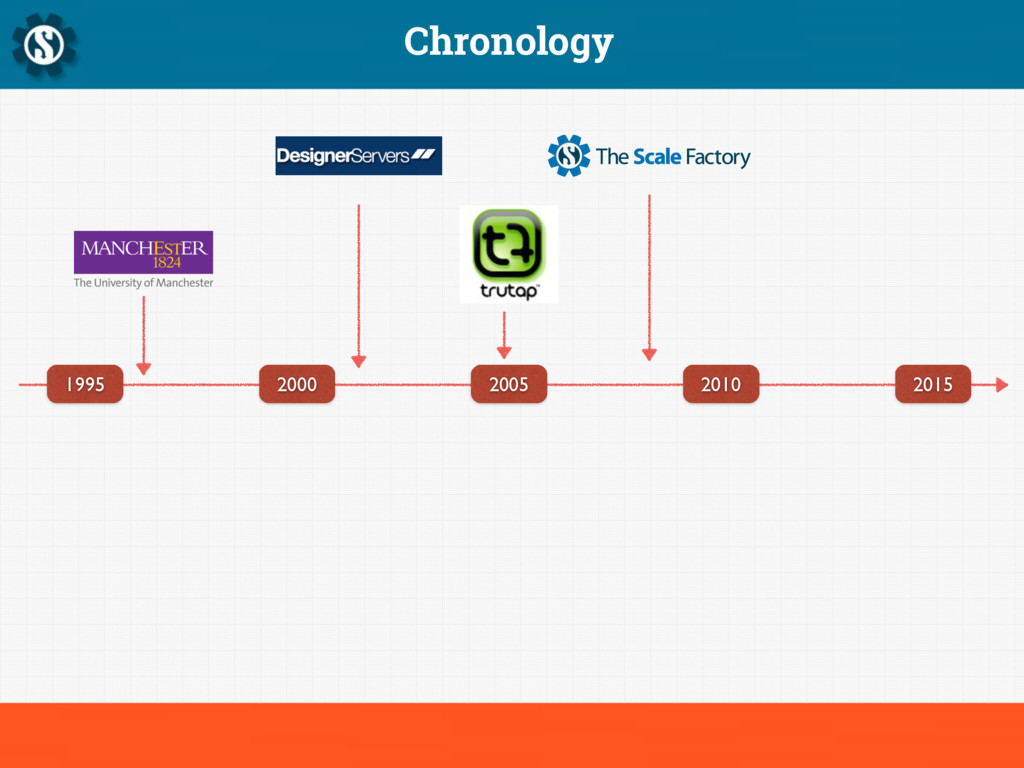
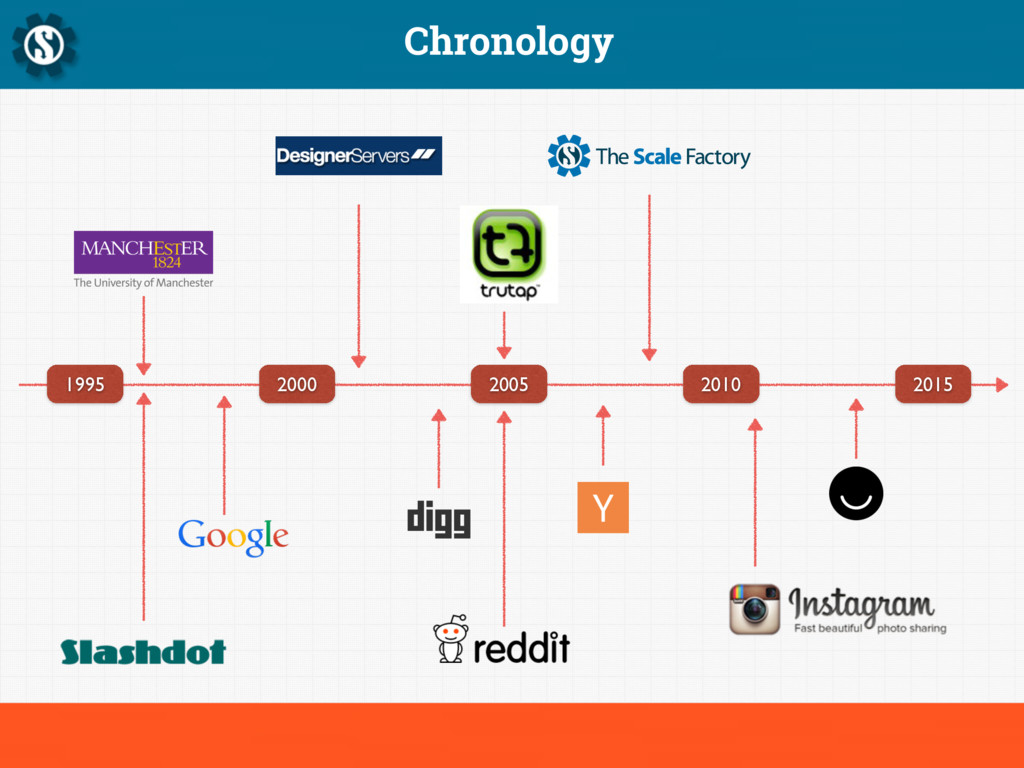
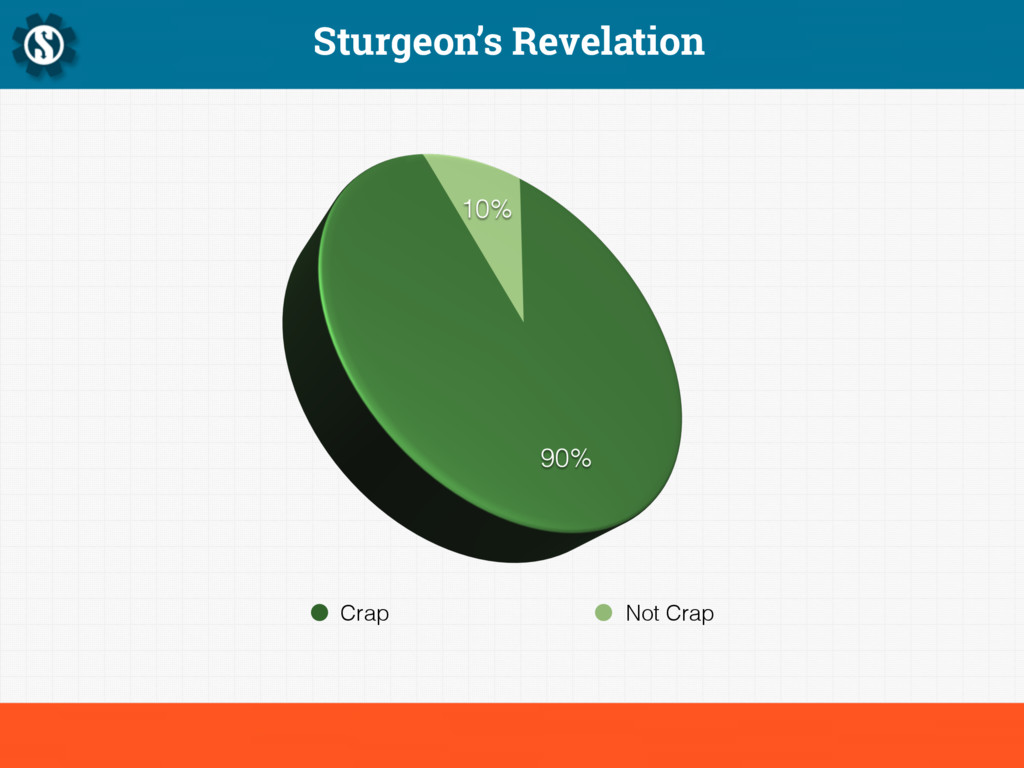
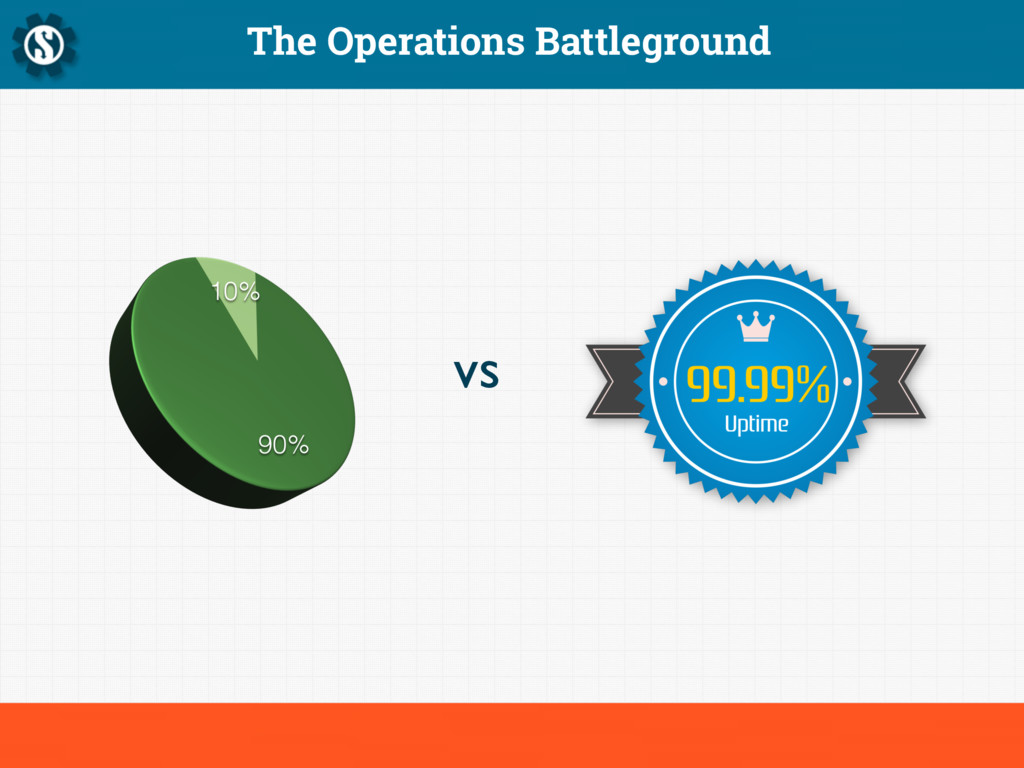
Sturgeon's revelation states that "ninety percent of everything is crap", and this is particularly true of computer systems. Given at the Hacker News London meetup in October 2014, this presentation talks about building platforms for the real world.
You can view a video recording of this talk: https://vimeo.com/110478911
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![http://www.scalefactory.com/ [email protected] @jtopper jtopper / scalefactory](https://files.speakerdeck.com/presentations/9128fb95f4ad4ebcb19f2d801bac952e/slide_25.jpg){kind=link}