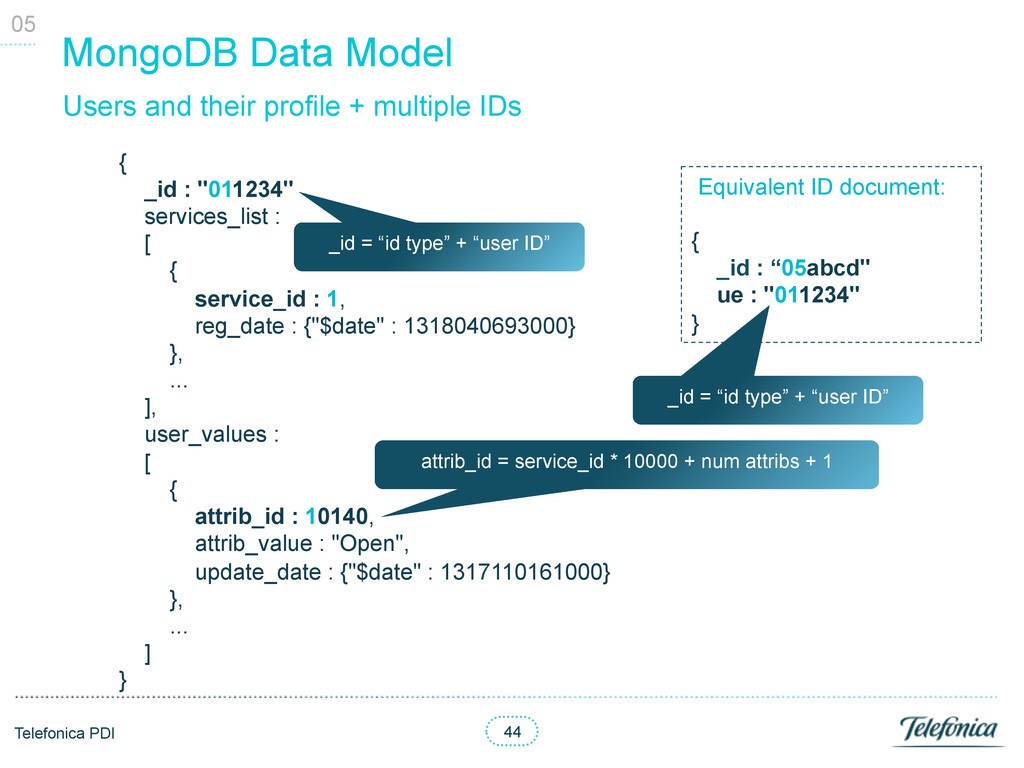
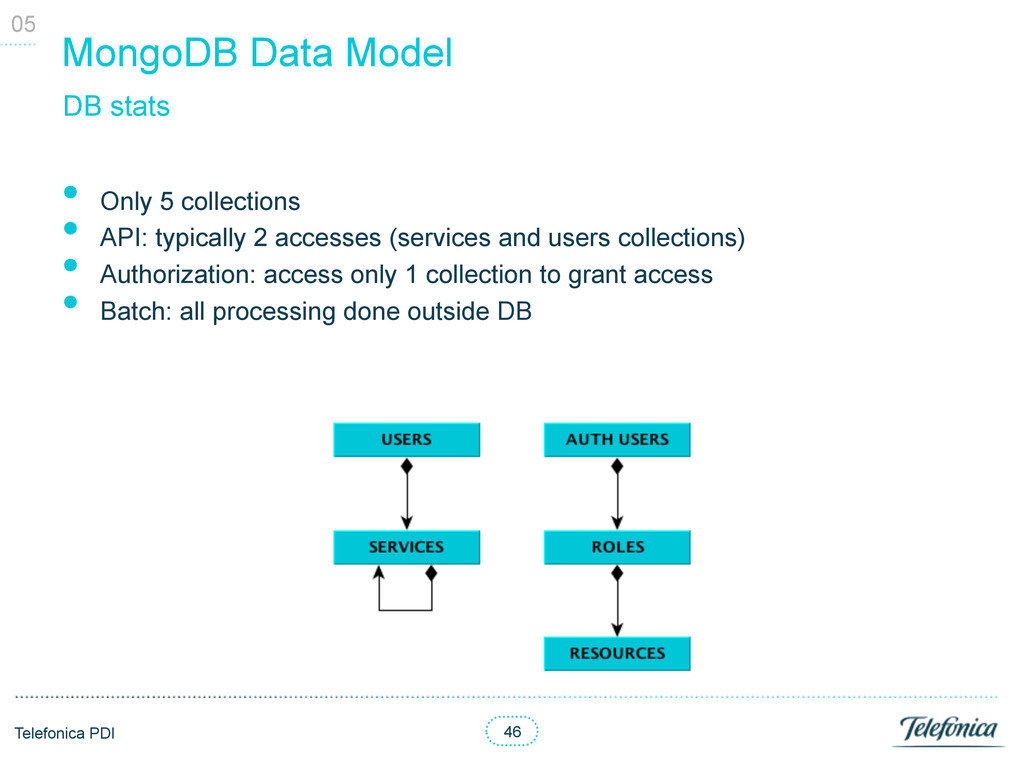
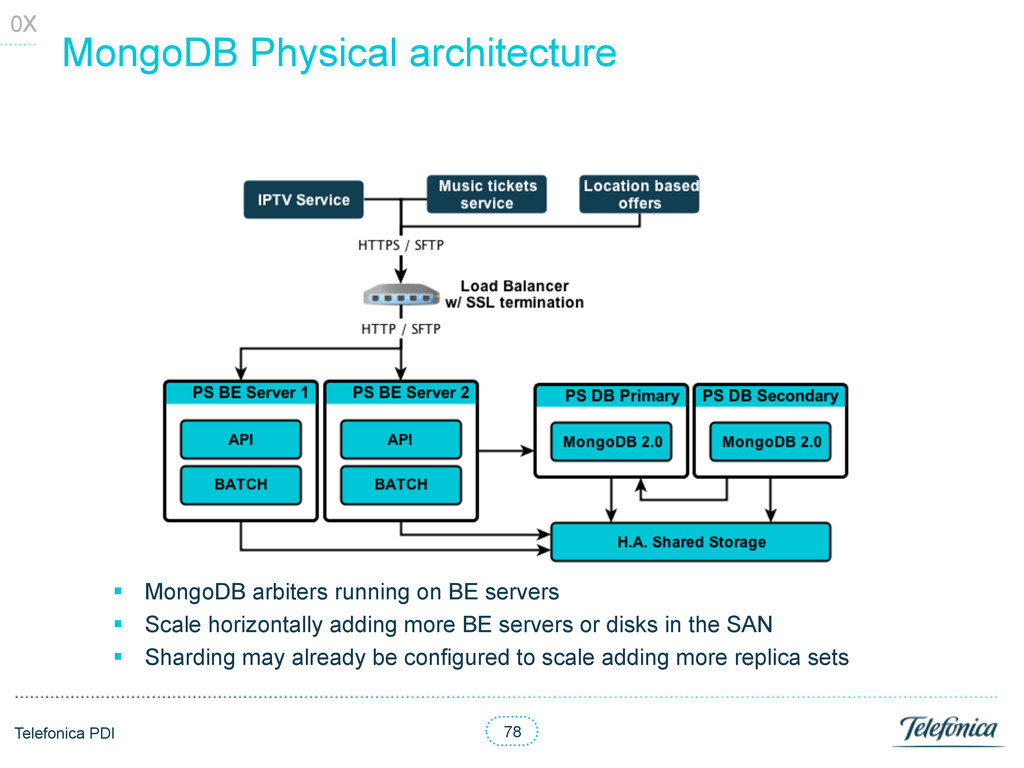
• API: typically 2 accesses (services and users collections) • Authorization: access only 1 collection to grant access • Batch: all processing done outside DB 05 DB stats
NoSQL version SQL version DB size 20Gb 80Gb Full DWH load 0:12 hours 1:10 hours Three Delta exports 0:40 hours 2:15 hours API while loading < 10ms 400ms API 600TPS + loading 300ms Timeout / failure United Kingdom NoSQL version SQL version DB size 210Gb 700Gb Two Delta loads < 0:40hours < 2:00 hours Mexico NoSQL version DB size 320Gb Initial Full load (40 attr) 2:00 hours Daily Full load (6 attr) 0:40 hours API while loading < 10ms API 500TPS + loading 270ms
too fast § To keep secondary nodes synched we needed oplog of 16 or 24Gb § We had to disable journaling for the first migrations • Labels of documents fields take up disc space § We reduce them to just 2 chars (“attribute_id” -> “ai”) and saved 12% aprox. • Respect the unwritten law of at least 70% of size in RAM • Always one index, but take care with compound indexes, order matters § You can save one index… or you can have problems § Put most important key (never nullable) the first one • DBAs whining and complaining about NoSQL § “If we had enough RAM for all data, Oracle would outperform MongoDB” 05
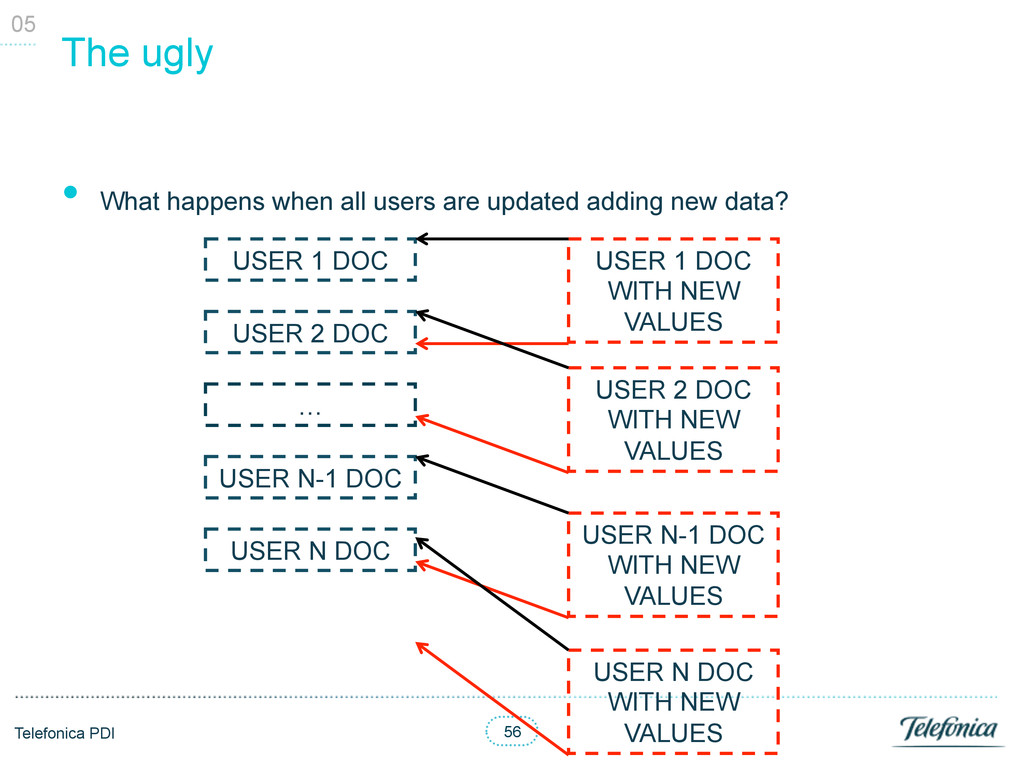
users are updated adding new data? 05 USER 1 DOC USER 2 DOC … USER N-1 DOC USER N DOC USER 1 DOC WITH NEW VALUES USER 2 DOC WITH NEW VALUES USER N-1 DOC WITH NEW VALUES USER N DOC WITH NEW VALUES
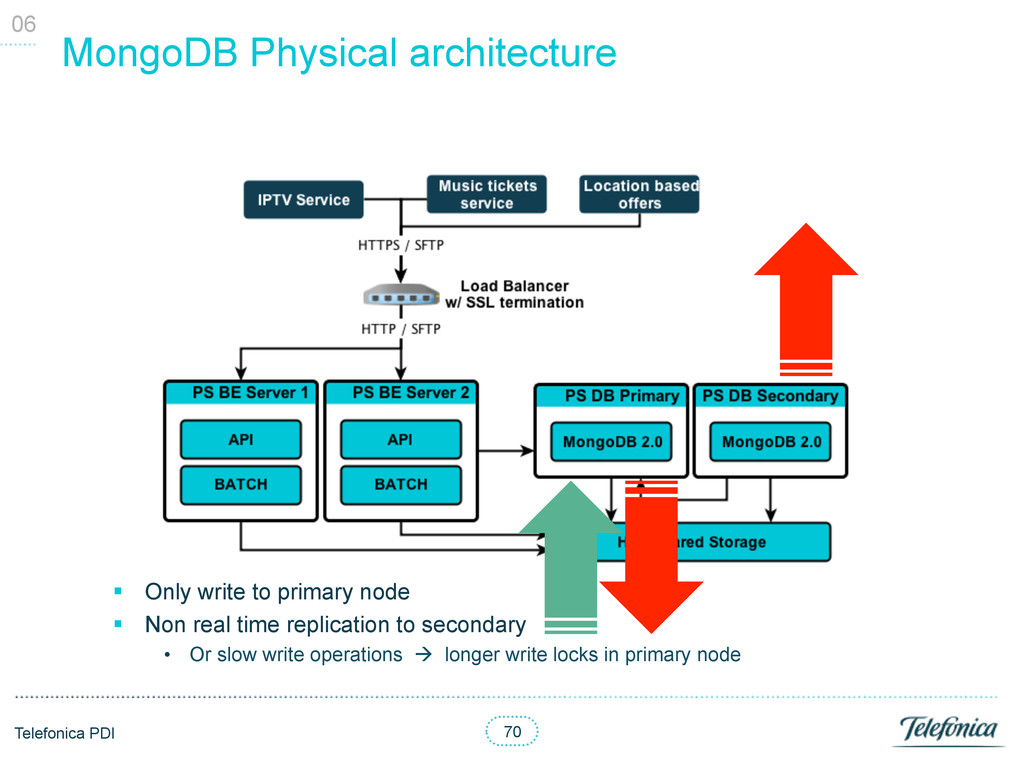
PS is already running § Full import adding 30 new attributes values: 10:00 hours § Full import adding 150 new attributes values: 40:00 hours • Increase considerably documents size (in our case adding lots of new values to the users) makes MongoDB rearrange the documents, performing around 5 times slower § That’s a problem when you are updating more than 10k documents per second • Solutions? § Avoid this situation at all cost. Run away! § Normalize users values; move to a new individual collection § Prealloc the size with a faux field • You would waste space! § Load in new collection, merge and swap, like we did in Oracle. Just kidding… 05
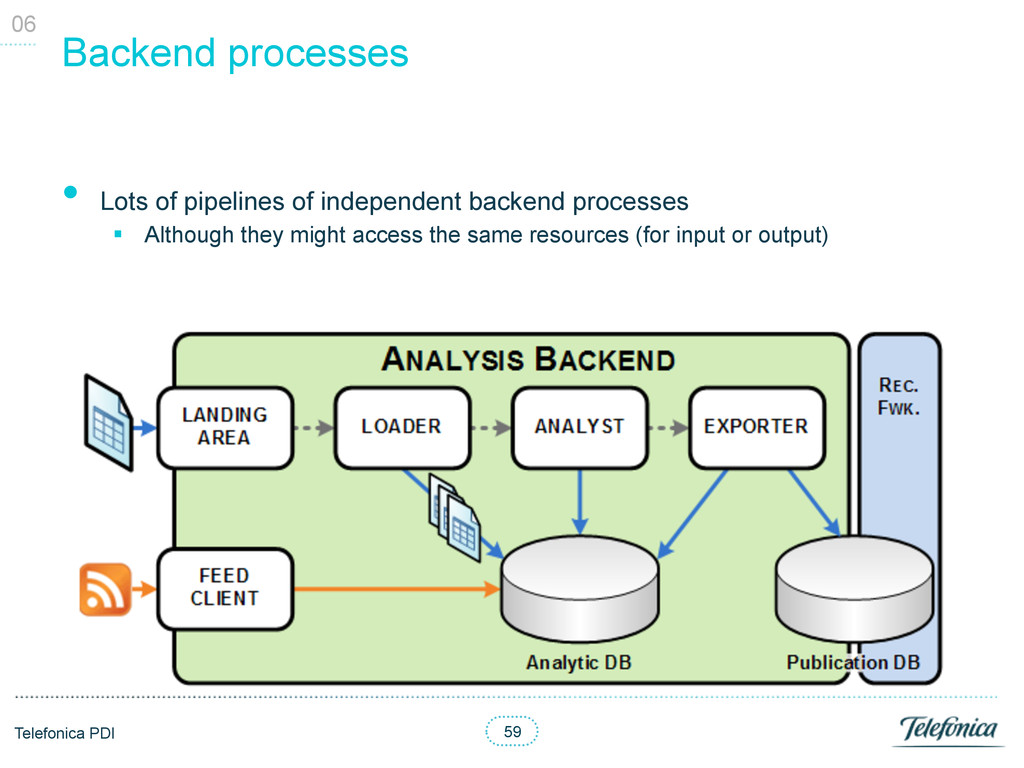
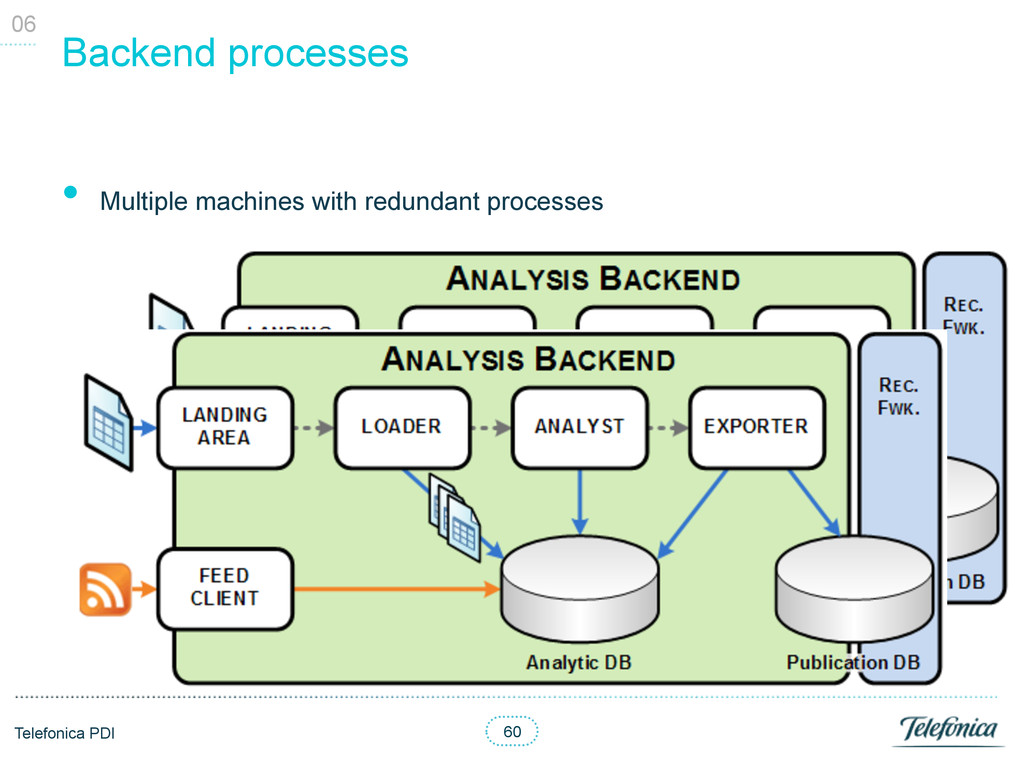
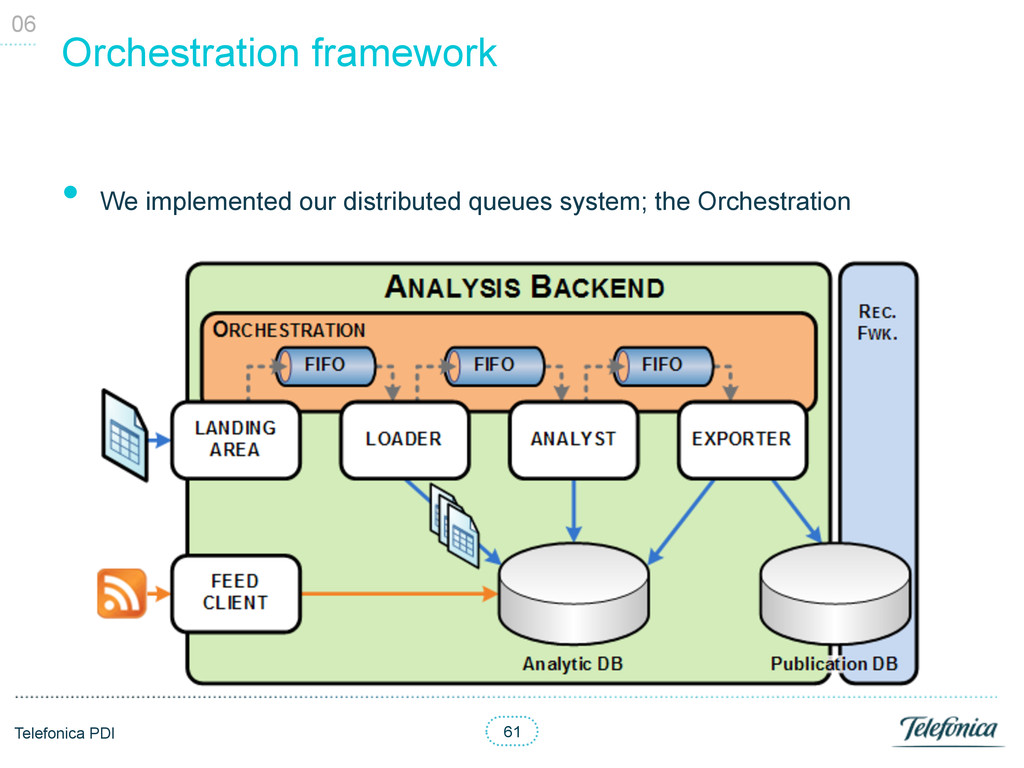
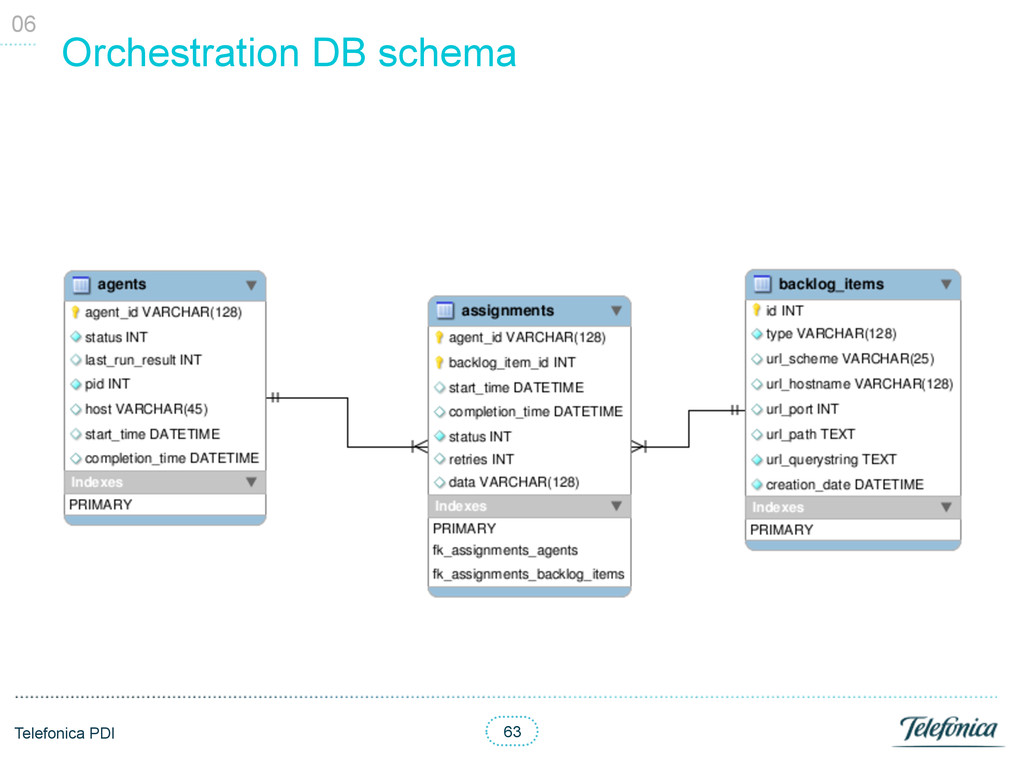
manage resources / tasks (Backlog Items) § Each Backlog Items had a type and the URI pointing to the resource • Each backend process (Agent) consumed and generated certain types § A Backlog Item could be assigned to several Agents § Running Agents could block / prevent other Agents execution • Distributed logic § Each Agent woke up on a certain periodicity § Each Agent was independent and agnostic of its pipeline § Each Agent had the logic to check if it could run § Each Agent had the logic the retrieve its own available Backlog Items • High availability and fault tolerance § Retries § Heart beat to monitor all Agents status • Synchronisation thanks to database transactions 06
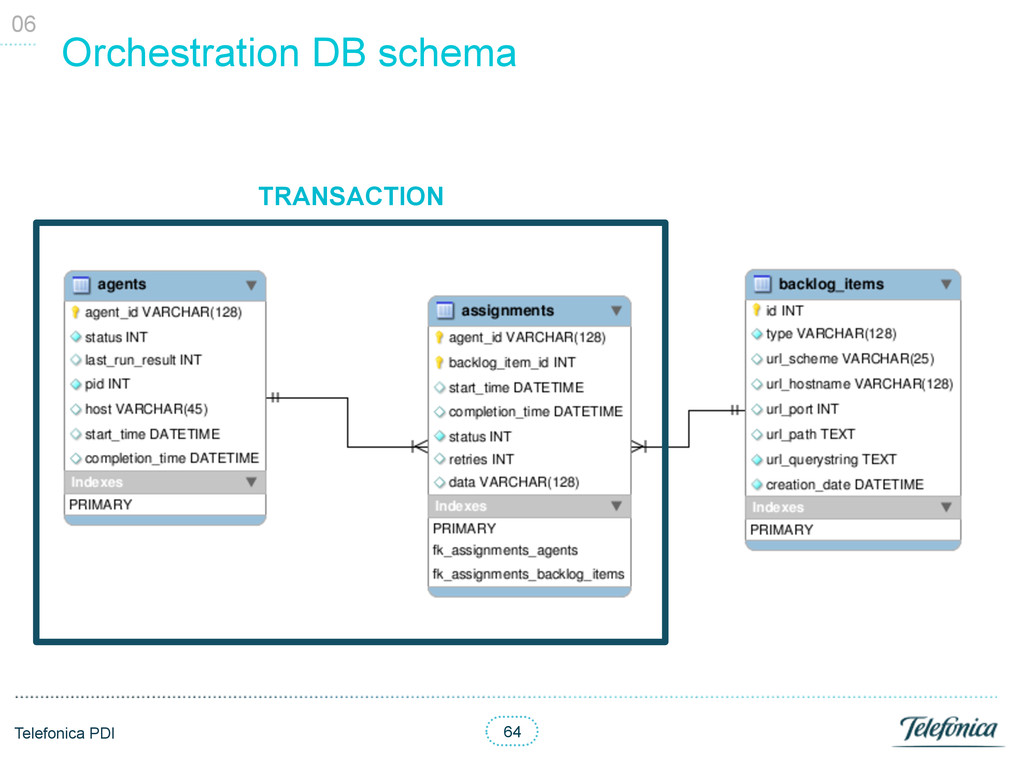
Agents • Two phase commits with an additional collection for “transactions” • Split transactions in two steps; update Agent as running and then update its Assignments 06
Agents § 16Mb document size limit! § Only denormalize active assignments à transaction needed to move them • Two phase commits with an additional collection for “transactions” § Create transaction as “pending” with ids of all involved documents § Update Agent status (and set pending transaction id) § Update or create each Assignment (and set pending transaction id) § Update transaction as “comitted” § Remove pending transaction from the Agent and each Assignment • Two steps process: update Agent as running and then update its Assignments § Lots of accesses too § Recovery more complicated 06
problems, no need to change • Not a clear profit • Too much possible pitfalls or disadvantages • Too much effort required • We left Orchestration in a relational database § MySQL running in both BE servers with master – master replication 06
boost with MongoDB § But not all use cases fit in a MongoDB / NoSQL solution! • New technology, different limitations • Fear of the unknown § “Young” technology. Mature enough? • Python + MongoDB + pymongo = fast development § I mean, really fast • MongoDB Monitoring Service (MMS) § 10gen people were very helpful • Lots of new paradigms with the wide variety of NoSQL solutions 07
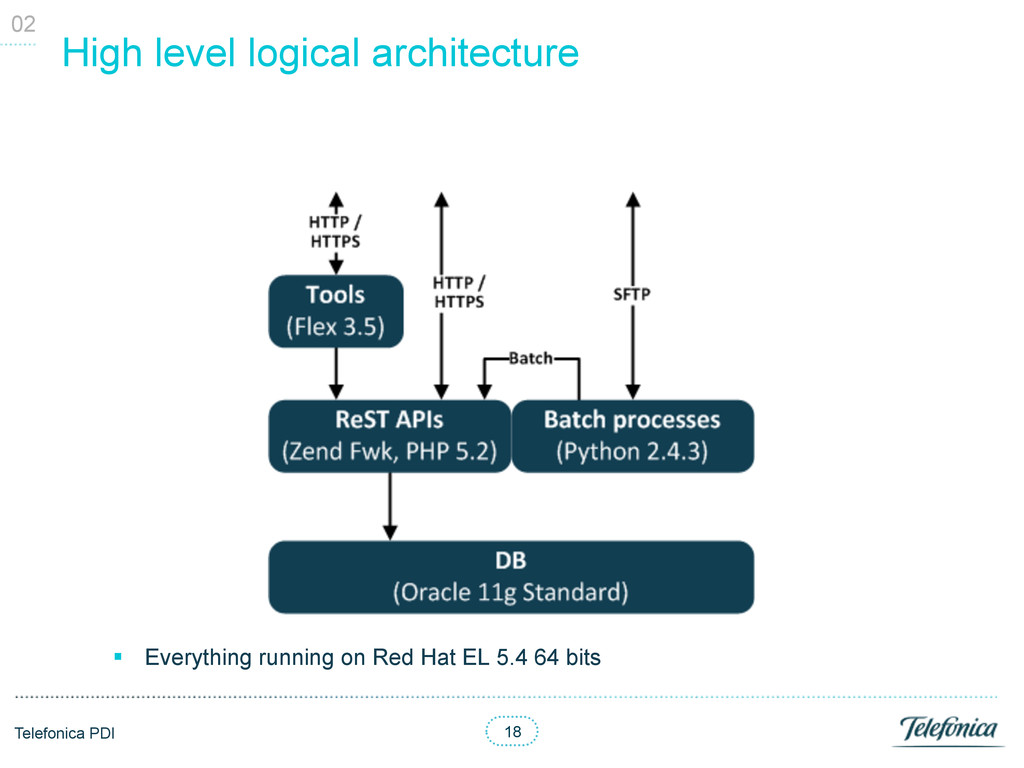
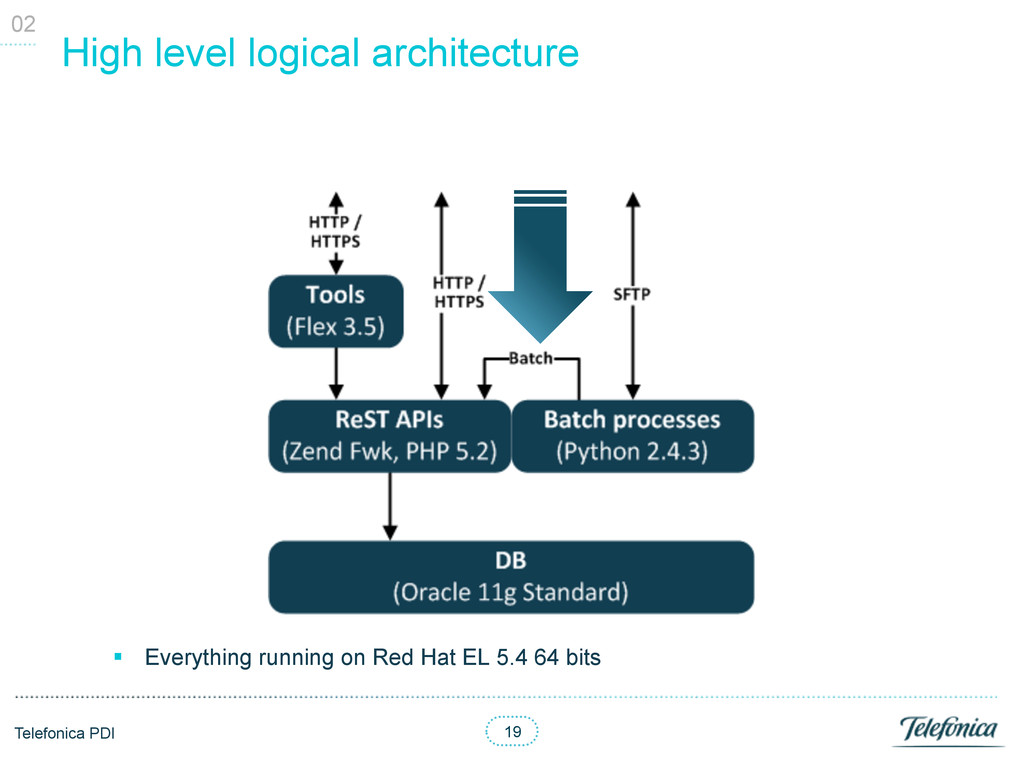
on BE servers § Scale horizontally adding more BE servers or disks in the SAN § Sharding may already be configured to scale adding more replica sets 0X
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}