Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
実践オブザーバビリティ
Search
Satoru Takeuchi
PRO
March 11, 2022
Technology
1.2k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
実践オブザーバビリティ
Observability Conference 2022の発表スライドです
https://event.cloudnativedays.jp/o11y2022/talks/1357
Satoru Takeuchi
PRO
March 11, 2022
More Decks by Satoru Takeuchi
See All by Satoru Takeuchi
Machine Check Exception
sat
PRO
2
36
バイナリダンプの模様を読む
sat
PRO
0
68
cpコマンドはディスク上でデータを コピーしないことがある
sat
PRO
3
54
114-ファイルのshallow_copy.pdf
sat
PRO
2
38
113-Btrfsのスナップショット.pdf
sat
PRO
0
16
システム強制終了時にファイルシステムの整合性を保つ~ コピーオンライト編 ~
sat
PRO
0
59
システム強制終了時に ファイルシステムの整合性を保つ ~ ジャーナリング編 ~
sat
PRO
2
63
ファイルシステムの整合性を回復するfsck
sat
PRO
1
65
小学校5,6年生向けキャリア教育 大人になるまでの道
sat
PRO
8
5.3k
Other Decks in Technology
See All in Technology
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
170
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
180
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
410
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
シンガポールで登壇してきます
yama3133
0
240
知らん間に、回ってる
ming_ayami
0
690
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.4k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
220
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
0
120
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
240
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
4
3.9k
OPENLOGI Company Profile for engineer
hr01
1
74k
Featured
See All Featured
Being A Developer After 40
akosma
91
590k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Become a Pro
speakerdeck
PRO
31
6k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Building Adaptive Systems
keathley
44
3.1k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Transcript
実践オブザーバビリティ プロダクショングレード監視/ログ基盤とその実用例 Mar. 11th, 2022 サイボウズ ストレージチーム sat 1
もくじ 2 ▌前提知識 ▌サイボウズの監視/ログ基盤 ▌工夫点と課題 ▌実用例
もくじ 3 ▌前提知識 ▌サイボウズの監視/ログ基盤 ▌工夫点と課題 ▌実用例
オブザーバビリティとは ▌システムが外部提供する情報から内部状態を観測できること ▌オブザーバビリティが高いシステムの例 ⚫サービスを提供できているかを観測できる ⚫サービスのレスポンス時間を観測できる ⚫ストレージの容量が足りているかを観測できる 4
システムが外部提供する情報 ▌メトリクス: システムの状態を定量化したもの ⚫例: リクエストが一秒あたりに完了した数 ▌ログ: システムに起きたことを記録したもの ⚫例: “<時刻> request
completed in 0.3 secs”のような文字列 5
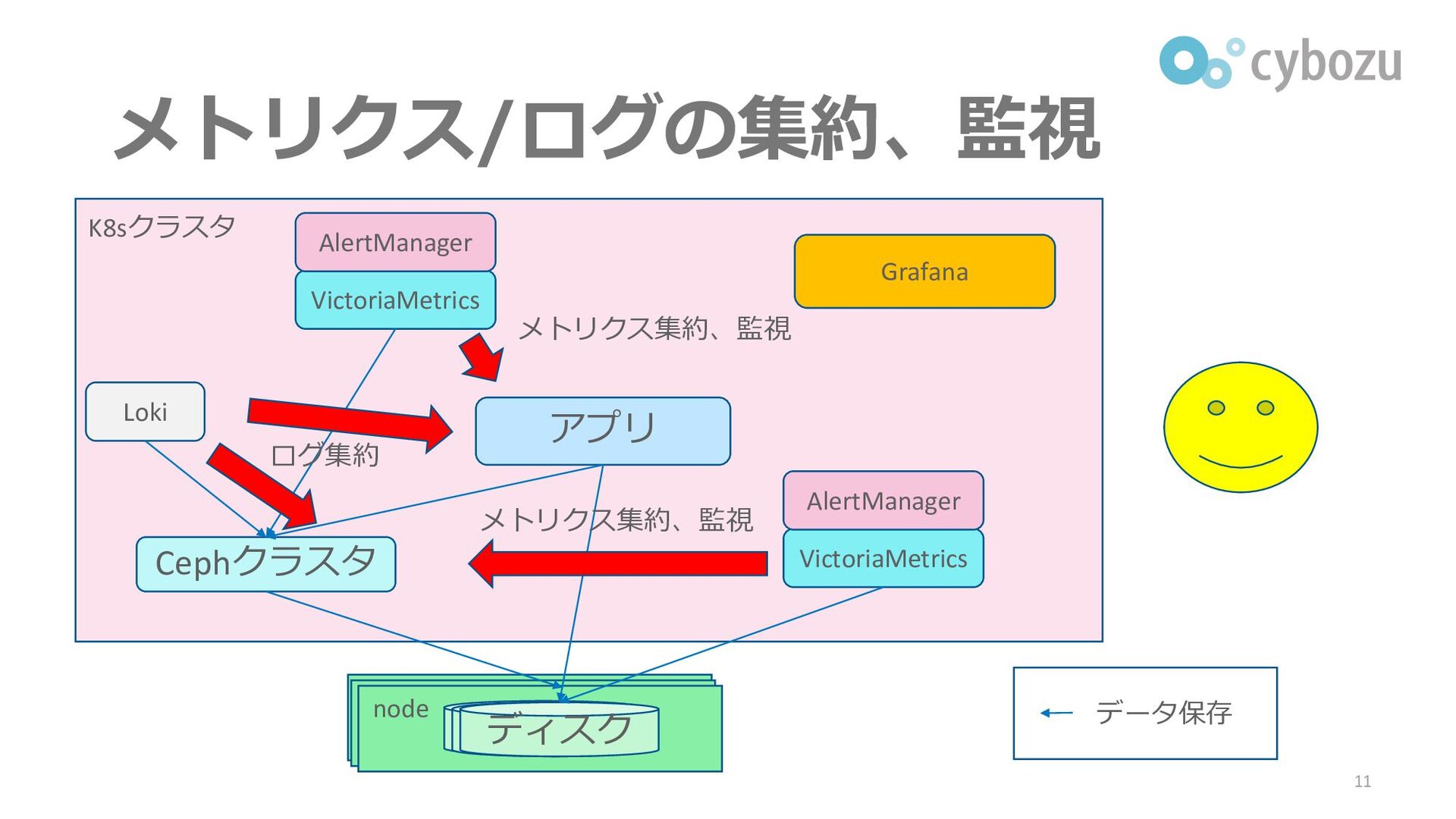
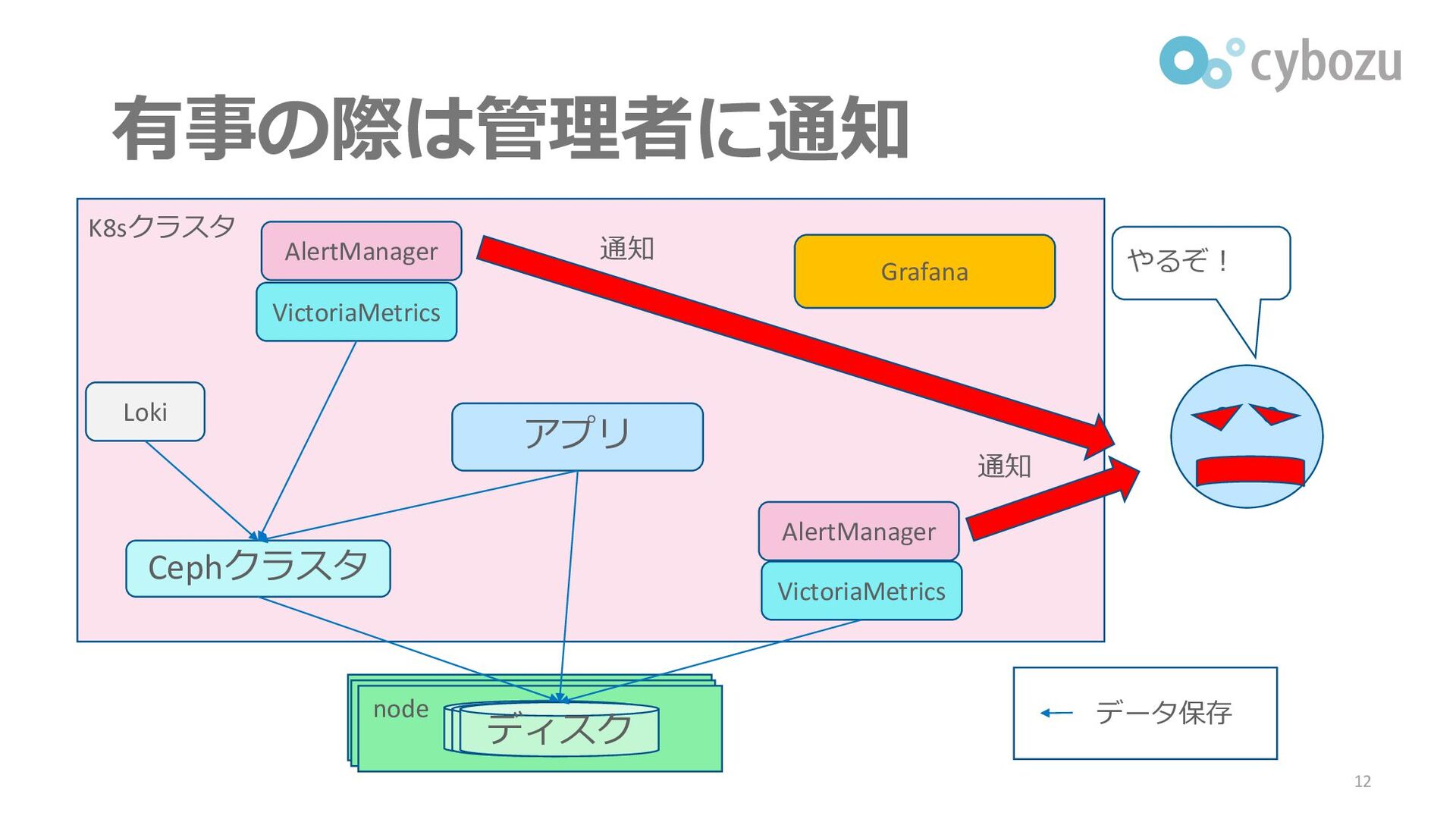
オブザーバビリティを高める手段 ▌メトリクス/ログの集約 ▌集約したメトリクスの監視(モニタリング) ▌監視によって検出した異常を通知(アラート) ▌メトリクス/ログの分析、可視化 6
もくじ 7 ▌前提知識 ▌サイボウズの監視/ログ基盤 ▌工夫点と課題 ▌実用例
サイボウズで開発中のインフラ ▌オンプレのKubernetes(K8s)クラスタ ▌マルチテナント ⚫ 1つのK8sクラスタにあらゆるアプリ(Pod)が同居 8 …
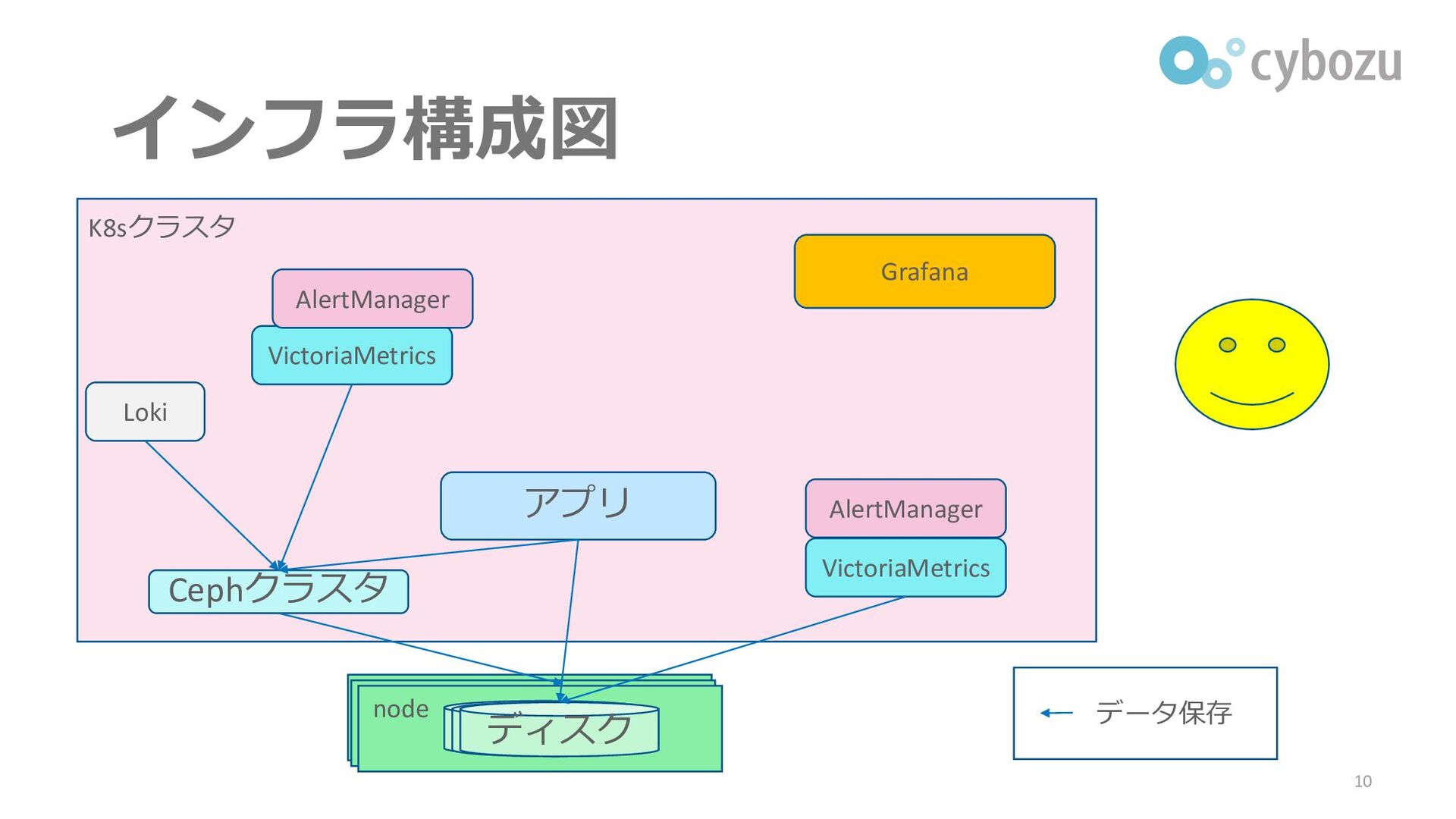
監視/ログ基盤に採用したソフトウェア ▌監視基盤 ⚫VictoriaMetrics: メトリクスの集約、監視 ⚫Alertmanager: 通知 ▌ログ基盤 ⚫Loki: ログの集約 ▌可視化、分析
⚫Grafana: ダッシュボード、VictoriaMetricsとLokiへのクエリ発行 9
インフラ構成図 10 Cephクラスタ HDD node HDD ディスク アプリ Loki VictoriaMetrics
VictoriaMetrics Grafana AlertManager AlertManager K8sクラスタ データ保存
メトリクス/ログの集約、監視 11 Cephクラスタ HDD node HDD ディスク アプリ Loki VictoriaMetrics
VictoriaMetrics Grafana ログ集約 メトリクス集約、監視 メトリクス集約、監視 AlertManager AlertManager K8sクラスタ データ保存
有事の際は管理者に通知 12 Cephクラスタ HDD node HDD ディスク アプリ Loki VictoriaMetrics
VictoriaMetrics Grafana 通知 通知 AlertManager AlertManager K8sクラスタ データ保存 やるぞ!
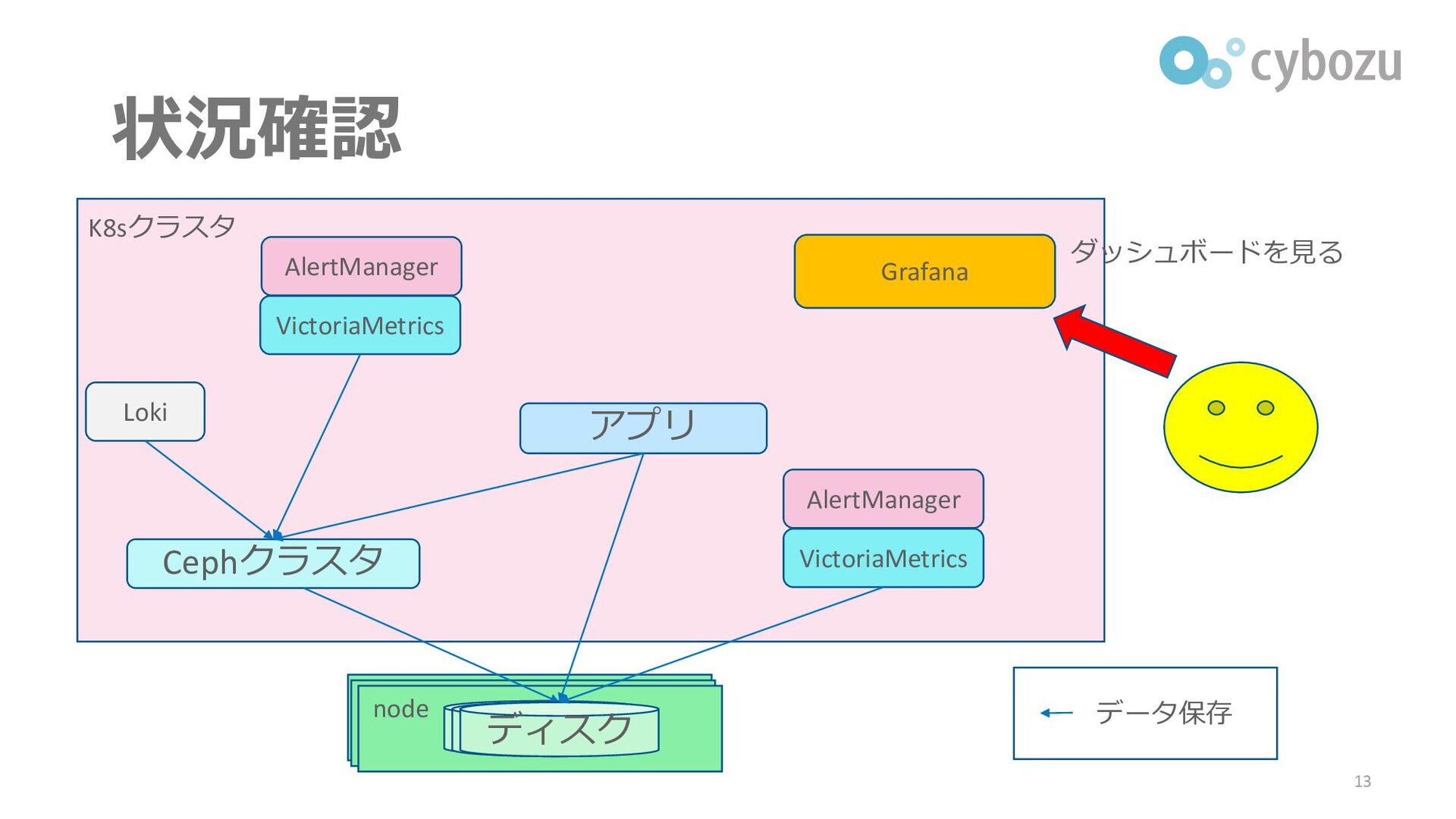
状況確認 13 Cephクラスタ HDD node HDD ディスク アプリ Loki VictoriaMetrics
VictoriaMetrics Grafana ダッシュボードを見る AlertManager AlertManager K8sクラスタ データ保存
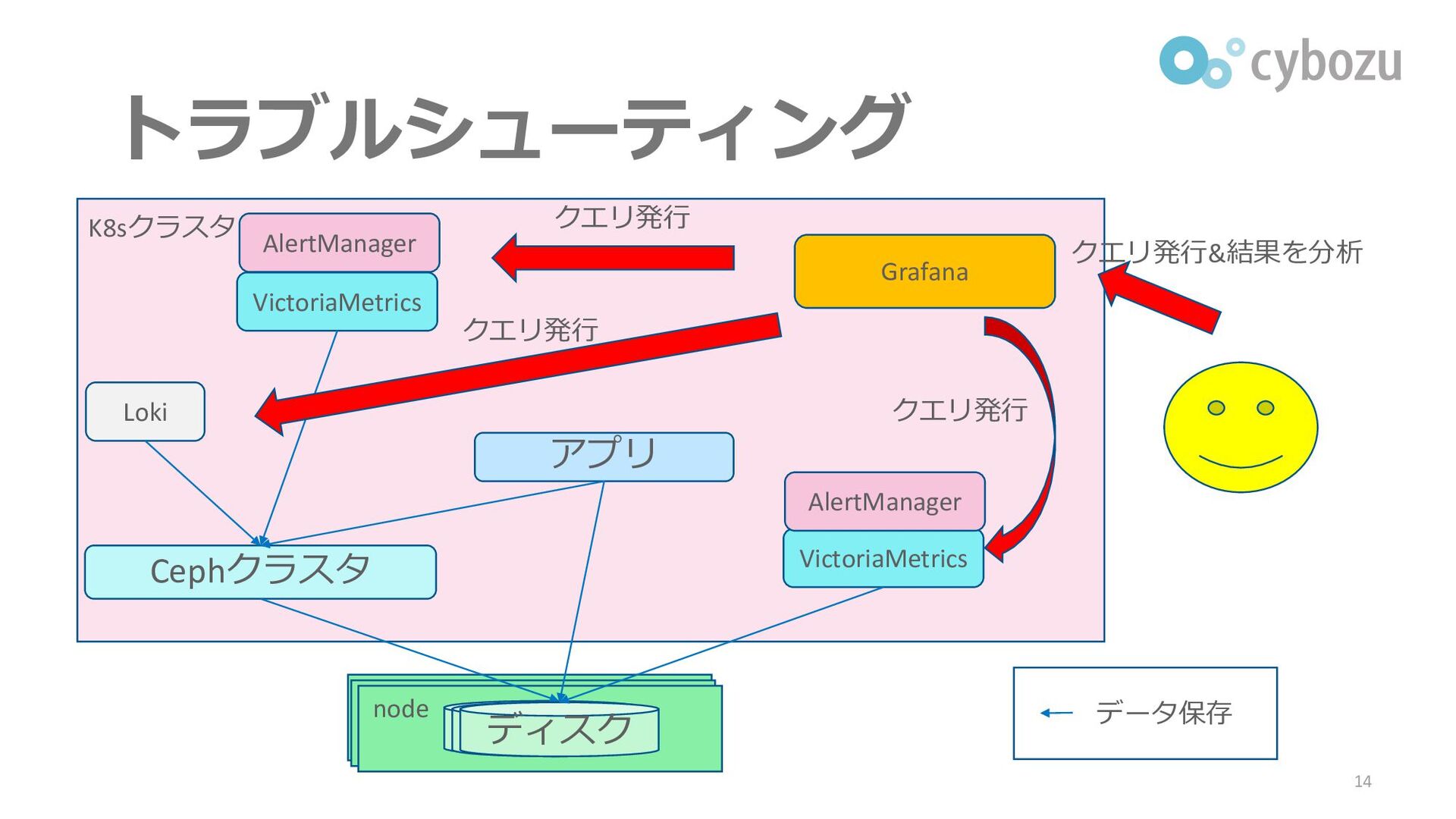
トラブルシューティング 14 Cephクラスタ HDD node HDD ディスク アプリ Loki VictoriaMetrics
VictoriaMetrics Grafana クエリ発行&結果を分析 クエリ発行 クエリ発行 クエリ発行 AlertManager AlertManager K8sクラスタ データ保存
その他Grafanaへのアクセス契機 ▌定期的なダッシュボード確認 ⚫前回確認時以降、変わったところがないか ⚫「何が正常か」を知るのに役立つ ▌インフラユーザからの連絡 ⚫できればなくしたい ⚫問題解決後に、自動検出できるよう改善を検討 15
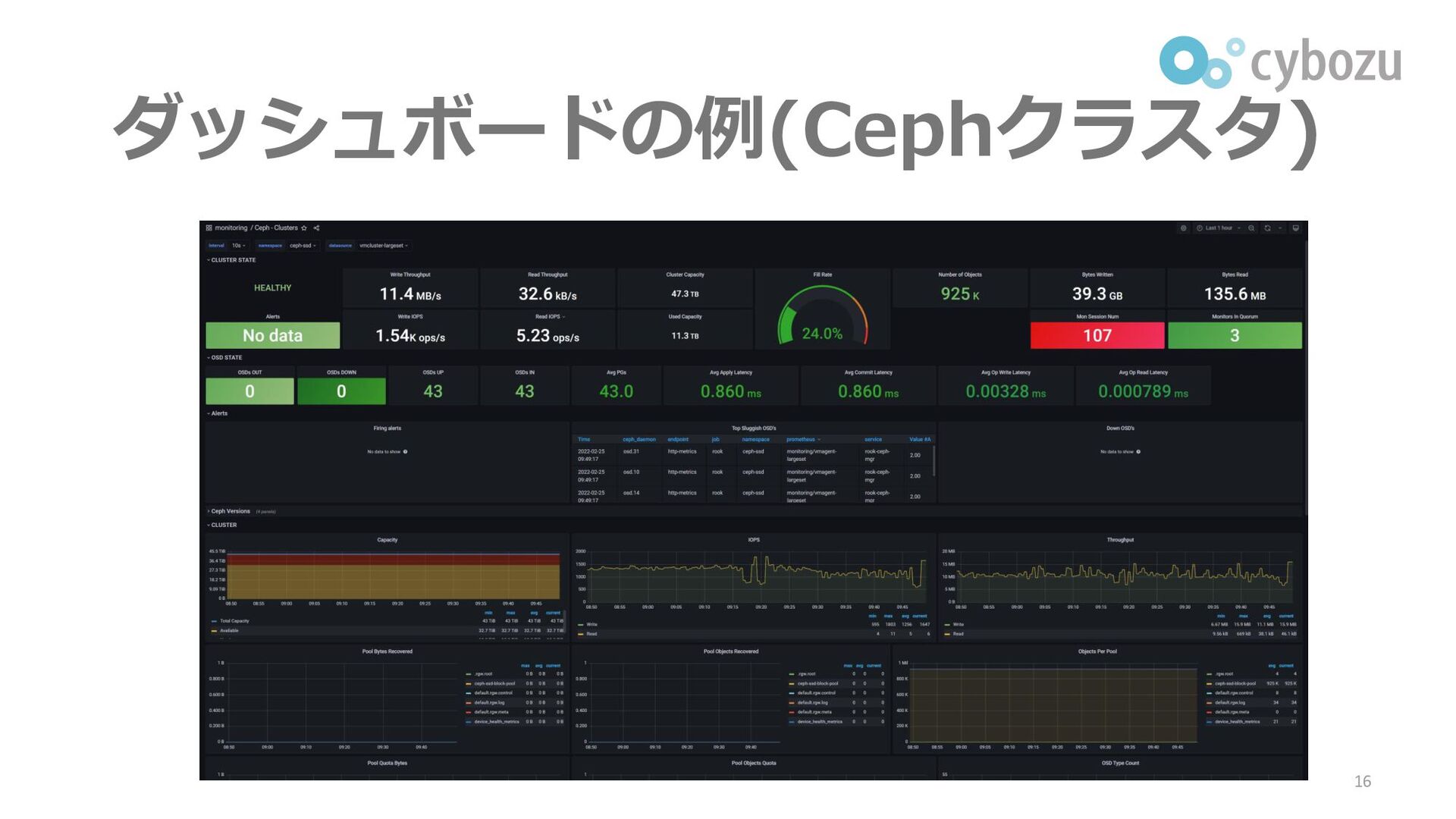
ダッシュボードの例(Cephクラスタ) 16
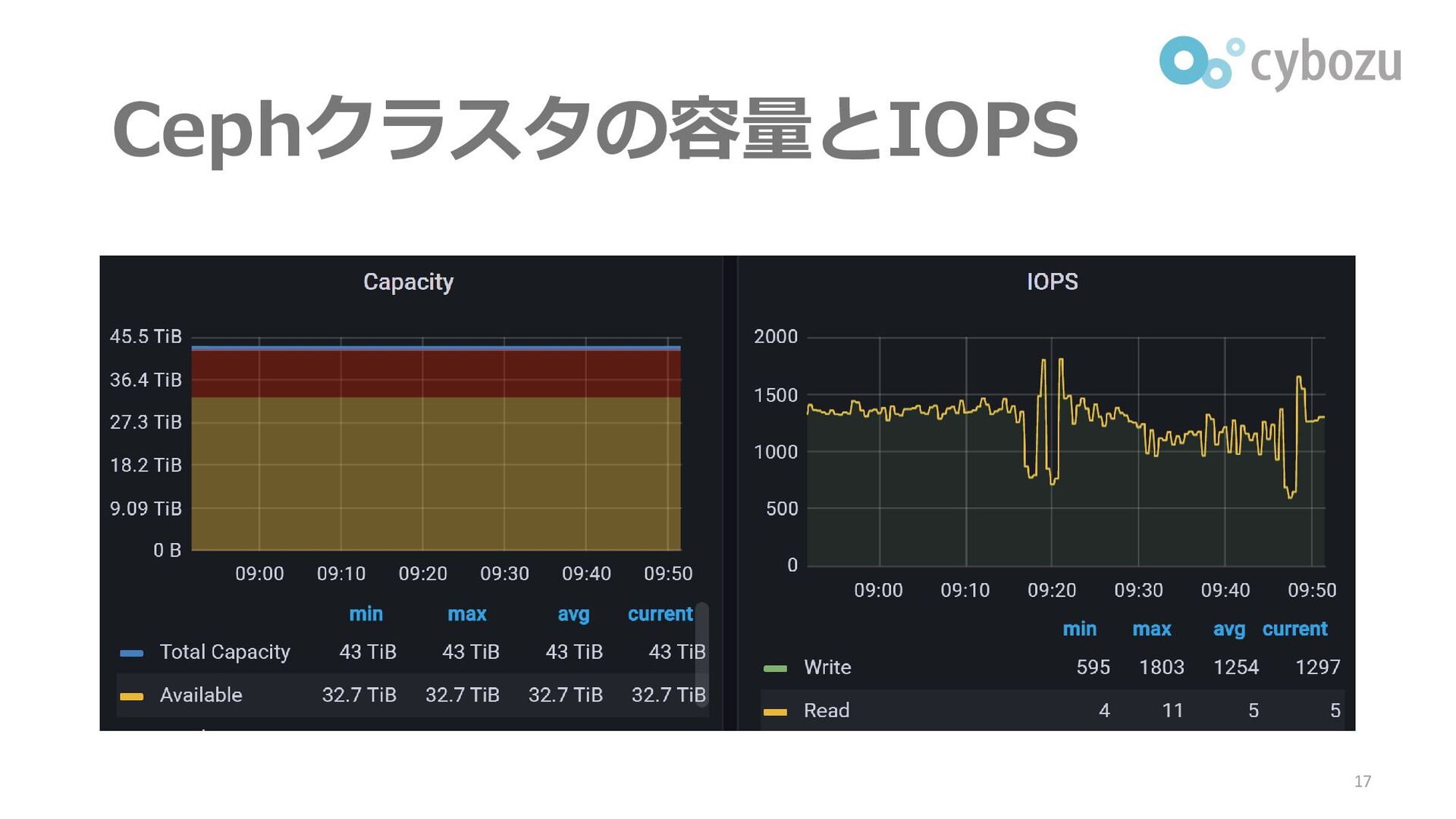
Cephクラスタの容量とIOPS 17
成果は全てOSSとして公開 ▌監視基盤 ⚫https://github.com/cybozu-go/neco-apps/tree/main/monitoring ▌ログ基盤 ⚫https://github.com/cybozu-go/neco-apps/tree/main/logging 18
もくじ 19 ▌前提知識 ▌サイボウズの監視/ログ基盤 ▌工夫点と課題 ▌実用例
工夫点: VictoriaMetricの採用 ▌Prometheus互換 ⚫様々な外部ツールが対応 ▌組み込み機能によってHA構成可能 ⚫構成がシンプルにできる ▌データストアが長期保存向け 20
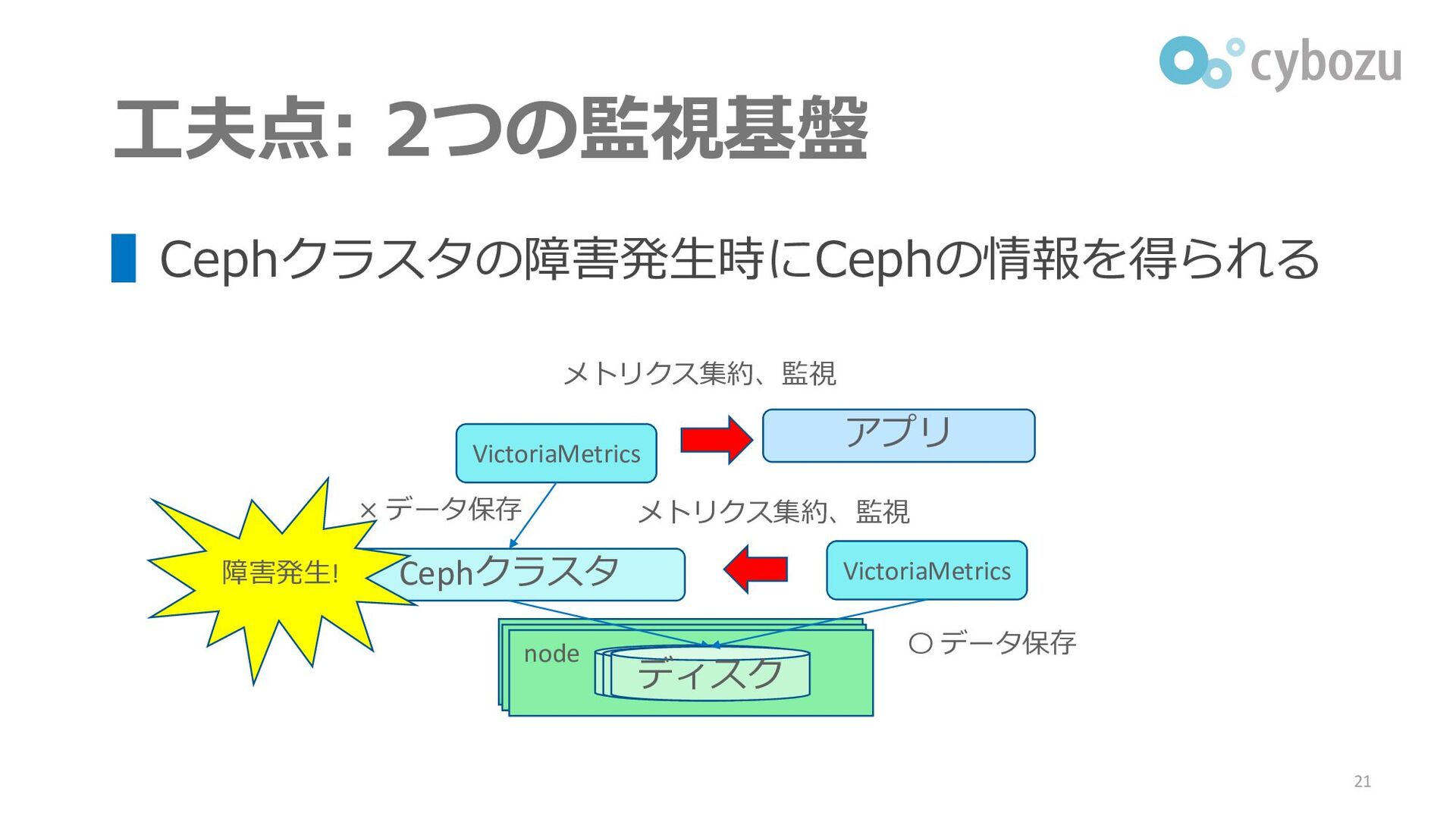
工夫点: 2つの監視基盤 ▌Cephクラスタの障害発生時にCephの情報を得られる 21 Cephクラスタ HDD node HDD ディスク VictoriaMetrics
VictoriaMetrics アプリ メトリクス集約、監視 メトリクス集約、監視 障害発生! × データ保存 〇 データ保存
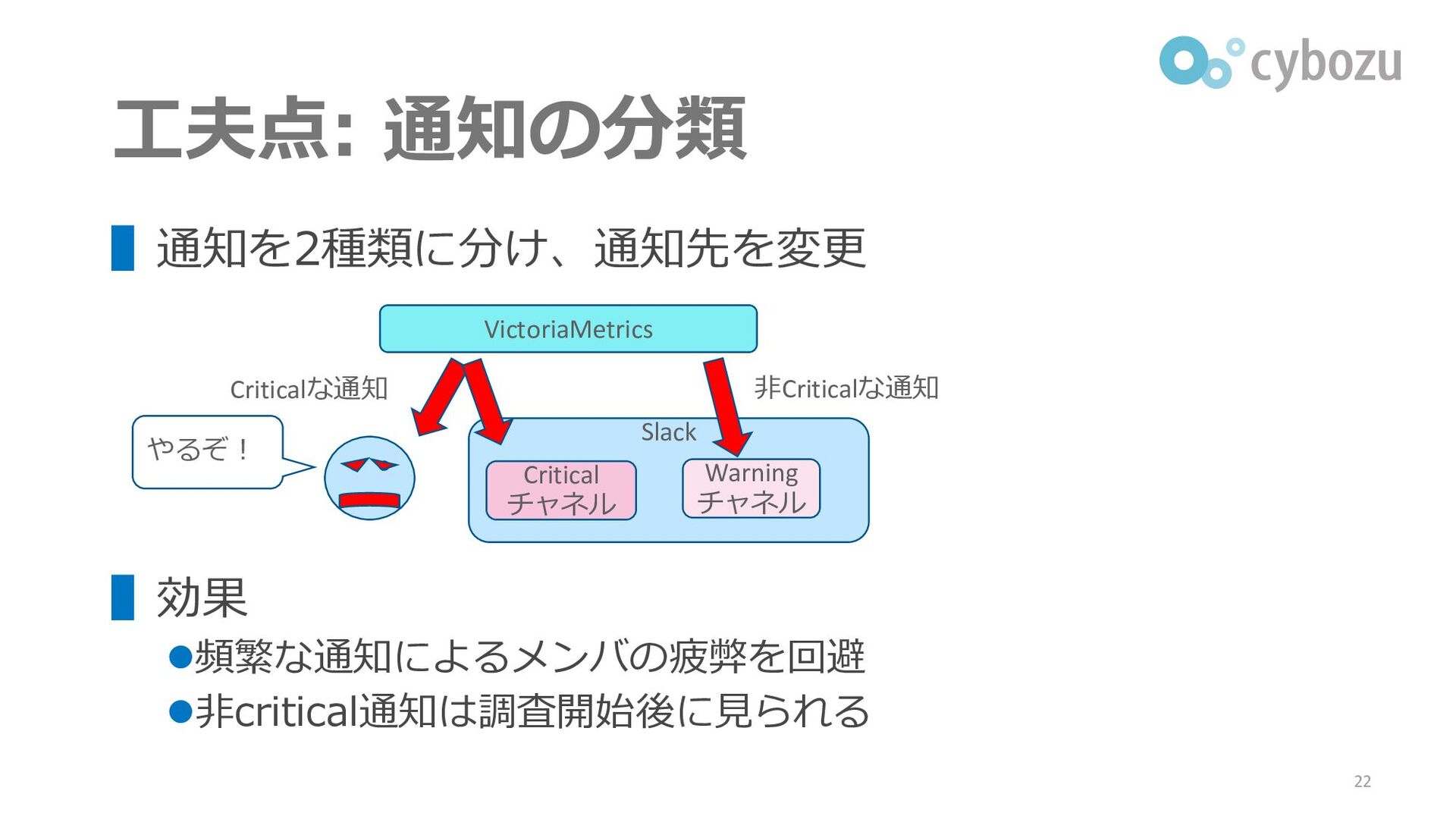
工夫点: 通知の分類 ▌通知を2種類に分け、通知先を変更 ▌効果 ⚫頻繁な通知によるメンバの疲弊を回避 ⚫非critical通知は調査開始後に見られる 22 VictoriaMetrics Criticalな通知 Slack
Critical チャネル Warning チャネル 非Criticalな通知 やるぞ!
課題: LokiがCephに依存している ▌Cephクラスタの障害発生時にlokiにアクセスできない ▌Cephクラスタ専用のLokiを導入予定 23 Cephクラスタ HDD node HDD ディスク
Loki アプリ ログ集約、監視 障害発生! × データ保存
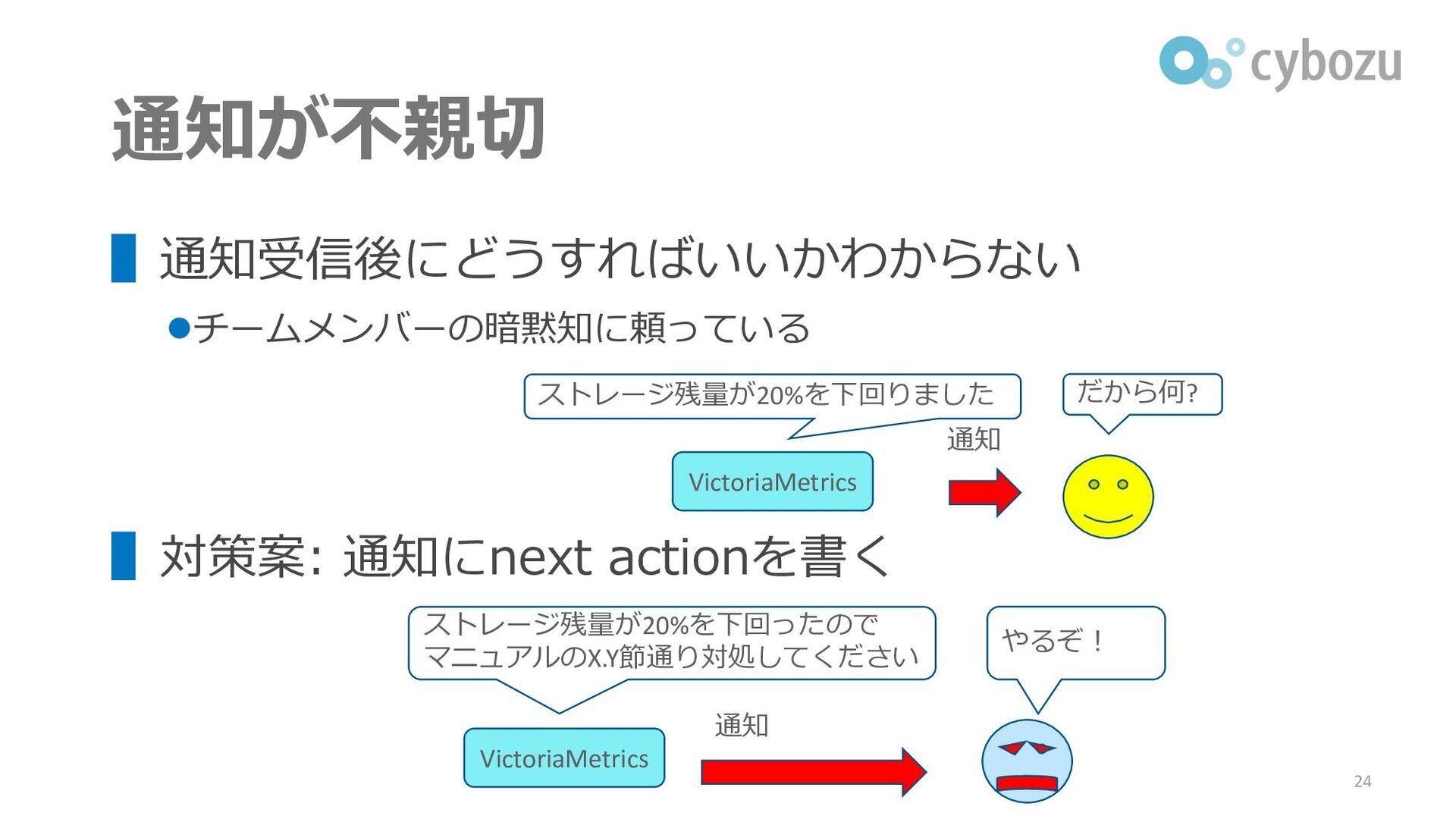
通知が不親切 ▌通知受信後にどうすればいいかわからない ⚫チームメンバーの暗黙知に頼っている ▌対策案: 通知にnext actionを書く 24 VictoriaMetrics ストレージ残量が20%を下回りました だから何?
通知 VictoriaMetrics ストレージ残量が20%を下回ったので マニュアルのX.Y節通り対処してください やるぞ! 通知
もくじ 25 ▌前提知識 ▌サイボウズの監視/ログ基盤 ▌工夫点と課題 ▌実用例
事例: オブジェクトストレージのアクセス障害 ▌前提 ⚫CephはRGWというオブジェクトストレージを提供 ▌問題 ⚫RGWにアクセスできなくなった ▌検出方法 ⚫RGW podの異常終了を示す通知が定期的に発生 26
ダッシュボードの確認 ▌アラート発生時からオブジェクト数が増えていない 27 オブジェクト数→ 時間→ オブジェクト数→ 時間→ 正常時 問題発生時
原因の候補 ▌RGW Pod自らが終了 ⚫何らかのエラーによって異常終了 ▌外部からの強制終了 ⚫例: K8sのprobeへの無応答が続くとシグナルによって強制終了 28
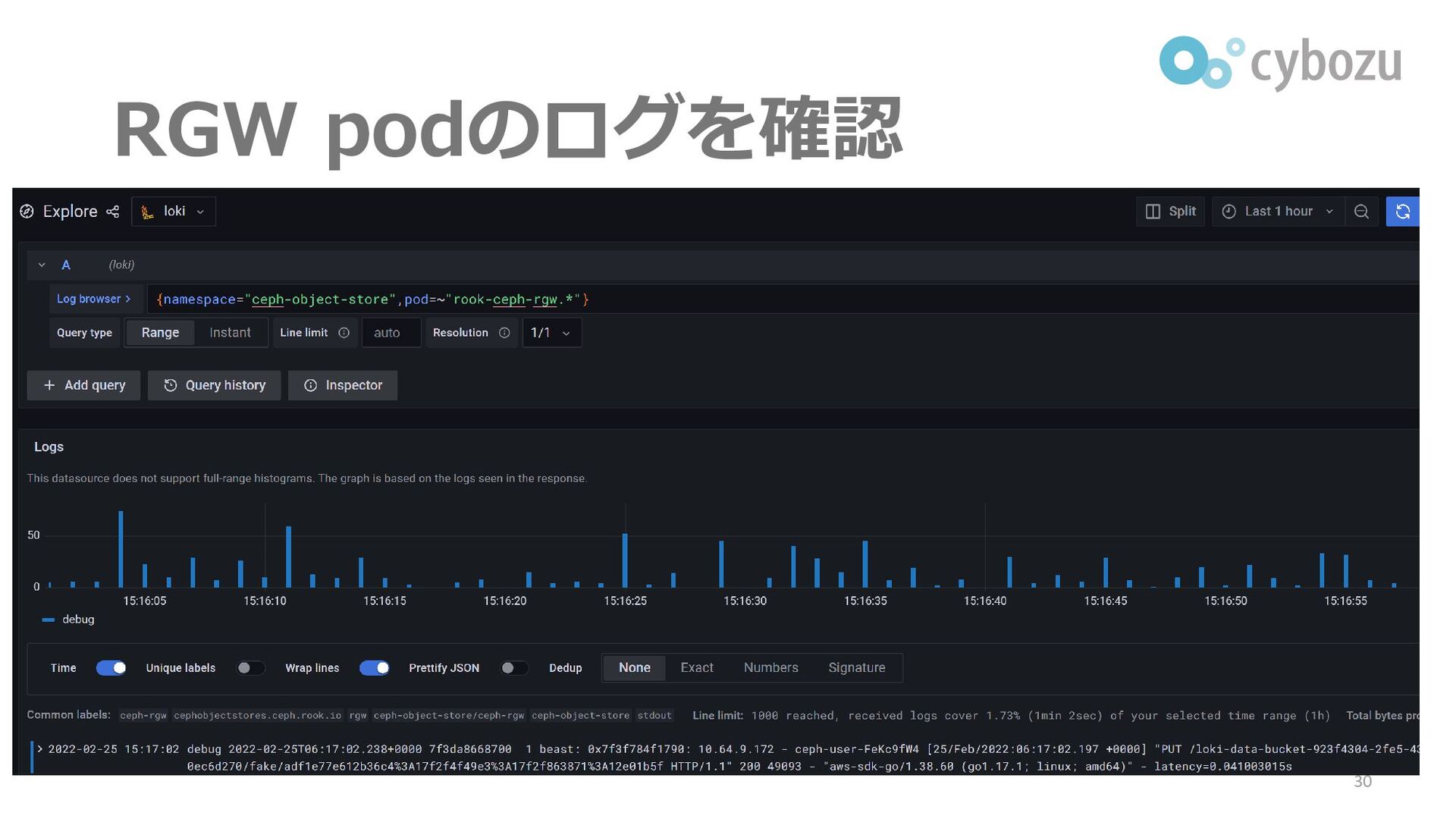
切り分け ▌RGW Pod強制終了時のログを見れば何かわかるはず ⚫RGW Podが自ら終了: エラーログが残る ⚫外部から強制終了: シグナル受信ログが残る ▌幸運: Loki上の直近のログだけは見られる
⚫LokiのストレージはCeph上に保存 ⚫古いログはRGWに保存 ⚫直近のデータはブロックデバイスに保存 29
RGW podのログを確認 30
ログを表示する期間 31
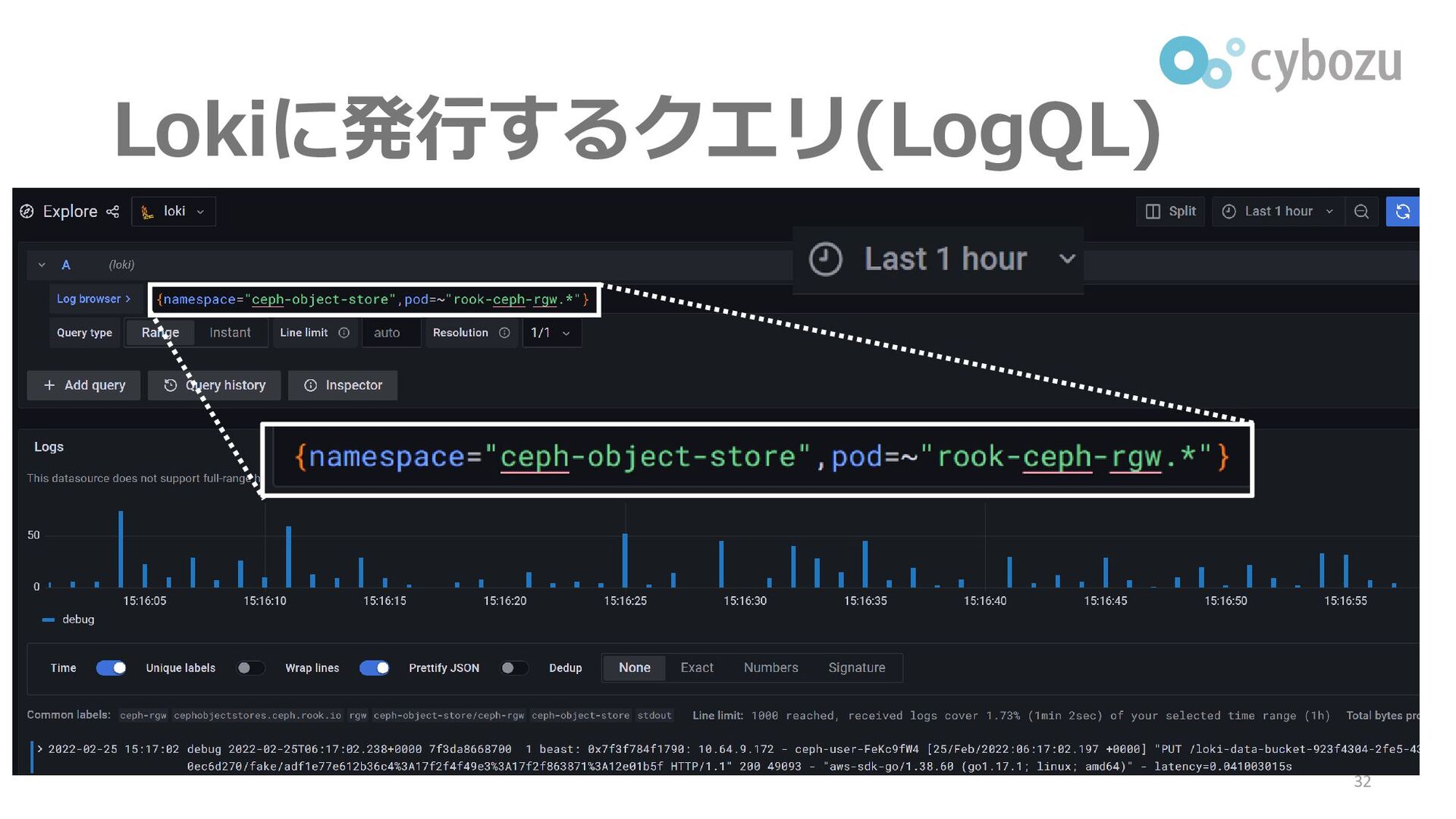
Lokiに発行するクエリ(LogQL) 32
全RGW Podのログをまとめて表示 33
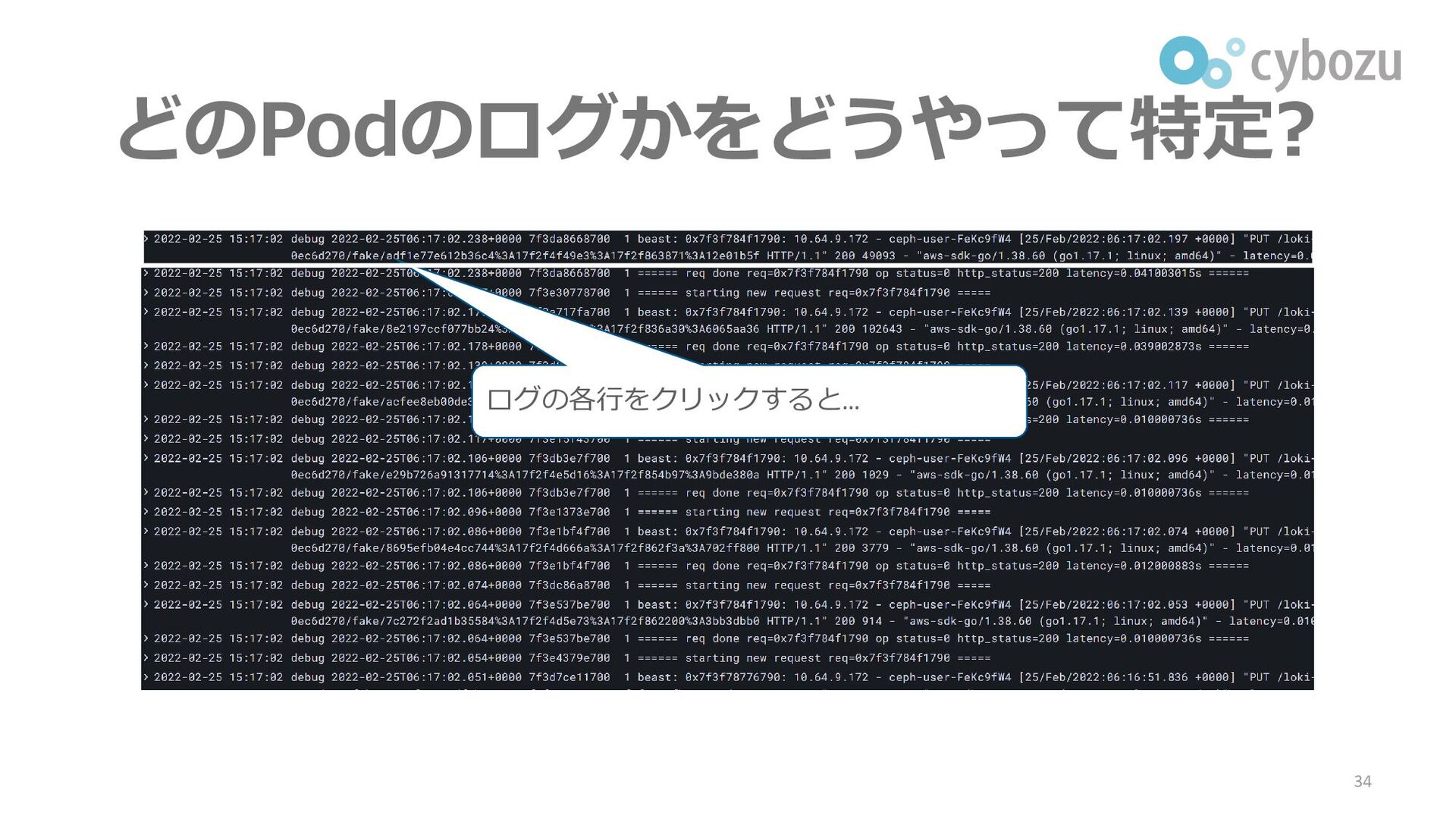
どのPodのログかをどうやって特定? 34 ログの各行をクリックすると…
行をクリックすると詳細情報が出る 35
出力するログを絞っていく ▌旧 ▌新 ▌出力期間も絞る 36
分析結果 ▌各RGW podは以下ログの出力&終了を繰り返していた NOTICE: resharding operation on bucket index detected,
blocking … received signal: Terminated from Kernel …) UID: 0 … NOTICE: resharding operation on bucket index detected, blocking … received signal: Terminated from Kernel …) UID: 0 … 37 “resharding”という処理が怪しそう シグナルによって終了
仮説 ▌Probe失敗によって強制終了させられていた ▌ログに残っていたreshardingという処理が怪しい ▌次のようなことを繰り返していたのでは? 1. resharding処理中はRGW podのprobeが失敗 2. Probeの失敗を繰り返したのでK8sが異常終了させる 3.
resharding処理が最初からやり直しに 38
その後の流れ ▌仮説は正しかった ⚫K8sのlivenessProbeが失敗し続けていた ▌詳細は別スライドを参照 ⚫ https://speakerdeck.com/sat/kubernetesshi-jian-toraburusiyuteingu 39
振り返り: よかったこと ▌監視と通知によって問題を早期検出できた ⚫無ければユーザからのクレームまで気づけなかった可能性も ▌ダッシュボードにより問題の概要が一目でわかった ▌メトリクスとログからトラシューの仮説が立てられた ⚫仮説の検証にも役立った 40
振り返り: 改善すべきこと ▌Cephクラスタ専用のLokiが欲しい ▌今回は偶然に助けられた ⚫直近のログにアクセスできなければ調査はさらに難航した ▌次はこうはいかないかもしれない 41
これまでの経験を踏まえたTIPS ▌オブザーバビリティ向上の肝は改善の繰り返し ⚫まずは単純な監視/ログ基盤を作る ⚫使い込んで、不備があれば改善 ▌定期的なダッシュボードのチェック重要 ⚫「何が正常か」が肌感覚でわかる ▌一度監視/ログ基盤を導入したら無い状態が想像できなくなる ⚫問題検知/トラシュー速度が全く違う ⚫可用性向上に投資を惜しまないほうがいい 42
おわり 43
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}