Plan and prepare for incidents • Ensure issues are never missed, and the right people are notified • Gain insights to improve your operational efficiency
At this point, we started leveraging AWS Lambda to help our customer run custom code First production usage Started using AWS Lambda for leveraging async / not business critical jobs such as DynamoDB autoscale 2016
At this point, we started leveraging AWS Lambda to help our customer run custom code First production usage Started using AWS Lambda for leveraging async / not business critical jobs such as DynamoDB autoscale 2016 Service and Incident Management A new customer facing feature running on AWS Lambda integrated with the rest of the code base. 2017
At this point, we started leveraging AWS Lambda to help our customer run custom code First production usage Started using AWS Lambda for leveraging async / not business critical jobs such as DynamoDB autoscale 2016 Service and Incident Management A new customer facing feature running on AWS Lambda integrated with the rest of the code base. 2017 A Spinoff: Thundra Observability for AWS Lambda 2018
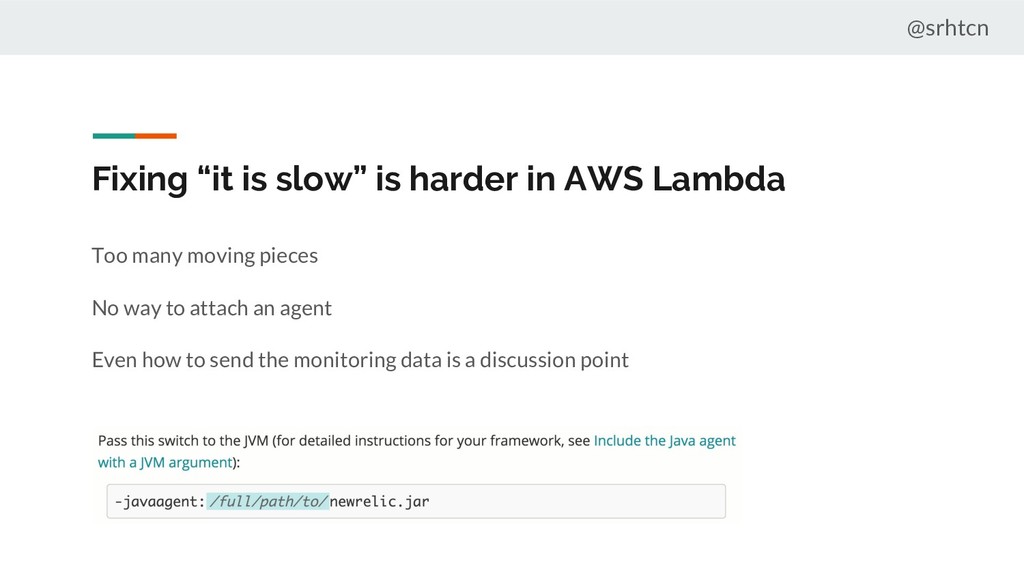
it Increase memory (and pay more) Lightweight application framework instead of Spring Do some smart warm-up https://medium.com/thundra/dealing-with-cold-starts-in-aws-lambda-a5e3aa8f532
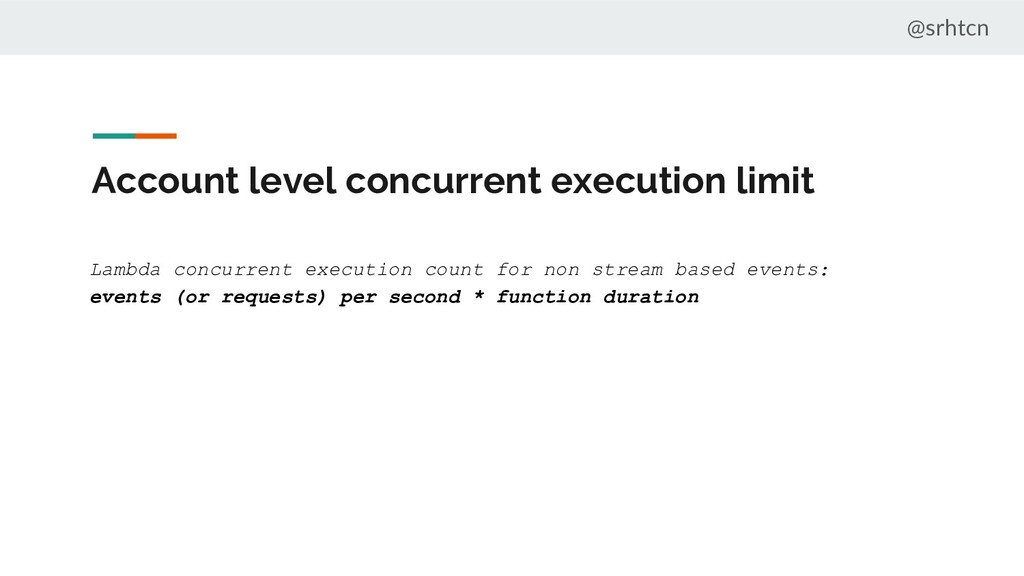
for non stream based events: events (or requests) per second * function duration Hard to deal with peaks in request numbers Takes time to increase the limit Functions affect each other’s scalability
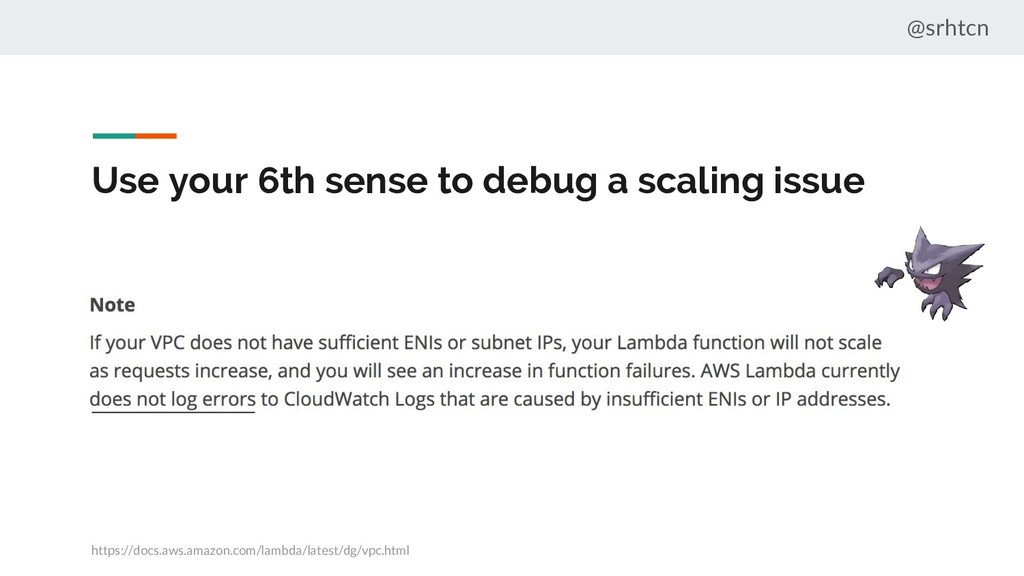
have to You need sufficient IP addresses in your subnet and ENI to scale https://docs.aws.amazon.com/lambda/latest/dg/vpc.html Determine the ENI capacity you need: Concurrent executions * (Memory in GB / 3 GB)
Thread counts & durations, CPU usage details Get the stack trace in case of an error and drill down See logs, traces, and metrics in one view thundra.io What we needed was
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}