Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MN-Coreグラフコンパイラを自作してMNISTを学習させよう
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Preferred Networks
PRO
January 28, 2026
Technology
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MN-Coreグラフコンパイラを自作してMNISTを学習させよう
Preferred Networks
PRO
January 28, 2026
More Decks by Preferred Networks
See All by Preferred Networks
PLaMo 3.0 Primeの事後学習
pfn
PRO
0
180
PLaMo 3.0 Primeの構造化出力サポート
pfn
PRO
0
120
plamo-3-translateの開発
pfn
PRO
0
190
PLaMoを毎日の開発で使い育てていく
pfn
PRO
0
120
The Making of AI Chips
pfn
PRO
1
1k
国産生成AI PLaMoを支える事後学習と推論最適化
pfn
PRO
13
5.4k
Japanese SimpleQA: 日本語における事実に基づいた回答能力の評価ベンチマーク
pfn
PRO
1
420
Headlampと独自プラグインを活用したKubernetesダッシュボードの機能拡張
pfn
PRO
2
440
AI/MLのマルチテナント基盤を支えるコンテナ技術
pfn
PRO
6
1.9k
Other Decks in Technology
See All in Technology
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
31
26k
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
290
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
260
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
400
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
5
1.2k
AIエージェントの知識表現と推論に なぜグラフが使われるのか - 記号的AIの復権とニューラルAIとの統合
yohei1126
1
210
AI工学特論: MLOps・継続的評価
asei
11
3k
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
120
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
140
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
250
CloudWatchから始めるAWS監視
butadora
0
290
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.7k
Featured
See All Featured
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
340
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
What's in a price? How to price your products and services
michaelherold
247
13k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
My Coaching Mixtape
mlcsv
0
180
Prompt Engineering for Job Search
mfonobong
0
390
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Building an army of robots
kneath
306
46k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
KATA
mclloyd
PRO
35
15k
Transcript
MN-Coreグラフコンパイラを自作して MNIST を学習させよう! Yuji Moroto Compiler Core 0 Team 株式会社
Preferred Networks 1
発表の流れ 2 ・グラフコンパイラとは ・MNIST を学習させよう!
グラフコンパイラとは? 3
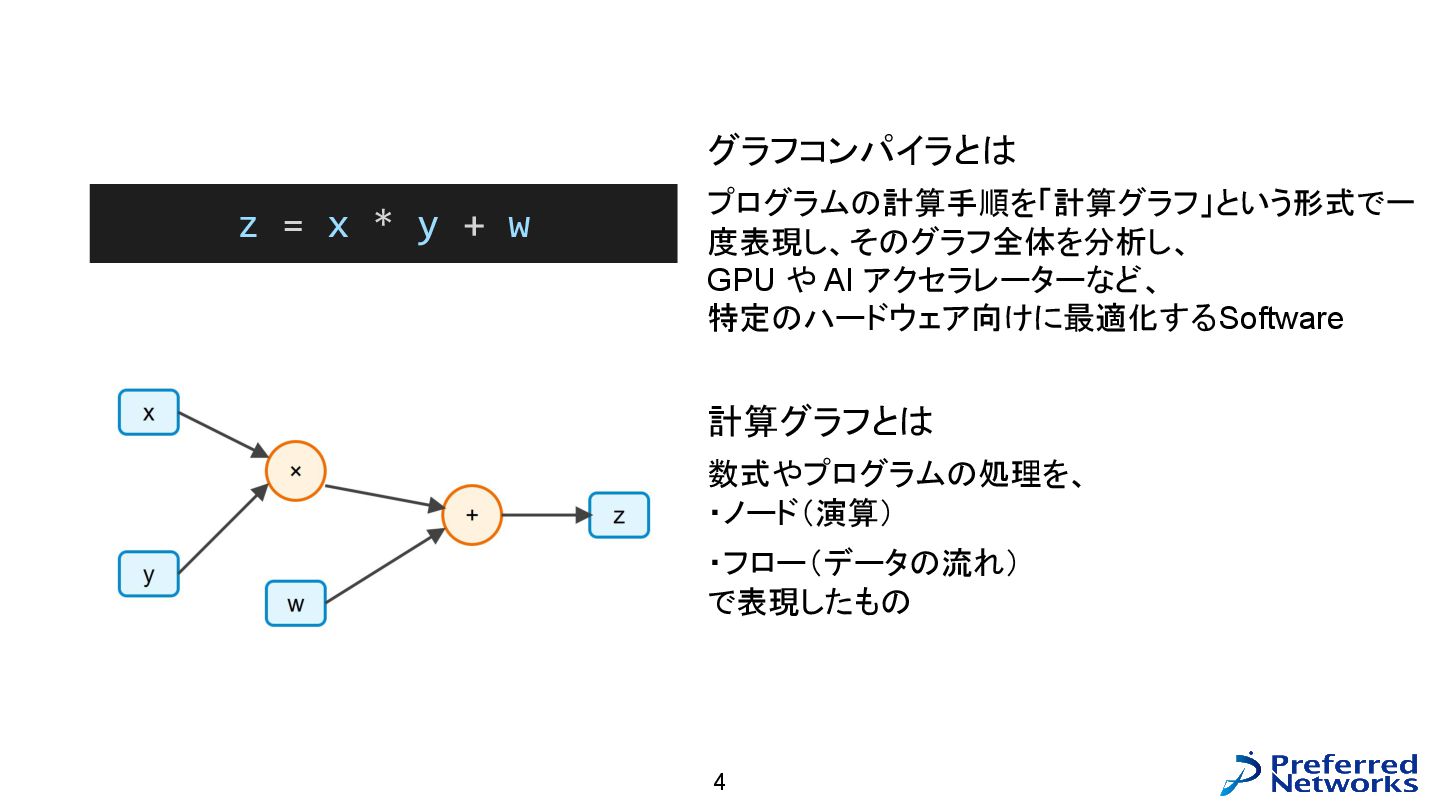
グラフコンパイラとは プログラムの計算手順を「計算グラフ」という形式で一 度表現し、そのグラフ全体を分析し、 GPU や AI アクセラレーターなど、 特定のハードウェア向けに最適化する Software 計算グラフとは
数式やプログラムの処理を、 ・ノード(演算) ・フロー(データの流れ) で表現したもの 計算を「グラフ」で捉えるコンパイラ 4 z = x * y + w
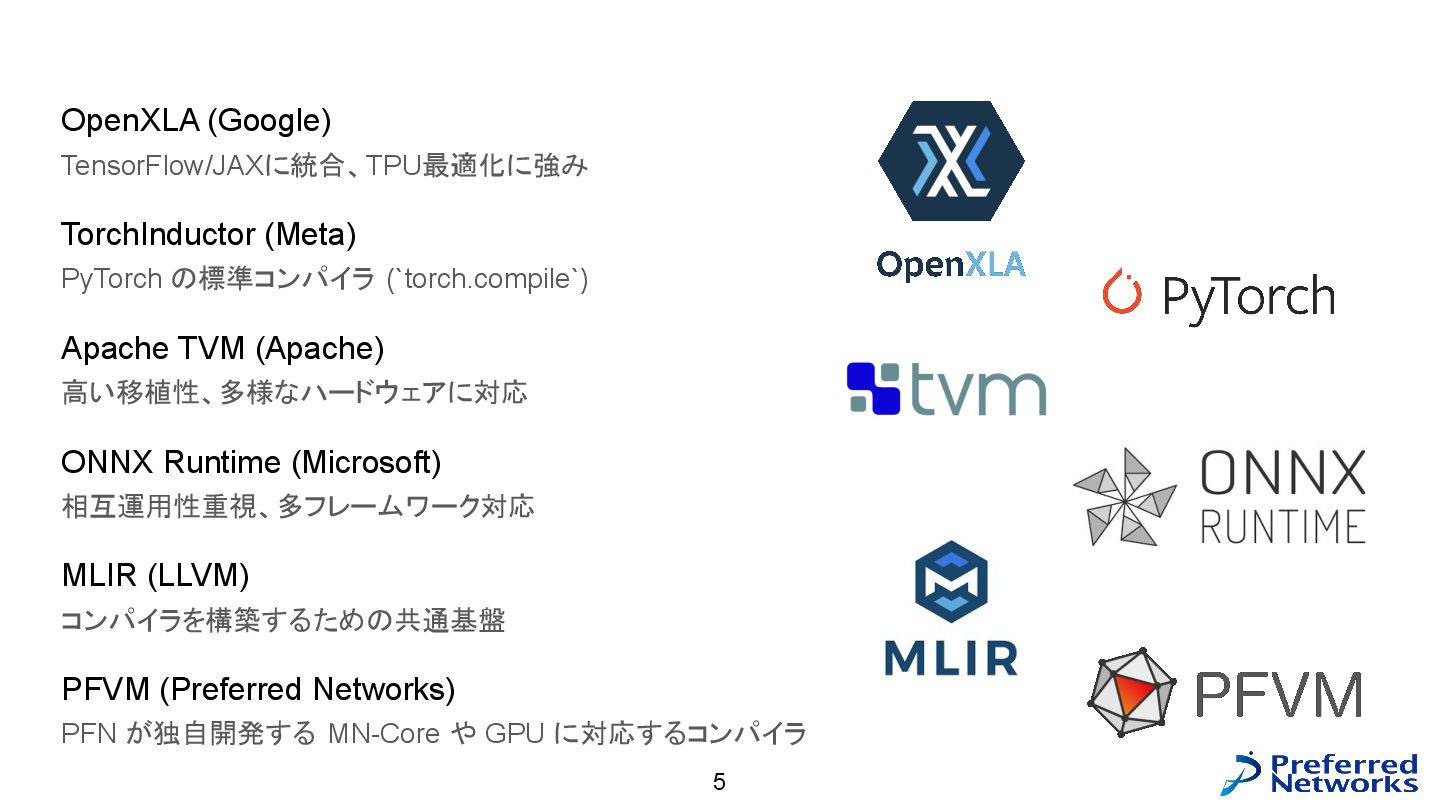
主要なグラフコンパイラ 5 OpenXLA (Google) TensorFlow/JAXに統合、TPU最適化に強み TorchInductor (Meta) PyTorch の標準コンパイラ (`torch.compile`)
Apache TVM (Apache) 高い移植性、多様なハードウェアに対応 ONNX Runtime (Microsoft) 相互運用性重視、多フレームワーク対応 MLIR (LLVM) コンパイラを構築するための共通基盤 PFVM (Preferred Networks) PFN が独自開発する MN-Core や GPU に対応するコンパイラ
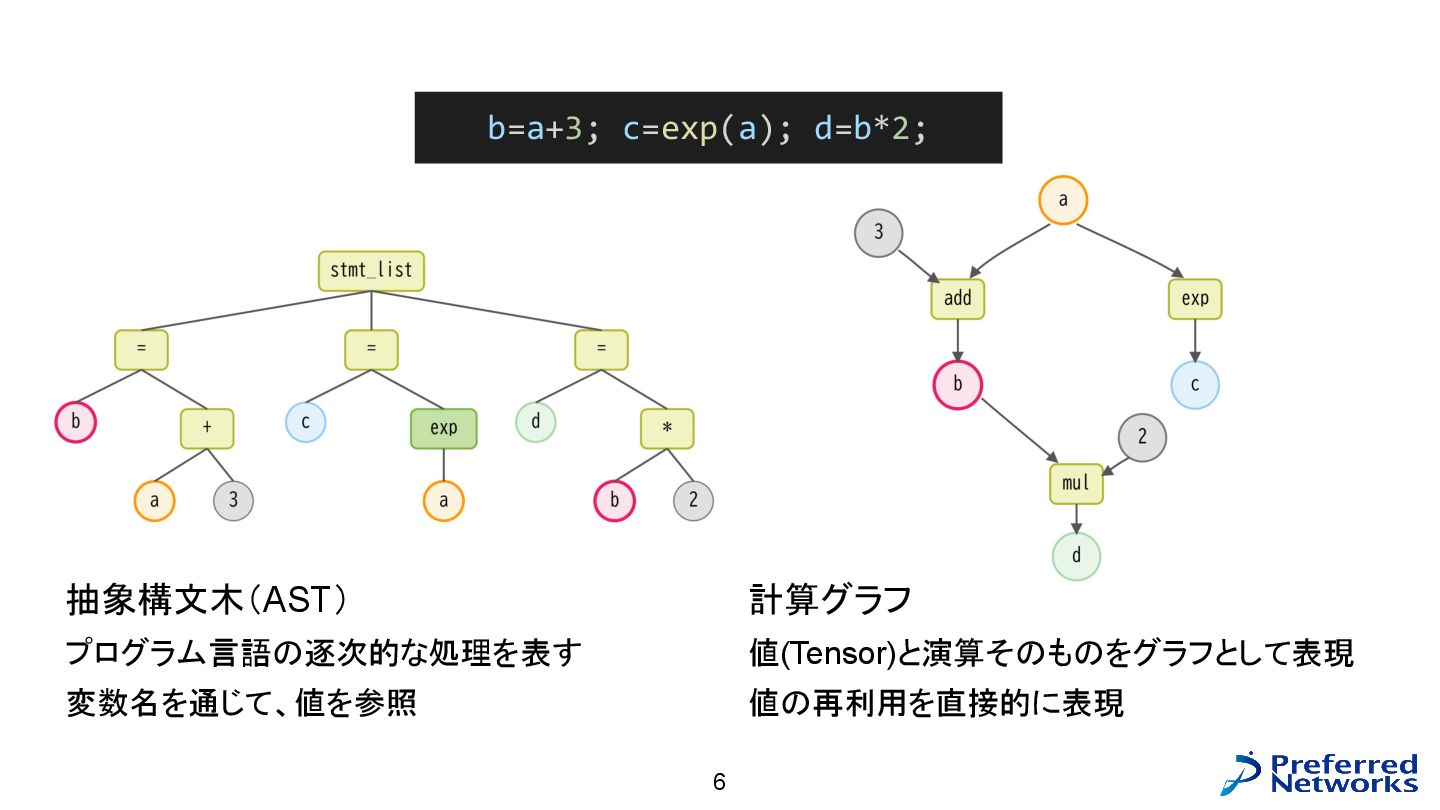
抽象構文木と計算グラフの違い 6 b=a+3; c=exp(a); d=b*2; 抽象構文木(AST) プログラム言語の逐次的な処理を表す 変数名を通じて、値を参照 計算グラフ 値(Tensor)と演算そのものをグラフとして表現
値の再利用を直接的に表現
汎用コンパイラとグラフコンパイラの違い 7 Q. GCC, LLVM, Rustc も AST を計算グラフっぽい静的単一代入(SSA)形式
に変換して最適化するけど、何が違うの? A. 扱う・得意とする「粒度」と「最適化の目的」が根本的に違う 例: Conv → ReLU という典型的な処理 汎用コンパイラの視点 何百もの低レベルな `load`, `add`, `mul` 命令の集まりとして扱うので、 「これが畳み込みと活性化関数だ」とは理解できず、命令レベルの最適化にとど まる 計算グラフの視点 Conv と ReLU という高レベルなノードとして見え、グラフコンパイラは「このパ ターンは 1 つのGPUカーネルにまとめられる」と判断し、融合(Fusion)する
なぜ、AI 開発ではグラフコンパイラを使うのか? 8 1. ハードウェアの多様化 • CPU, GPU, 各種 AI
チップなどで、それぞれに得意な計算が全く異なる • すべての HW で最高の性能を出すコードをAI開発者が書くのは困難 2. 開発者の生産性向上 • AI 開発者は HW の低レベルな詳細を気にせず、モデルの設計という本質的 な作業に集中したい 3. AI 計算の性質 • ほとんどの計算が密な線形代数演算(行列積、畳み込みなど)で構成され、非 常に規則的で、機械的に並列化しやすい • 計算グラフは静的で明示的に構築されコンパイル時に決まるものが多く、また 同じ演算が大量のデータに繰り返し適用される
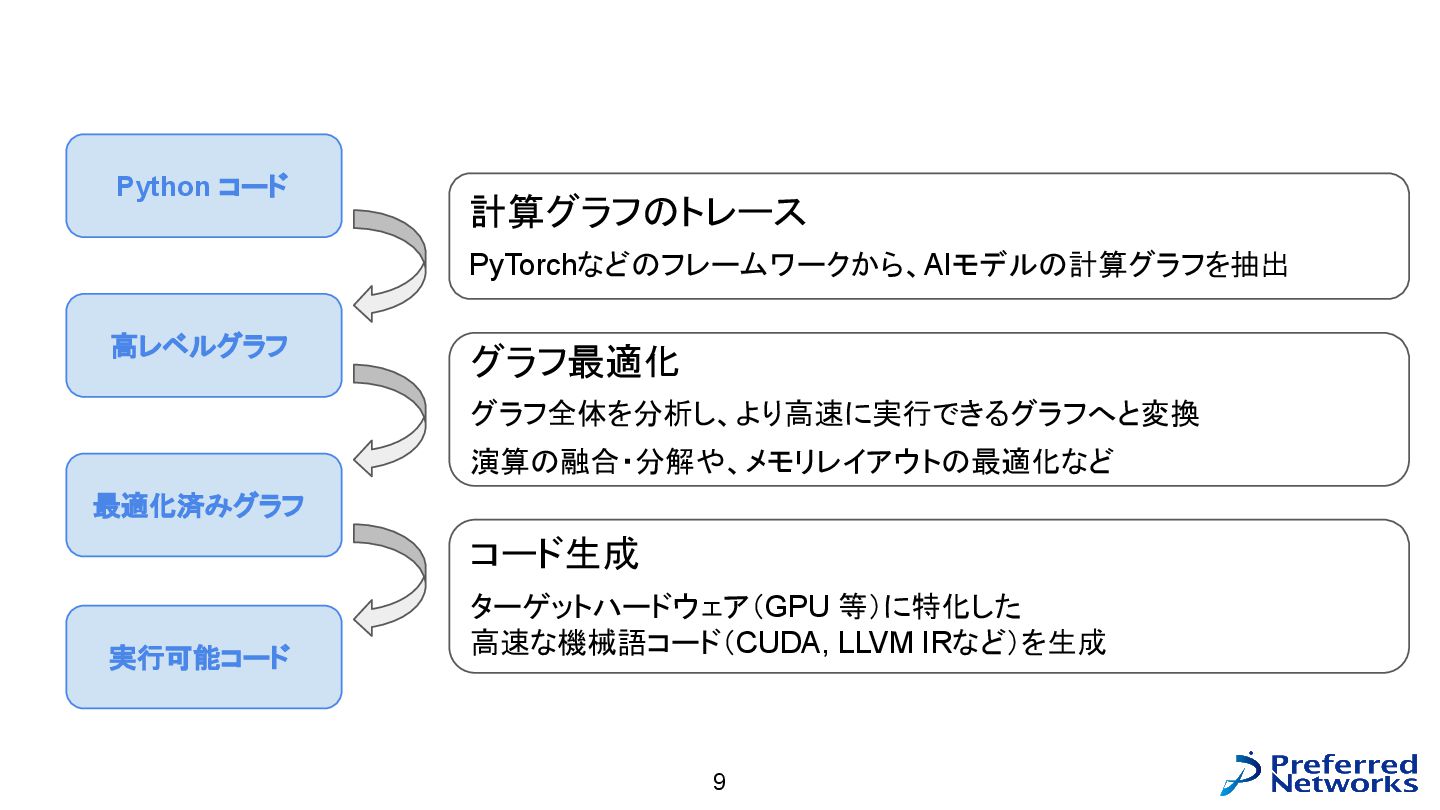
グラフコンパイラの大まかなステップ 9 Python コード 高レベルグラフ 最適化済みグラフ 実行可能コード 計算グラフのトレース PyTorchなどのフレームワークから、AIモデルの計算グラフを抽出 グラフ最適化
グラフ全体を分析し、より高速に実行できるグラフへと変換 演算の融合・分解や、メモリレイアウトの最適化など コード生成 ターゲットハードウェア(GPU 等)に特化した 高速な機械語コード(CUDA, LLVM IRなど)を生成
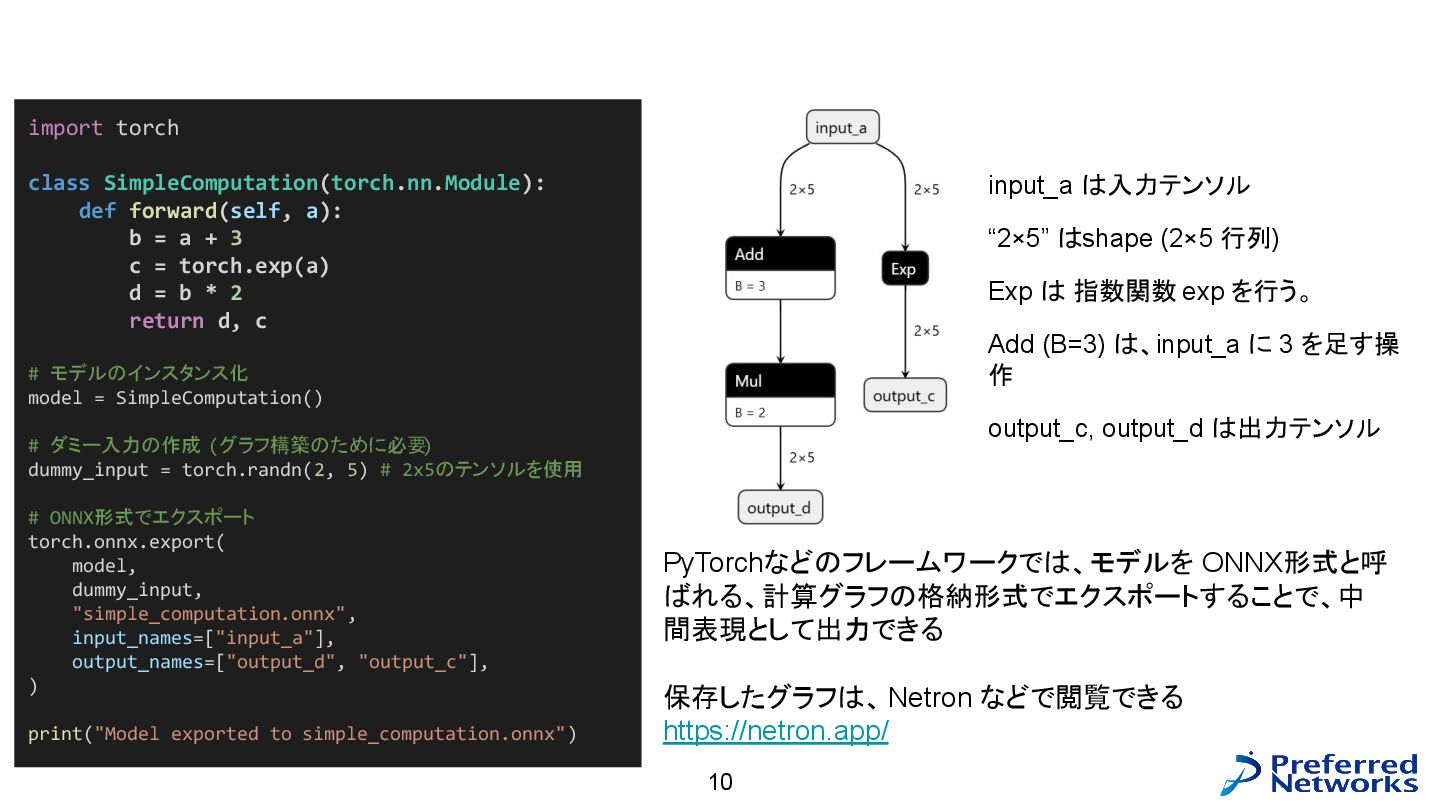
計算グラフのトレース 10 import torch class SimpleComputation(torch.nn.Module): def forward(self, a): b
= a + 3 c = torch.exp(a) d = b * 2 return d, c # モデルのインスタンス化 model = SimpleComputation() # ダミー入力の作成 (グラフ構築のために必要 ) dummy_input = torch.randn(2, 5) # 2x5のテンソルを使用 # ONNX形式でエクスポート torch.onnx.export( model, dummy_input, "simple_computation.onnx", input_names=["input_a"], output_names=["output_d", "output_c"], ) print("Model exported to simple_computation.onnx") PyTorchなどのフレームワークでは、モデルを ONNX形式と呼 ばれる、計算グラフの格納形式でエクスポートすることで、中 間表現として出力できる 保存したグラフは、Netron などで閲覧できる https://netron.app/ input_a は入力テンソル “2×5” はshape (2×5 行列) Exp は 指数関数 exp を行う。 Add (B=3) は、input_a に 3 を足す操 作 output_c, output_d は出力テンソル
補足:逆伝播グラフの自動構築 11 import torch # シンプルな計算を表現するモデル class SquareOperation(torch.nn.Module): def forward(self,
x): y = x.pow(2) return y model = SquareOperation() # ダミー入力の作成 dummy_input = torch.tensor(3.0, requires_grad=True) # 順伝播を実行 (この時点で逆伝播のための情報が記録される) output = model(dummy_input) # 損失を定義し、逆伝播を実行 (ここでは例としてoutput自体を損失と見なす) # output.backward() を呼び出すことで、dummy_input.grad に勾配が計算される output.backward() print(f"Gradient for dummy_input: {dummy_input.grad}") # 2 * 3.0 = 6.0 が期待される PyTorchなどのフレームワークでは、 モデルの順伝播を定義するだけで、 自動的に勾配計算のための逆伝播 グラフも内部で構築される 左の例は f(x) = x² を順伝播で計算 し、 微分した計算グラフ f’(x) = 2x が構 築され、 f’(3.0) = 6.0 を求めている
グラフ最適化の例 12 演算子融合 (Operator Fusion) 複数の演算を1つのカーネルにまとめて、カーネル起動コストとメモリアクセスを削減 例:Add, ReLU, Neg などの
element-wise な処理をまとめる。MatMul→ReLU をまとめる等 レイアウト変換 (Layout Transformation) テンソルのメモリ上の並び順(レイアウト)を、対象のハードウェアで効率的な形式に変換・ 計画。例:[N, C, H, W] の次元順のテンソルを、[N, H, W, C] に入れ替える (N: Batch, Channel, Height, Width) 自動混合精度 (Automatic Mixed Precision) モデルの重みや演算の精度を、アーキテクチャに合わせて、 fp32 から fp16, bf16, tf32 等に落とせる場所 を落とし、モデルサイズを削減したり、計算速度を上げる 単純にすべての計算の精度を落とすと学習が不安定になるので、重みの更新など精度に影響を与えやす い部分は高精度のまま計算し、影響の少ない部分だけを低精度にする
コード生成 13 Gemm(行列積)、Softmax、DFT(離散フーリエ変換)などの粒度の Operator をもとに、アーキテクチャに適したコードを生成 大規模なテンソル計算を、効率よく並列処理するカーネルコードを生成。専用の行列 積命令や高速メモリ(レジスタ, Shared Memory 等)を考慮し、パラメーターに合わ
せた効率的な命令を生成
MN-Coreグラフコンパイラを自作して MNIST を学習させよう! 14
目的 15 多層パーセプトロンを利用した、MNIST データセットの分類器 の学習を行えるグラフコンパイラのコードがあります 現状、PyTorch で記述されたモデルを C++ コードに出力 ・コンパイル・実行する機能があります
MN-Core 2 用のコードを出力する機能が、未完成ですがあり ます。これを完成させて、MNIST データセット分類器の学習を しよう!
多層パーセプトロン( MLP) 16 多層パーセプトロンは、最も基本的なニューラルネットワークの一つ 人間の脳の神経細胞(ニューロン)の仕組みを模倣しており、複数の層に配置された 「ニューロン」が互いに結合し、情報を伝達することで学習を行う MLPの基本構造 1. 入力層 (Input
Layer): データ(特徴量)を受け取る 2. 隠れ層 (Hidden Layer): 入力層からの情報を受け取り、複雑なパターンを学習・ 抽出する。MLPでは、この隠れ層が複数存在することが特徴 3. 出力層 (Output Layer): 最終的な予測や分類結果を出力 各ニューロンは、前の層からの入力に重みを掛け合わせ、バイアスを加算し、活性化関数を 通して次の層へと出力を伝える
具体的な計算(順伝播) 17 class SimpleNN(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784,
16) self.fc2 = nn.Linear(16, 10) self.relu = nn.ReLU() def forward(self, x): x = x.view(x.size(0), -1) x = self.relu(self.fc1(x)) return self.fc2(x) nn.Linear は数式で表すと y = Wx+b という行列積和計算 x:入力(input), W: 重み(fc_weight), b: バイアス(fc1_bias), y: 出力 入力層 28x28 = 784 ピクセルの画素値 隠れ層 今回は 1 層で、サイズは16 出力層 0~9 の 10 択 効率的に学習するため、複数画像を同時に処理して計算する今回 はバッチサイズ: 256
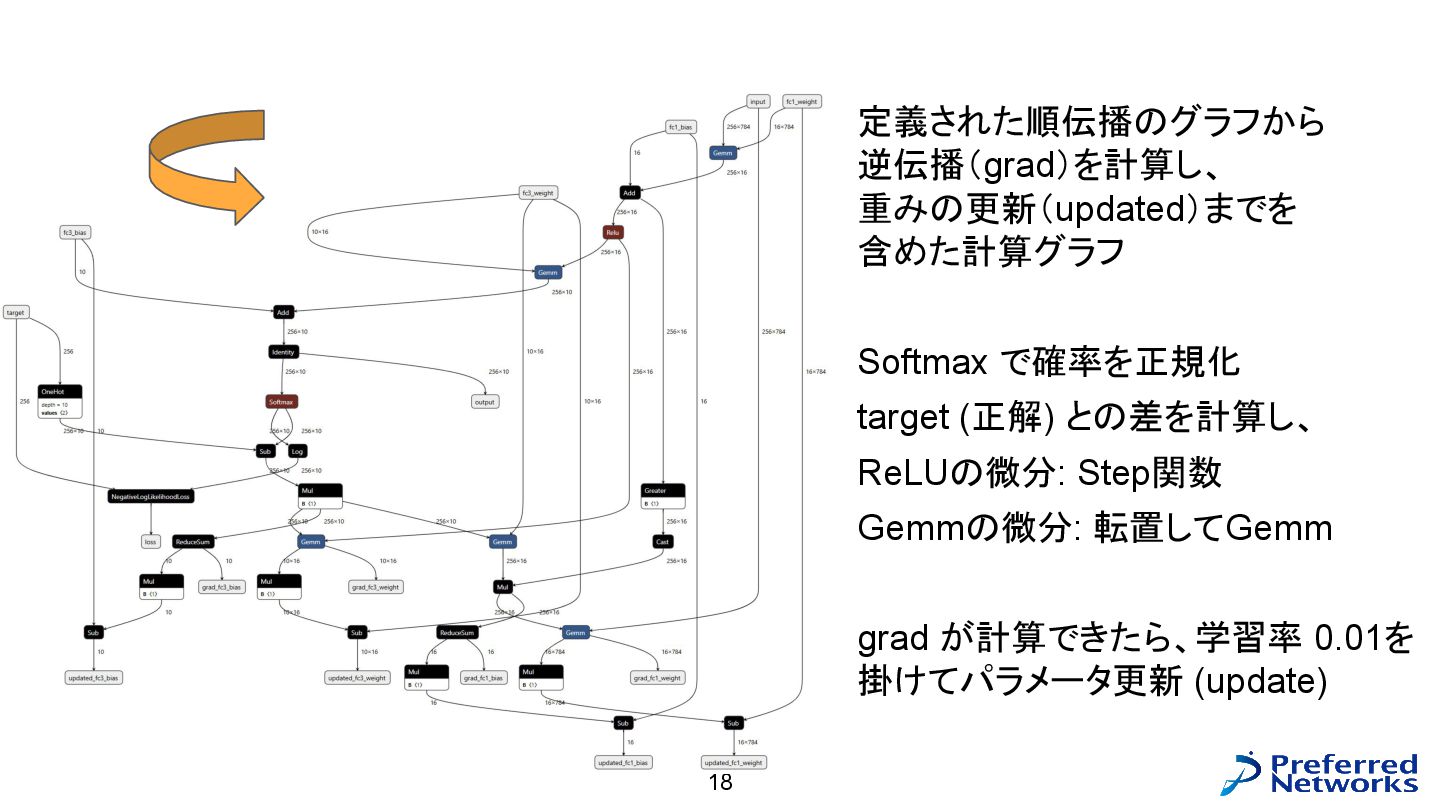
具体的な計算(逆伝播) 18 定義された順伝播のグラフから 逆伝播(grad)を計算し、 重みの更新(updated)までを 含めた計算グラフ Softmax で確率を正規化 target (正解)
との差を計算し、 ReLUの微分: Step関数 Gemmの微分: 転置してGemm grad が計算できたら、学習率 0.01を 掛けてパラメータ更新 (update)
演習用グラフコンパイラの説明 : C++ コード生成編、 Step1 export 19 class SimpleNN(nn.Module): def
__init__(self) -> None: super().__init__() self.fc1 = nn.Linear(784, 16) # 入力 784 pixel → 隠れ層 16 self.fc2 = nn.Linear(16, 10) # 隠れ層 16 → 出力 10 クラス self.relu = nn.ReLU() def forward(self, x: torch.Tensor) -> torch.Tensor: x = x.view(x.size(0), -1) x = self.relu(self.fc1(x)) return self.fc2(x) def train_step(inputs: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]: x = inputs["x"] t = inputs["t"] optimizer.zero_grad() output = model(x) loss = criterion(output, t) loss.backward() optimizer.step() return {"loss": loss, "output": output} $ ./haribote_graph_compiler.py export === ONNXエクスポート === 自動微分ベースのグラフエクスポートを使用します。 ONNXモデルを /tmp/train_step/model.onnx に保存しました エクスポート完了 : /tmp/train_step - model.onnx - input_*.npy (6 files) - output_*.npy (10 files) コード生成するには以下を実行 : ./haribote_graph_compiler.py compile /tmp/train_step/model.onnx 以下のコマンドで、右のコードから ONNX を生成
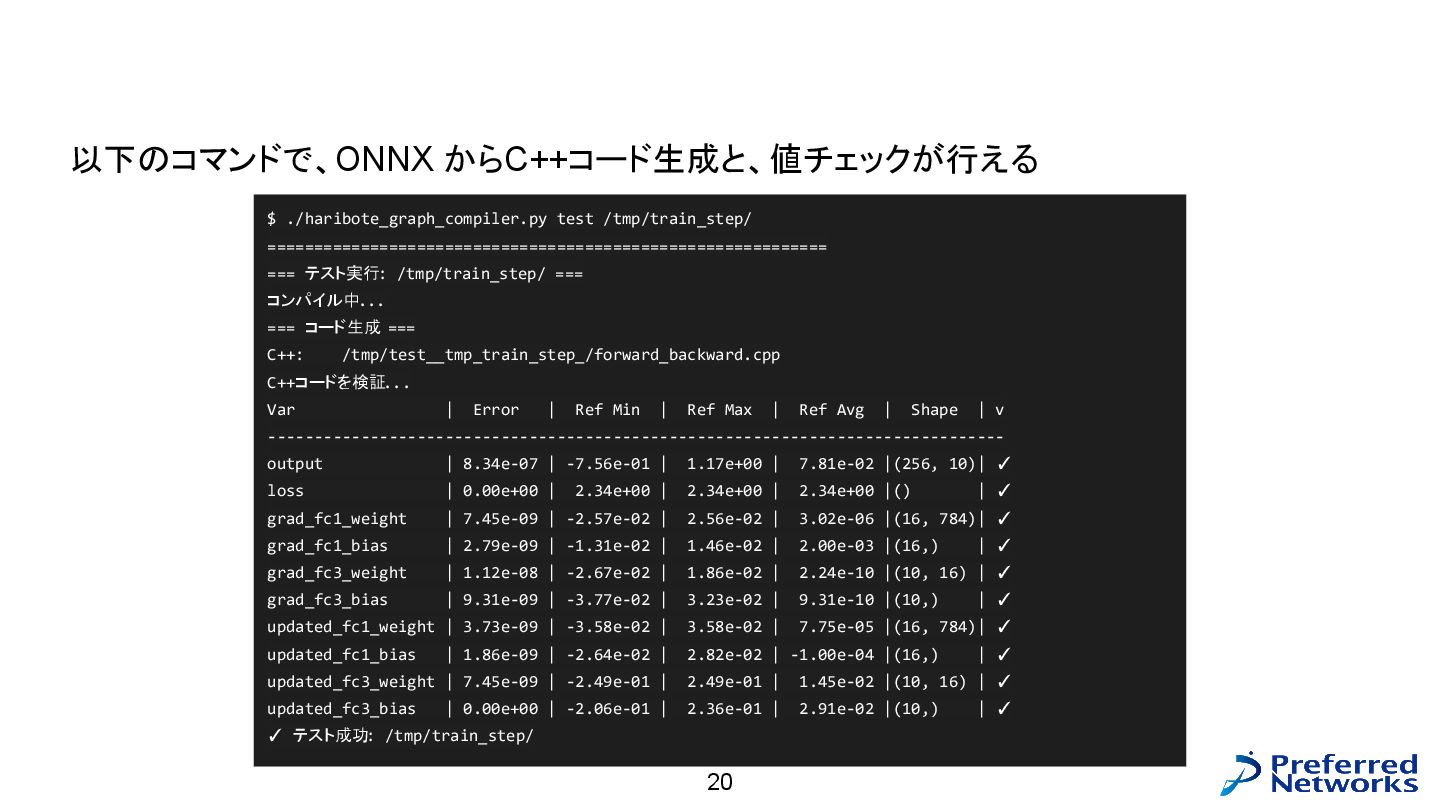
演習用グラフコンパイラの説明 : C++ コード生成編、 Step2 test 20 $ ./haribote_graph_compiler.py test
/tmp/train_step/ ============================================================ === テスト実行: /tmp/train_step/ === コンパイル中... === コード生成 === C++: /tmp/test__tmp_train_step_/forward_backward.cpp C++コードを検証... Var | Error | Ref Min | Ref Max | Ref Avg | Shape | v ------------------------------------------------------------------------------- output | 8.34e-07 | -7.56e-01 | 1.17e+00 | 7.81e-02 |(256, 10)| ✓ loss | 0.00e+00 | 2.34e+00 | 2.34e+00 | 2.34e+00 |() | ✓ grad_fc1_weight | 7.45e-09 | -2.57e-02 | 2.56e-02 | 3.02e-06 |(16, 784)| ✓ grad_fc1_bias | 2.79e-09 | -1.31e-02 | 1.46e-02 | 2.00e-03 |(16,) | ✓ grad_fc3_weight | 1.12e-08 | -2.67e-02 | 1.86e-02 | 2.24e-10 |(10, 16) | ✓ grad_fc3_bias | 9.31e-09 | -3.77e-02 | 3.23e-02 | 9.31e-10 |(10,) | ✓ updated_fc1_weight | 3.73e-09 | -3.58e-02 | 3.58e-02 | 7.75e-05 |(16, 784)| ✓ updated_fc1_bias | 1.86e-09 | -2.64e-02 | 2.82e-02 | -1.00e-04 |(16,) | ✓ updated_fc3_weight | 7.45e-09 | -2.49e-01 | 2.49e-01 | 1.45e-02 |(10, 16) | ✓ updated_fc3_bias | 0.00e+00 | -2.06e-01 | 2.36e-01 | 2.91e-02 |(10,) | ✓ ✓ テスト成功: /tmp/train_step/ 以下のコマンドで、ONNX からC++コード生成と、値チェックが行える
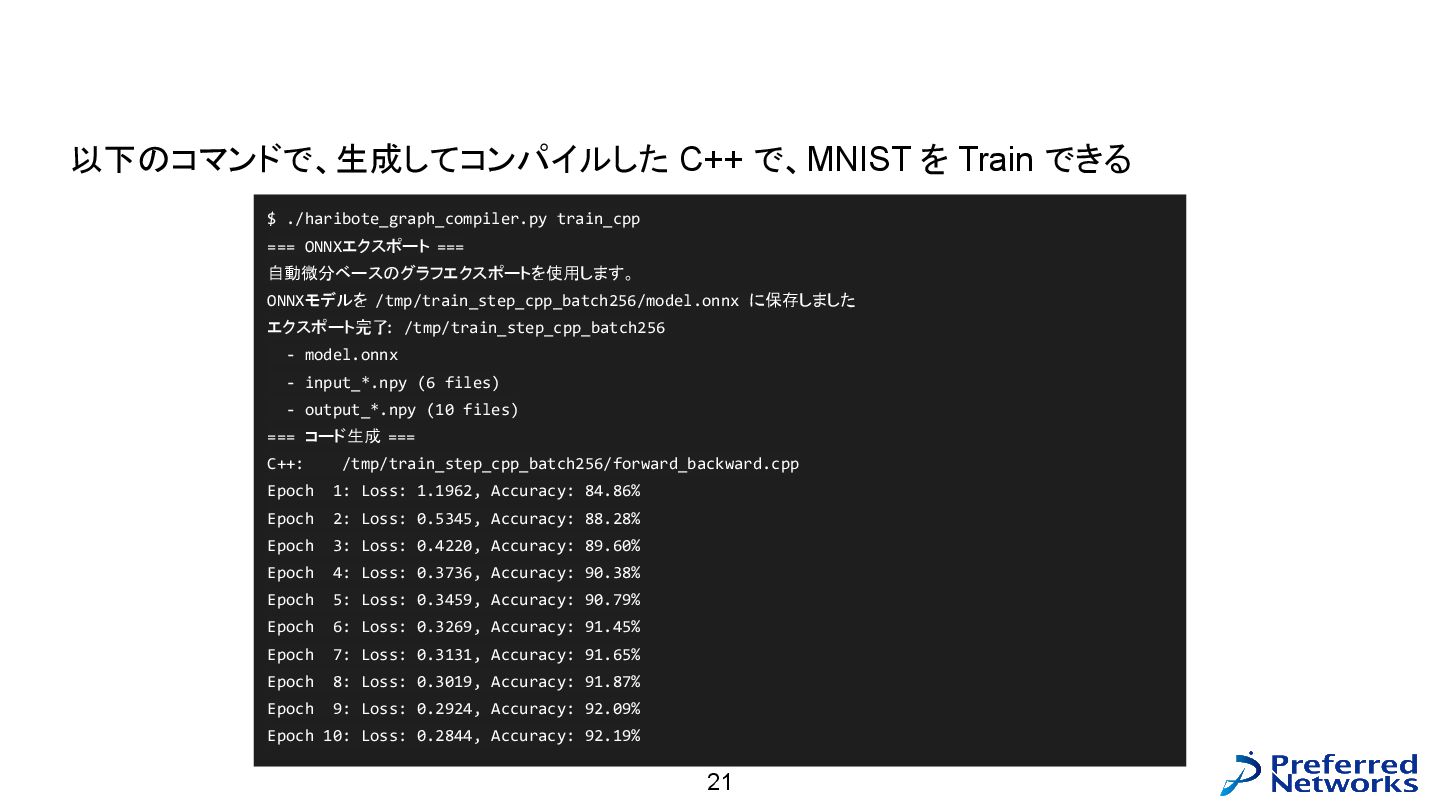
演習用グラフコンパイラの説明 : C++ コード生成編、 Step3 train 21 $ ./haribote_graph_compiler.py train_cpp
=== ONNXエクスポート === 自動微分ベースのグラフエクスポートを使用します。 ONNXモデルを /tmp/train_step_cpp_batch256/model.onnx に保存しました エクスポート完了 : /tmp/train_step_cpp_batch256 - model.onnx - input_*.npy (6 files) - output_*.npy (10 files) === コード生成 === C++: /tmp/train_step_cpp_batch256/forward_backward.cpp Epoch 1: Loss: 1.1962, Accuracy: 84.86% Epoch 2: Loss: 0.5345, Accuracy: 88.28% Epoch 3: Loss: 0.4220, Accuracy: 89.60% Epoch 4: Loss: 0.3736, Accuracy: 90.38% Epoch 5: Loss: 0.3459, Accuracy: 90.79% Epoch 6: Loss: 0.3269, Accuracy: 91.45% Epoch 7: Loss: 0.3131, Accuracy: 91.65% Epoch 8: Loss: 0.3019, Accuracy: 91.87% Epoch 9: Loss: 0.2924, Accuracy: 92.09% Epoch 10: Loss: 0.2844, Accuracy: 92.19% 以下のコマンドで、生成してコンパイルした C++ で、MNIST を Train できる
演習用グラフコンパイラの説明 : C++ コード生成編、生成物 22 // 入力とパラメータを読み込む const Matrix input
= load<256, 784>(input_ptr); const std::array target = load<256, int>(target_ptr); const Matrix fc1_weight = load<16, 784>(fc1_weight_ptr); const Vector fc1_bias = load<16>(fc1_bias_ptr); const Matrix fc3_weight = load<10, 16>(fc3_weight_ptr); const Vector fc3_bias = load<10>(fc3_bias_ptr); // 計算 const Matrix fc1_pre_matmul = matmul<256, 784, 16>(input, trans<16, 784>(fc1_weight)); const Matrix fc1_pre = add_colvec<256, 16>(fc1_pre_matmul, fc1_bias); const Matrix fc1 = relu<256, 16>(fc1_pre); const Matrix fc3_pre_matmul = matmul<256, 16, 10>(fc1, trans<10, 16>(fc3_weight)); const Matrix fc3_pre = add_colvec<256, 10>(fc3_pre_matmul, fc3_bias); const Matrix probs = softmax<256, 10>(fc3_pre); 以下のような C++ コードが生成される(load, matmul などの定義はテンプレートに)
演習用グラフコンパイラの説明 : ユニットテスト作成 23 $ make build_mn_unittest === /tmp/train_step/ のunit
test生成を開始 === 中間結果を取得するために完全なグラフを実行 ... テストケースを ./unit_tests/ に生成... 生成中: Gemm_256x784_16x784_256x16_transB 生成中: Add_256x16_16_256x16 生成中: Relu_256x16_256x16 生成中: Gemm_256x16_10x16_256x10_transB 生成中: Add_256x10_10_256x10 生成中: Identity_256x10_256x10 生成中: Softmax_256x10_256x10 生成中: Log_256x10_256x10 生成中: NegativeLogLikelihoodLoss_256x10_256_1 生成中: OneHot_256_1_2_256x10 生成中: Sub_256x10_256x10_256x10 生成中: Mul_256x10_1_256x10 生成中: Gemm_256x10_256x16_10x16_transA 生成中: ReduceSum_256x10_10 生成中: Gemm_256x10_10x16_256x16 (…省略) 生成中: Mul_16x784_1_16x784 生成中: Sub_16x784_16x784_16x784 生成中: Mul_16_1_16 生成中: Sub_16_16_16 ✓ 28 個のテストケースを生成しました : ./unit_tests/ 左のコマンドでユニットテストが作れる ONNX とダミー入力から各 Node 毎に ONNX とテス トを分離した小ケースを作る
演習用グラフコンパイラの説明 : ユニットテスト実行 24 $ ./haribote_graph_compiler.py test unit_tests/Add_256x10_10_256x10/ ============================================================ ===
テスト実行: unit_tests/Add_256x10_10_256x10/ === === コード生成 === C++: /tmp/test_unit_tests_Add_256x10_10_256x10_/forward_backward.cpp C++コードを検証... === C++ check検証 === Var | Error | Ref Min | Ref Max | Ref Avg | Shape | v -------------------------------------------------------------------- fc3_pre | 0.00e+00 | -7.56e-01 | 1.17e+00 | 7.81e-02 |(256, 10)| ✓ ✓ テスト成功: unit_tests/Add_256x10_10_256x10/ ============================================================ === テストサマリー === ✓ PASS: unit_tests/Add_256x10_10_256x10/ 合計: 1/1 テスト成功 ユニットテストのディレクトリを指定した test で、1 node だけのテストができる ディレクトリは複数指定して一斉にテストも可能 一部の Operator の実装しかできていなくてもテ ストができるので、 MN-Core 用の Operator 実装では、 このユニットテストを進めていくことになる
MN-Core 用に向けた方針(グラフコンパイラ入門者向け) 25 • 1 演算ごとに DRAM から LM に値を転送し演算し、また
DRAM に値を戻します ◦ 本当は値をどこに保存するかプランも作れると性能が出る • 使用する MN-Core DRAM アドレスのプランロジックは実装済みです ◦ free しません。 • 簡単のため、入力サイズを 784 (=28²) ではなく、1024 (=32²) にします 出力サイズも10(10クラス)ではなく、16 にパディングします(実装済み) • 今回は、それぞれの Operator の実装をしてもらえば、最低限動くようになっています ◦ それぞれの Op は、https://seccamp-2025.mncore-challenge.preferred.tech/ に実装がある状態なので、Op の入出力の location (DRAM or LM0 or LM1), address, length を確認して、↑のコードから入出力を入れ替えられるようにする ◦ 各 Op にある C++ を出力するコードも参考にすると良いでしょう ◦ 想定外の入力は無視するか、raise NotImplementedError で大丈夫です
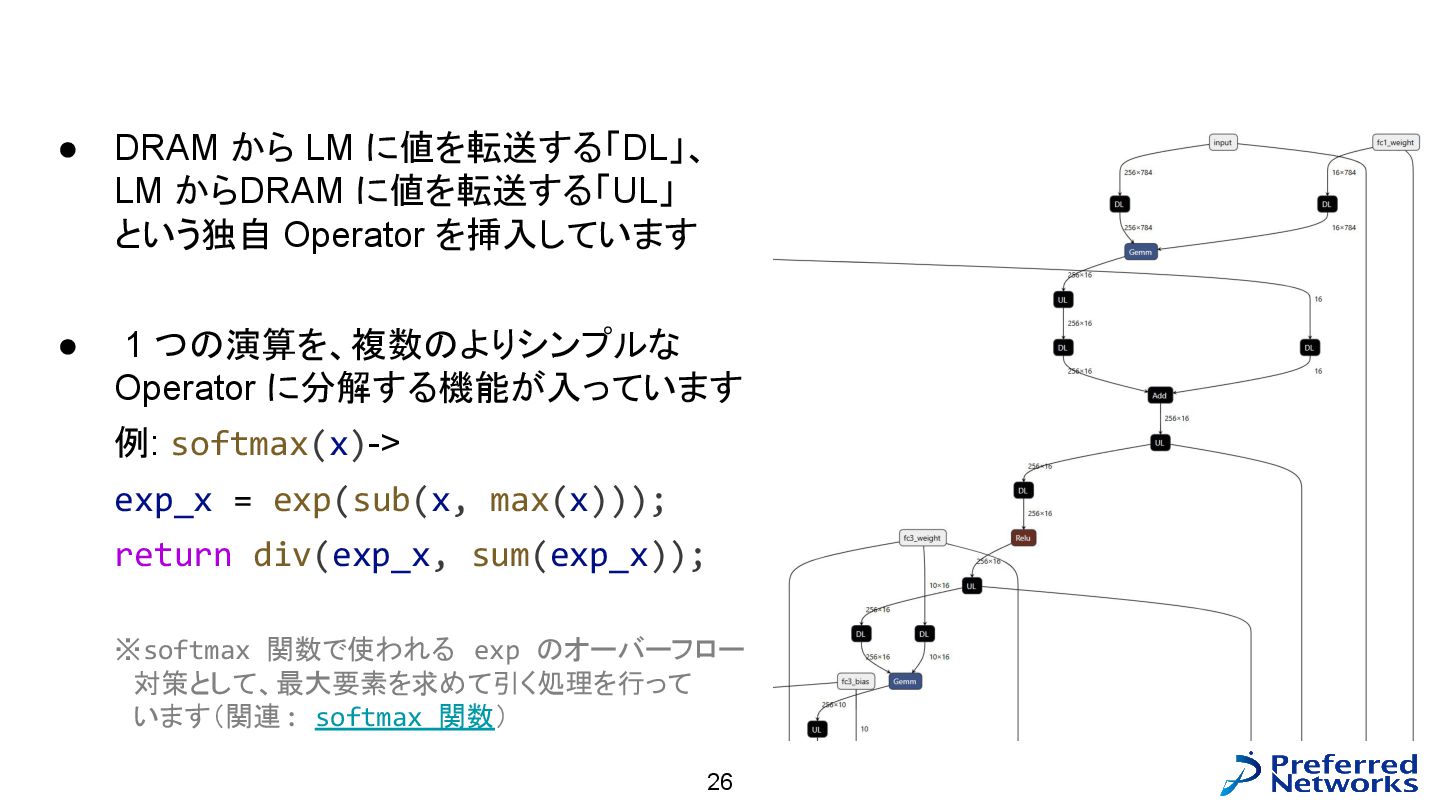
MN-Core 向けに行っているグラフ処理 26 • DRAM から LM に値を転送する「DL」、 LM からDRAM
に値を転送する「UL」 という独自 Operator を挿入しています • 1 つの演算を、複数のよりシンプルな Operator に分解する機能が入っています 例: softmax(x)-> exp_x = exp(sub(x, max(x))); return div(exp_x, sum(exp_x)); ※softmax 関数で使われる exp のオーバーフロー 対策として、最大要素を求めて引く処理を行って います(関連: softmax 関数)
Making the real world computable 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}