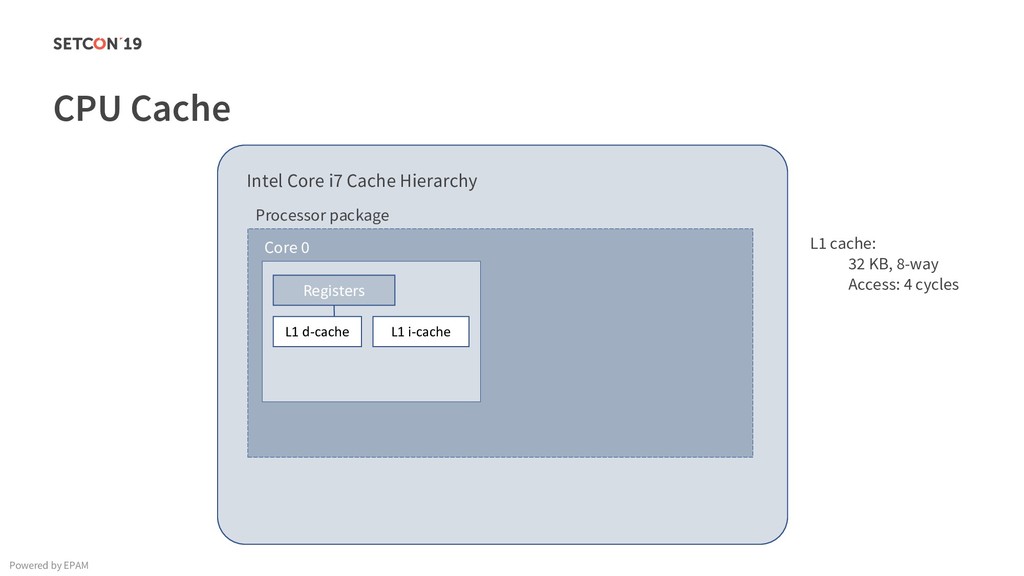
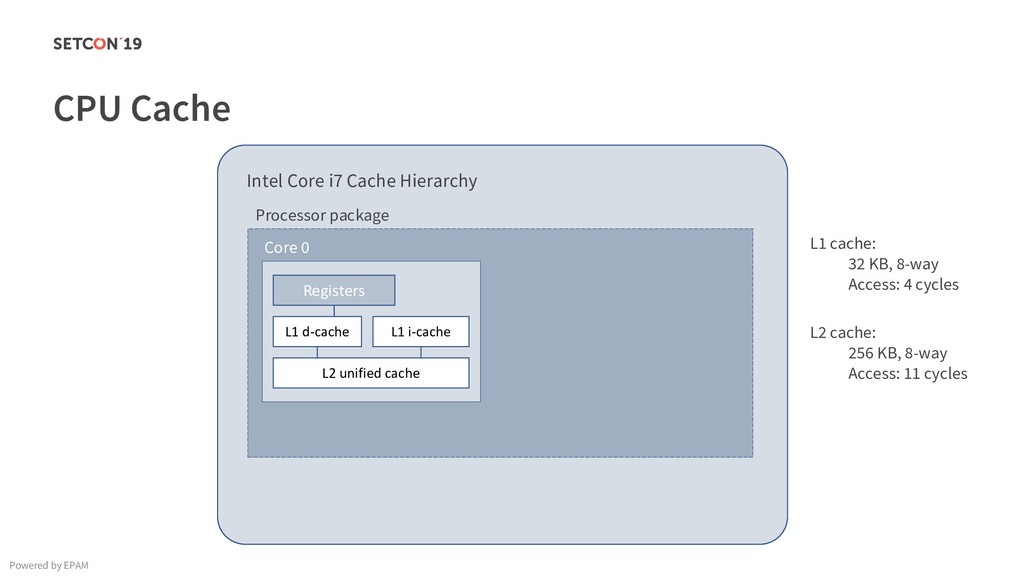
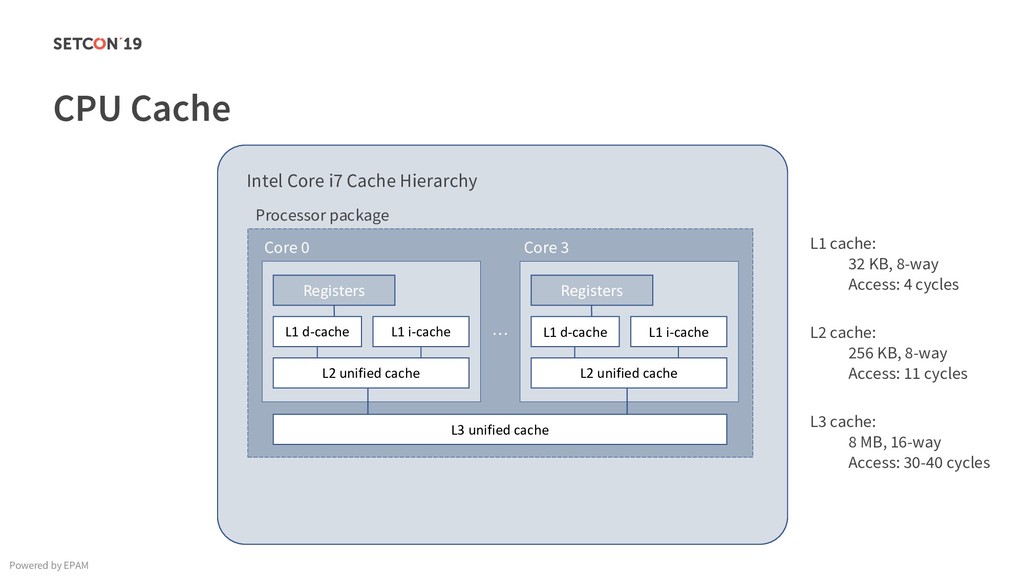
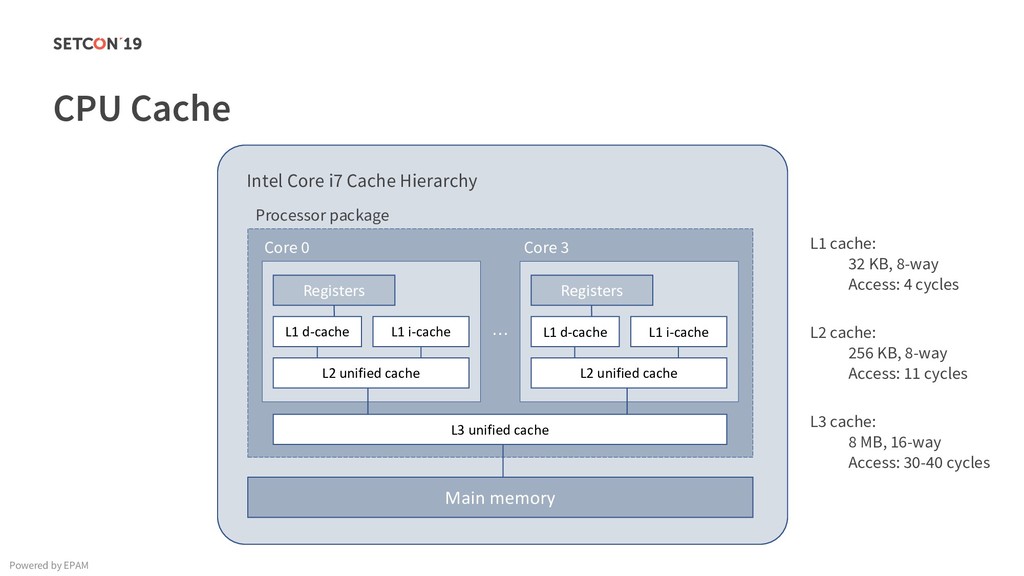
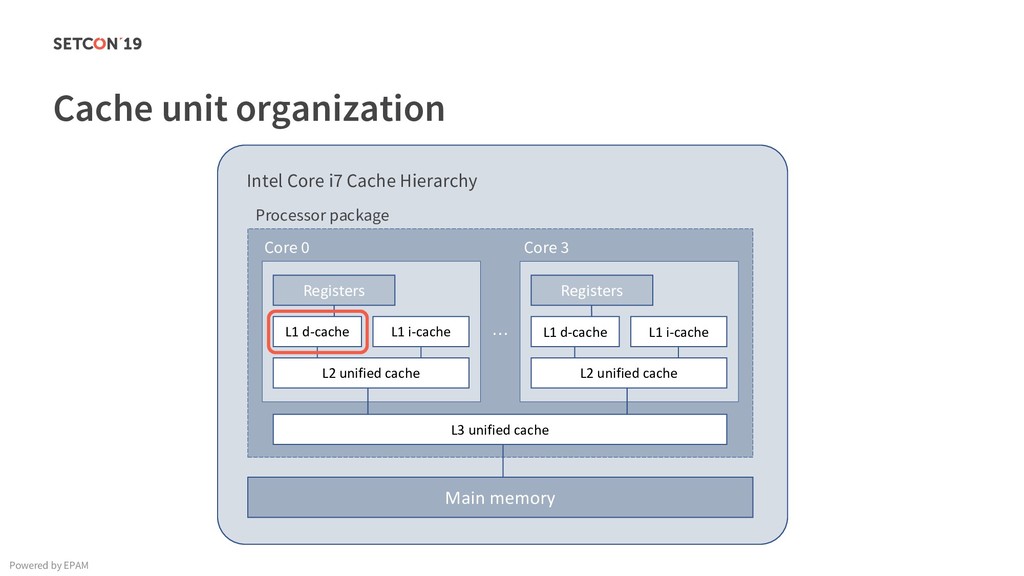
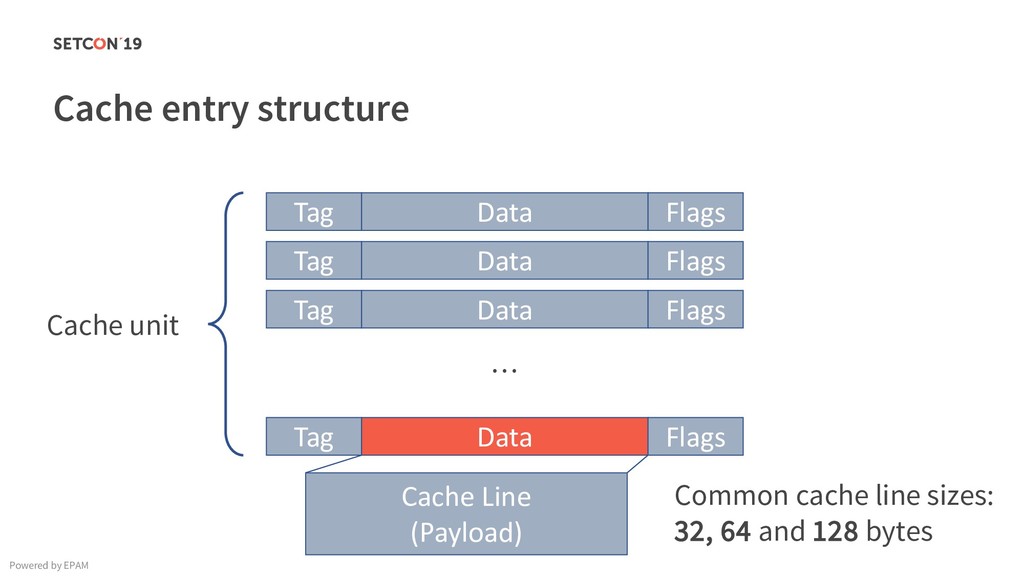
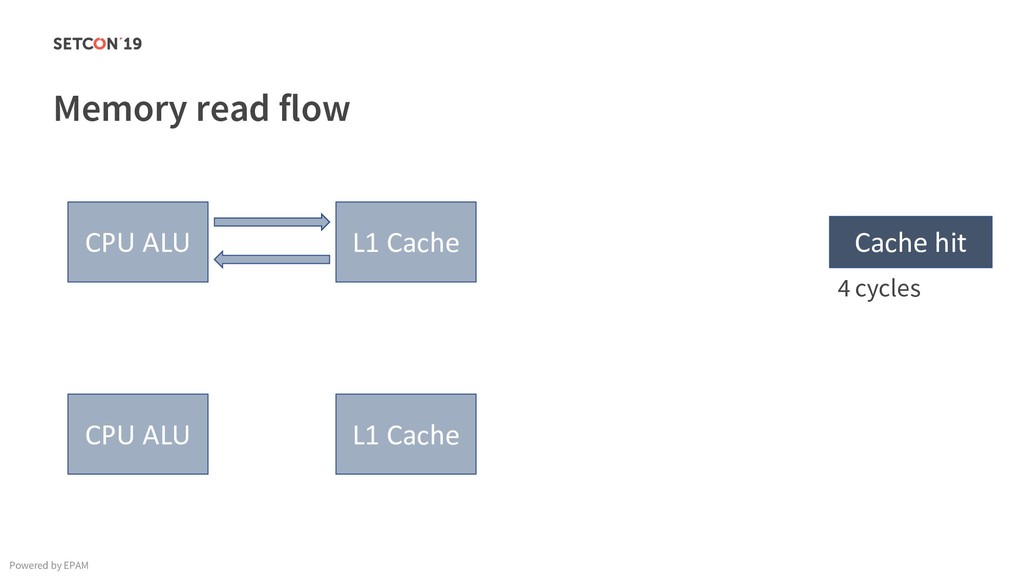
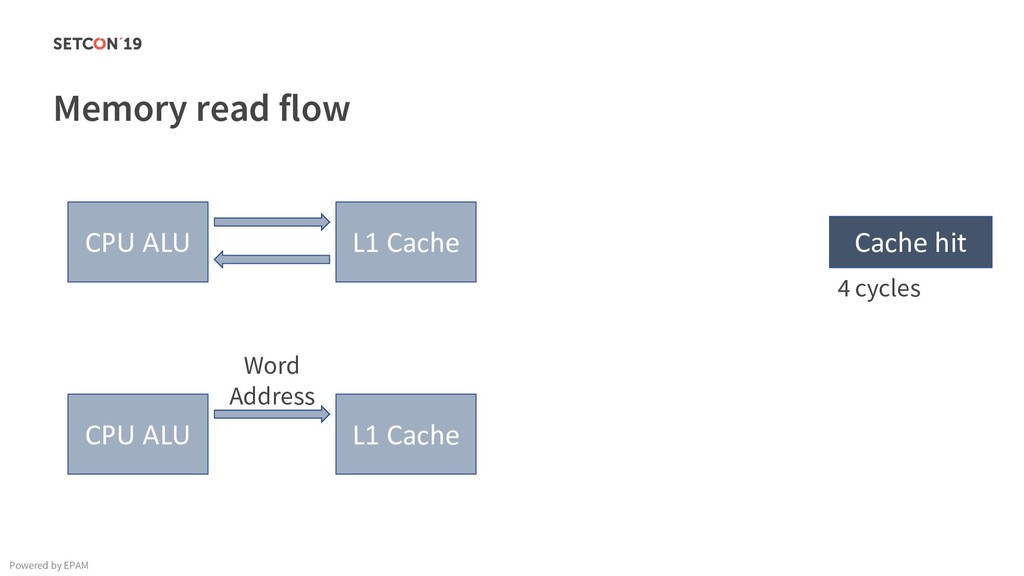
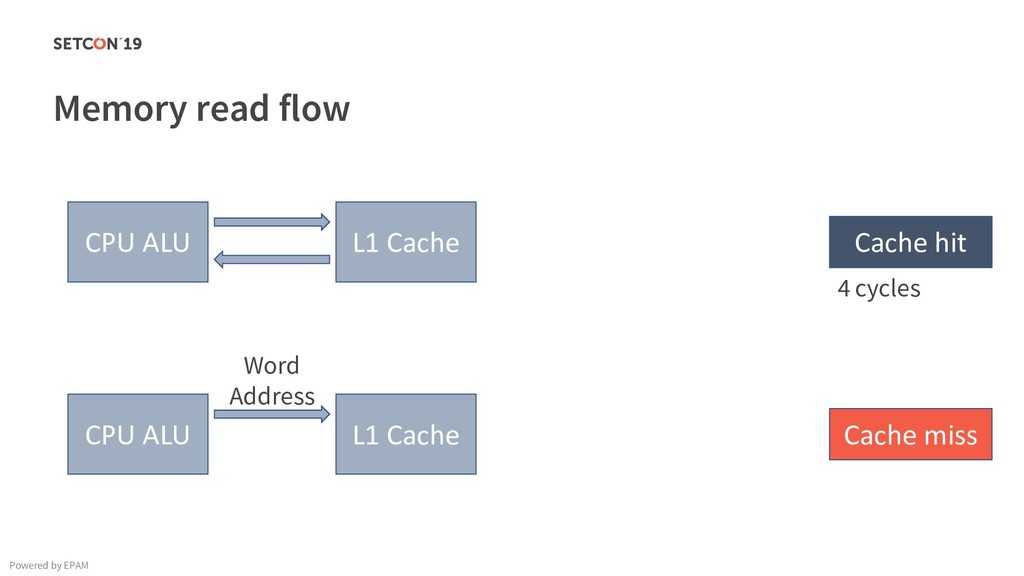
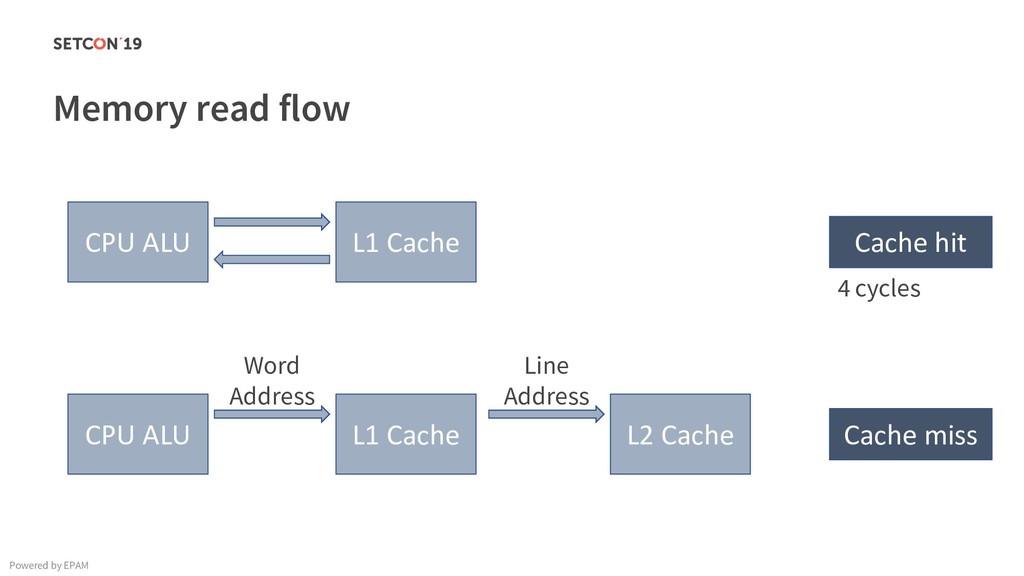
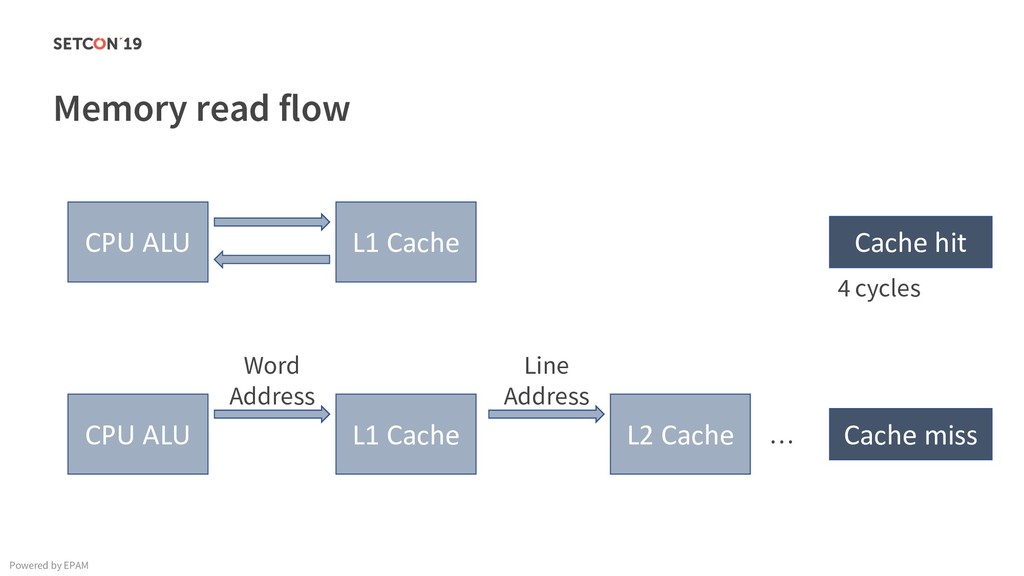
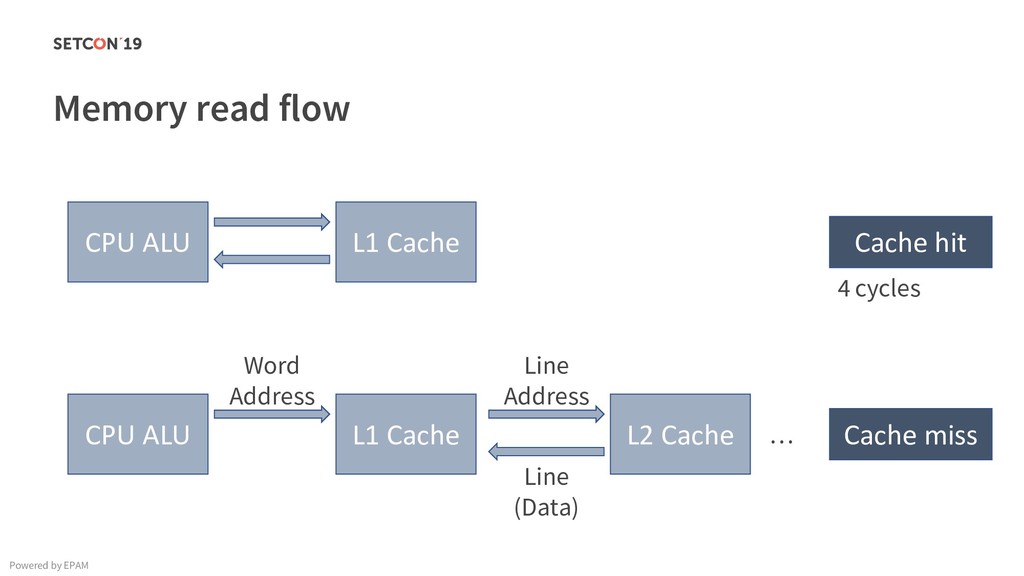
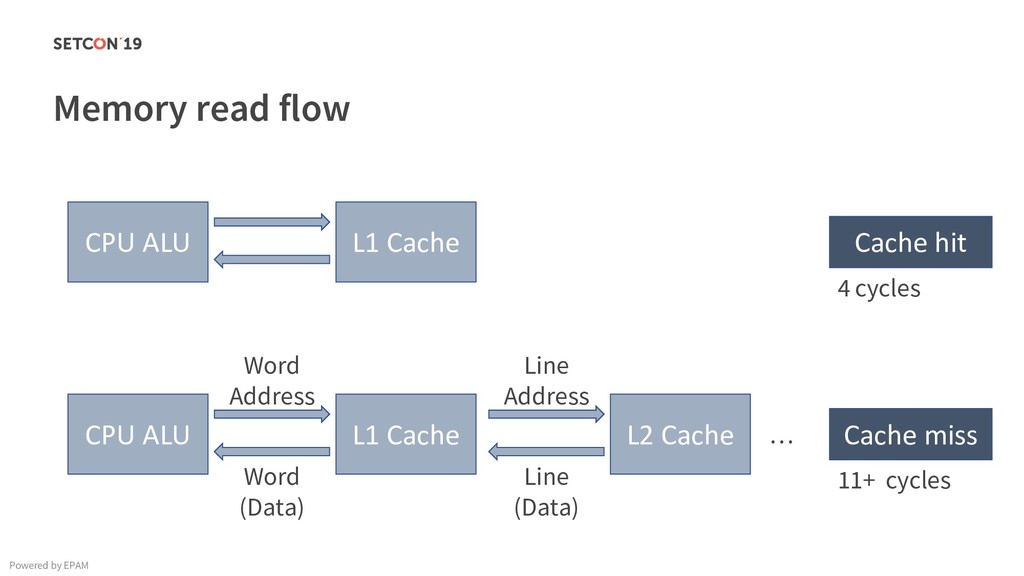
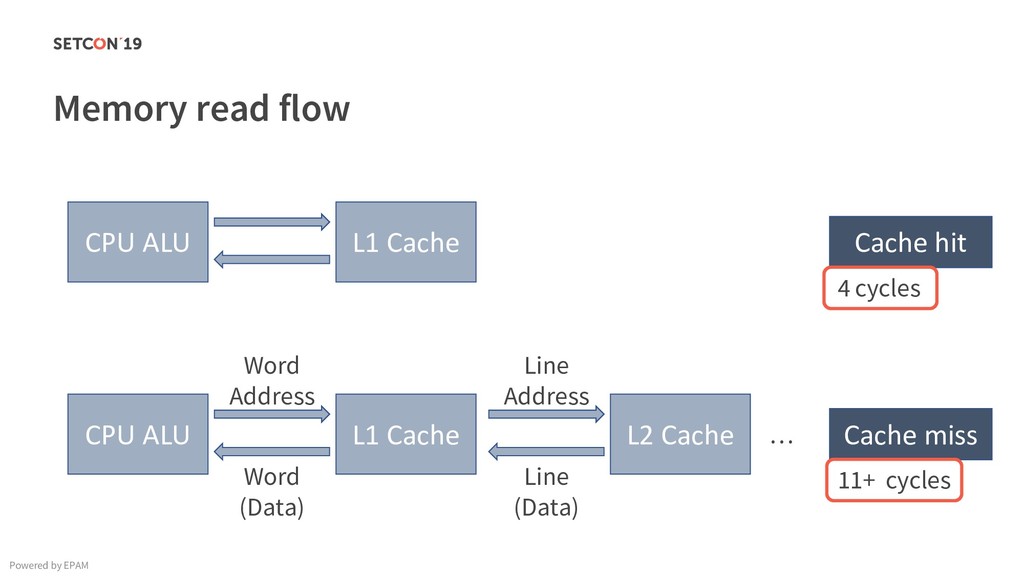
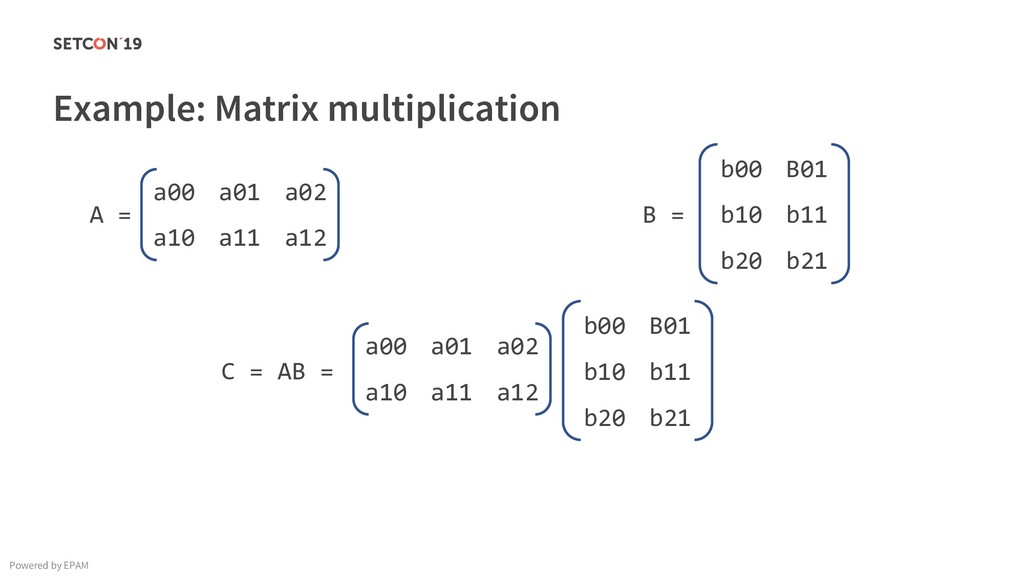
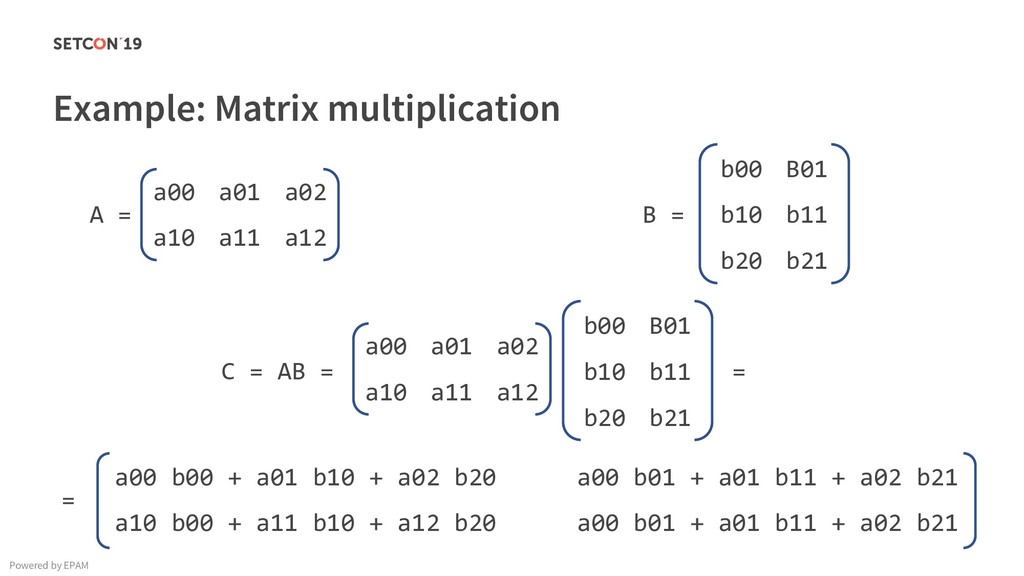
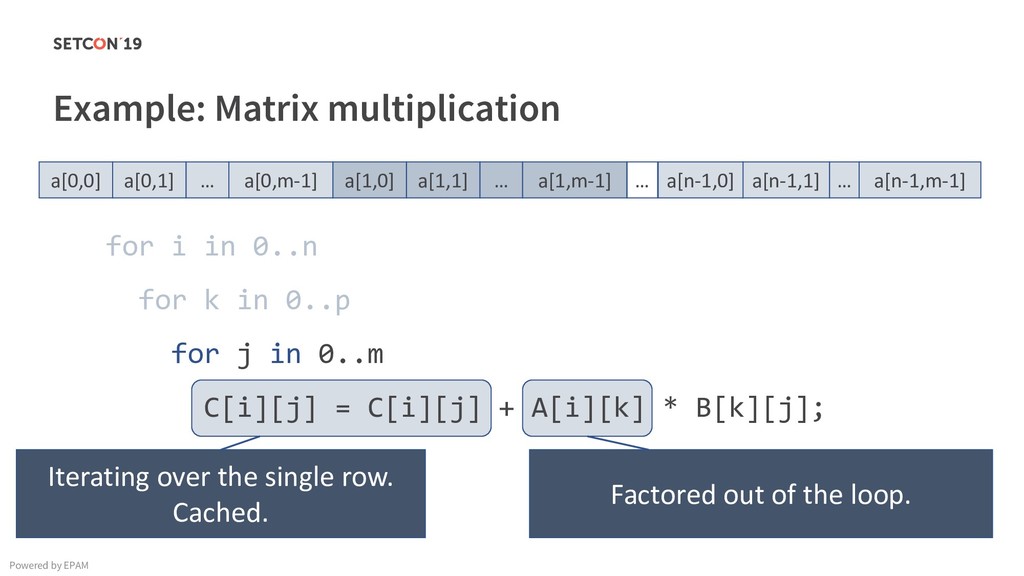
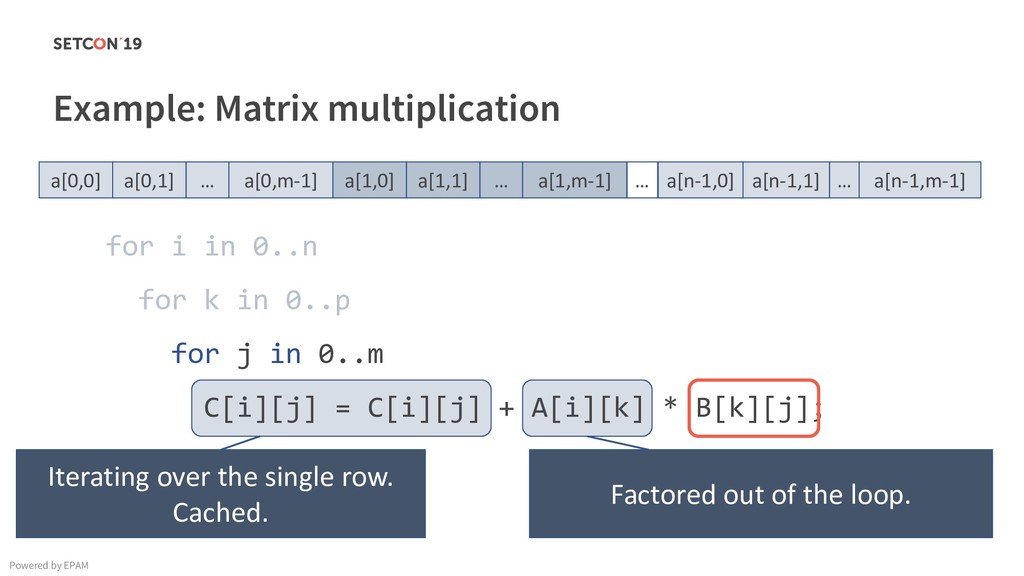
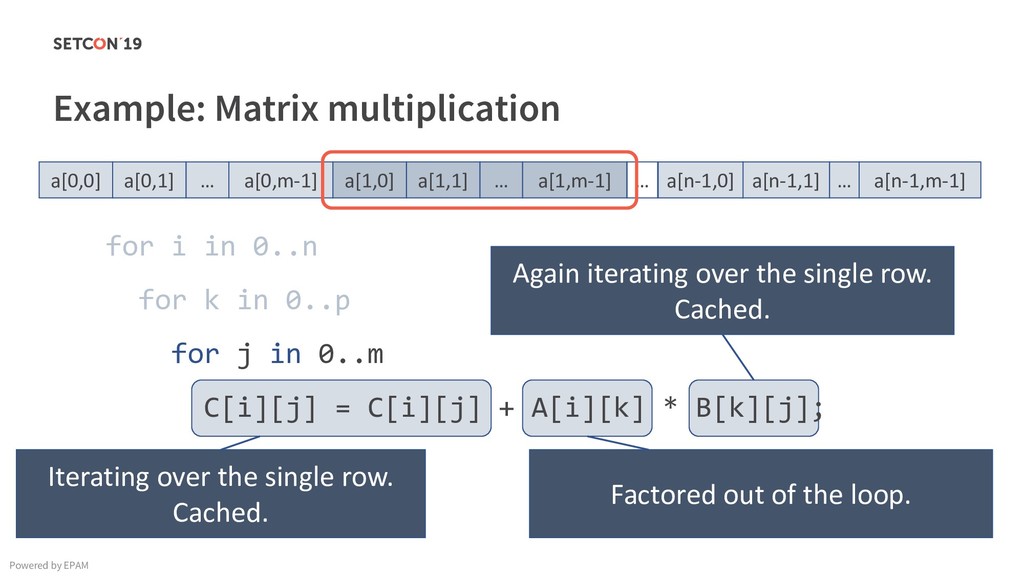
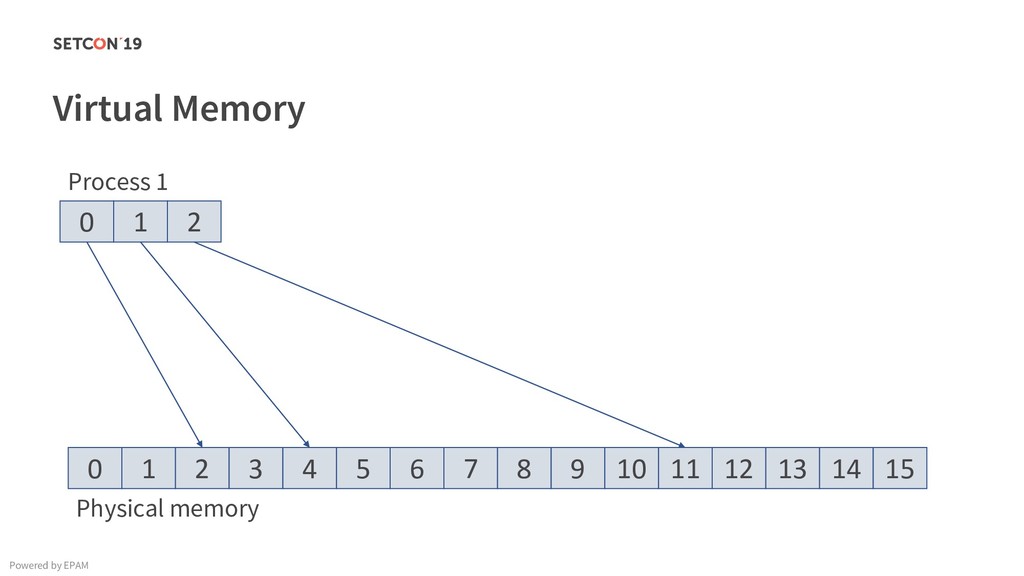
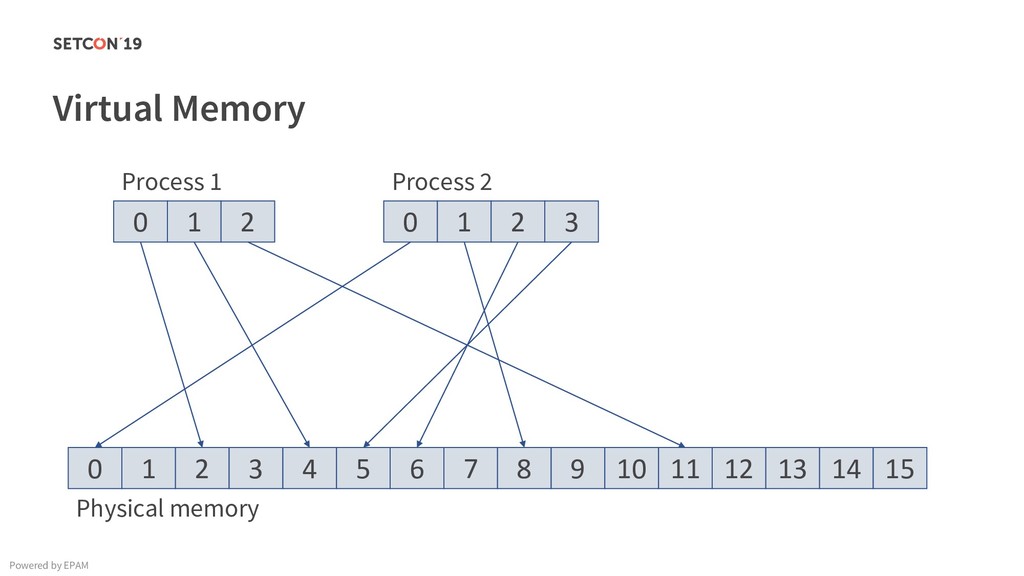
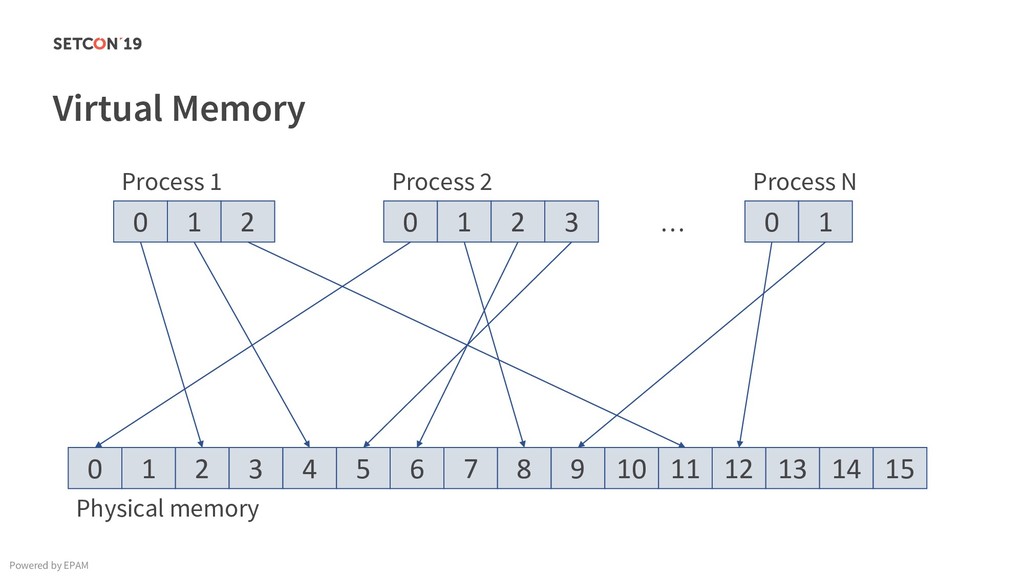
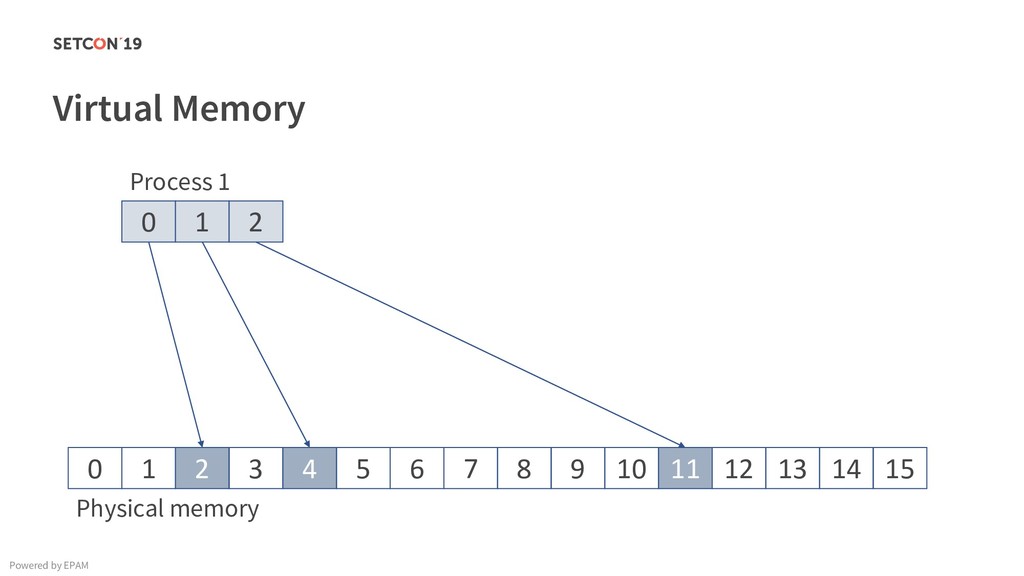
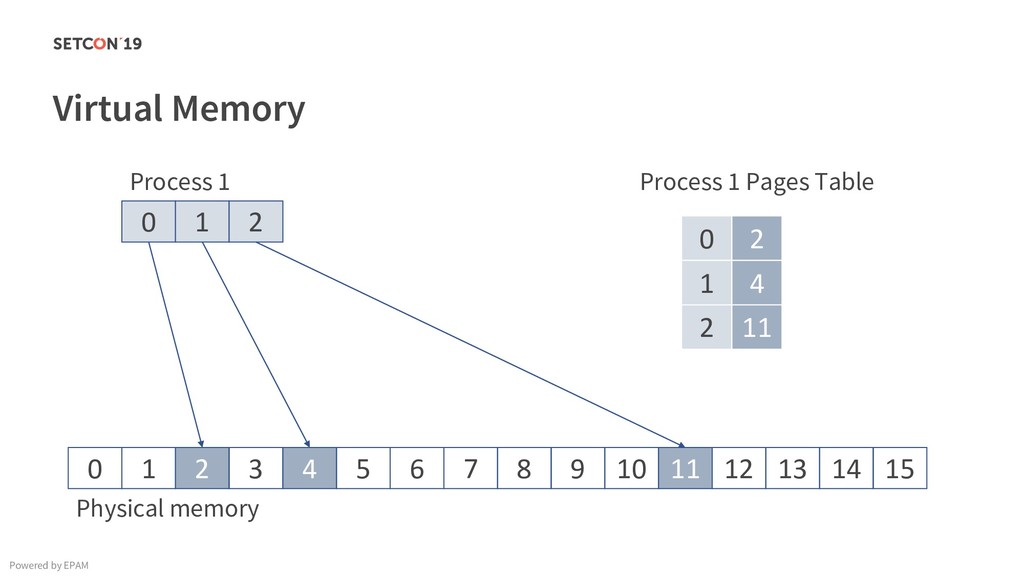
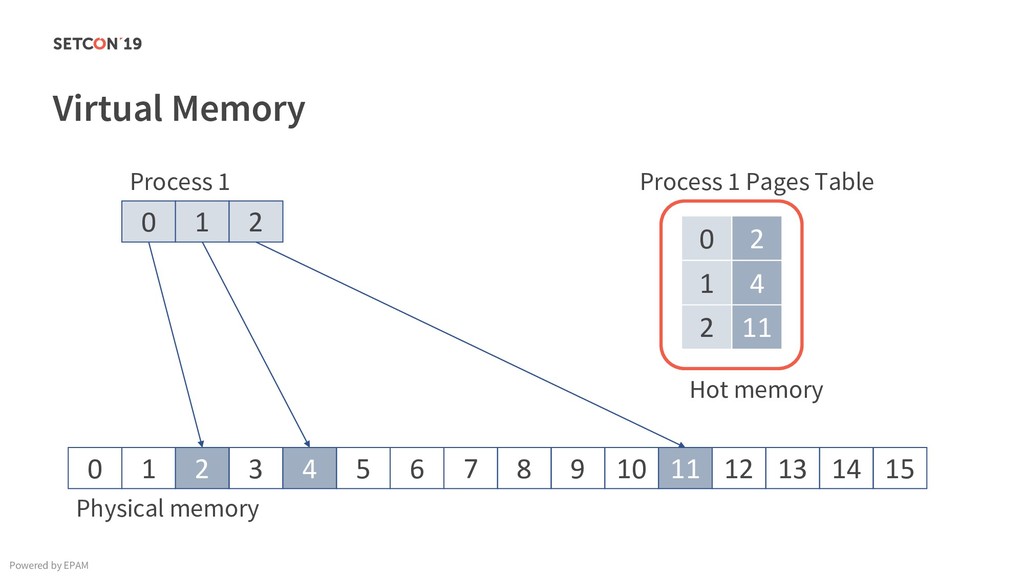
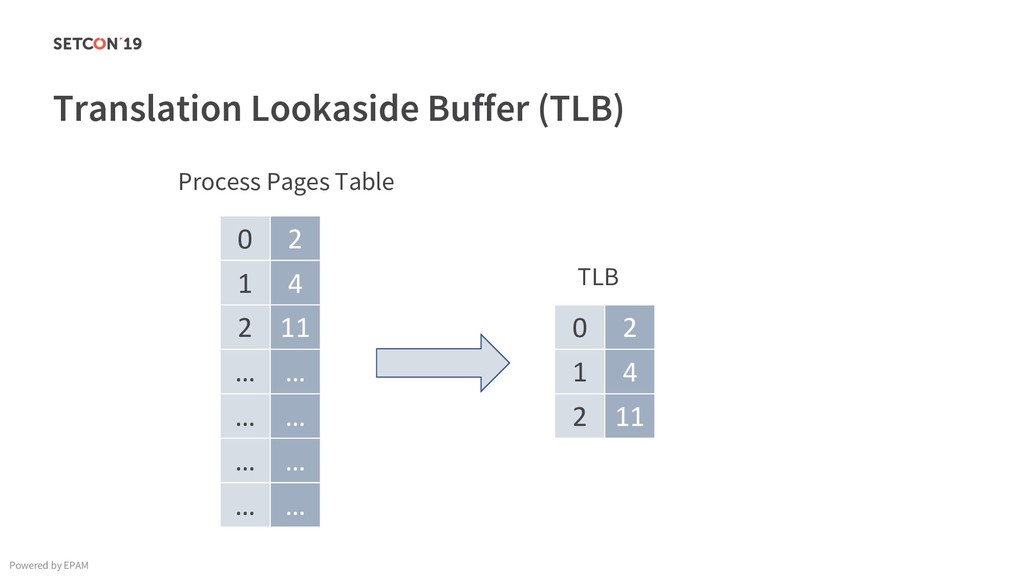
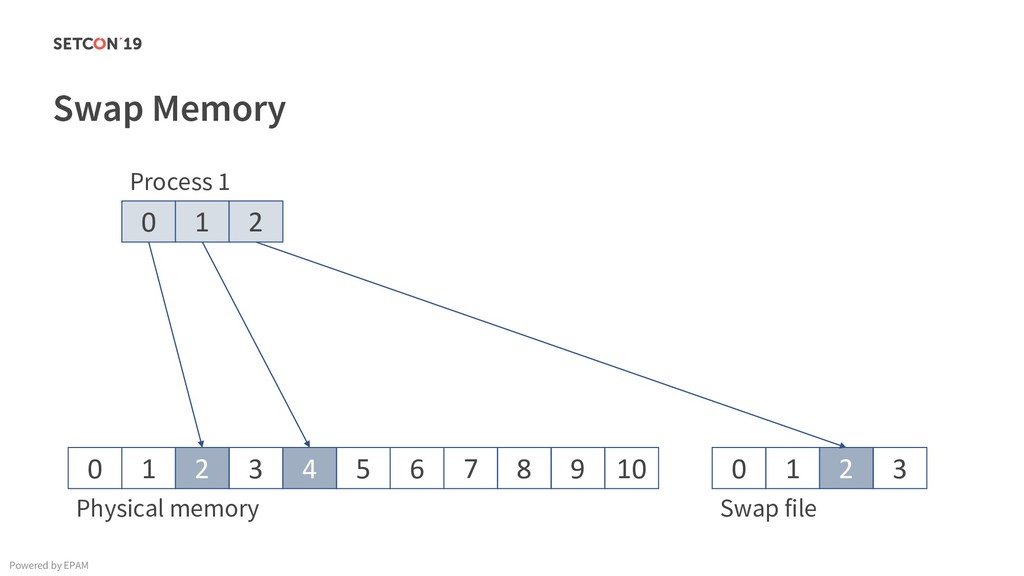
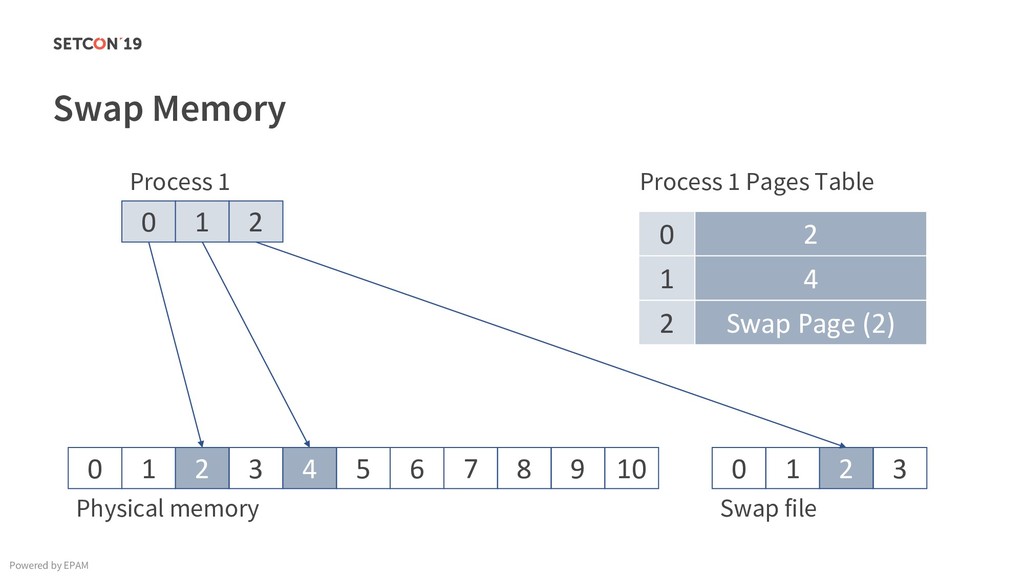
in 0..m C[i][j] = C[i][j] + A[i][k] * B[k][j]; Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1] … a[1,m-1] … a[n-1,1] … a[n-1,m-1] a[0,0] a[1,0] a[n-1,0] Iterating over the single row. Cached. Factored out of the loop. Again iterating over the single row. Cached.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,0] a[0,1] … a[0,m-1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_47.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,0] a[0,1] … a[0,m-1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_48.jpg){kind=link}
![a[0,0] a[0,1] … a[0,m-1] a[1,0] a[1,1] … a[1,m-1] … a[n-1,0]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_49.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_50.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_51.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_52.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_53.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_54.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_55.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_56.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_57.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_58.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_59.jpg){kind=link}
![Example: Matrix multiplication Powered by EPAM a[0,1] … a[0,m-1] a[1,1]](https://files.speakerdeck.com/presentations/269e9a1c0dfd4047b17dc6cdf4d0cd4e/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
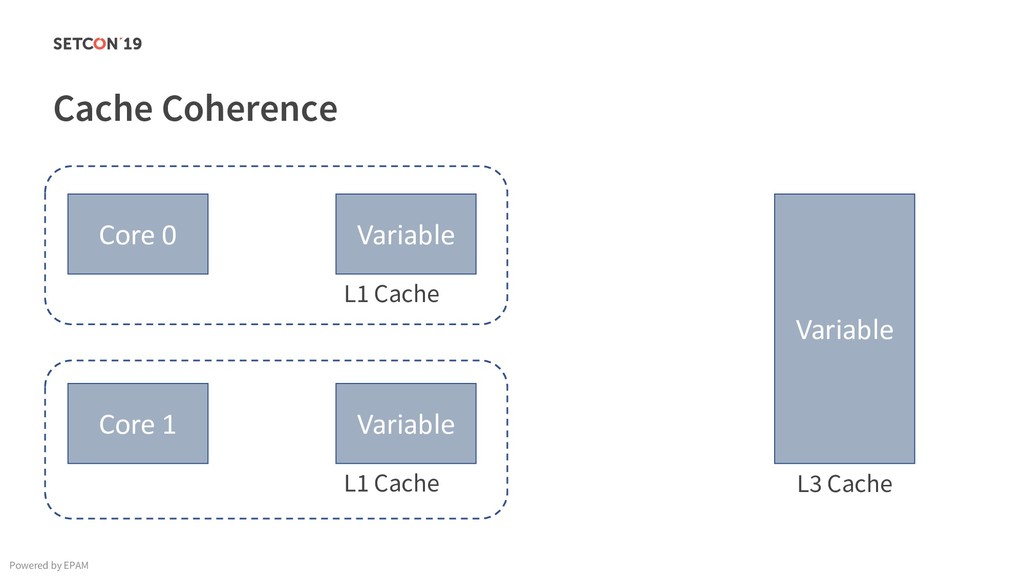{kind=link}
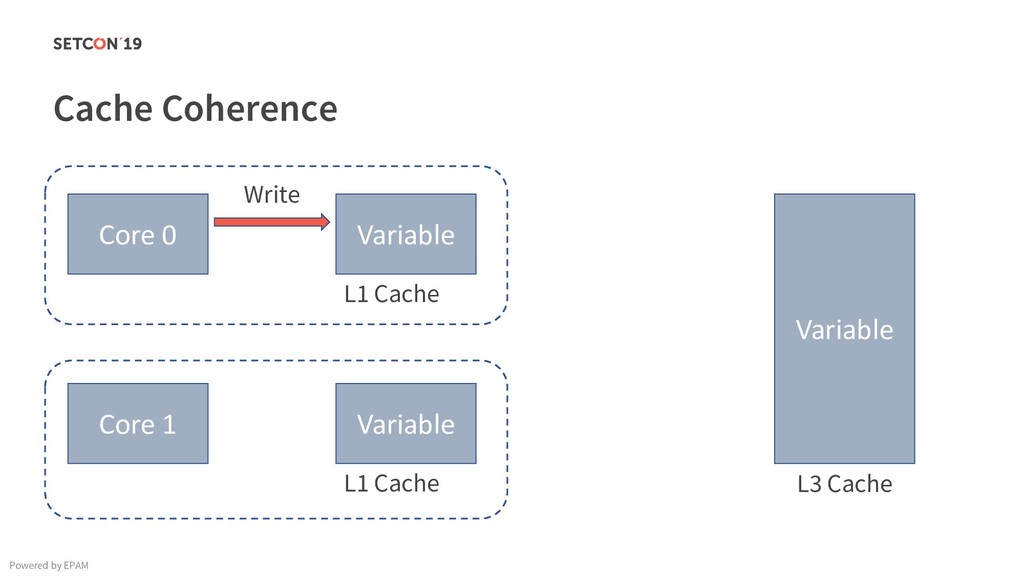{kind=link}
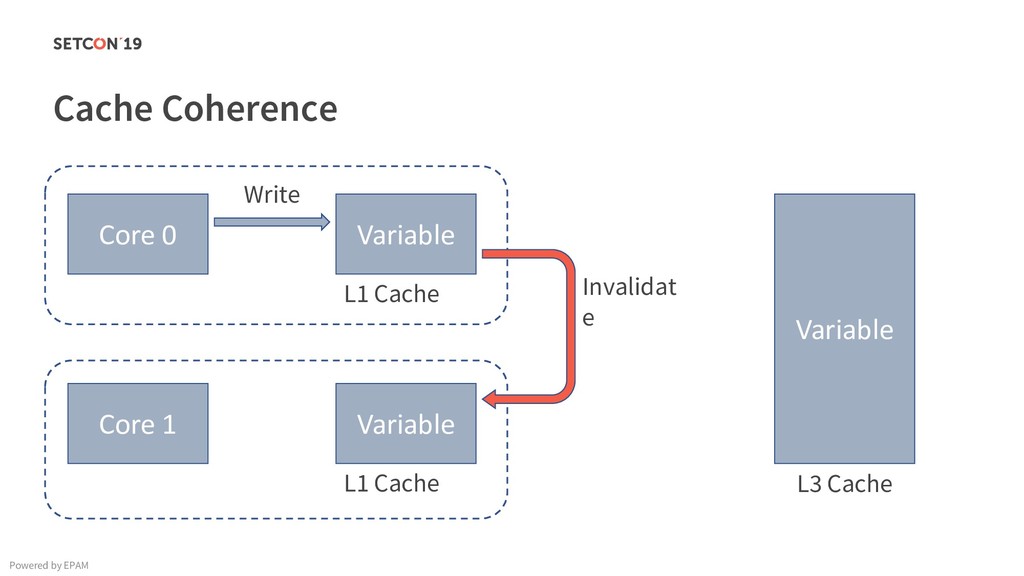{kind=link}
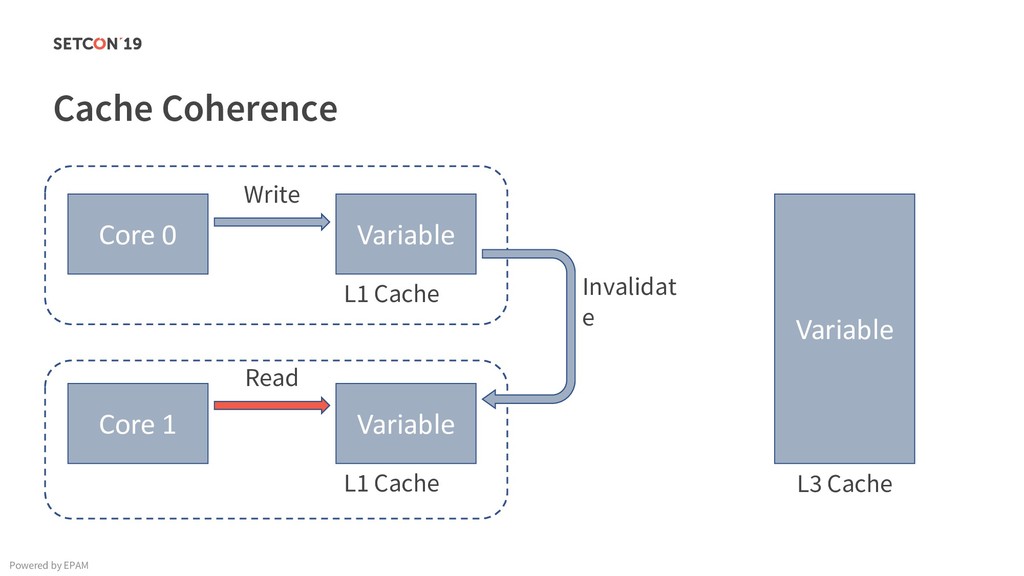{kind=link}
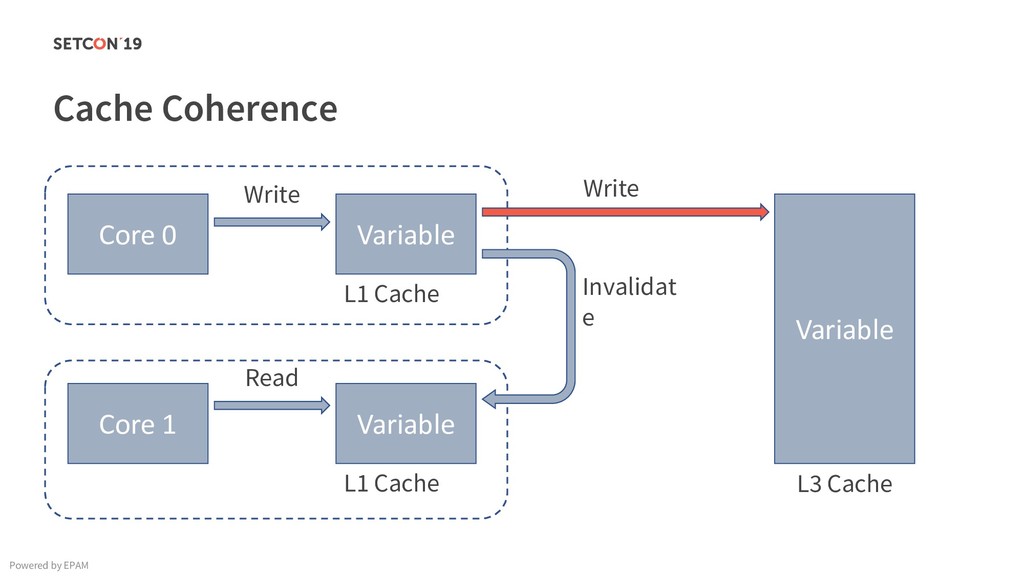{kind=link}
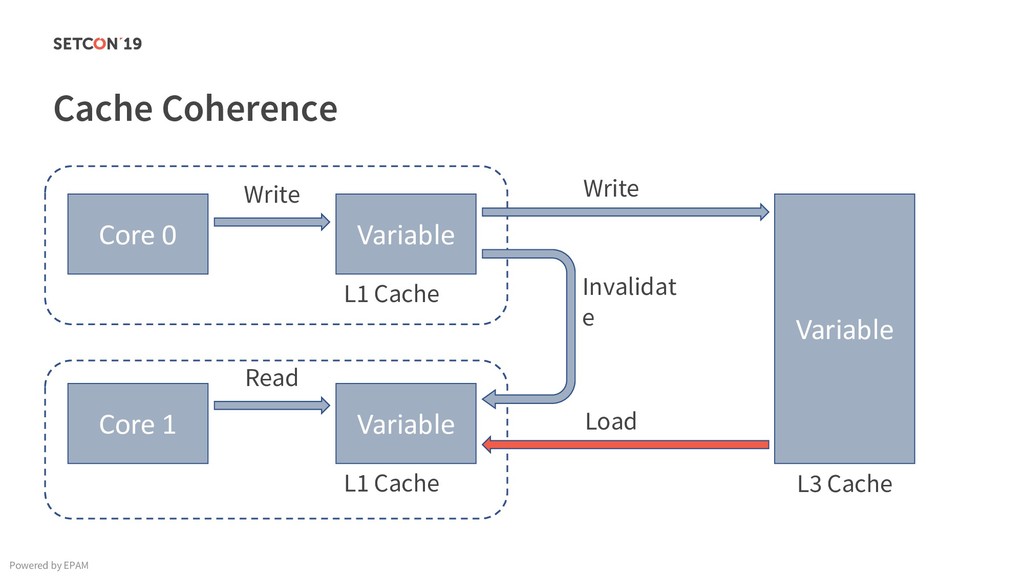{kind=link}
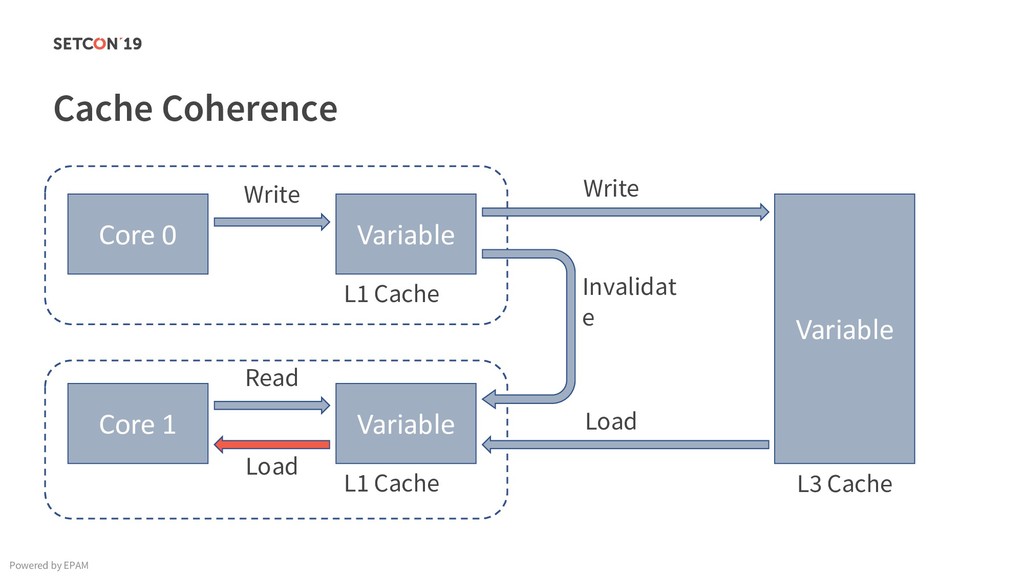{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
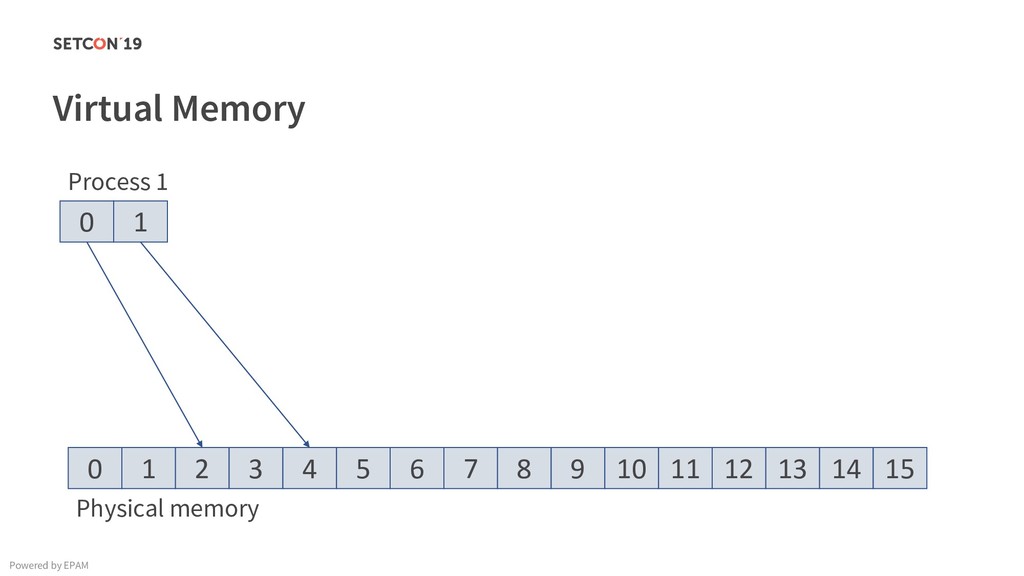{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}