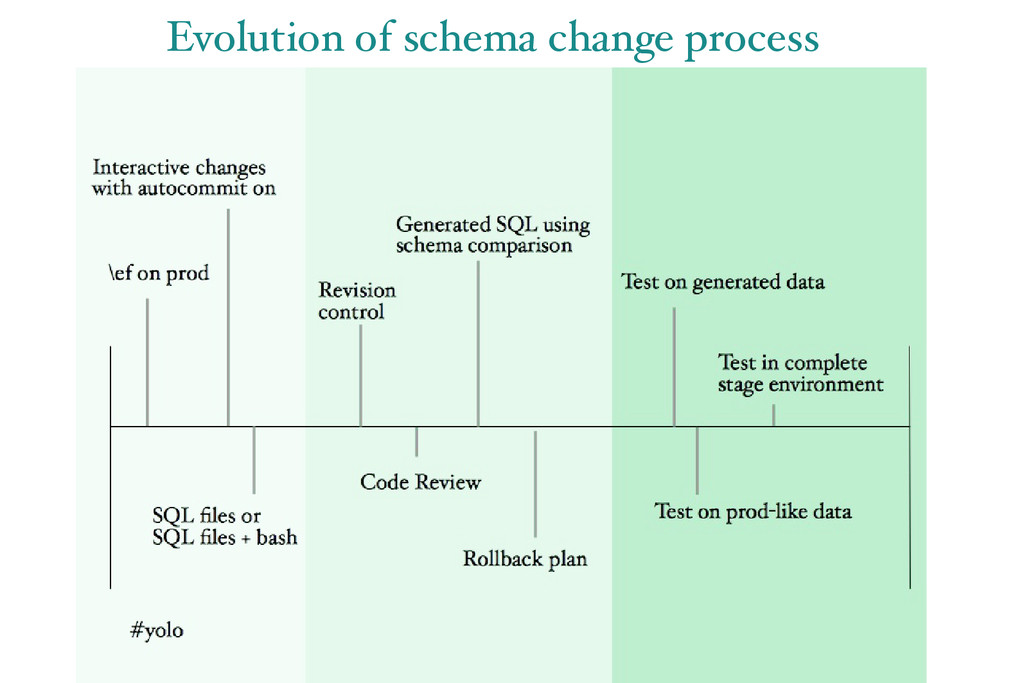
2012 bugs) • Change snuck into partitioning UDF Jan-April 2013 • No useful audit trail • Some partitions affected, not others • Error dated back to 2010 • Wake up call to examine process!
• Tested in stage • Experimentation revealed which partitions could be modified without deadlocking • Rolled out change with a regular release during normal business hours
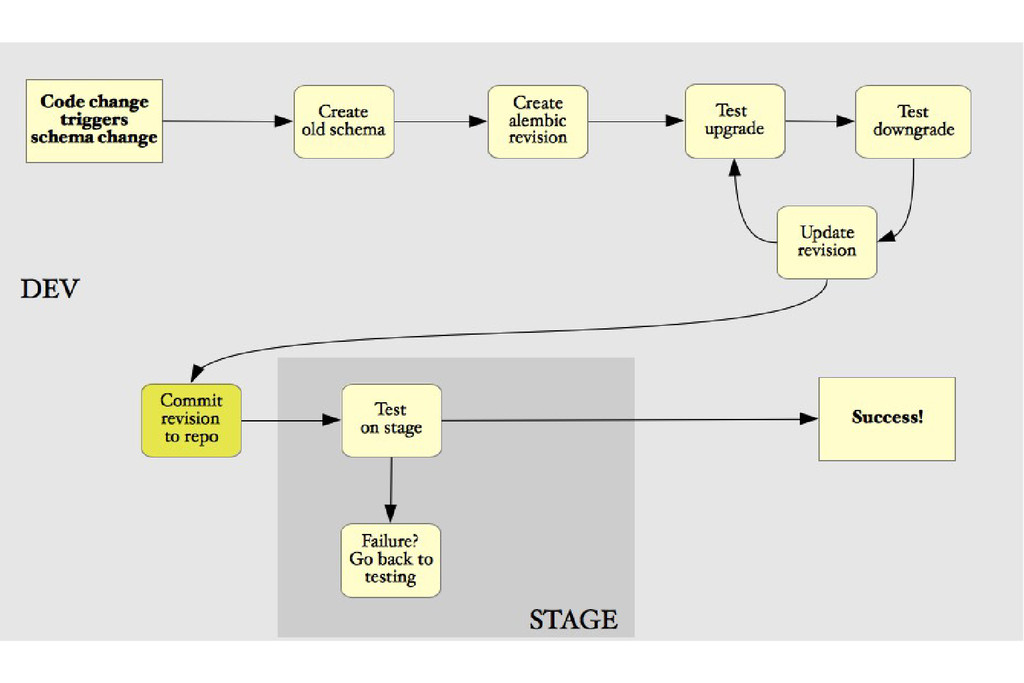
files 2. Run: alembic revision -–auto-generate 3. Edit revision file 4.Commit changes 5. Run migration on stage after auto-deploy of a release 5.Have jenkins run downgrade/upgrade as part of test suite.
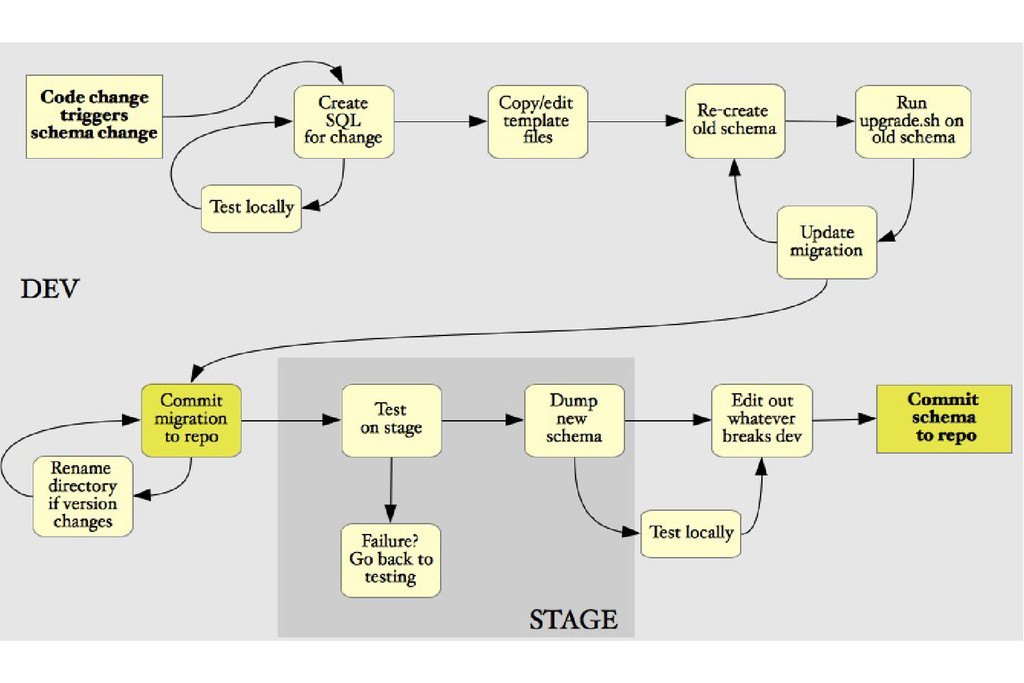
• No more post-deploy schema checkins • Enabling a tested, automated stage deployment • Separated schema definition from version-specific configuration
• Apply changes in the correct order • Apply a change only once • Use raw SQL where needed • Provide a single interface for change • Rollback gracefully
schemas • Develops compassion for how horrible ORMs can be • Gives you developer-friendly vocabulary for discussing why ORM- generated code is often terrible
tool to create a new schema from scratch. 2. Write a simple tool to generate fake data. 3. Write tests for these tools. 4.When anything fails, add a test.
tool to create a new schema from scratch. 2. Write a simple tool to generate fake data. 3. Write tests for these tools. 4.When anything fails, add a test.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}