be useful Struggle against causation: How to use causal assumptions to design estimators, contrast alternative models Struggle against data: How to make the estimators work X Y Z B A C
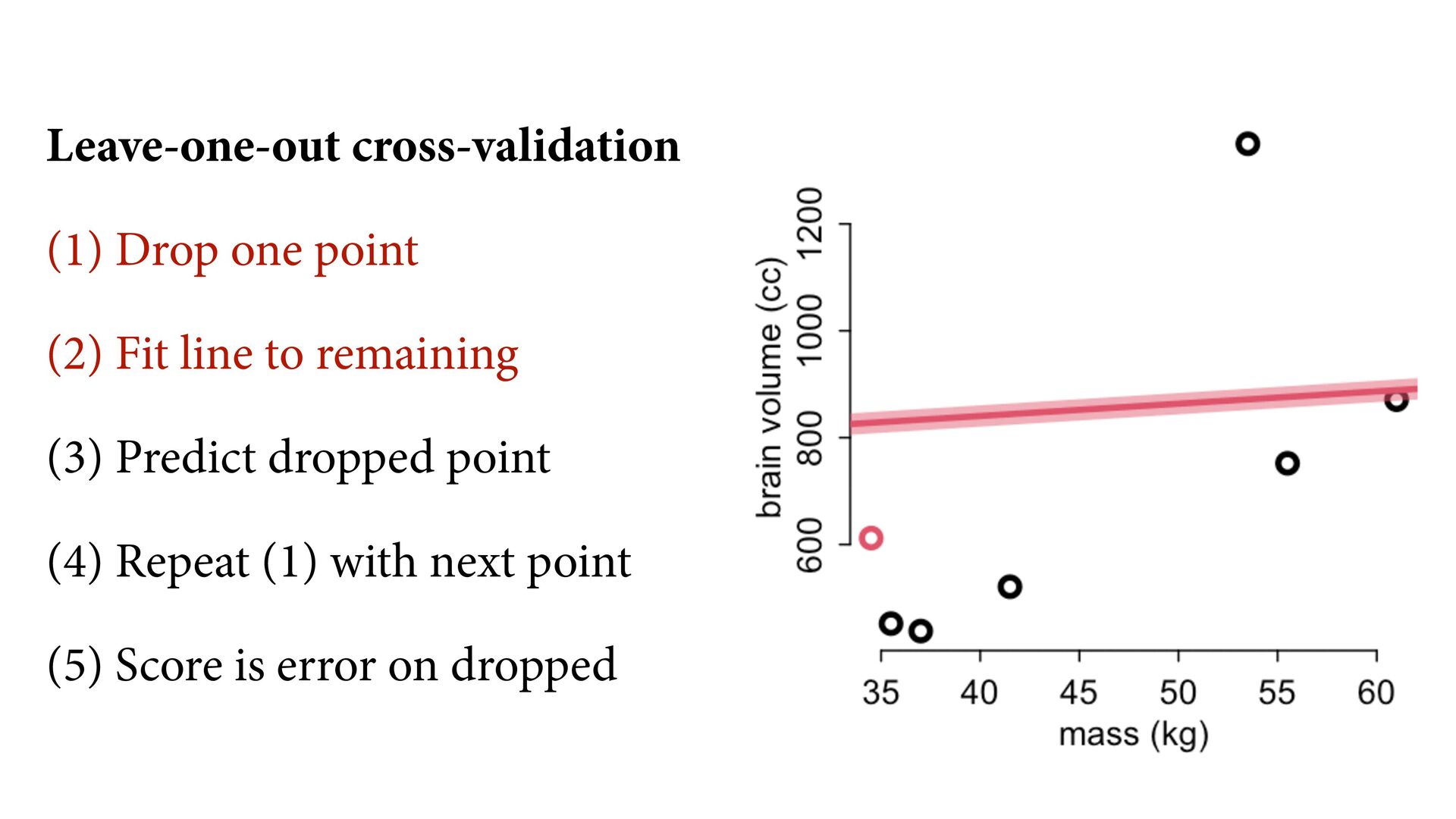
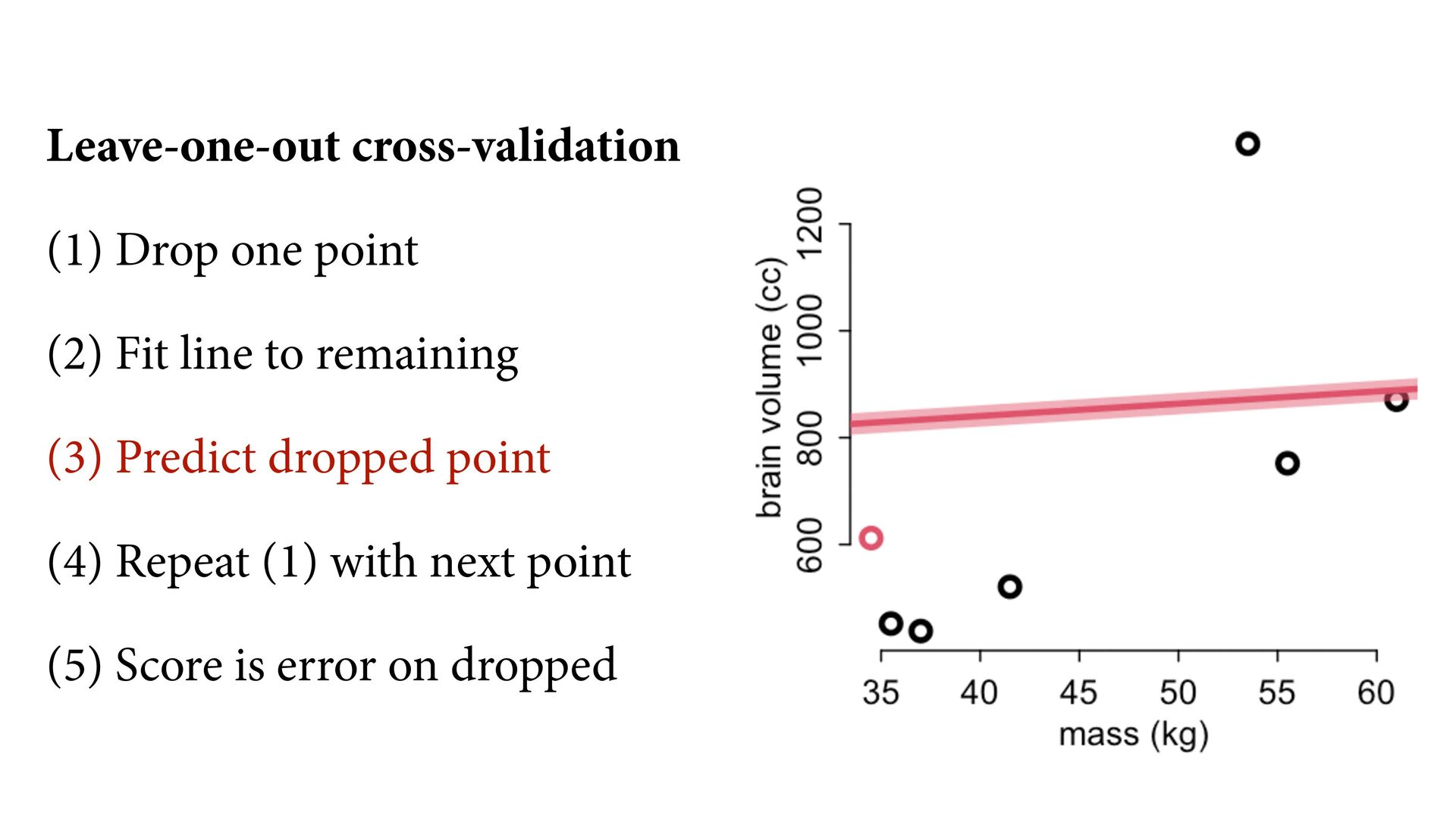
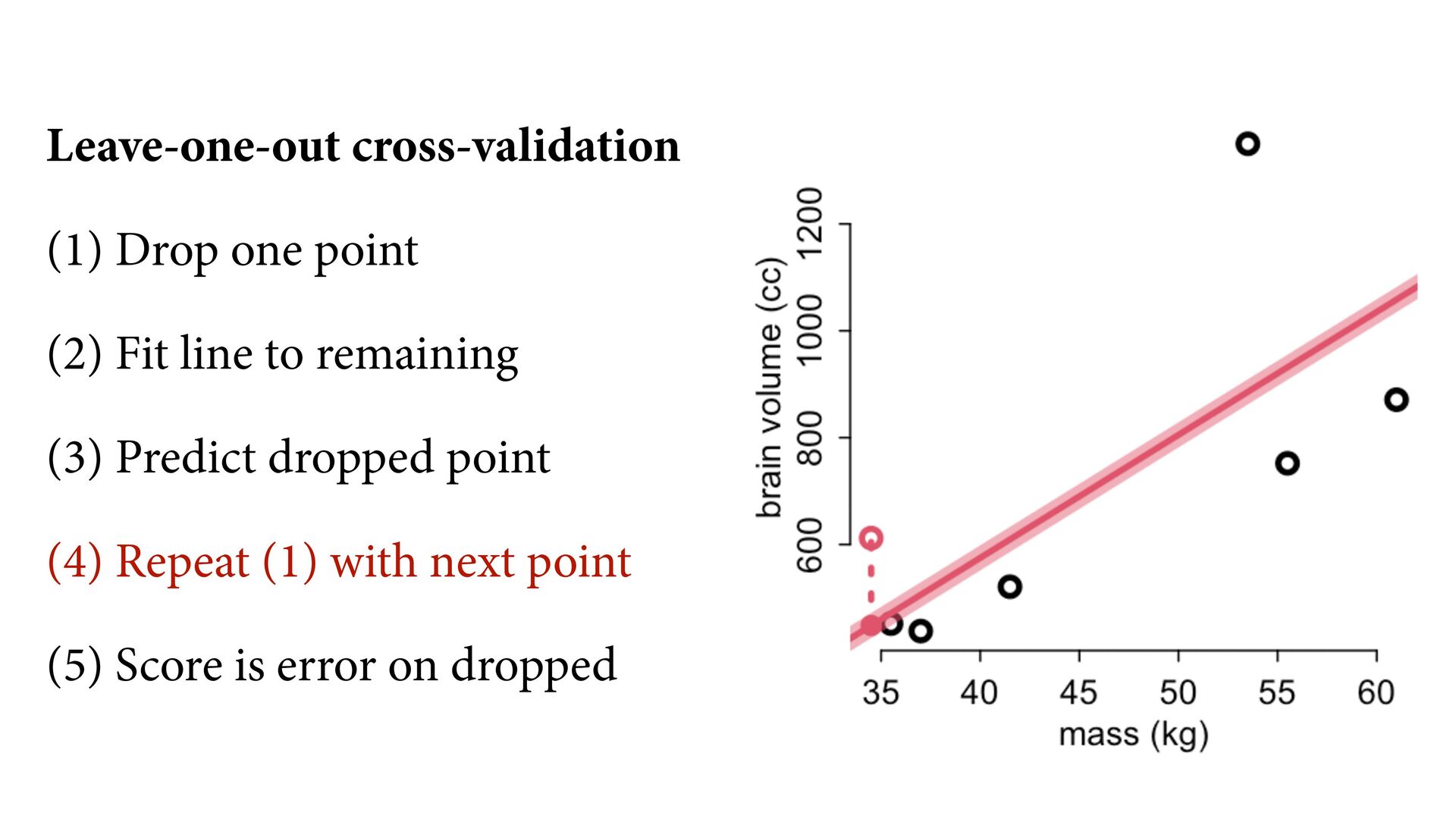
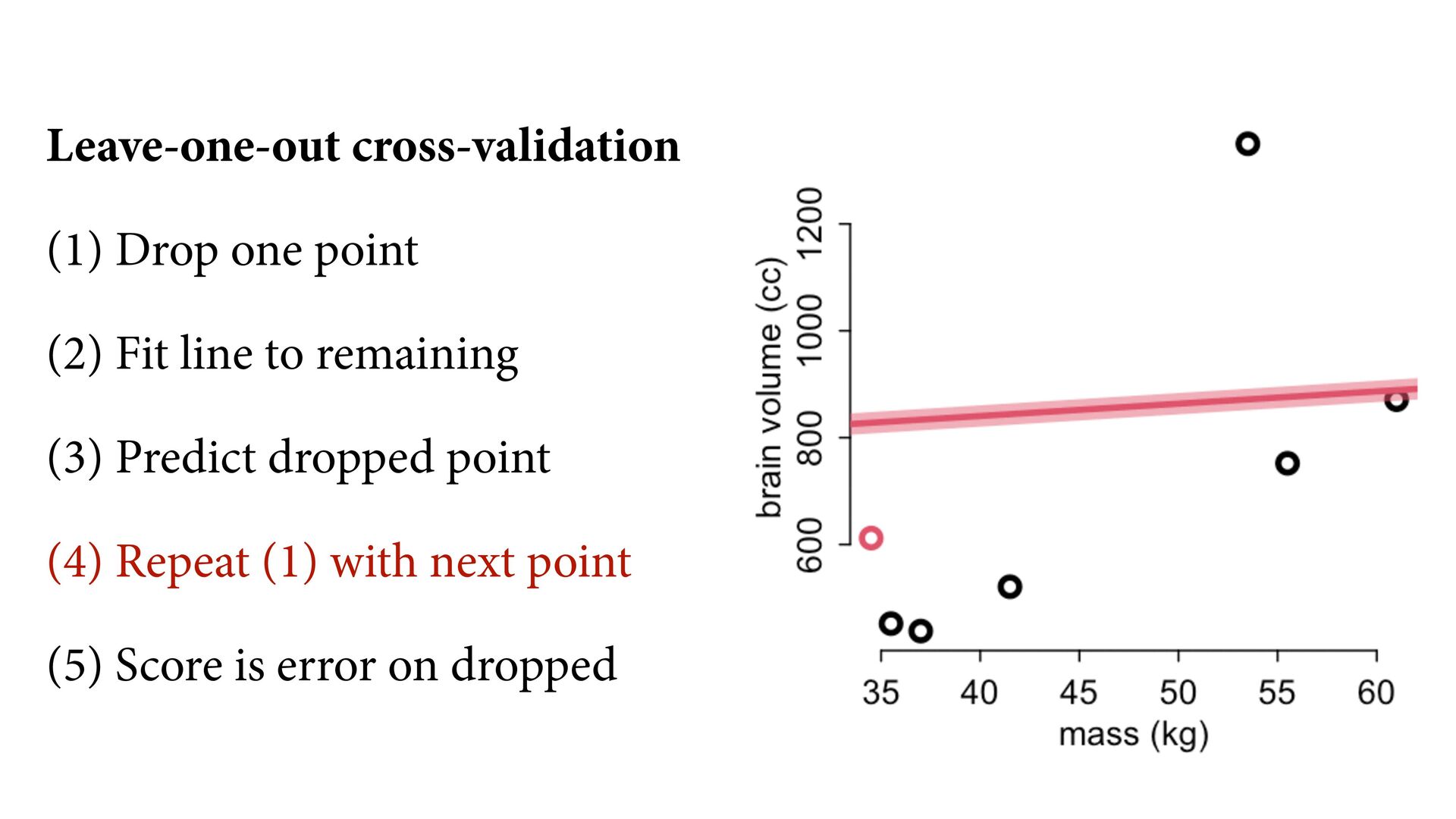
compression) What function explains these points? (causal inference) What would happen if we changed a point’s mass? (intervention) What is the next observation from the same process? (prediction) 35 40 45 50 55 60 600 800 1000 1200 mass (kg) brain volume (cc)
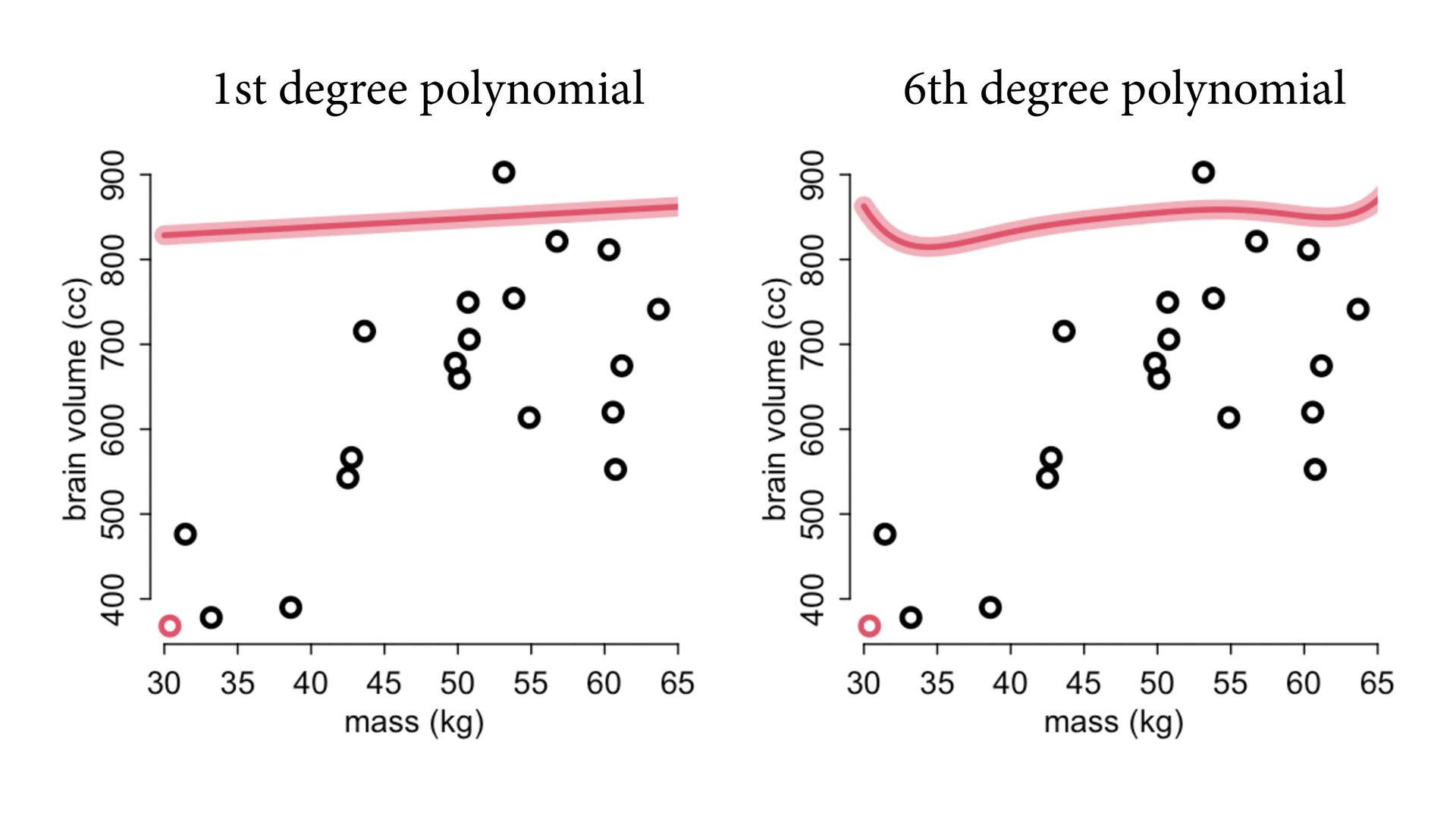
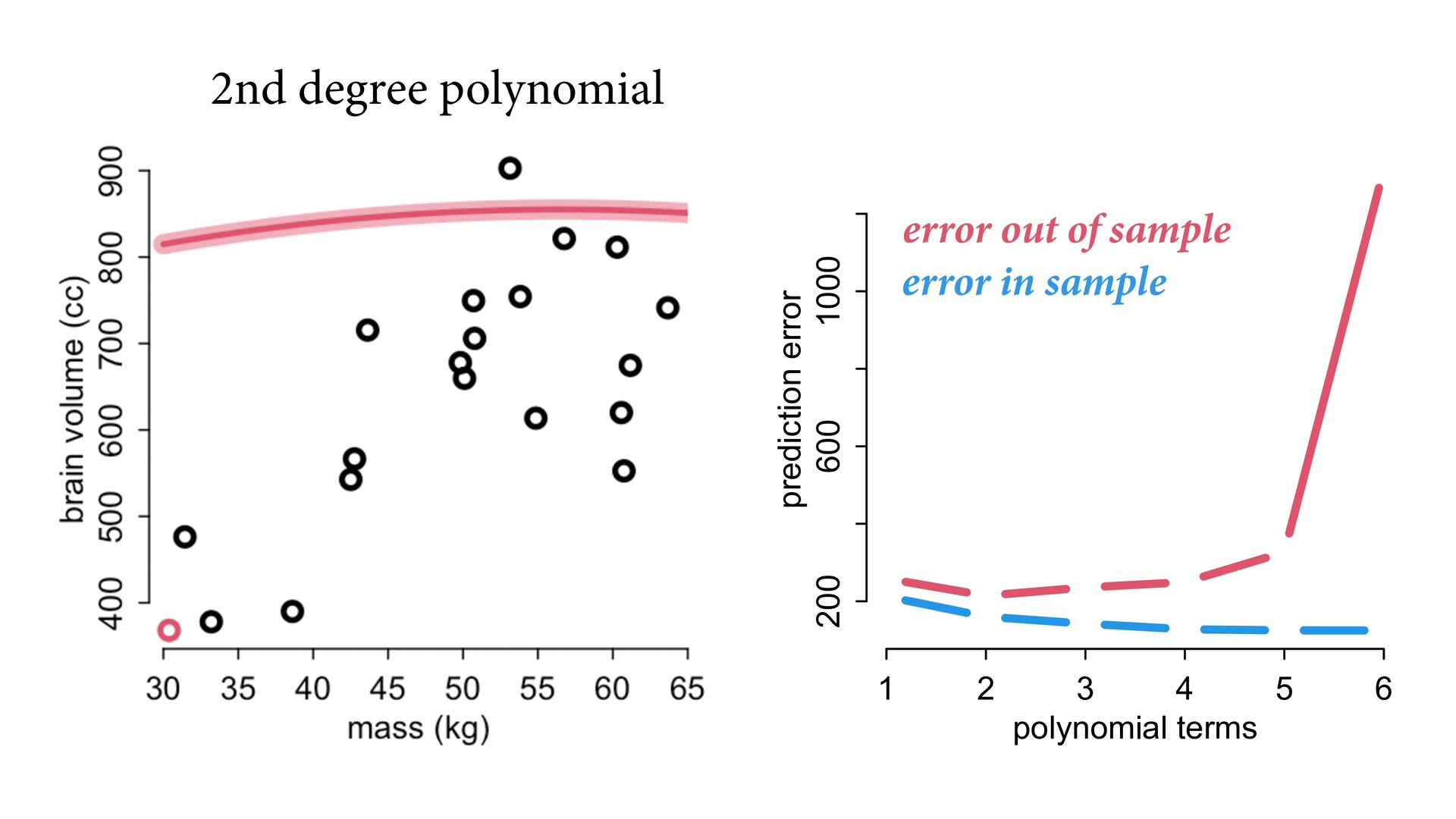
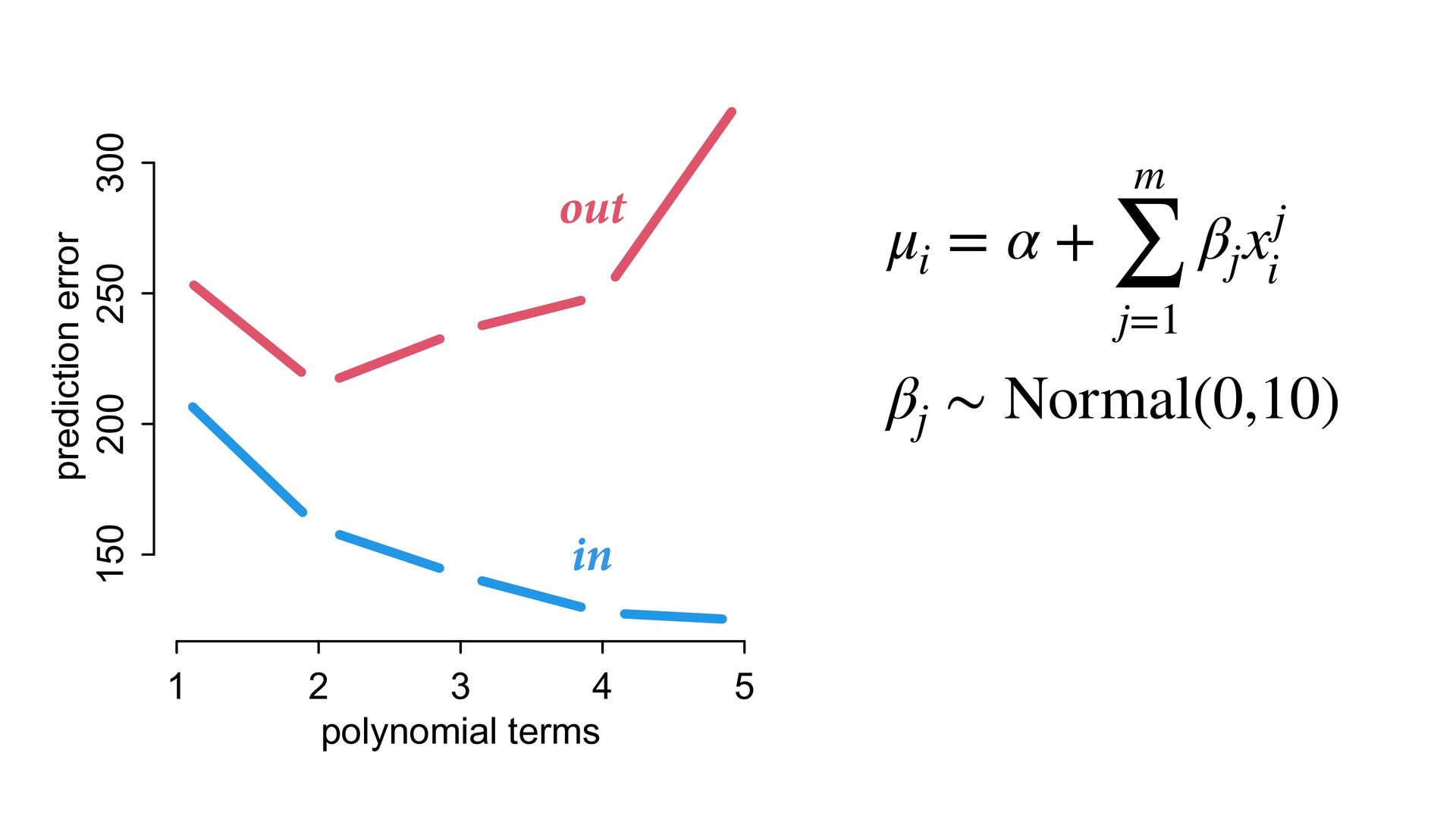
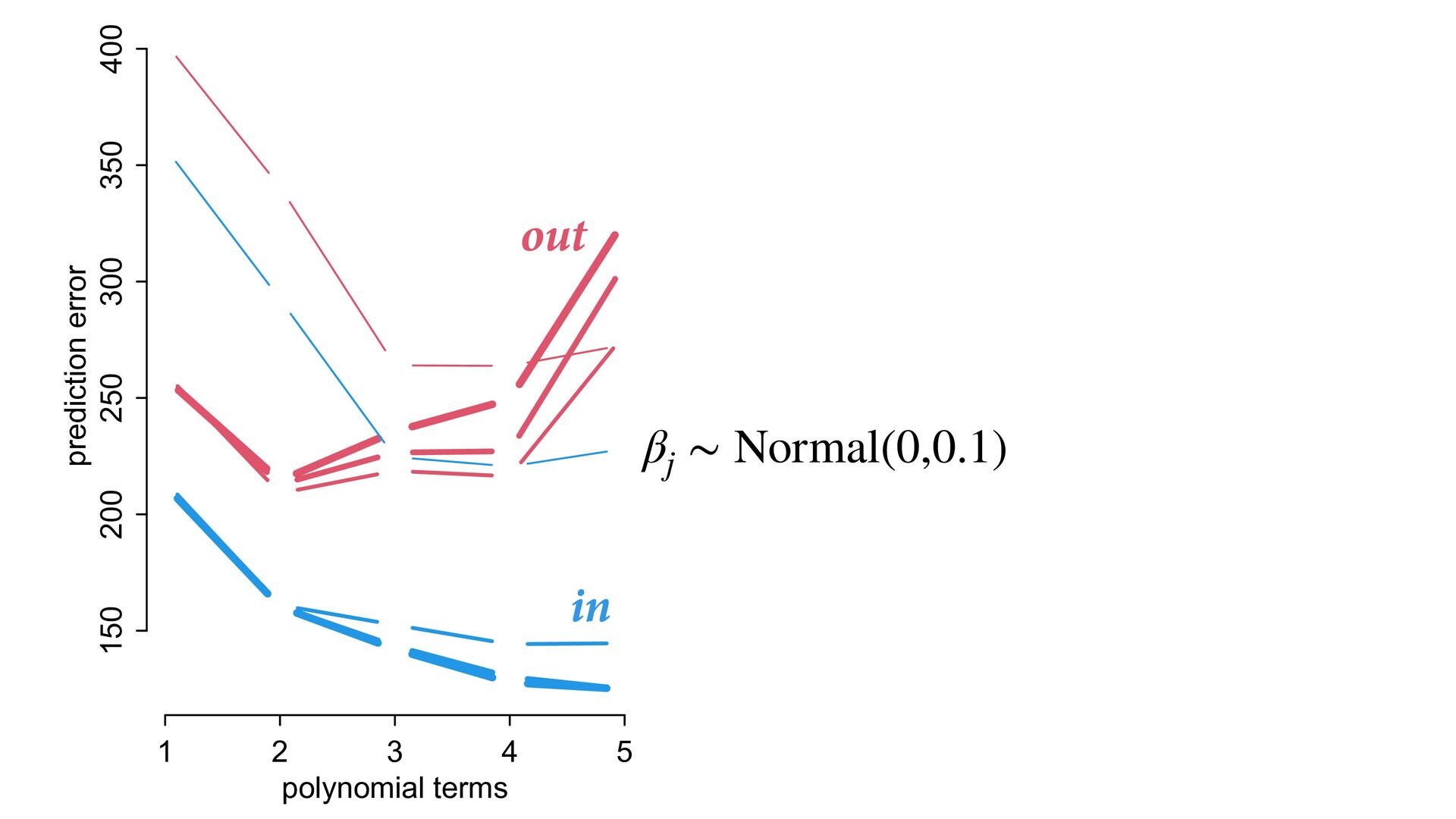
But may reduce accuracy of predictions out of sample Most accurate model trades o exibility with over tting 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 polynomial terms relative error error in sample error out of sample
inference, use science For pure prediction, can tune the prior using cross-validation Many tasks are a mix of inference and prediction No need to be perfect, just better
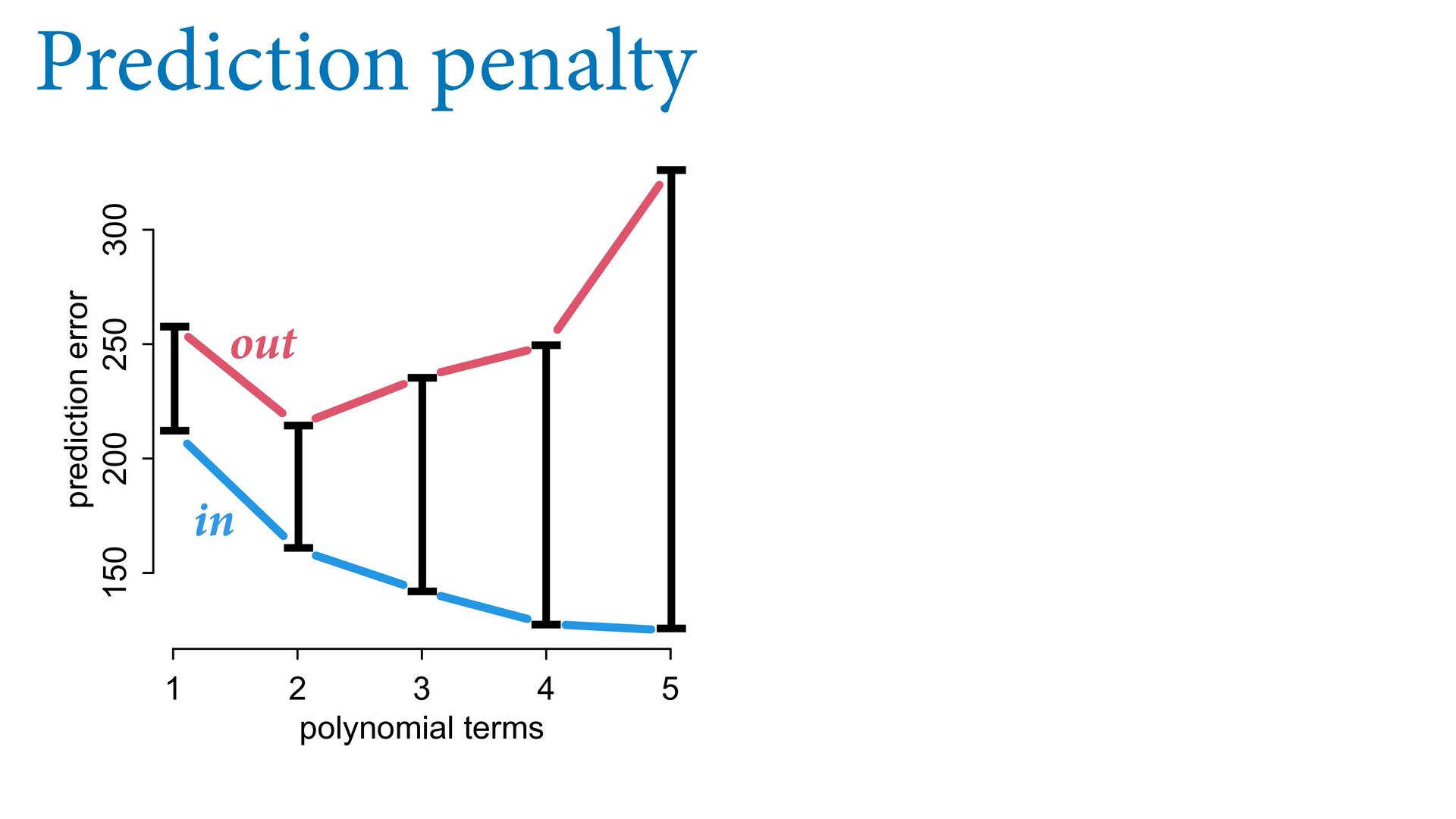
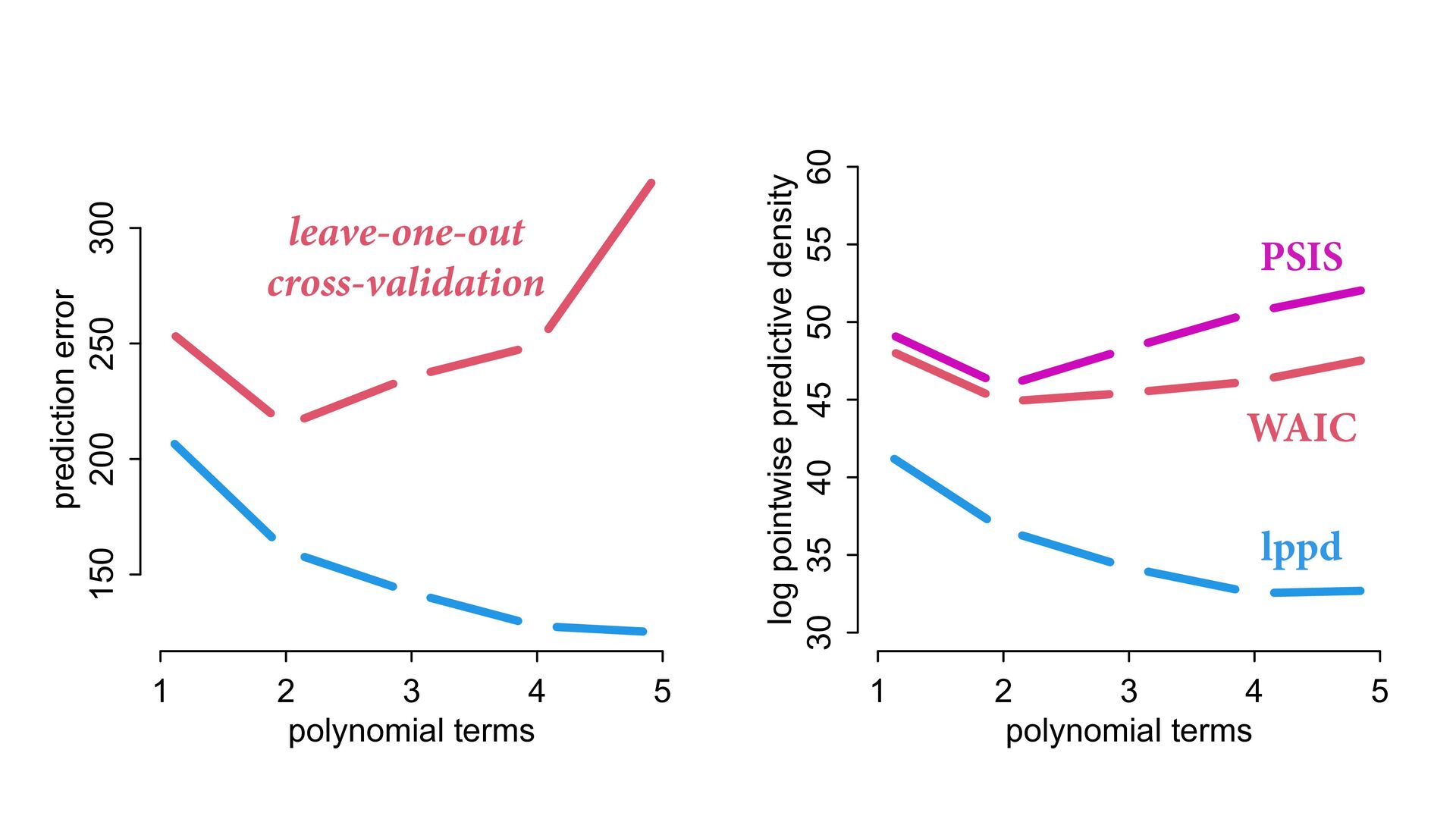
What if you could estimate the penalty from a single model t? Good news! You can: Importance sampling (PSIS) Information criteria (WAIC) 1 2 3 4 5 0 50 100 150 200 polynomial terms out-of-sample penalty
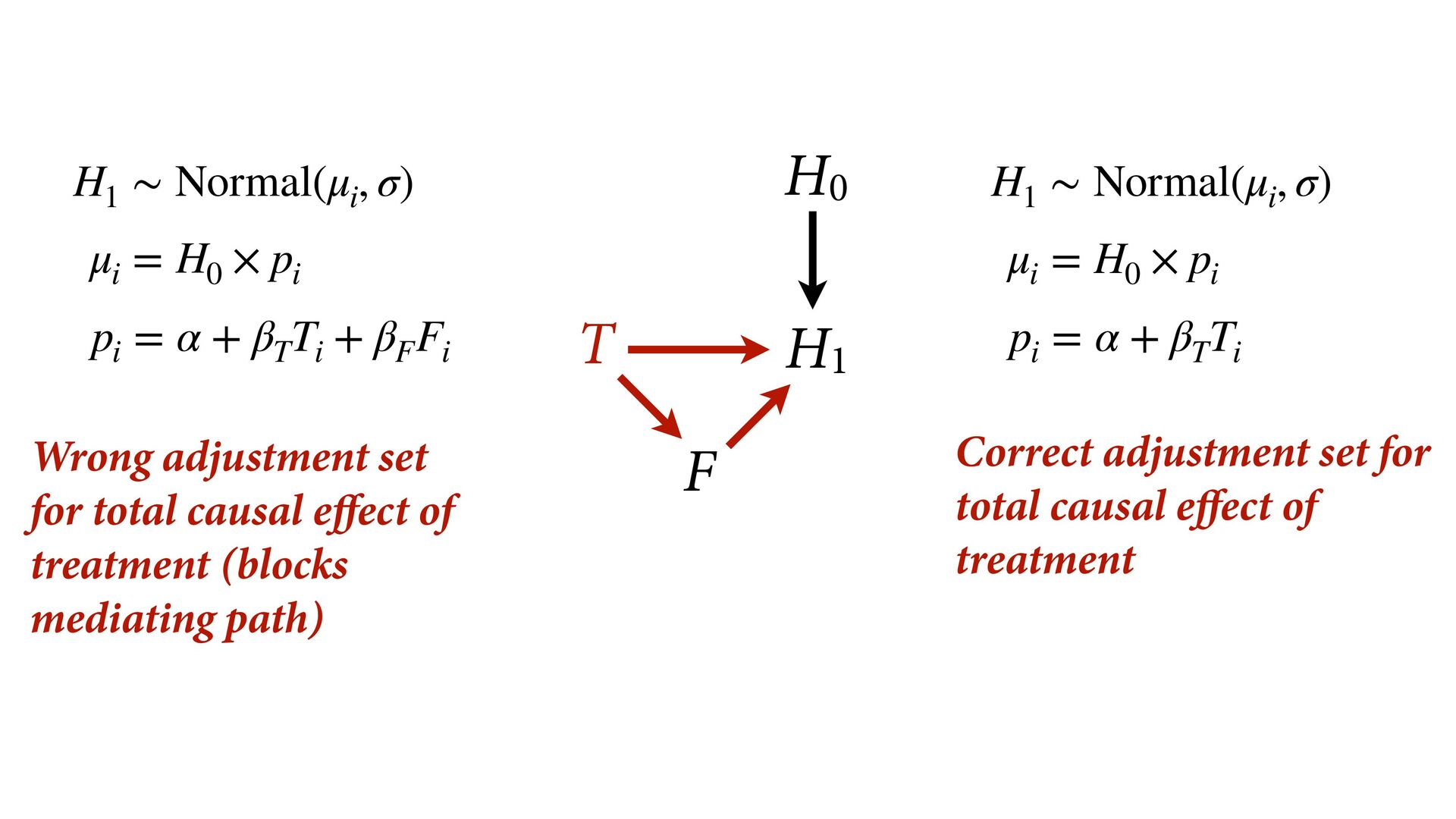
H 0 × p i p i = α + β T T i + β F F i H 1 ∼ Normal(μ i , σ) μ i = H 0 × p i p i = α + β T T i Wrong adjustment set for total causal e ect of treatment (blocks mediating path) Correct adjustment set for total causal e ect of treatment H0 H1 T F
H 0 × p i p i = α + β T T i + β F F i H 1 ∼ Normal(μ i , σ) μ i = H 0 × p i p i = α + β T T i -0.15 -0.10 -0.05 0.00 0.05 0.10 0.15 0.20 0 4 8 12 effect of treatment (posterior) Density correct biased
H 0 × p i p i = α + β T T i + β F F i H 1 ∼ Normal(μ i , σ) μ i = H 0 × p i p i = α + β T T i m6.8 m6.7 350 360 370 380 390 400 410 deviance PSIS H1 ~ H0 + T + F H1 ~ H0 + T Wrong model wins at prediction
PSIS H1 ~ H0 + T + F H1 ~ H0 + T Wrong model wins at prediction Score in sample Score out of sample Standard error of score PSIS contrast and standard error
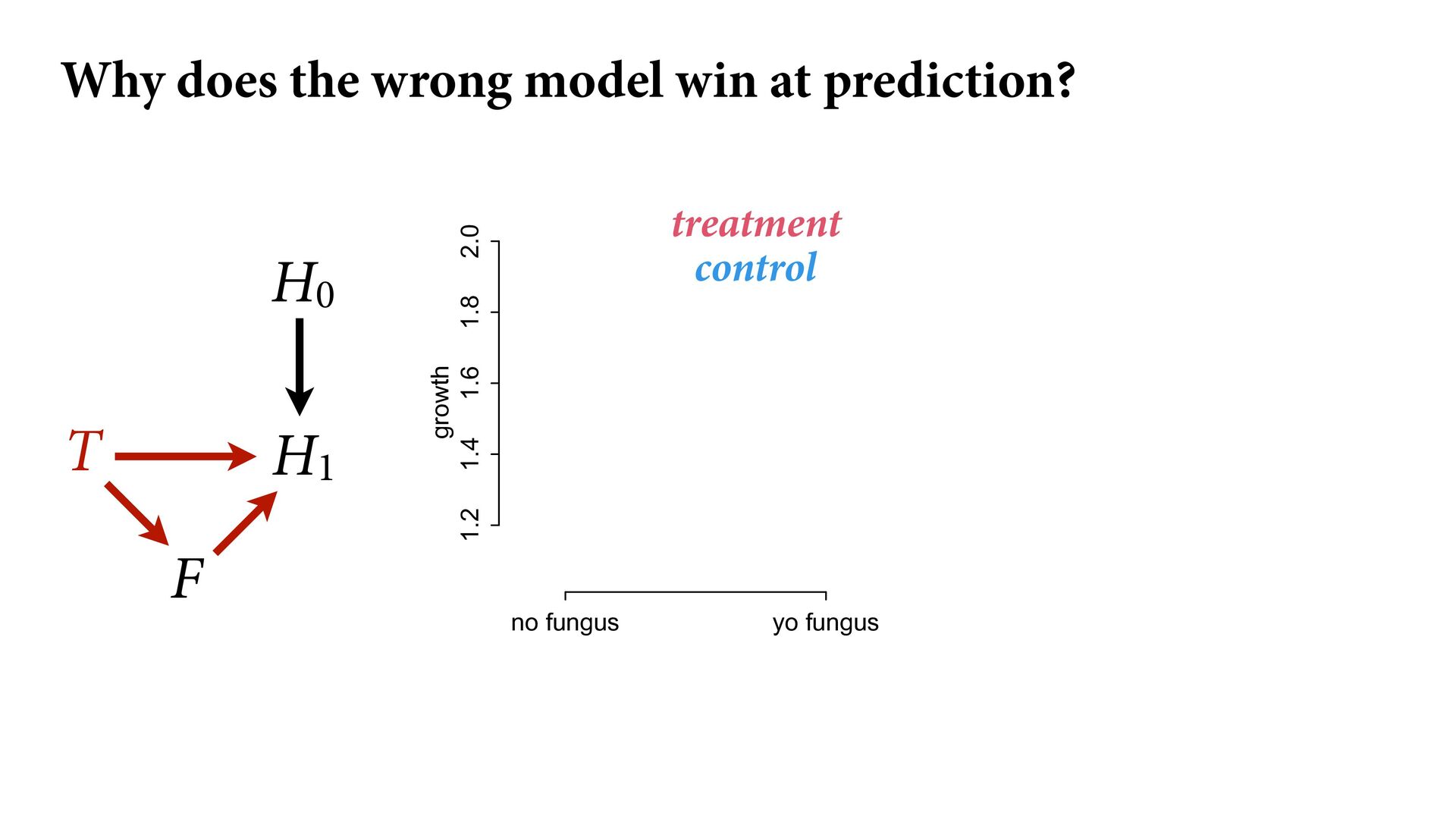
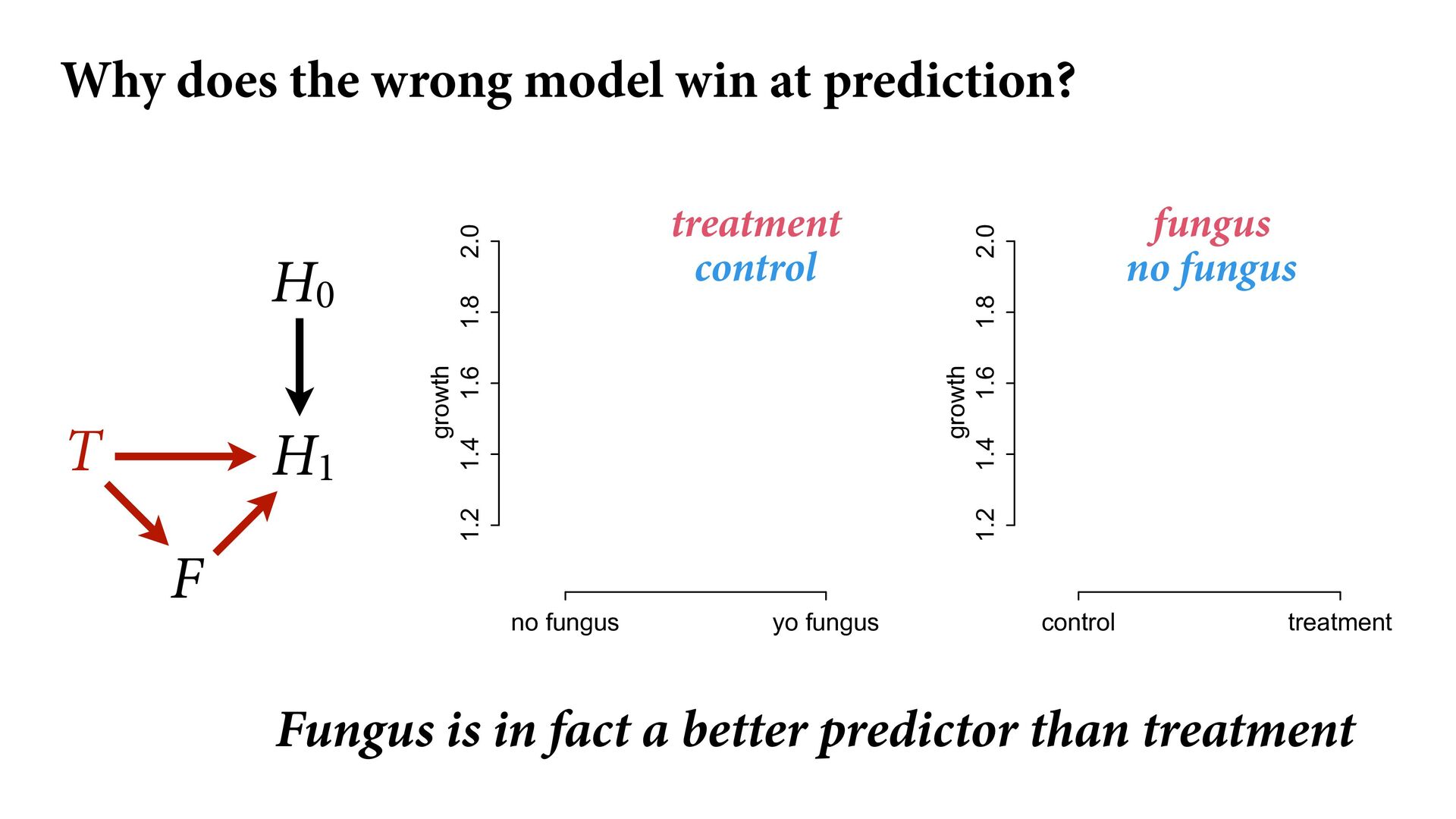
1.2 1.4 1.6 1.8 2.0 growth control treatment treatment control fungus no fungus H0 H1 T F Why does the wrong model win at prediction? Fungus is in fact a better predictor than treatment
to choose a causal estimate However, many analyses are mixes of inferential and predictive chores Still need help nding good functional descriptions while avoiding over tting H0 H1 T F
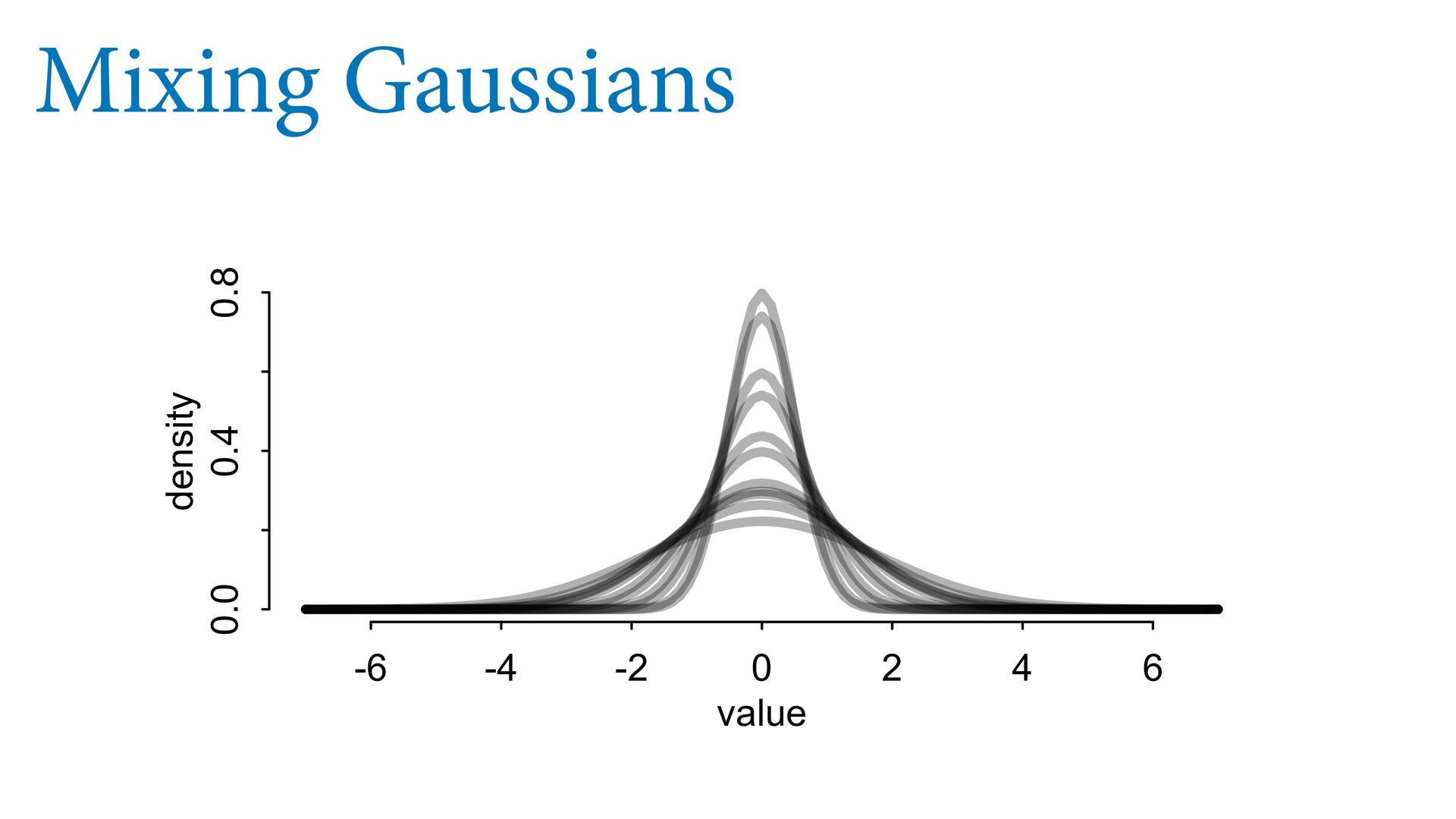
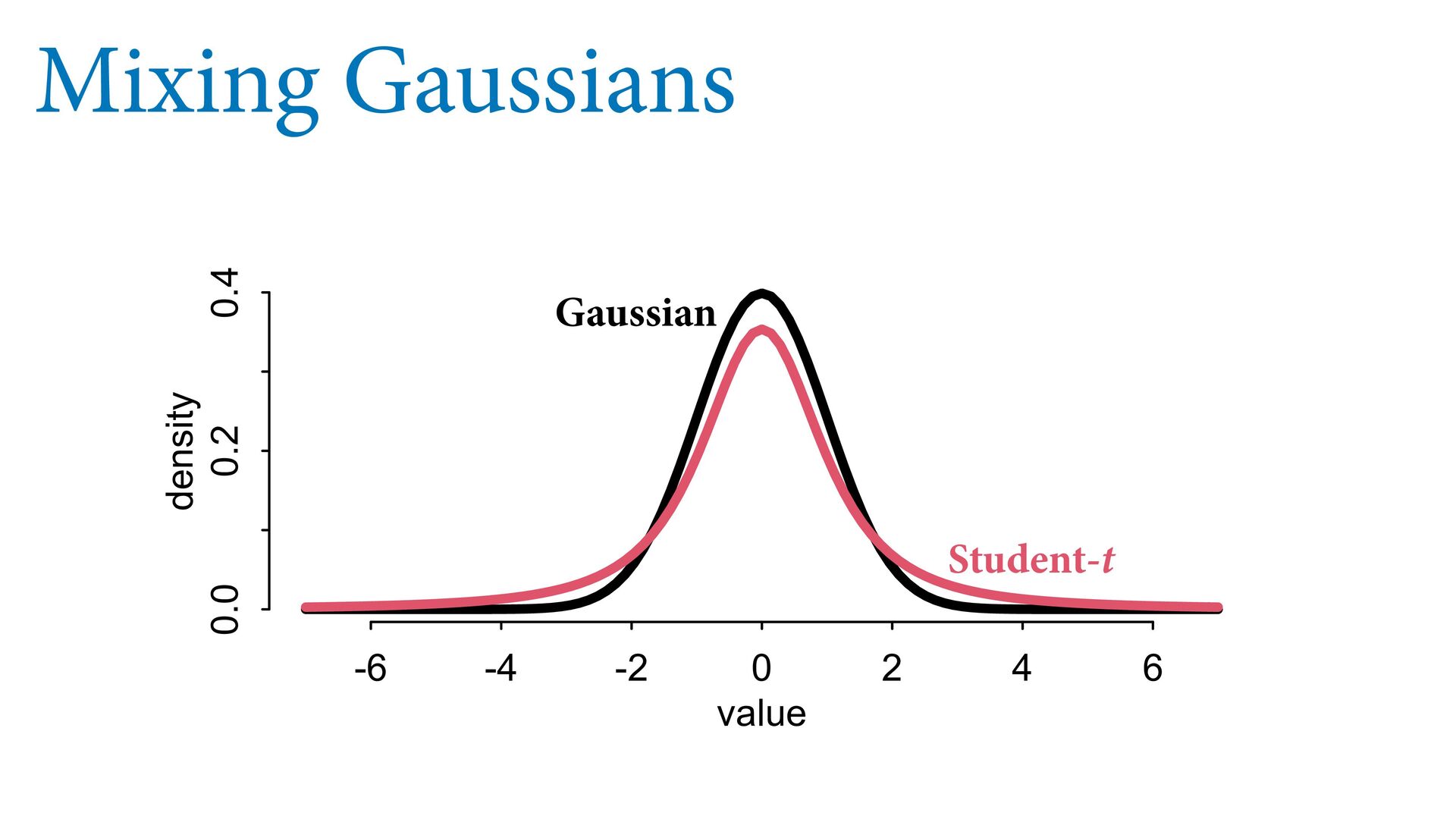
the problem; predictions are still bad! It’s the model that’s wrong, not the data First, quantify in uence of each point Second, use a mixture model (robust regression) -4 -2 0 2 4 -4 -2 0 2 4 -4 -2 0 2 4 -4 -2 0 2 4
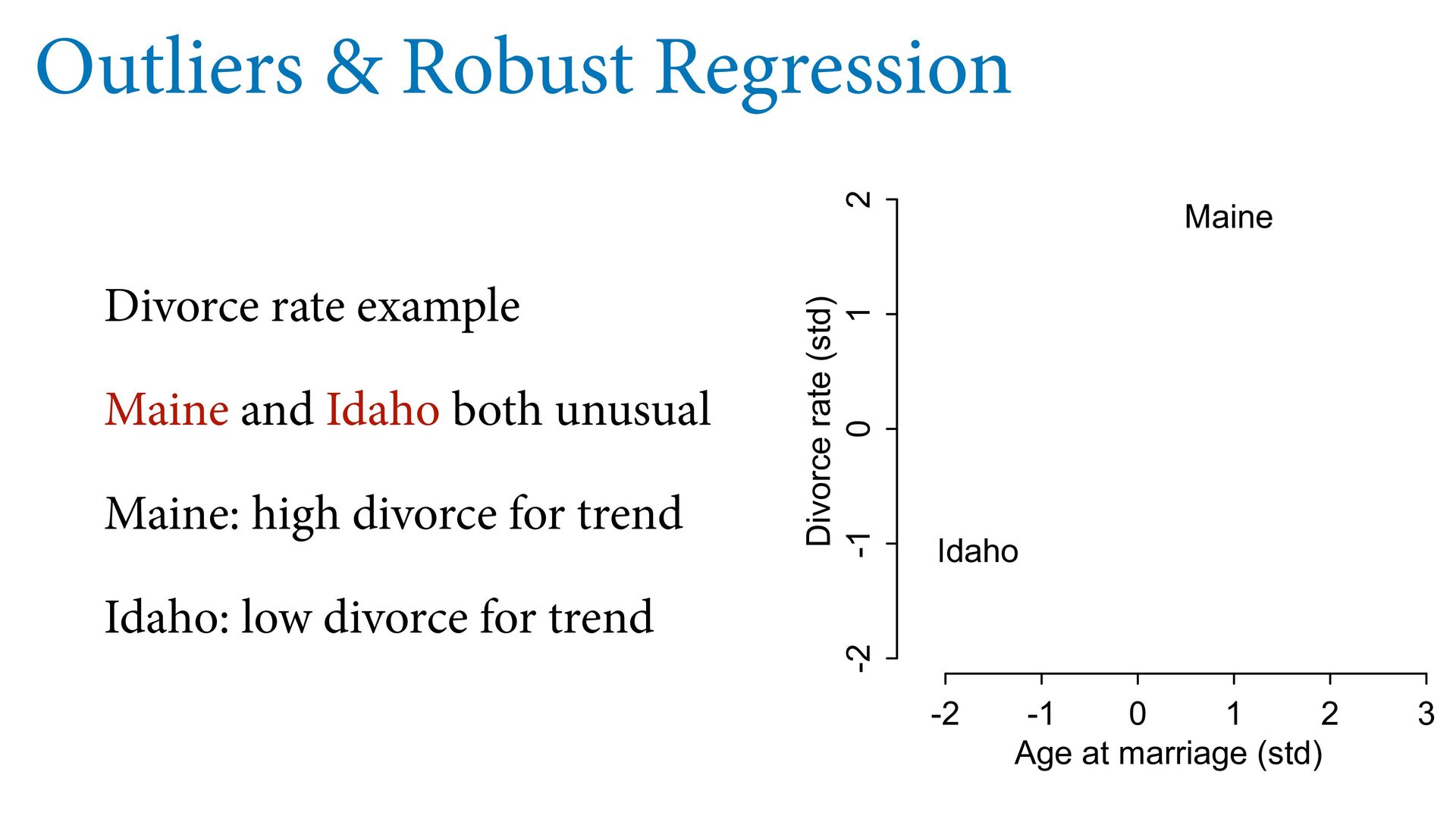
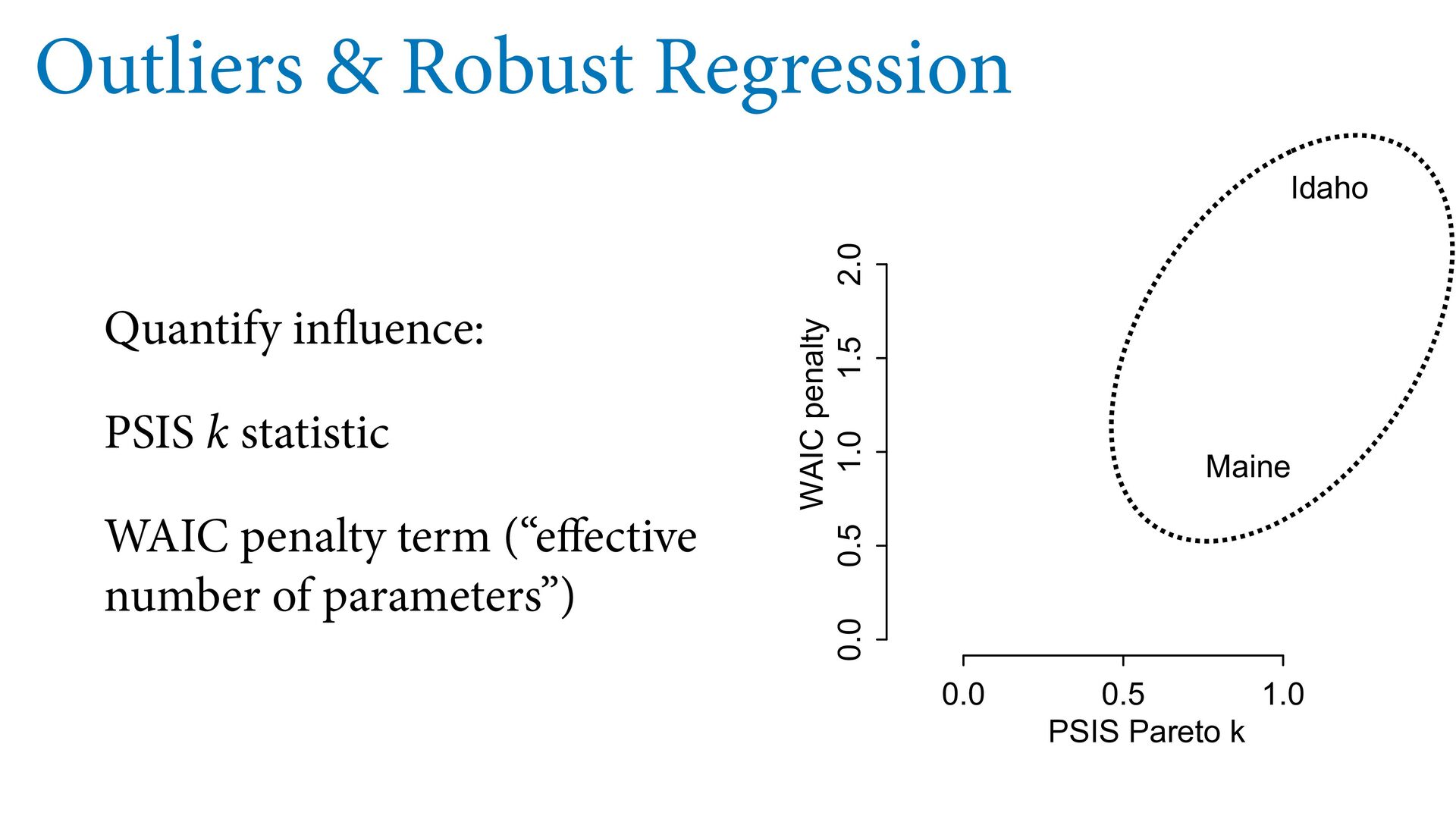
means model is less surprised by extreme values Usually impossible to estimate distribution of extreme values Student-t regression as default? -2 -1 0 1 2 3 -2 -1 0 1 2 Age at marriage (std) Divorce rate (std) Idaho Maine
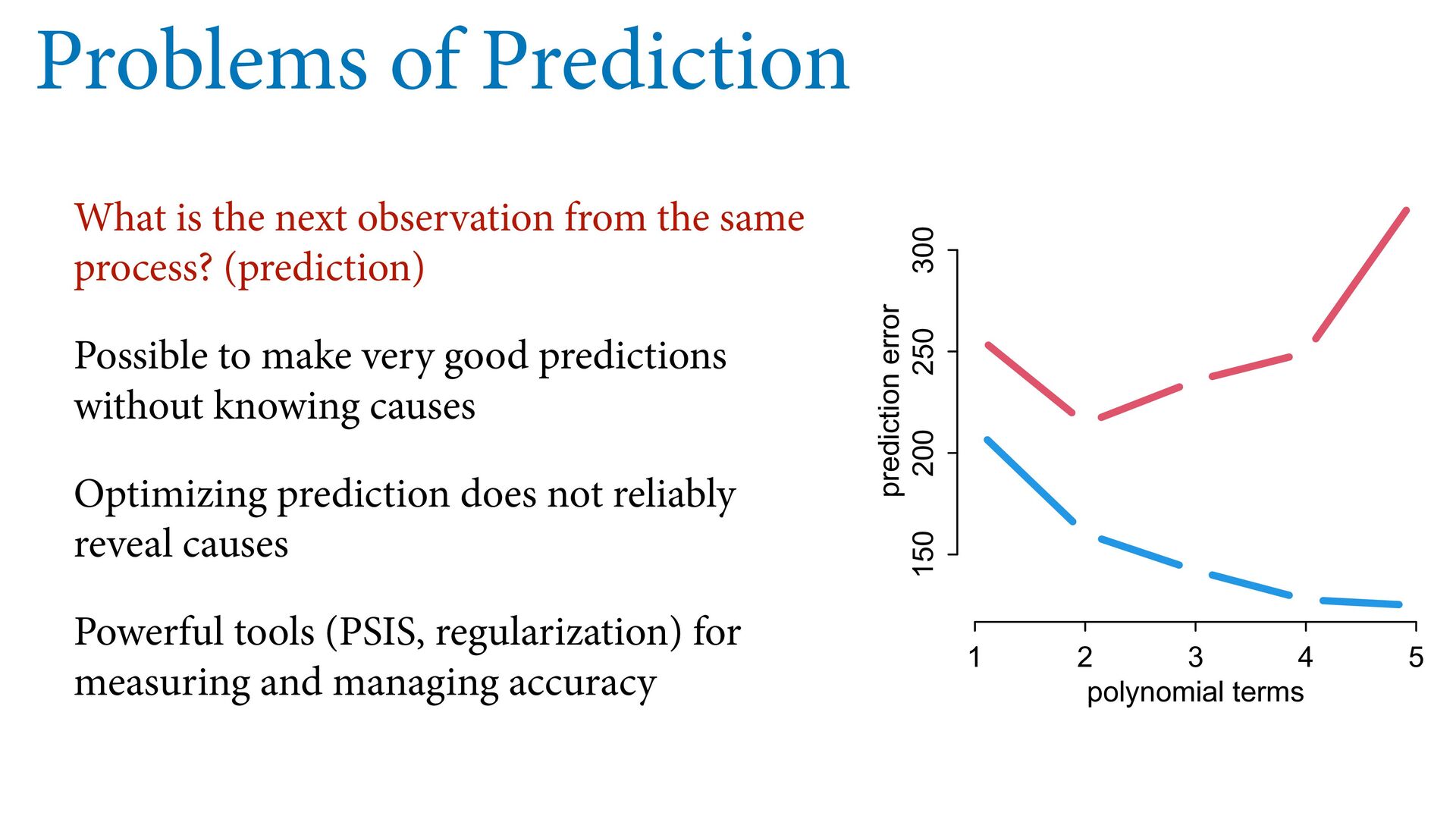
same process? (prediction) Possible to make very good predictions without knowing causes Optimizing prediction does not reliably reveal causes Powerful tools (PSIS, regularization) for measuring and managing accuracy 1 2 3 4 5 150 200 250 300 polynomial terms prediction error
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
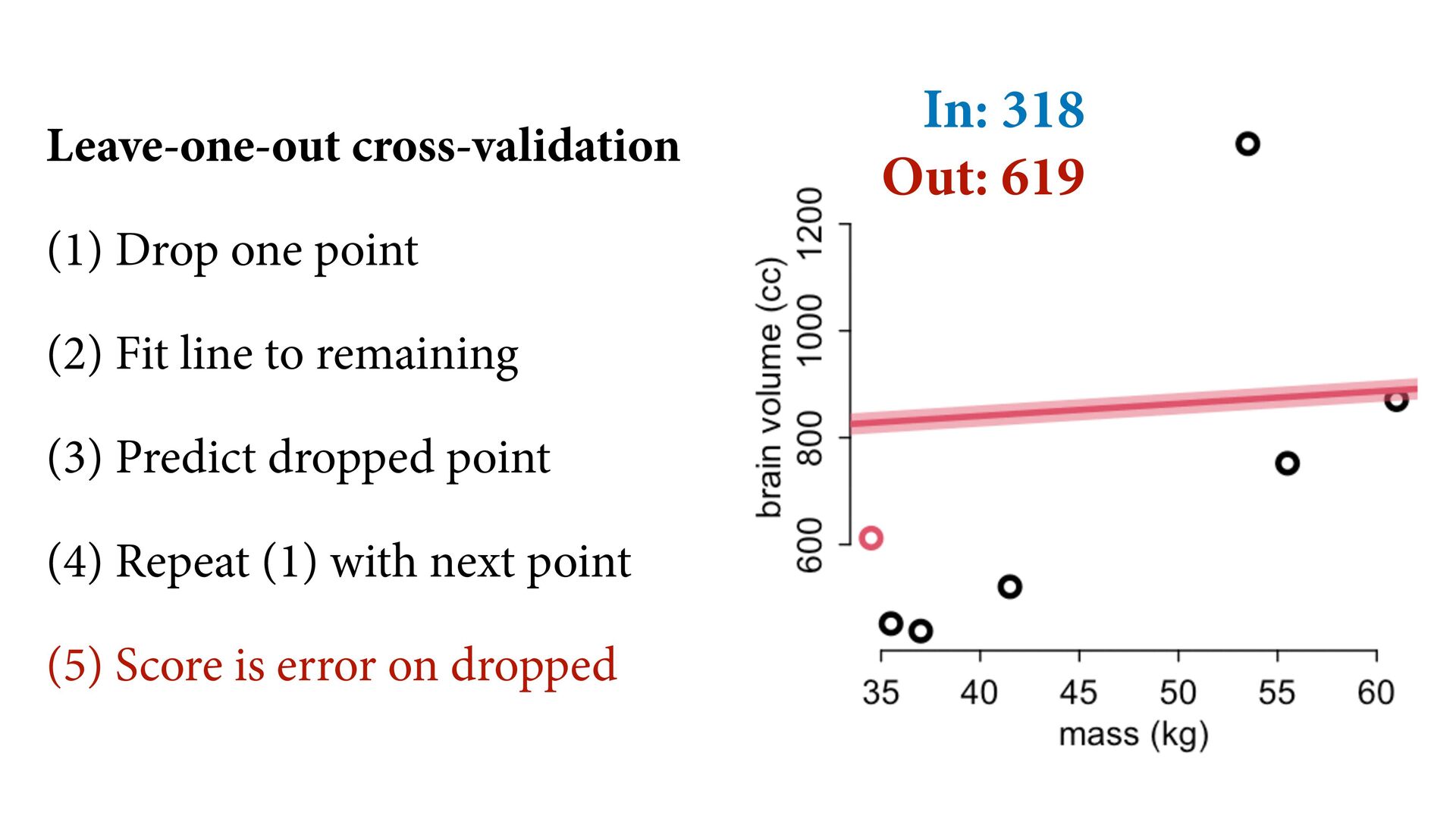
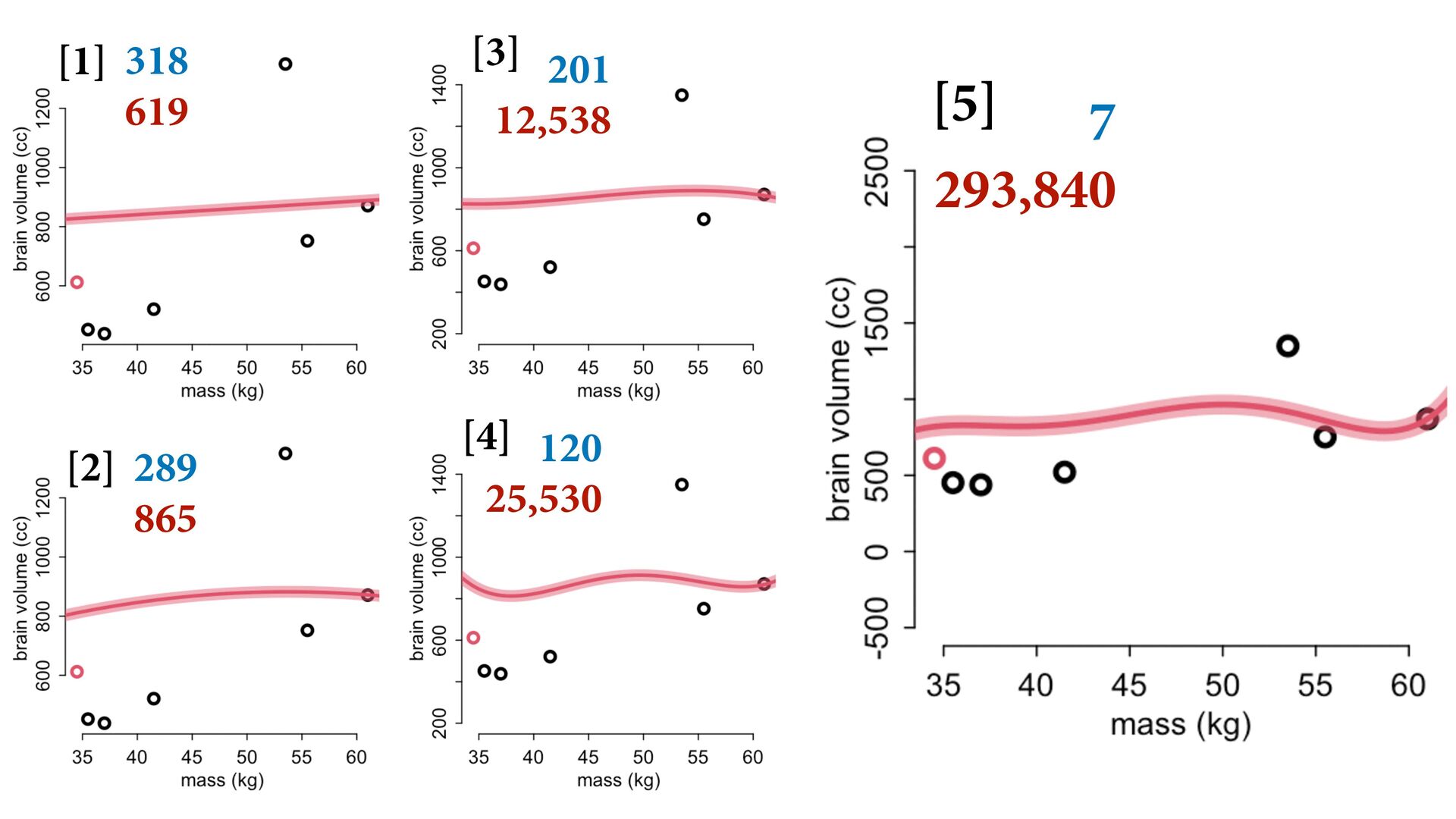
![In: 318 Out: 619 In: 289 Out: 865 [1] [2]](https://files.speakerdeck.com/presentations/ce463d21a3ad422e8074437ecf93e81d/slide_11.jpg){kind=link}
![318 619 289 865 In: 201 Out: 12,538 [3] [1]](https://files.speakerdeck.com/presentations/ce463d21a3ad422e8074437ecf93e81d/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}