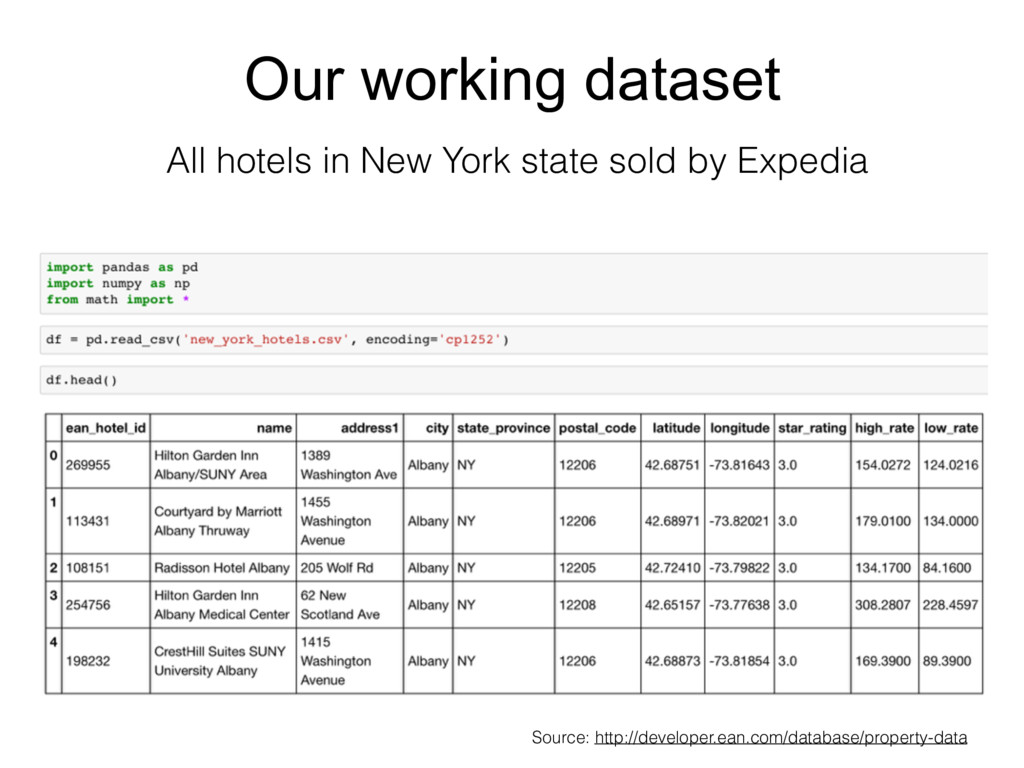
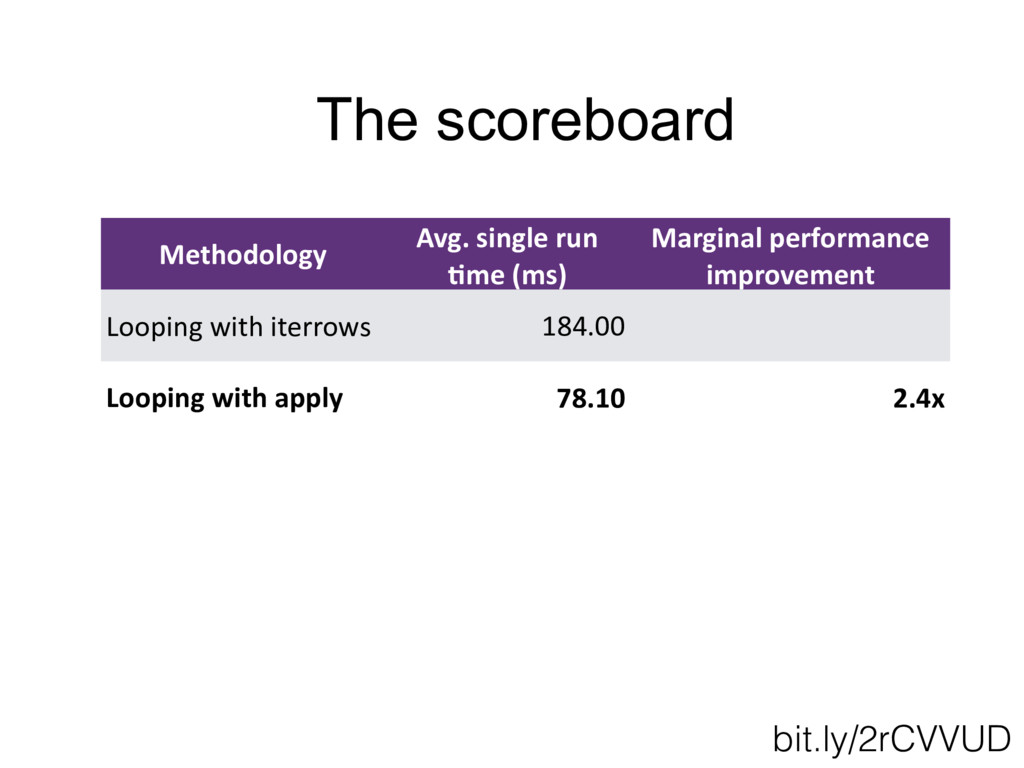
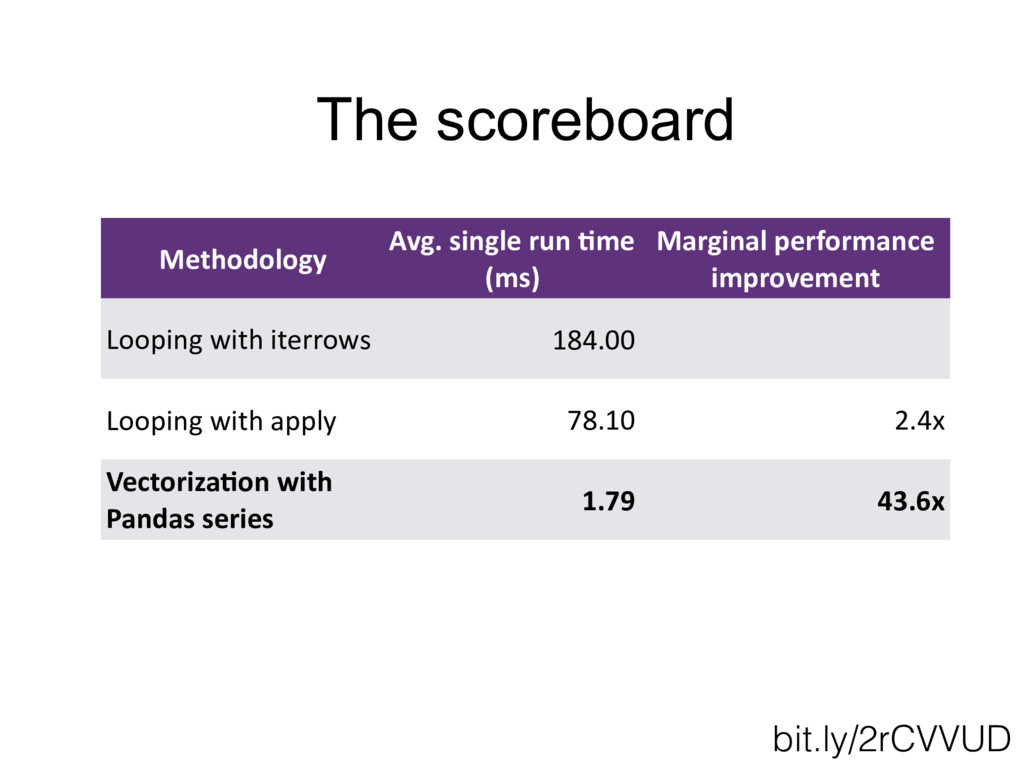
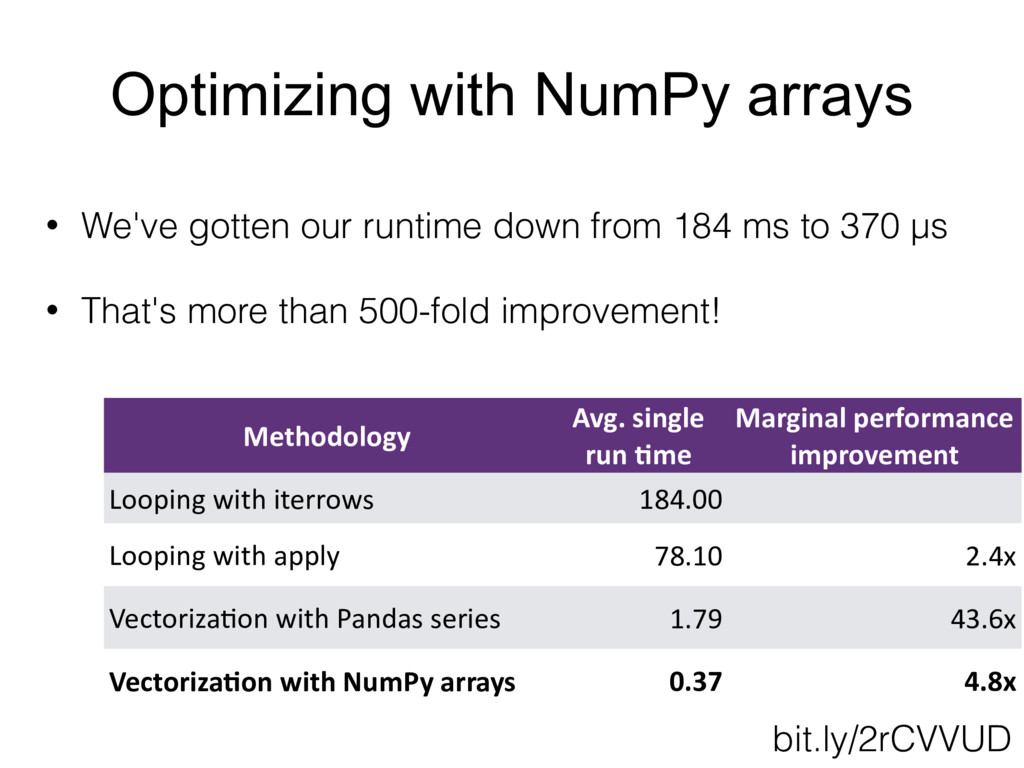
When I first began working with the Python Pandas library, I was told by an experienced Python engineer: "Pandas is fine for prototyping a bit of calculations, but it's too slow for any time-sensitive applications." Over multiple years of working with the Pandas library, I have realized that this was only true if not enough care is put into identifying proper ways to optimize the code's performance. This talk will review some of the most common beginner pitfalls that can cause otherwise perfectly good Pandas code to grind to a screeching halt, and walk through a set of tips and tricks to avoid them. Using a series of examples, we will review the process for identifying the elements of the code that may be causing a slowdown, and discuss a series of optimizations, ranging from good practices of input data storage and reading, to the best methods for avoiding inefficient iterations, to using the power of vectorization to optimize functions for Pandas dataframes.
https://us.pycon.org/2017/schedule/presentation/628/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![%timeit df['hr_norm'] = normalize(df, df['high_rate']) 2.84 ms ± 180 µs](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_9.jpg){kind=link}
![%load_ext line_profiler %lprun -f normalize df['hr_norm'] =\ normalize(df, df['high_rate']) Profiling](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Running function with iterrows %%timeit haversine_series = [] for index,](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_14.jpg){kind=link}
{kind=link}
![Timing looping with apply %%timeit df['distance'] =\ df.apply(lambda row: haversine(40.671,](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Vectorizing significantly improves performance %%timeit df['distance'] = haversine(40.671, -73.985,\ df['latitude'],](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Re-defining the function in the Cython compiler %%timeit df['distance'] =\](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_34.jpg){kind=link}
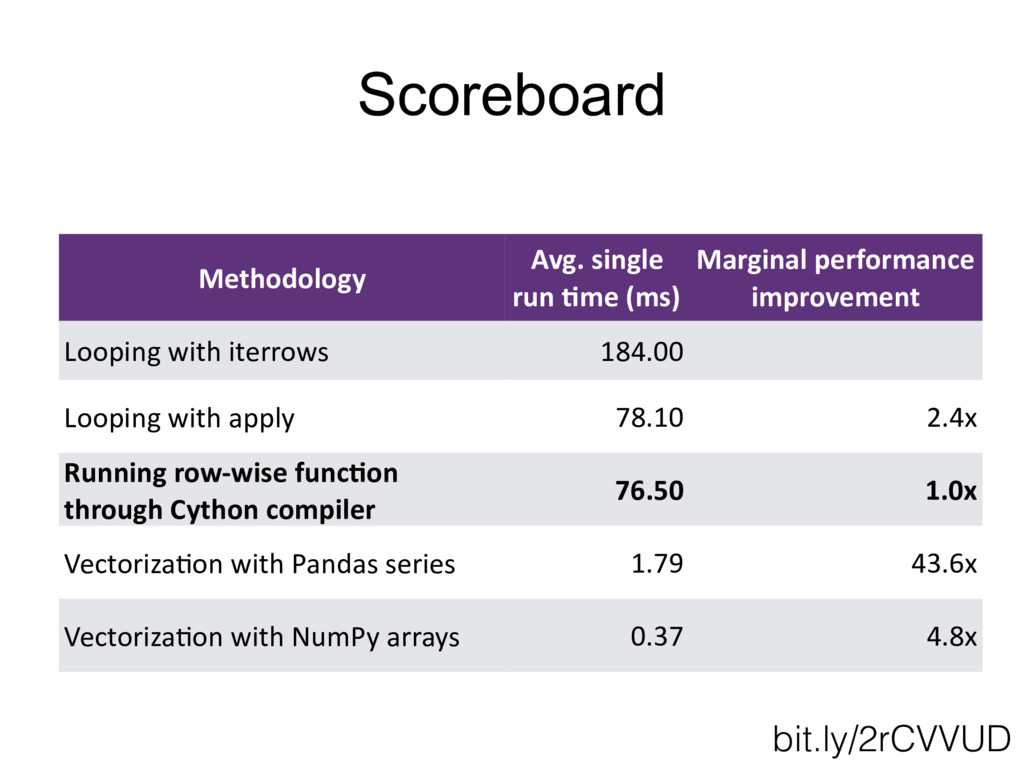{kind=link}
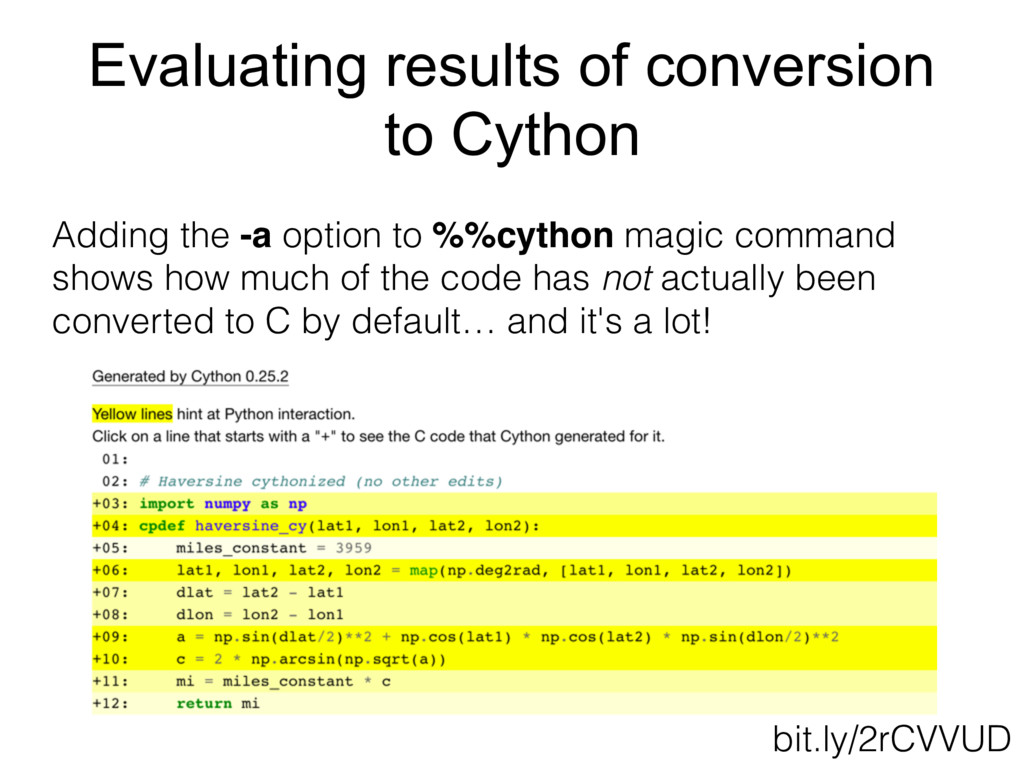{kind=link}
{kind=link}
{kind=link}
![Timing the cythonized function %%timeit df['distance'] =\ df.apply(lambda row: haversine_cy_dtyped(40.671,](https://files.speakerdeck.com/presentations/4d5e49c4b77540b19ea98bc251b808ee/slide_39.jpg){kind=link}
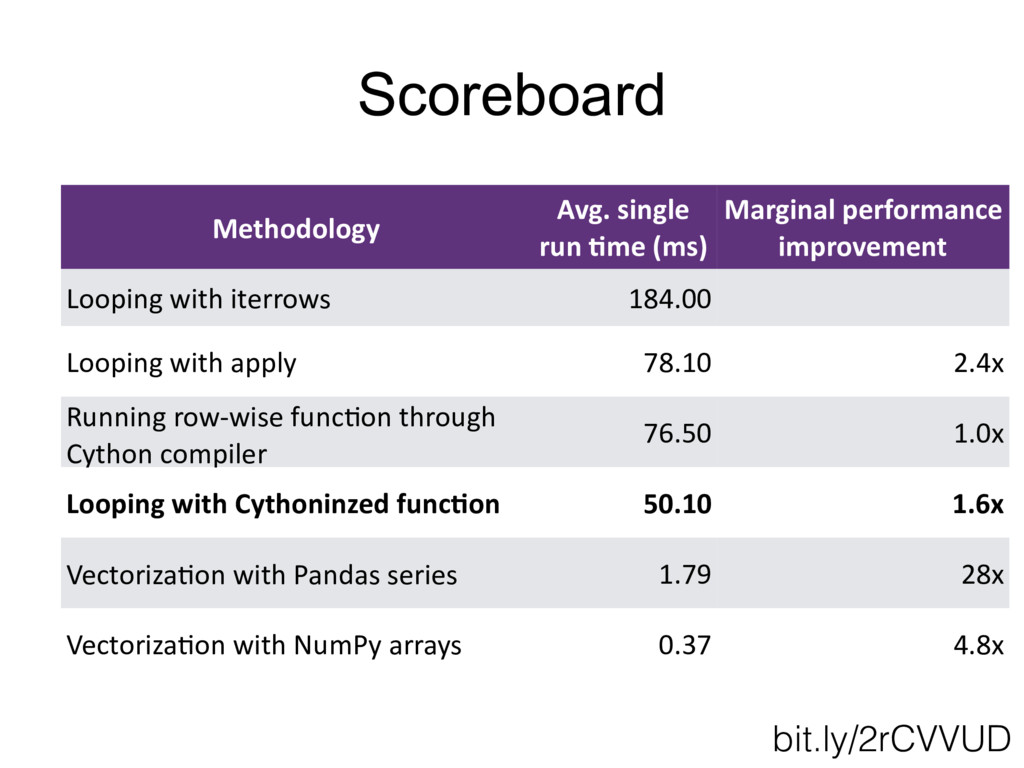{kind=link}
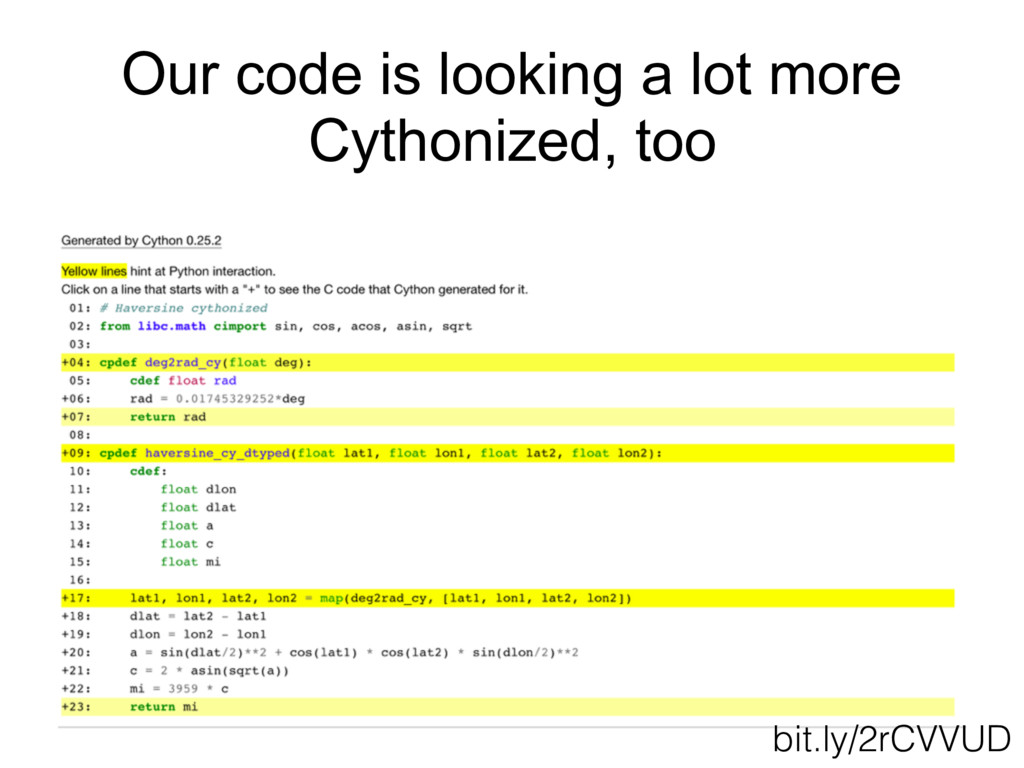{kind=link}
{kind=link}
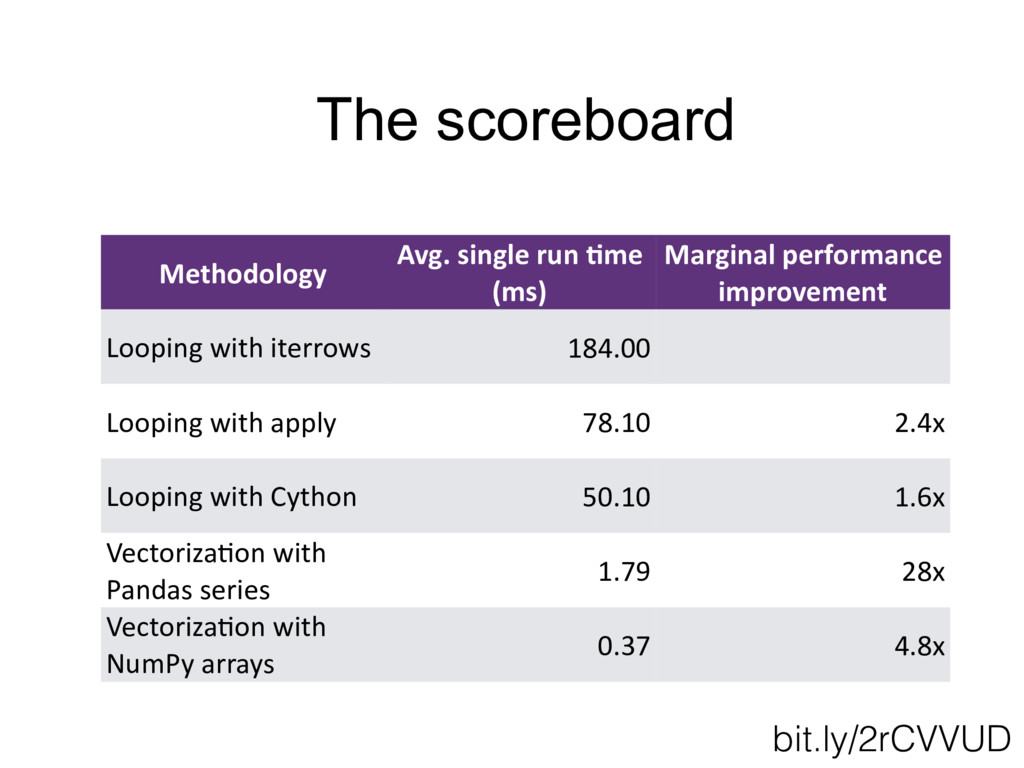{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}