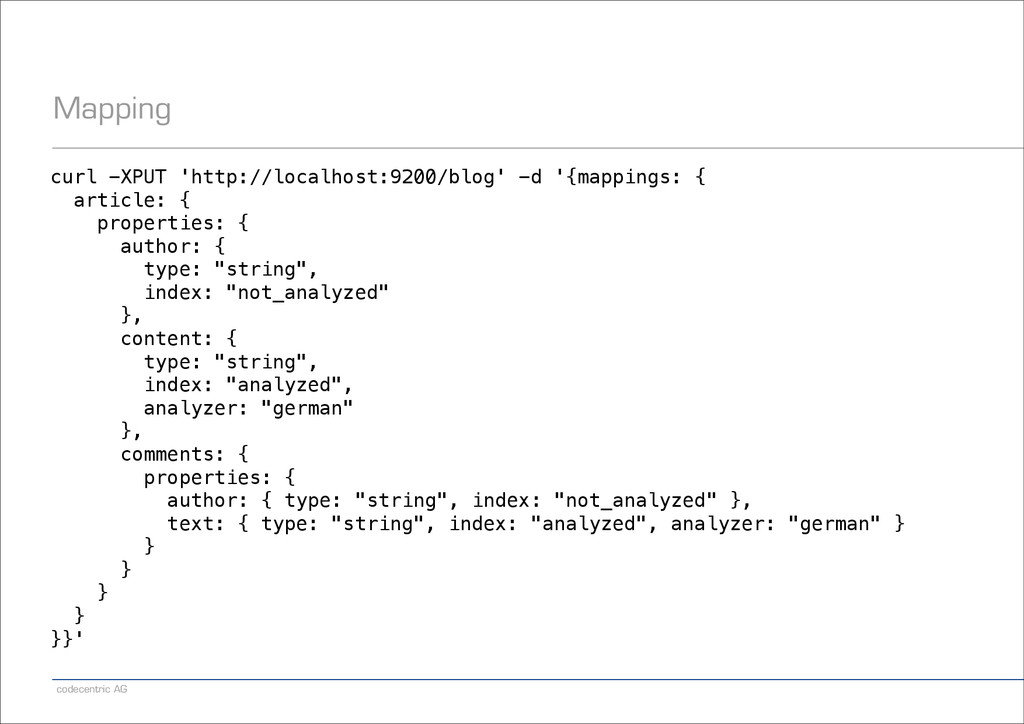
abschalten ! − Falls nicht benötigt: _source-Feld abschalten ! − Falls _source verwendet wird, keine einzelnen Felder mehr auf _stored setzen ! − Falls nicht benötigt: Schalte dynamic mapping ab ! − Verwende not_analyzed, wenn Werte unverändert indiziert werden sollen
wann immer möglich − Viele Filter (z.B. Term-Filter) können gecached werden − „Nur Filter“ lässt sich mit constant_score-Query oder match_all-Query realisieren
wann immer möglich − Viele Filter (z.B. Term-Filter) können gecached werden − „Nur Filter“ lässt sich mit constant_score-Query oder match_all-Query realisieren ! − Zusammengesetzte Filter (bool/and/or/not) werden nicht gecached − Es kann sich aber lohnen, das explizit zu verlangen (_cache setzen)
wann immer möglich − Viele Filter (z.B. Term-Filter) können gecached werden − „Nur Filter“ lässt sich mit constant_score-Query oder match_all-Query realisieren ! − Zusammengesetzte Filter (bool/and/or/not) werden nicht gecached − Es kann sich aber lohnen, das explizit zu verlangen (_cache setzen) ! − Bevorzuge bool-Filter vor and/or/not, wenn sie Cached-Filter kombinieren − Denn and/or/not benutzen den Cache nicht (aber: andere Vorteile)
wann immer möglich − Viele Filter (z.B. Term-Filter) können gecached werden − „Nur Filter“ lässt sich mit constant_score-Query oder match_all-Query realisieren ! − Zusammengesetzte Filter (bool/and/or/not) werden nicht gecached − Es kann sich aber lohnen, das explizit zu verlangen (_cache setzen) ! − Bevorzuge bool-Filter vor and/or/not, wenn sie Cached-Filter kombinieren − Denn and/or/not benutzen den Cache nicht (aber: andere Vorteile) ! − Es gibt verschiedene Möglichkeiten, Filter anzuwenden − Je nachdem findet die Ausführung vor oder nach dem Query statt − Beeinflusst den Scope von Facetten im selben Request − Meistens ist „filtered query“ das, was man benötigt
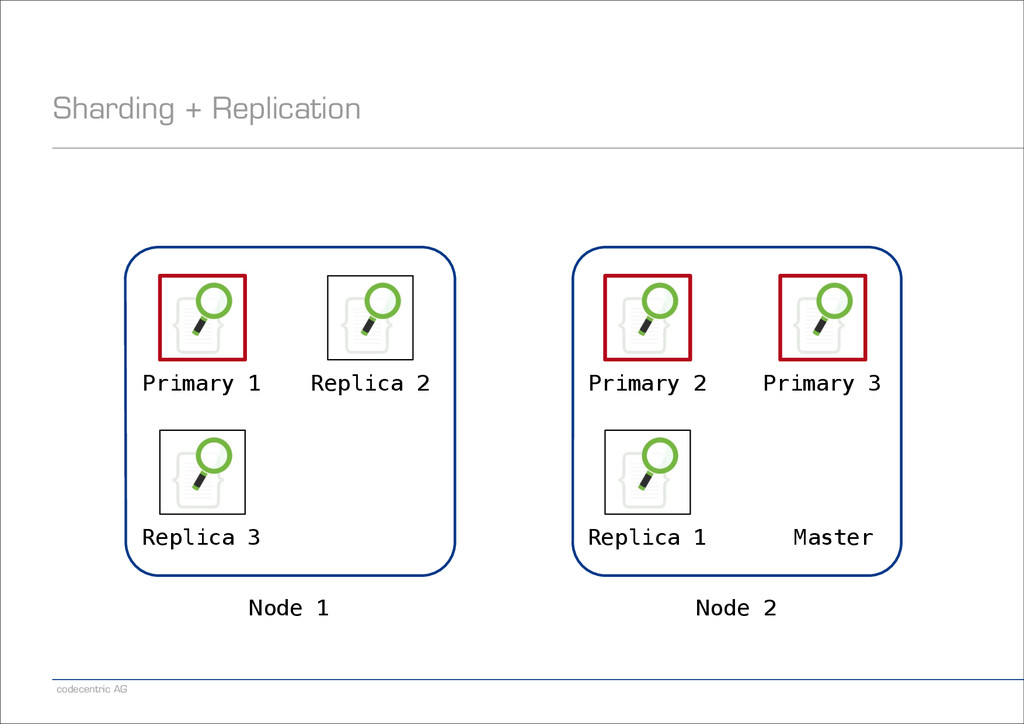
Shard wird ein Dokument indiziert? − In welchen Shards wird gesucht? − Default: Basierend auf Dokument-ID − Kann aber überschrieben werden ! − Anzahl Shards wird bei Anlegen eines Indexes final festgelegt ! − Anzahl Replicas kann dynamisch geändert werden ! − Es gibt exakt einen Master-Knoten im Cluster
ist nicht angelegt − gelb = Primary Shard ist angelegt, aber nicht alle verlangten Replicas − grün = Alle Shards sind angelegt ! − „Index-Status“ = Schlechtester Status aller Shards des Indexes ! − „Cluster-Status“ = Schlechtester Status aller Indexe des Clusters ! − „Wait Until“: Möglichkeit, auf den gewünschten Status zu warten ! − Beachte: Auch bei Cluster-Status Rot funktioniert noch so einiges!
Cluster-Name − Unicast- vs. Multicast-Discovery ! − Allocation Awareness − Praktisch beliebige Regeln, damit Shards nur auf bestimmten Knoten angelegt werden − Indizes können ebenfalls Einschränkungen definieren ! − Knoten können verschiedene Fähigkeiten haben − „master“, „data“, „client“ − Ermöglicht Architektur mit Aggregator-Knoten ! − Gefährlicher Default: minimum_master_nodes = 1
quorum, one − Default: quorum − Wie viele Shards müssen da sein, damit die Operation zulässig ist? ! − „replication=async“ − Kehrt bereits nach Indizierung auf dem Primary Shard zurück − Default: Vollständige Replikation wird abgewartet
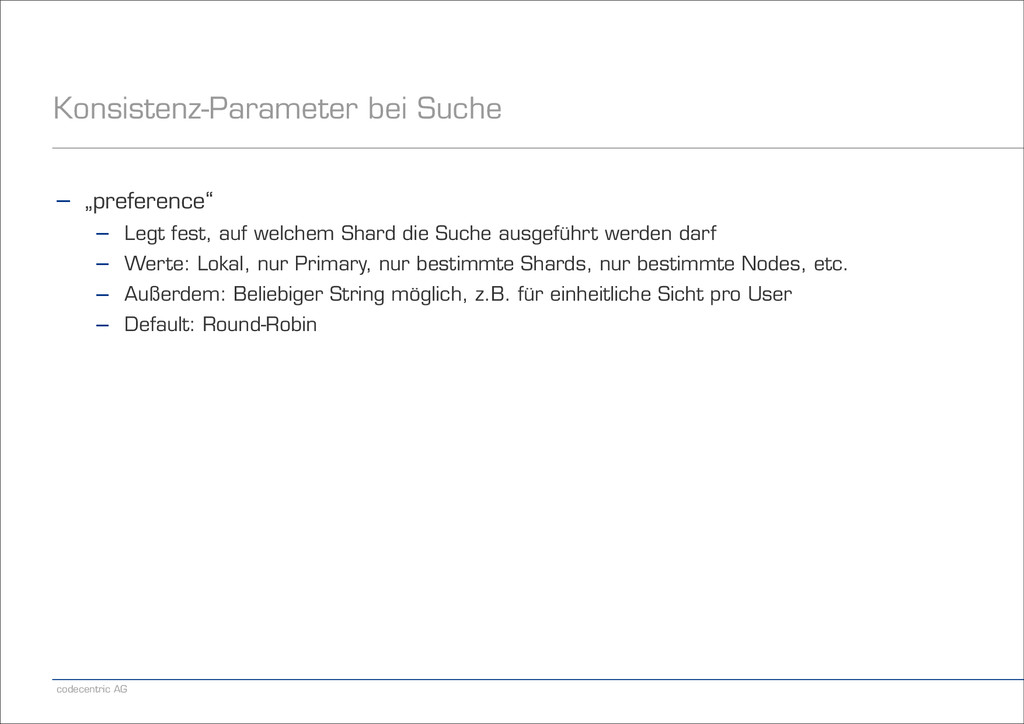
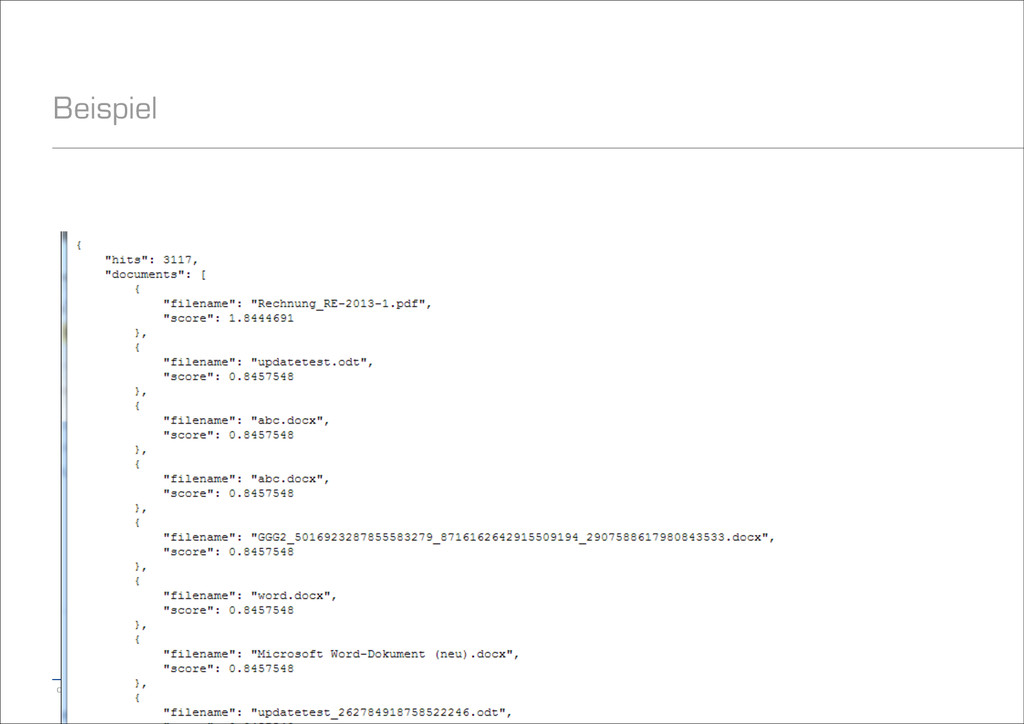
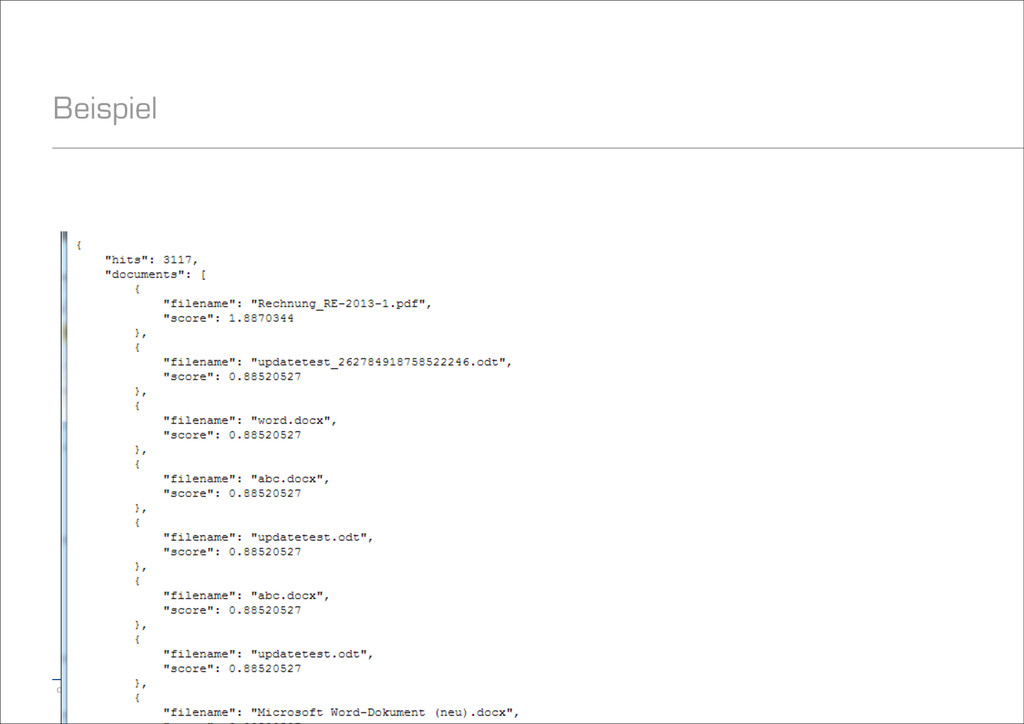
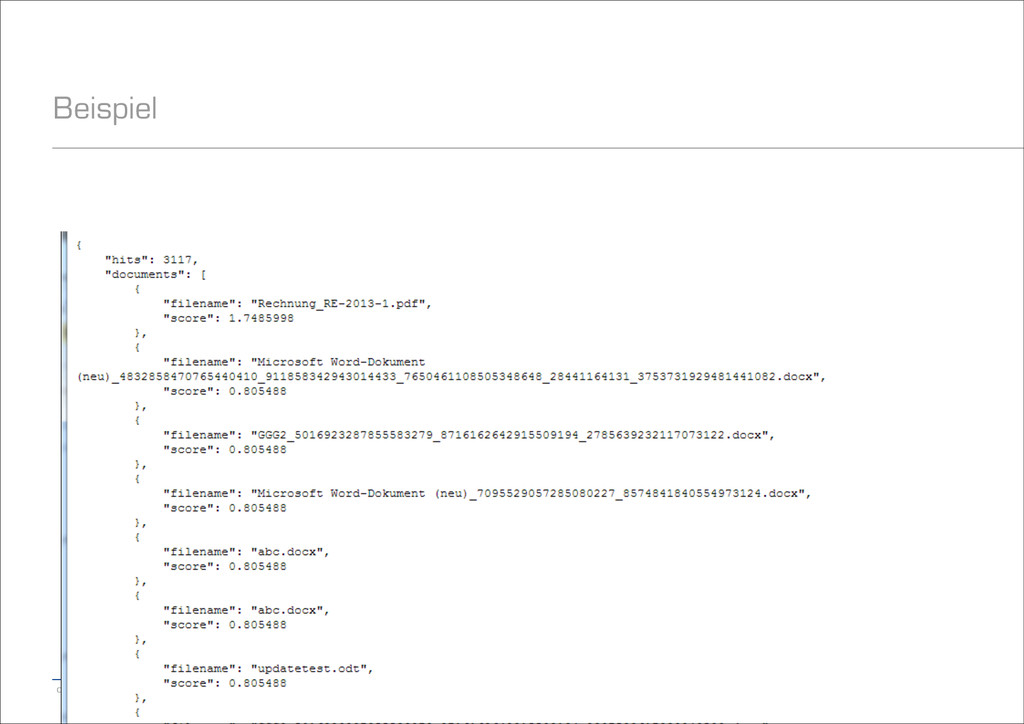
auf welchem Shard die Suche ausgeführt werden darf − Werte: Lokal, nur Primary, nur bestimmte Shards, nur bestimmte Nodes, etc. − Außerdem: Beliebiger String möglich, z.B. für einheitliche Sicht pro User − Default: Round-Robin
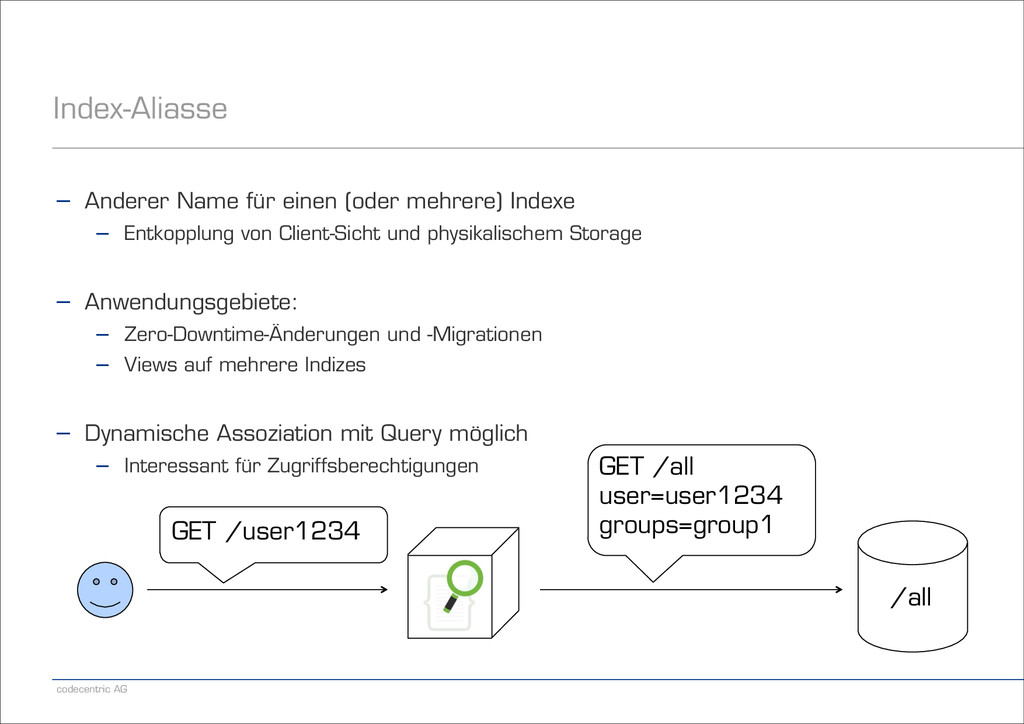
Indexe − Entkopplung von Client-Sicht und physikalischem Storage ! − Anwendungsgebiete: − Zero-Downtime-Änderungen und -Migrationen − Views auf mehrere Indizes
Indexe − Entkopplung von Client-Sicht und physikalischem Storage ! − Anwendungsgebiete: − Zero-Downtime-Änderungen und -Migrationen − Views auf mehrere Indizes ! − Dynamische Assoziation mit Query möglich − Interessant für Zugriffsberechtigungen GET /user1234 GET /all user=user1234 groups=group1 /all
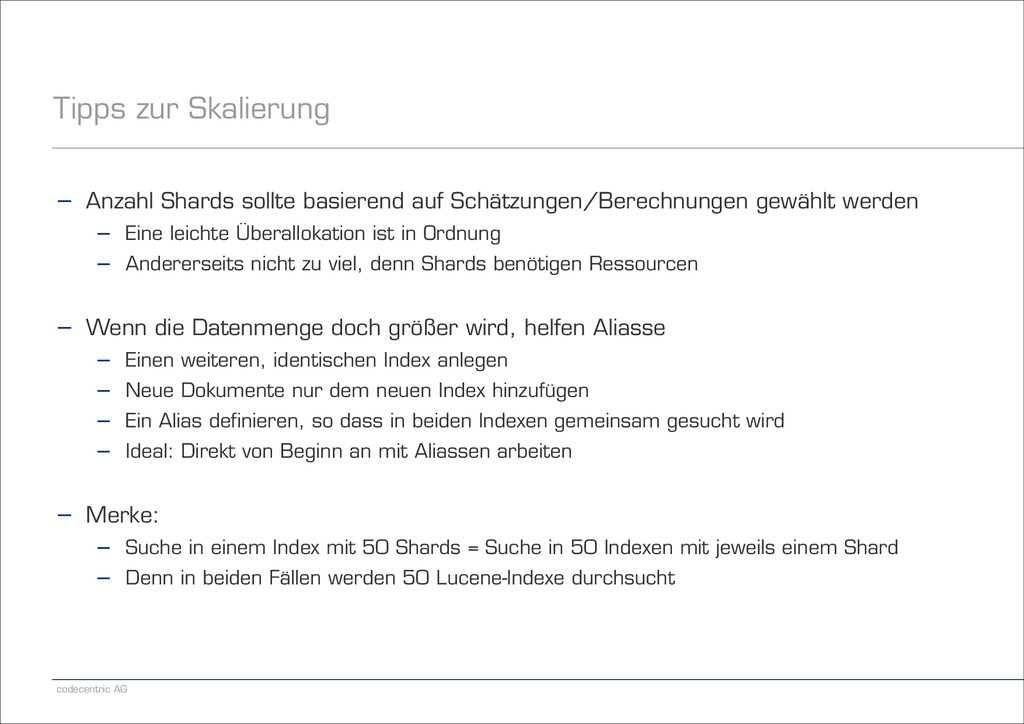
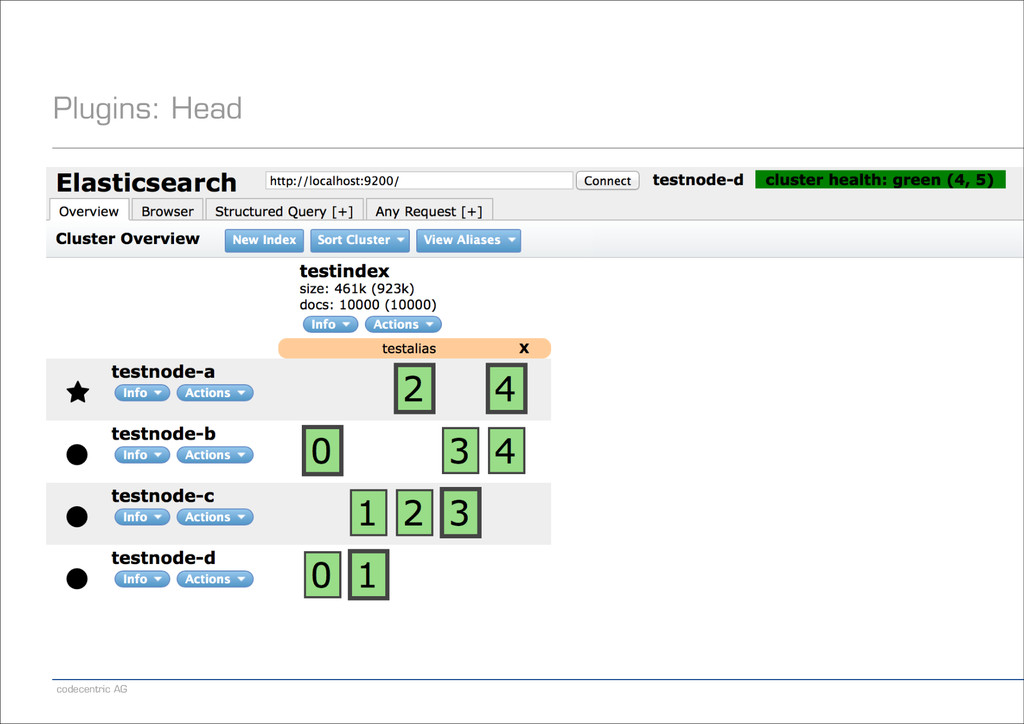
auf Schätzungen/Berechnungen gewählt werden − Eine leichte Überallokation ist in Ordnung − Andererseits nicht zu viel, denn Shards benötigen Ressourcen ! − Wenn die Datenmenge doch größer wird, helfen Aliasse − Einen weiteren, identischen Index anlegen − Neue Dokumente nur dem neuen Index hinzufügen − Ein Alias definieren, so dass in beiden Indexen gemeinsam gesucht wird − Ideal: Direkt von Beginn an mit Aliassen arbeiten ! − Merke: − Suche in einem Index mit 50 Shards = Suche in 50 Indexen mit jeweils einem Shard − Denn in beiden Fällen werden 50 Lucene-Indexe durchsucht
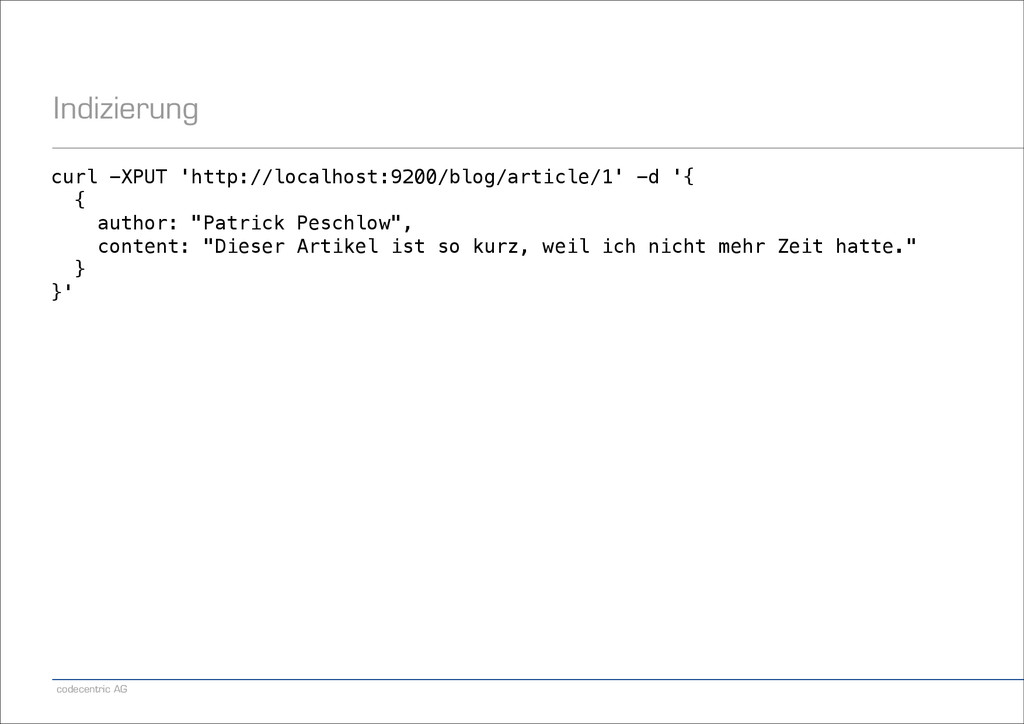
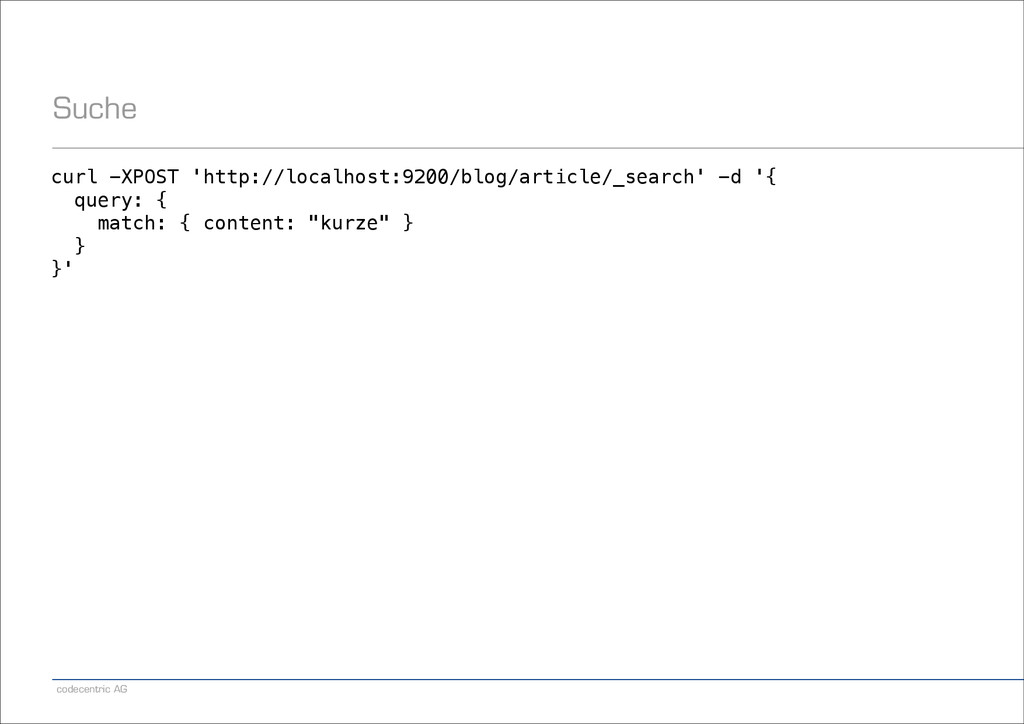
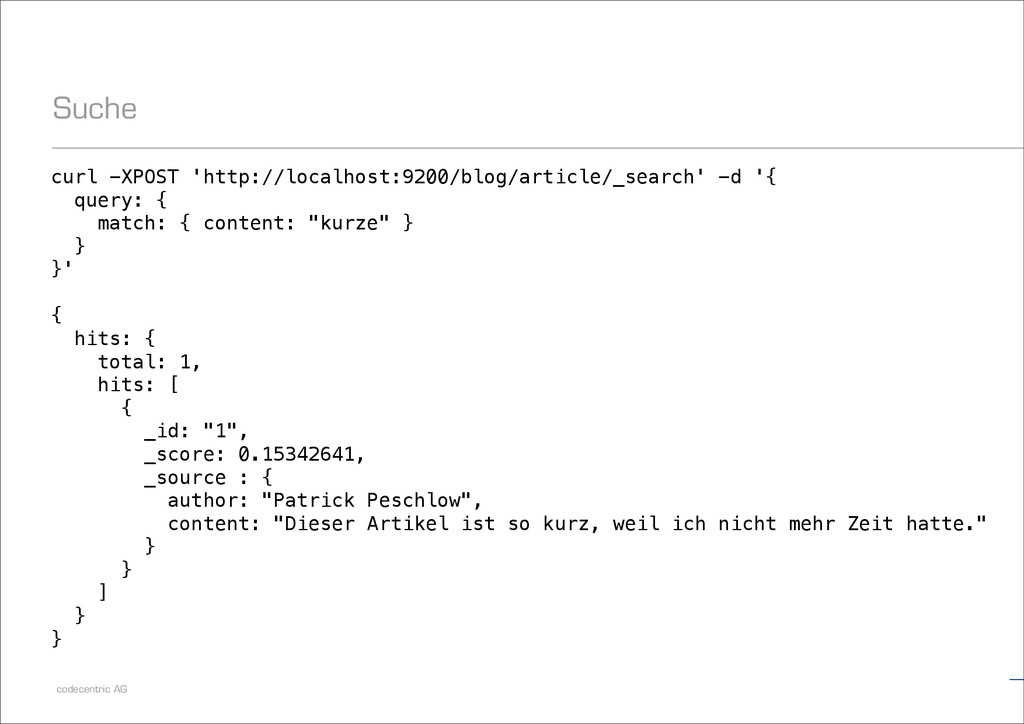
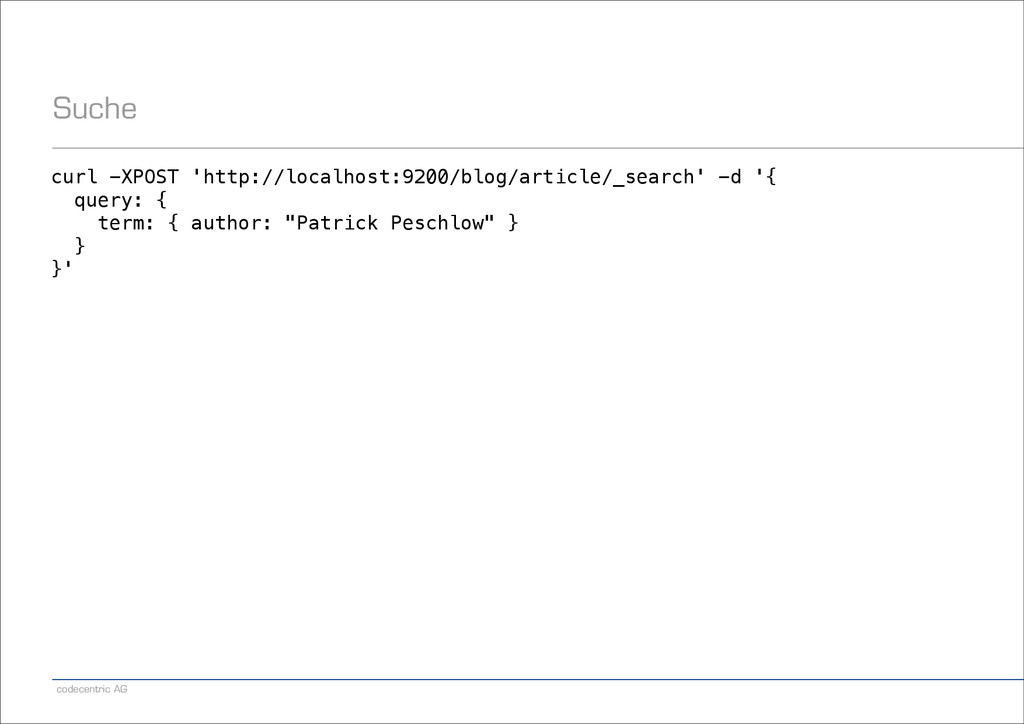
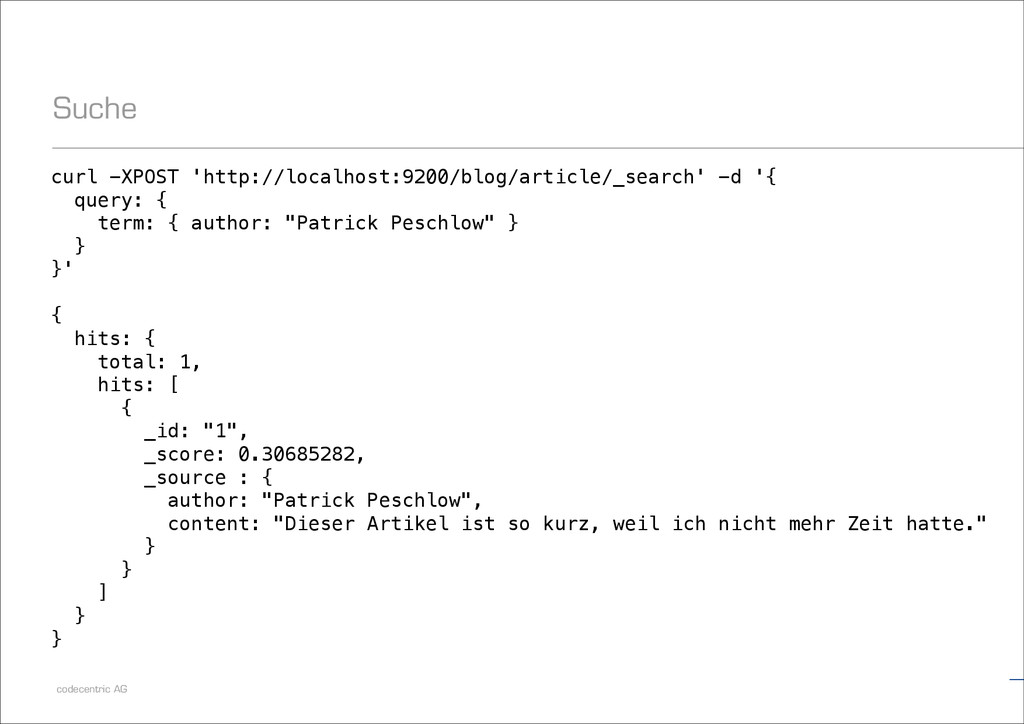
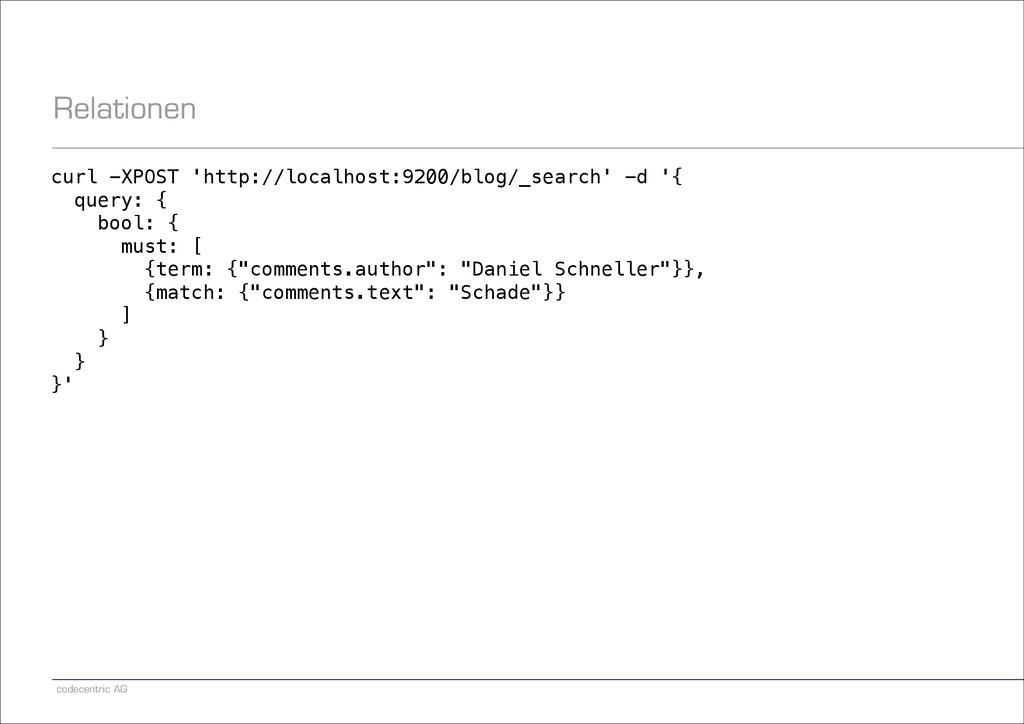
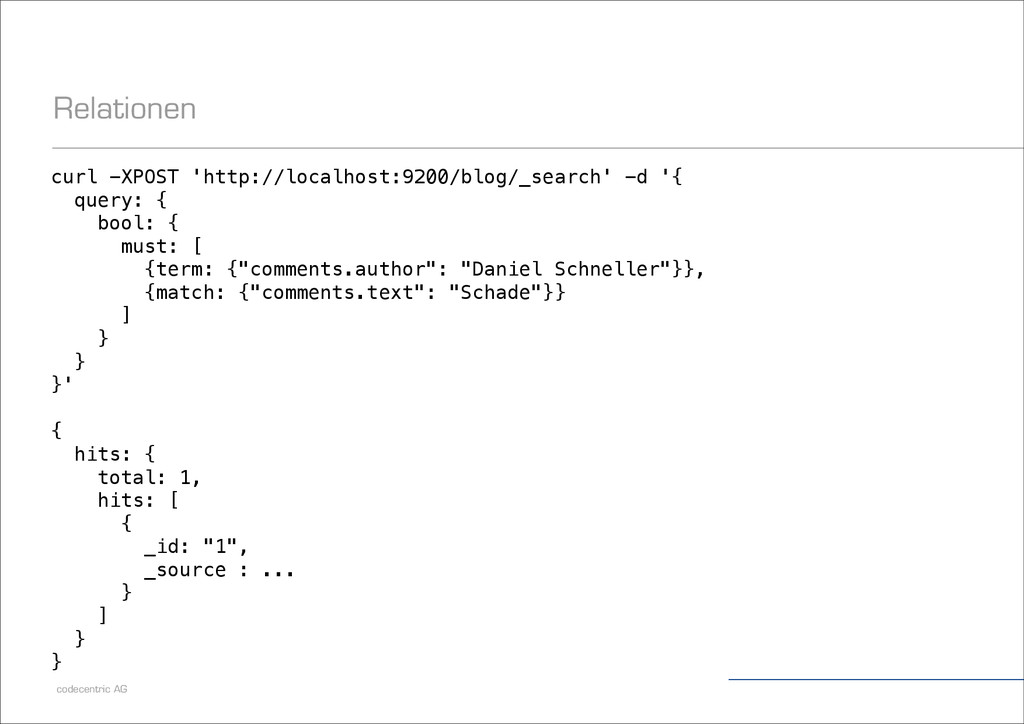
"Patrick Peschlow", content: "Dieser Artikel ist so kurz, weil ich nicht mehr Zeit hatte.“, comments: [ {author: "Lukas Pustina", text: "Schade."}, {author: "Daniel Schneller", text: "Wie zu erwarten war."} ] } }'
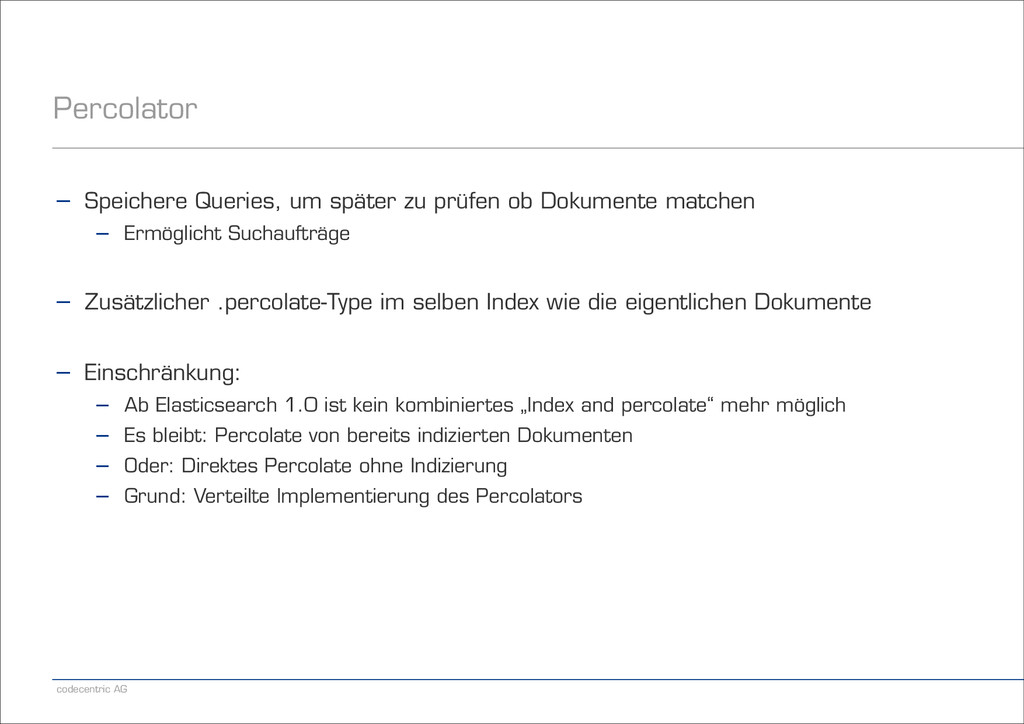
ob Dokumente matchen − Ermöglicht Suchaufträge ! − Zusätzlicher .percolate-Type im selben Index wie die eigentlichen Dokumente ! − Einschränkung: − Ab Elasticsearch 1.0 ist kein kombiniertes „Index and percolate“ mehr möglich − Es bleibt: Percolate von bereits indizierten Dokumenten − Oder: Direktes Percolate ohne Indizierung − Grund: Verteilte Implementierung des Percolators
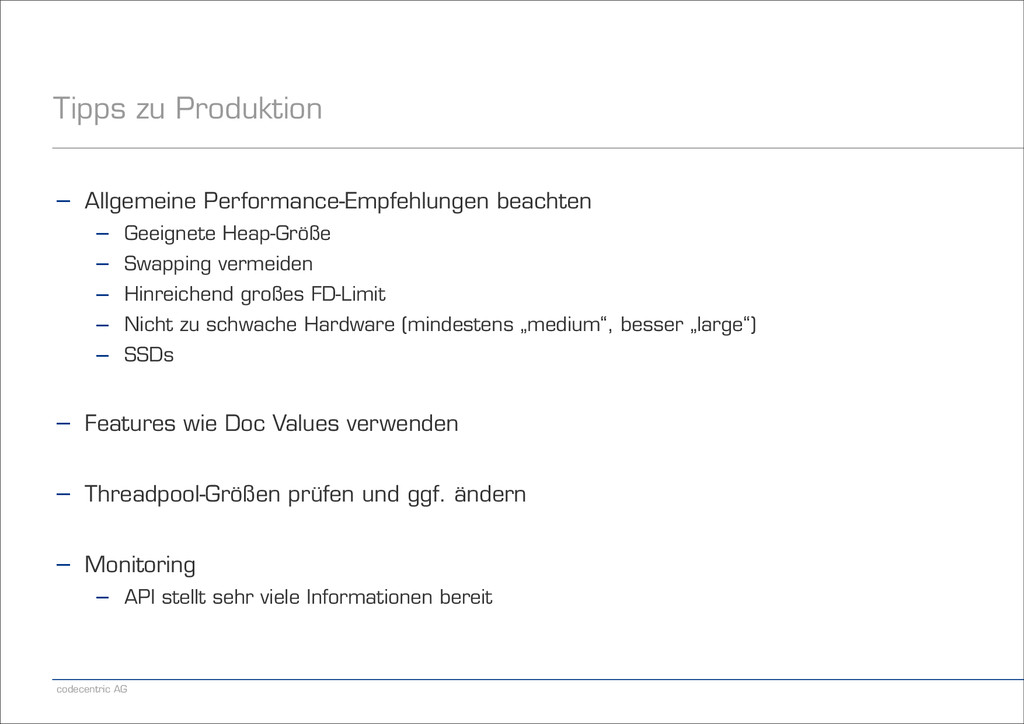
Geeignete Heap-Größe − Swapping vermeiden − Hinreichend großes FD-Limit − Nicht zu schwache Hardware (mindestens „medium“, besser „large“) − SSDs ! − Features wie Doc Values verwenden ! − Threadpool-Größen prüfen und ggf. ändern ! − Monitoring − API stellt sehr viele Informationen bereit
− Script ! − Achtung − Auch feingranulare Updates bedeuten intern „Löschen + Hinzufügen“ − Updates benötigen _source − Partial Document Update von inneren Objekten ist ein Merge, alles sonst ein Replace − Partial Document und Script können nicht miteinander kombiniert werden
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}