e Silva (Montes Claros, MG, Brazil) E-mail: [email protected][email protected] Site: https://petroniocandido.github.io/ This material is licensed under “ Creative Commons Attribution - NonCommercial - ShareAlike” license. All external portions included in this material are cited in loco. Esse material está licenciado com uma licença “ Creative Commons Atribuição - NãoComercial - CompartilhaIgual ”. Todos os materiais externos inclusos neste material serão referenciados in loco.
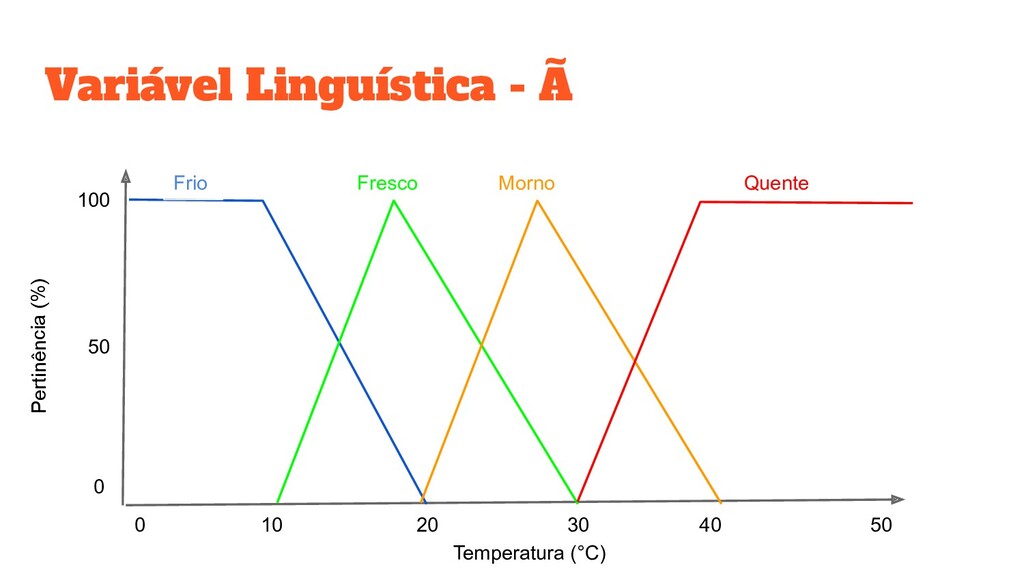
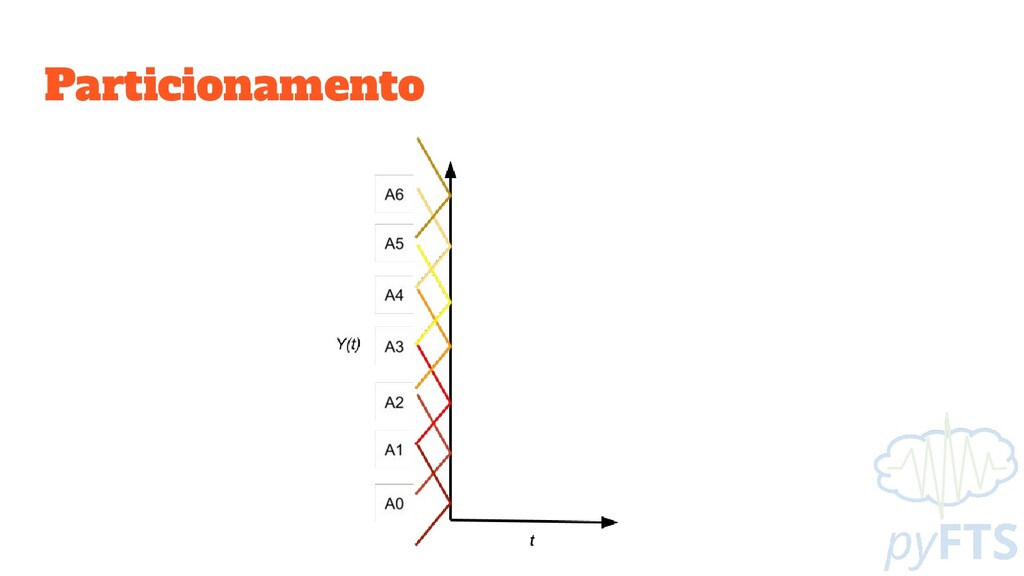
• U: Universo de Discurso U = [ min(Y), max(Y) ] • μ: Função de Pertinência μ: U → [0,1] • A: Conjunto Nebuloso ◦ É um subconjunto de U definido por uma função de pertinência μ ◦ Os conjuntos são sobrepostos, um mesmo valor y ∈ Y pode pertencer à vários conjuntos simultaneamente, em diferentes graus
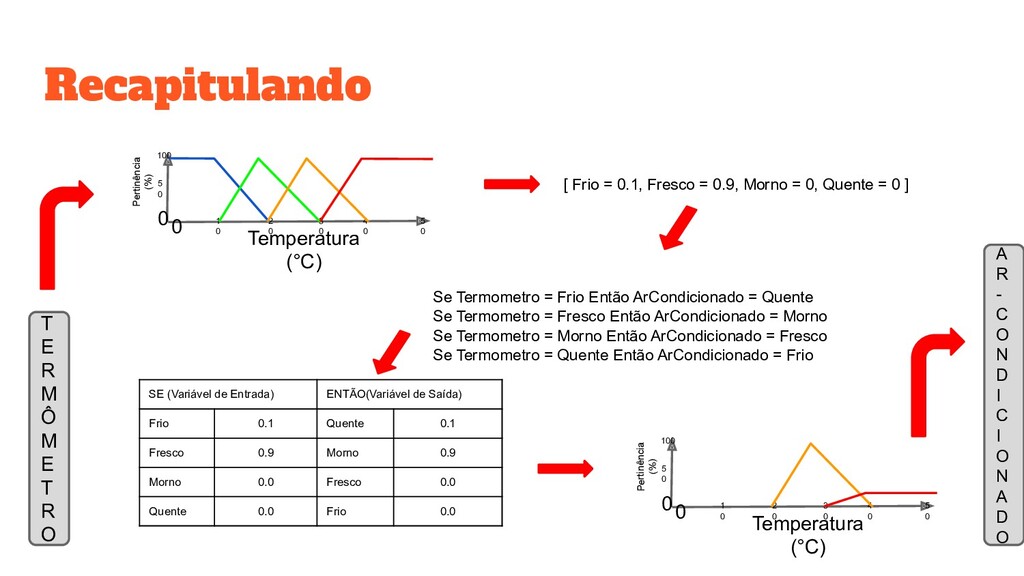
O A R - C O N D I C I O N A D O Temperatura (°C) Pertinência (%) 0 1 0 2 0 3 0 4 0 5 0 0 5 0 100 [ Frio = 0.1, Fresco = 0.9, Morno = 0, Quente = 0 ] Se Termometro = Frio Então ArCondicionado = Quente Se Termometro = Fresco Então ArCondicionado = Morno Se Termometro = Morno Então ArCondicionado = Fresco Se Termometro = Quente Então ArCondicionado = Frio SE (Variável de Entrada) ENTÃO(Variável de Saída) Frio 0.1 Quente 0.1 Fresco 0.9 Morno 0.9 Morno 0.0 Fresco 0.0 Quente 0.0 Frio 0.0 Temperatura (°C) Pertinência (%) 0 1 0 2 0 3 0 4 0 5 0 0 5 0 100
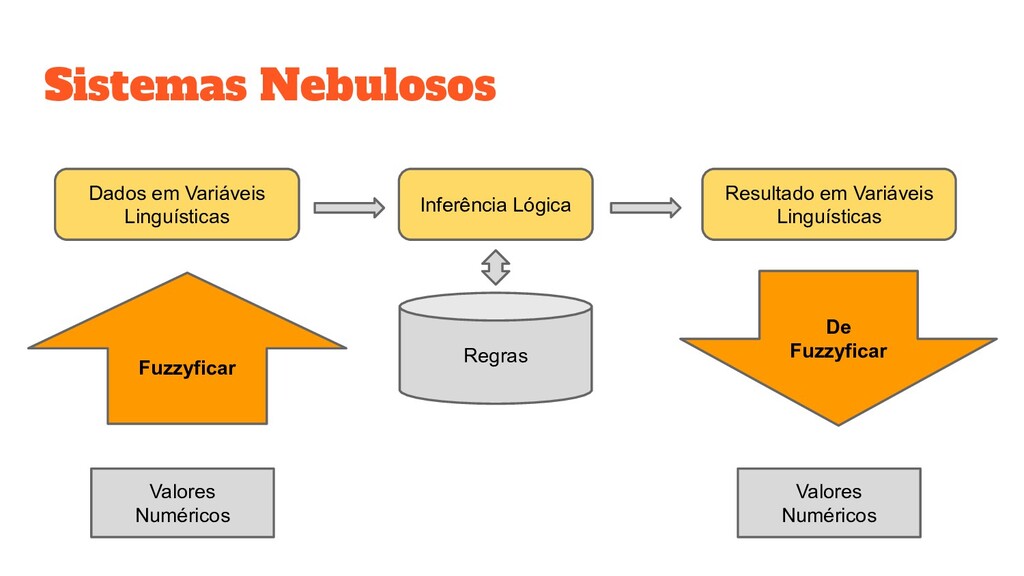
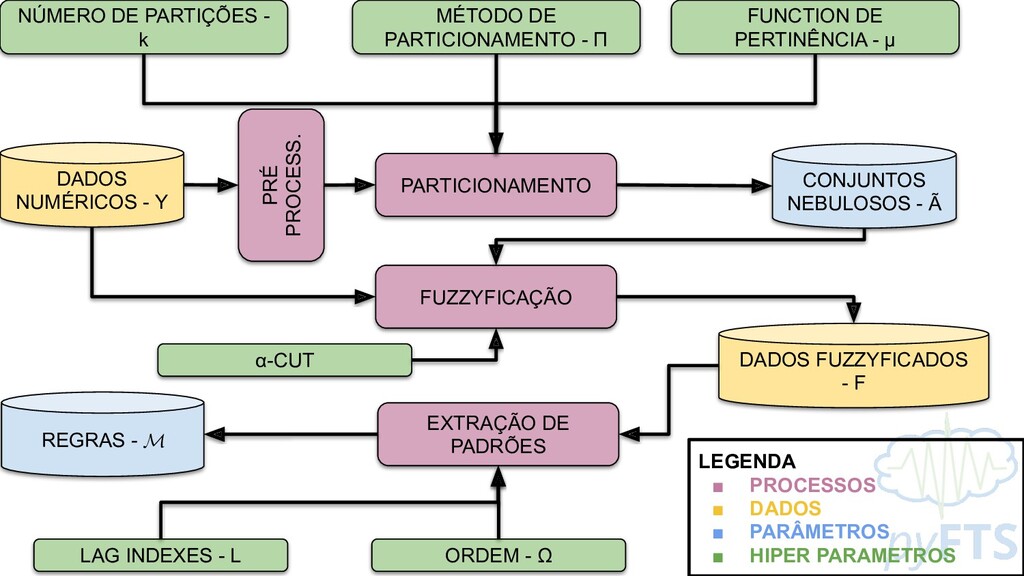
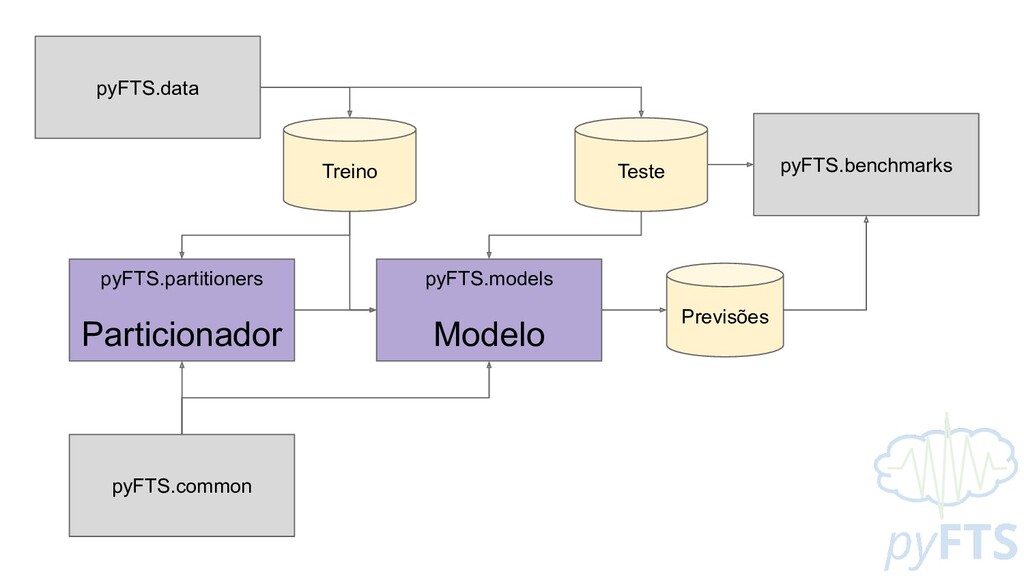
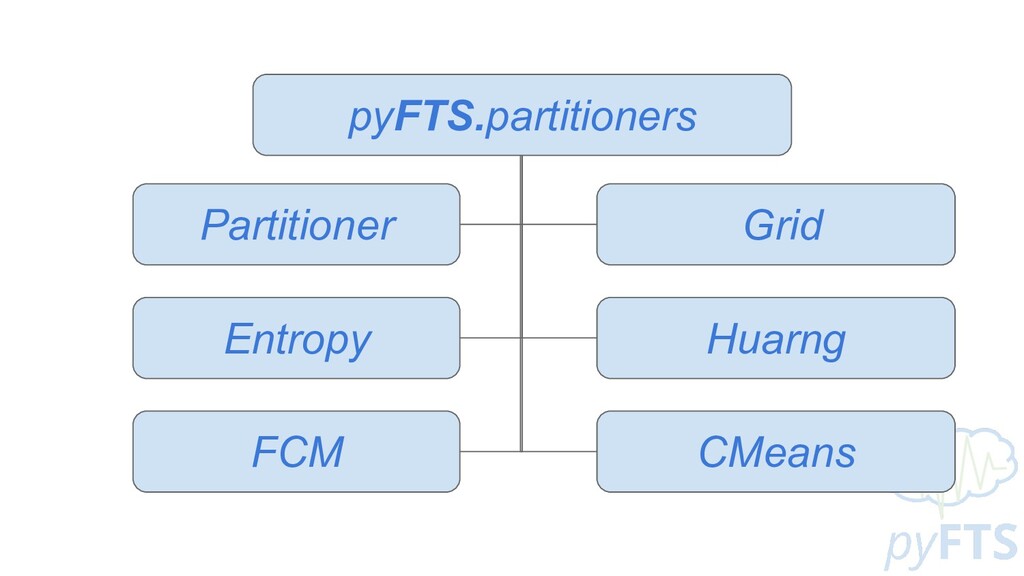
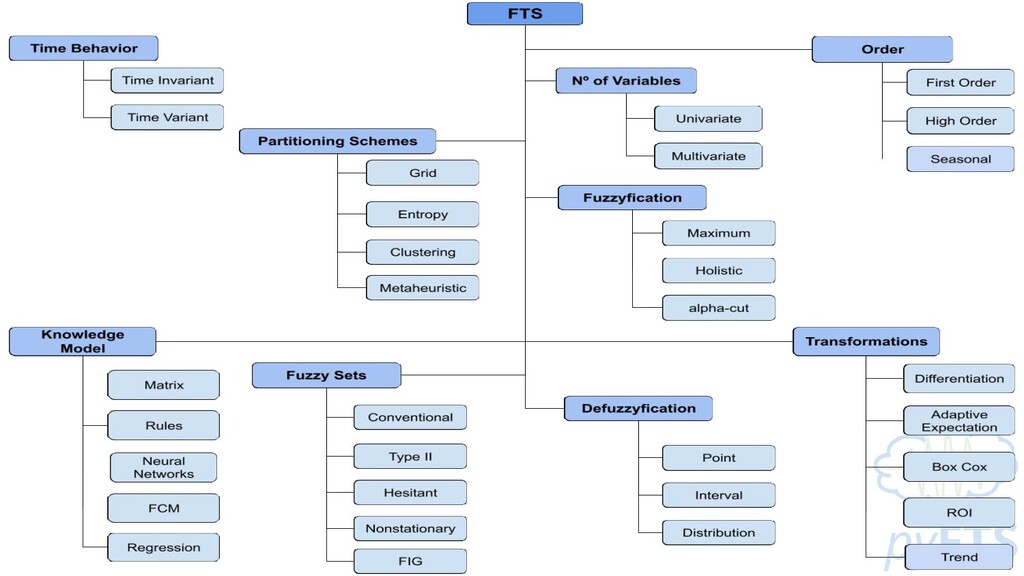
DADOS FUZZYFICADOS - F REGRAS - EXTRAÇÃO DE PADRÕES NÚMERO DE PARTIÇÕES - k MÉTODO DE PARTICIONAMENTO - Π FUNCTION DE PERTINÊNCIA - μ ORDEM - Ω LEGENDA ▪ PROCESSOS ▪ DADOS ▪ PARÂMETROS ▪ HIPER PARAMETROS PRÉ PROCESS. LAG INDEXES - L α-CUT
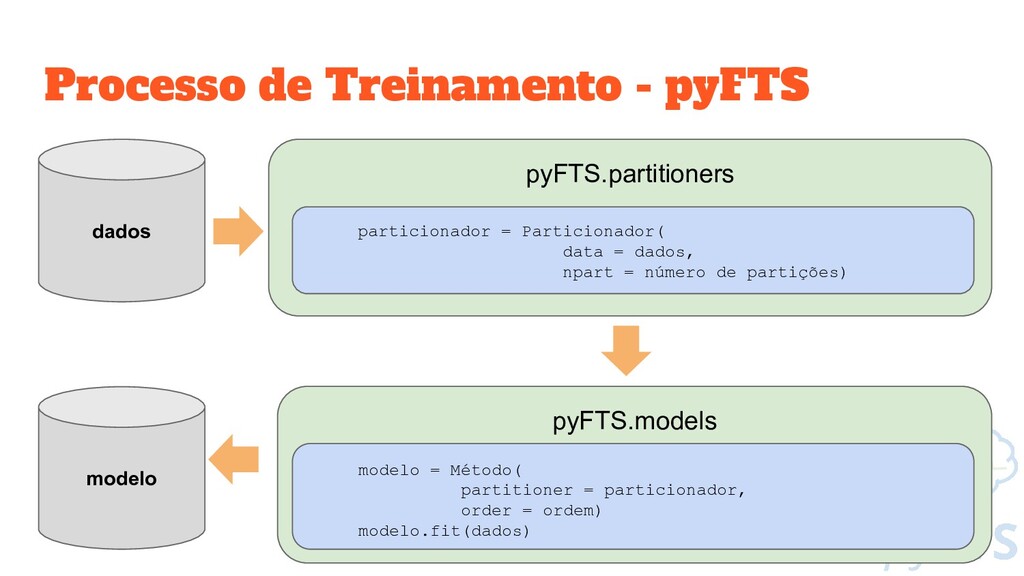
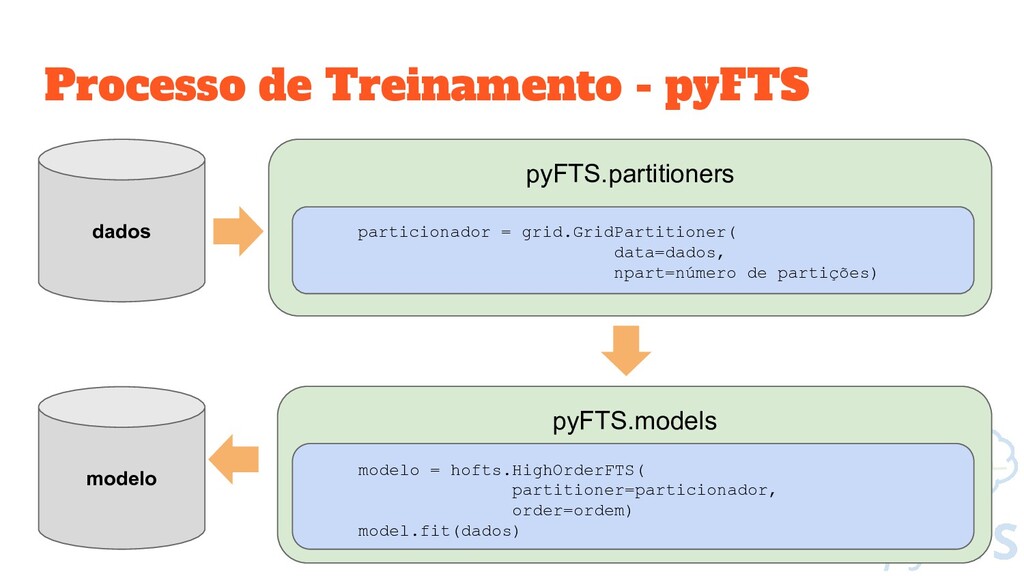
do Universo de Discurso particionador = Grid.GridPartitioner(data=dados_treino, npart=10) # Cria uma figura no Matplotlib fig, ax = plt.subplots(nrows=1, ncols=1, figsize=[15,5]) # Plota o particionamento particionador.plot(ax)
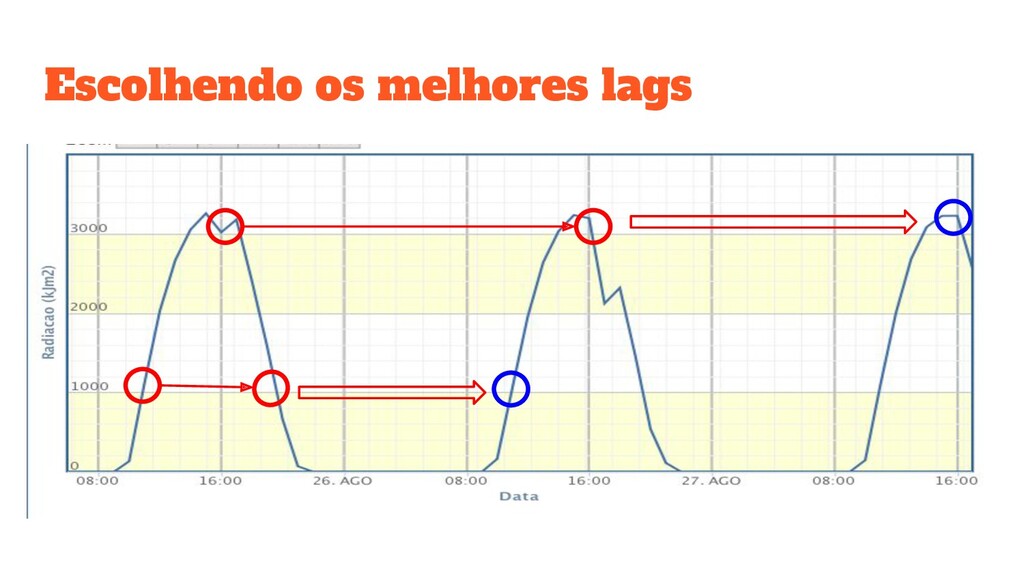
Granularidade média ◦ Ajuste ideal (fit) ◦ Aprende o sinal sem aprender o ruído ◦ Não há um valor de referência, depende dos dados ◦ Precisa ser testado!
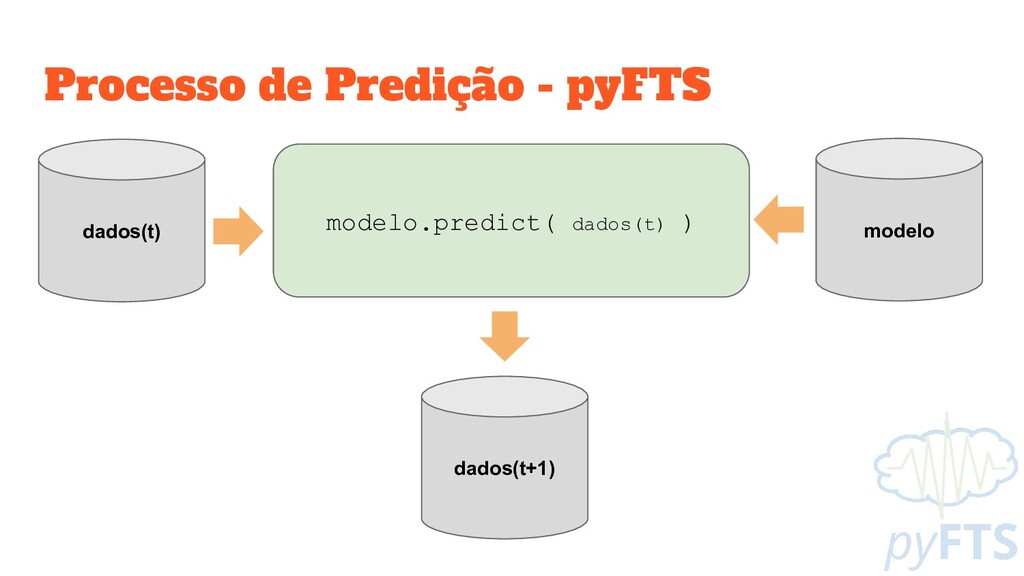
Cria um modelo vazio, utilizando o método de High Order FTS modelo = hofts.HighOrderFTS(partitioner=particionador, order=2) # Todo o procedimento de treinamento é feito pelo método fit modelo.fit(dados_treino) # Salva o modelo treinado Util.persist_obj(modelo, “arquivo”)
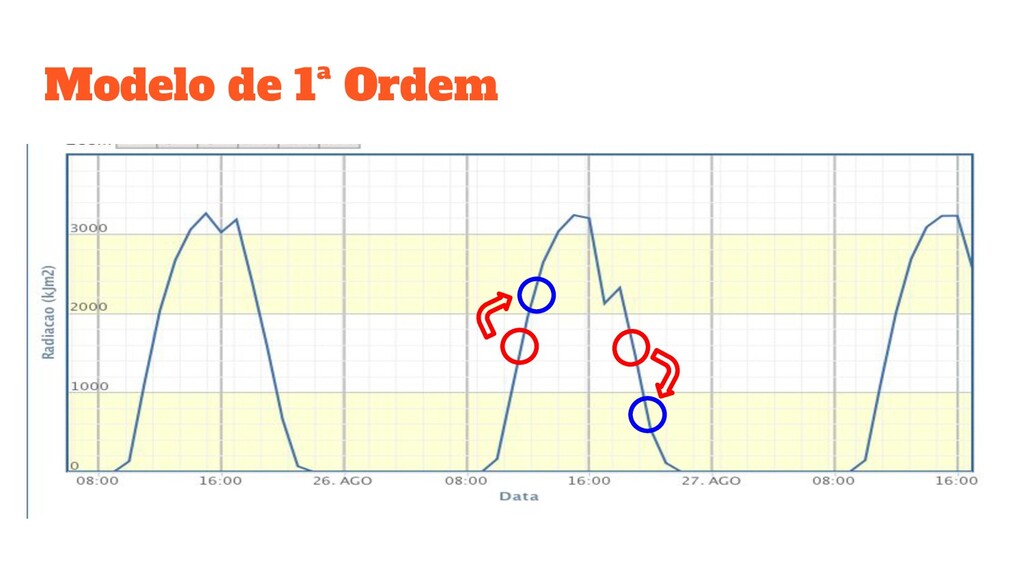
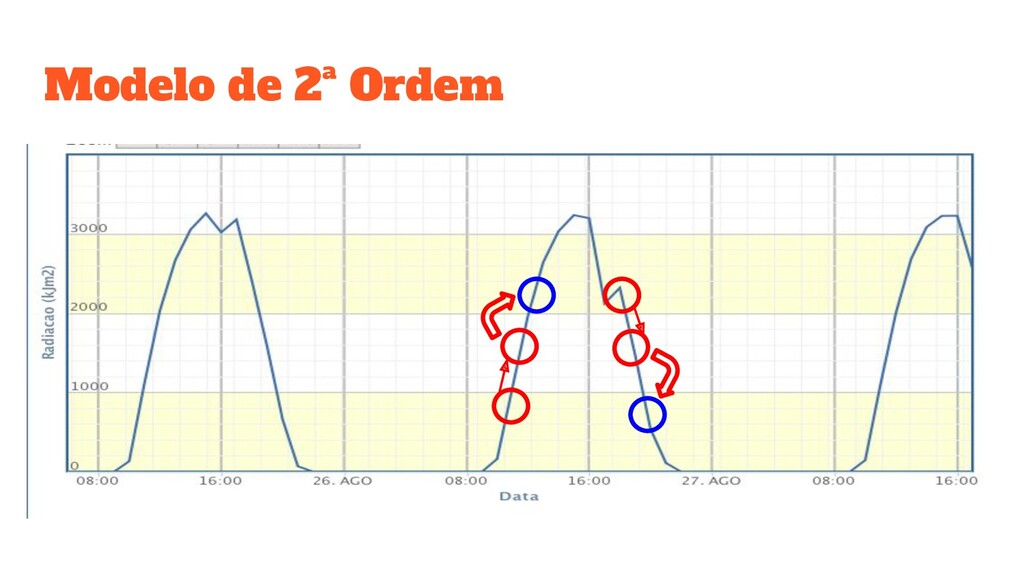
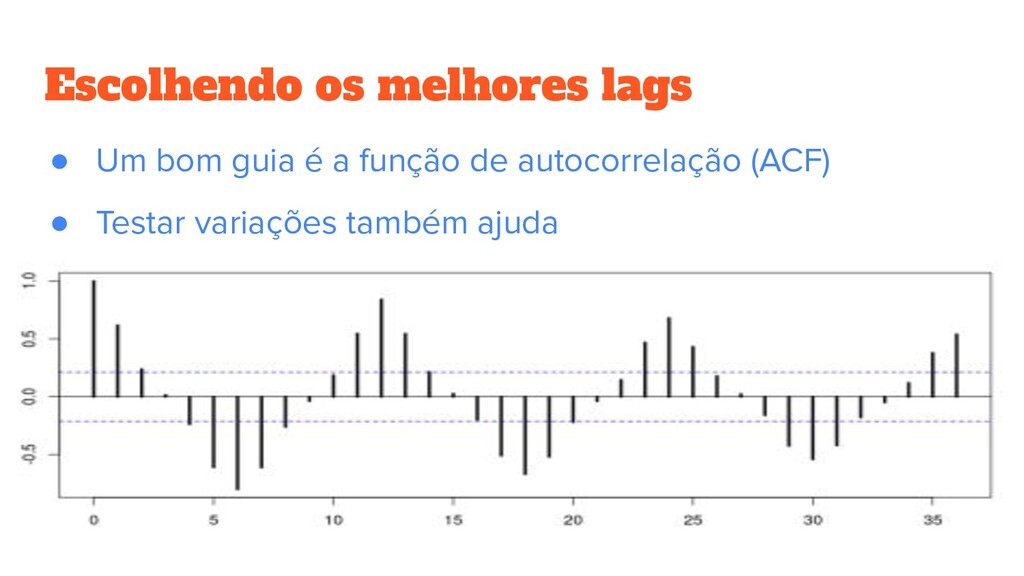
pelo modelo ? • FTS funcionam com base em padrões sequenciais / temporais • A ordem é a quantidade de dados usada para definir esses padrões • Ordem muito baixa: underfit • Ordem muito alta: overfit
pyFTS.benchmarks import Measures # Carrega o modelo modelo = Util.load_obj(“arquivo”) # Todo o procedimento de inferência é feito pelo método predict predicoes = modelo.predict(dados_teste) # Avalia as predições pelo RMSE, MAPE e U Measures.get_point_statistics(dados_teste,model)
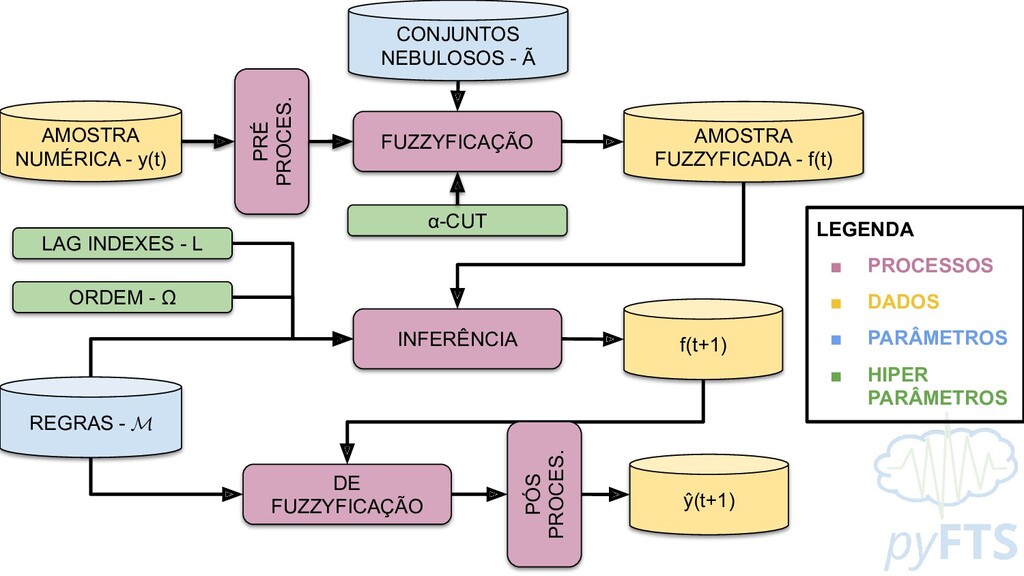
Previsão por ponto, intervalo e distribuição de probabilidades ◦ opção type na função predict • Previsão para um ou mais passos à frente ◦ opção steps_ahead na função predict • Auditabilidade e interpretabilidade ◦ opção explain da função predict
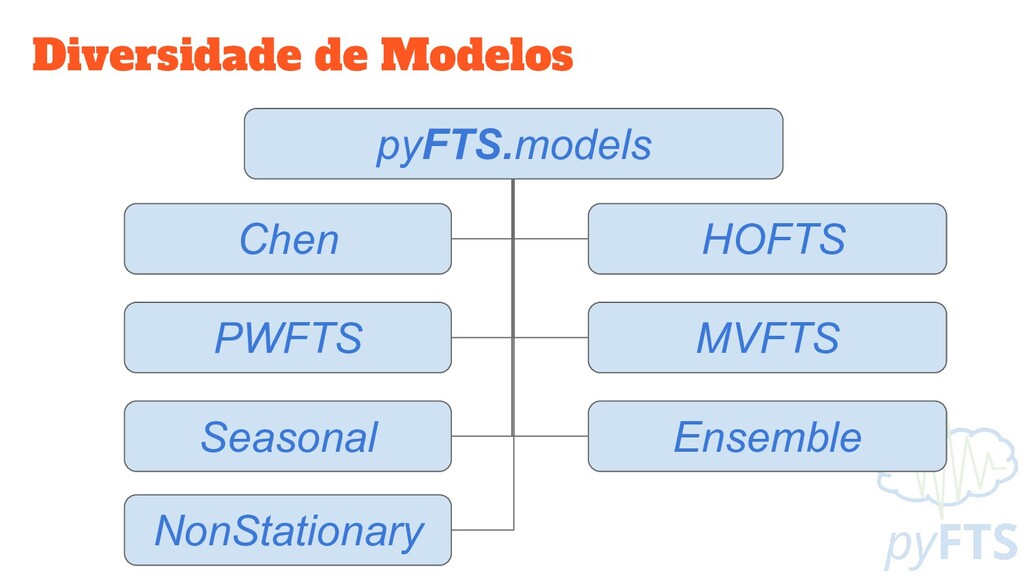
Um campo de dados pode ser utilizado para mais de uma variável! ◦ Aplicando transformações de dados ◦ Retirando componentes de dados estruturados • Os modelos ficam mais descritivos, porém bem maiores e mais complexos!
ou na variância) • Concept Drift ◦ Alteração da distribuição da série temporal • Alternativas: ◦ Retreinar os modelos ◦ Ensemble adaptativo ◦ Conjuntos Nebulosos Não Estacionários
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] https://petroniocandido.github.io/](https://files.speakerdeck.com/presentations/0ccf03feaf4d44d28b856e30e41ae406/slide_55.jpg){kind=link}