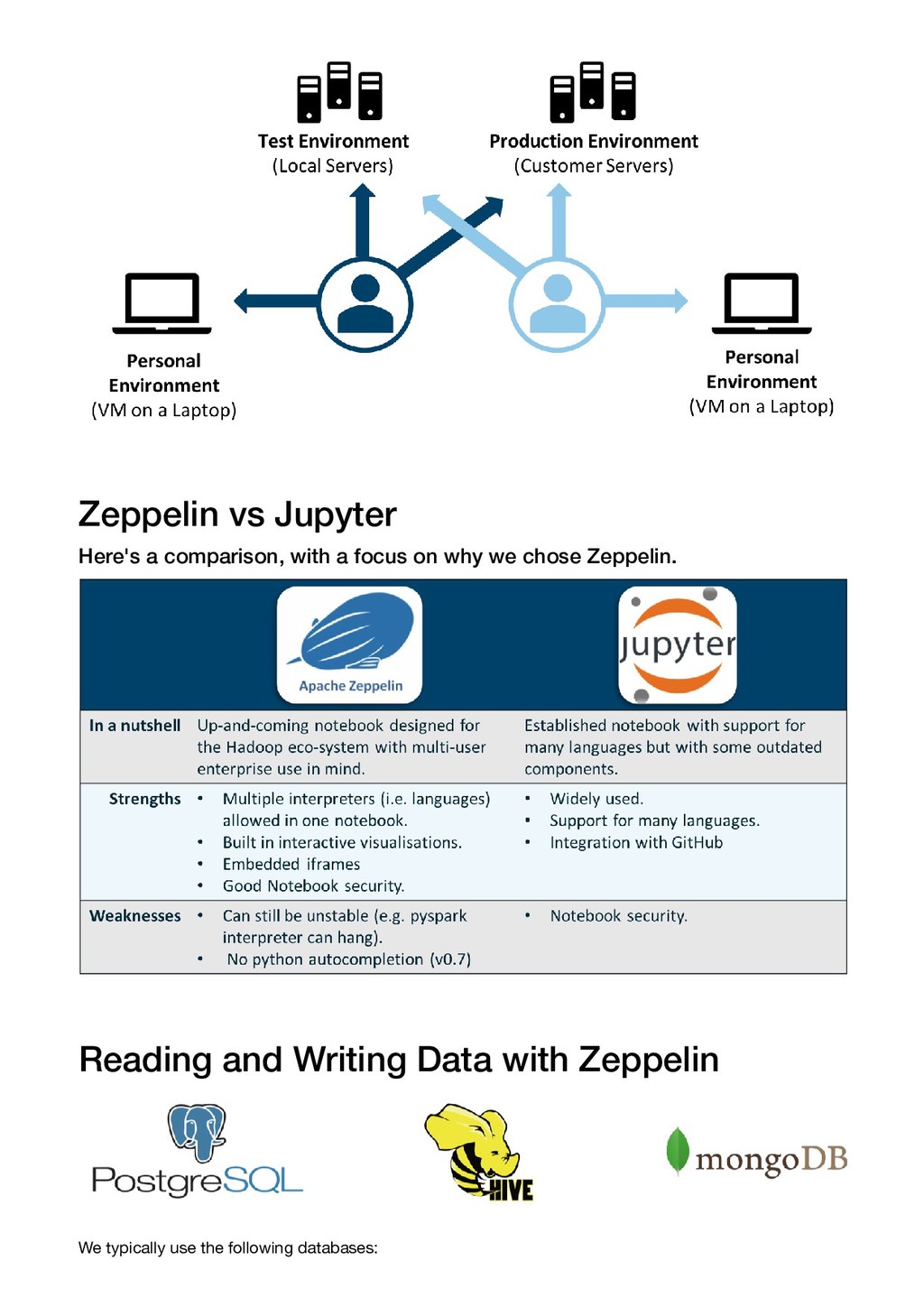
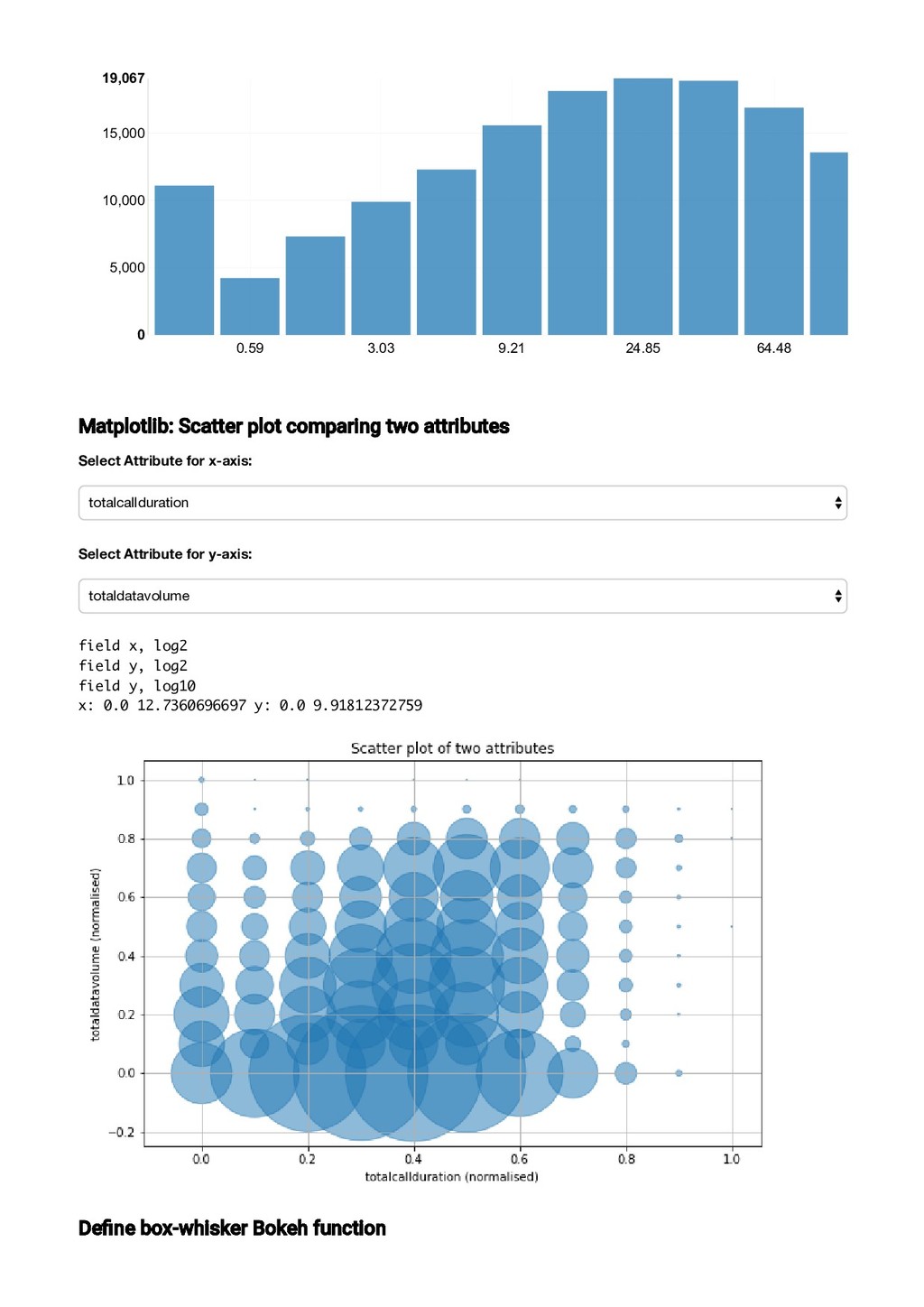
Zeppelin is a web based notebook which enables interactive data analytics on big data. Data can easily be ingested from a variety of databases and analysis can be performed in Python and Pyspark. Visualisations can be built and displayed together with the code, using Zeppelin’s built in tool Helium, or Python specific tools such as Matplotlib and Bokeh. The web based interface facilitates easy sharing of results, and collaboration on projects.
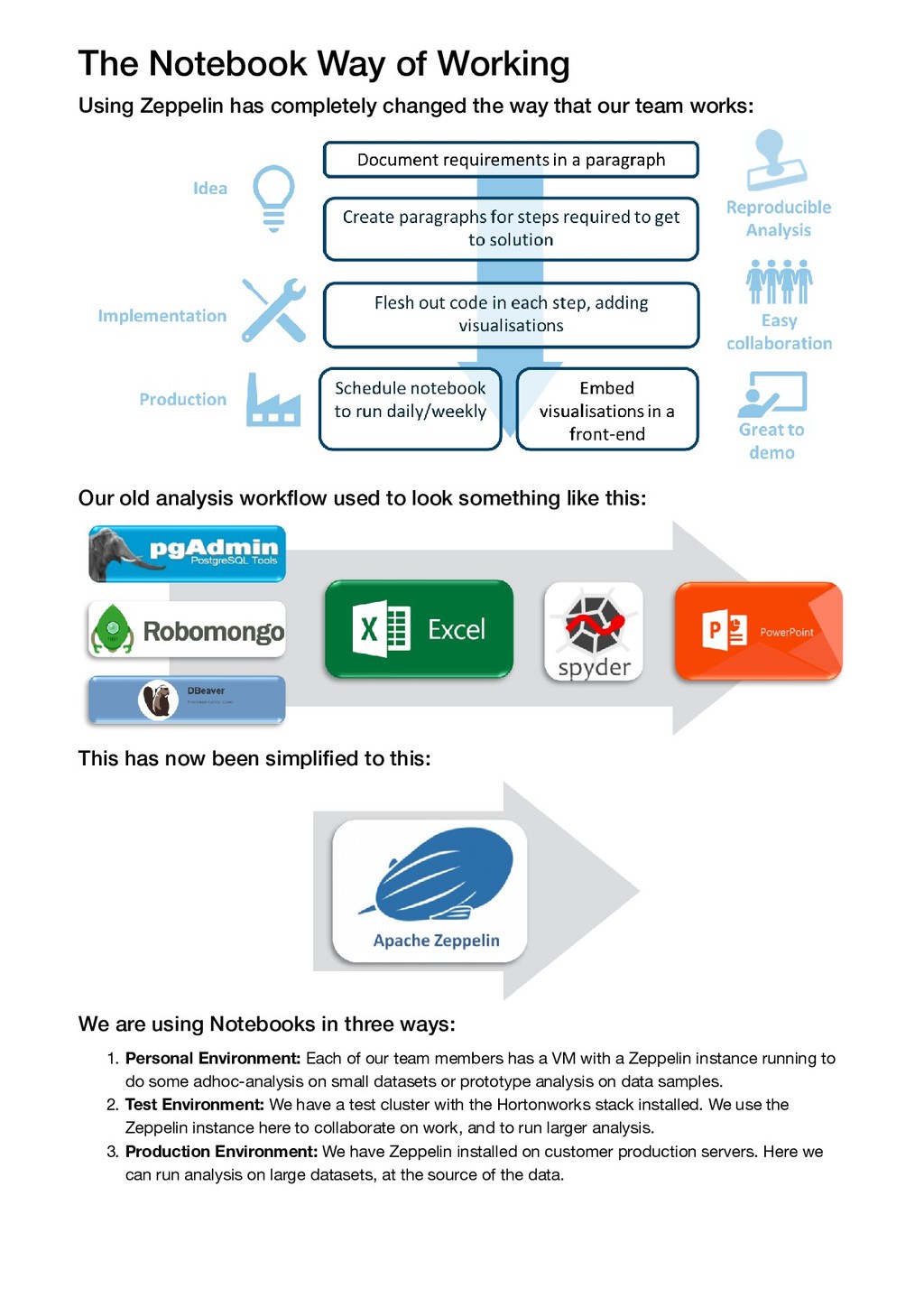
Developing in Zeppelin has changed the way we approach model development. We are able to take a project from an idea to a product all within one tool using the fo3llowing process:
1. Come up with an idea. Write some notes in a Zeppelin notebook describing how we would like the idea implemented.
2. Slowly start fleshing out the idea, with real code, until the solution is built. This is great to demo, as the code is in bite size chunks, and visualisations can be added directly in.
3. Take the code into production. It can be scheduled it to run directly in Zeppelin with a cron scheduler, or from a tool such as Nifi. Interactive visualisations can be embedded in a web-based frontend.
This talk is aimed at data scientists, particularly those working with big data. We will demonstrate how we have built a catalogue of subscriber attributes based on customer mobile usage and purchase behavior using Zeppelin and Pyspark. These attributes can be used to profile subscribers, and are the starting point for indivisualised customer engagement. Anyone who attends this talk will get an introduction to Zeppelin and Pyspark and an overview of what can be achieved with these tools.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}