• highly engineered version of mergesort • comparison based, internal, and stable • multiply adaptive: ▶ galloping merges ▶ run detection on the fly BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 1 / 16
• highly engineered version of mergesort • comparison based, internal, and stable • multiply adaptive: ▶ galloping merges ▶ run detection on the fly BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 1 / 16
• highly engineered version of mergesort • comparison based, internal, and stable • multiply adaptive: ▶ galloping merges ▶ run detection on the fly ▶ Timsort’s merge policy is less than optimal: • 1.5 times the optimal merge cost in the worst case (Buss and Knop 2018) • Hard to analyze • Prone to algorithmic bugs BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 1 / 16
• highly engineered version of mergesort • comparison based, internal, and stable • multiply adaptive: ▶ galloping merges ▶ run detection on the fly ▶ Timsort’s merge policy is less than optimal: • 1.5 times the optimal merge cost in the worst case (Buss and Knop 2018) • Hard to analyze • Prone to algorithmic bugs ▶ Munro and Wild introduced Powersort in 2018 • Merge policy update – retains most of Timsort • Optimal merge cost (up to lower order terms) • Built from first principles • Easy to analyze BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 1 / 16
• highly engineered version of mergesort • comparison based, internal, and stable • multiply adaptive: ▶ galloping merges ▶ run detection on the fly ▶ Timsort’s merge policy is less than optimal: • 1.5 times the optimal merge cost in the worst case (Buss and Knop 2018) • Hard to analyze • Prone to algorithmic bugs ▶ Munro and Wild introduced Powersort in 2018 • Merge policy update – retains most of Timsort • Optimal merge cost (up to lower order terms) • Built from first principles • Easy to analyze BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 1 / 16
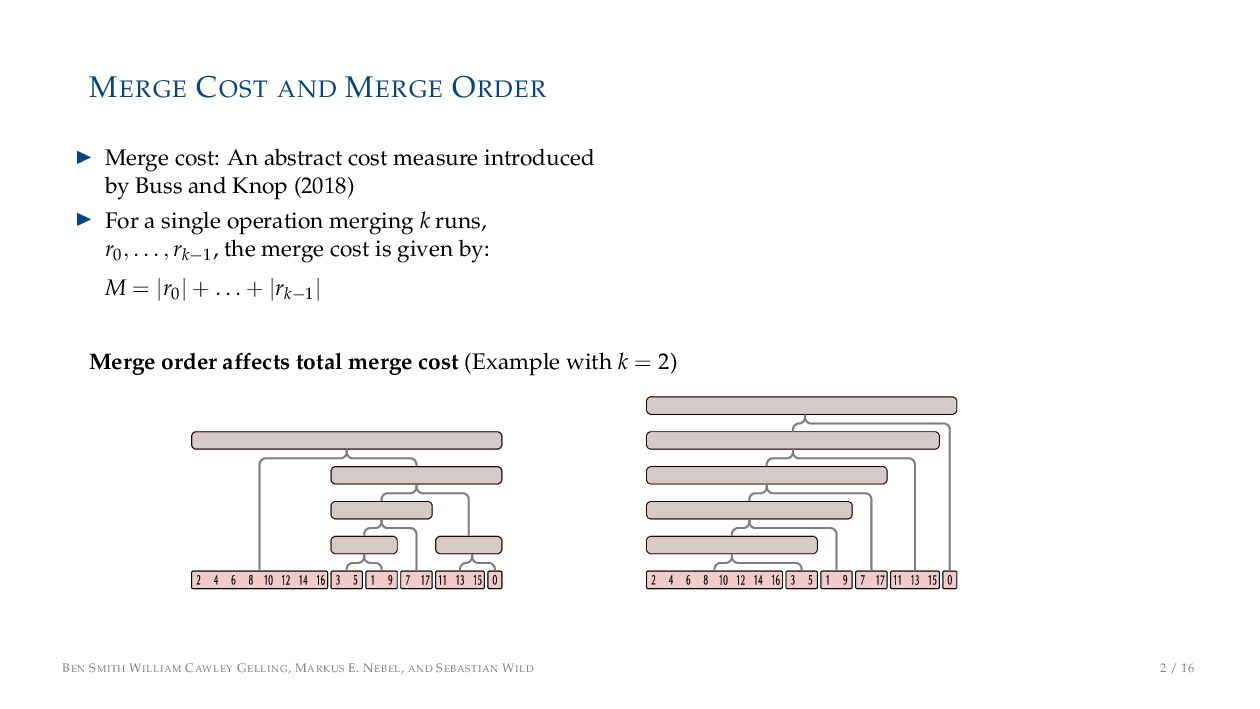
cost measure introduced by Buss and Knop (2018) ▶ For a single operation merging k runs, r0, . . . , rk−1 , the merge cost is given by: M = |r0 | + . . . + |rk−1 | BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 2 / 16
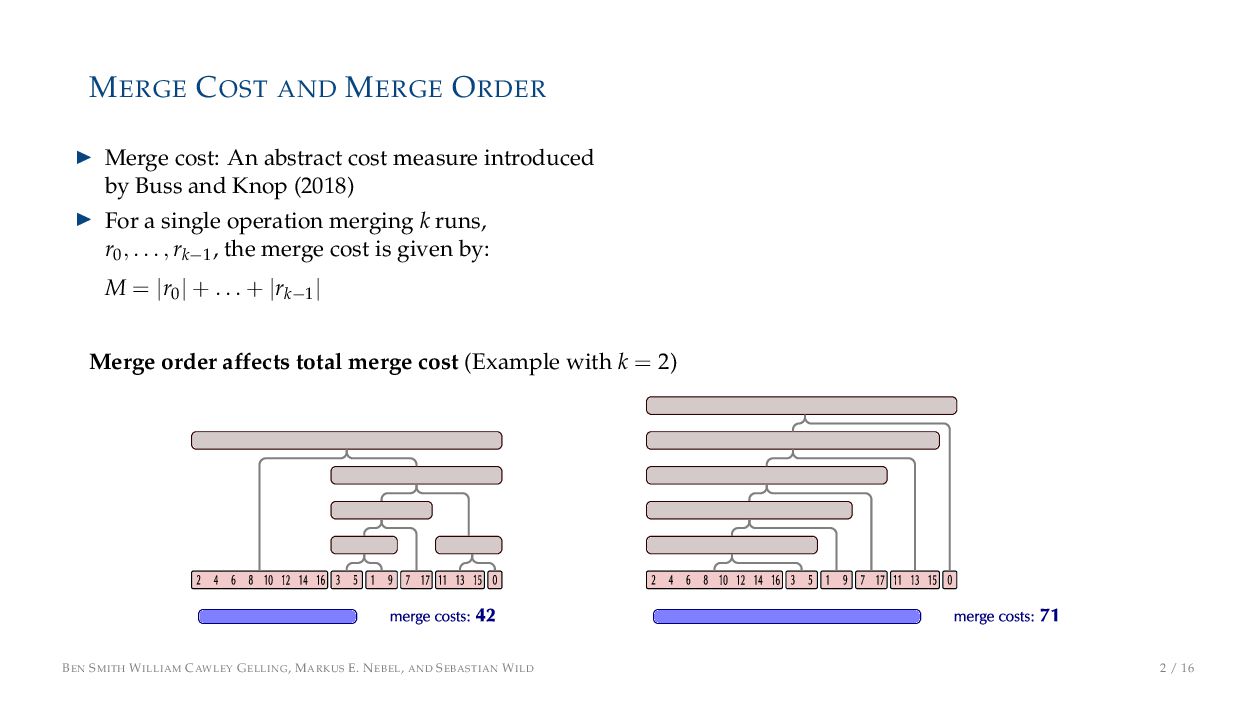
cost measure introduced by Buss and Knop (2018) ▶ For a single operation merging k runs, r0, . . . , rk−1 , the merge cost is given by: M = |r0 | + . . . + |rk−1 | Merge order affects total merge cost (Example with k = 2) BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 2 / 16
cost measure introduced by Buss and Knop (2018) ▶ For a single operation merging k runs, r0, . . . , rk−1 , the merge cost is given by: M = |r0 | + . . . + |rk−1 | Merge order affects total merge cost (Example with k = 2) BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 2 / 16
cost measure introduced by Buss and Knop (2018) ▶ For a single operation merging k runs, r0, . . . , rk−1 , the merge cost is given by: M = |r0 | + . . . + |rk−1 | Merge order affects total merge cost (Example with k = 2) BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 2 / 16
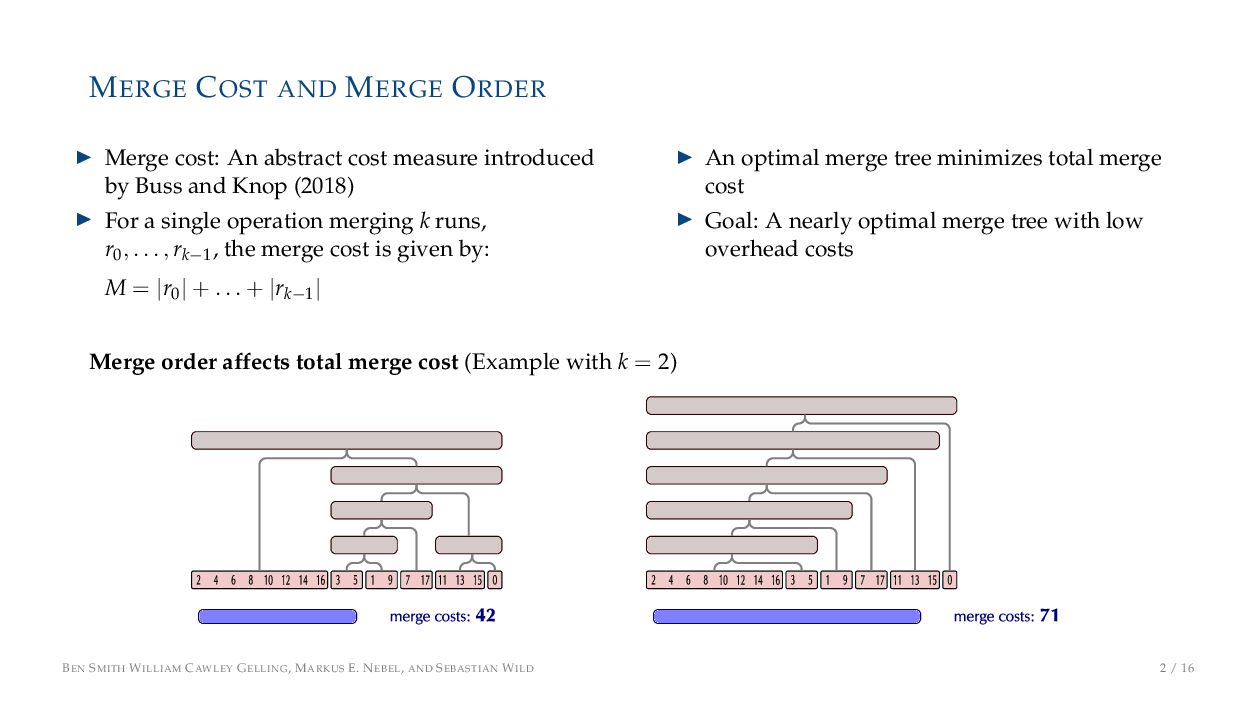
cost measure introduced by Buss and Knop (2018) ▶ For a single operation merging k runs, r0, . . . , rk−1 , the merge cost is given by: M = |r0 | + . . . + |rk−1 | ▶ An optimal merge tree minimizes total merge cost ▶ Goal: A nearly optimal merge tree with low overhead costs Merge order affects total merge cost (Example with k = 2) BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 2 / 16
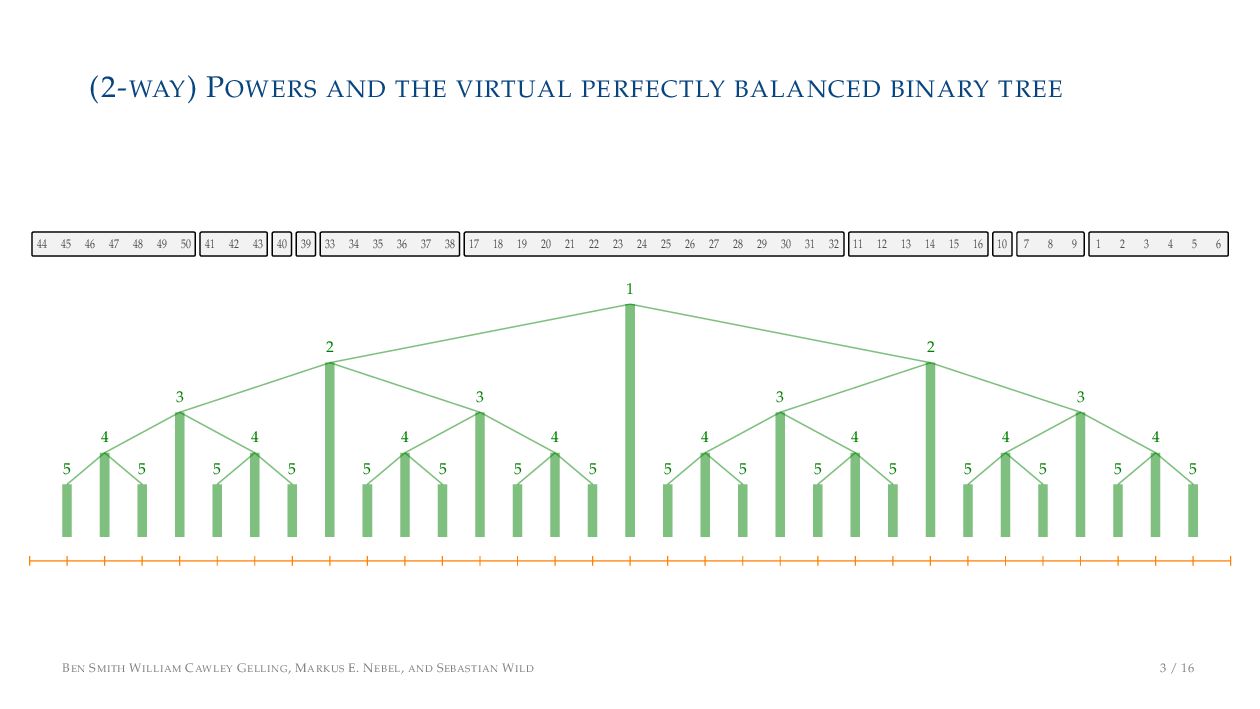
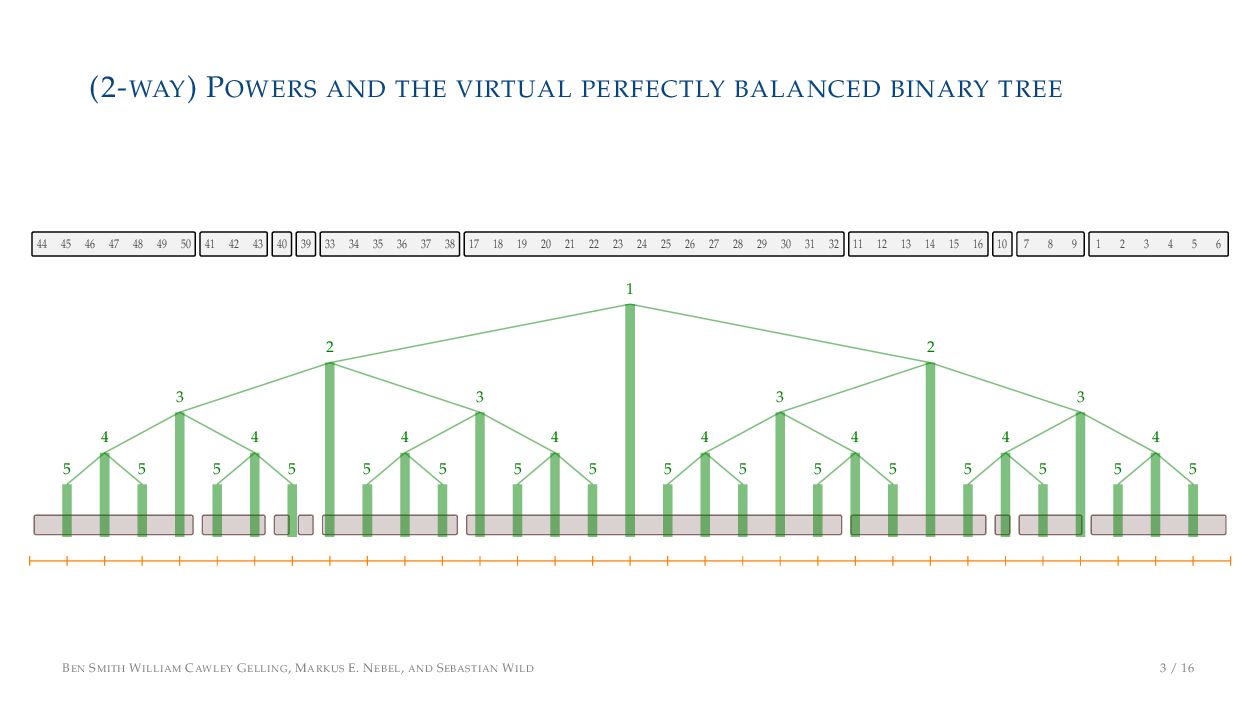
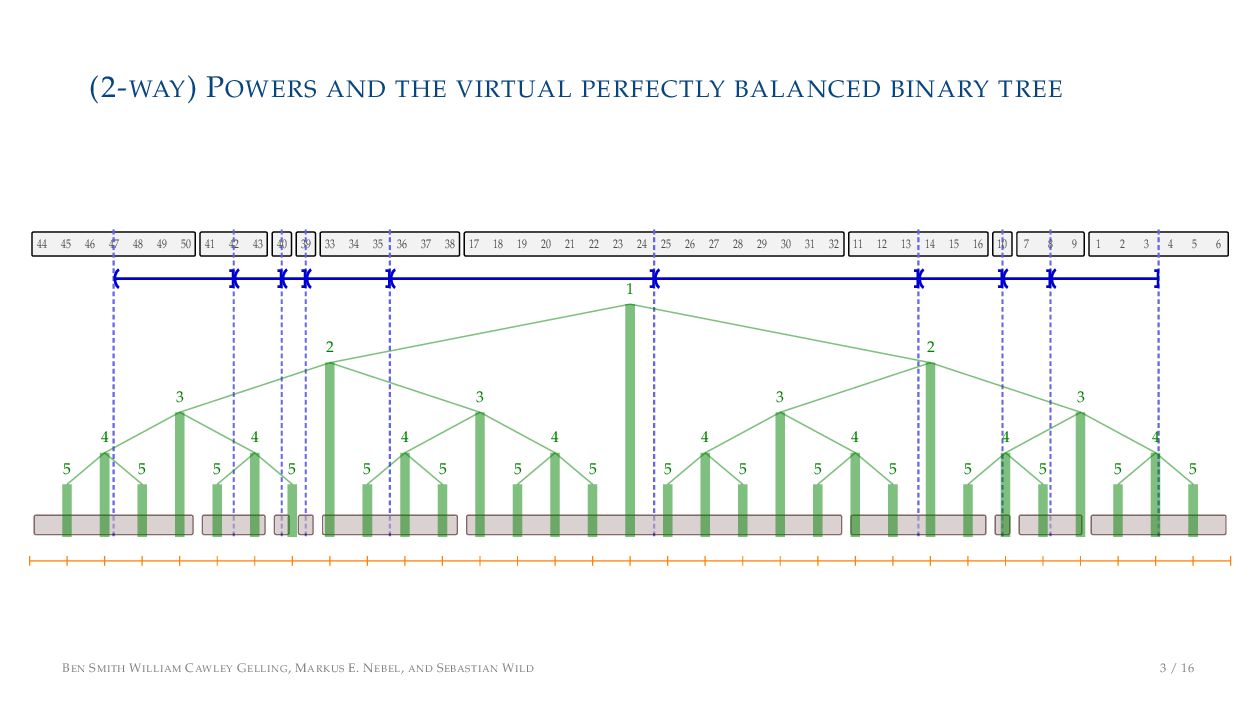
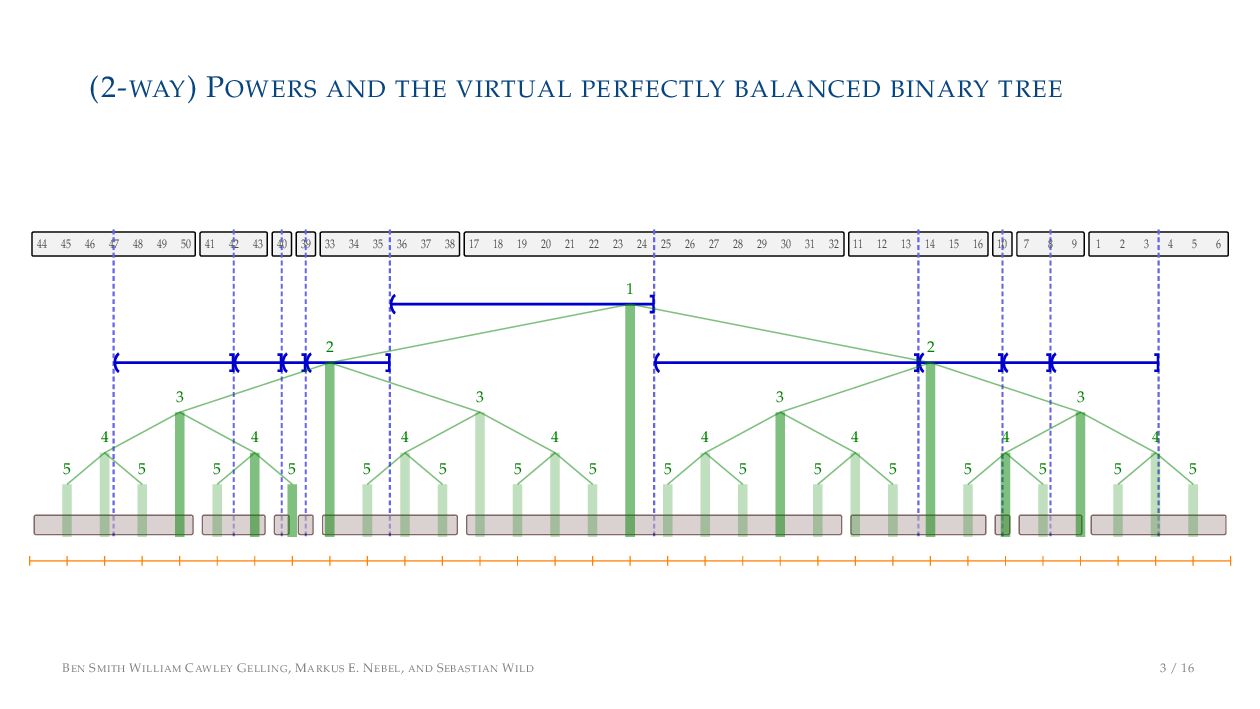
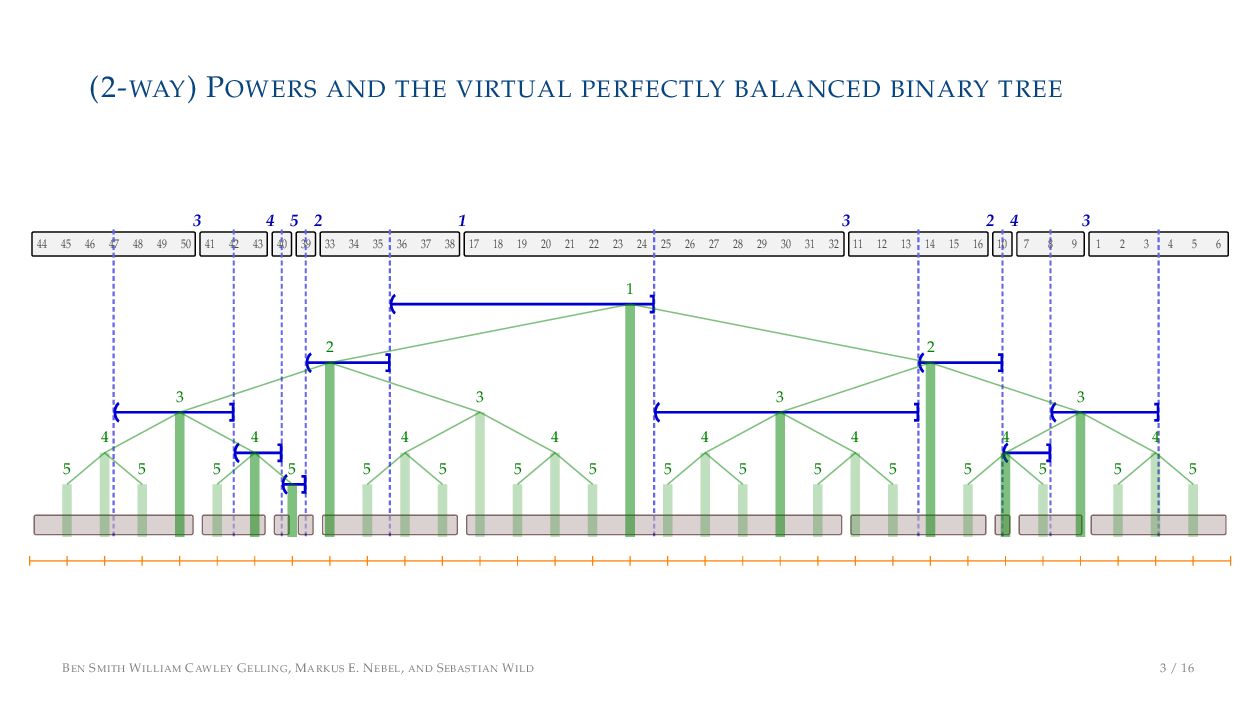
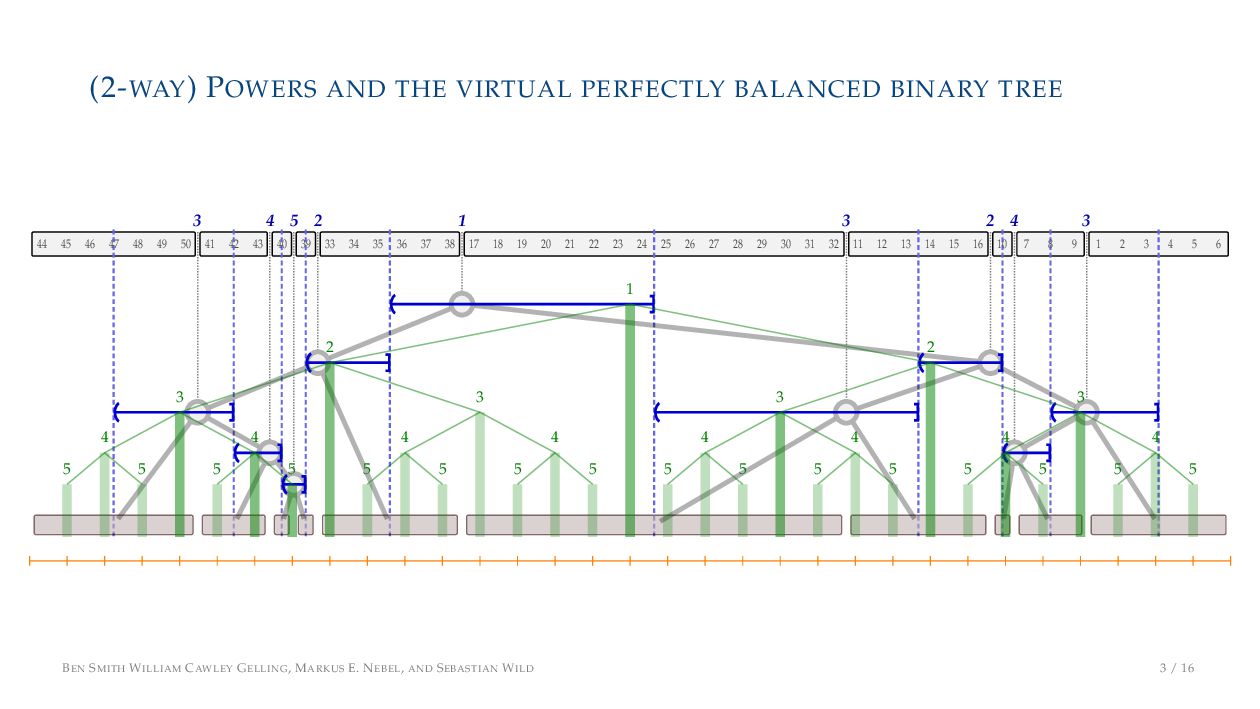
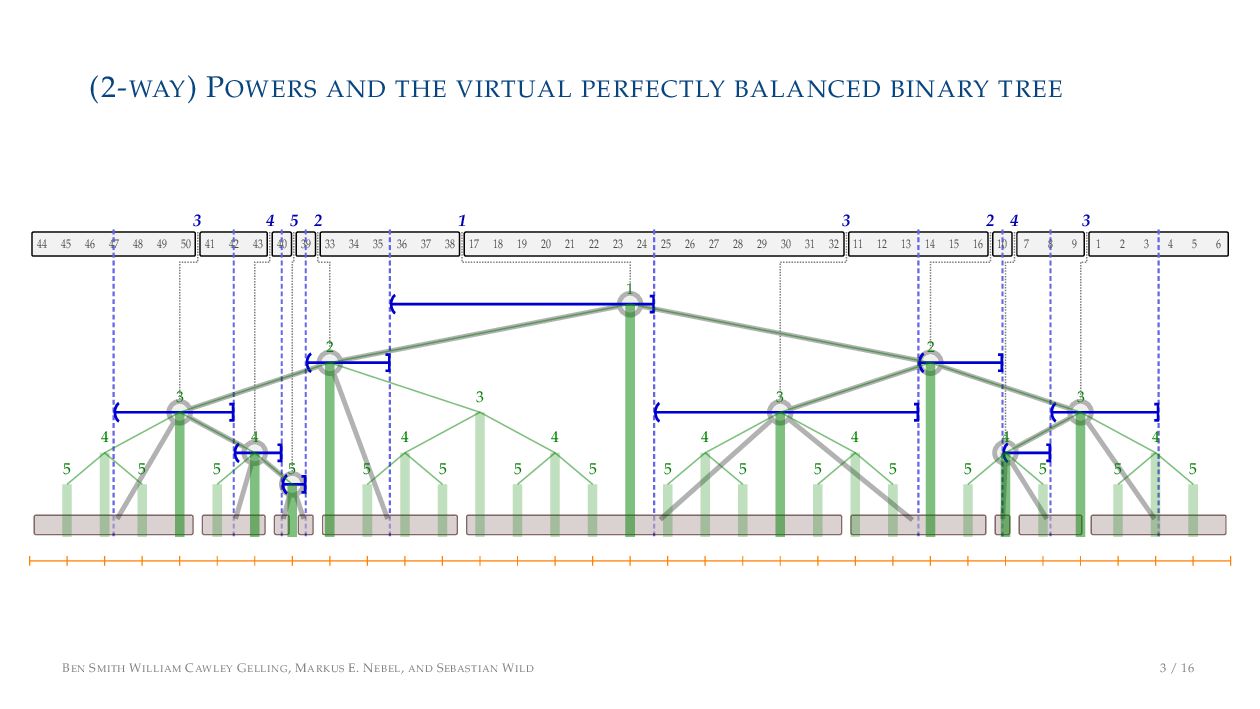
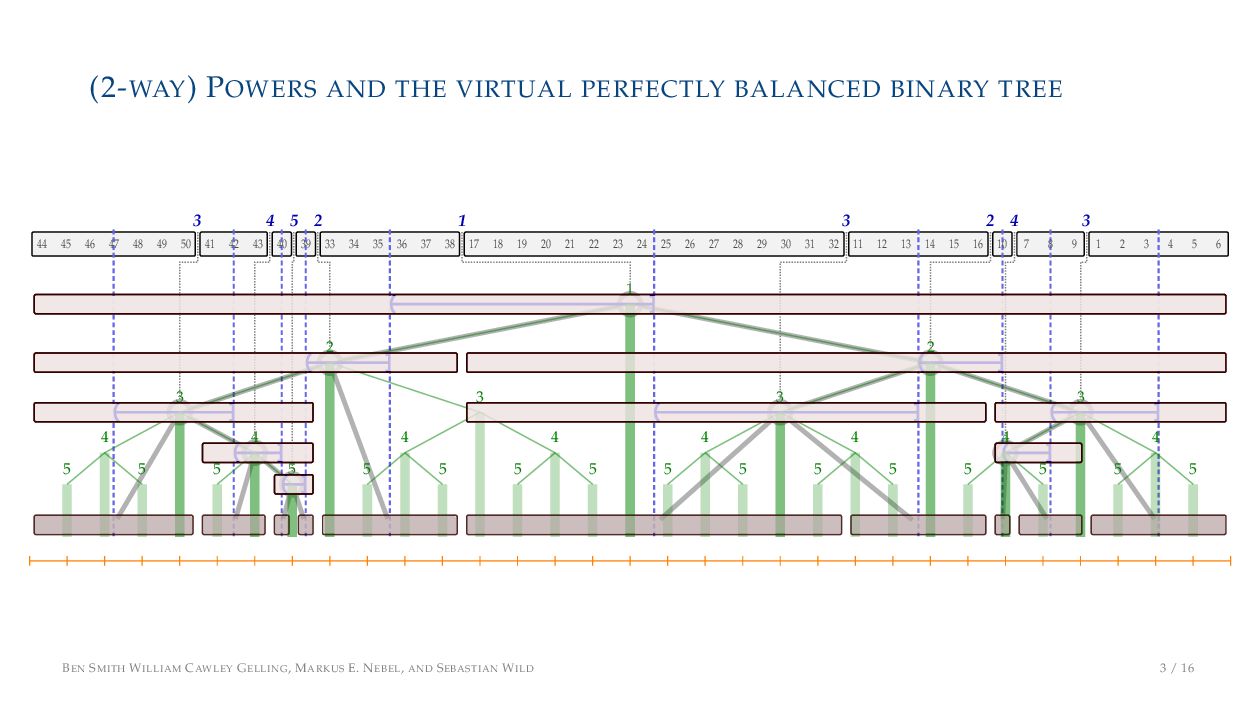
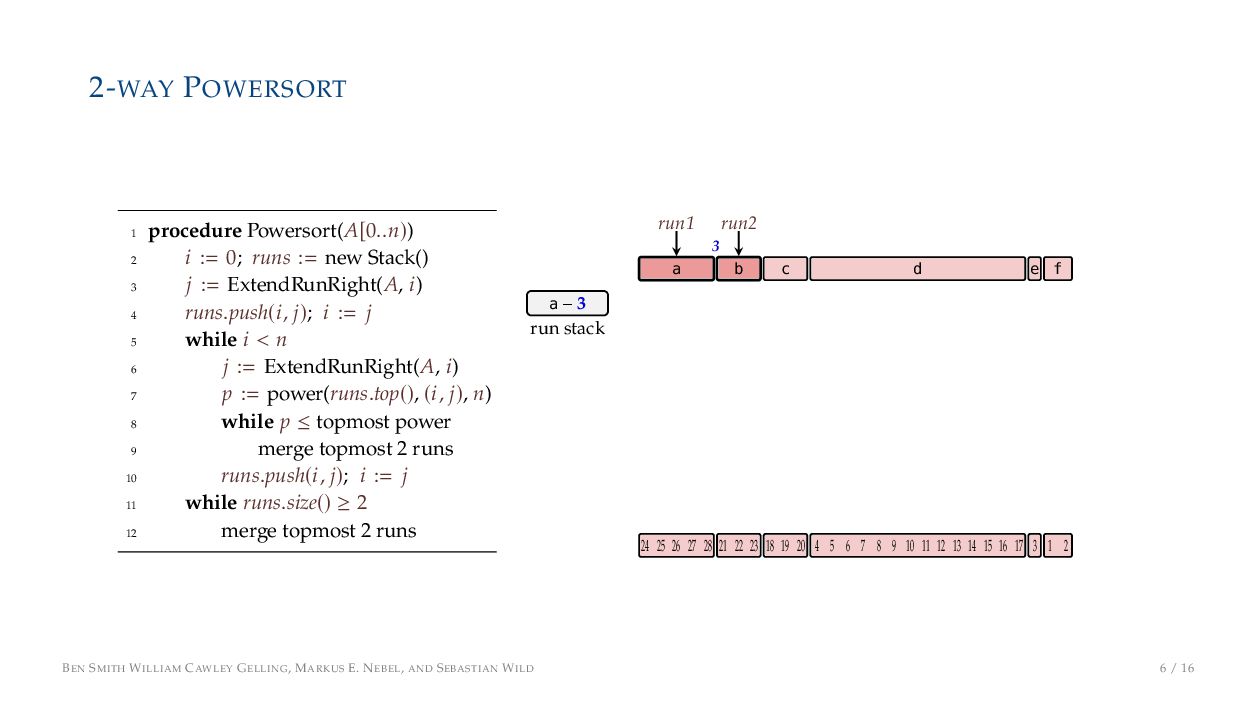
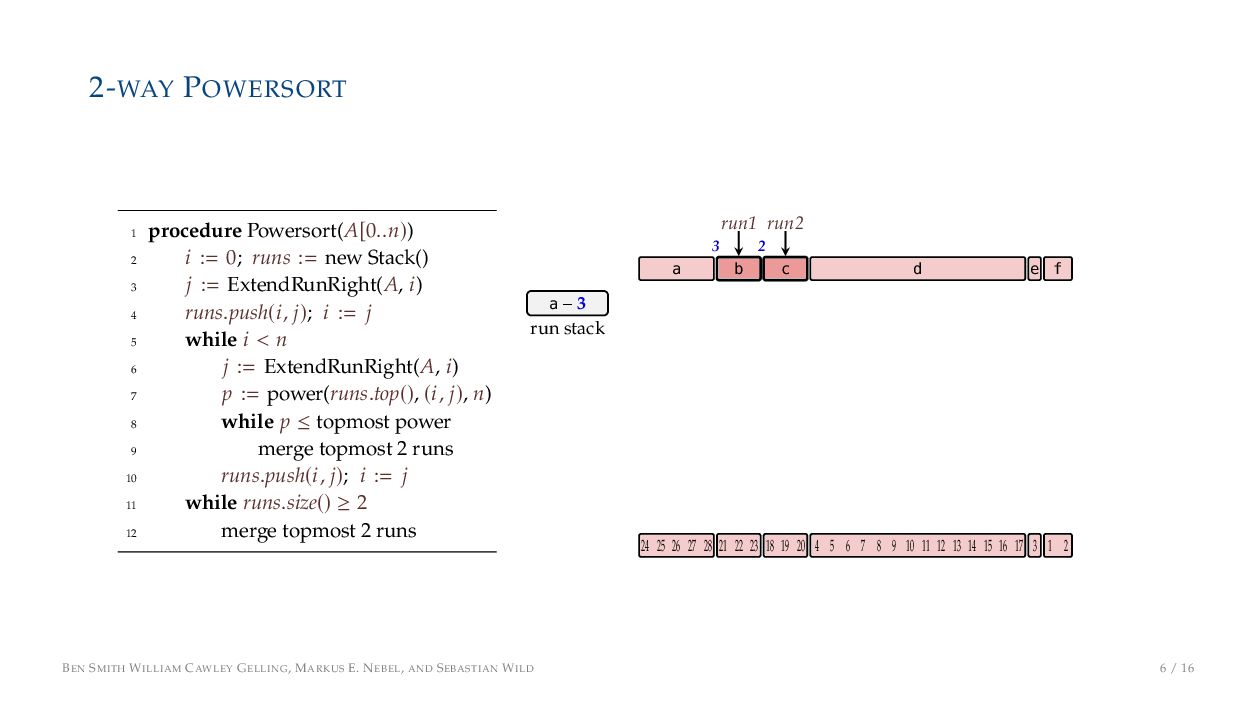
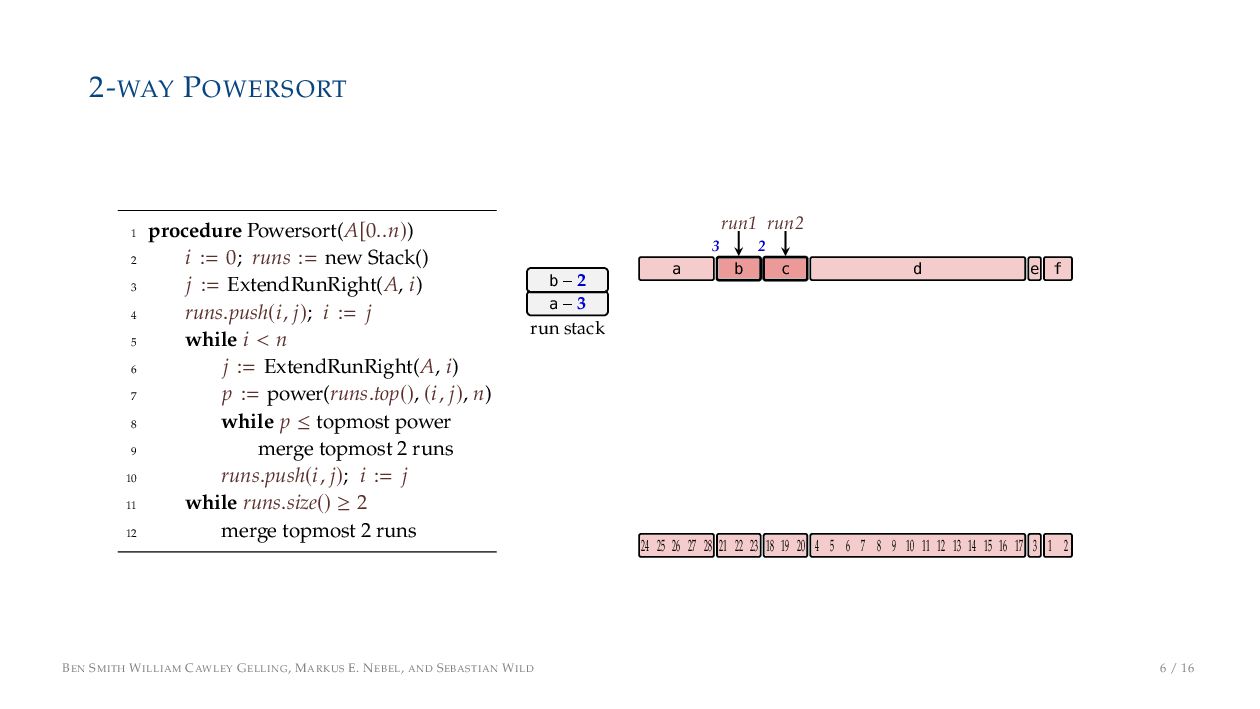
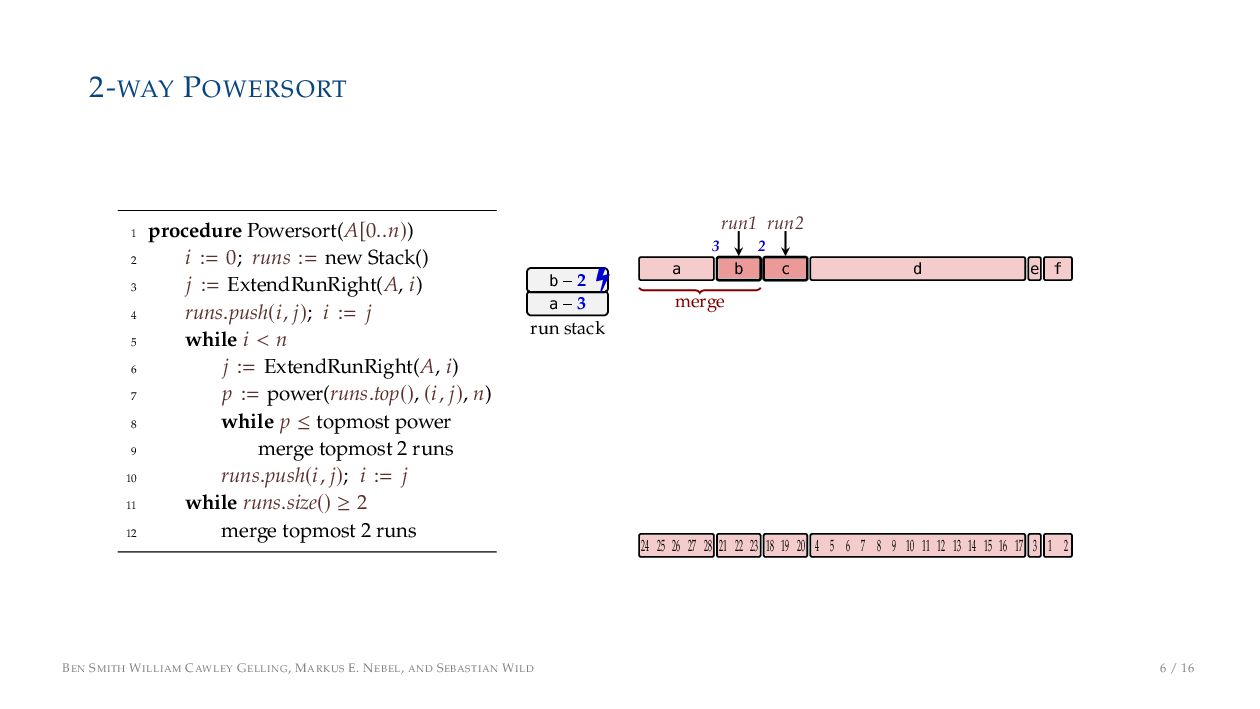
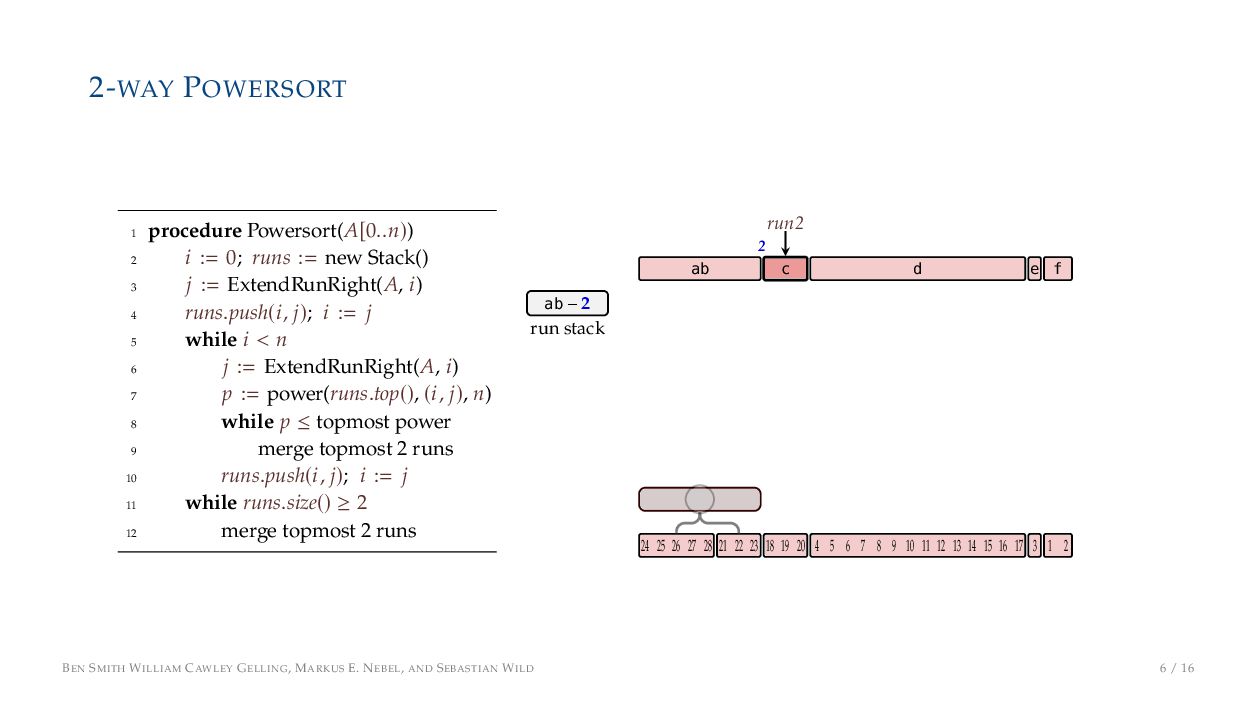
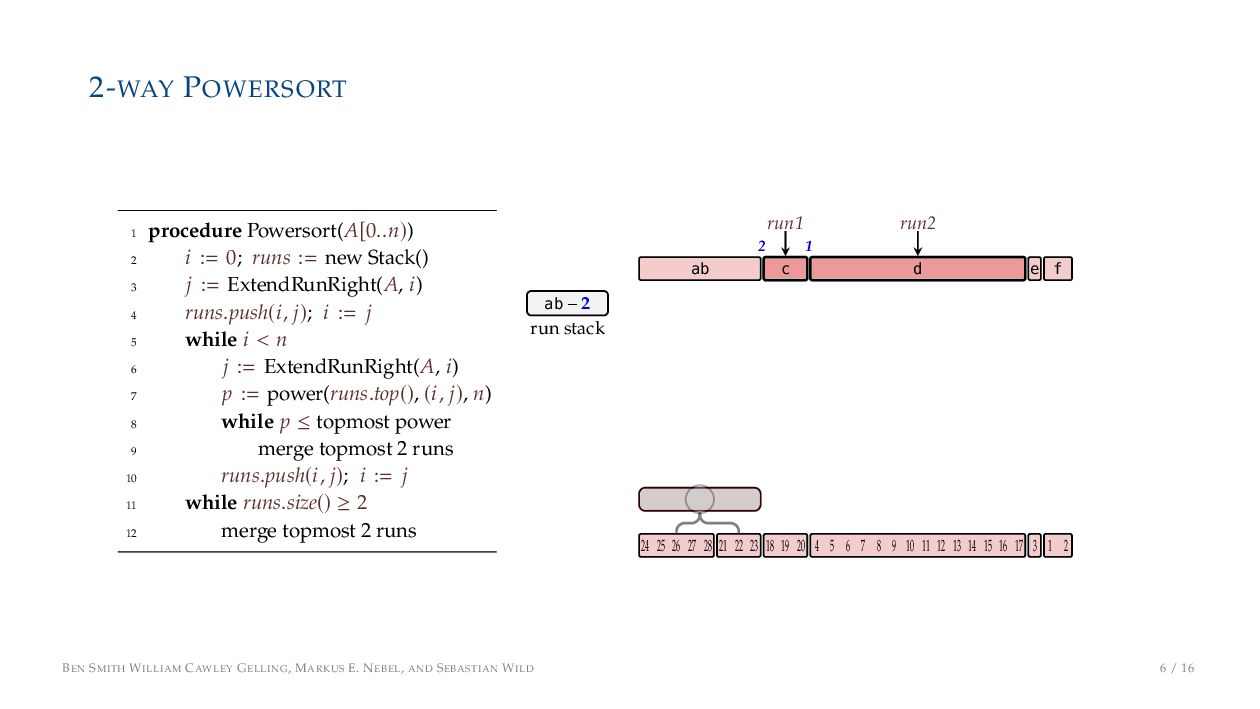
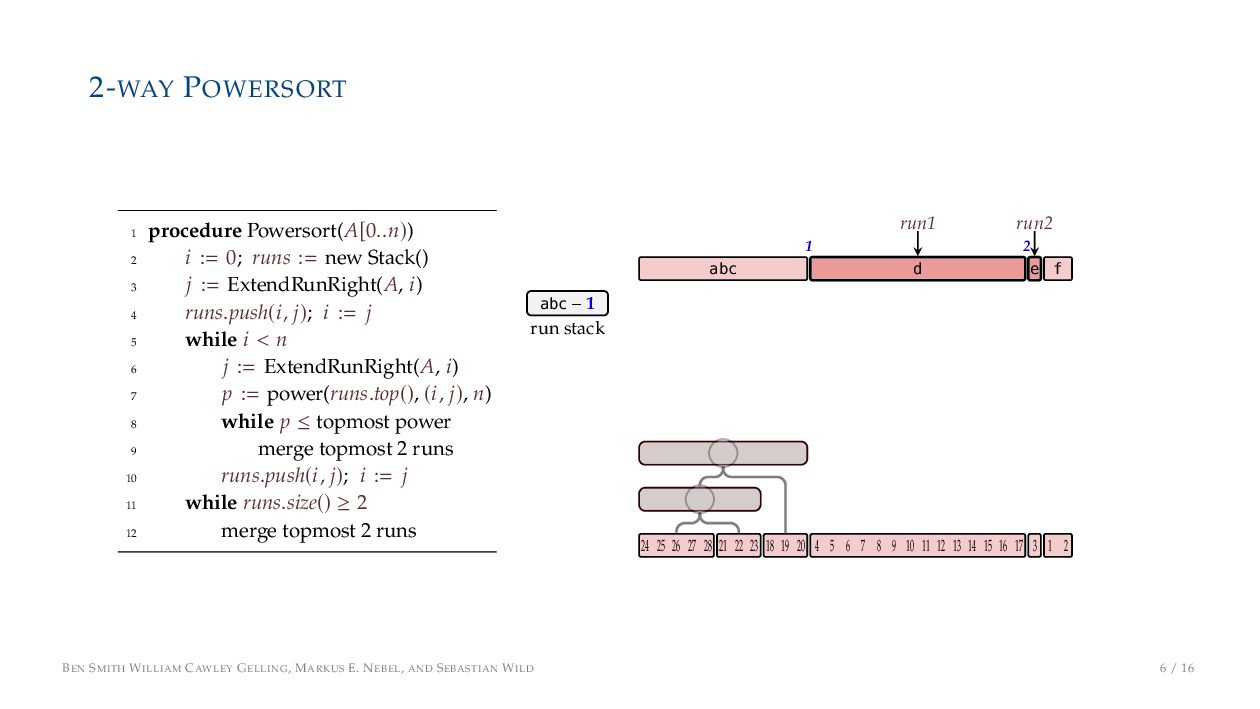
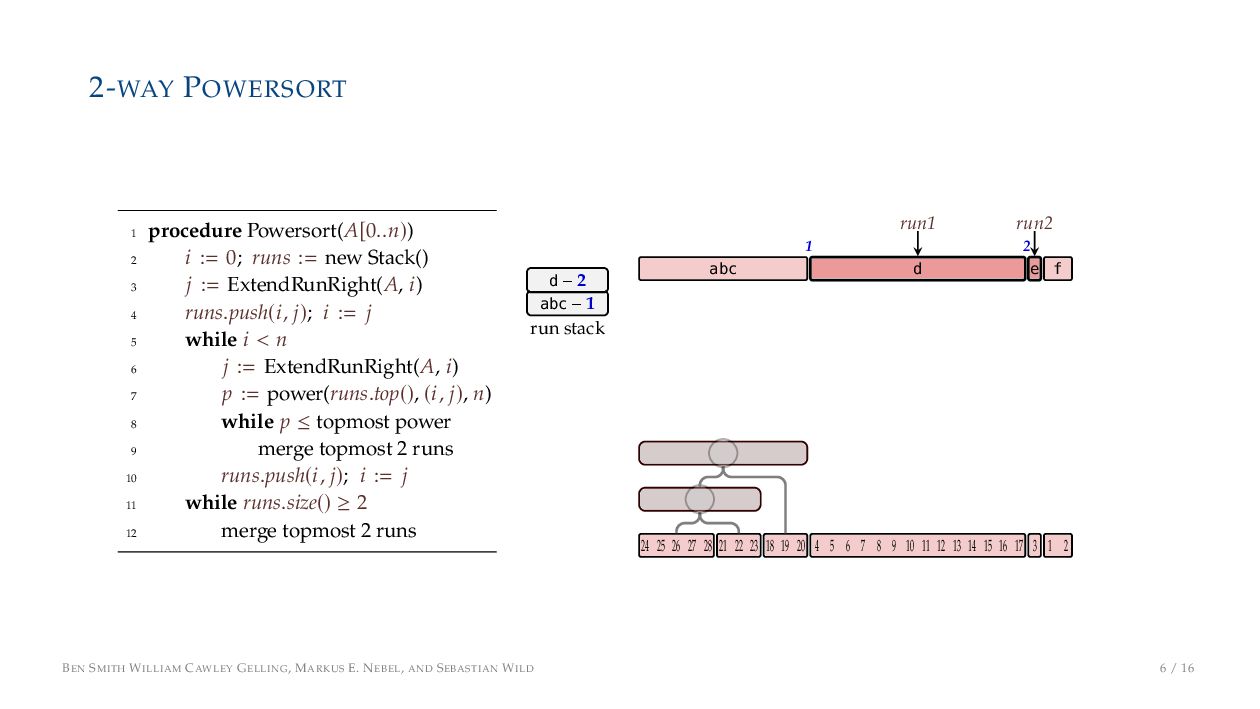
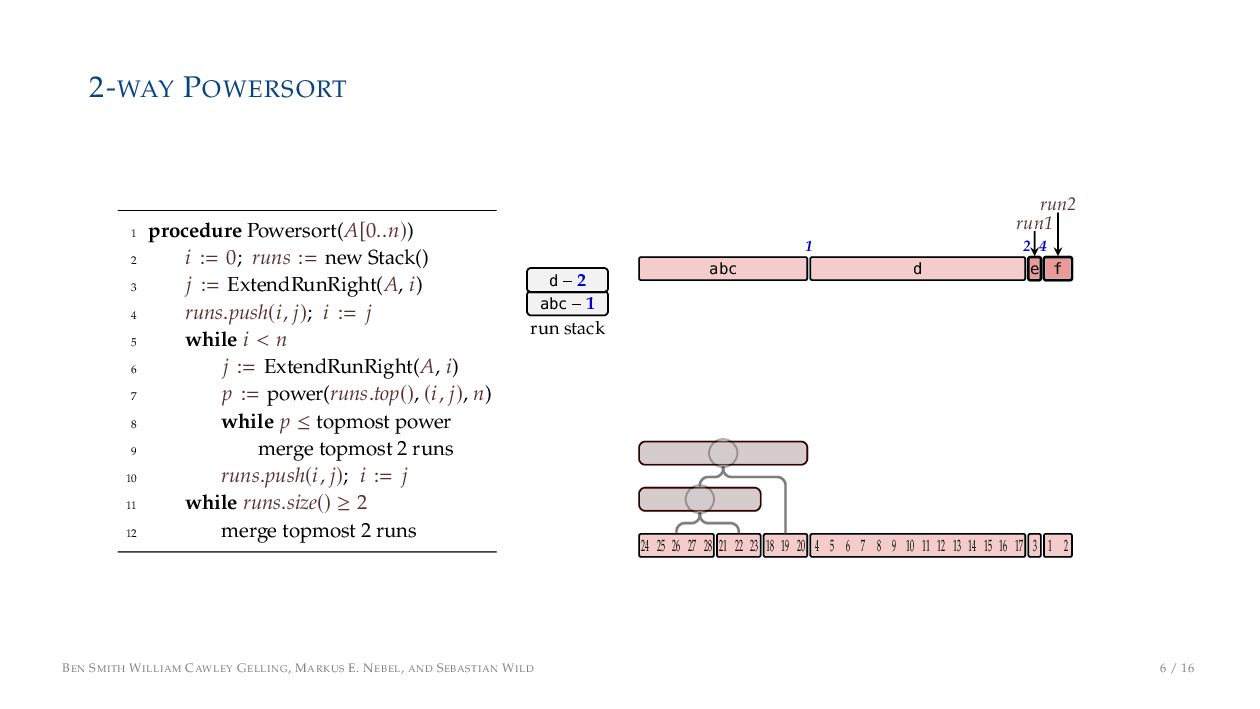
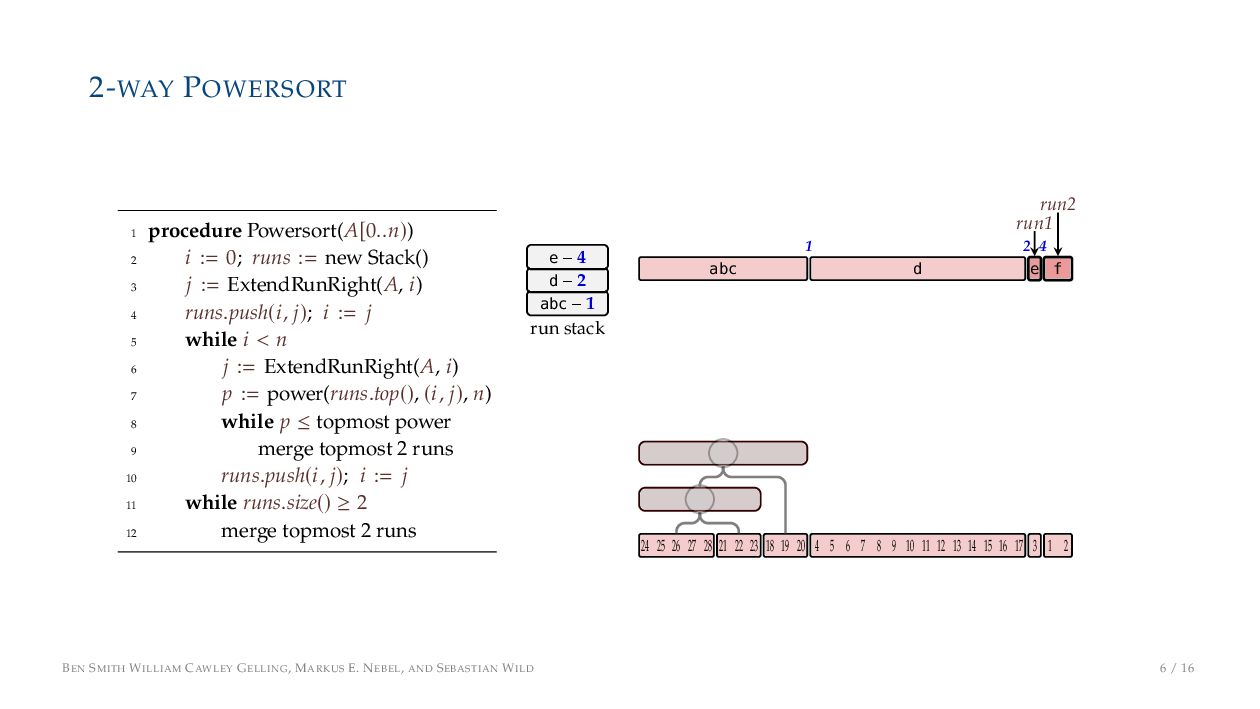
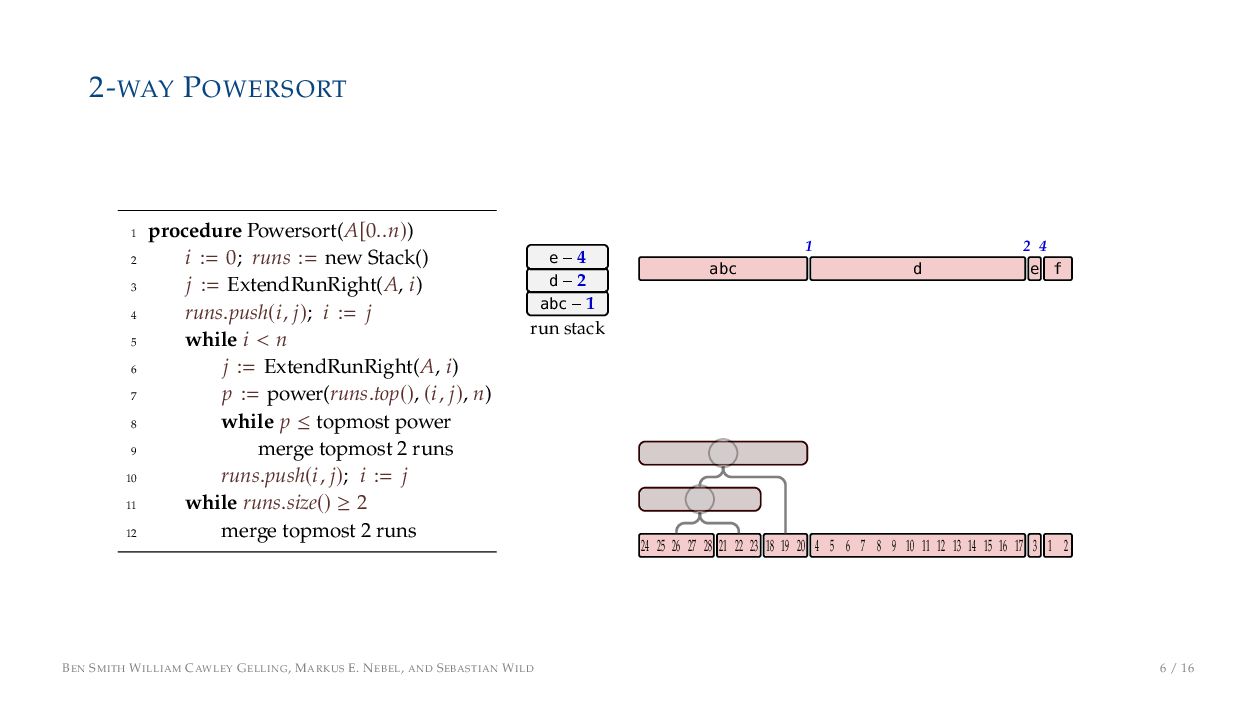
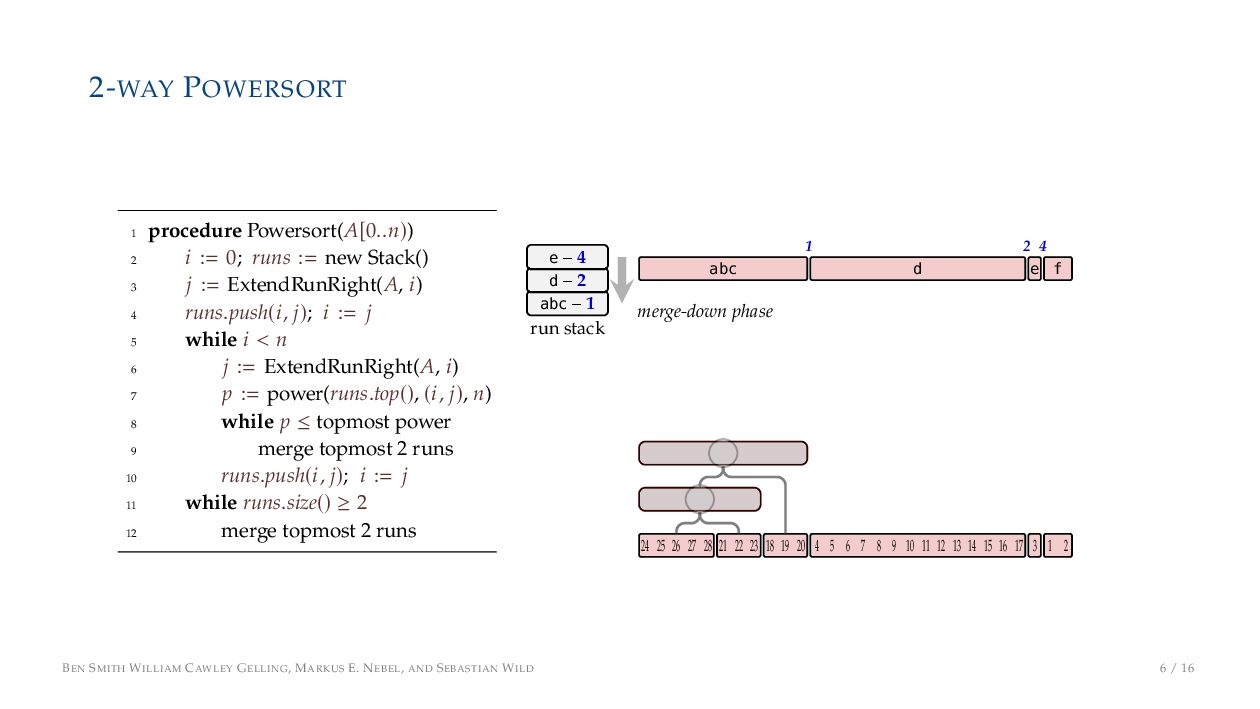
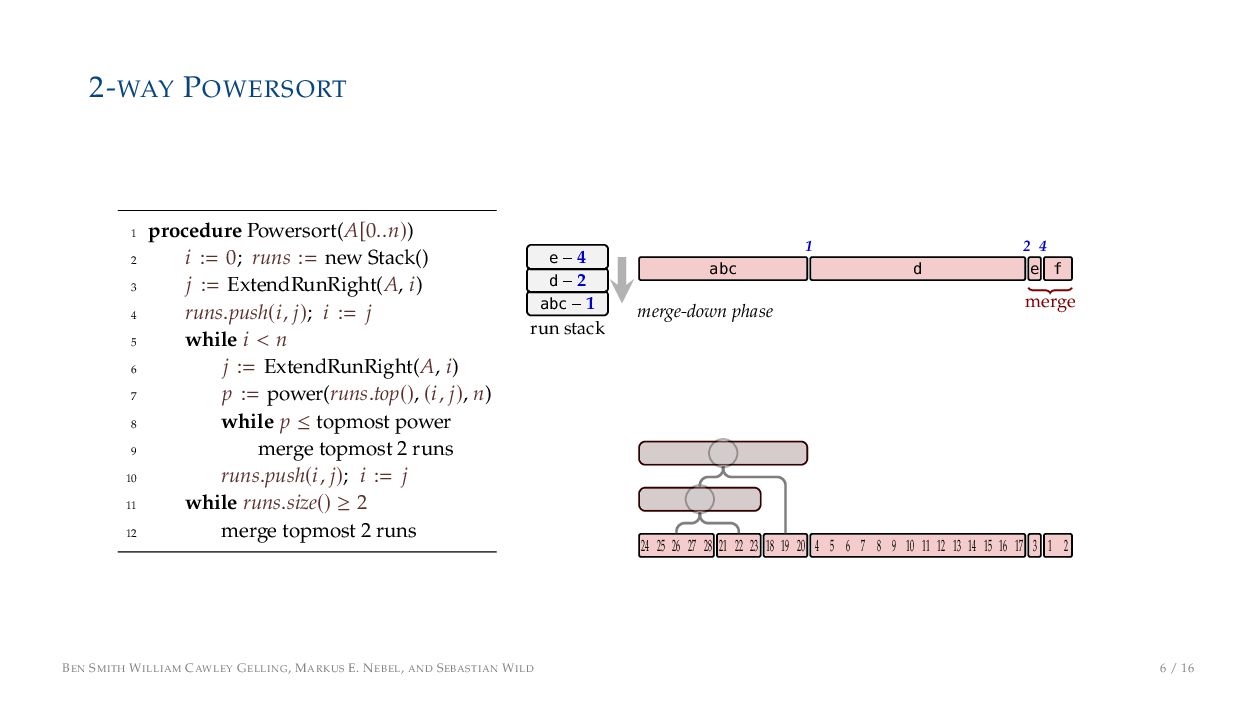
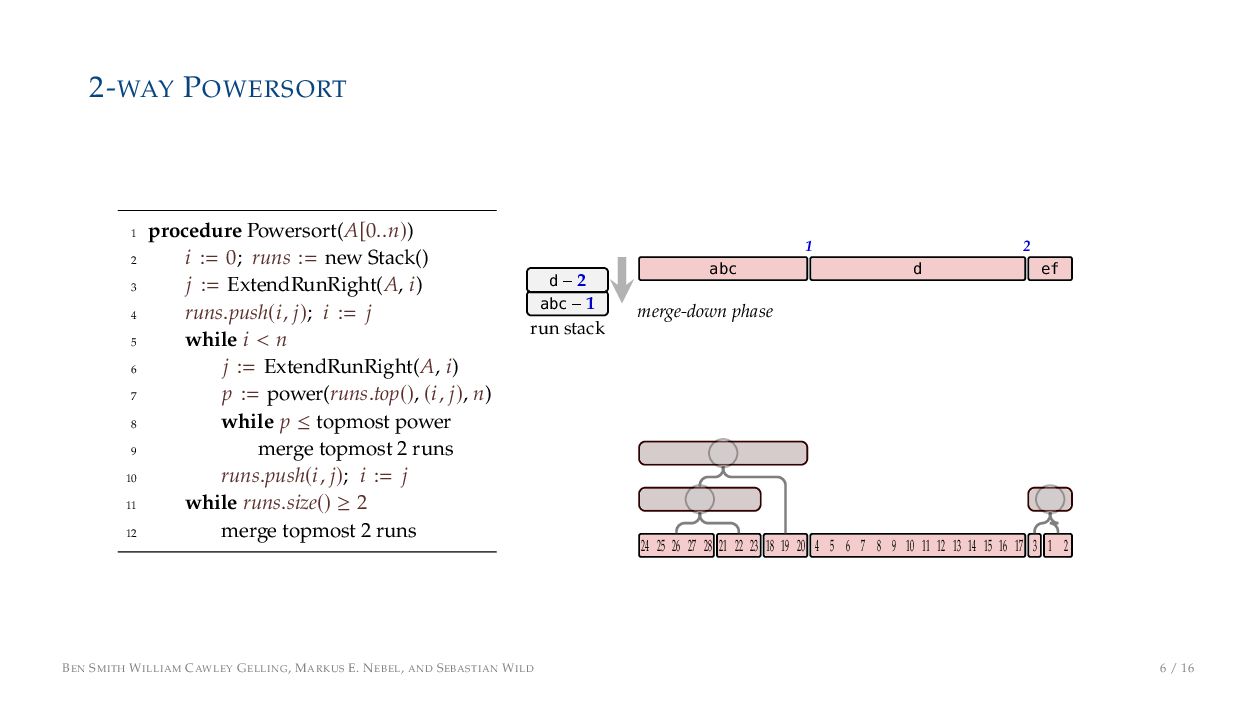
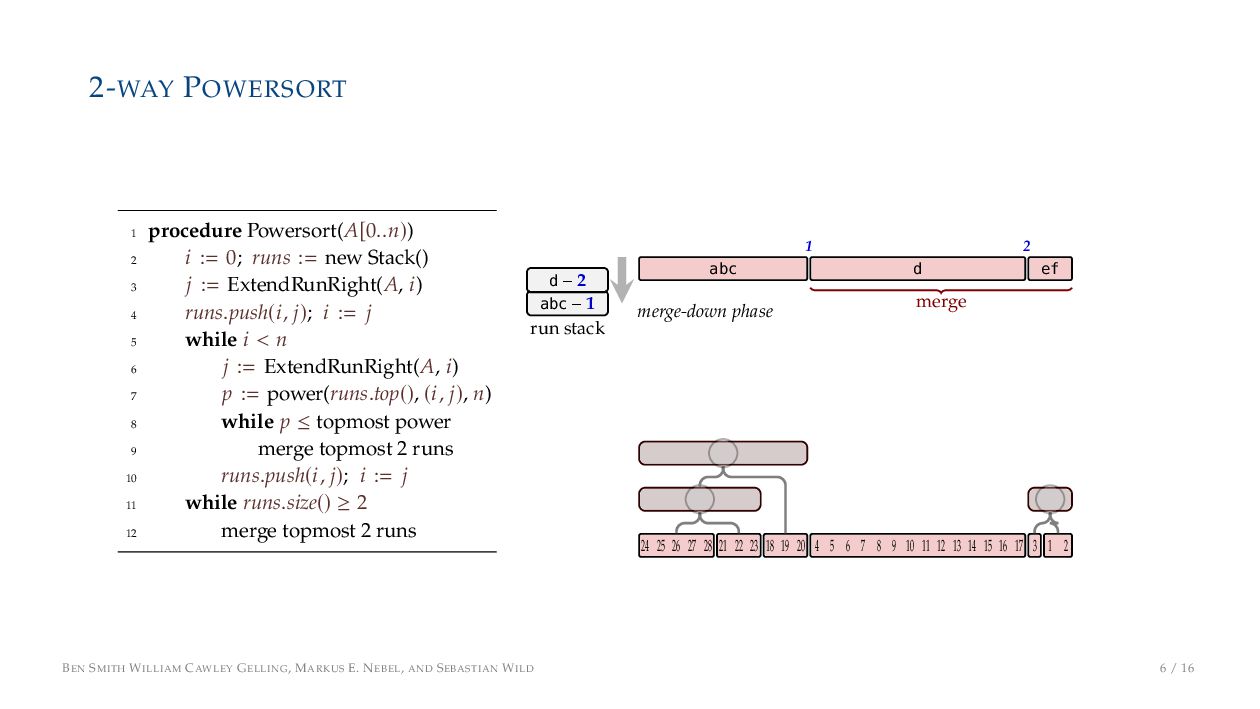
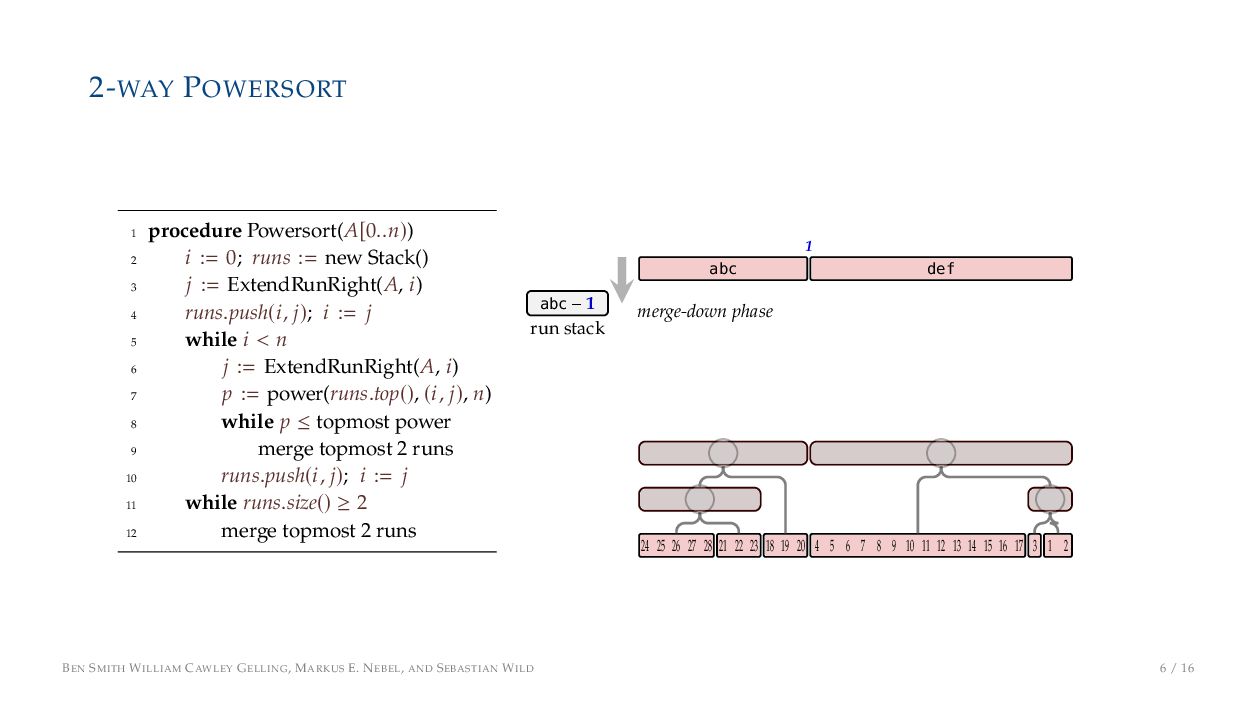
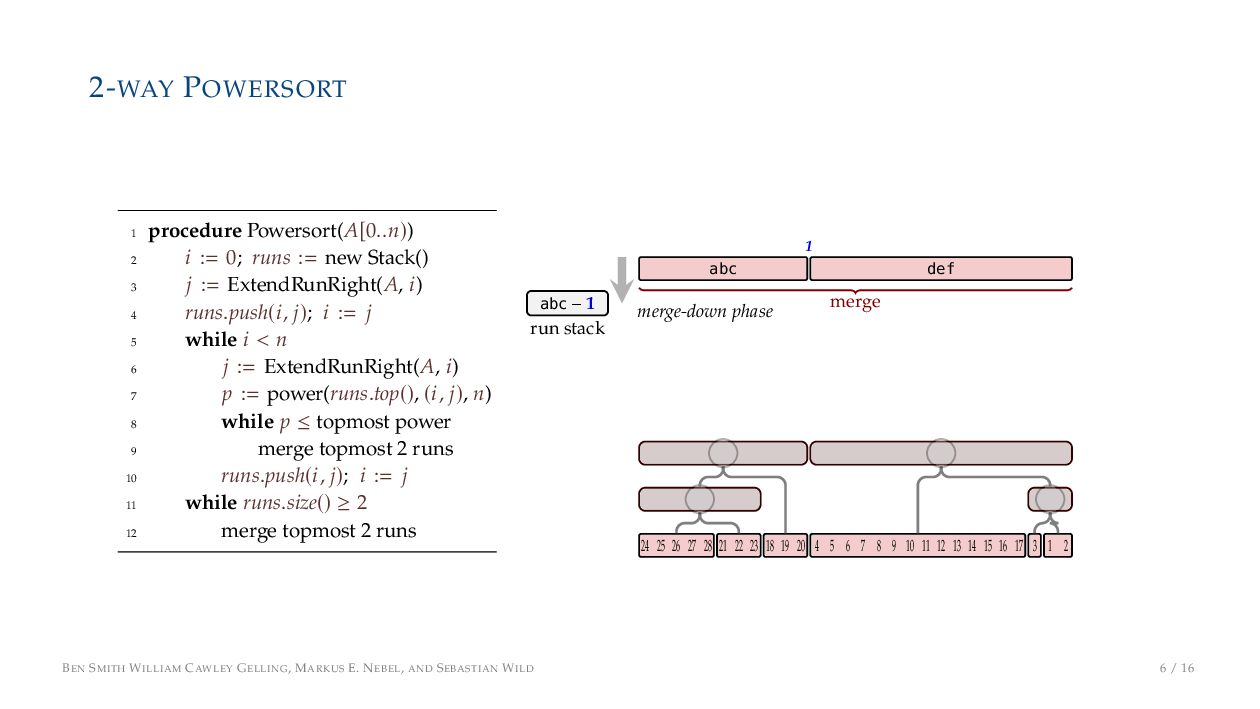
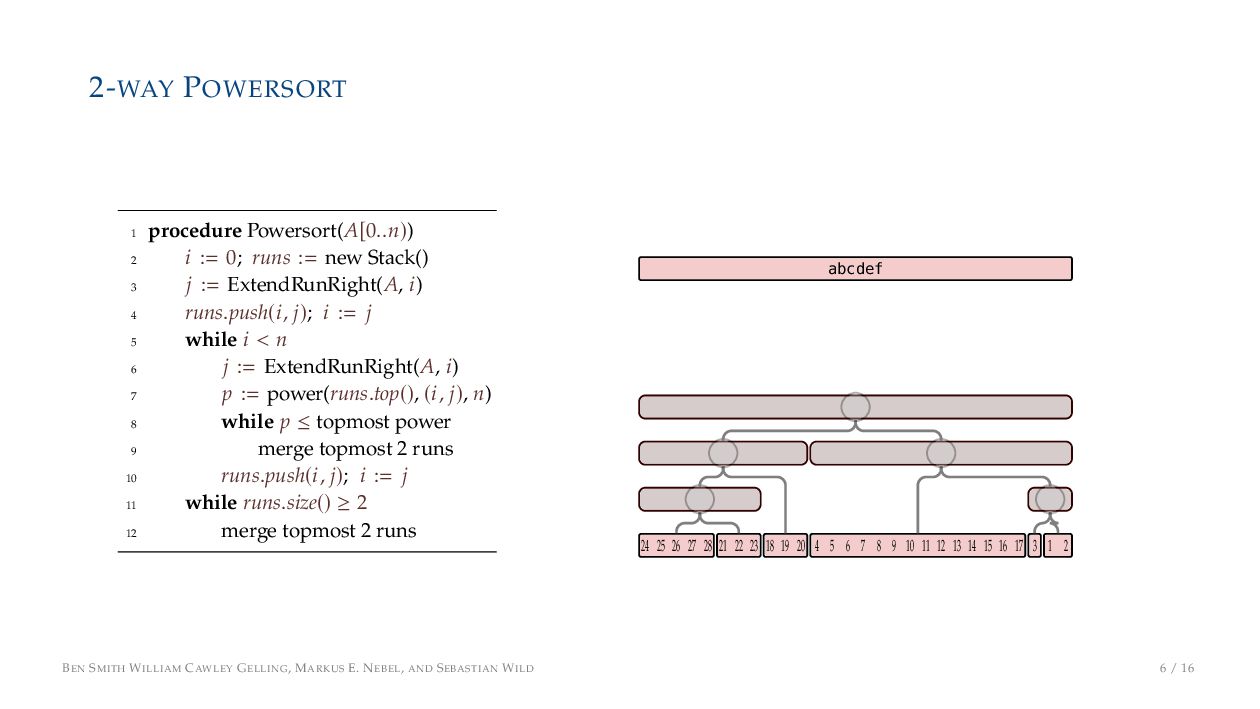
. , Lr−1, first set li = Li n , then: • Define ai , the normalized centre of the (i − 1)st run: ai = i−1 j=0 lj − 1 2 li−1, • Define bi , the normalized centre of ith run: bi = i−1 j=0 lj + 1 2 li • Hence, define the power of the boundary between these runs, Pk i : Pk i = min{p ∈ N : ⌊ai · kp⌋ < ⌊bi · kp⌋} BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 5 / 16
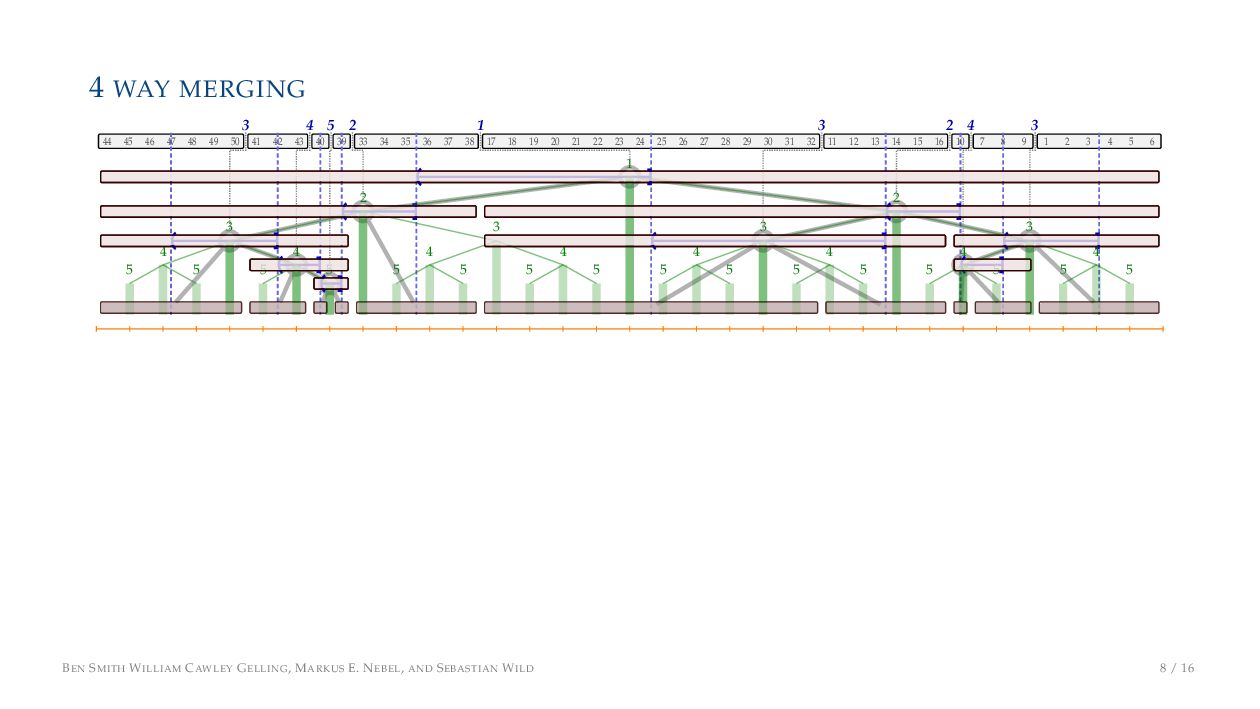
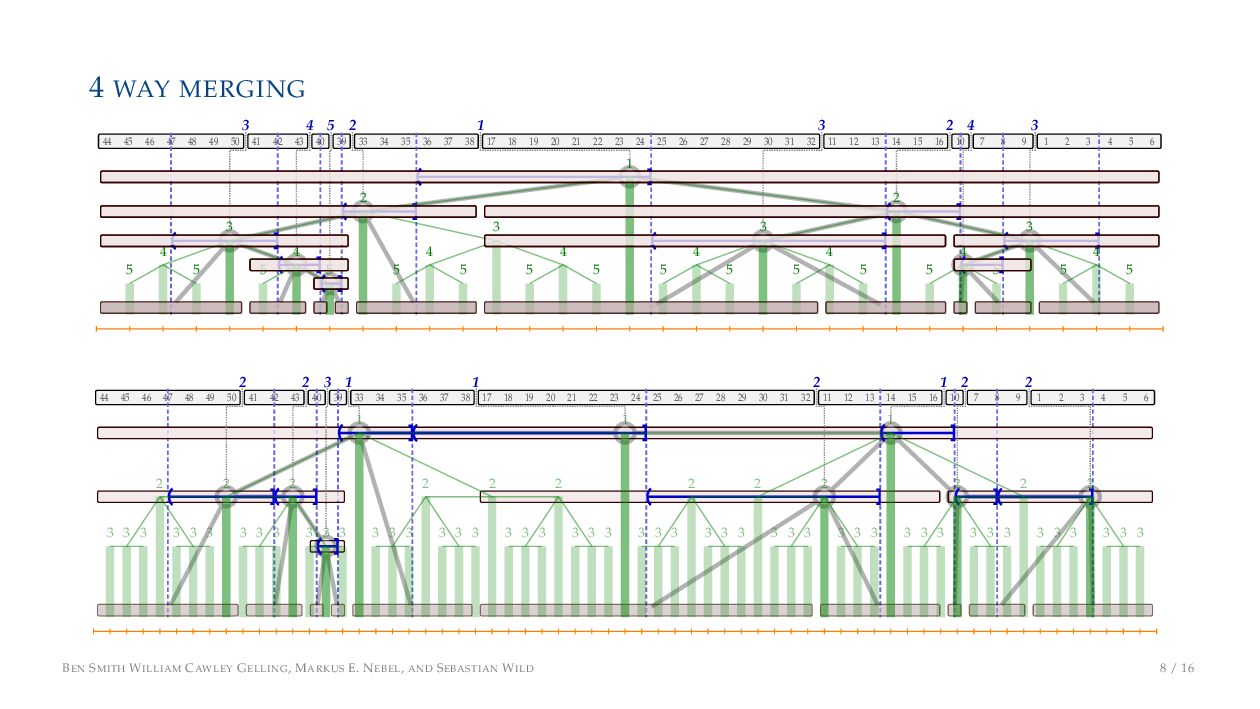
tighter bottleneck than Processor costs in various sorting algorithms (Kushagra et.al., 2014) • But it’s a close run thing! ▶ To reduce these costs, take inspiration from external memory techniques/algorithms • Specifically, k-way merging ▶ Tuning is important: • Low k reduces Processor costs and is easy to implement • High k reduces Memory costs (I/Os) but is harder to implement • Optimal value depends on data type, hardware, language,.. . BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 7 / 16
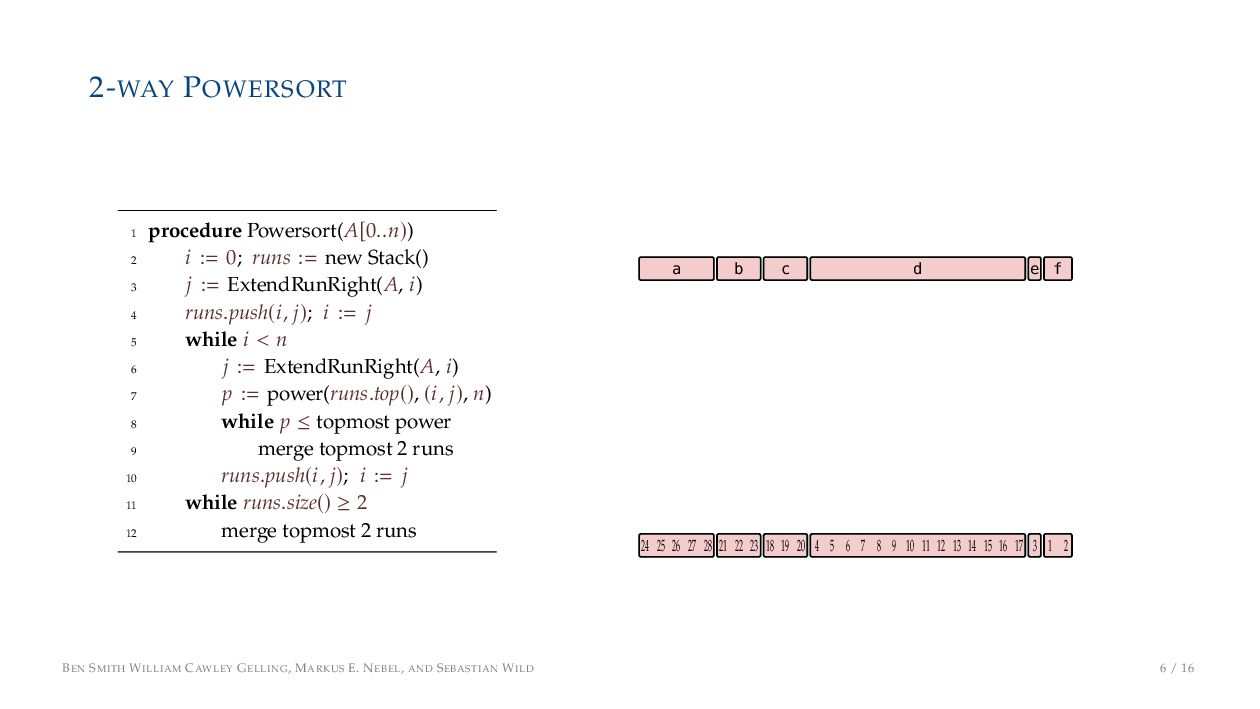
on the stack with the same power ▶ Handle but using a multi-way merge ▶ Specifically, a Winner tree, using sentinels wherever possible BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 9 / 16
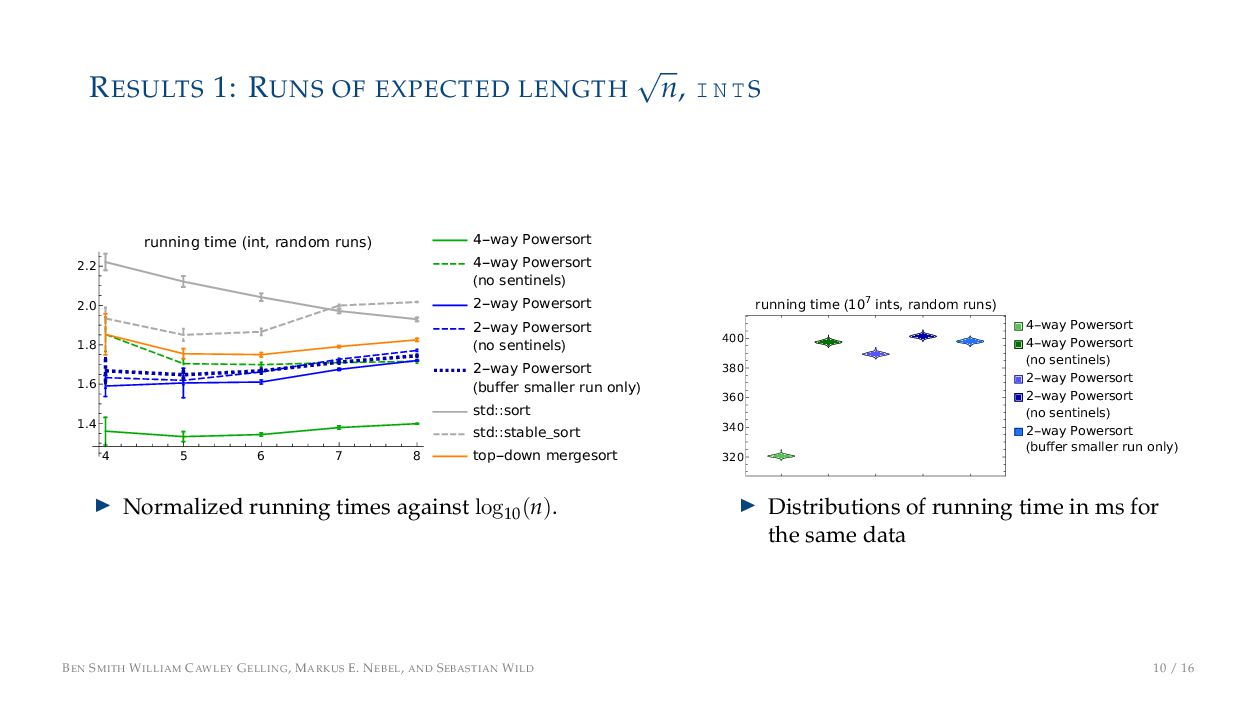
TS 4 5 6 7 8 1.4 1.6 1.8 2.0 2.2 running time (int, random runs) 4-way Powersort 4-way Powersort (no sentinels) 2-way Powersort 2-way Powersort (no sentinels) 2-way Powersort (buffer smaller run only) std::sort std::stable_sort top-down mergesort ▶ Normalized running times against log10 (n). 320 340 360 380 400 running time (107 ints, random runs) 4-way Powersort 4-way Powersort (no sentinels) 2-way Powersort 2-way Powersort (no sentinels) 2-way Powersort (buffer smaller run only) ▶ Distributions of running time in ms for the same data BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 10 / 16
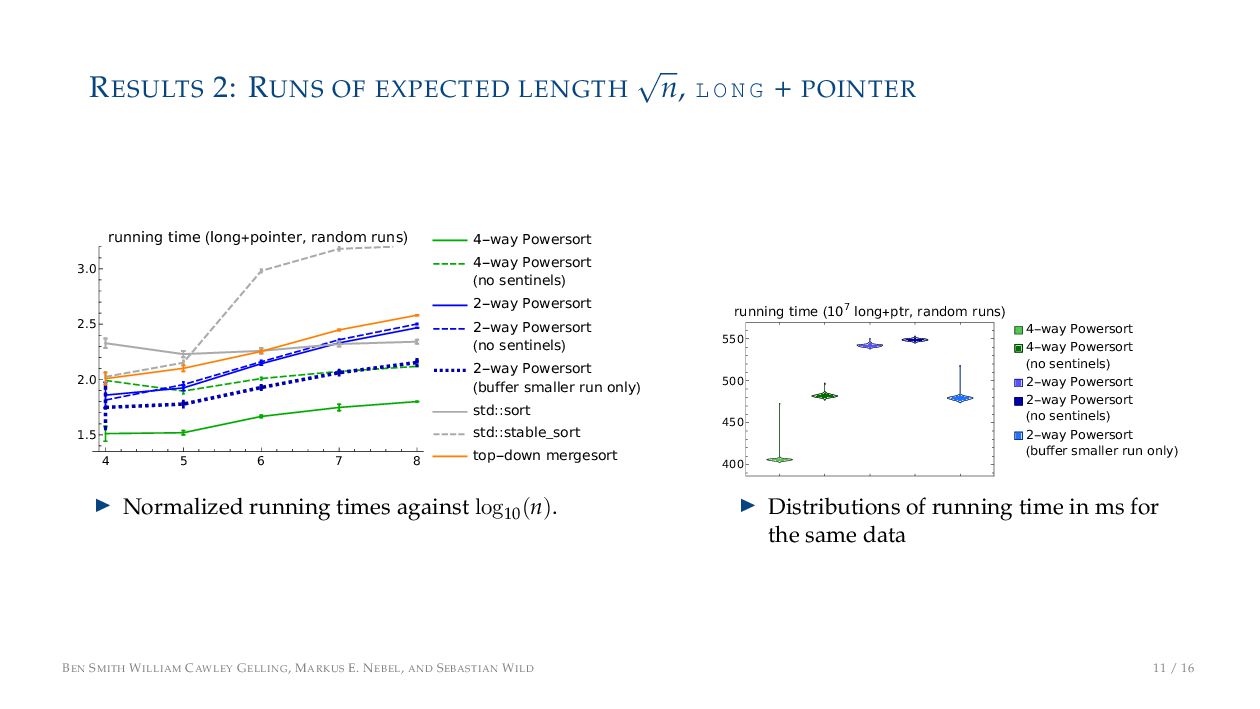
N G + POINTER 4 5 6 7 8 1.5 2.0 2.5 3.0 running time (long+pointer, random runs) 4-way Powersort 4-way Powersort (no sentinels) 2-way Powersort 2-way Powersort (no sentinels) 2-way Powersort (buffer smaller run only) std::sort std::stable_sort top-down mergesort ▶ Normalized running times against log10 (n). 400 450 500 550 running time (107 long+ptr, random runs) 4-way Powersort 4-way Powersort (no sentinels) 2-way Powersort 2-way Powersort (no sentinels) 2-way Powersort (buffer smaller run only) ▶ Distributions of running time in ms for the same data BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 11 / 16
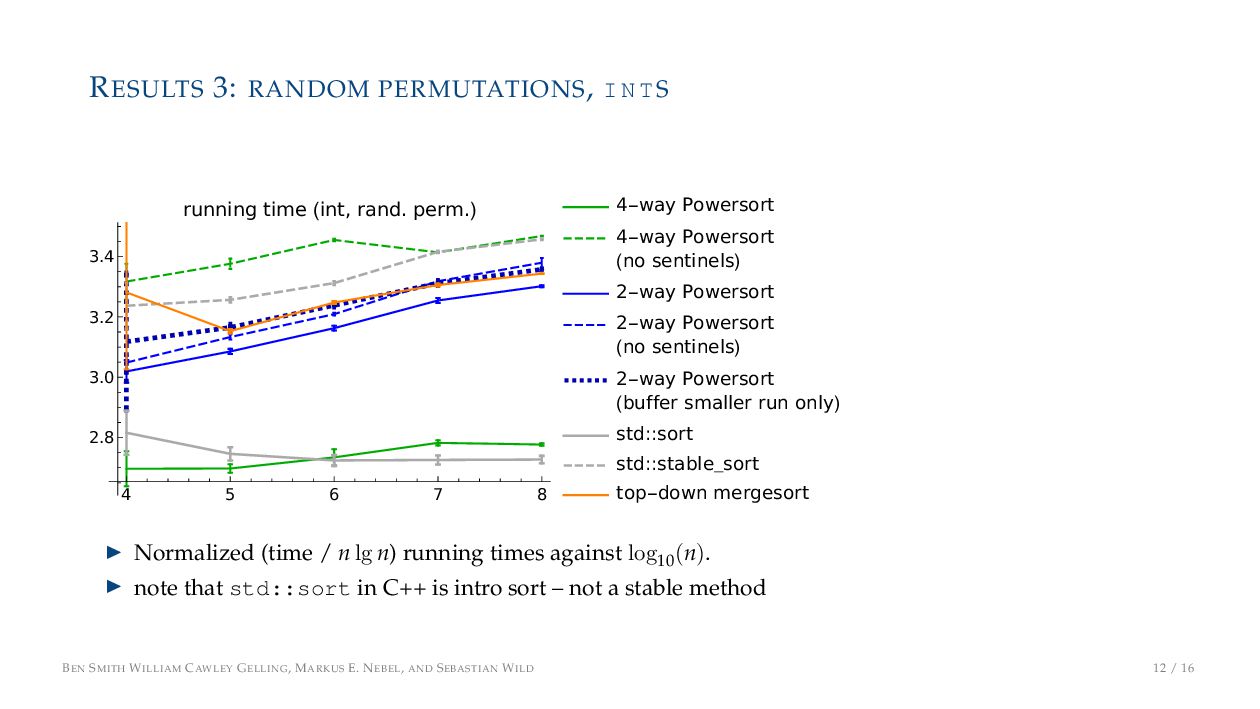
7 8 2.8 3.0 3.2 3.4 running time (int, rand. perm.) 4-way Powersort 4-way Powersort (no sentinels) 2-way Powersort 2-way Powersort (no sentinels) 2-way Powersort (buffer smaller run only) std::sort std::stable_sort top-down mergesort ▶ Normalized (time / n lg n) running times against log10 (n). ▶ note that std::sort in C++ is intro sort – not a stable method BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 12 / 16
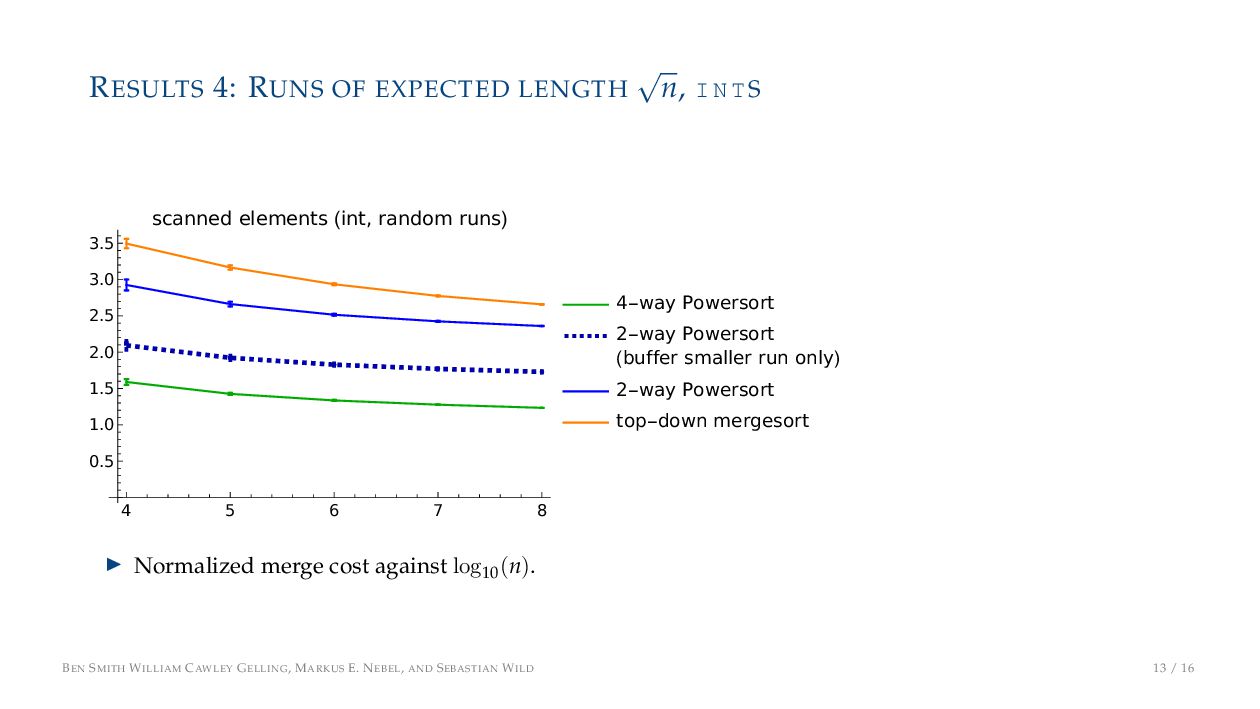
TS 4 5 6 7 8 0.5 1.0 1.5 2.0 2.5 3.0 3.5 scanned elements (int, random runs) 4-way Powersort 2-way Powersort (buffer smaller run only) 2-way Powersort top-down mergesort ▶ Normalized merge cost against log10 (n). BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 13 / 16
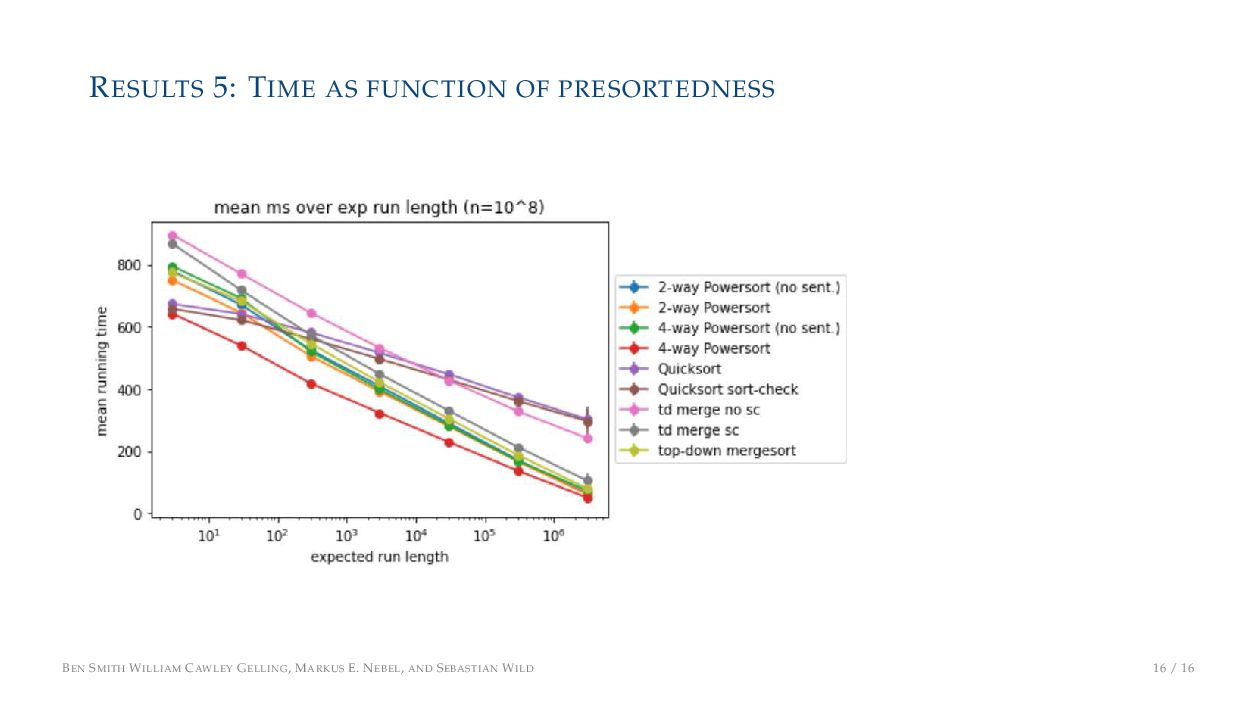
improvements • This can be explained by its reduced merge cost • Some of these results rely on the use of sentinels BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 14 / 16
improvements • This can be explained by its reduced merge cost • Some of these results rely on the use of sentinels ▶ Further Work • Fast multi-way merging without simple sentinels • Study multi-way powersort in a wider technological context • Compare multi-way powersort with more competitors, specifically multiway quicksort variants. BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 14 / 16
improvements • This can be explained by its reduced merge cost • Some of these results rely on the use of sentinels ▶ Further Work • Fast multi-way merging without simple sentinels • Study multi-way powersort in a wider technological context • Compare multi-way powersort with more competitors, specifically multiway quicksort variants. ▶ Recommendations • Users of Timsort should seriously consider the Powersort merge policy • Users of Timsort and 2-way powersort may wish to consider multi-way Powersort ▶ Particularly where comparisons are cheap and sentinels are useable BEN SMITH WILLIAM CAWLEY GELLING, MARKUS E. NEBEL, AND SEBASTIAN WILD 14 / 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}