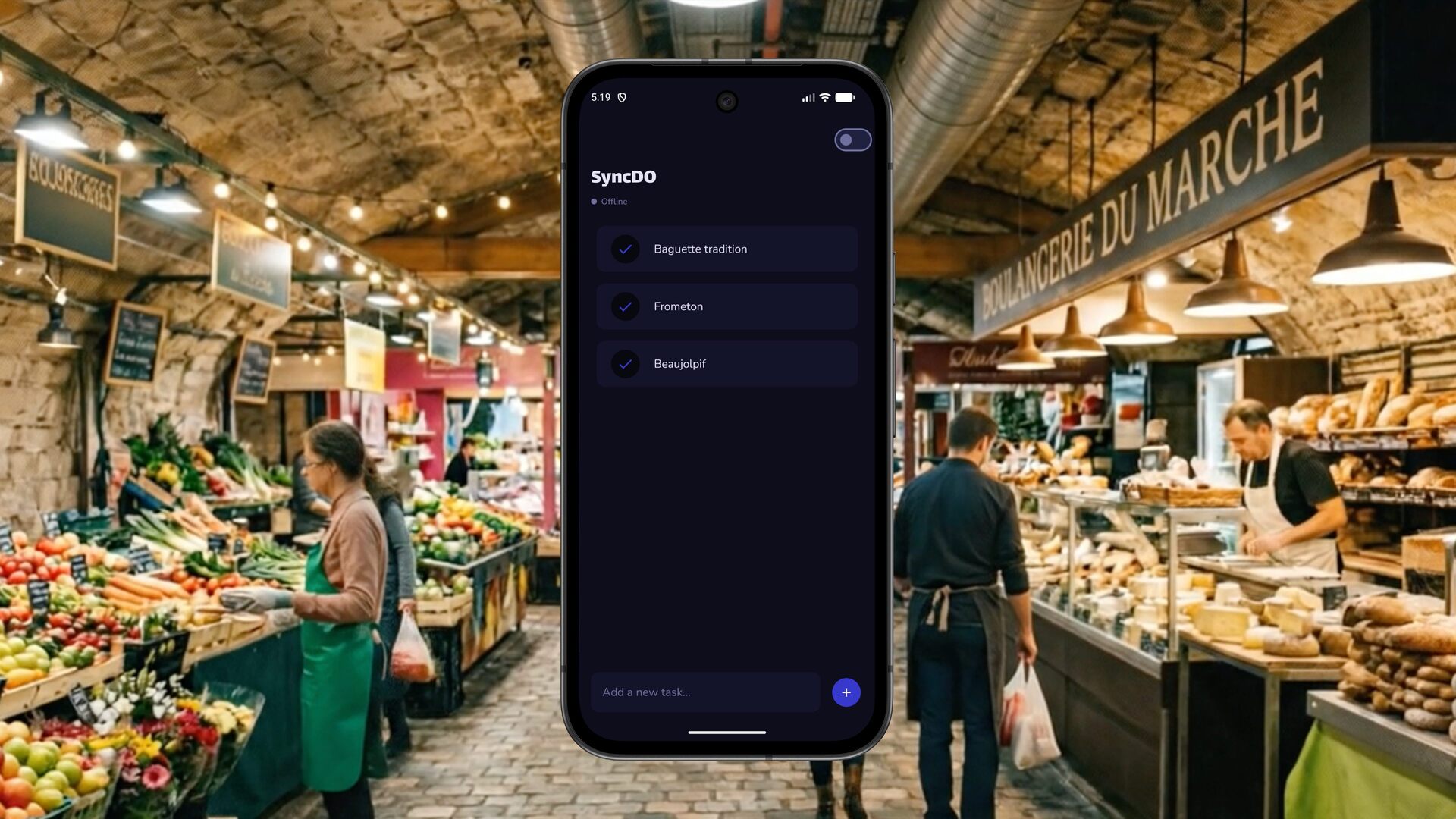
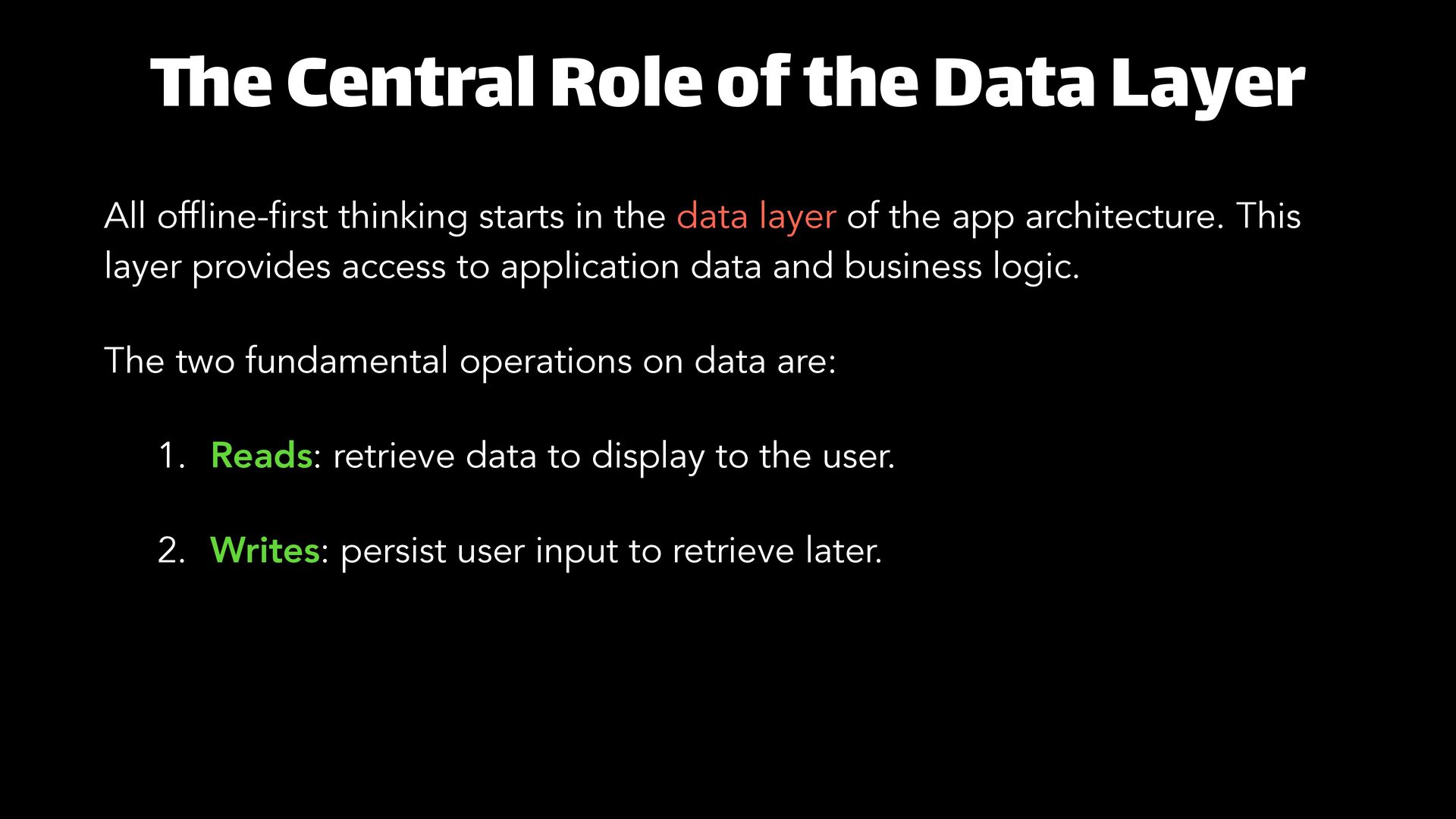
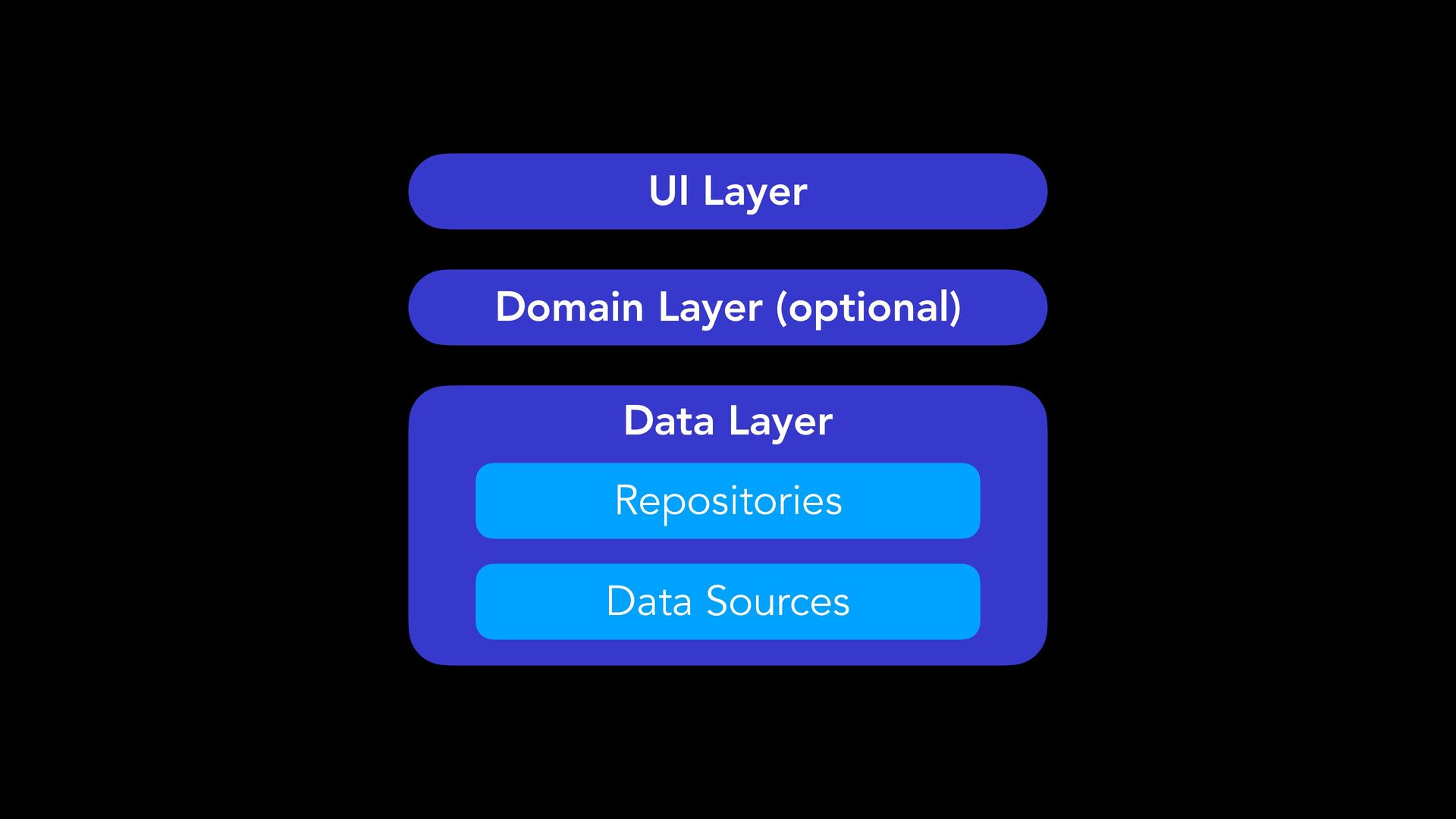
In 2026, a loading spinner in the subway isn’t “bad connectivity”. It’s a cloud-first app showing its limits. This talk is about offline-first architecture: write locally first, and treat sync as a background process, not a user-blocking gate. The hard part is concurrency: Alice edits a to-do offline while Bob checks it off. Who wins? Definitely not “last-write-wins”. We will unpack CRDTs, a data structure designed to merge changes without conflicts and converge reliably. Then we go hands-on with Kotlin Multiplatform by designing a practical local-first architecture, local persistence, a sync engine built around deltas, and the real-world challenges (tombstones, pruning, UI “glitches”). The goal: one robust, shared sync core for Android, iOS, the Web, and apps that stays trustworthy even when the network isn’t.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}