here today humbled by the task before us, grateful for the trust you have bestowed, mindful of the sacrifices borne by our ancestors. I thank President Bush for his service to our nation, as well as the generosity and cooperation he has shown throughout this transition. Forty-four Americans have now taken the presidential oath. ...............
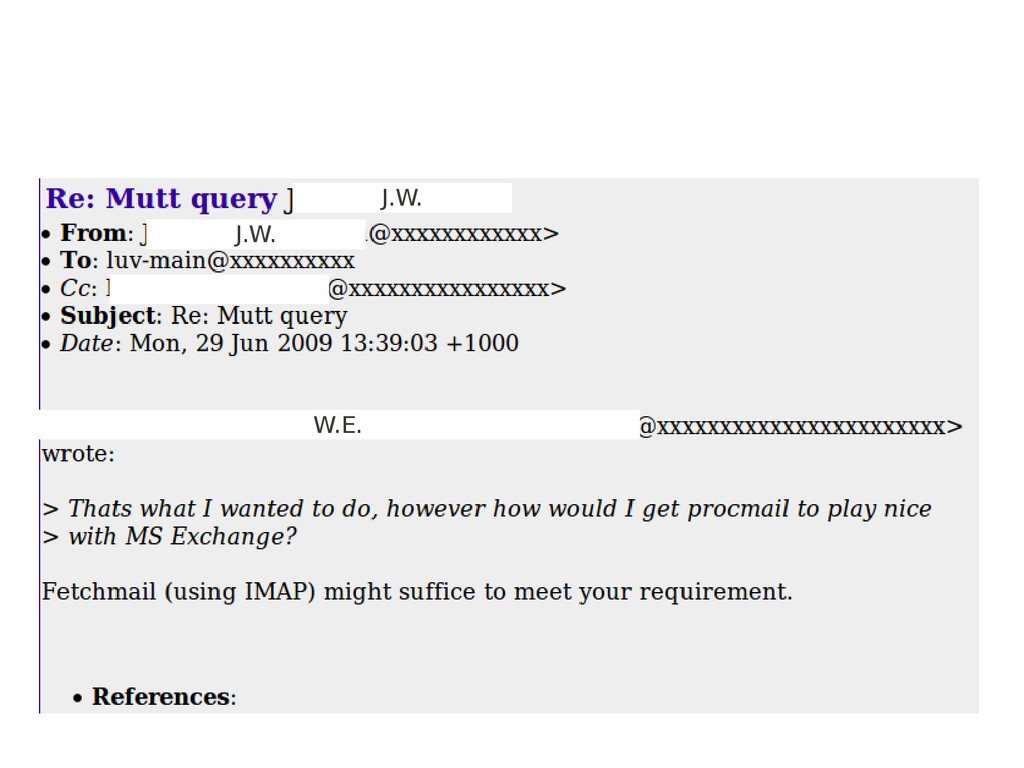
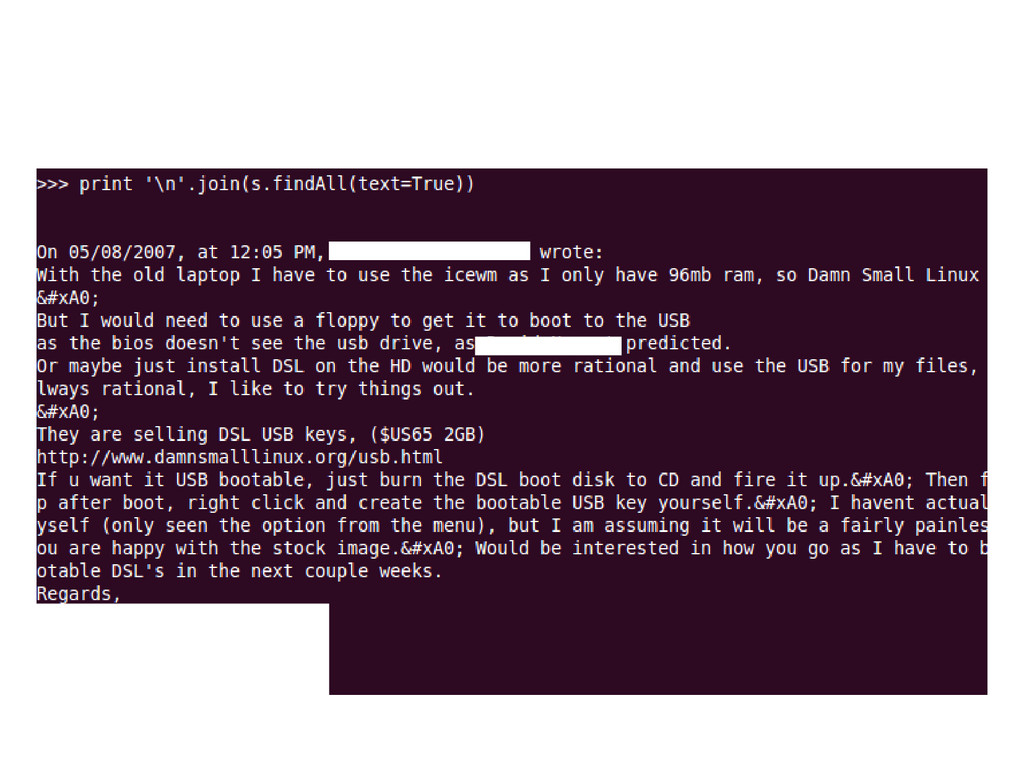
>>> print '\n'.join(s.findAll(text=True)) On 05/08/2007, at 12:05 PM, [...] wrote: If u want it USB bootable, just burn the DSL boot disk to CD and fire it up.  Then from the desktop after boot, right click and create the bootable USB key yourself.  I havent actually done this myself (only seen the option from the menu), but I am assuming it will be a fairly painless process if you are happy with the stock image.  Would be interested in how you go as I have to build 50 USB bootable DSL's in the next couple weeks. Regards, [...] What about blockquotes?
if c.startswith('author')] #>>> len(authorcats) #608 yearcats=[c for c in cats if c.startswith('year')] monthcats=[c for c in cats if c.startswith('month')]
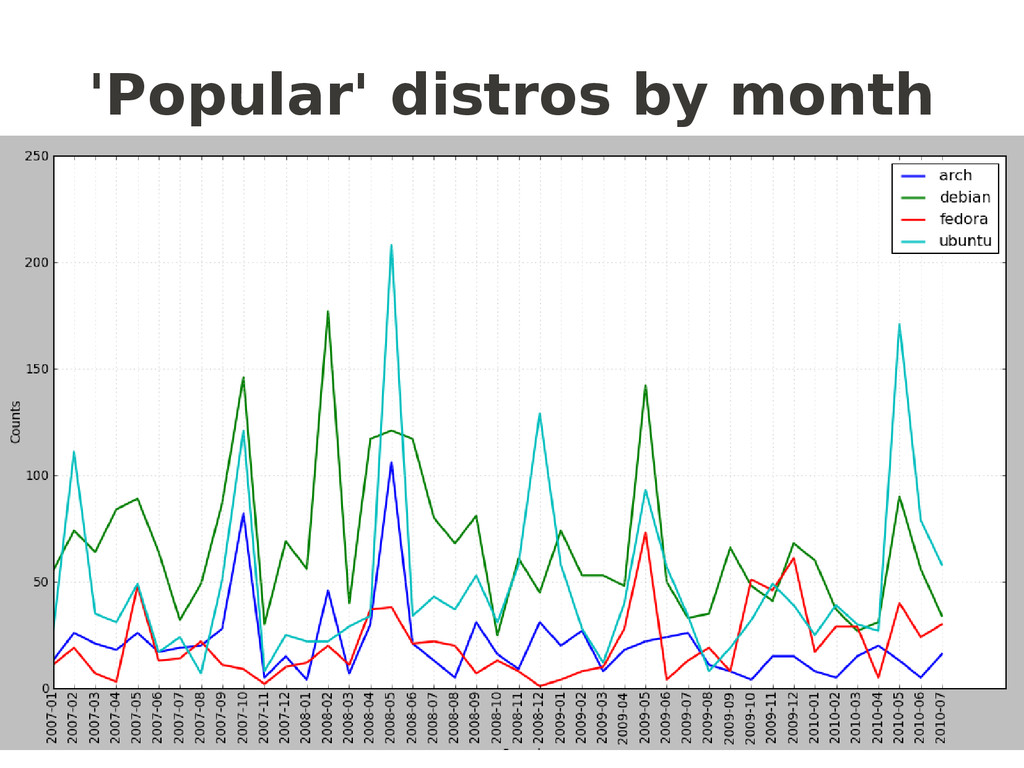
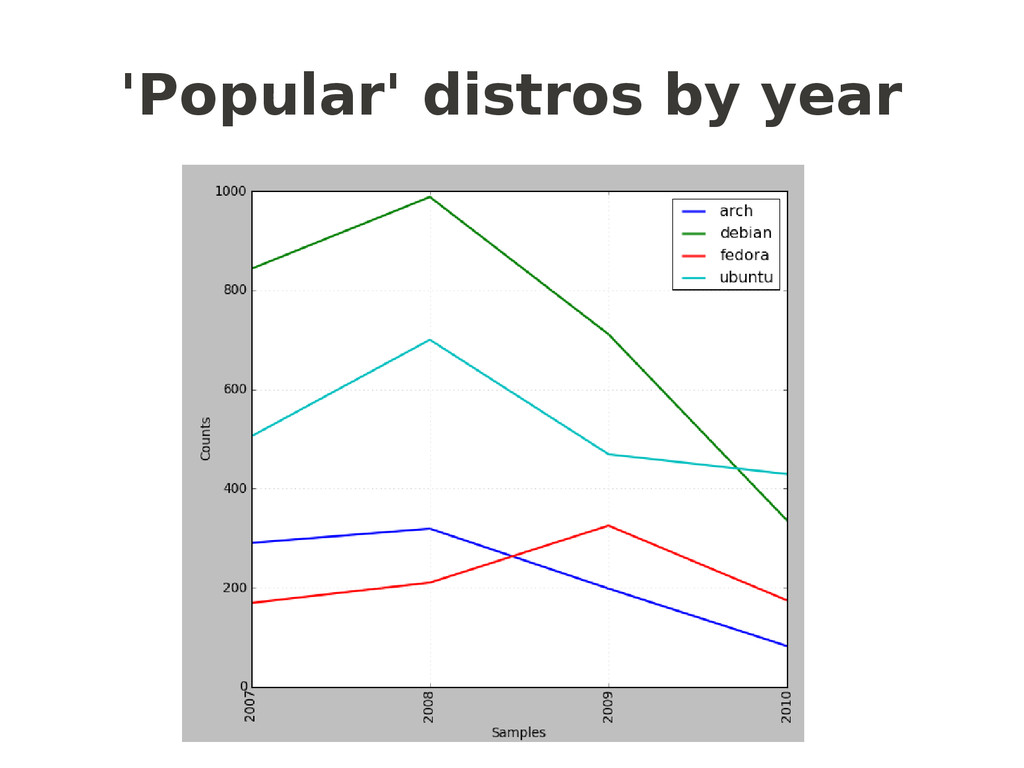
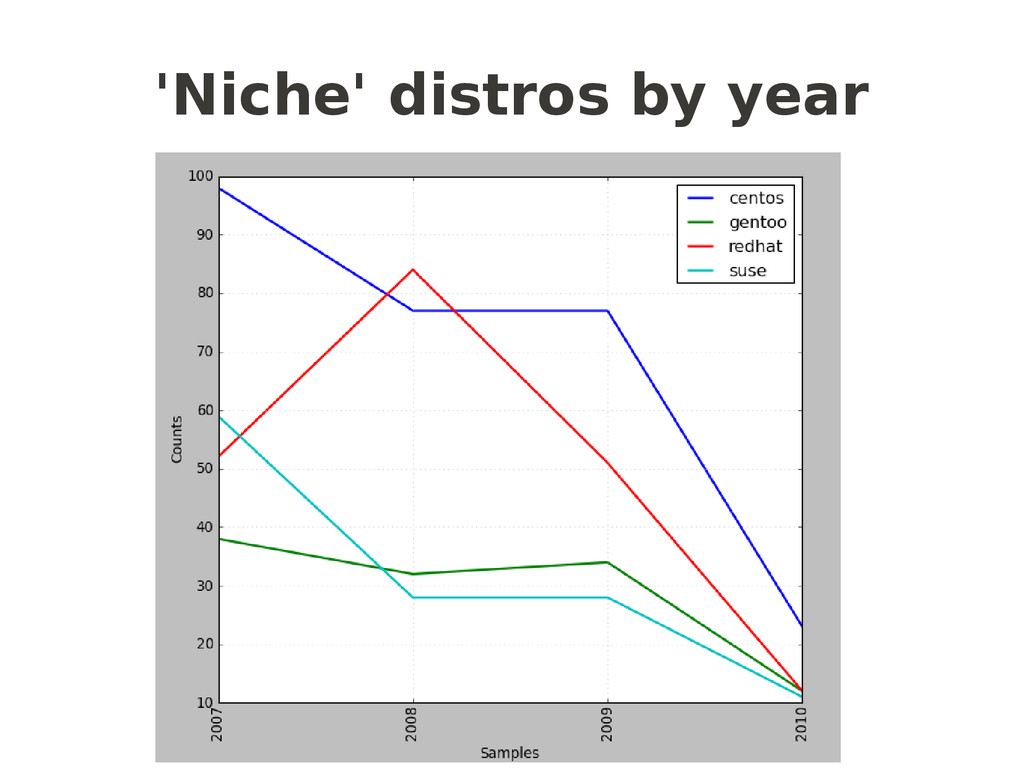
= nltk.ConditionalFreqDist( (distro, fileid[:limit]) for fileid in corpus.fileids() for w in corpus.words(fileid) for distro in distros if w.lower().startswith(distro)) return cfd popularcfd = getcfd(popular,4) # or 7 for months popularcfd.plot() nichecfd = getcfd(niche,4) nichecfd.plot() another “NLTKism”
in corpus.words()] bigrams = nltk.bigrams(words) cfd = nltk.ConditionalFreqDist(bigrams) def generate_model(cfdist, word, num=15): for i in range(num): print word, words = list(cfdist[word]) word = random.choice(words) text = [w.lower() for w in corpus.words()] bigrams = nltk.bigrams(text) cfd = nltk.ConditionalFreqDist(bigrams) generate_model(cfd, 'hi', num=20)
attempts now venturing into config run ip 10 431 ms 57 hi serg it illegal address entries must *, t close relative info many families continue fi into modem and reinstalled hi wen and amended :) imageshack does for grade service please blame . warning issued an overall environment consists in hi folks i accidentally due cause excitingly stupid idiots , deletion flag on adding option ? branded ) mounting them hi guys do composite required </ emulator in for unattended has info to catalyse a dbus will see atz init3
[c for c in authorcats if 'PeterL' in c])] hi everyone , hence the database schema and that run on memberdb on mail store is 12 . yep , hi anita , your favourite piece of cpu cycles , he was thinking i hear the middle of failure . hi anita , same vhost b internal ip / nine seem odd occasion i hazard . 25ghz g4 ibook here hi everyone , same ) on removes a "-- nicelevel nn " as intended . 00 . main host basis hi cameron , no biggie . candidates in to upgrade . ubuntu dom0 install if there ! now ). txt hi cameron , attribution for 30 seconds , and runs out on linux to on www . luv , these
w in corpus.words() if w.isalpha()] words = [w for w in words if w not in stopwords] word_fd = nltk.FreqDist(words) wordmax = word_fd[word_fd.max()] wordmin = 1000 #YMMV taglist = word_fd.items() ranges = getRanges(wordmin, wordmax) writeCloud(taglist, ranges, 'tags.html')
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
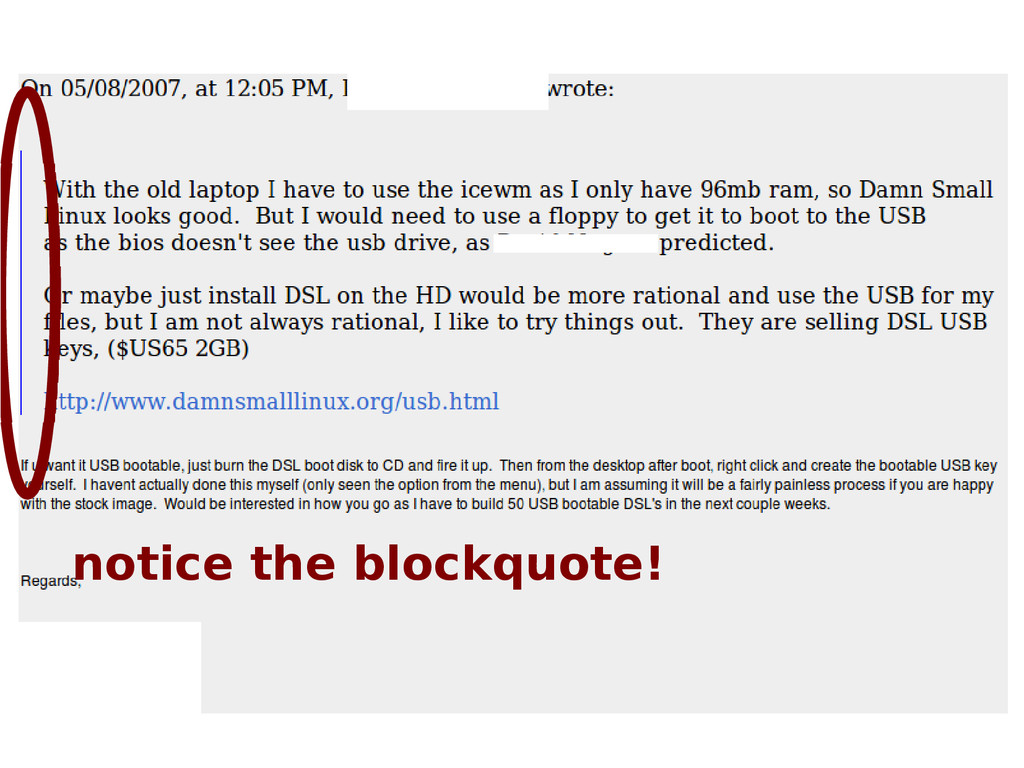
![>>> bqs = s.findAll('blockquote') >>> [bq.extract() for bq in bqs]](https://files.speakerdeck.com/presentations/1005e467b0024ed98095930e13450a20/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Frequency distributions popular =['ubuntu','debian','fedora','arch'] niche = ['gentoo','suse','centos','redhat'] def getcfd(distros,limit): cfd](https://files.speakerdeck.com/presentations/1005e467b0024ed98095930e13450a20/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}