$lmt[2,4066,0,0] $lbi; dvpassa $lmt[2,4066,0,0] $ln0/0010 l1bmd+2 $lmt[4,4068,20,4084] $lb128; l1bmd+1 $lbi $ln[4094,30,0,0]/1100 l1bmd+3 $lmt[6,4070,22,4086] $lb0; l1bmd+2 $lbi $ln[4092,28,0,0]/1100 l1bmd+4 $lmt[8,4072,24,4088] $lb512; l1bmd+3 $lbi $ln[4090,26,0,0]/1100 l1bmd+5 $lmt[10,4074,26,4090] $lb384; l1bmd+4 $lbi $ln[4088,24,0,0]/1100 l1bmd+6 $lmt[12,4076,28,4092] $lb896; l1bmd+5 $lbi $ln[4086,22,0,0]/1100 l1bmd+7 $lmt[14,4078,30,4094] $lb768; l1bmd+6 $lbi $ln[4084,20,0,0]/1100 l1bmd+8 $lmt[16,4080,0,0] $lbi; l1bmd+7 $lbi $ln[4082,18,0,0]/1100 l1bmd+9 $lmt[18,4082,0,0] $lbi; l1bmd+8 $lbi $ln[4080,16,0,0]/1100 l1bmd+9/1100 $lbi $ln[4078,14,4078,4078]/1100 l1bmd+8 $lb128 $ln[4074,10,4076,12] l1bmd+8 $lb512 $ln[4070,6,4072,8] l1bmd+8 $lb896 $ln[4066,2,4068,4]
{kind=link}
{kind=link}
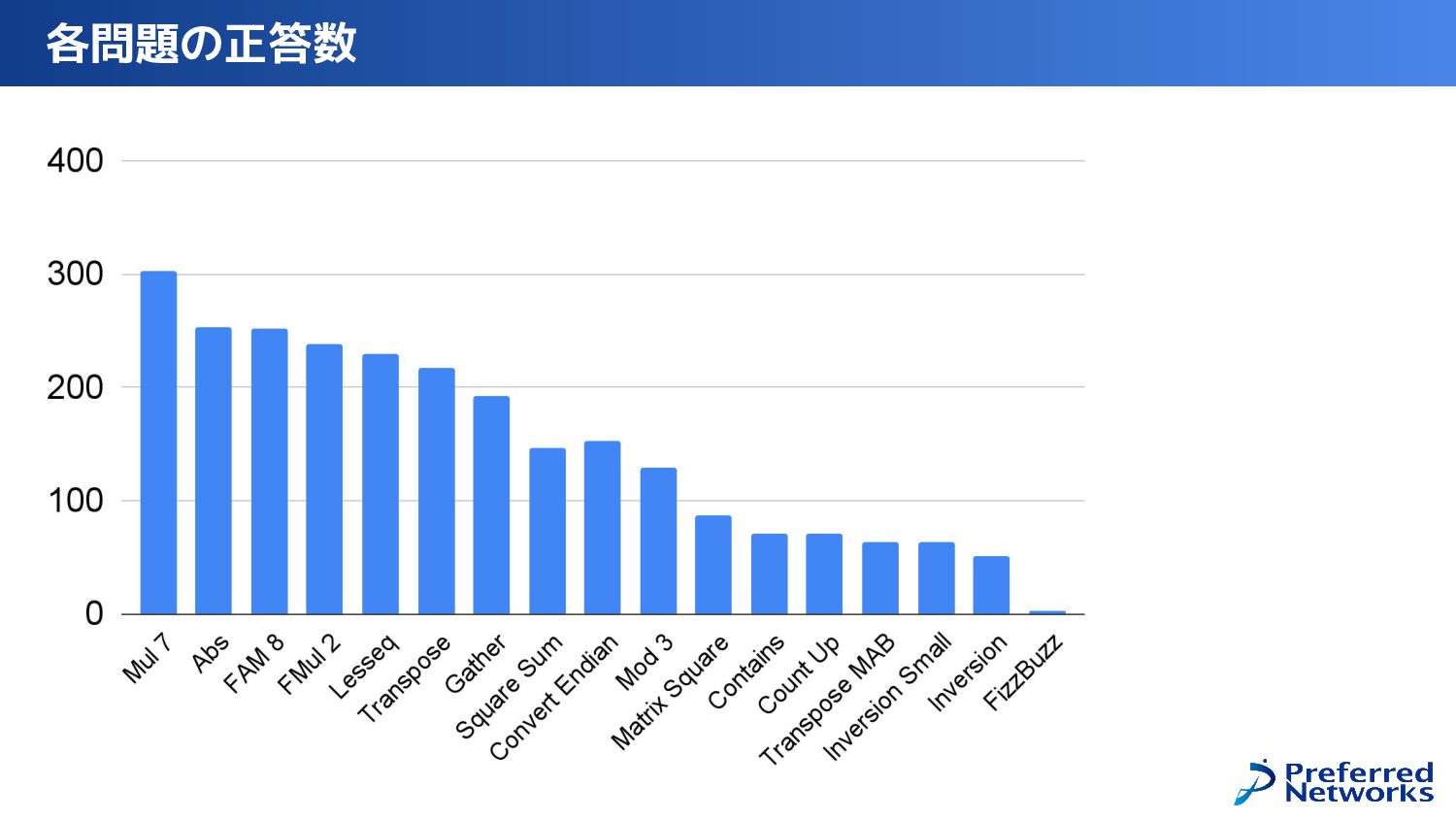{kind=link}
{kind=link}
{kind=link}
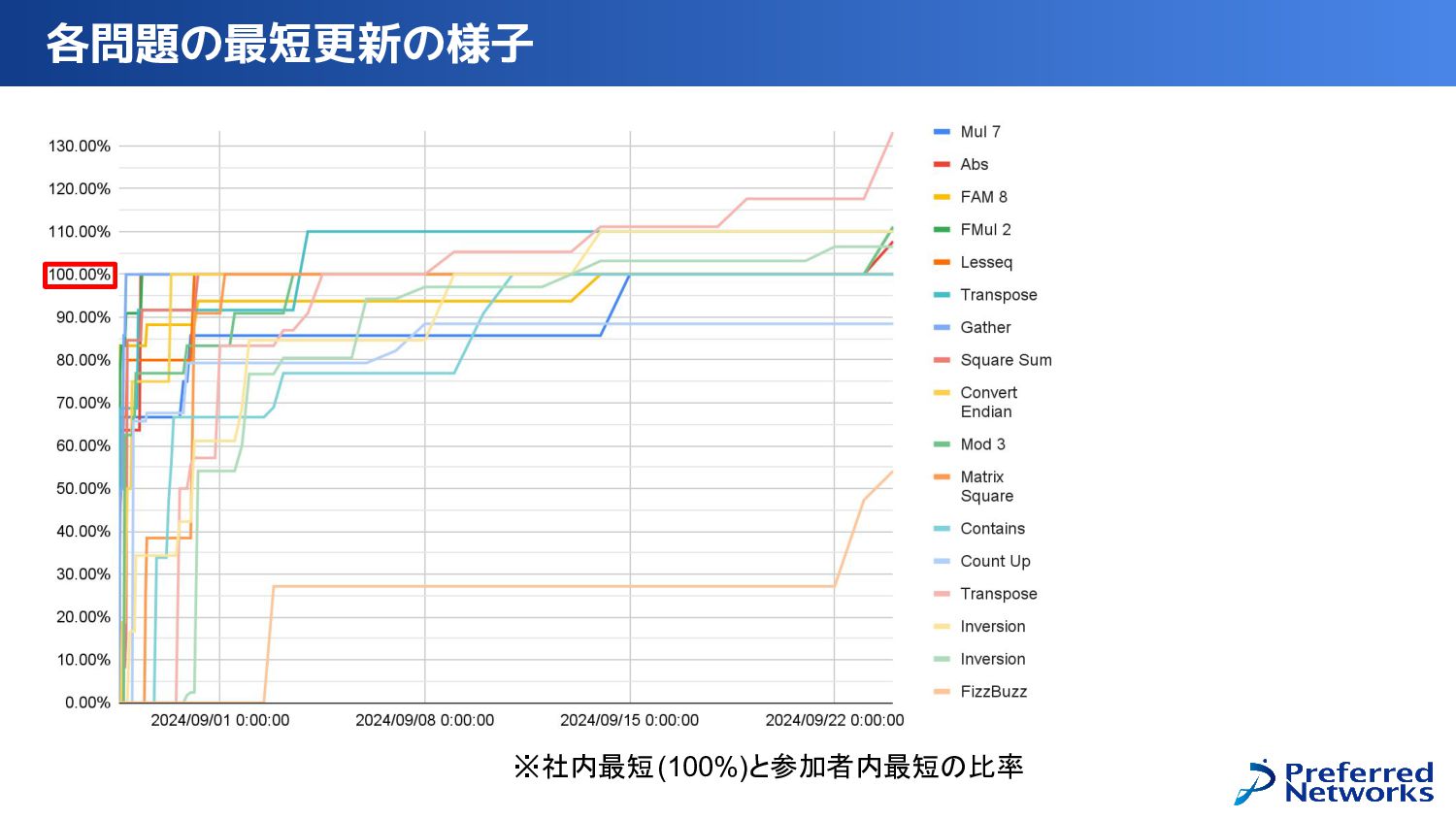{kind=link}
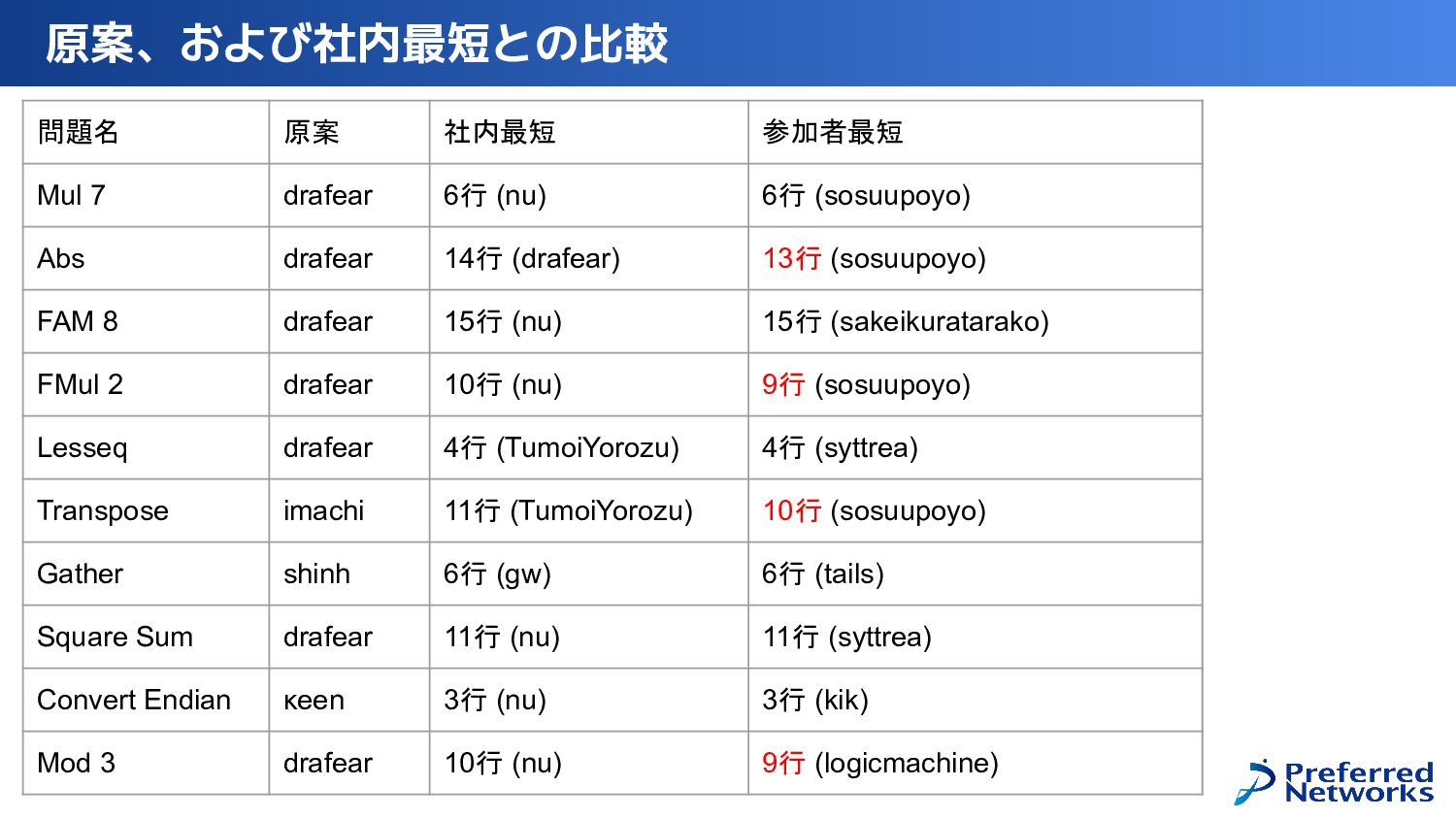{kind=link}
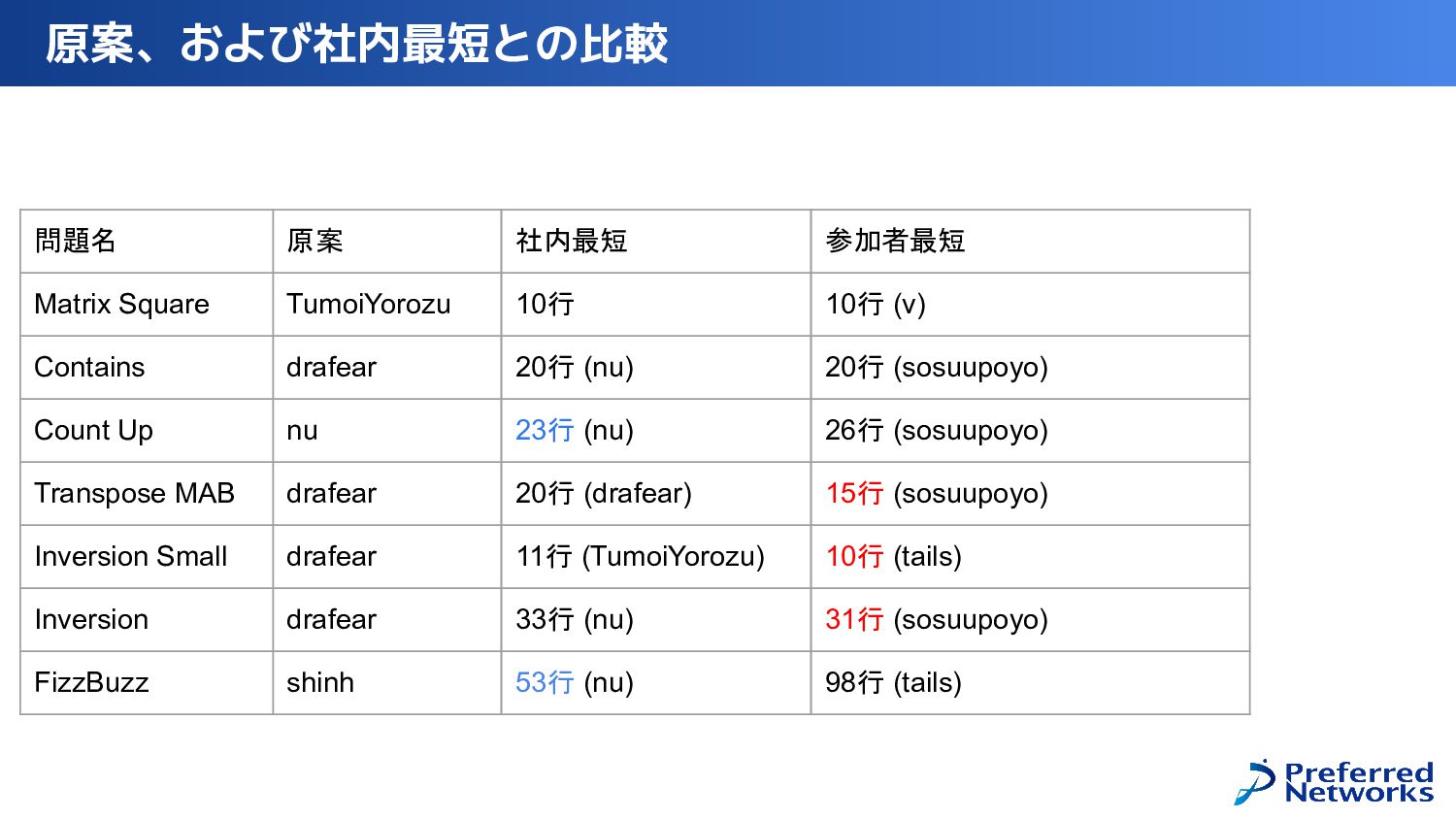{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
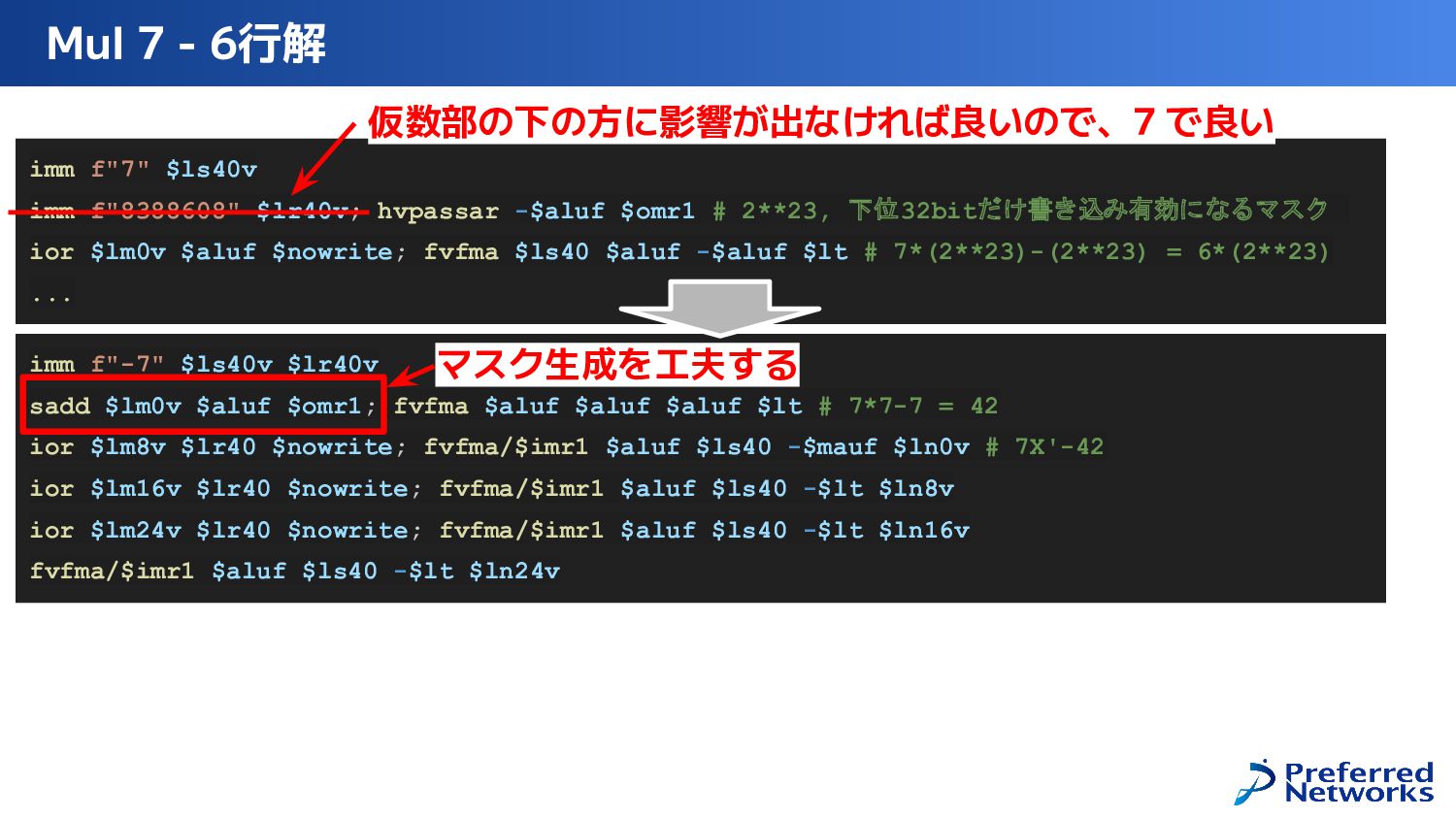{kind=link}
{kind=link}
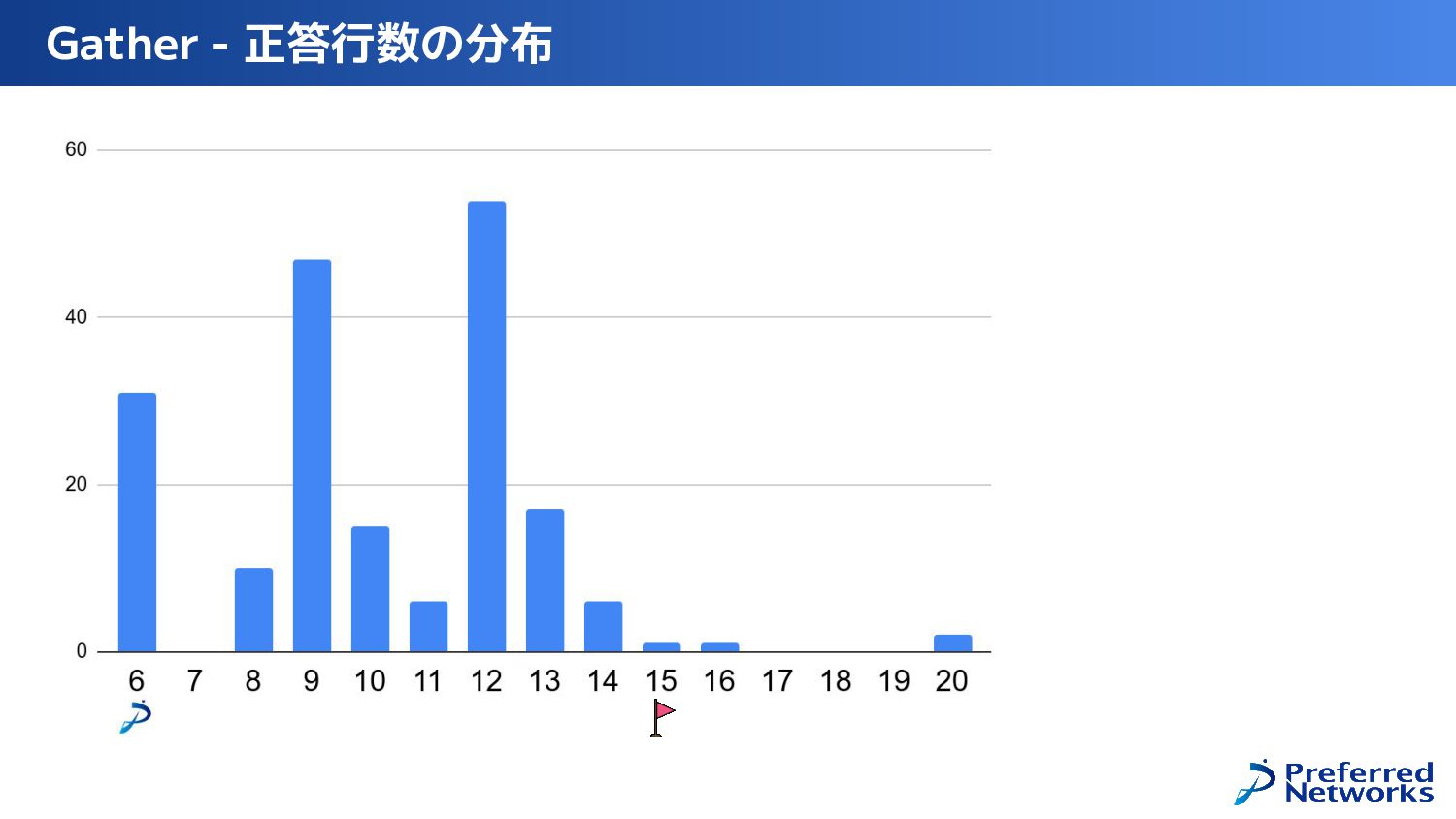{kind=link}
![Gather 簡易解説 問題 Y = X[I] • チュートリアルに従って解くと、T間接が律速で9行 • PEごとに並列に間接参照を行うと8行](https://files.speakerdeck.com/presentations/66f3d29f9f9246ac8ed4c243bb687a96/slide_56.jpg){kind=link}
{kind=link}
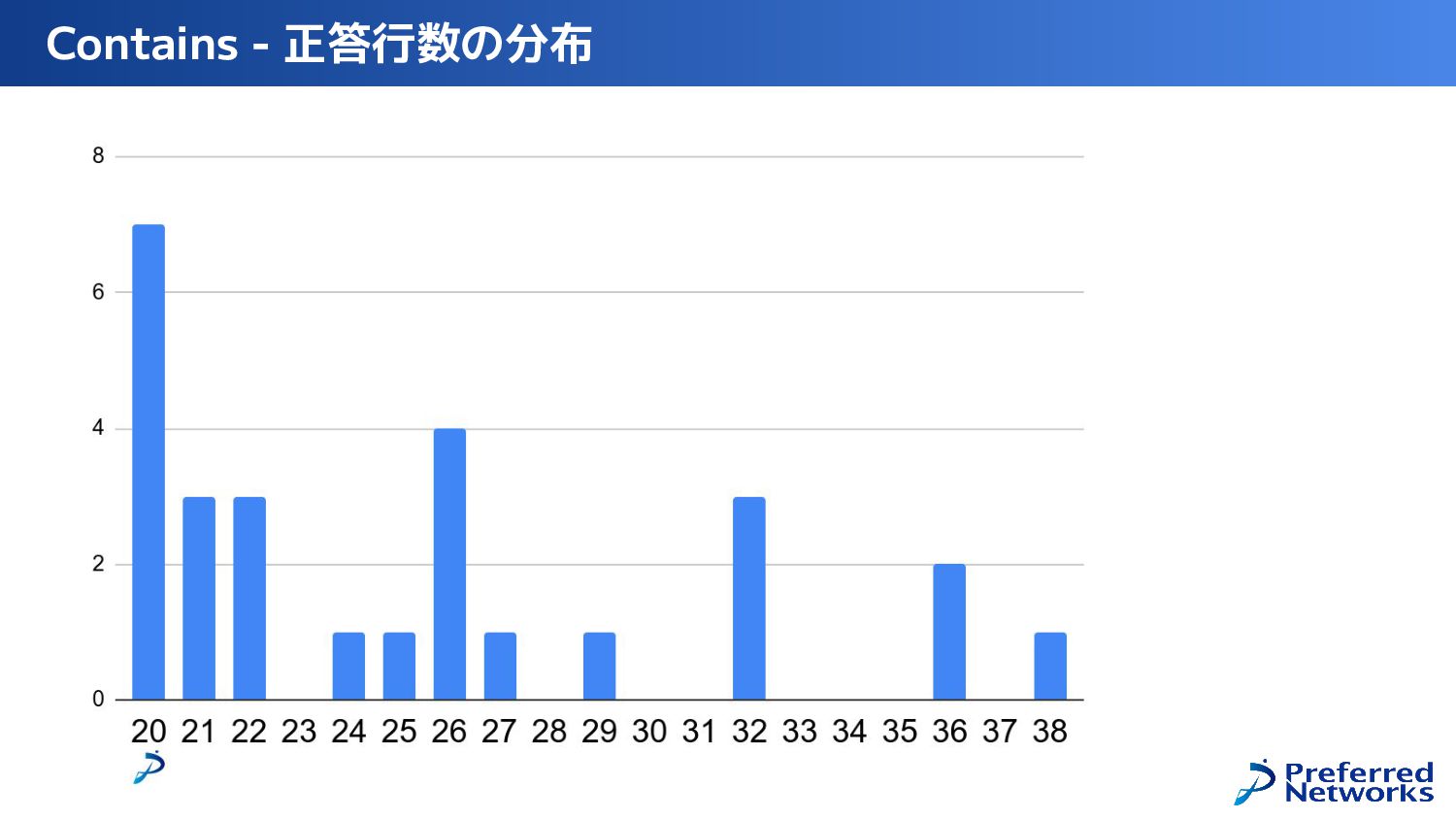{kind=link}
![Contains 簡易解説 C[i] = A[i] in B ? 1 :](https://files.speakerdeck.com/presentations/66f3d29f9f9246ac8ed4c243bb687a96/slide_59.jpg){kind=link}
{kind=link}
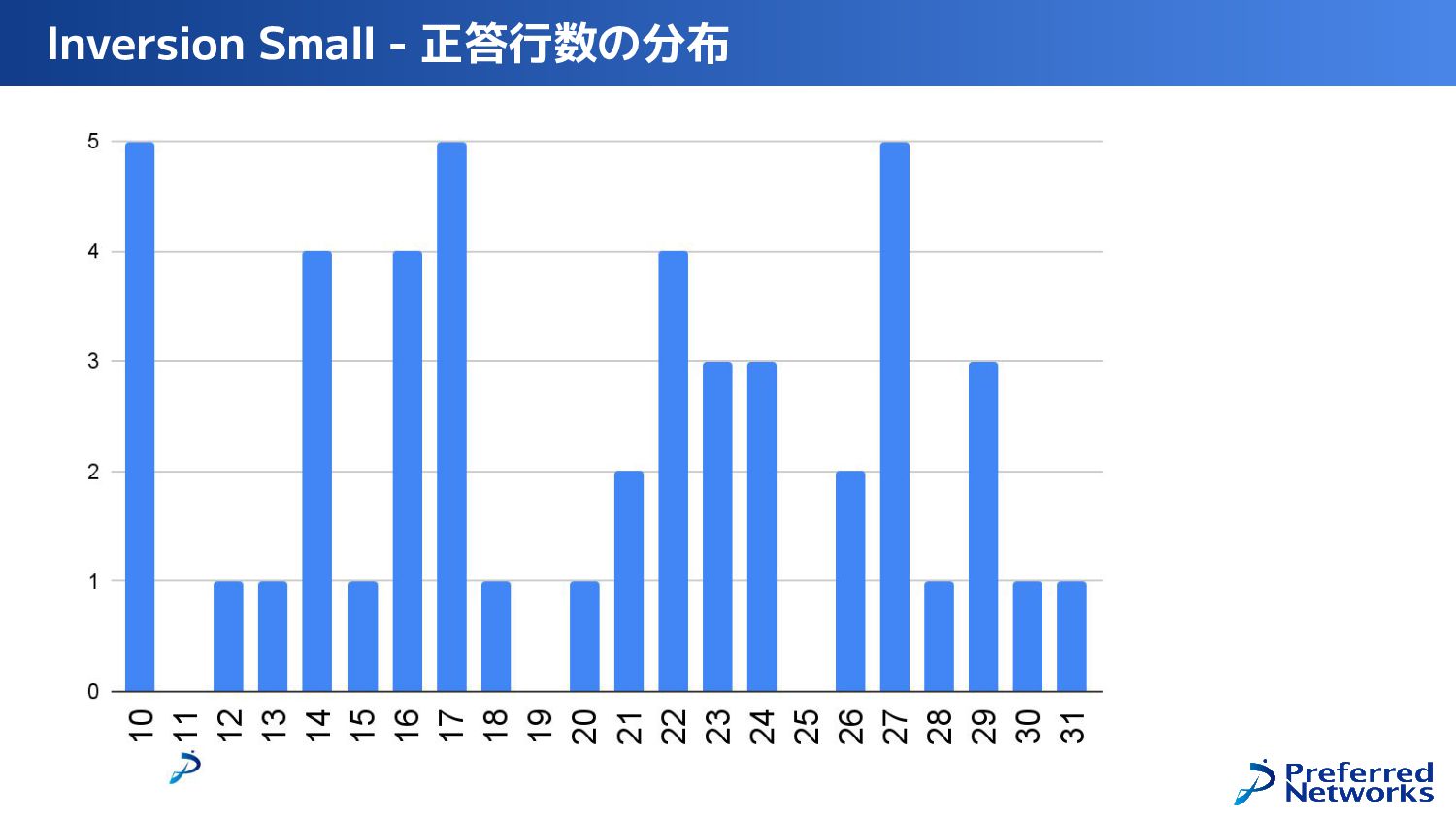{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
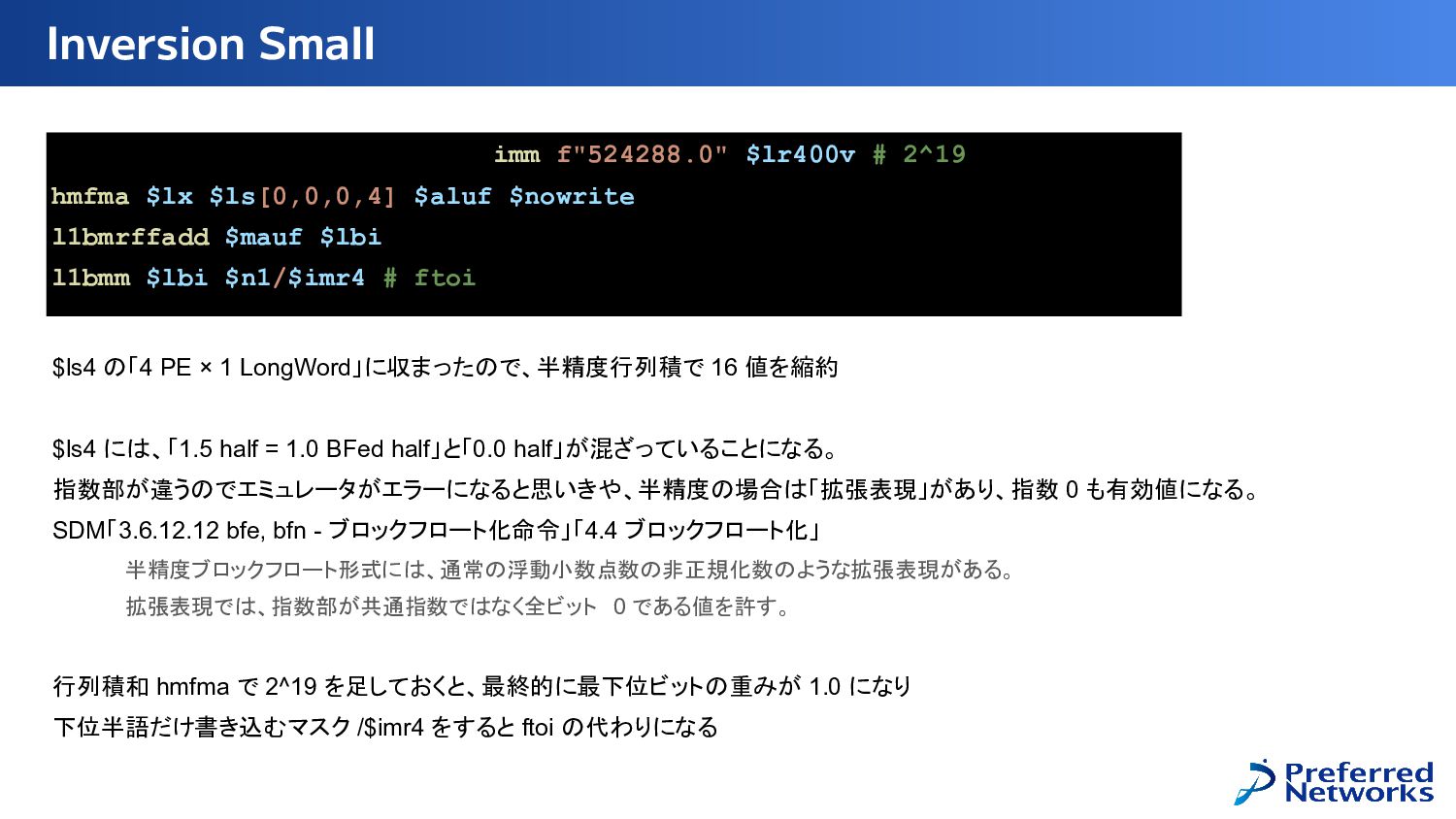{kind=link}
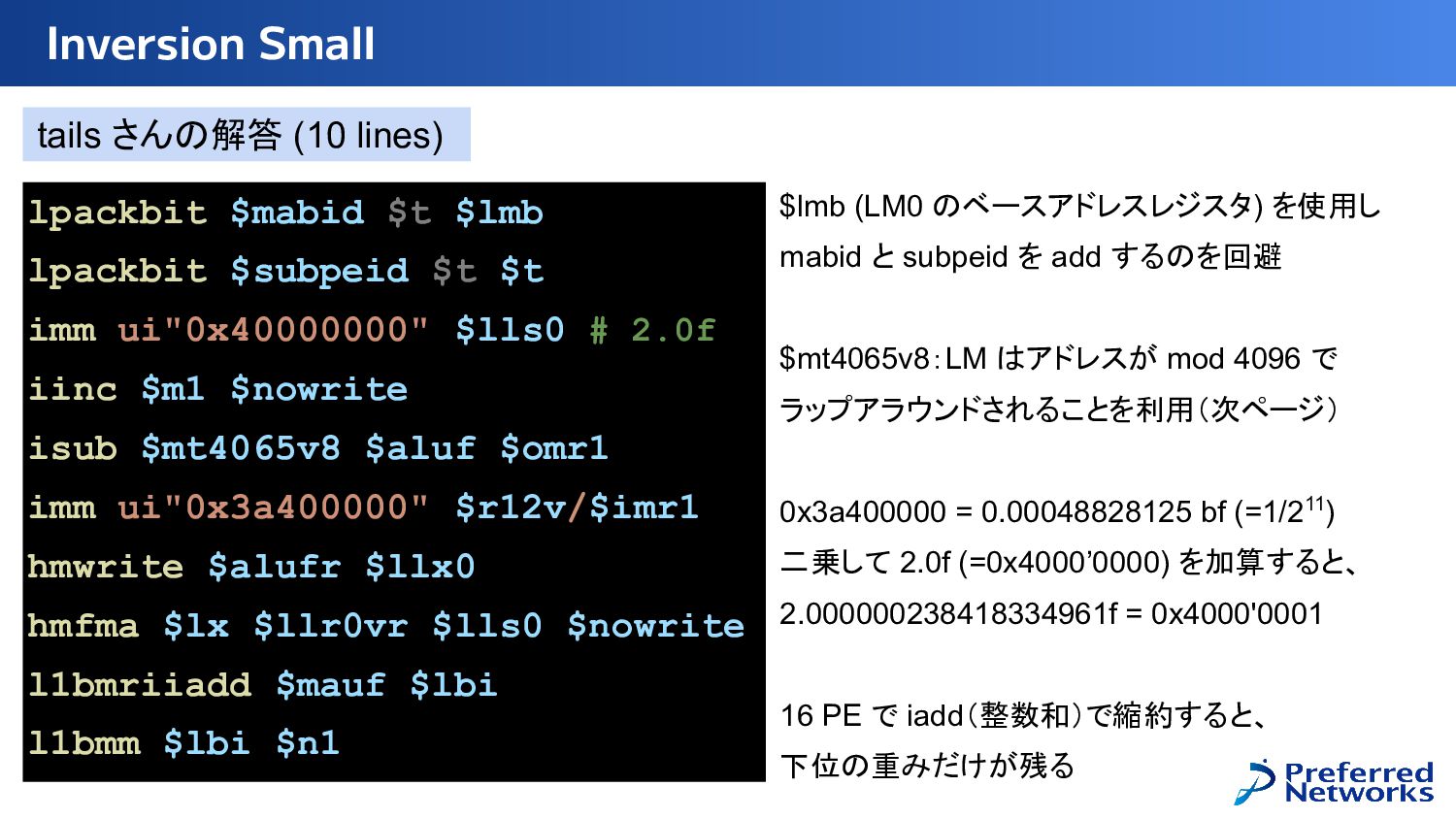{kind=link}
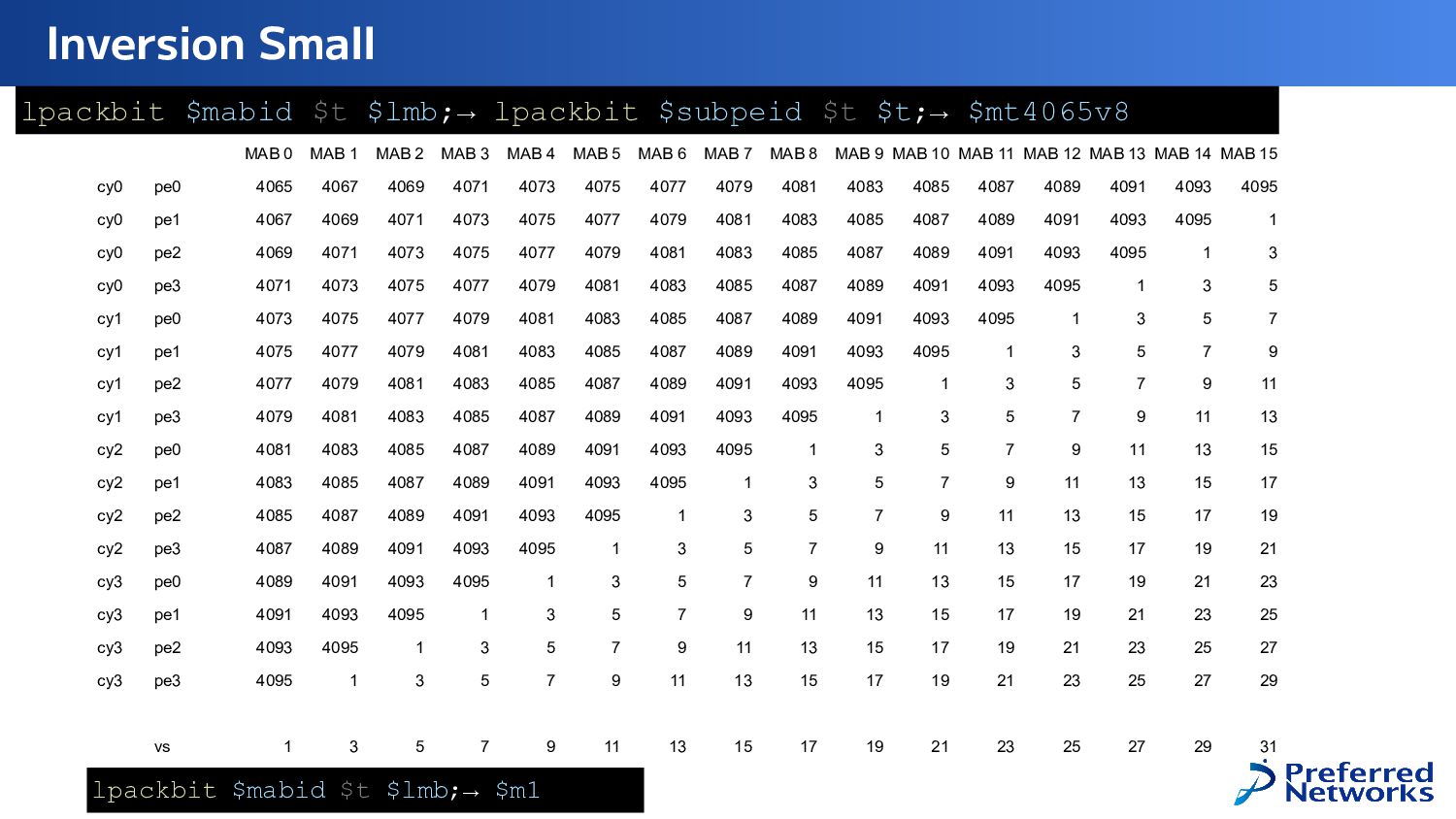{kind=link}
{kind=link}
{kind=link}
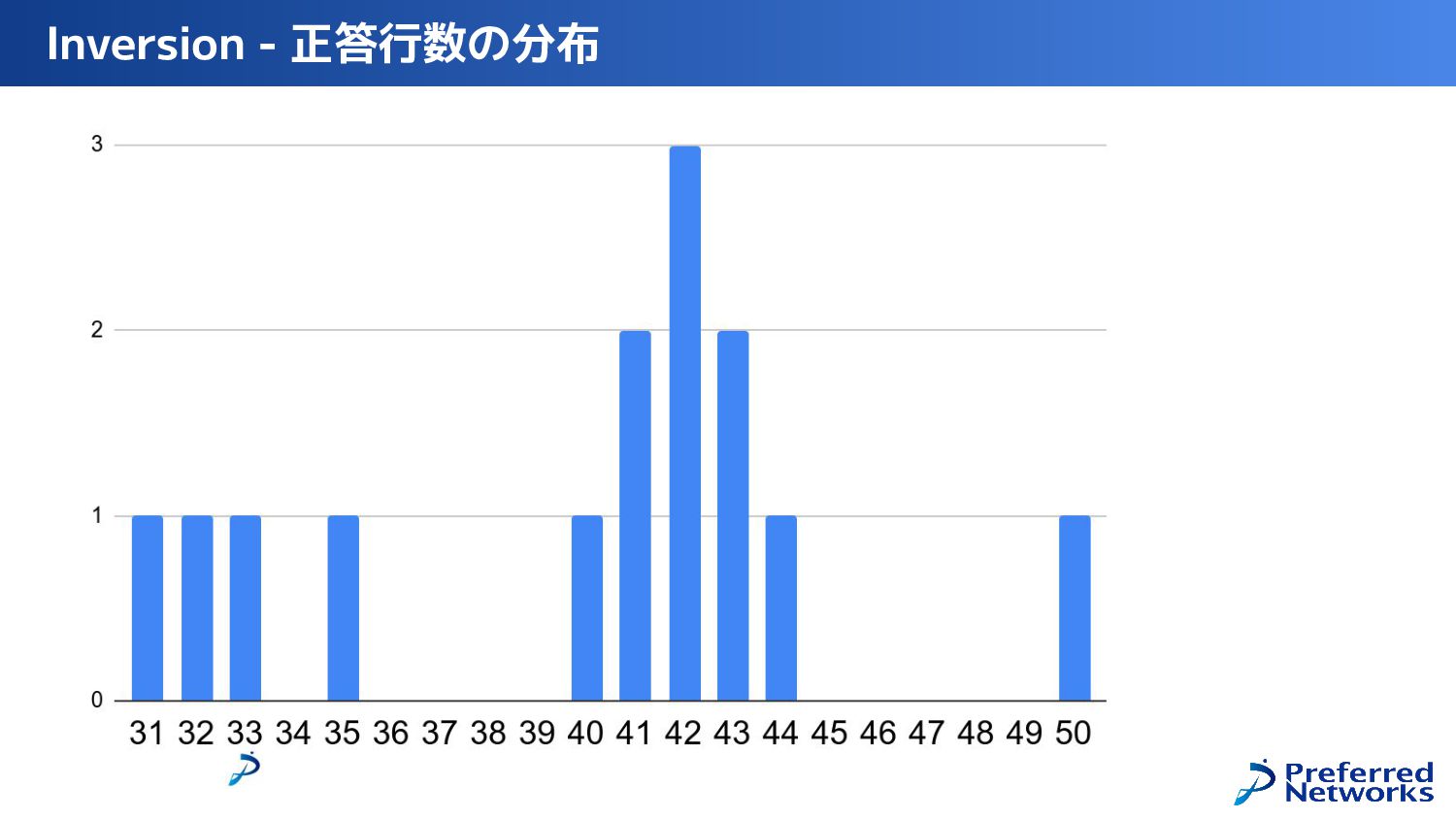{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
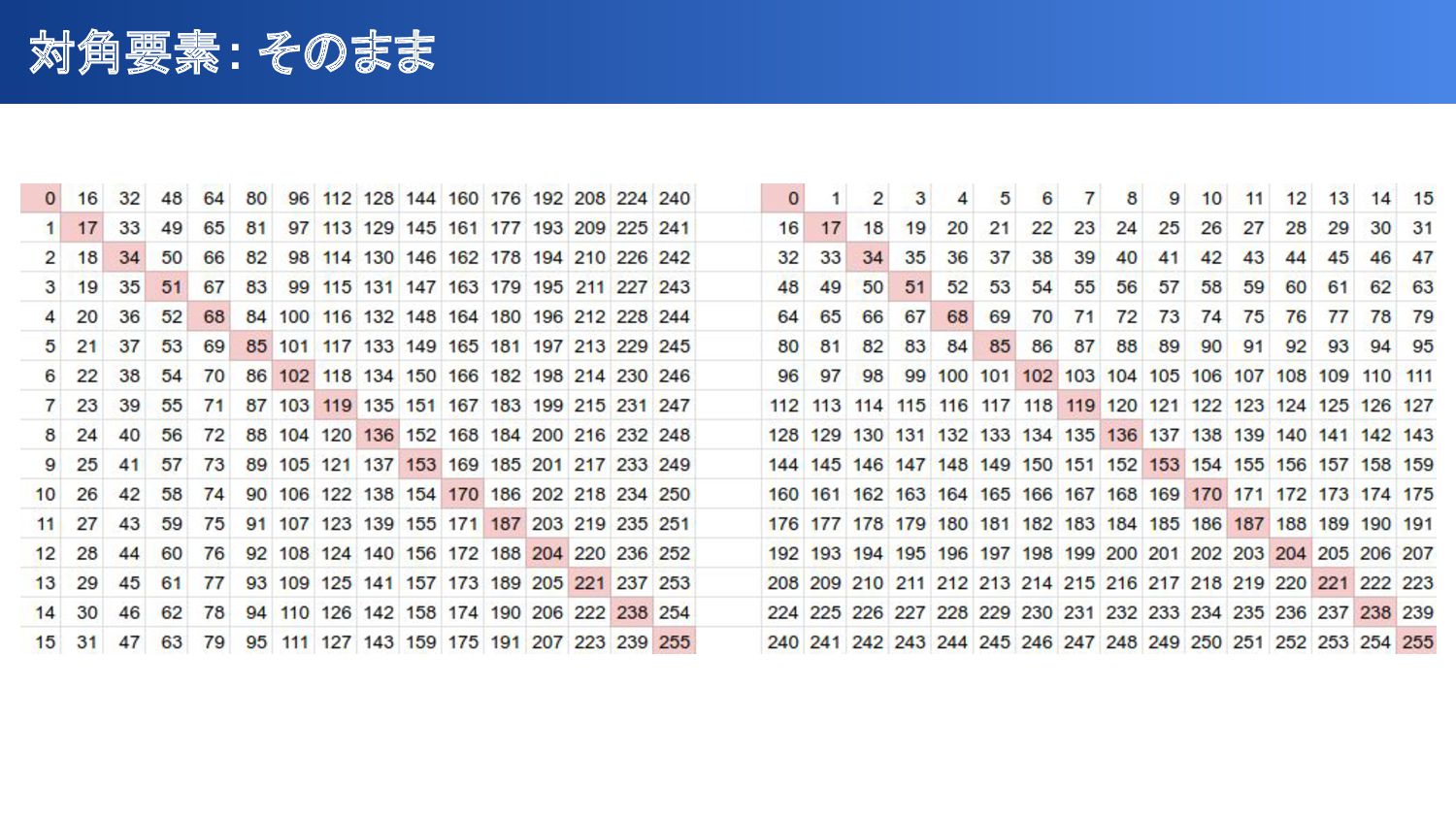{kind=link}
{kind=link}
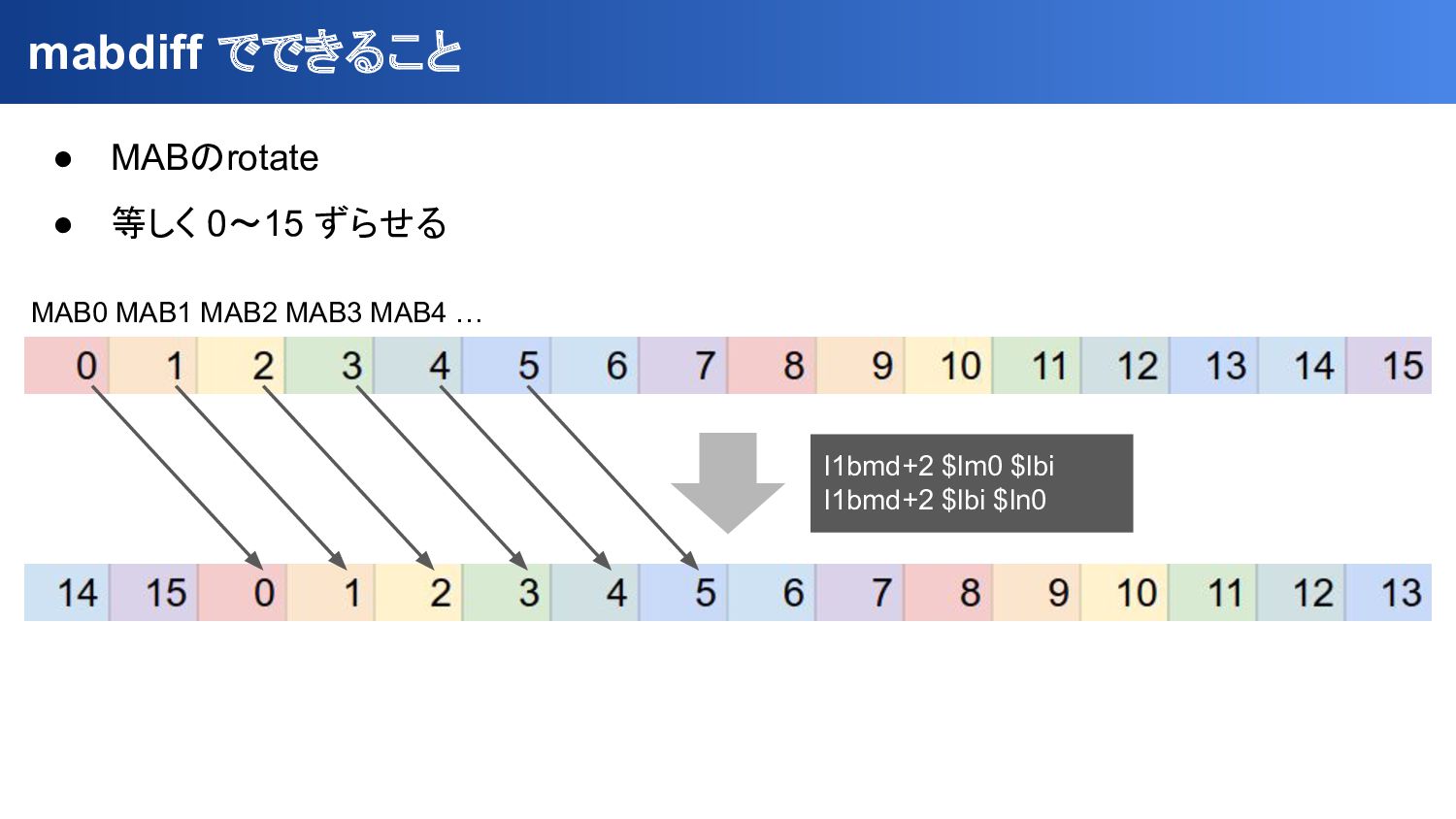{kind=link}
![非対角要素 : mabdiffで移動 LM[$mabid + 1 & 15] を l1bmd+1](https://files.speakerdeck.com/presentations/66f3d29f9f9246ac8ed4c243bb687a96/slide_85.jpg){kind=link}
![毎回Tレジスタの値を書き換えるのは大変なので、 入力を2倍して間を取る作戦 非対角要素 : mabdiffで移動 LM[$mabid + 1 & 15]](https://files.speakerdeck.com/presentations/66f3d29f9f9246ac8ed4c243bb687a96/slide_86.jpg){kind=link}
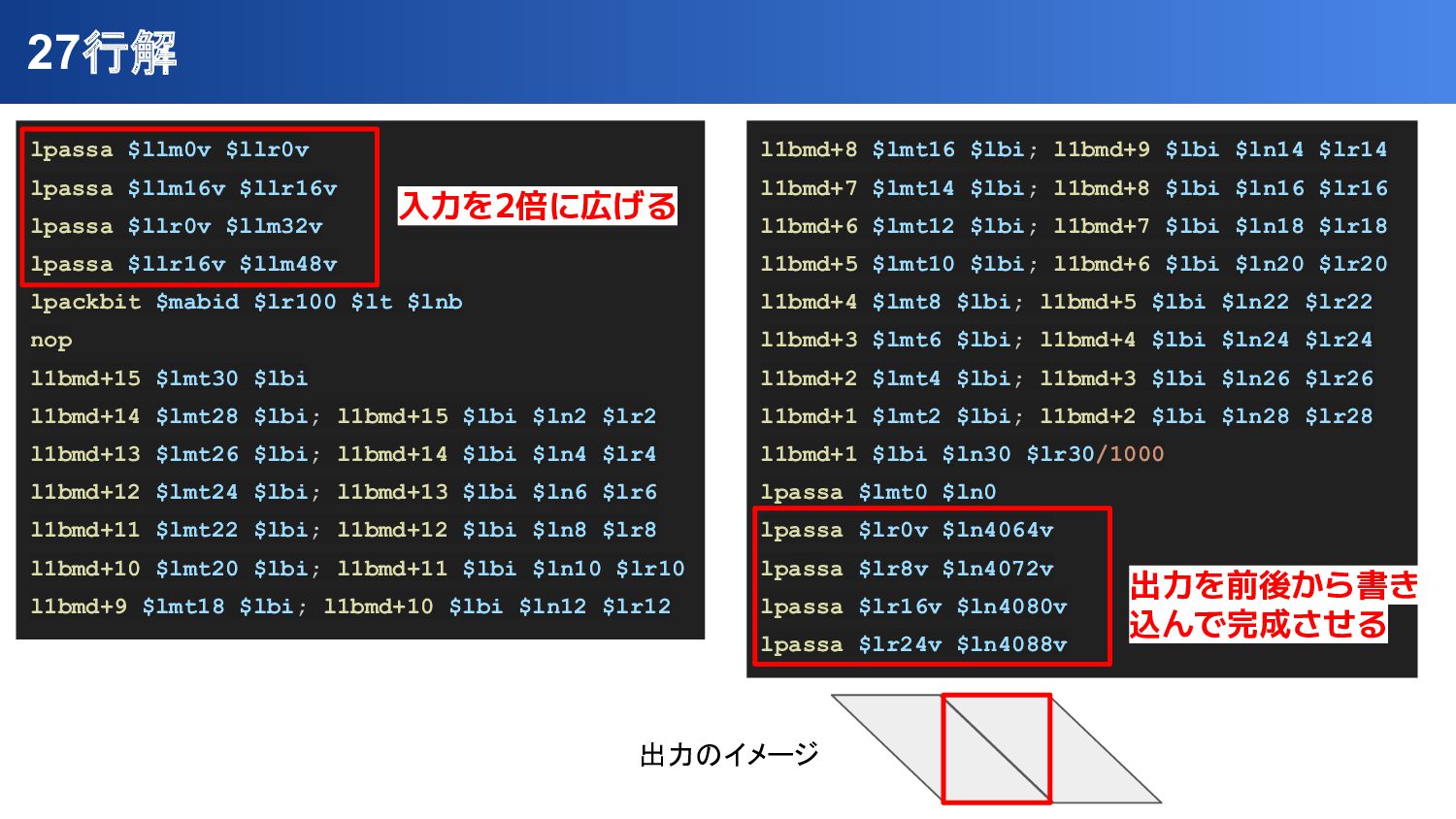{kind=link}
{kind=link}
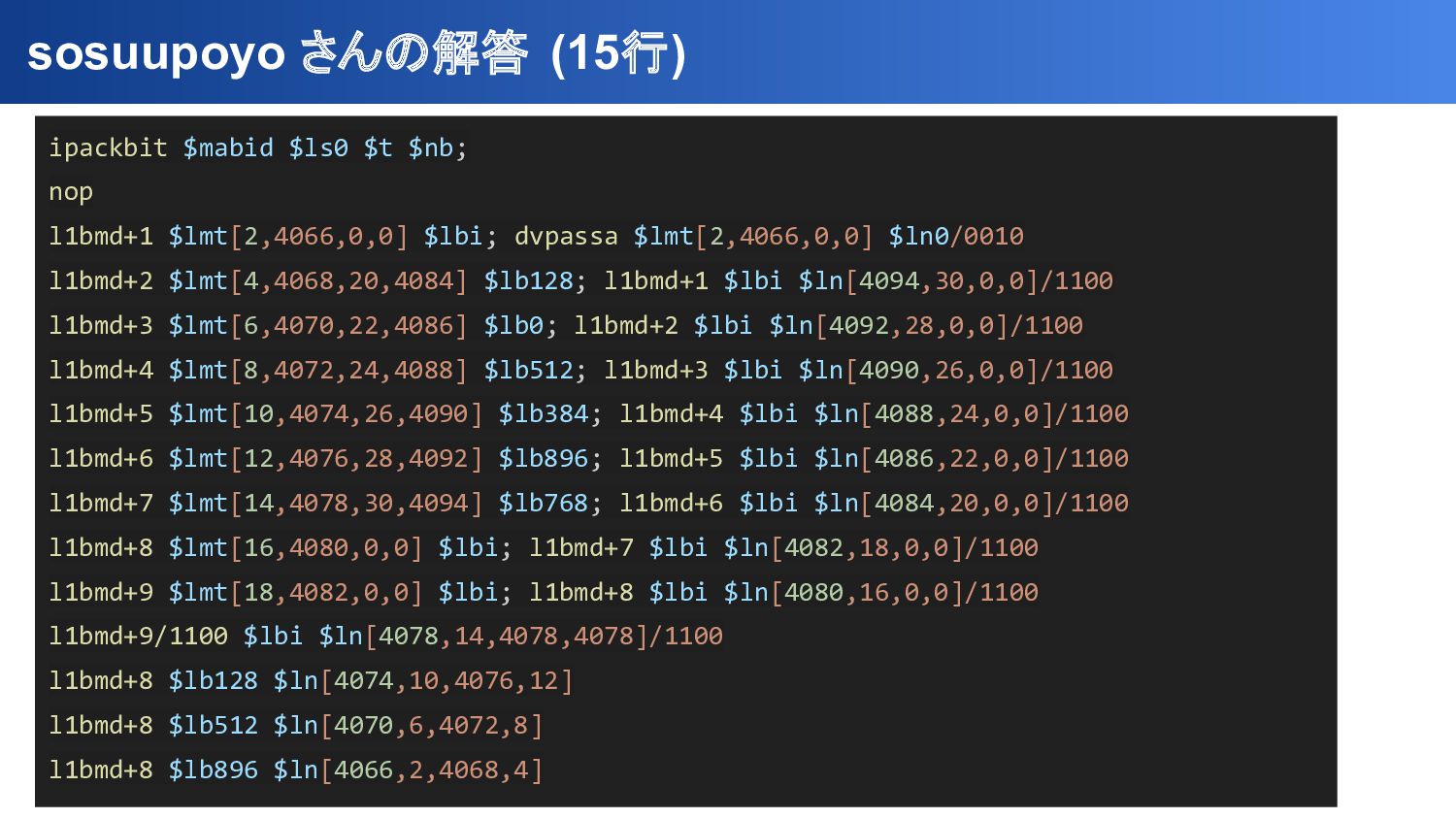{kind=link}