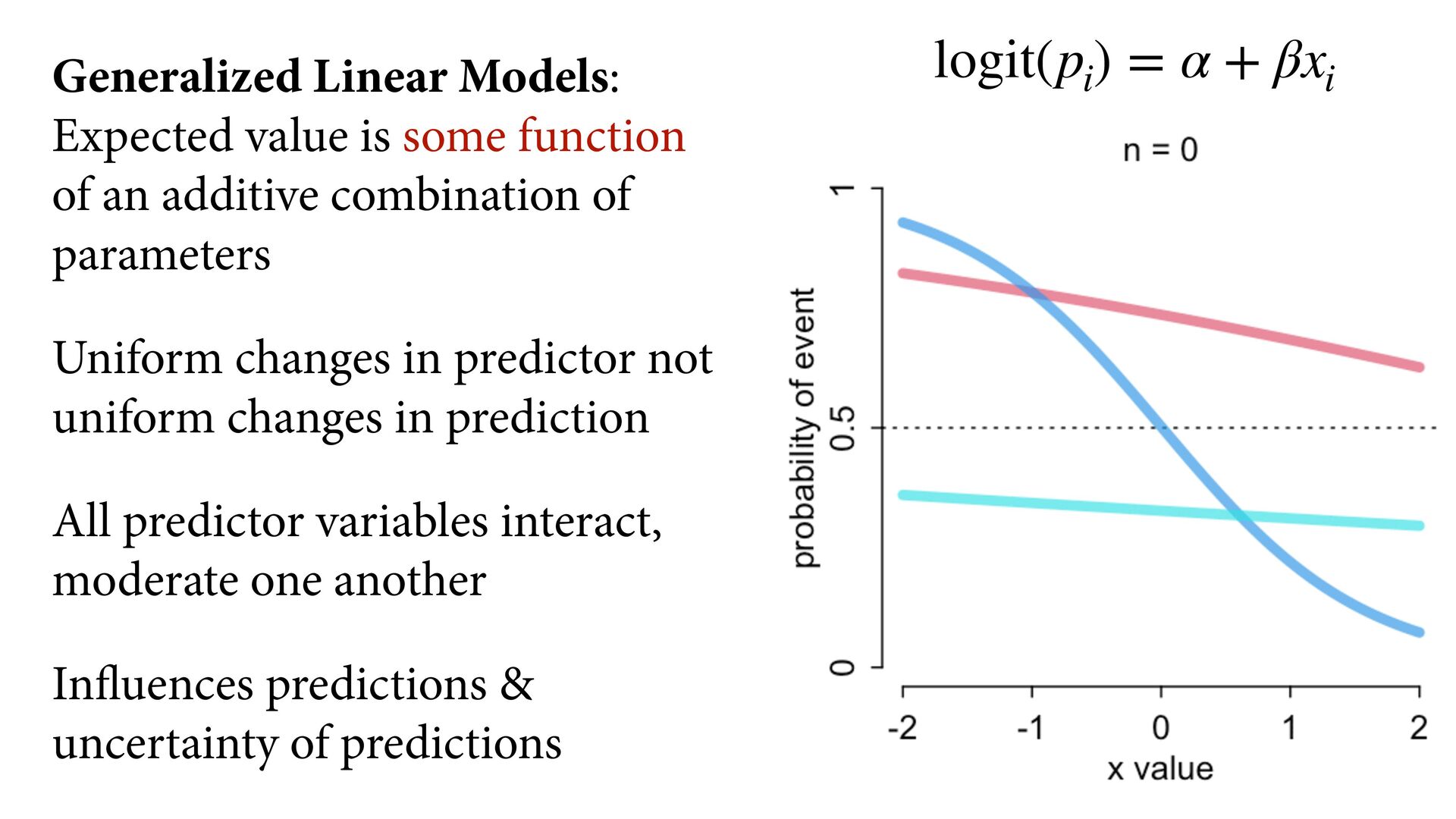
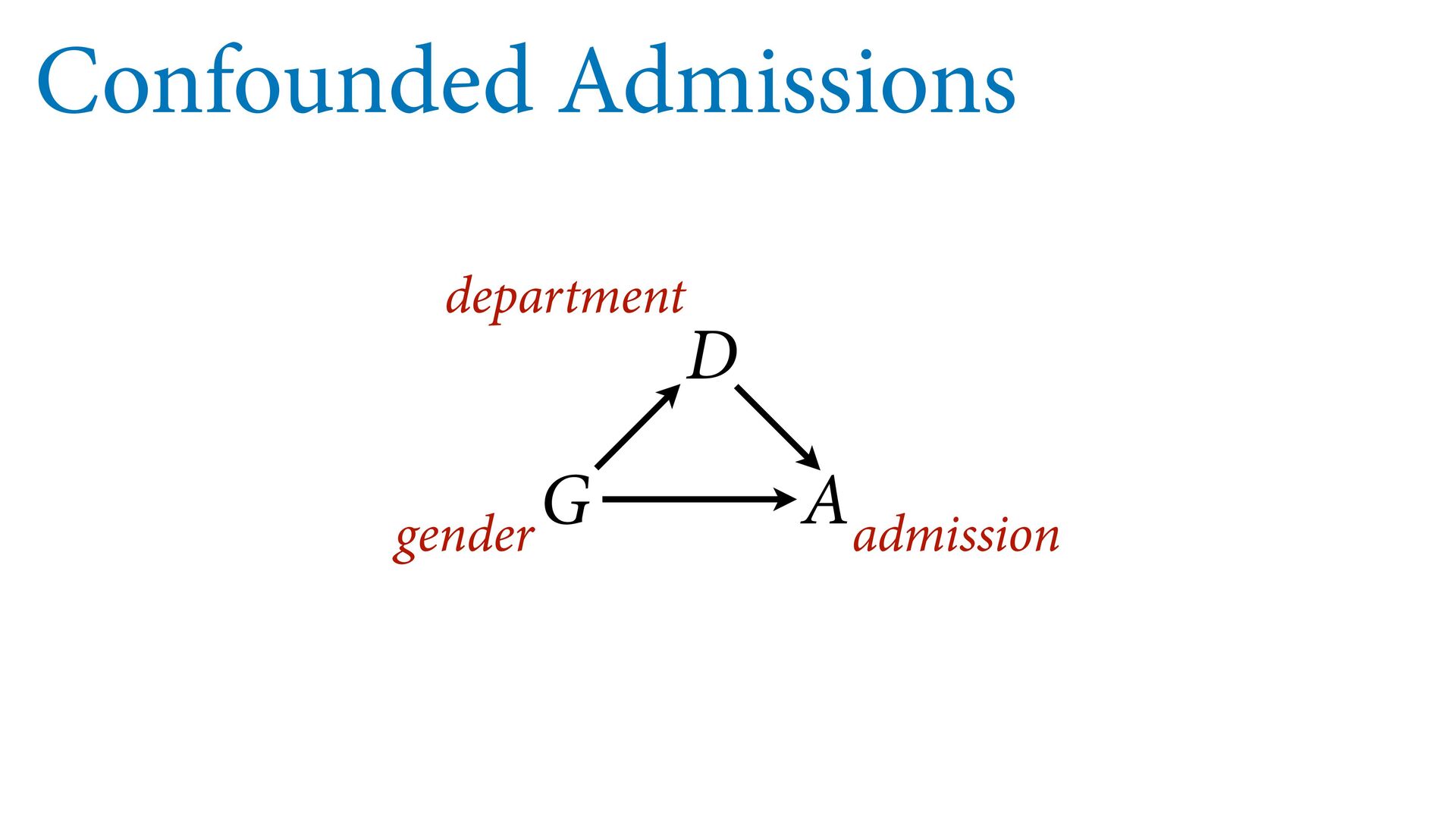
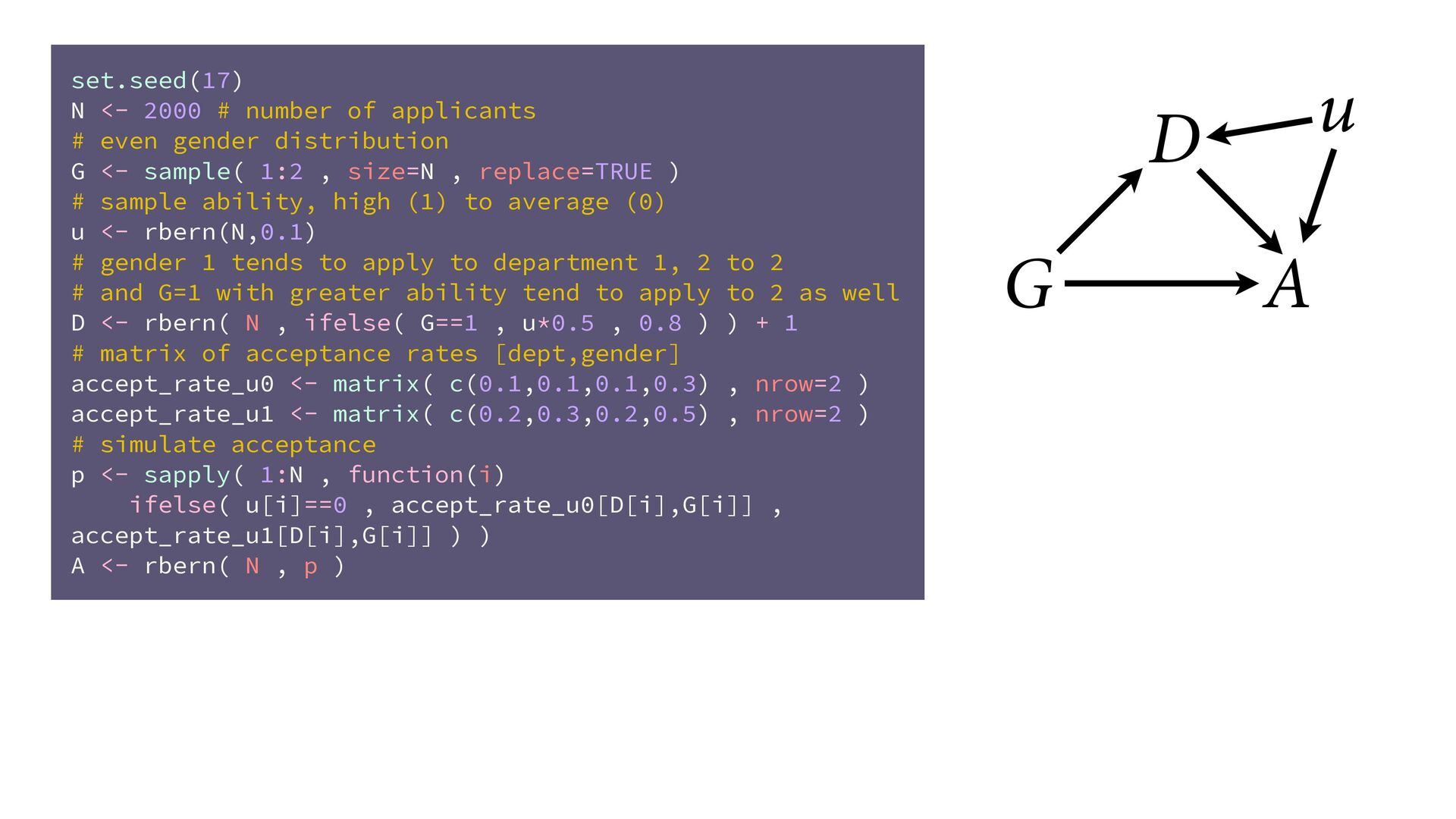
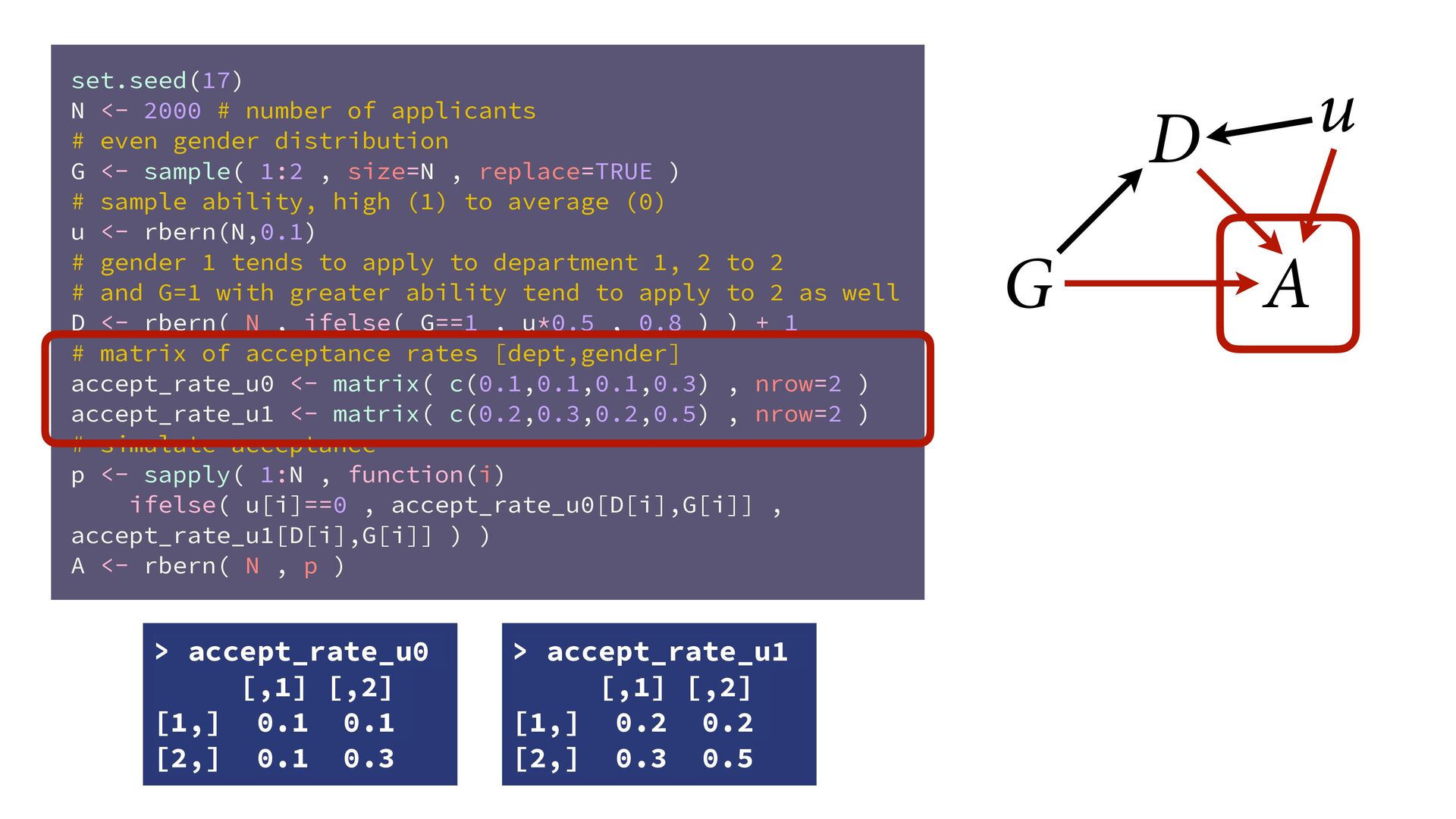
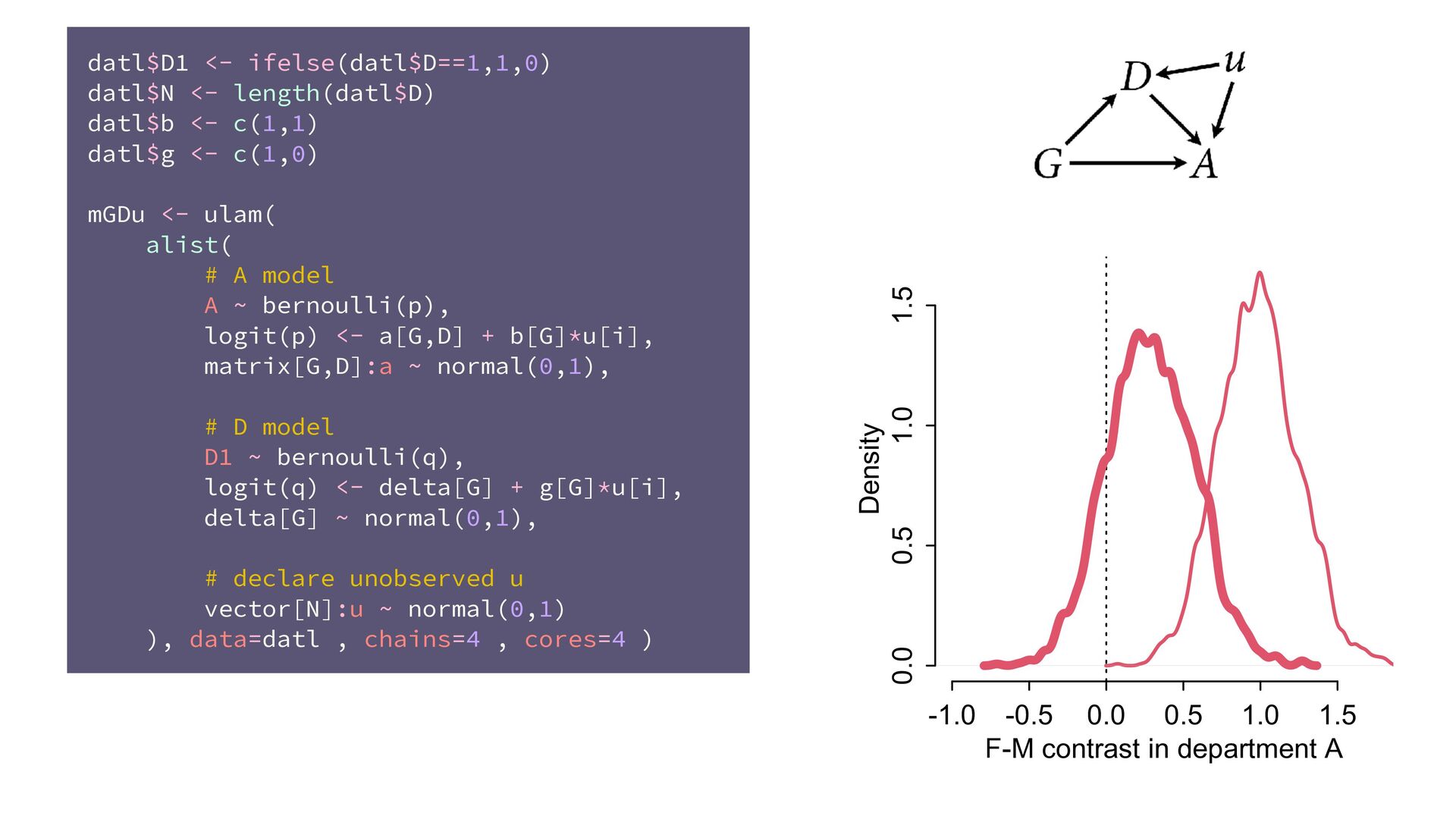
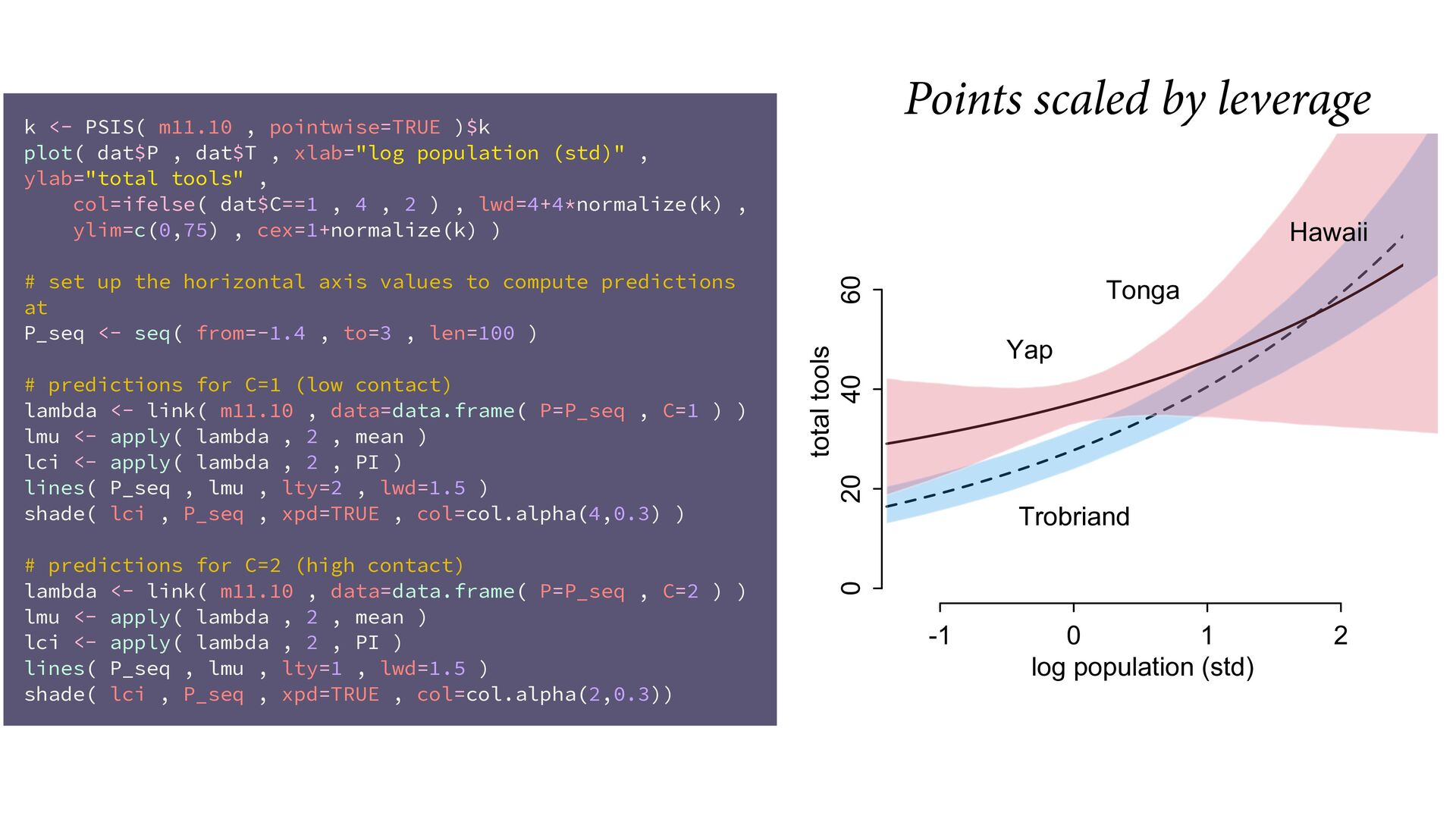
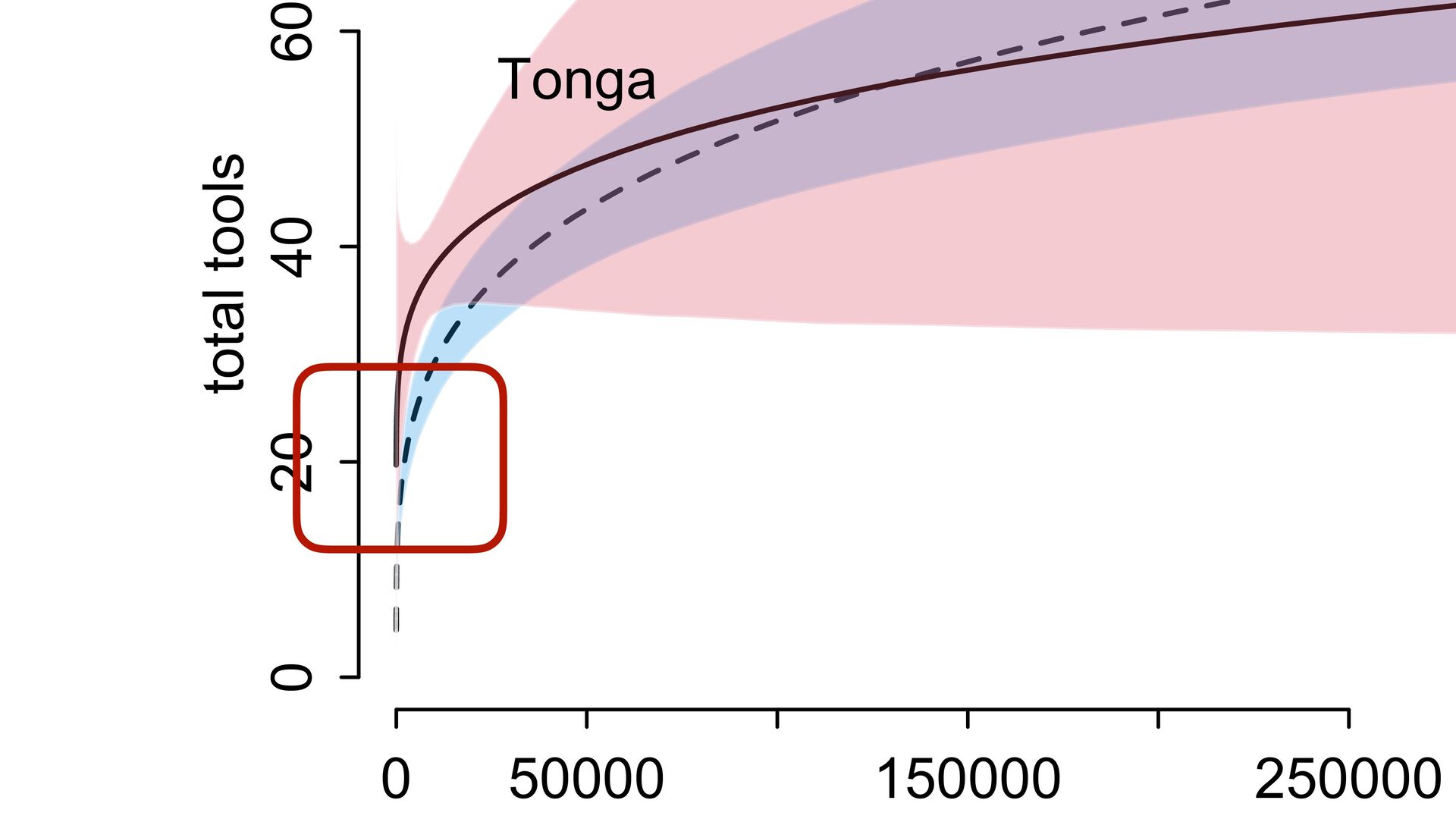
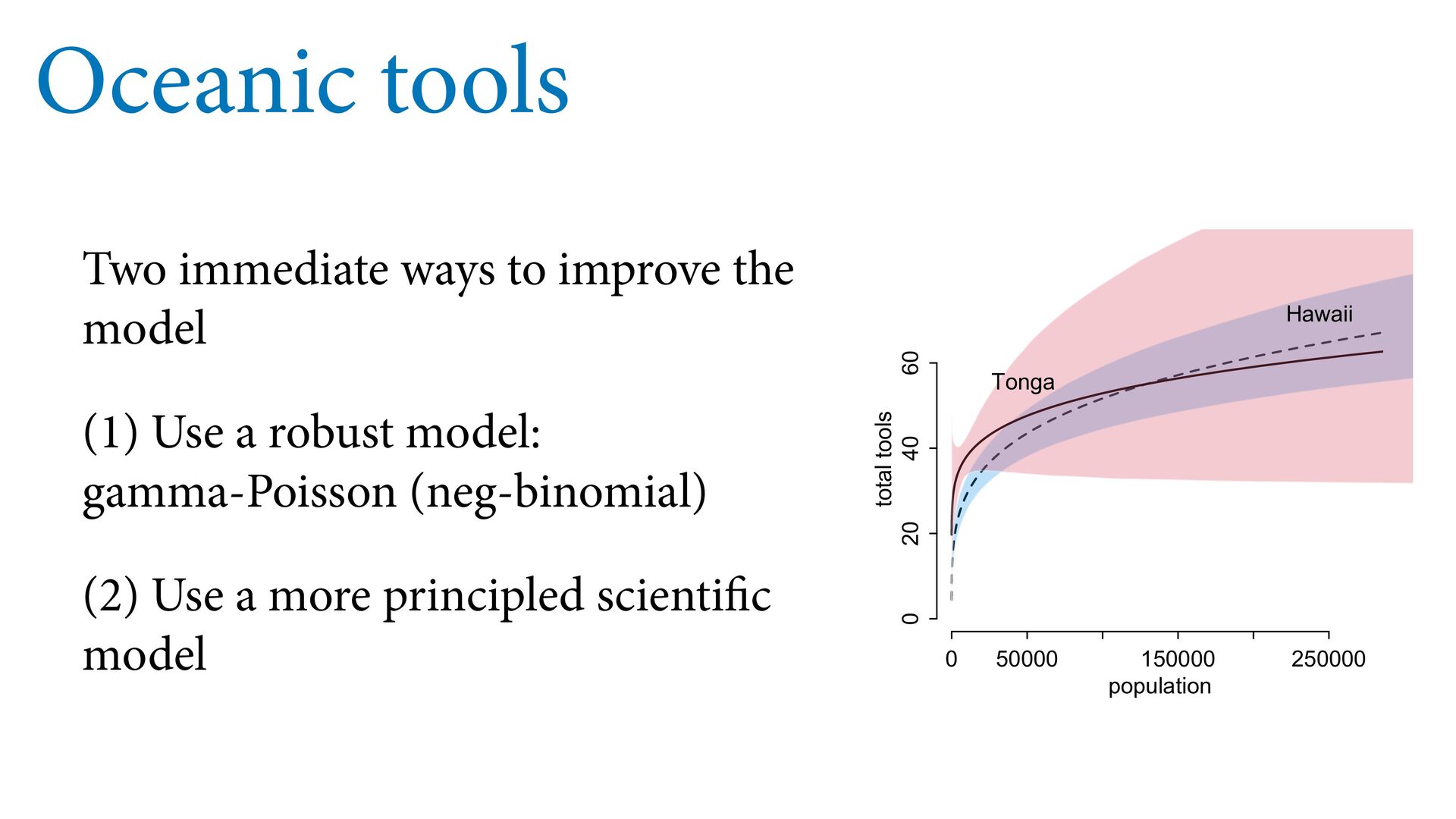
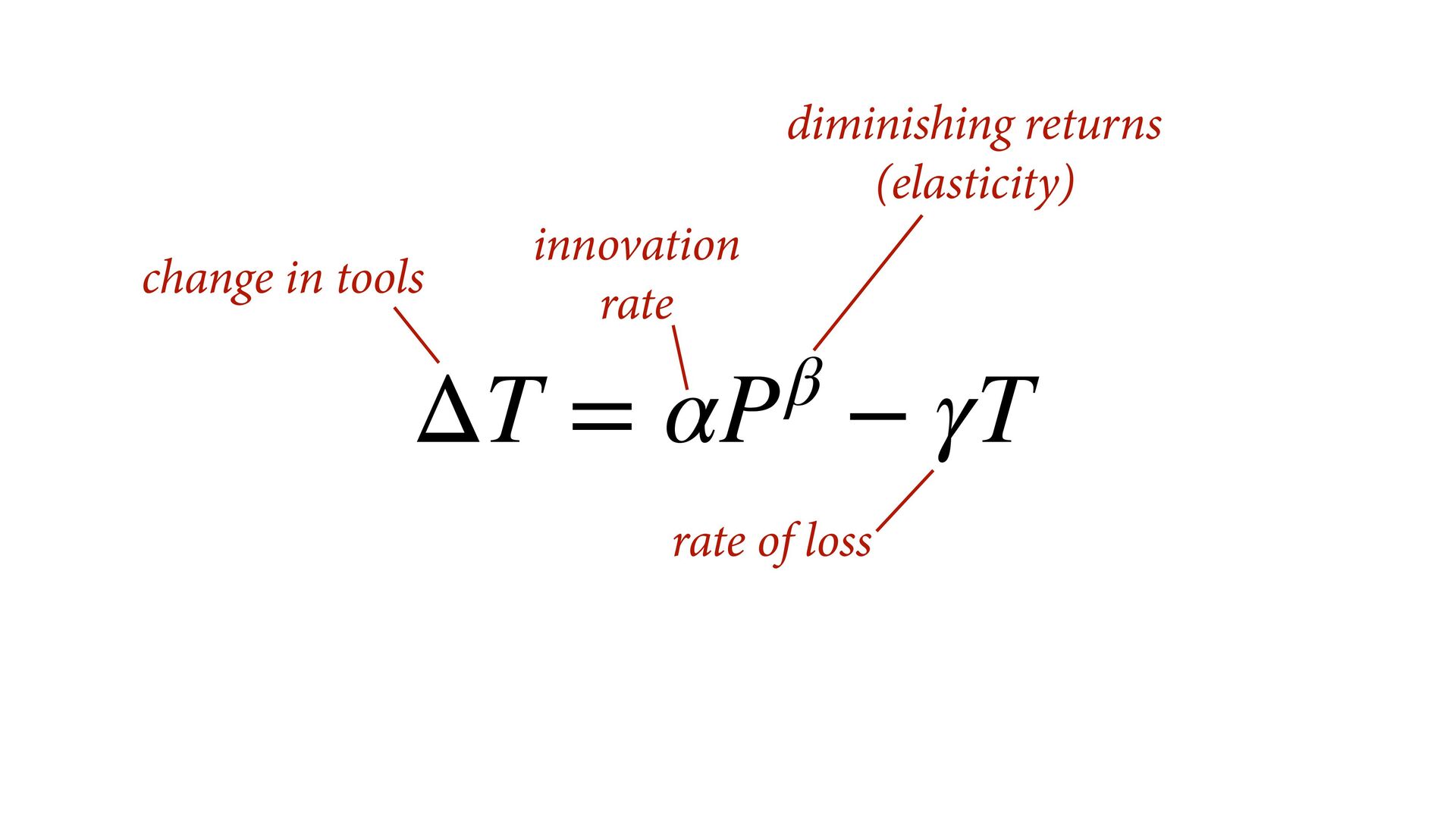
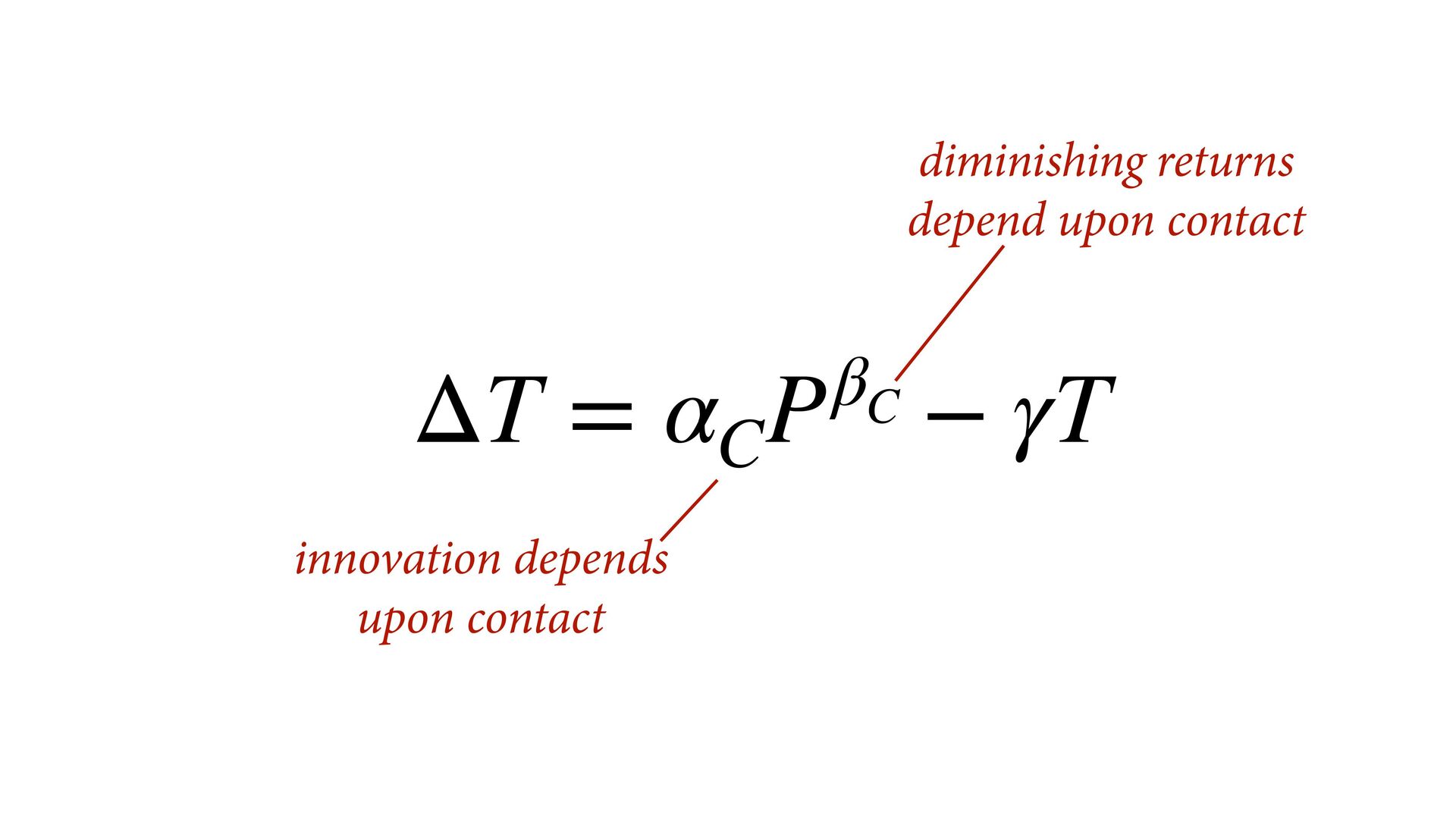
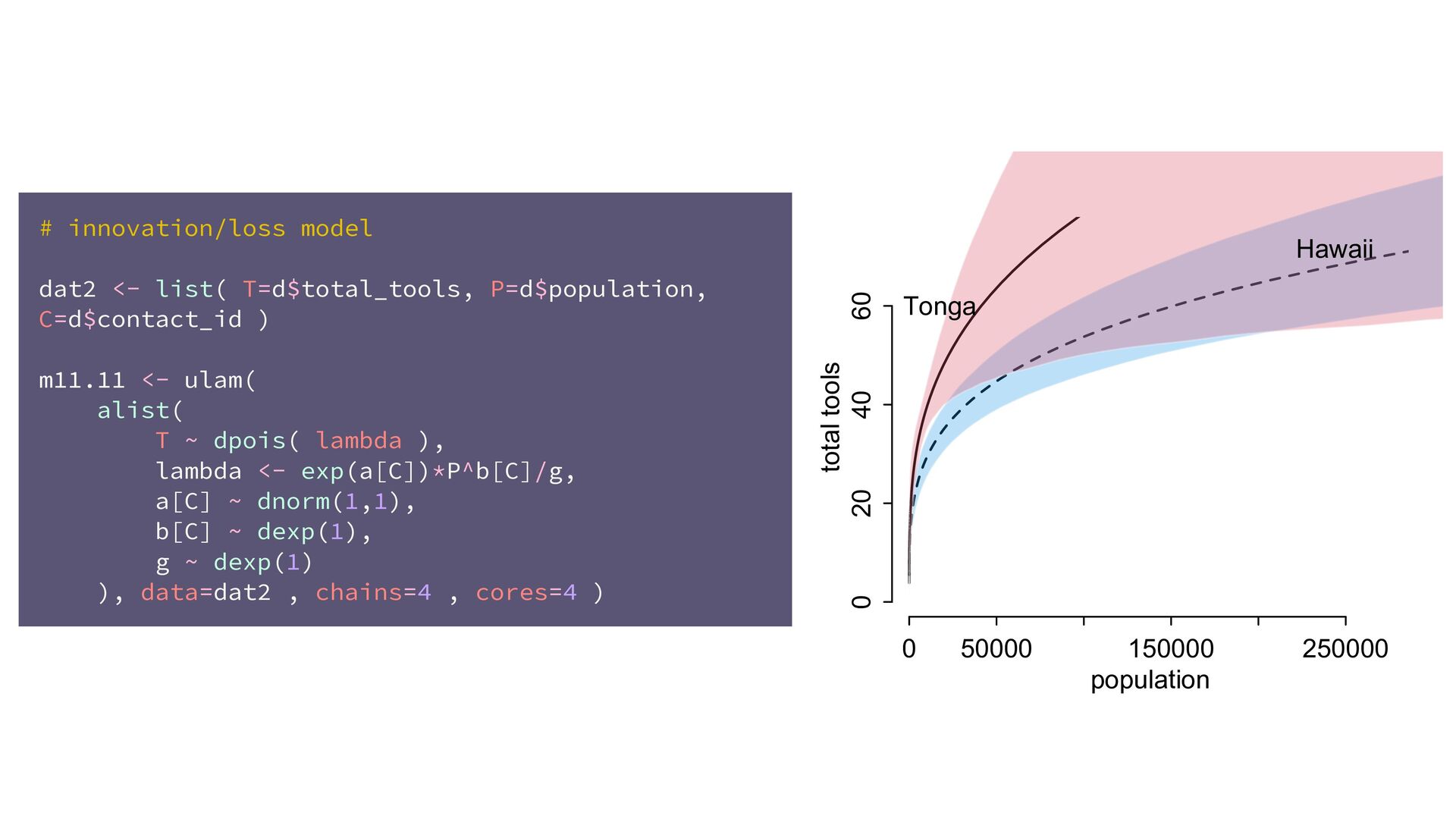
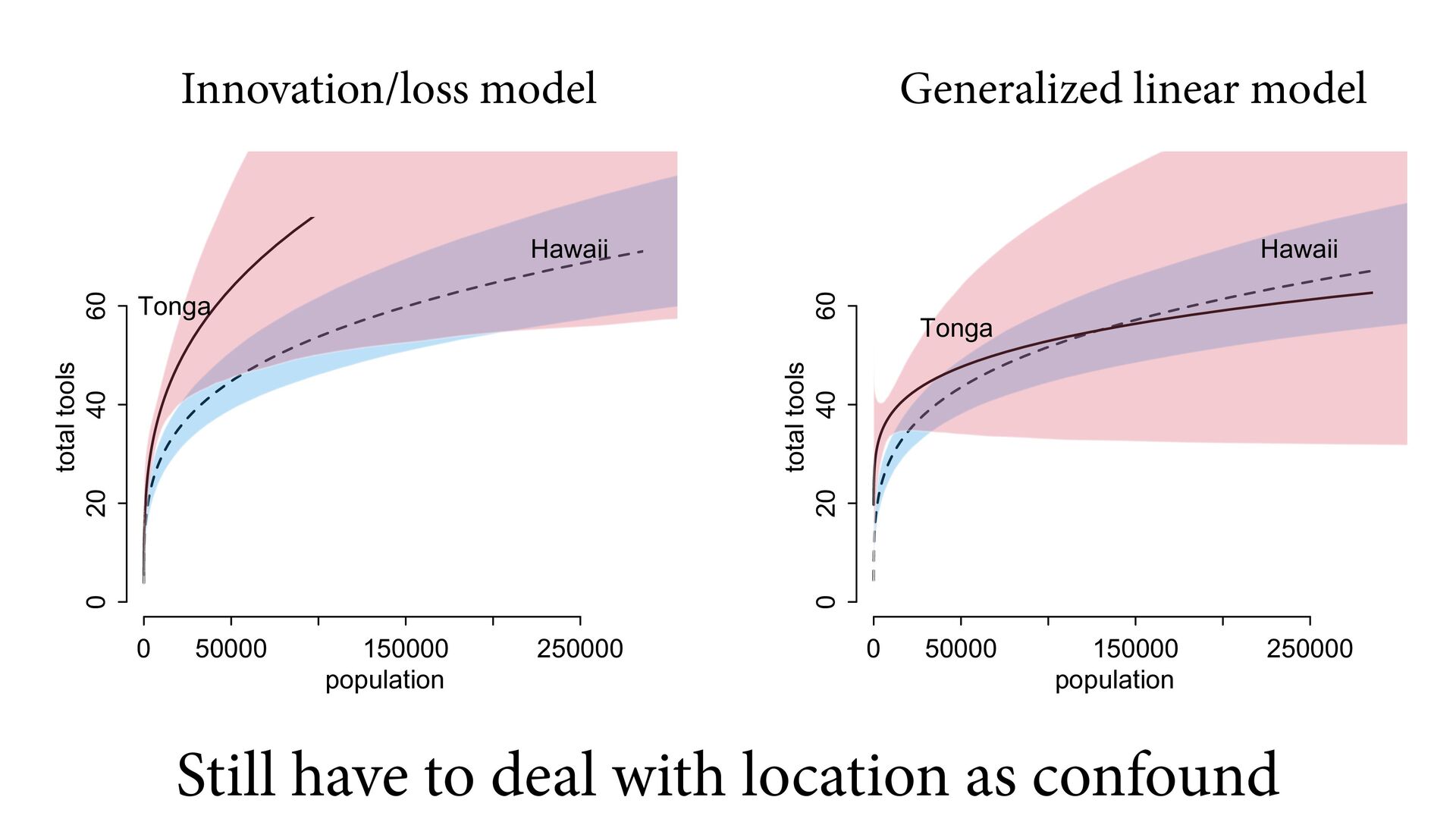
(std) total tools Yap Trobriand Tonga Hawaii k <- PSIS( m11.10 , pointwise=TRUE )$k plot( dat$P , dat$T , xlab="log population (std)" , ylab="total tools" , col=ifelse( dat$C==1 , 4 , 2 ) , lwd=4+4*normalize(k) , ylim=c(0,75) , cex=1+normalize(k) ) # set up the horizontal axis values to compute predictions at P_seq <- seq( from=-1.4 , to=3 , len=100 ) # predictions for C=1 (low contact) lambda <- link( m11.10 , data=data.frame( P=P_seq , C=1 ) ) lmu <- apply( lambda , 2 , mean ) lci <- apply( lambda , 2 , PI ) lines( P_seq , lmu , lty=2 , lwd=1.5 ) shade( lci , P_seq , xpd=TRUE , col=col.alpha(4,0.3) ) # predictions for C=2 (high contact) lambda <- link( m11.10 , data=data.frame( P=P_seq , C=2 ) ) lmu <- apply( lambda , 2 , mean ) lci <- apply( lambda , 2 , PI ) lines( P_seq , lmu , lty=1 , lwd=1.5 ) shade( lci , P_seq , xpd=TRUE , col=col.alpha(2,0.3)) Points scaled by leverage
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
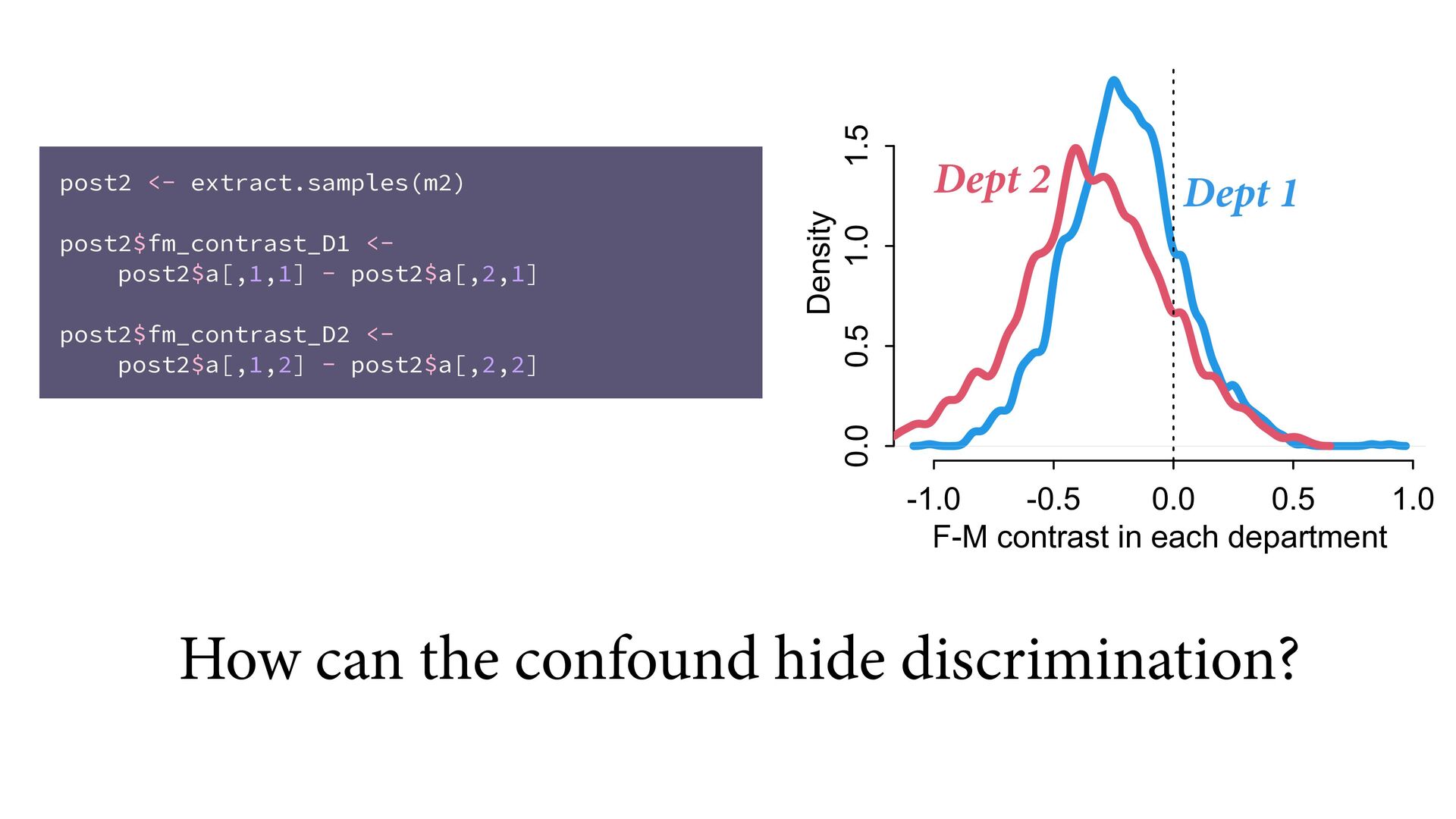{kind=link}
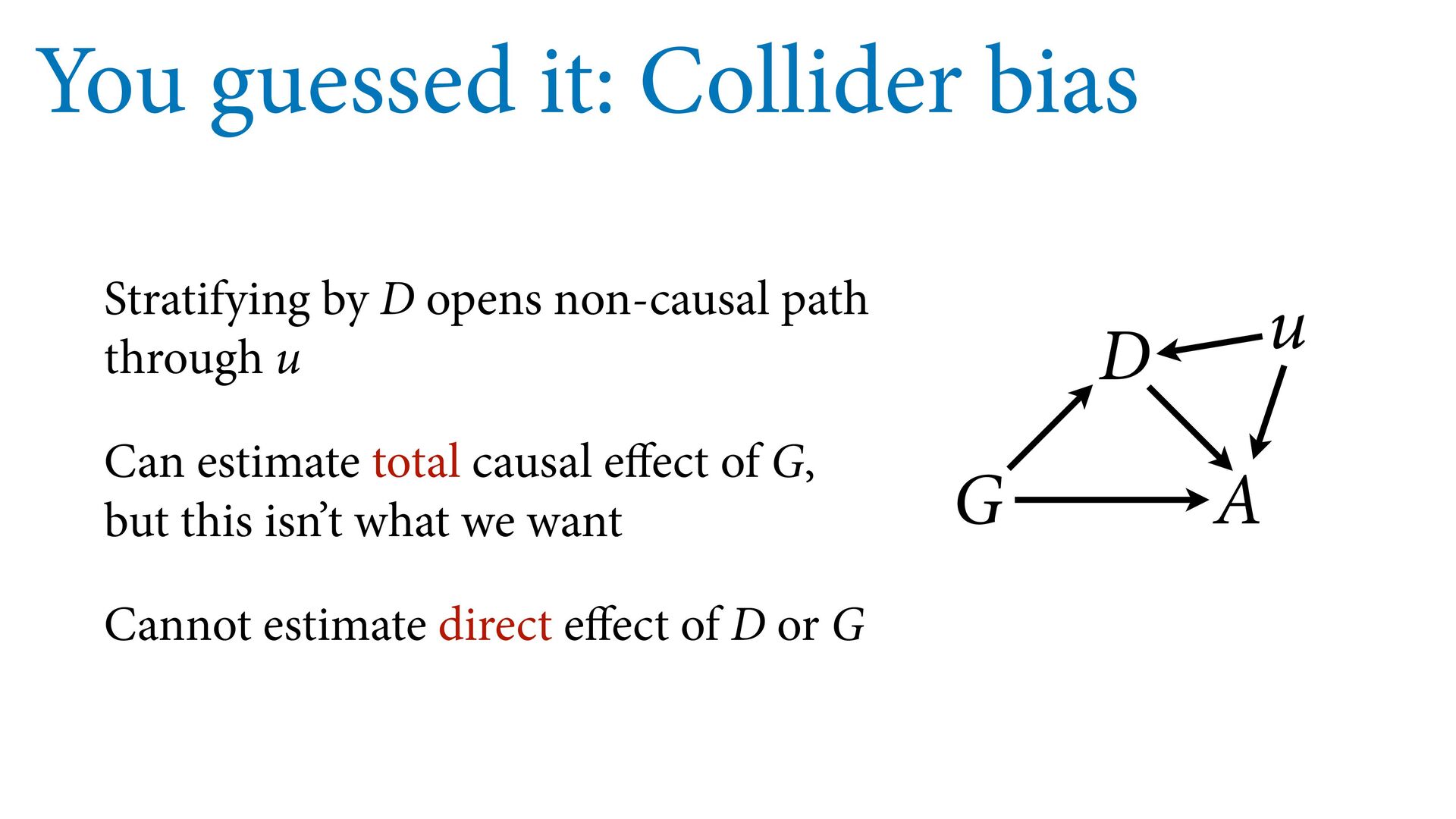{kind=link}
{kind=link}
{kind=link}
{kind=link}
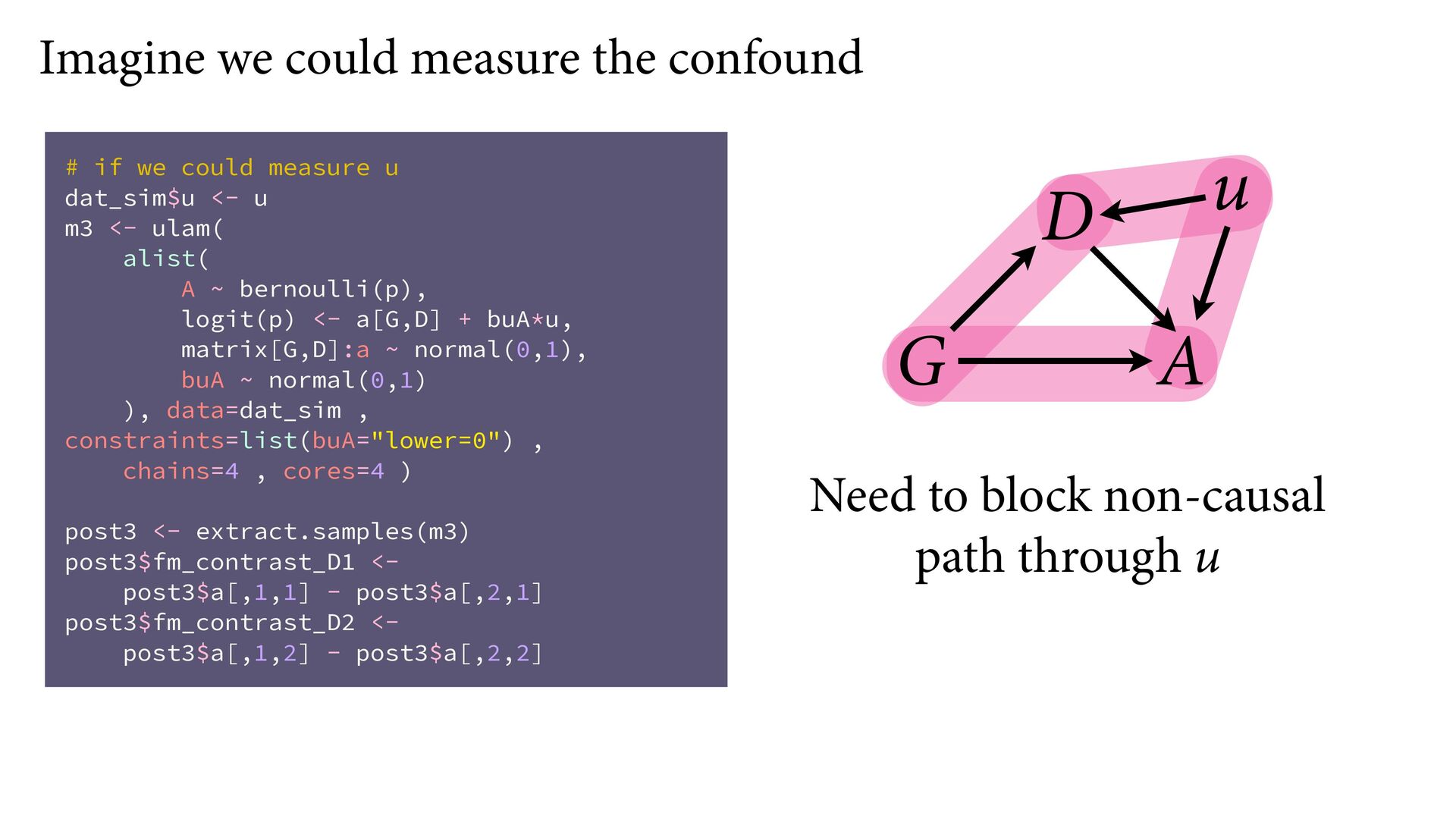{kind=link}
{kind=link}
{kind=link}
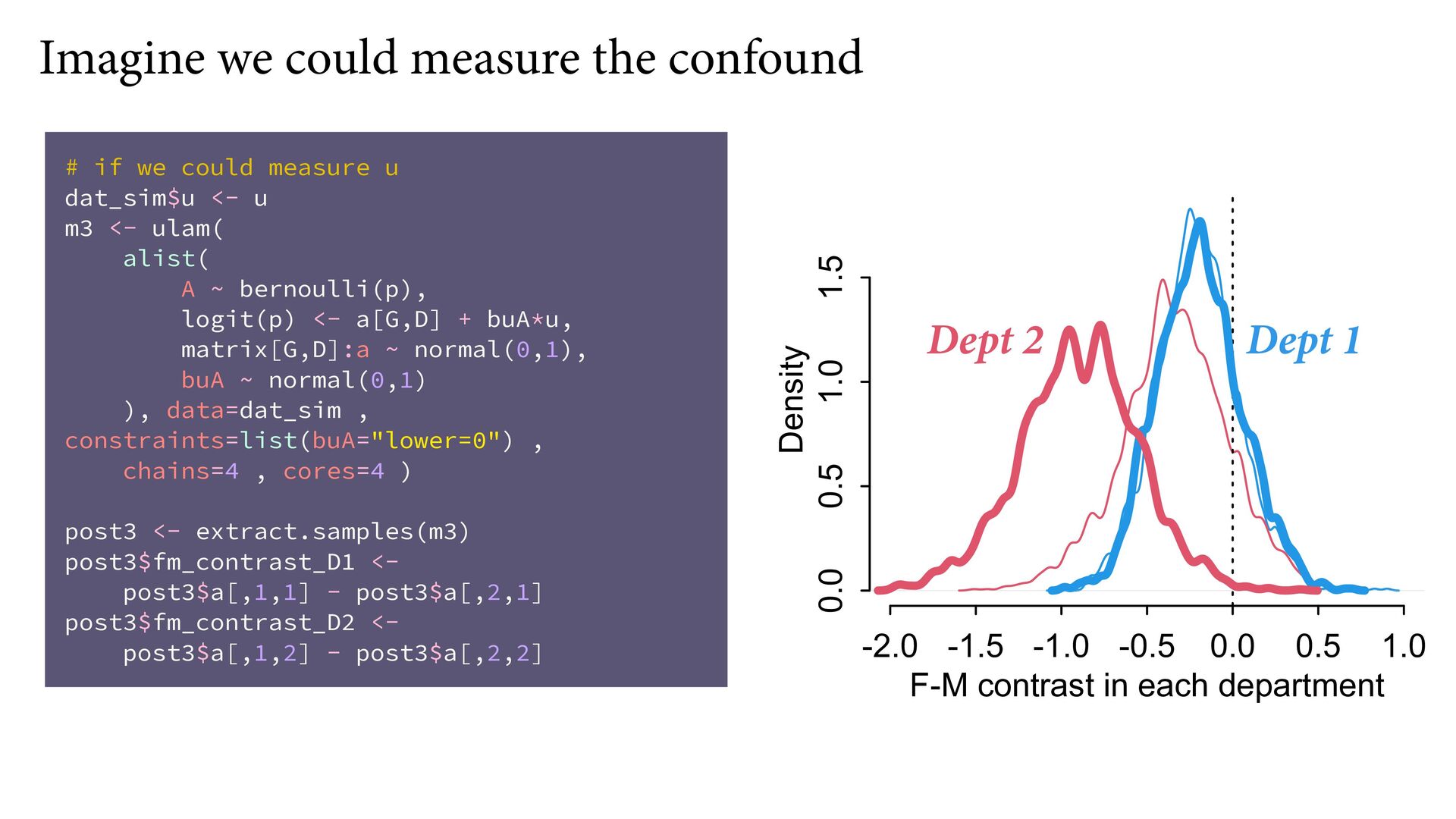{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
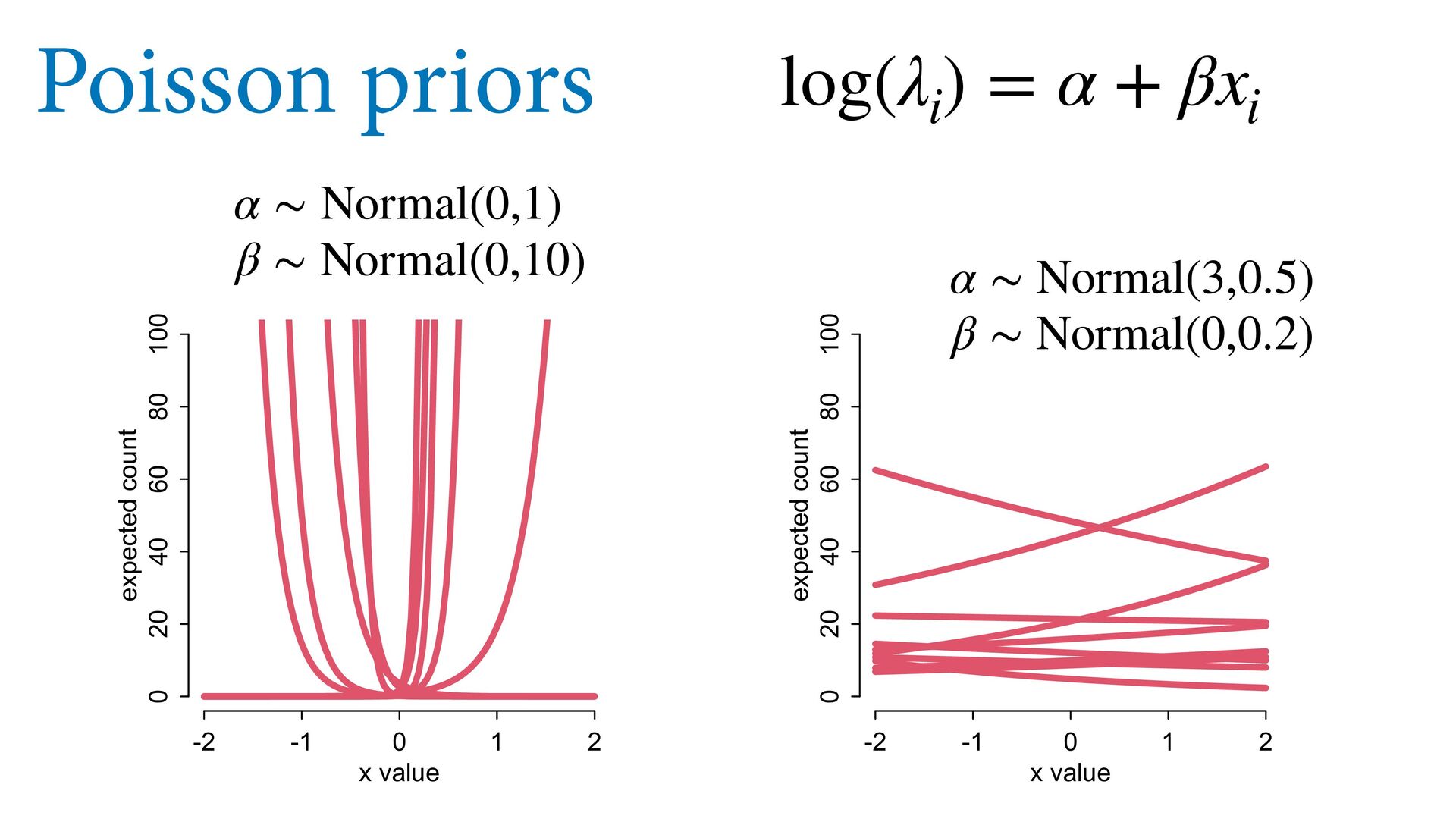{kind=link}
{kind=link}
{kind=link}
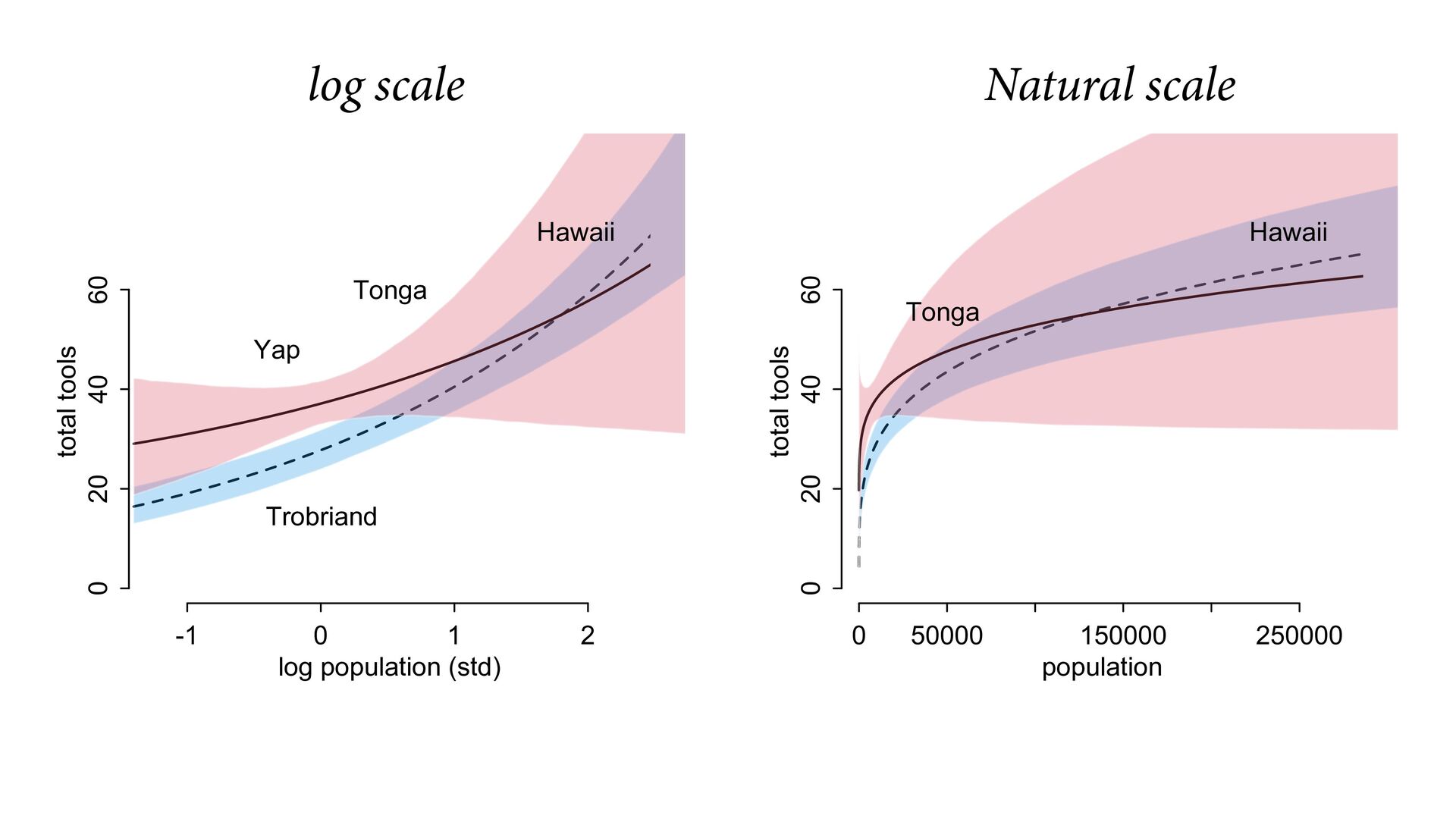
{kind=link}
{kind=link}
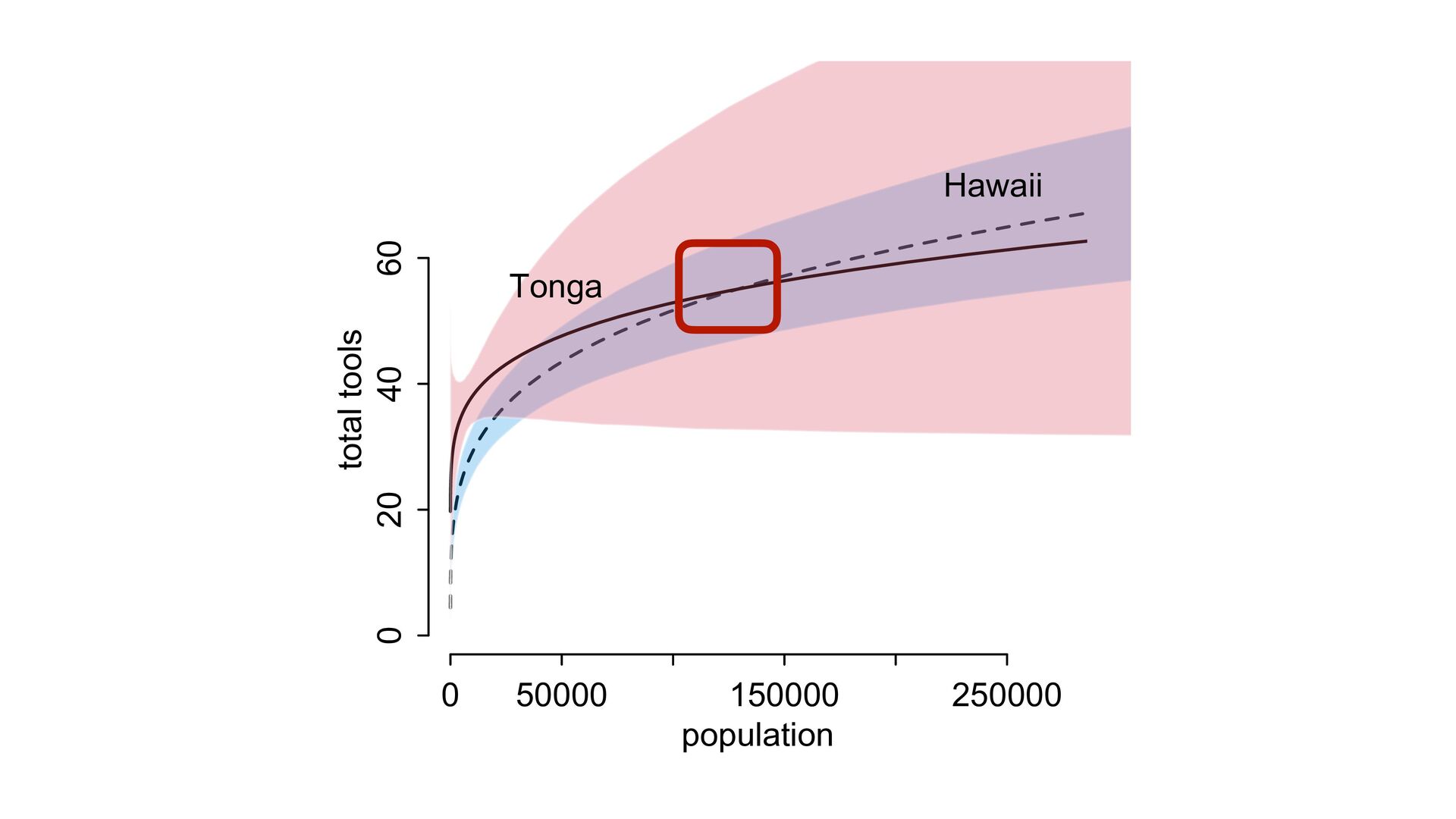{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
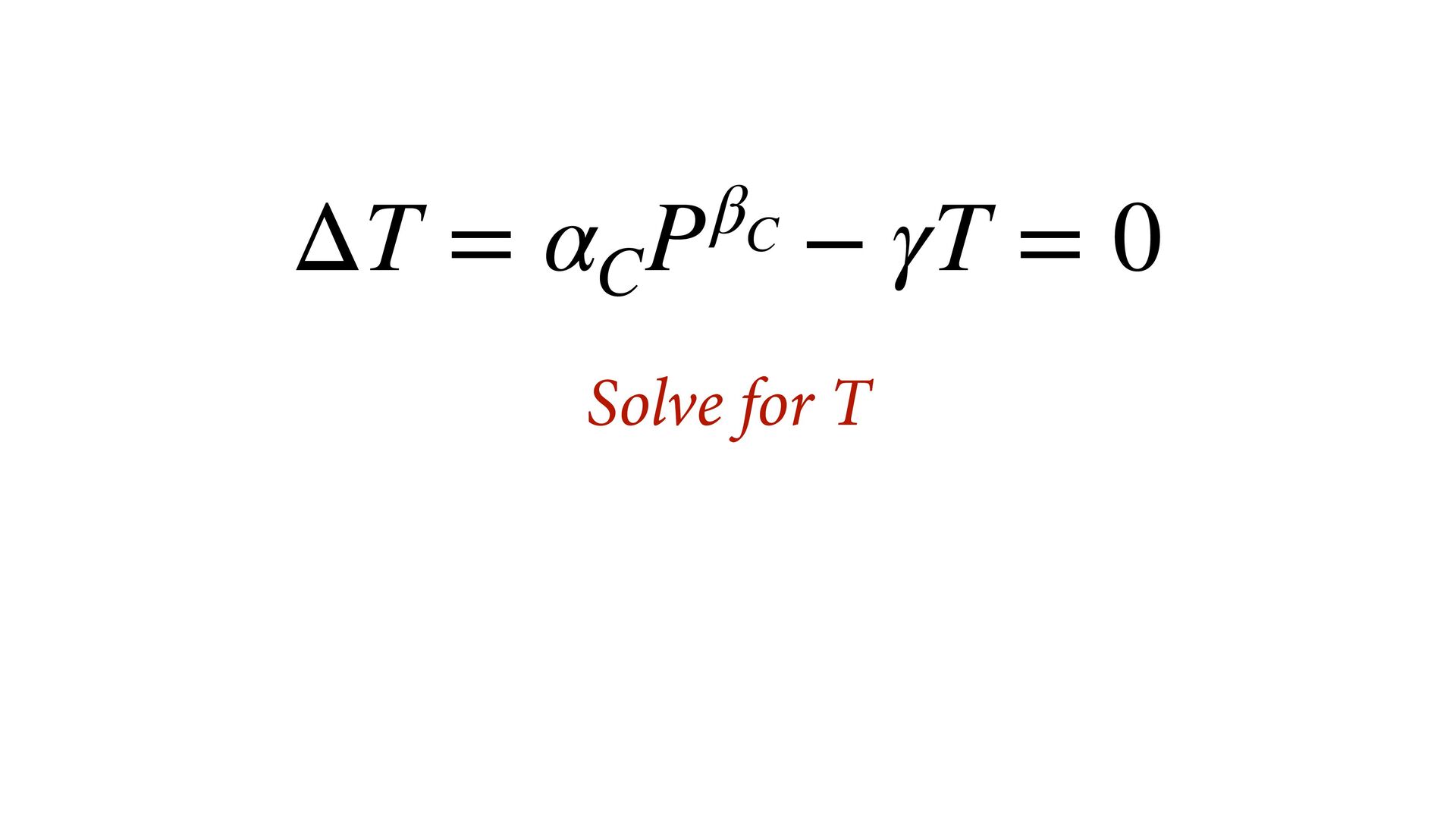{kind=link}
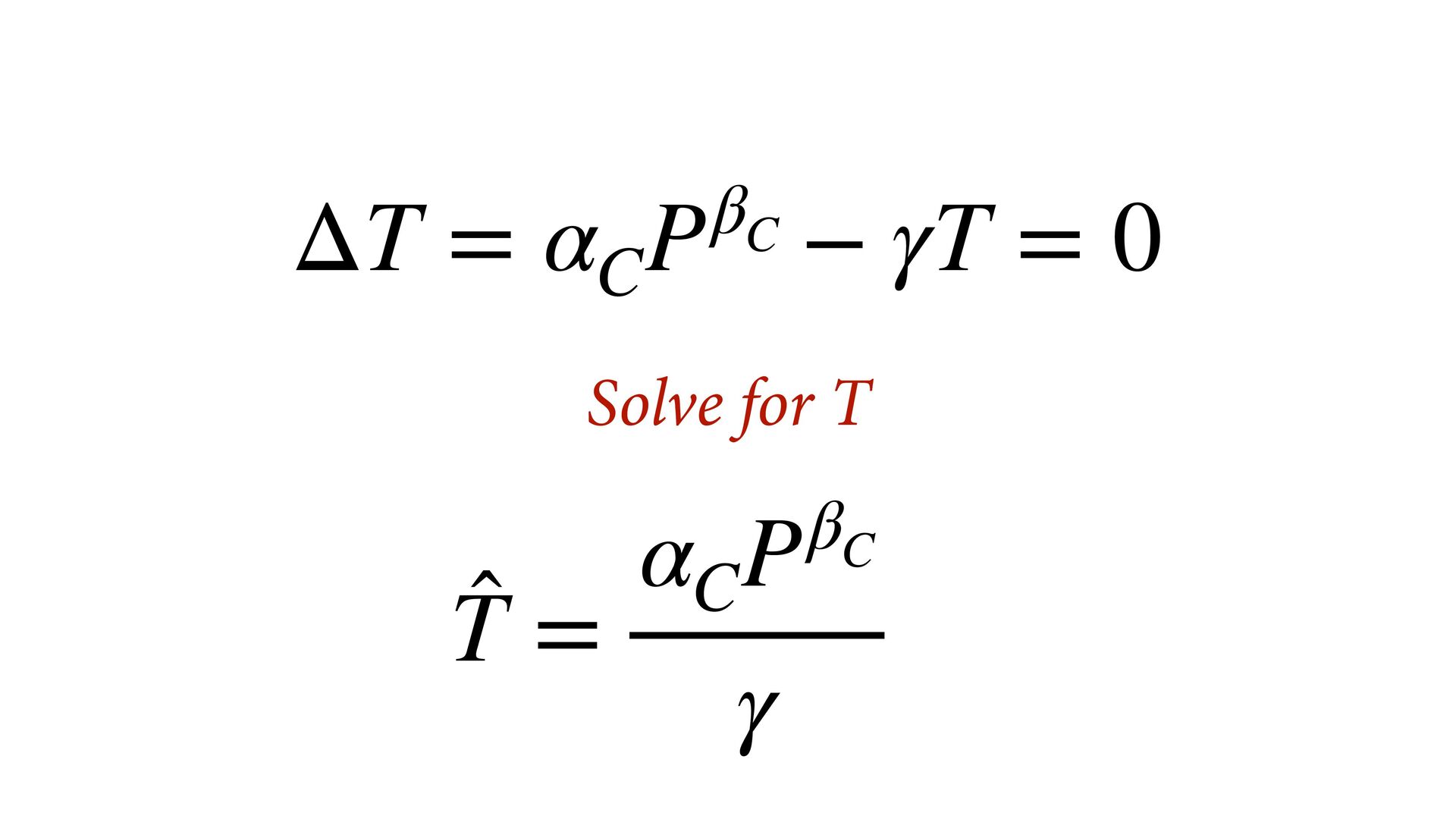{kind=link}
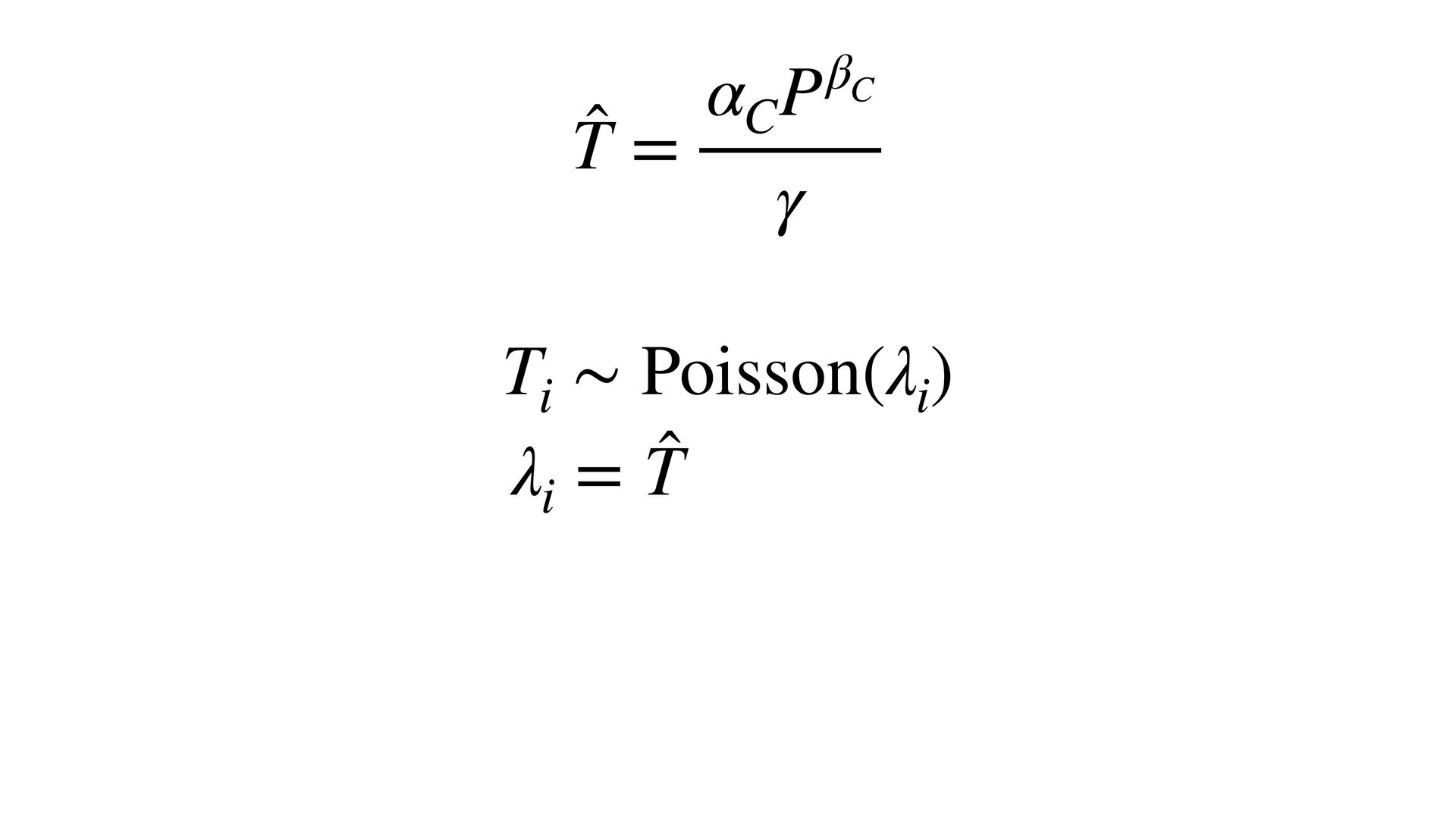{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}