Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Factorization Machines
Search
roronya
October 19, 2016
Research
870
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Factorization Machines
大学院の輪講ゼミで発表しました
roronya
October 19, 2016
More Decks by roronya
See All by roronya
速習 Spring AI Gemini CLIのようなLLM CLIを自作しよう
roronya
0
450
TeXの本懐
roronya
0
280
Other Decks in Research
See All in Research
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
660
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
410
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.5k
LLM Compute Infrastructure Overview
karakurist
2
1.5k
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
730
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
110
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
460
Using our influence and power for patient safety
helenbevan
0
370
Featured
See All Featured
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
390
Are puppies a ranking factor?
jonoalderson
1
3.7k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Music & Morning Musume
bryan
47
7.3k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
New Earth Scene 8
popppiees
3
2.4k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Skip the Path - Find Your Career Trail
mkilby
1
170
ラッコキーワード サービス紹介資料
rakko
1
4M
Transcript
Factorization Machines in Proceedings of the 10th IEEE International Conference
on Data Mining (ICDM 2010) @roronya
2 1. 概要 1. Factorization Machines(以下FMs) は SVM のように分類・回帰問題に利用できる一般的な予測モデル 2.
FMs は SVM が失敗するようなスパースなデータに対して有効に動作する 3. FMs は直接最適化できて、サポートベクトルが要らない (SVM は双対問題への変換が必要) 4. FMs は一般的な予測器でどんな実際の特徴ベクトルでも動作する (他の state-of-the-art な factorization モデルは 入力も学習アルゴリズムが特化しすぎている) FMs はその他の factorization モデルに擬態 (mimic) できる。 5. 最近コンペで優勝してる Field-aware Factorization Machines の元のモデル
3 Factorization Machines 1. 概要 2. Factorization Machines 1. 説明のためのデータについて
2. 定式化 3. スパースなデータでの学習 4. 計算量 5. 学習 3. SVM との比較 4. 他の Factorization モデルとの比較 5. まとめ
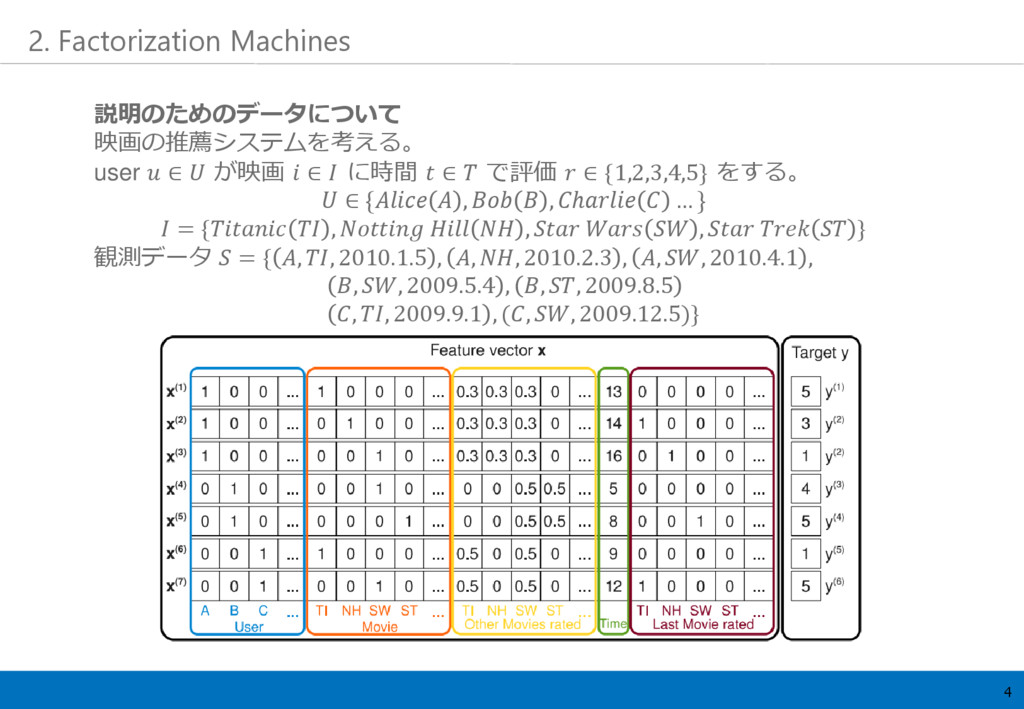
4 2. Factorization Machines 説明のためのデータについて 映画の推薦システムを考える。 user ∈ が映画 ∈
に時間 ∈ で評価 ∈ {1,2,3,4,5} をする。 ∈ { , , ℎ … } = { , , , } 観測データ = { , , 2010.1.5 , , , 2010.2.3 , , , 2010.4.1 , , , 2009.5.4 , , , 2009.8.5 , , 2009.9.1 , (, , 2009.12.5)}
5 2. Factorization Machines 定式化 ≔ 0 + =1 +
=1 =+1 < , > < , >≔ =1 , ∙ , 0 ∈ ℝ と ∈ ℝ と ∈ ℝ× を推定する ただし は の次元数 はハイパーパラメータ は の 番目の要素 目的変数への個々の影響とペアでの相互作用の影響を捉えるモデル ペアだけでなく d 個の組み合わせの相互作用にも拡張が可能 独立した w i,j として推論できるほどデータ無い Factorization モデルにすることで、 スパースなデータに対応している
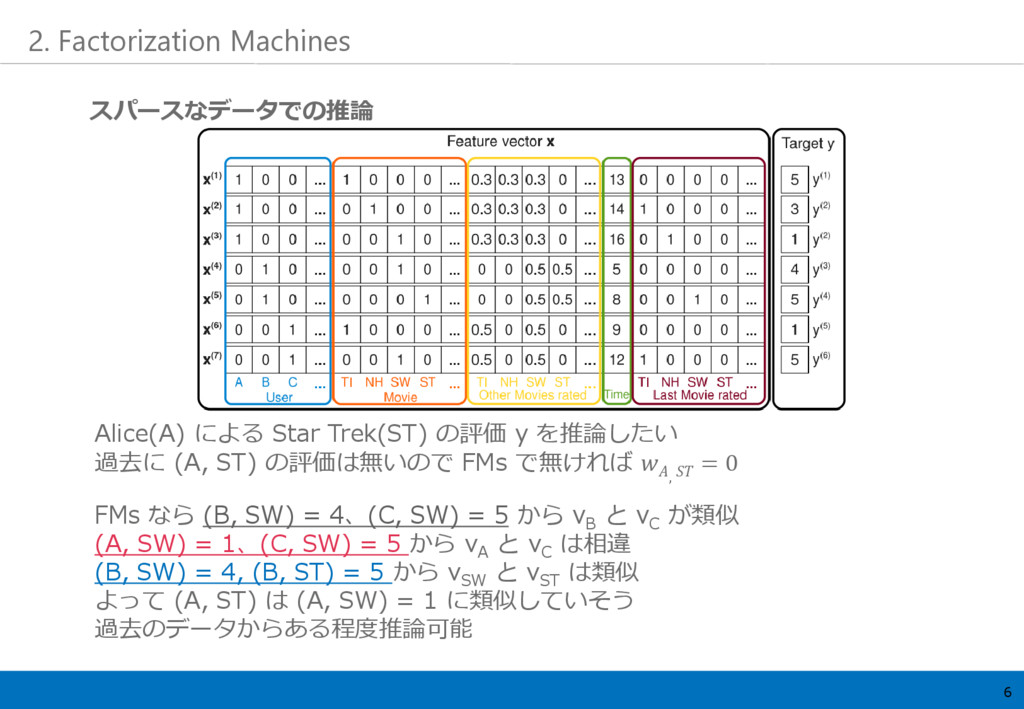
6 2. Factorization Machines Alice(A) による Star Trek(ST) の評価 y
を推論したい 過去に (A, ST) の評価は無いので FMs で無ければ , = 0 FMs なら (B, SW) = 4、(C, SW) = 5 から v B と v C が類似 (A, SW) = 1、(C, SW) = 5 から v A と v C は相違 (B, SW) = 4, (B, ST) = 5 から v SW と v ST は類似 よって (A, ST) は (A, SW) = 1 に類似していそう 過去のデータからある程度推論可能 スパースなデータでの推論
7 2. Factorization Machines ≔ 0 + =1 + =1
=+1 < , > 単純にやれば 2 だけど () にできる =1 =+1 < , > = 1 2 =1 =1 < , > − 1 2 =1 < , > = 1 2 =1 =1 =1 , , − =1 =1 , , = 1 2 =1 =1 , =1 , − =1 , 2 2) = 1 2 =1 =1 , 2 − =1 , 2 2) 計算量
8 2. Factorization Machines SGD でパラメータが求まる 微分は以下。損失関数は自乗誤差でもロジットでもヒンジでも良いとのこと。 = 1, 0
, =1 , − , 2, , =1 , は と独立しているので計算しておくことで勾配は (1) ( 計算するときに計算しておく) 1データ(, ) につき () で全てのパラメータが更新される 学習
9 Factorization Machines 1. 概要 2. Factorization Machines 3. SVM
との比較 1. 線形カーネル 2. 多項式カーネル 3. その他話題とまとめ 4. 他の Factorization モデルとの比較 5. まとめ
10 3. SVM との比較 K ( , ) ≔ 1+
< , > = =1 (1 + ) = =1 + =1 = 0 + =1 FMs の相互作用項の無い式と同じ形 線形カーネル (FMs) ≔ 0 + =1 + =1 =+1 < , > = { 1 , 1 , … , , } のとき識別関数は = =1 ( )() = =1 ( , ) ただし は未定乗数
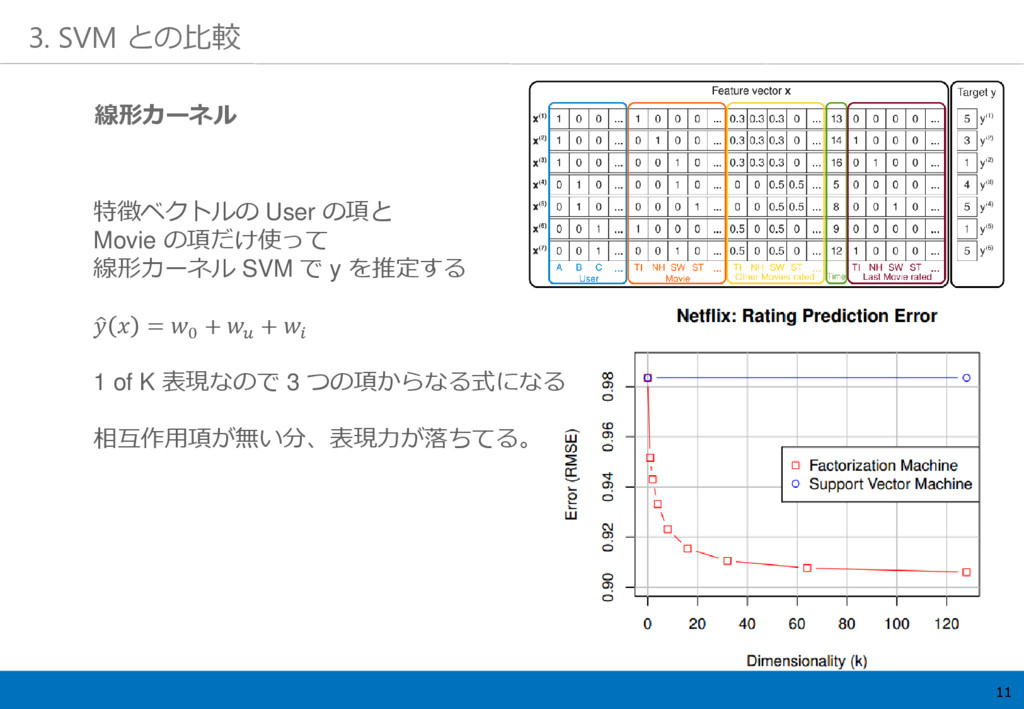
11 3. SVM との比較 特徴ベクトルの User の項と Movie の項だけ使って 線形カーネル
SVM で y を推定する = 0 + + 1 of K 表現なので 3 つの項からなる式になる 相互作用項が無い分、表現力が落ちてる。 線形カーネル
12 3. SVM との比較 K ( , ) ≔ (1+
< , >) = 2 のとき ≔ (1, 21 , … , 2 , 1 2 … , 2, 21 2 , … , 21 , 22 3 , … , 2−1 ) = 0 + 2 =1 + =1 , 2 + 2 =1 =+1 , FMs の< , >を独立した, としている 多項式カーネル (FMs) ≔ 0 + =1 + =1 =+1 < , > (SVM) = =1 ( )() = =1 ( , )
13 3. SVM との比較 Alice(A) による Star Trek(ST) の評価 y
を推論したい 過去に (A, ST) の評価は無いので 多項式カーネル SVM では , = 0 FMs なら (B, SW) = 4、(C, SW) = 5 から v B と v C が類似 (A, SW) = 1、(C, SW) = 5 から v A と v C は相違 (B, SW) = 4, (B, ST) = 5 から v SW と v ST は類似 よって (A, ST) は (A, SW) = 1 に類似していそう 過去のデータからある程度推論可能 多項式カーネル 特徴ベクトルの User の項と Movie の項だけ使って 多項式カーネル SVM で y を推定する = 0 + 2 + + , + , + 2,
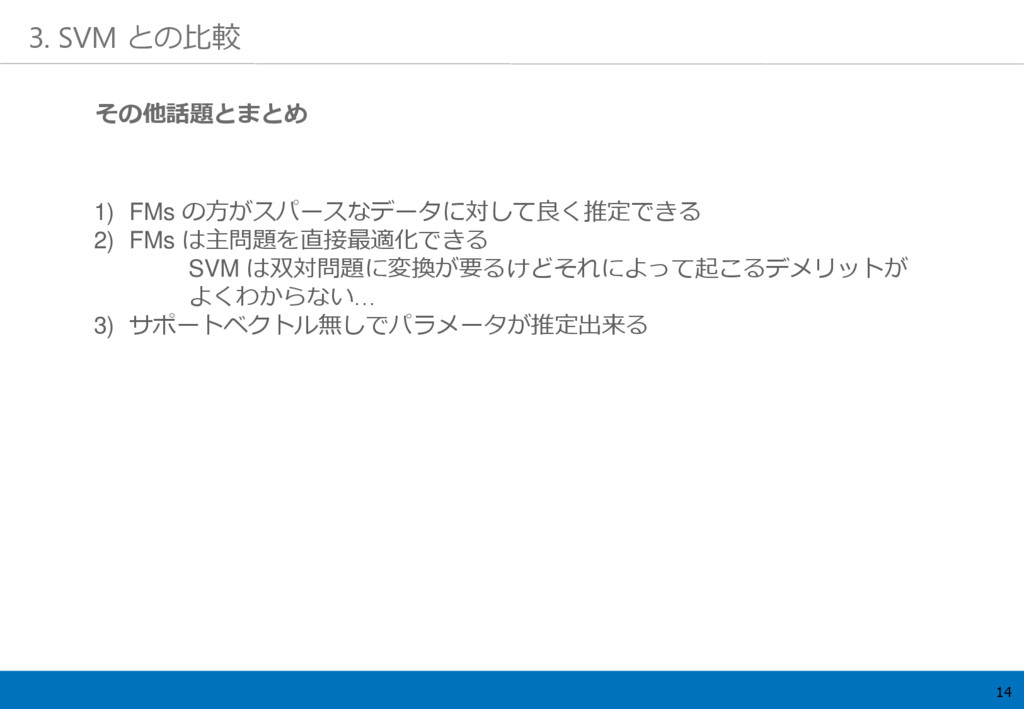
14 3. SVM との比較 1) FMs の方がスパースなデータに対して良く推定できる 2) FMs は主問題を直接最適化できる
SVM は双対問題に変換が要るけどそれによって起こるデメリットが よくわからない… 3) サポートベクトル無しでパラメータが推定出来る その他話題とまとめ
15 Factorization Machines 1. 概要 2. Factorization Machines 3. SVM
との比較 4. 他の Factorization モデルとの比較 1. Matrix Factorization 2. SVD++ 3. PITF 4. FPMC 5. まとめ
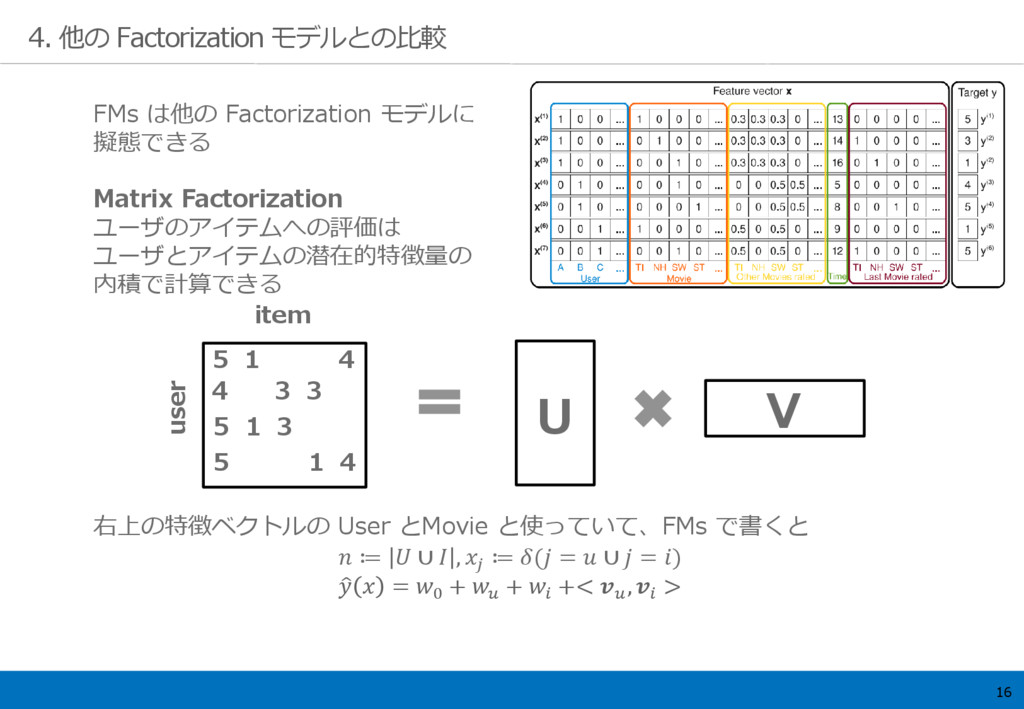
16 4. 他の Factorization モデルとの比較 FMs は他の Factorization モデルに 擬態できる
Matrix Factorization ユーザのアイテムへの評価は ユーザとアイテムの潜在的特徴量の 内積で計算できる 右上の特徴ベクトルの User とMovie と使っていて、FMs で書くと ≔ ∪ , ≔ ( = ∪ = ) = 0 + + +< , > 5 1 4 4 3 3 5 1 3 5 1 4 item user U V
17 4. 他の Factorization モデルとの比較 SVD++ Matrix Factorization の改良モデル 今見たアイテムと
その直前に見たアイテムとの 相互作用を考慮している 右上の特徴ベクトルの User とMovie と Last Movie rated を使っていて、 FMs で書くと ≔ ∪ ∪ , : = 1, = ∪ = 1 , ∈ 0, ただし は評価済みのアイテムの集合 = 0 + + +< , > + 1 ∈ < , > + 1 +< , > + 1 ′∈,′> < , ′ > 本来の SVD++ は ここまで FMs だと その他の相互作用も 考慮することになる
18 4. 他の Factorization モデルとの比較 PITF for Tag Recommendation PITF
= Pairwise Interaction Tensor Factorization) ユーザがアイテムにタグをつけるときに良さそうなタグを推薦したい ECML/PKDD Discovery Challenge で優勝した手法 1 of K されたユーザーとアイテムとタグを特徴ベクトルとする FMs で書くと ≔ ∪ ∪ , : = ( = ∪ = ∪ = ) = 0 + + + +< , >+< , >+< , > PITF のオリジナルモデルだと 1) が無かった 2) < , >+< , >が, + , だった (Factorization してなかった) 右はコンペティションのデータで FMs が PITF と同じくらいスコアが出ている という図
19 4. 他の Factorization モデルとの比較 FPMC =Factorized Personalized markov Chains
1 okf K 表現されたUser とMovie と Last Movie rated を特徴ベクトルとする FMs で書くと ≔ ∪ ∪ , : = 1, = ∪ = 1 |−1 | , ∈ −1 0, ただし ⊆ は時刻 でユーザー が買ったアイテムの集合 = 0 + + +< , > + 1 |−1 | ∈−1 < , > + 1 |−1 | +< , > + 1 |−1 | ′∈−1 ,′> < , ′ > SVD++ は今まで買ったアイテムを 1 としていた FPMCは直前に買ったアイテムの集合を 1 |−1 | としている
20 5. まとめ • Factorization Machines を紹介した • SVM と比較して
スパースなデータに置ける優位を示した • 他の state-of-the-art な Factorization モデルの 汎化モデルであることを示した • 次に読むならこれ Field-aware Factorization Machines http://www.csie.ntu.edu.tw/~r01922136/slides/ffm.pdf
補足
22 2. Factorization Machines FMs の表現力 が十分に大きければ = ∙ が正定値行列となることが知られている。
だから FMs は が十分に大きければどんな相互作用も表現できる。 しかし、 を大きくするとモデルの複雑性が大きくなるので ほどほどの を選択する。
23 2. Factorization Machines d-way Factorization Machines ≔ 0 +
=1 + =2 1=1 ∙∙∙ =−1+1 =1 =1 =1 ,
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}