Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Linuxのプロセススケジューラの歴史 v2.6.23~v4.18
Search
Satoru Takeuchi
PRO
January 29, 2022
Technology
560
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Linuxのプロセススケジューラの歴史 v2.6.23~v4.18
以下動画のテキストです。
https://youtu.be/hrKENEC7Gsg
Satoru Takeuchi
PRO
January 29, 2022
More Decks by Satoru Takeuchi
See All by Satoru Takeuchi
Machine Check Exception
sat
PRO
2
37
バイナリダンプの模様を読む
sat
PRO
0
68
cpコマンドはディスク上でデータを コピーしないことがある
sat
PRO
3
54
114-ファイルのshallow_copy.pdf
sat
PRO
2
38
113-Btrfsのスナップショット.pdf
sat
PRO
0
16
システム強制終了時にファイルシステムの整合性を保つ~ コピーオンライト編 ~
sat
PRO
0
59
システム強制終了時に ファイルシステムの整合性を保つ ~ ジャーナリング編 ~
sat
PRO
2
63
ファイルシステムの整合性を回復するfsck
sat
PRO
1
65
小学校5,6年生向けキャリア教育 大人になるまでの道
sat
PRO
8
5.3k
Other Decks in Technology
See All in Technology
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
150
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
120
公式ドキュメントの歩き方etc
coco_se
1
120
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
9
4k
マルチアカウント環境でSecurity Hubの運用、その後どうなった? / SRE NEXT 2026 miniLT会
genda
0
110
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
460
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
280
SRE Next 2026 何でも屋からの脱却
bto
0
1k
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
570
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
500
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3.4k
Featured
See All Featured
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
The untapped power of vector embeddings
frankvandijk
2
1.8k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Transcript
Linuxのプロセススケジューラの歴史 v2.6.23~v4.18 Jan. 29th, 2022 Satoru Takeuchi Twitter: satoru_takeuchi 1
はじめに • Linuxカーネル(以下カーネル)のプロセススケジューラの歴史を振り返る • 対象バージョン: 最初のリリースv2.6.23からv4.18まで • 用語 ◦ タスク:
カーネルのスケジューリング単位。プロセスあるいはスレッド ◦ LCPU: カーネルがCPUとして認識するもの(物理CPU or コア or スレッド) ◦ Current: LCPU上で現在動作中のタスク 2
Completely Fair Scheduler (CFS) • レイテンシターゲットによるスケジューリング • 細かいタイムスライス粒度 • プラガブルなスケジューリングアルゴリズム
3
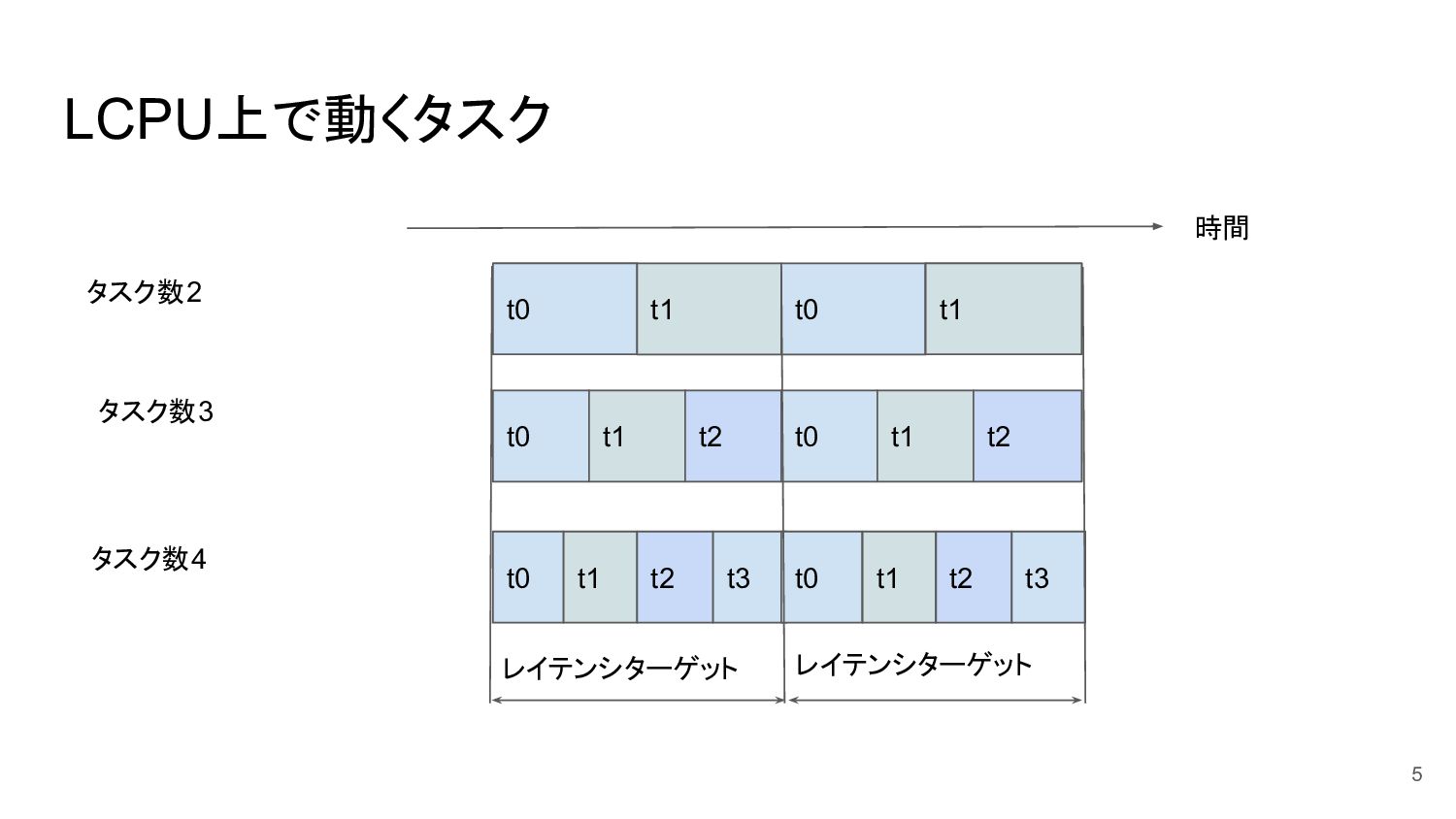
レイテンシターゲットによるスケジューリング • ランキューはvruntimeと呼ばれる仮想的なキー(後述)とした赤黒木 ◦ スケジューリング処理の計算量は O(log(n)) ◦ active/inactiveキュー、および優先度別ランキューは廃止 • 各タスクはレイテンシターゲットと呼ばれる期間に一度CPU時間を得られる
◦ レイテンシターゲットは数 ms~数十ms。システムのLCPU数やバージョンによって変わる ◦ タイムスライス = レイテンシターゲット ()/runnableタスク数 4
LCPU上で動くタスク 5 タスク数2 タスク数3 タスク数4 時間 t0 t1 t0 t1
t0 t1 t2 t0 t1 t2 t0 t1 t2 t3 t0 t1 t2 t3 レイテンシターゲット レイテンシターゲット
スケジューラの挙動: 初期状態 • 仮定 ◦ レイテンシターゲット : 10 [ms] •
タイムスライス=10/(runnableタスク数=3) [ms] 6 0 0 0 t0 t1 t2 vruntime(簡単のため簡略化している ) LCPU
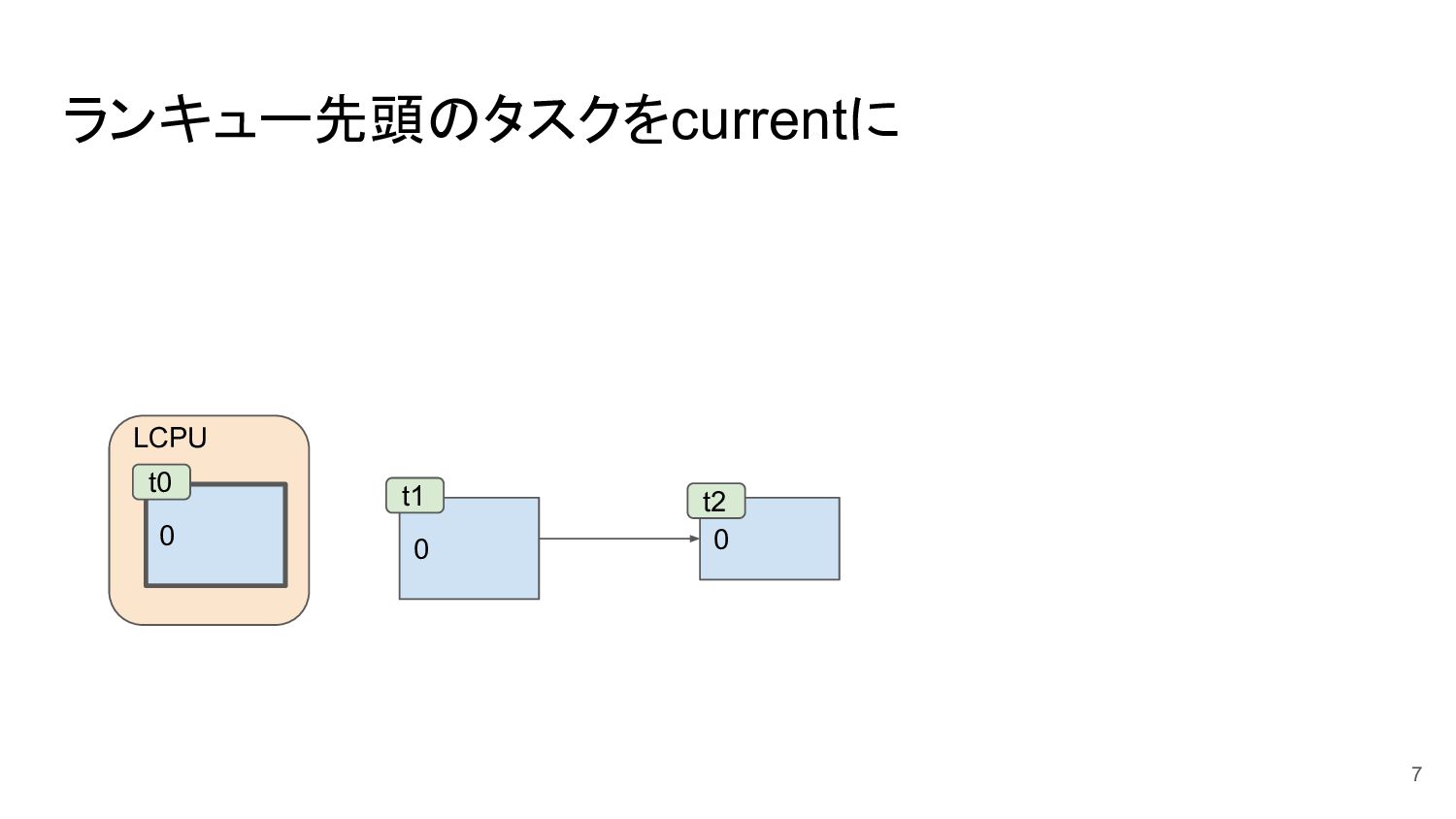
ランキュー先頭のタスクをcurrentに 7 0 0 t1 t2 LCPU 0 t0
タイムスライス切れまで動かす • 10/3 [ms]動くとvruntimeが1.0増えるよう計算 8 0 0 t1 t2 LCPU
1.0 t0
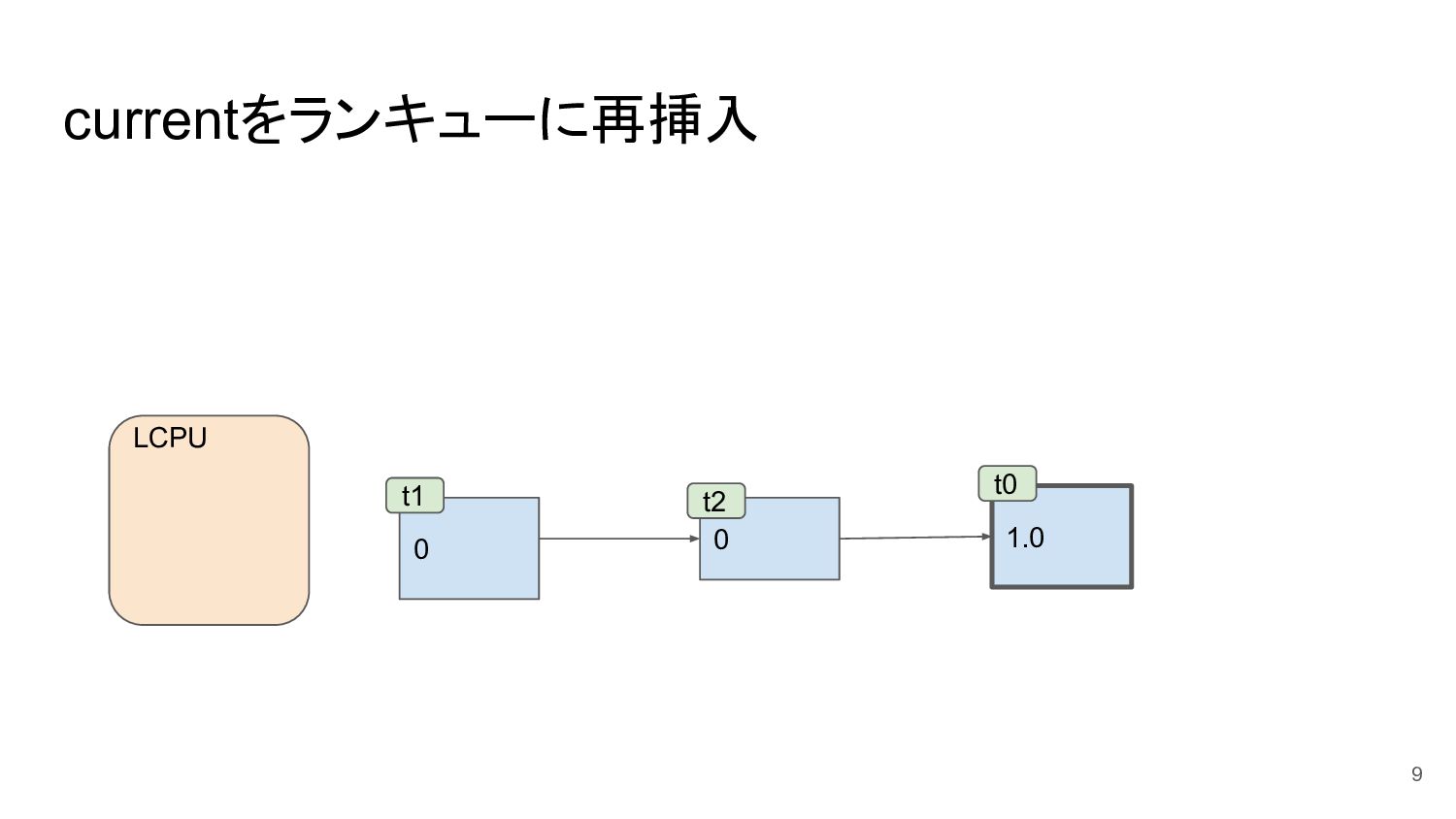
currentをランキューに再挿入 9 0 0 t1 t2 LCPU 1.0 t0
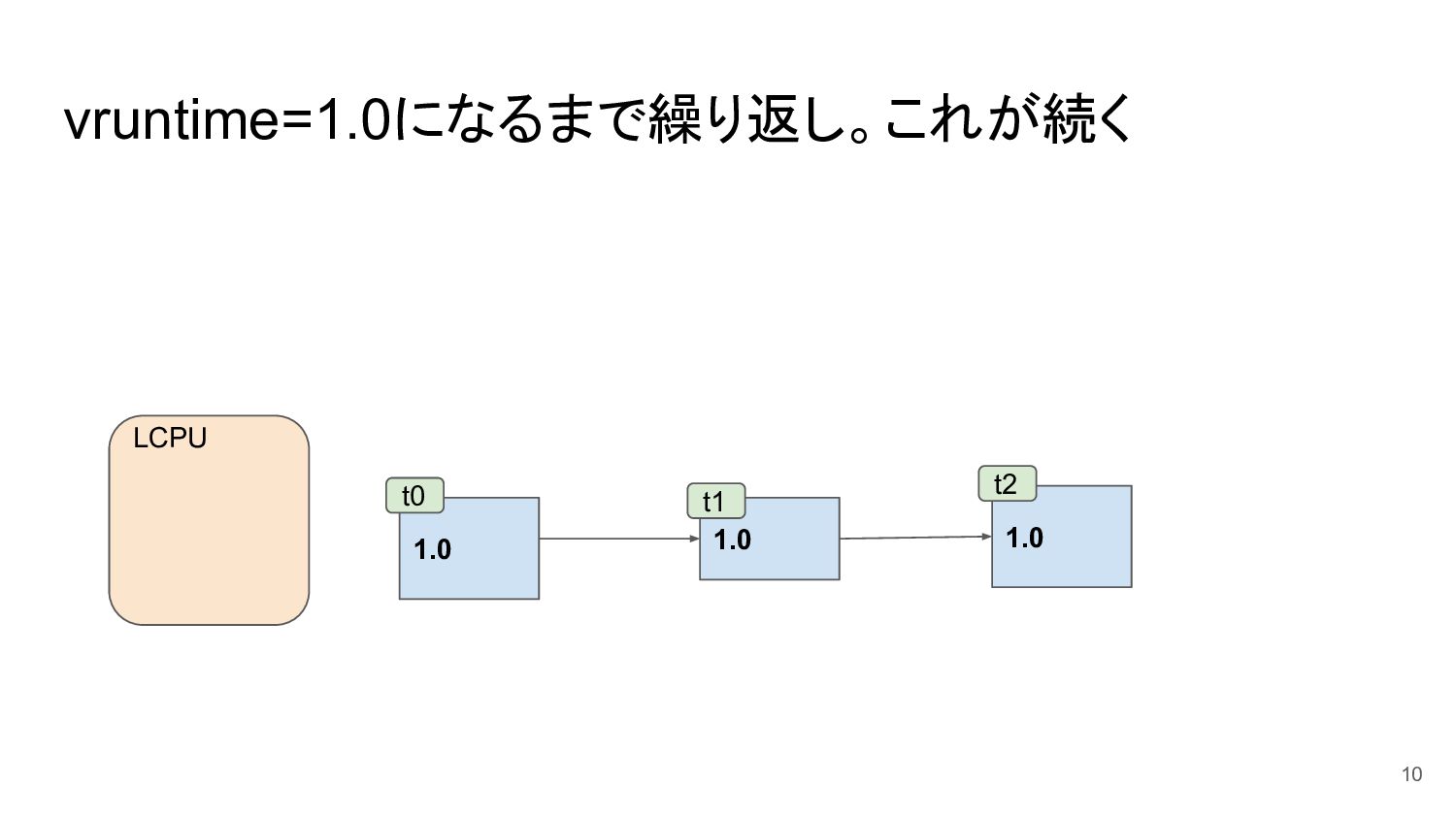
vruntime=1.0になるまで繰り返し。これが続く 10 1.0 1.0 t0 t1 LCPU 1.0 t2
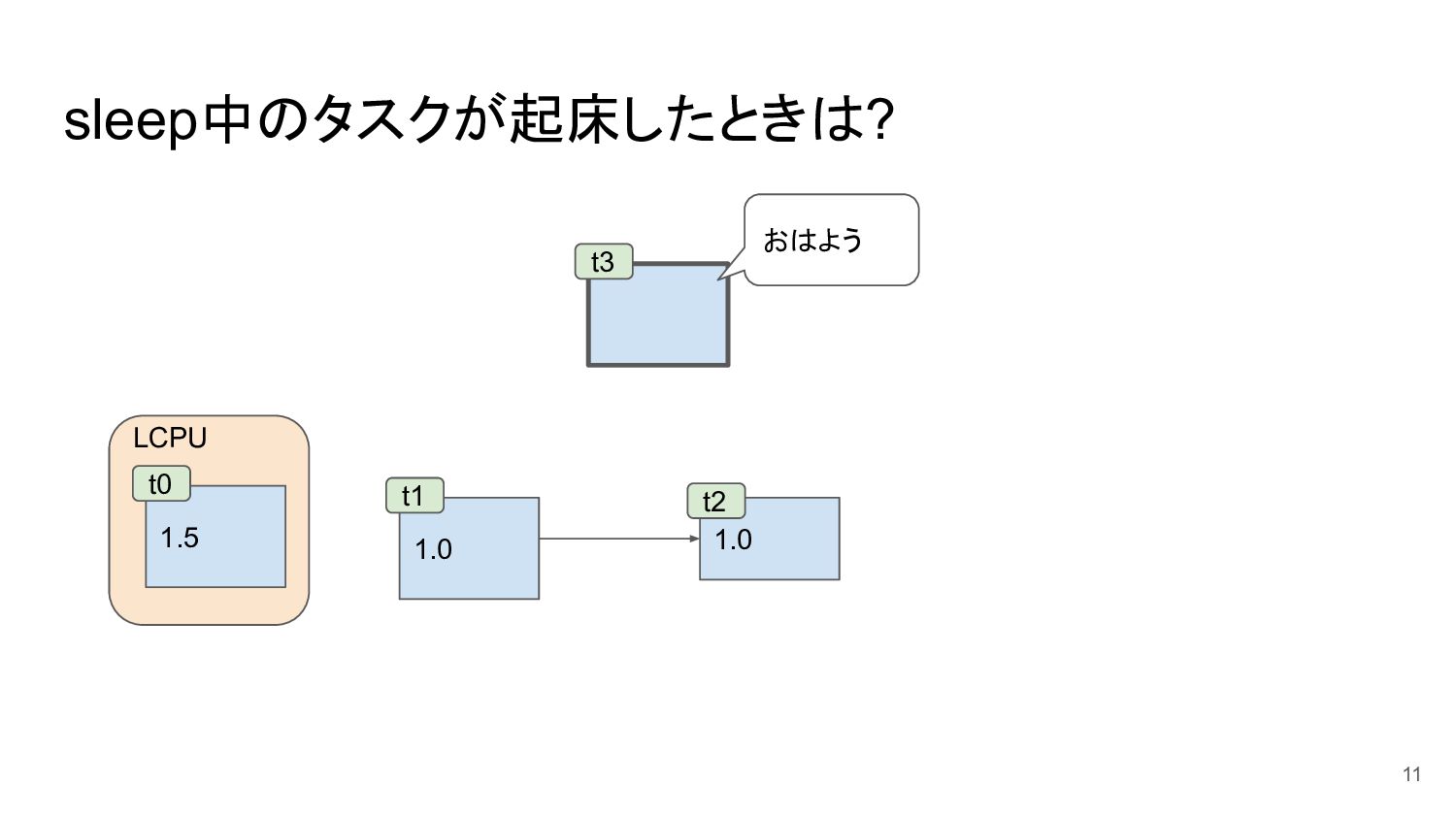
sleep中のタスクが起床したときは? 11 1.0 1.0 t1 t2 LCPU t3 1.5 t0
おはよう
vruntimeをrunnableタスク内最小値にしてランキューに挿入 • vruntime=15のタスクの残りタイムスライス ◦ (2.0-1.5)*(10/3)=1.67 [ms] → (2.0-1.5)*(10/4) = 1.25
[ms] • vruntime=10のタスクの残りタイムスライス ◦ (2.0-1.0)*(10/3)=3.3 [ms] → (2.0-1.0)*(10/4) = 2.5 [ms] 12 1.0 1.0 t1 t2 LCPU 1.0 t3 1.5 t0
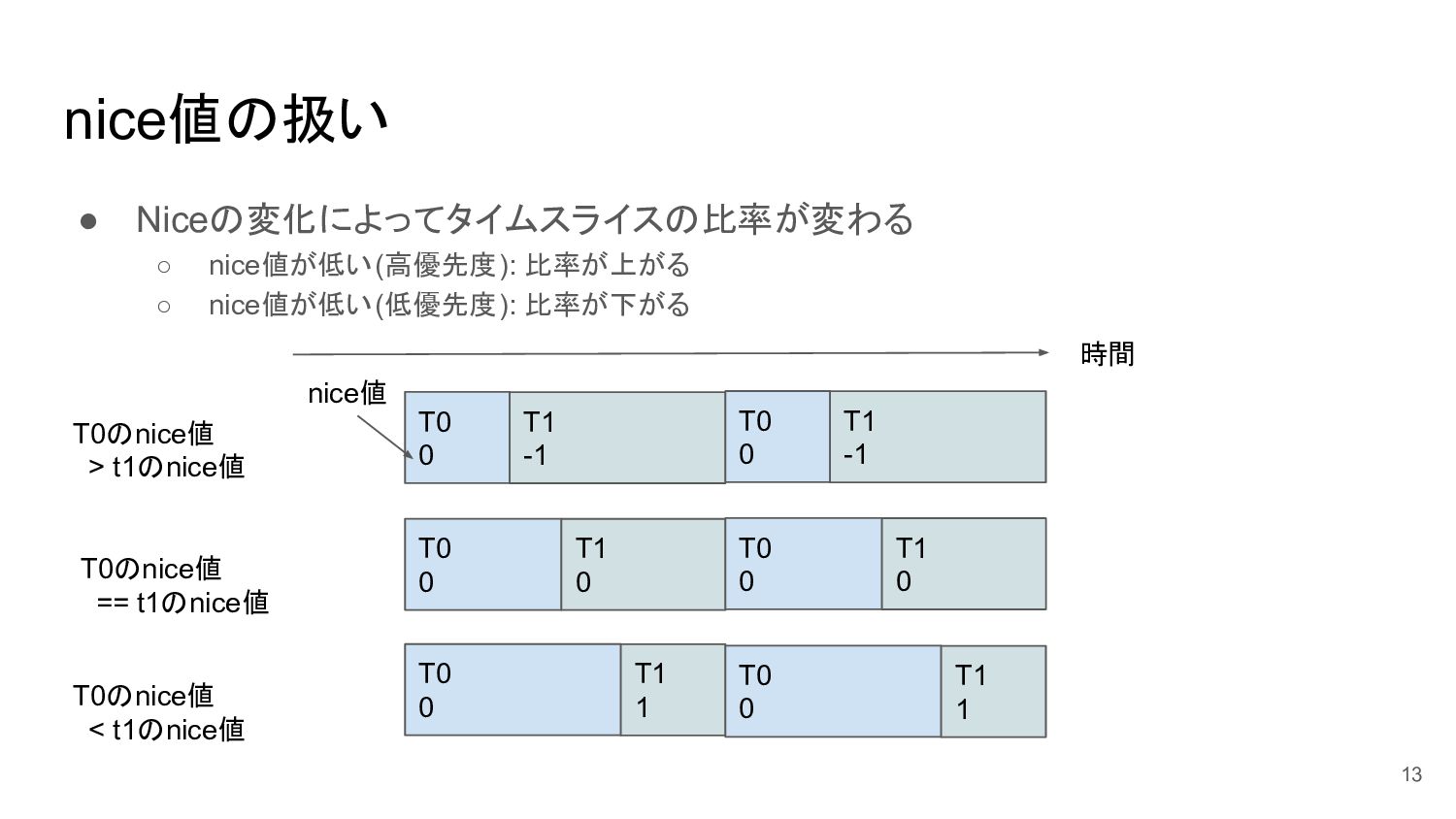
nice値の扱い • Niceの変化によってタイムスライスの比率が変わる ◦ nice値が低い(高優先度): 比率が上がる ◦ nice値が低い(低優先度): 比率が下がる 13
T0 0 T1 -1 T0 0 T1 0 T0 0 T1 1 時間 T0 0 T1 0 nice値 T0のnice値 > t1のnice値 T0のnice値 == t1のnice値 T0のnice値 < t1のnice値 T0 0 T1 -1 T0 0 T1 1
プラガブルなスケジューラ • アルゴリズム別にスケジューリングクラスという概念を導入 ◦ 効果: 後からスケジューラを追加するのが楽 & コードの見通しが良い ◦ クラスごとにコールバック関数のセットを用意
▪ 次のcurrentを選ぶ関数、タスクの sleep時に呼ぶ関数、起床時に呼ぶ関数、など • 高優先度のクラスに属する実行可能タスクは低優先度のクラスに属するタスクより 優先動作 ◦ スケジューリングクラス (優先度順) ▪ rt_shed_class: リアルタイムタスク。ポリシーは SCHED_{FIFO,RR} ▪ fair_sched_class: 通常のプロセス。ポリシーは SCHED_OTHER 14
細かいタイムスライス粒度 • O(1)まで ◦ レガシーなインターバルタイマーを使用 : 定期的に割り込みが発生し続ける ◦ ms単位が限度 •
CFS ◦ ワンショット高精度タイマー : タイムスライスが切れる時に割り込みを発生させる ◦ ns単位の制御が可能 15
V2.6.24: fair group scheduling • Cpu cgroup 1. グループ間でCPUを均等配分 2.
グループ内でさらに均等配分 • Cpu cgroupのcpu.sharesパラメタによって重み付けも可能 • ネストも可能 16
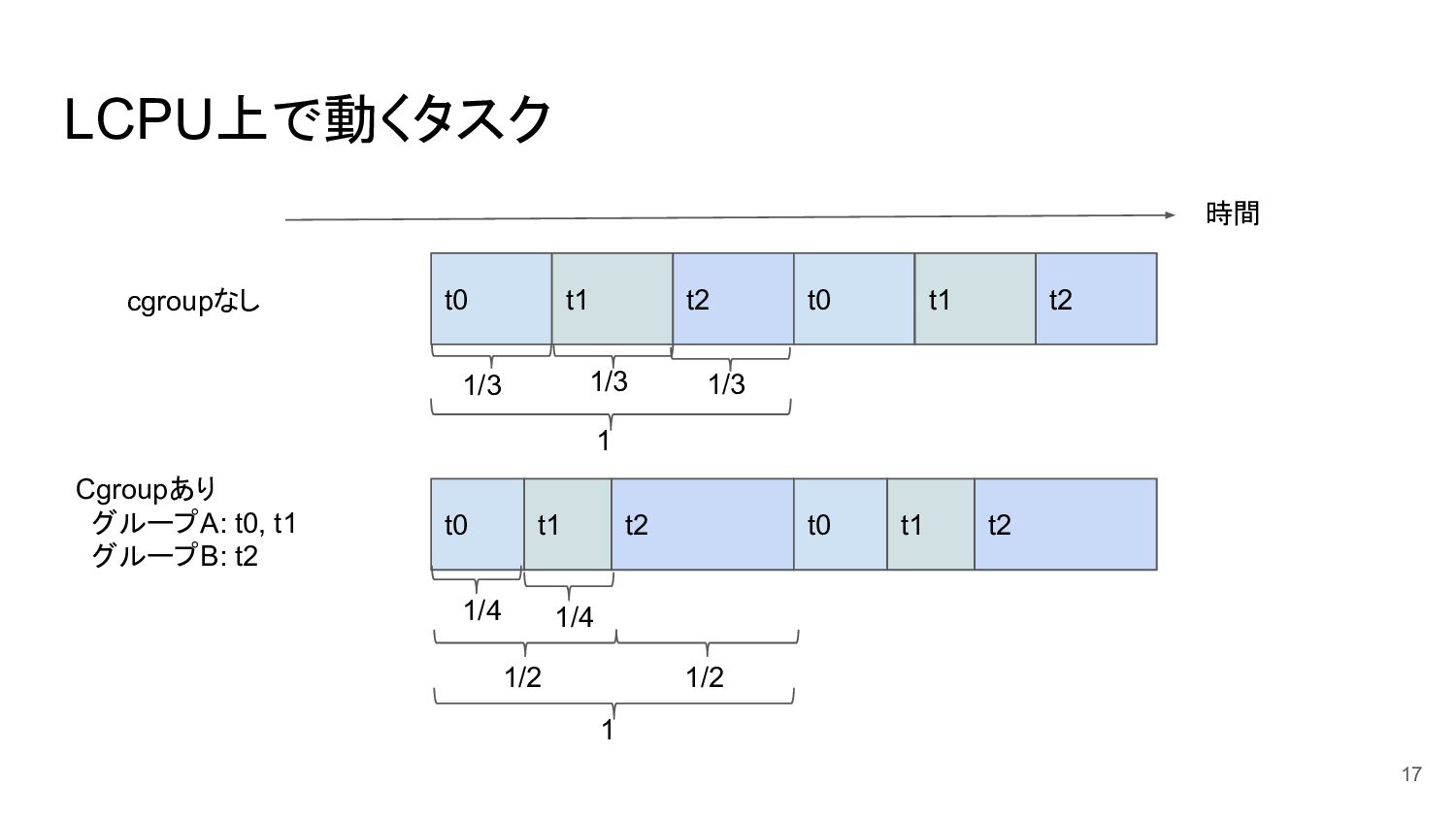
LCPU上で動くタスク 17 時間 t0 t1 t2 t0 t1 t2 cgroupなし
Cgroupあり グループA: t0, t1 グループB: t2 t0 t1 t2 t0 t1 t2 1 1/3 1/3 1/3 1 1/4 1/4 1/2 1/2
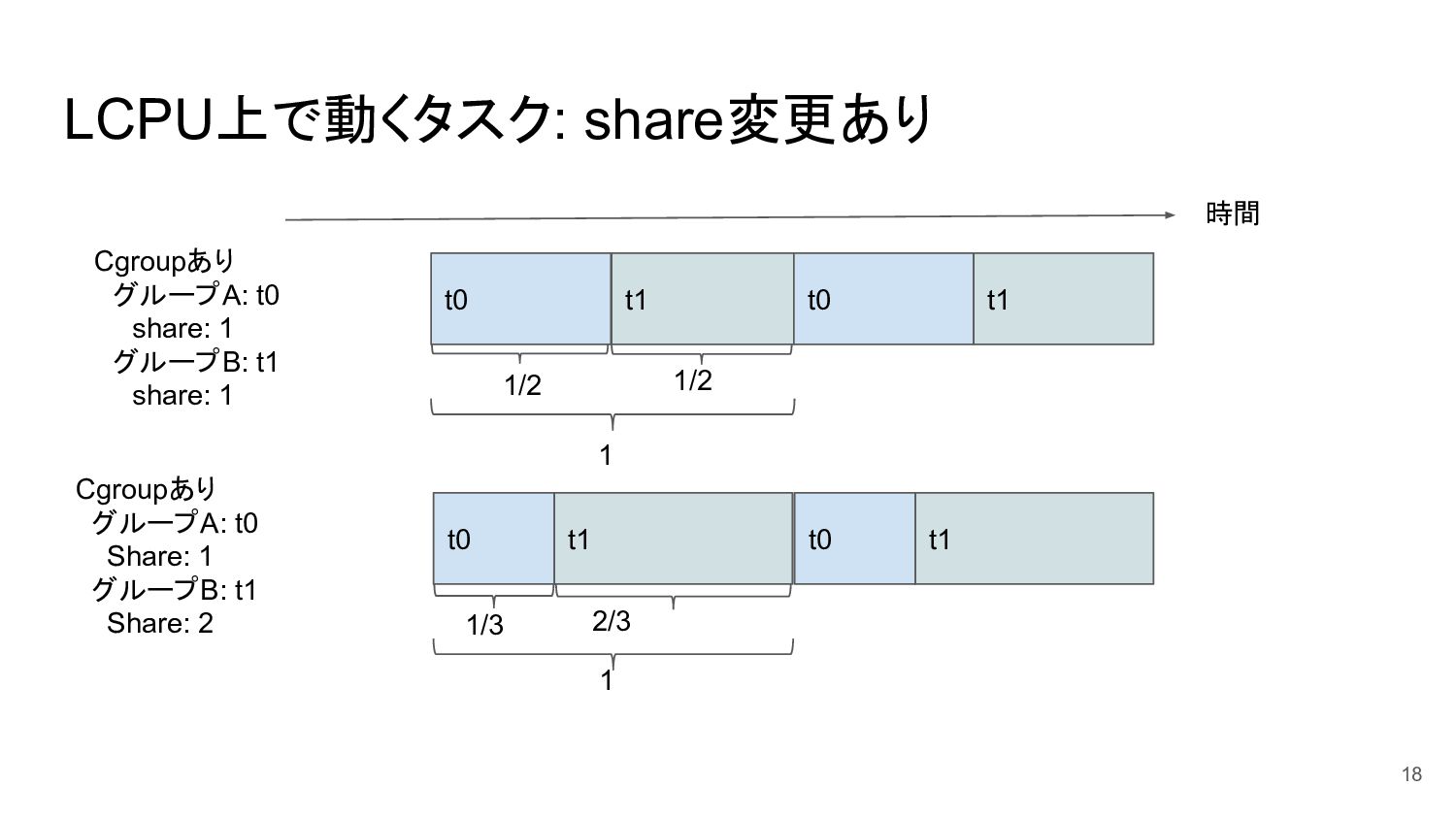
LCPU上で動くタスク: share変更あり 18 時間 t0 t1 t0 t1 Cgroupあり グループA:
t0 share: 1 グループB: t1 share: 1 Cgroupあり グループA: t0 Share: 1 グループB: t1 Share: 2 1 1/2 1/2 t0 t1 1 1/3 2/3 t0 t1
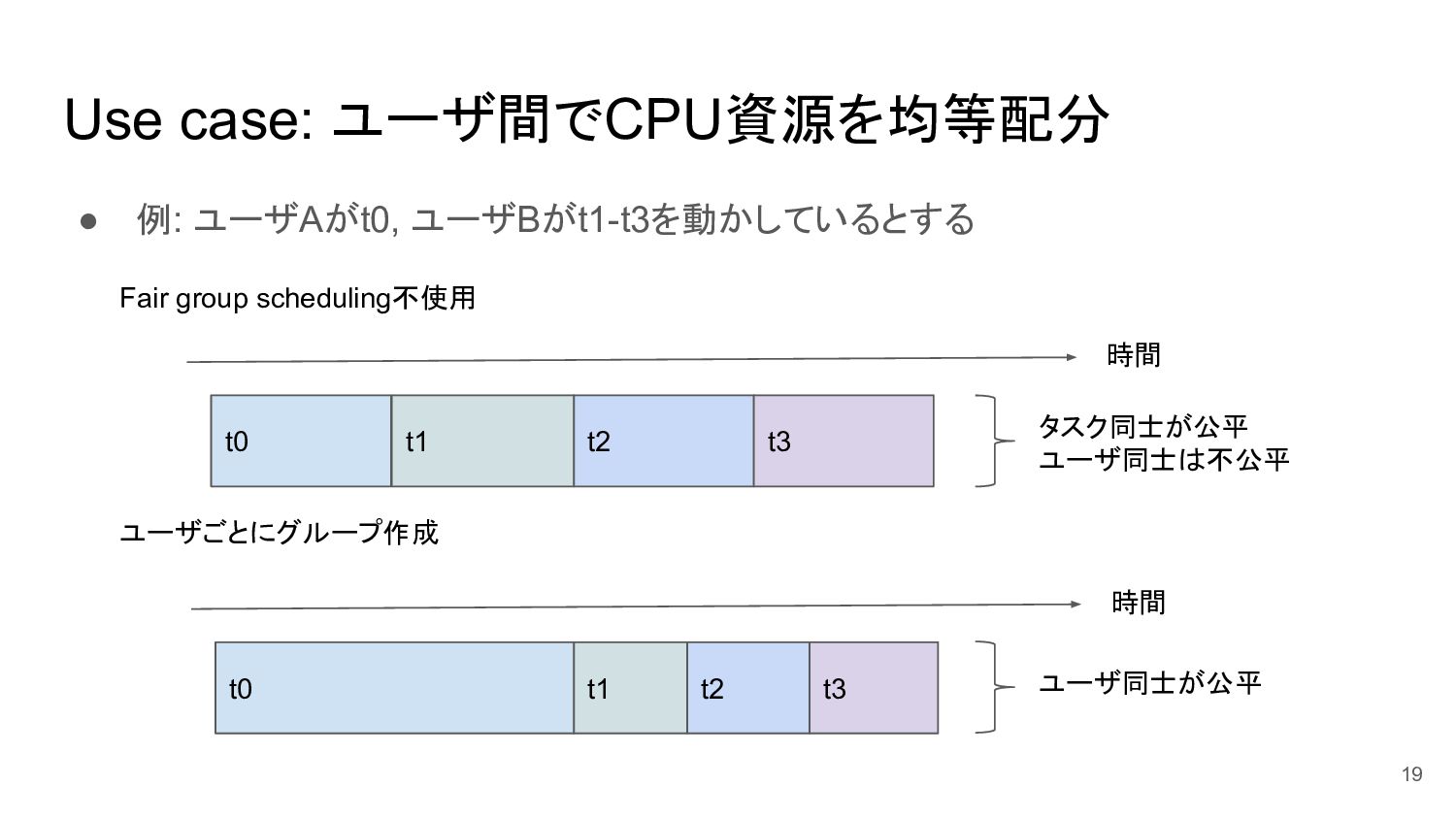
Use case: ユーザ間でCPU資源を均等配分 • 例: ユーザAがt0, ユーザBがt1-t3を動かしているとする 19 Fair group
scheduling不使用 ユーザごとにグループ作成 時間 t0 t1 t2 t3 時間 t0 t1 t2 t3 タスク同士が公平 ユーザ同士は不公平 ユーザ同士が公平
V2.6.24: cpuset cgroup • Cpusetをcgroupに統合したもの • cpusetを/dev/cpusetだけでなく/sys/fs/cgroupから操作可能に 20
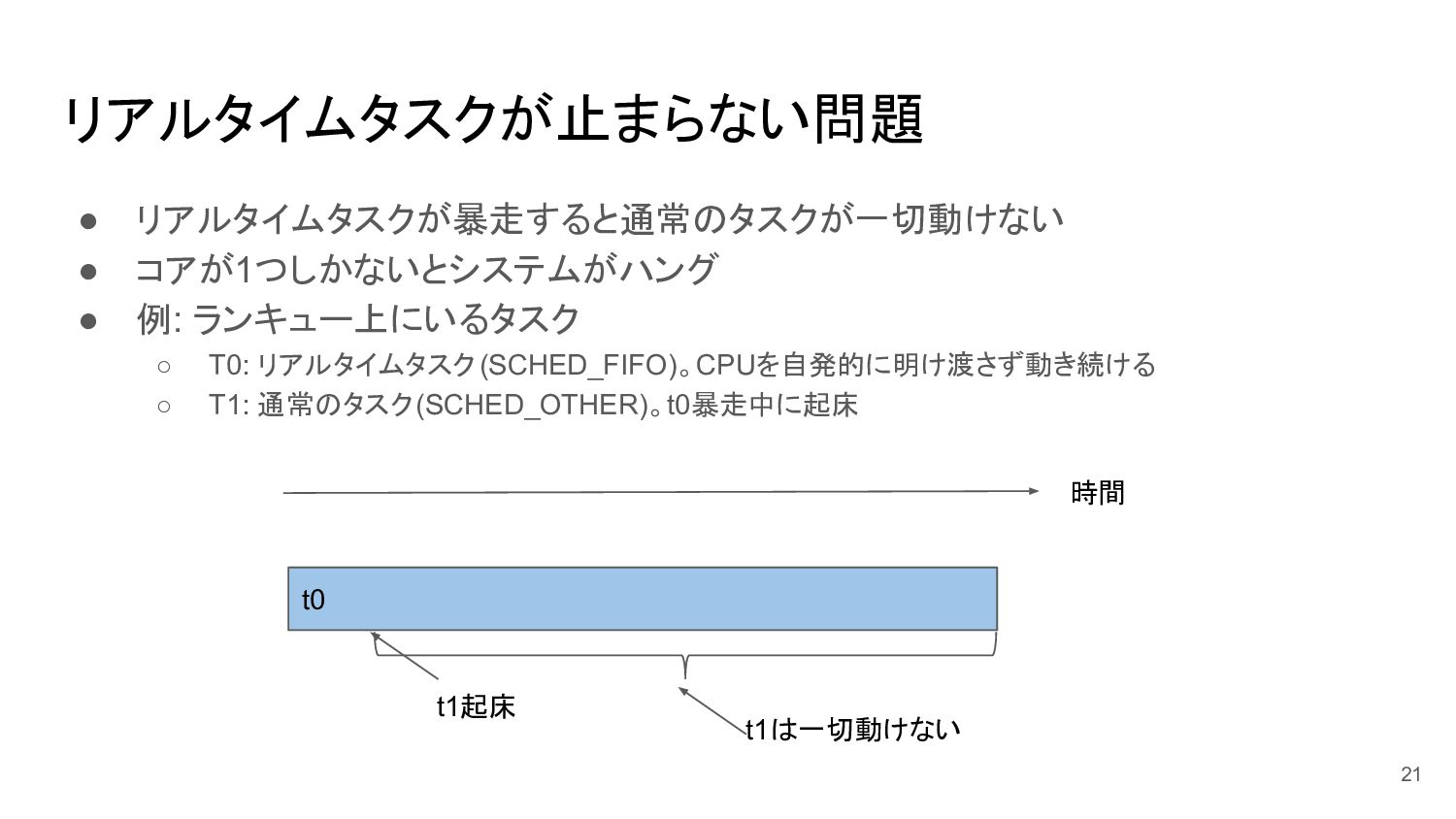
リアルタイムタスクが止まらない問題 • リアルタイムタスクが暴走すると通常のタスクが一切動けない • コアが1つしかないとシステムがハング • 例: ランキュー上にいるタスク ◦ T0:
リアルタイムタスク(SCHED_FIFO)。CPUを自発的に明け渡さず動き続ける ◦ T1: 通常のタスク(SCHED_OTHER)。t0暴走中に起床 21 t0 時間 t1は一切動けない t1起床
V2.6.25: Realtime group scheduling • リアルタイムタスクは所定の期間内に一定の時間しか動作できない ◦ 所定の期間: sysctlのkernel.sched_rt_period_us(デフォルトは1000000[us]) ◦
一定の時間: sysctlのkernel.sched_rt_runtime_us(デフォルトは950000[us]) • 空いた時間に通常のタスクが動ける • Cpu cgroupのcpu.rt_{period,runtime}によって入れ子構造にできる 22 t0 時間 t1は1秒間に50msだけは動ける t1 t0 t1 t1起床
重要なカーネルスレッドが動けない問題 • 優先度最高のリアルタイムタスクがCPUを使い続けるとカーネルの重要なタスクが 動けなくなる ◦ 例: CPU hotplug時のシステムの機能をほぼ止める stop_machineという処理 •
原因: カーネルタスクの最高優先度 == ユーザタスクの最高優先度 23
V2.6.37: Stop scheduling class • 全てのユーザプロセスに優先して動くカーネル専用スケジューリングクラス • スケジューリングクラス(優先度順) 1. (new)
Stop_sched_class 2. Rt_sched_class 3. fair_sched_class 24
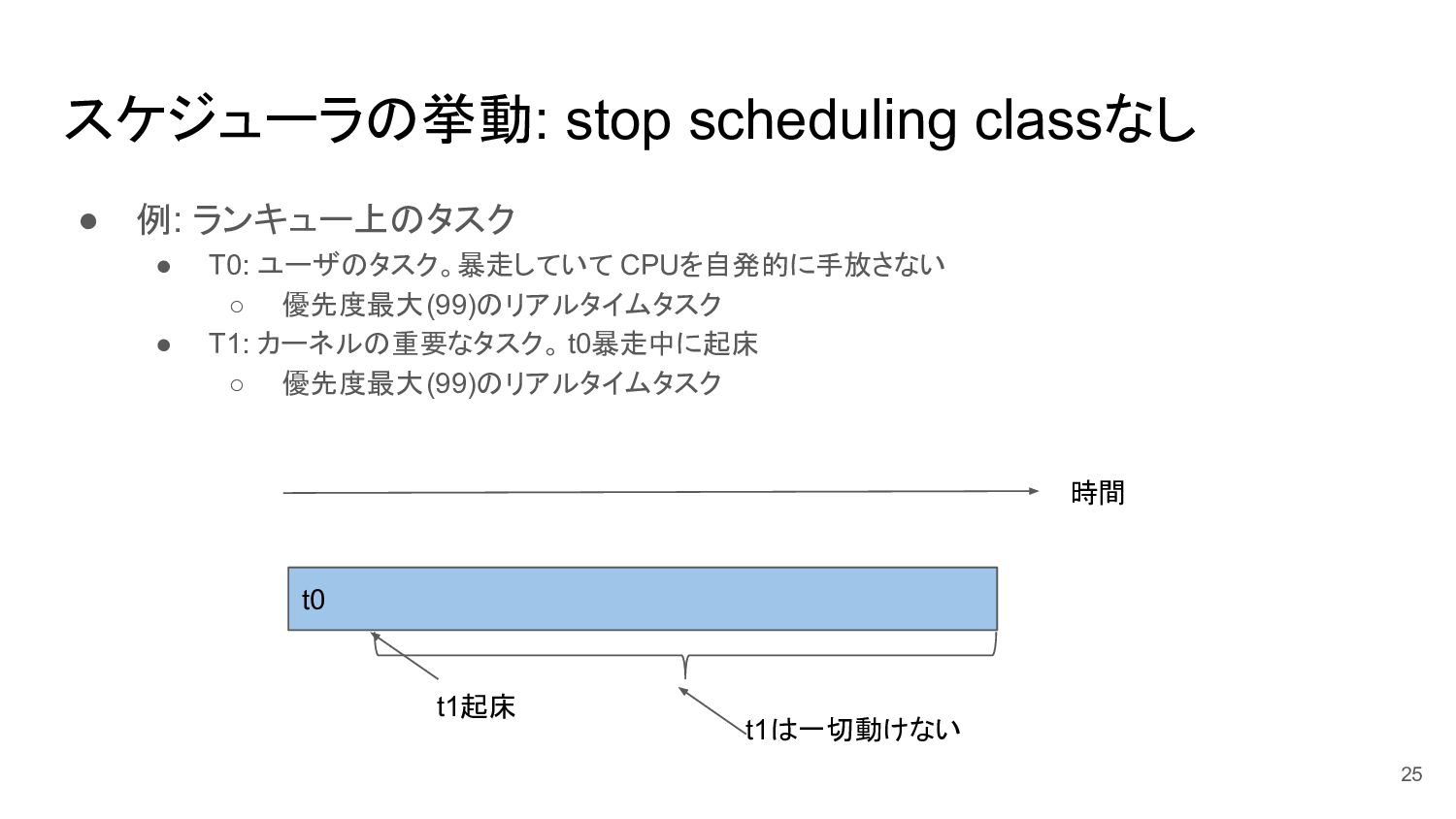
スケジューラの挙動: stop scheduling classなし • 例: ランキュー上のタスク • T0: ユーザのタスク。暴走していて
CPUを自発的に手放さない ◦ 優先度最大(99)のリアルタイムタスク • T1: カーネルの重要なタスク。 t0暴走中に起床 ◦ 優先度最大(99)のリアルタイムタスク 25 t0 時間 t1は一切動けない t1起床
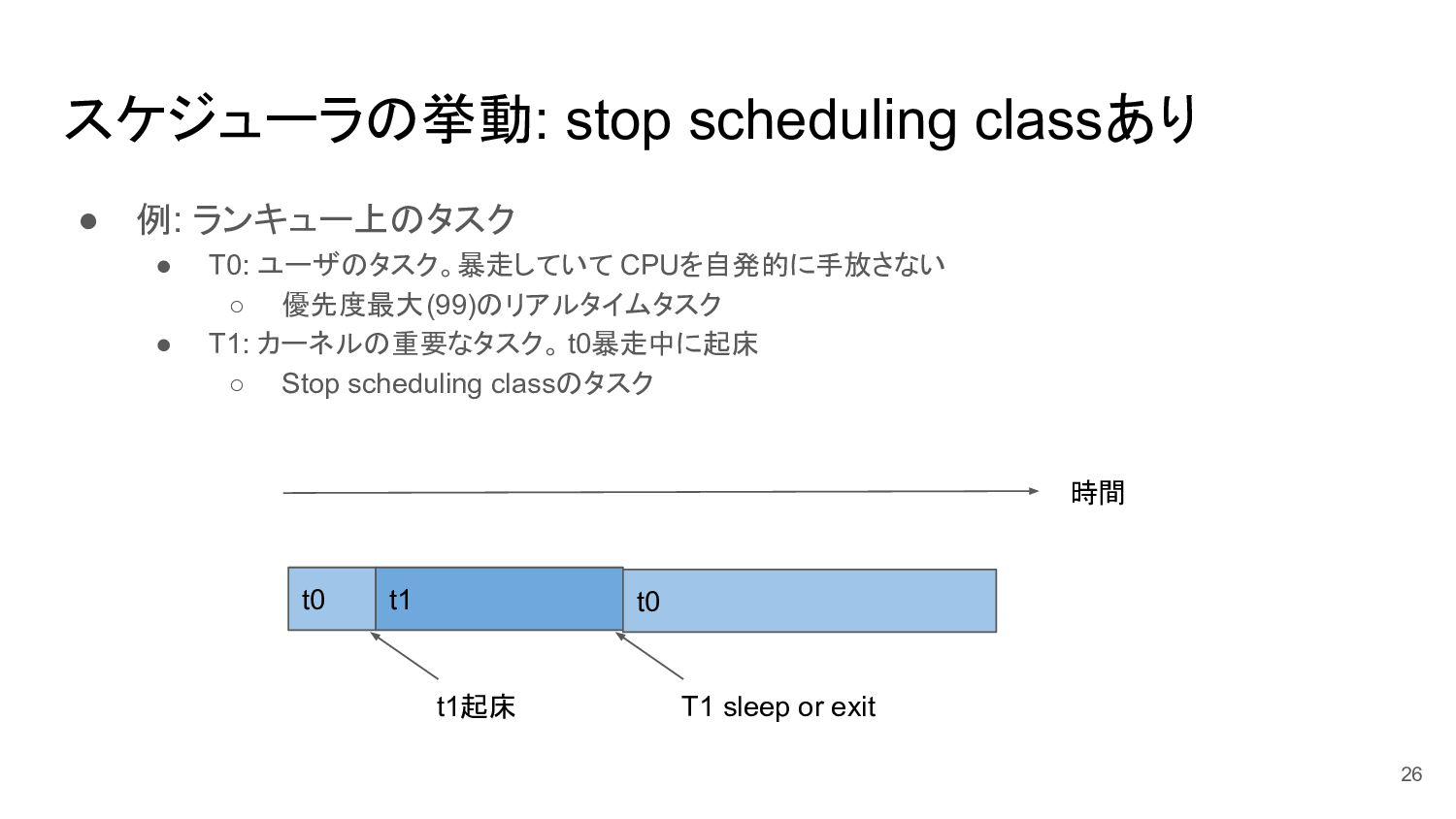
スケジューラの挙動: stop scheduling classあり • 例: ランキュー上のタスク • T0: ユーザのタスク。暴走していて
CPUを自発的に手放さない ◦ 優先度最大(99)のリアルタイムタスク • T1: カーネルの重要なタスク。 t0暴走中に起床 ◦ Stop scheduling classのタスク 26 t0 時間 t1起床 t1 t0 T1 sleep or exit
Con Kolivas氏、再び • Brain Fuck Scheduler(BFS)というスケジューラを引っ提げてLKMLに帰還 • 「mainlineに入れるつもりは無い」と最初から宣言 27 待たせたな
しばらくしたらフェードアウト 28 じゃあの
V2.6.38: autogroup • システム高負荷時におけるデスクトップ環境の応答性向上機能 ◦ 通称ミラクルパッチ • アイデア ◦ セッションごとにタスクを自動的にグループ分け
◦ グループごとに平等に CPU資源を与える • Linus氏が「小さい効果で効果が大きい」と大絶賛。パッチ投稿後速攻マージ • しかしこれも一部ケースを救うだけ ◦ 例: デスクトップアプリを動かす横でカーネルビルドをぶん回す非常に一般的なワークロード 29
Fair group schedulingの課題: 上限設定ができない • 例: 2ユーザA, B同居のマルチテナントシステム ◦ やりたいこと:
個々のユーザにCPU資源を”最大”1/2与えたい ▪ ユーザ間の不平等、過剰なサービスの提供を避けたい ◦ Fair group schedulingにできること: ユーザごとにグループ作成 30 時間 Aだけがタスクを動かしている状態 (あるべき姿) Aのタスク Aだけがタスクを動かしている状態 (現実) Aのタスク idle Aのタスク idle
V3.2: CFS bandwidth controller • あるcpu cgroupが所定期間内に動ける時間を制限 ◦ cpu.Cfs_period: 期間([us]単位)
◦ Cpu.cfs_quota: 動ける時間([us]単位) • ネストも可能 • コンテナやVMのリソース制限に使われる 31
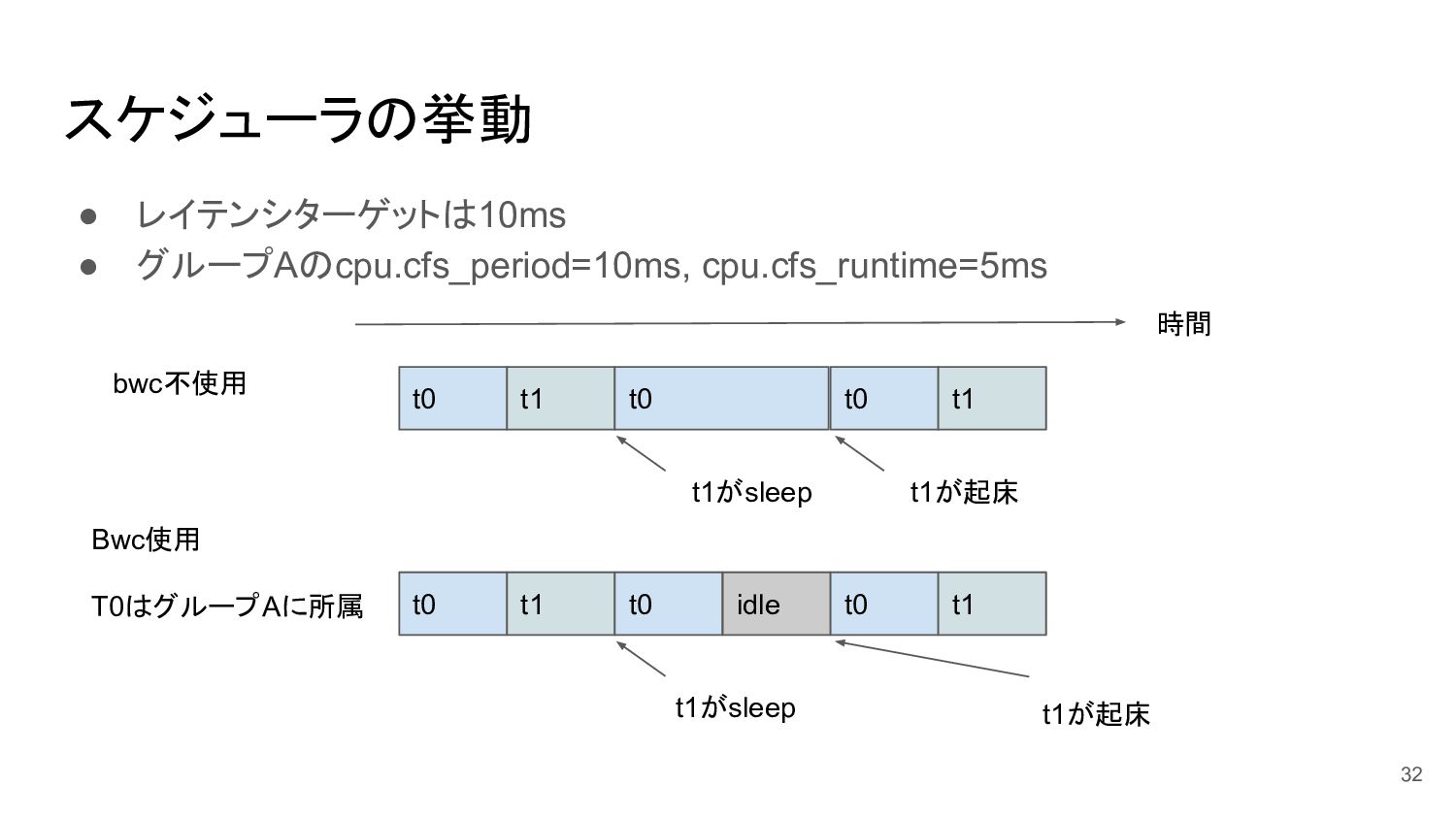
スケジューラの挙動 • レイテンシターゲットは10ms • グループAのcpu.cfs_period=10ms, cpu.cfs_runtime=5ms 32 時間 t0 t1
t0 t0 t1 bwc不使用 t1がsleep t1が起床 t0 t1 t0 idle t0 t1 Bwc使用 T0はグループAに所属 t1がsleep t1が起床
V3.14: Deadlineスケジューラ • 所定の期間中にどれだけのCPU時間を使うかを設定できる • rootのみ使える • スケジューリングクラス 1. Stop_sched_class
2. (new) Deadline_sched_class 3. Rt_sched_class 4. Fair_sched_class • sched_setscheduler() or sched_setparam()で以下3つのパラメタを与える 1. Period: タスクはperiodで示された期間中に最大 1度動作 2. Runtime: タスクが一度起床してから sleepするまでの計算所要時間 3. deadline: タスクが起床してから計算を終了しなくてはならない期間 33
v4.18 • マイナーチェンジ中心、機能的にはあんまり変わってない(はず) 34
まとめ • CFSの導入 • Cgroupによるfair share scheduler, bandwidth controllerの導入 •
Deadline schedulerの導入 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![スケジューラの挙動: 初期状態 • 仮定 ◦ レイテンシターゲット : 10 [ms] •](https://files.speakerdeck.com/presentations/0b9f5901d4264ff5938d6db4c14809b1/slide_5.jpg){kind=link}
{kind=link}
![タイムスライス切れまで動かす • 10/3 [ms]動くとvruntimeが1.0増えるよう計算 8 0 0 t1 t2 LCPU](https://files.speakerdeck.com/presentations/0b9f5901d4264ff5938d6db4c14809b1/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![vruntimeをrunnableタスク内最小値にしてランキューに挿入 • vruntime=15のタスクの残りタイムスライス ◦ (2.0-1.5)*(10/3)=1.67 [ms] → (2.0-1.5)*(10/4) = 1.25](https://files.speakerdeck.com/presentations/0b9f5901d4264ff5938d6db4c14809b1/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![V2.6.25: Realtime group scheduling • リアルタイムタスクは所定の期間内に一定の時間しか動作できない ◦ 所定の期間: sysctlのkernel.sched_rt_period_us(デフォルトは1000000[us]) ◦](https://files.speakerdeck.com/presentations/0b9f5901d4264ff5938d6db4c14809b1/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![V3.2: CFS bandwidth controller • あるcpu cgroupが所定期間内に動ける時間を制限 ◦ cpu.Cfs_period: 期間([us]単位)](https://files.speakerdeck.com/presentations/0b9f5901d4264ff5938d6db4c14809b1/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}