Wang (MIT, AeroAstro) David Gleich (Purdue, CS) COMPUTING ACTIVE SUBSPACES WARNING: These slides are meant to complement the oral presentation. Use out of context at your own risk. This material is based upon work supported by the U.S. Department of Energy Office of Science, Office of Advanced Scientific Computing Research, Applied Mathematics program under Award Number DE-SC-0011077.
solar cell modeling (Mark Campanelli, NREL) • Aerospace shape optimization (Juan Alonso, Stanford) • Combustion stability analysis (Franck Nicoud, University Montpellier 2) • Evapotranspiration in hydrology (Reed Maxwell, School of Mines) • In-situ combustion reservoir simulation (Margot Gerritsen, Stanford) • Combustion LES calibration (Guilhem Lacaze, Mohammad Khalil, SNL) • Atmospheric re-entry (Nagi Mansour, NASA Ames; Thierry Magin, VKI) • Subsurface sensitivity and inversion (Reed Maxwell, School of Mines) • Wind turbine modeling (Peter Graf, Katherine Dykes, NREL) (And I’m open to others that might make me rich, famous, and/or tenured.) There are more applications than I have time for.
high dimensions is hard, in general. ˜ f( x ) ⇡ f( x ) minimize x f( x ) x = f 1( y ) APPROXIMATION OPTIMIZATION INTEGRATION INVERSION You must first discover and then exploit some low- dimensional structure to make these problems tractable.
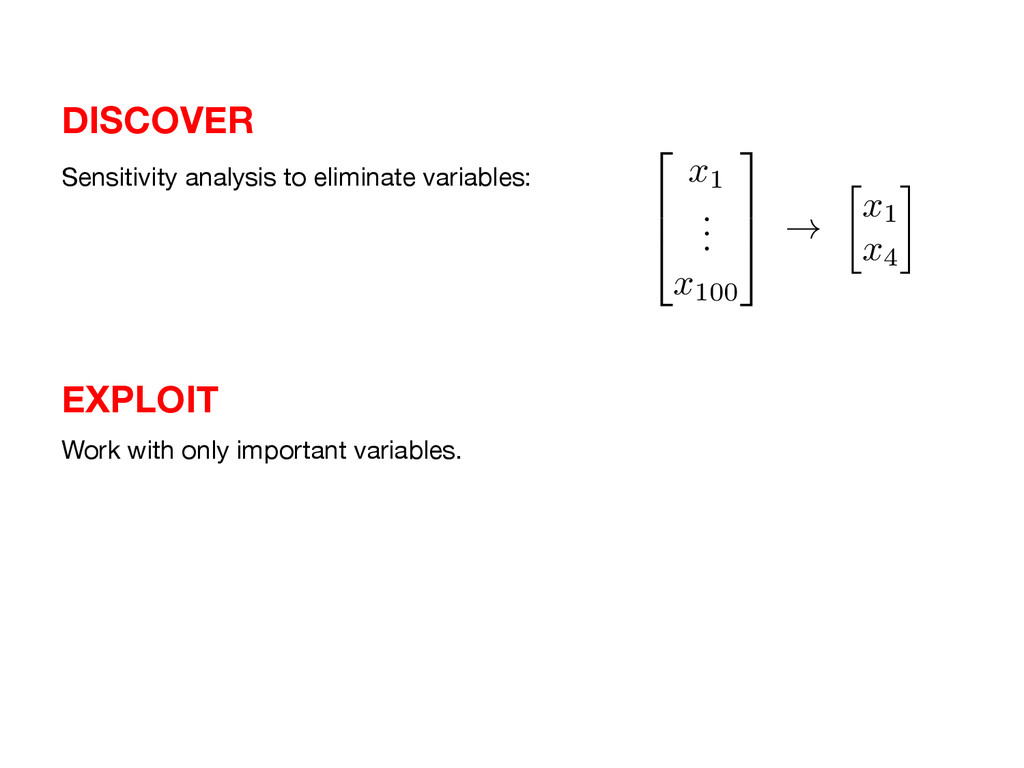
x1) + · · · + fm( xm) DISCOVER EXPLOIT Use sparse grids. Pray for sparsity: f( x ) ⇡ P X i=1 ai i( x ), many ai = 0 Pray for low rank: f ( x ) ⇥ r X i=1 f i 1 ( x1) · · · f i m ( xm) Use separation of variables (PGD, TT, ACA, …) Use compressed sensing.
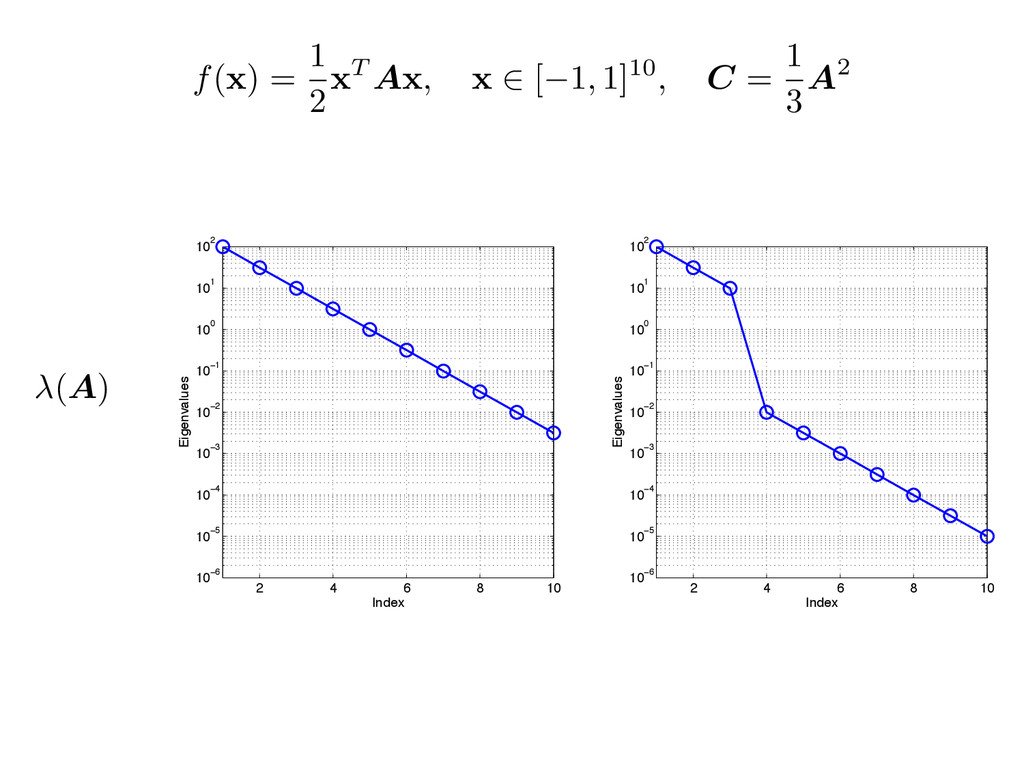
derived from the function. f = f( x ), x ⇥ X Rm, ⇤ x f = 2 6 4 f/ x1 . . . f/ xm 3 7 5 Consider a function and its gradient vector, The uncentered covariance of the gradient and its eigendecomposition Partition the eigendecomposition Rotate and separate the coordinates ⇢ : Rm ! R + ⇤ = ⇤1 ⇤2 , W = ⇥ W 1 W 2 ⇤ , W 1 2 Rm⇥n x = W W T x = W 1W T 1 x + W 2W T 2 x = W 1y + W 2z active variables inactive variables C = Z (r x f)(r x f)T ⇢ d x = W ⇤W T
the most---on average. Lemma 1: Proof sketch: Definition of . Lemma 2: Proof sketch: Chain rule, linearity of trace, definition of . i = Z (r x f)T wi 2 ⇢ d x , i = 1, . . . , m C Z (ryf)T (ryf) ⇢ d x = 1 + · · · + n Z (rzf)T (rzf) ⇢ d x = n+1 + · · · + m C
and fj = f( xj) r x fj = r x f( xj) Approximate with Monte Carlo Equivalent to SVD of samples of the gradient. Called an active subspace method in T. Russi’s 2010 Ph.D. thesis, Uncertainty Quantification with Experimental Data in Complex System Models xj ⇠ ⇢ C ⇡ 1 N N X j=1 r x fj r x fT j = ˆ W ˆ ⇤ ˆ W T 1 p N ⇥ r x f1 · · · r x fN ⇤ = ˆ W p ˆ ⇤ ˆ V T
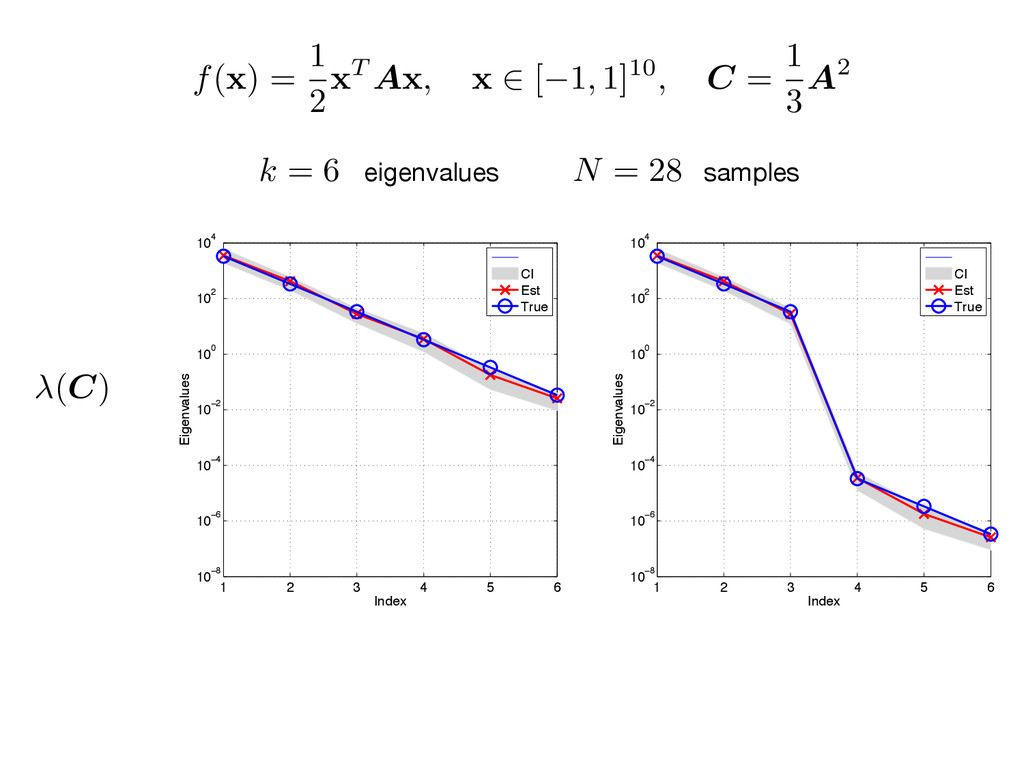
think. Probability that eigenvalue estimate precedes true eigenvalue Number of samples Bound on gradient norm squared P n ˆk (1 " ) k o k exp ✓ N 2 k "2 4 1L2 ◆ Using Gittens and Tropp (2011)
think. P n ˆk (1 + " ) k o ( m k + 1) exp ✓ N k"2 4 L2 ◆ Probability that eigenvalue estimate exceeds true eigenvalue Number of samples Bound on gradient norm squared Using Gittens and Tropp (2011)
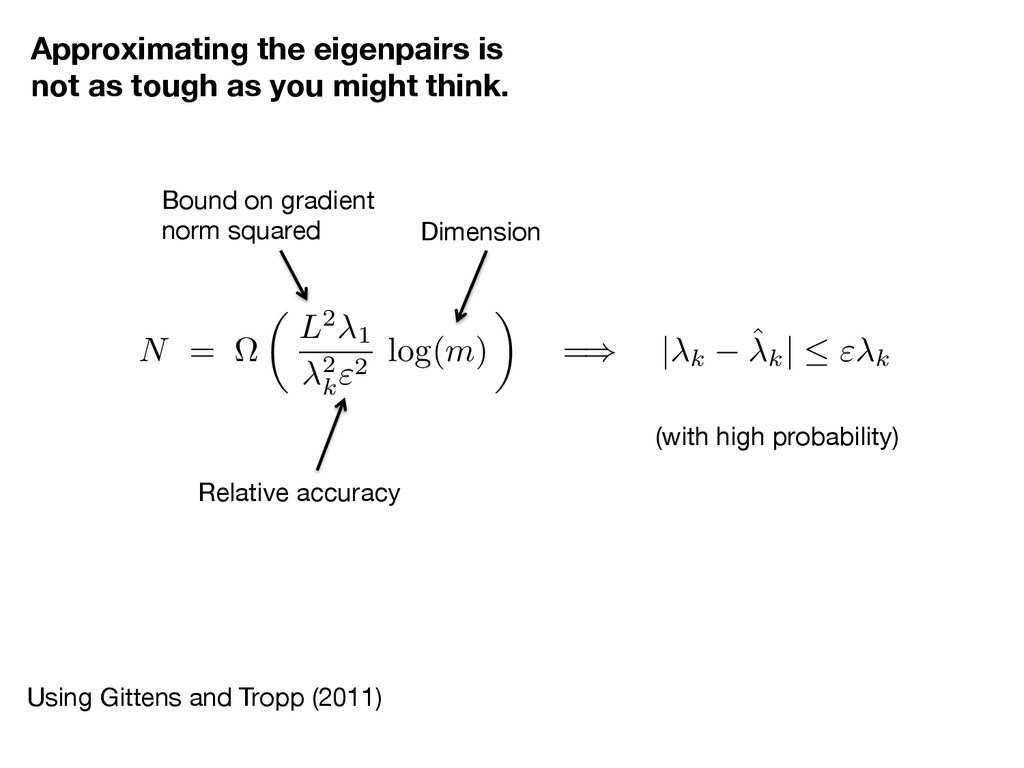
as tough as you might think. Bound on gradient norm squared Relative accuracy Dimension (with high probability) N = ⌦ ✓ L2 1 2 k "2 log( m ) ◆ = ) | k ˆk | " k
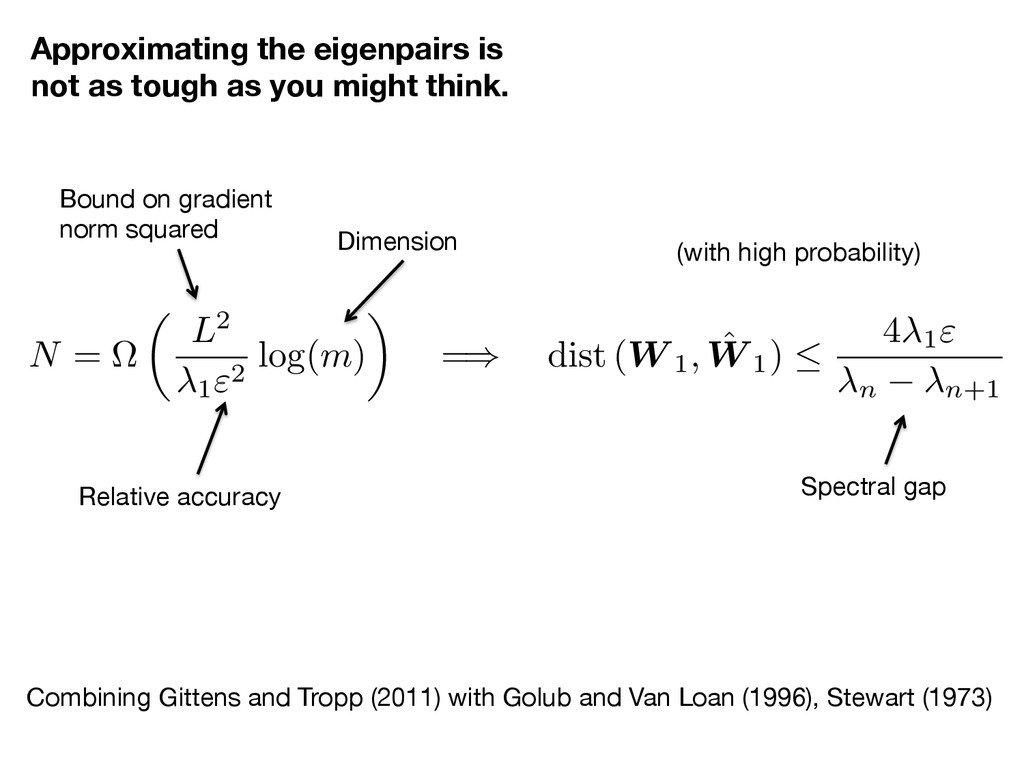
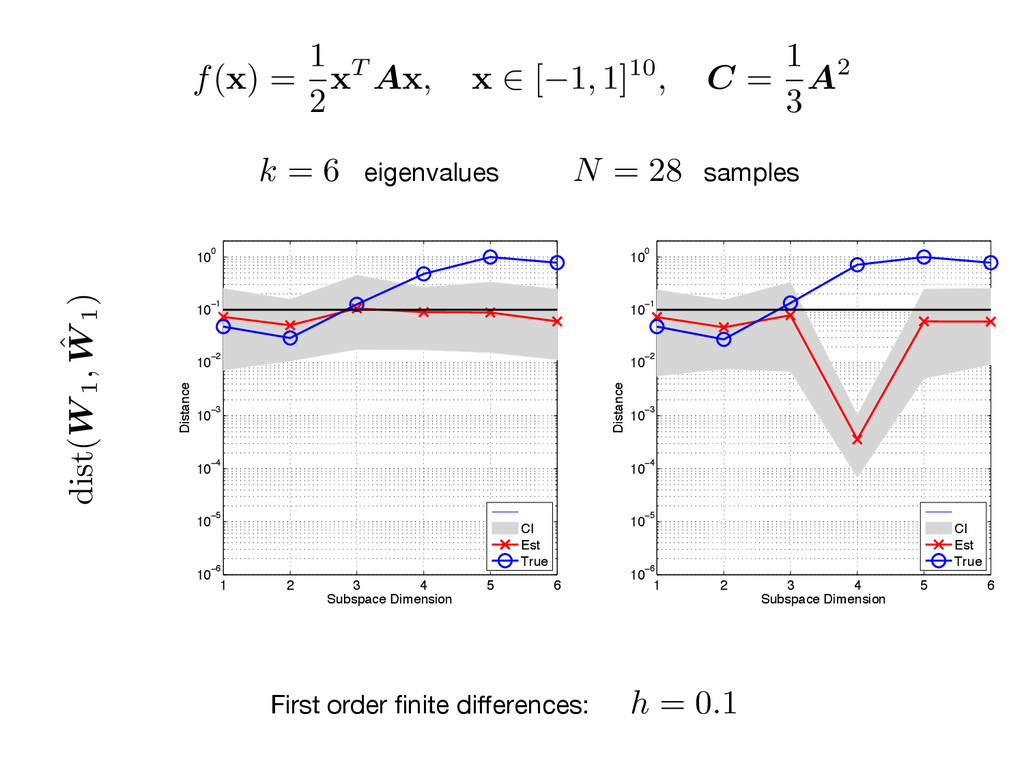
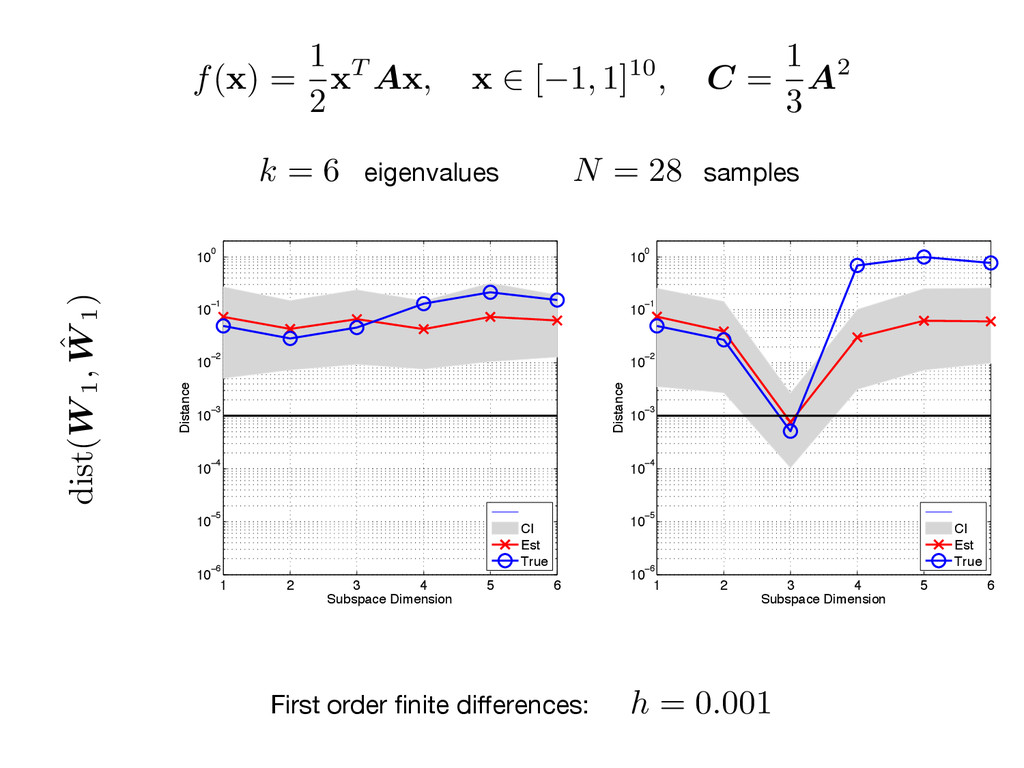
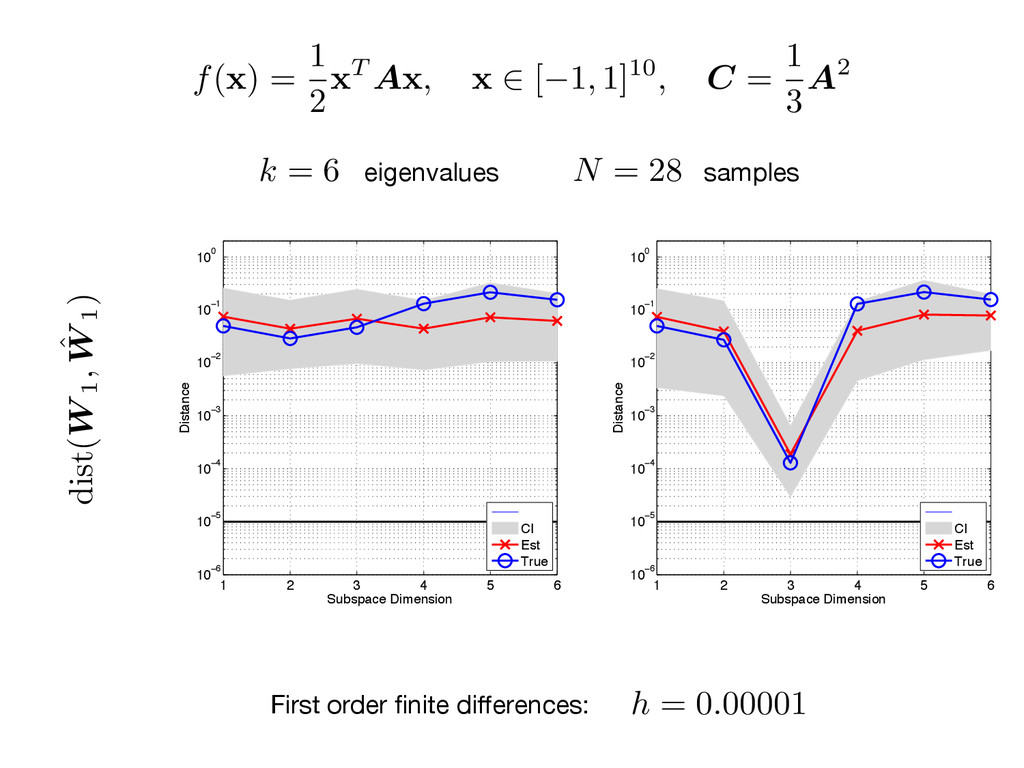
think. Combining Gittens and Tropp (2011) with Golub and Van Loan (1996), Stewart (1973) Bound on gradient norm squared Relative accuracy Dimension (with high probability) Spectral gap N = ⌦ ✓ L2 1"2 log( m ) ◆ = ) dist ( W 1, ˆ W 1) 4 1" n n+1
A: Scales like log of dimension times problem-dependent constants. Q: How do I choose the dimension of the active subspace? A: Look for spectral gaps. Q: What happens if I have inaccurate gradients? A: Bias (that goes to zero) appears in the error bounds. Q: How do I quantify uncertainty in the estimates? A: Use a bootstrap!
x 2 [ 1, 1]10, C = 1 3 A2 1 2 3 4 5 6 10−8 10−6 10−4 10−2 100 102 104 Index Eigenvalues CI Est True 1 2 3 4 5 6 10−8 10−6 10−4 10−2 100 102 104 Index Eigenvalues CI Est True (C) First order finite differences: h = 0.1 k = 6 N = 28 eigenvalues samples
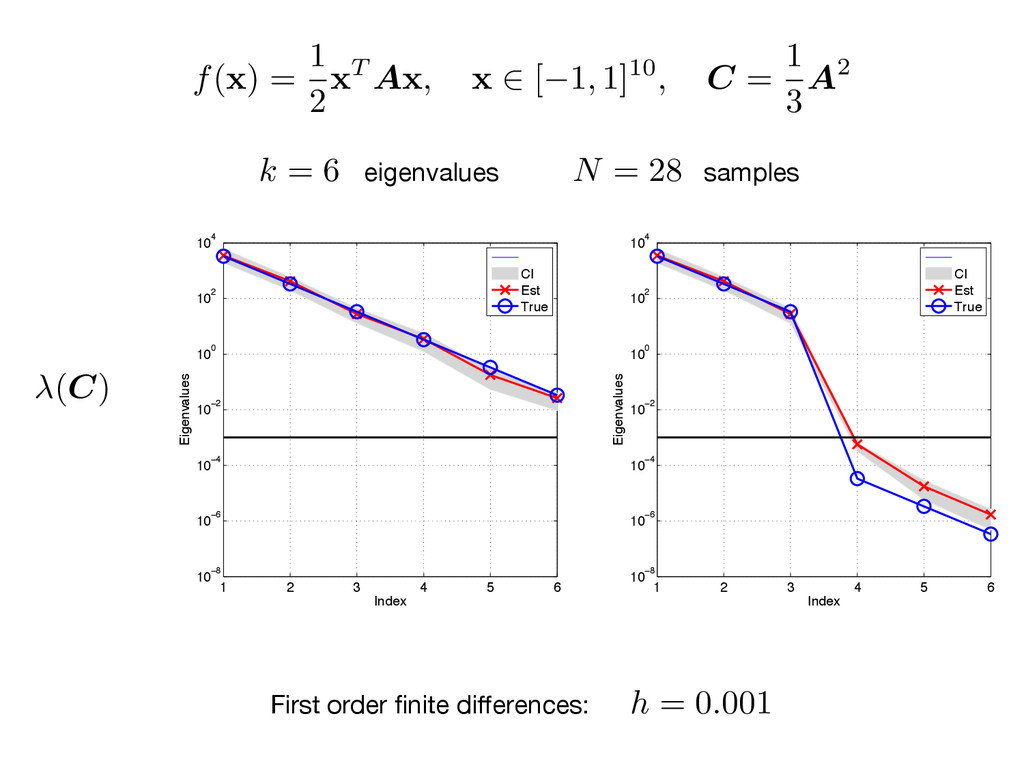
A x , x 2 [ 1, 1]10, C = 1 3 A2 1 2 3 4 5 6 10−8 10−6 10−4 10−2 100 102 104 Index Eigenvalues CI Est True 1 2 3 4 5 6 10−8 10−6 10−4 10−2 100 102 104 Index Eigenvalues CI Est True First order finite differences: (C) k = 6 N = 28 eigenvalues samples
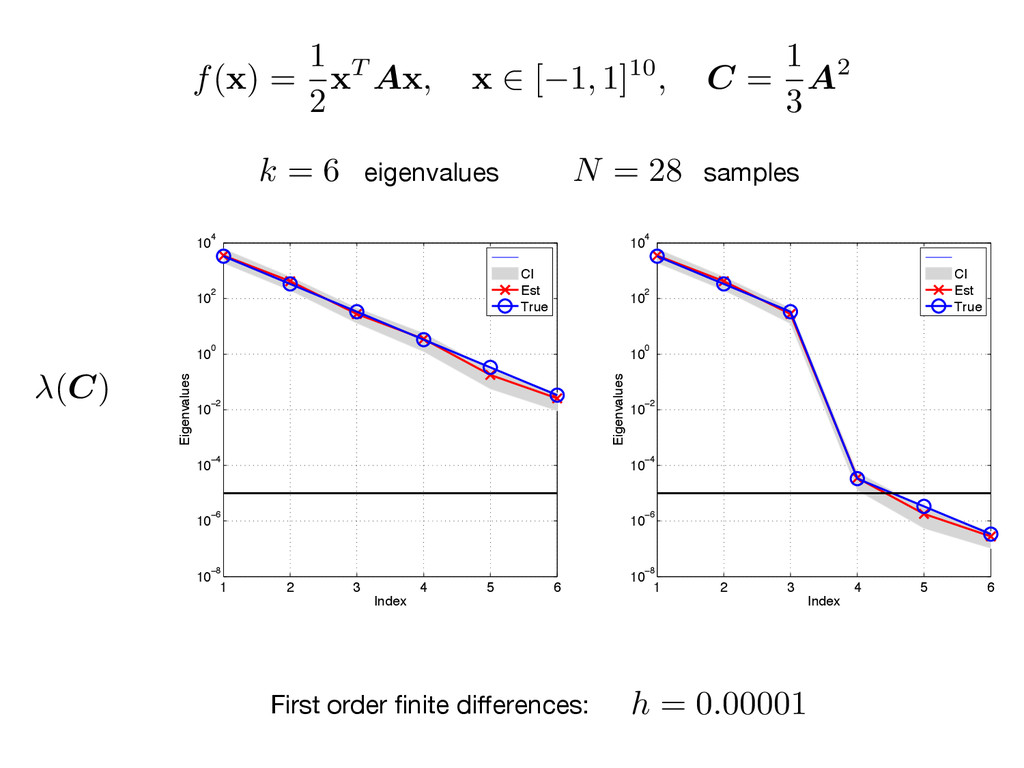
A x , x 2 [ 1, 1]10, C = 1 3 A2 1 2 3 4 5 6 10−8 10−6 10−4 10−2 100 102 104 Index Eigenvalues CI Est True 1 2 3 4 5 6 10−8 10−6 10−4 10−2 100 102 104 Index Eigenvalues CI Est True First order finite differences: (C) k = 6 N = 28 eigenvalues samples
r x fN ⇤ ⇡ ˆ W 1 q ˆ ⇤1 ˆ V T 1 Low-rank approximation of the collection of gradients: Let’s be abundantly clear about the problem we are trying to solve. Low-dimensional linear approximation of the gradient: rf( x ) ⇡ ˆ W 1 a ( x ) f( x ) ⇡ g ⇣ ˆ W T 1 x ⌘ Approximate a function of many variables by a function of a few linear combinations of the variables: ✔ ✖ ✖
inequality, triangle inequality. g( y ) = Z f(W 1y + W 2z ) ⇢( z | y ) d z , f( x ) ⇡ g(W T 1 x ) EXPLOIT active subspaces for response surfaces with conditional averaging. ✓Z ⇣ f( x ) g( ˆ W T 1 x ) ⌘2 ⇢ d x ◆1 2 CP ⇣ " ( 1 + · · · + n)1 2 + ( n+1 + · · · + m)1 2 ⌘ Conditional expectation* Estimated eigenvectors Poincare constant Subspace error Eigenvalues for active variables Eigenvalues for inactive variables
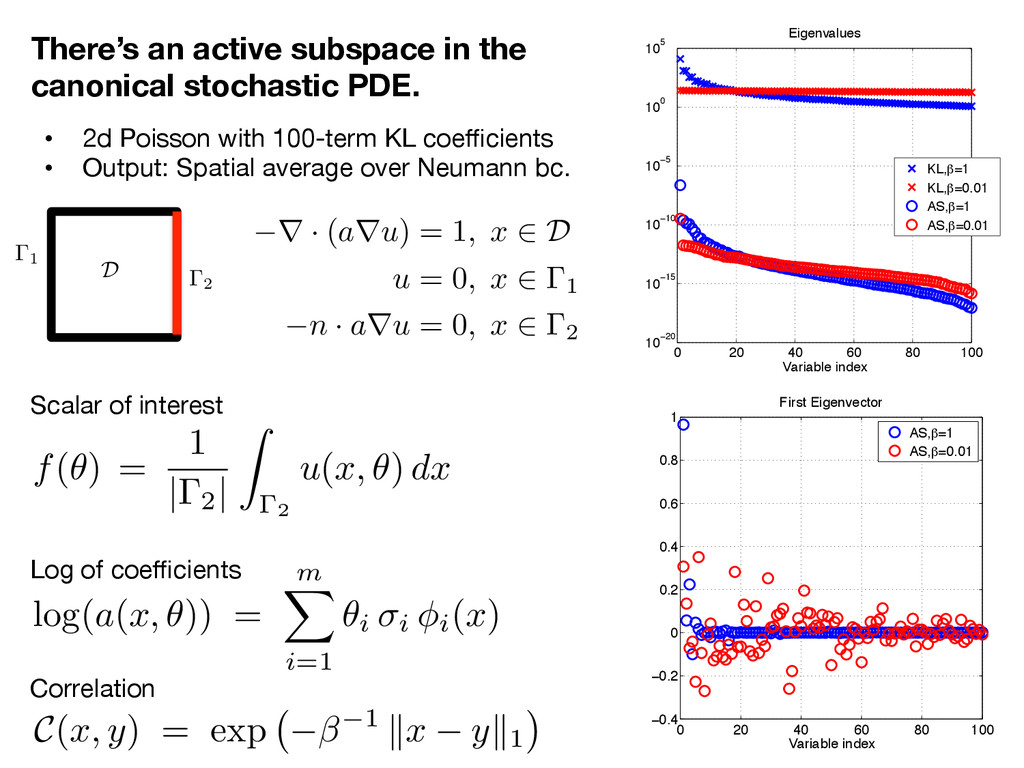
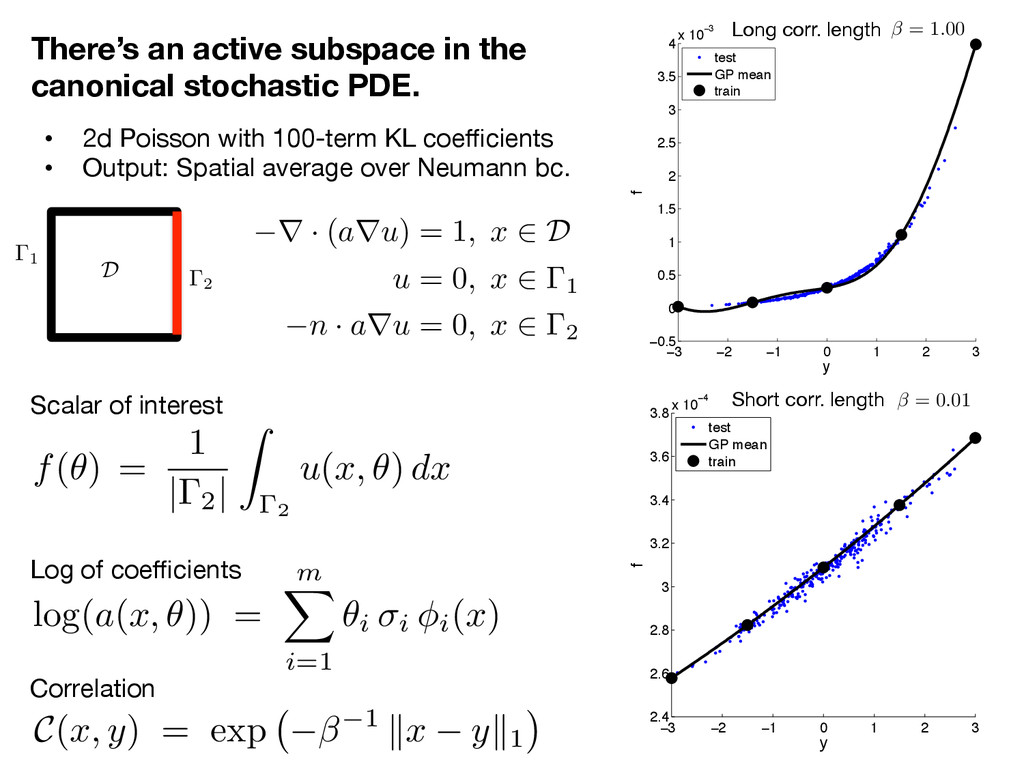
2d Poisson with 100-term KL coefficients • Output: Spatial average over Neumann bc. Log of coefficients Correlation Scalar of interest 0 20 40 60 80 100 10−20 10−15 10−10 10−5 100 105 Eigenvalues Variable index KL,β=1 KL,β=0.01 AS,β=1 AS,β=0.01 0 20 40 60 80 100 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 First Eigenvector Variable index AS,β=1 AS,β=0.01 1 2 D r · ( a r u ) = 1 , x 2 D u = 0 , x 2 1 n · a r u = 0 , x 2 2 C (x, y) = exp 1 k x y k1 log(a(x, ✓)) = m X i=1 ✓i i i(x) f ( ✓ ) = 1 | 2 | Z 2 u ( x, ✓ ) dx
2d Poisson with 100-term KL coefficients • Output: Spatial average over Neumann bc. Log of coefficients Correlation Scalar of interest −3 −2 −1 0 1 2 3 −0.5 0 0.5 1 1.5 2 2.5 3 3.5 4 x 10−3 y f test GP mean train −3 −2 −1 0 1 2 3 2.4 2.6 2.8 3 3.2 3.4 3.6 3.8 x 10−4 y f test GP mean train Long corr. length Short corr. length = 0.01 = 1.00 1 2 D r · ( a r u ) = 1 , x 2 D u = 0 , x 2 1 n · a r u = 0 , x 2 2 C (x, y) = exp 1 k x y k1 log(a(x, ✓)) = m X i=1 ✓i i i(x) f ( ✓ ) = 1 | 2 | Z 2 u ( x, ✓ ) dx
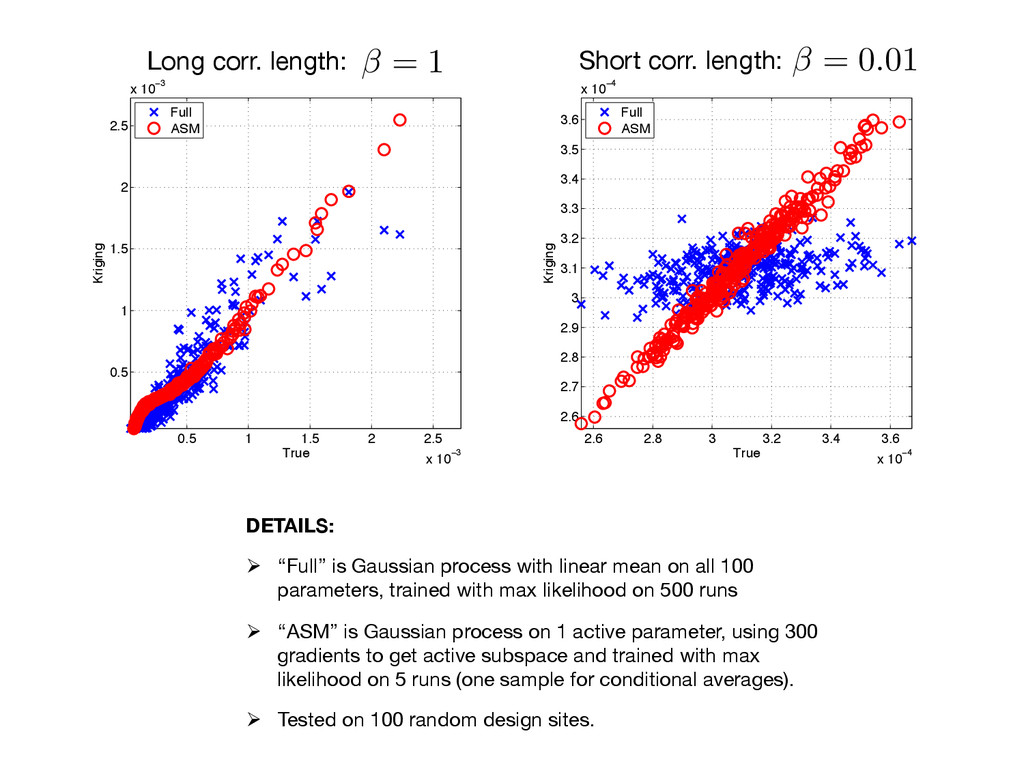
all 100 parameters, trained with max likelihood on 500 runs Ø “ASM” is Gaussian process on 1 active parameter, using 300 gradients to get active subspace and trained with max likelihood on 5 runs (one sample for conditional averages). Ø Tested on 100 random design sites. 0.5 1 1.5 2 2.5 x 10−3 0.5 1 1.5 2 2.5 x 10−3 True Kriging Full ASM 2.6 2.8 3 3.2 3.4 3.6 x 10−4 2.6 2.7 2.8 2.9 3 3.1 3.2 3.3 3.4 3.5 3.6 x 10−4 True Kriging Full ASM = 1 Long corr. length: Short corr. length: = 0.01
low-dimensional structure to make high-dimensional problems tractable. Active subspaces offer a new set of tools for working with functions that depends on several (tens to thousands of) variables. The right way to exploit active subspaces depends on what you’re trying to do (e.g., approximation, optimization, inversion, integration). COMING IN MARCH! Active Subspaces Emerging Ideas for Dimension Reduction in Parameter Studies SIAM, 2015
we talk about the trade-off between discovering and exploiting? • Can you tell me more about [insert application]? • How does this relate to other dimension reduction techniques? • How new is all this? • Can you show us the cool videos of the active subspace in the aerodynamic shape optimization? Paul Constantine Colorado School of Mines paulconstantine.net @DrPaulynomial Website: activesubspaces.org
{kind=link}
{kind=link}
{kind=link}
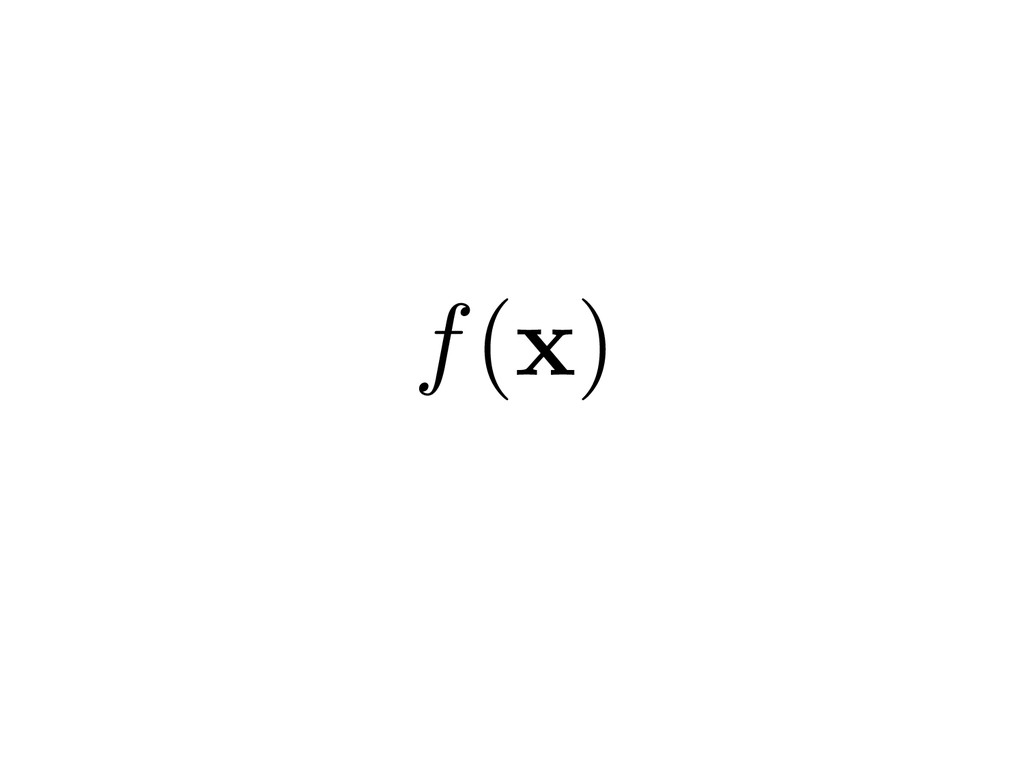{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[ Show them that cool animation! ] https://www.youtube.com/watch?v=70BTwlV3Kwg](https://files.speakerdeck.com/presentations/f24595e07b5801327c0342650df4e8dd/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}