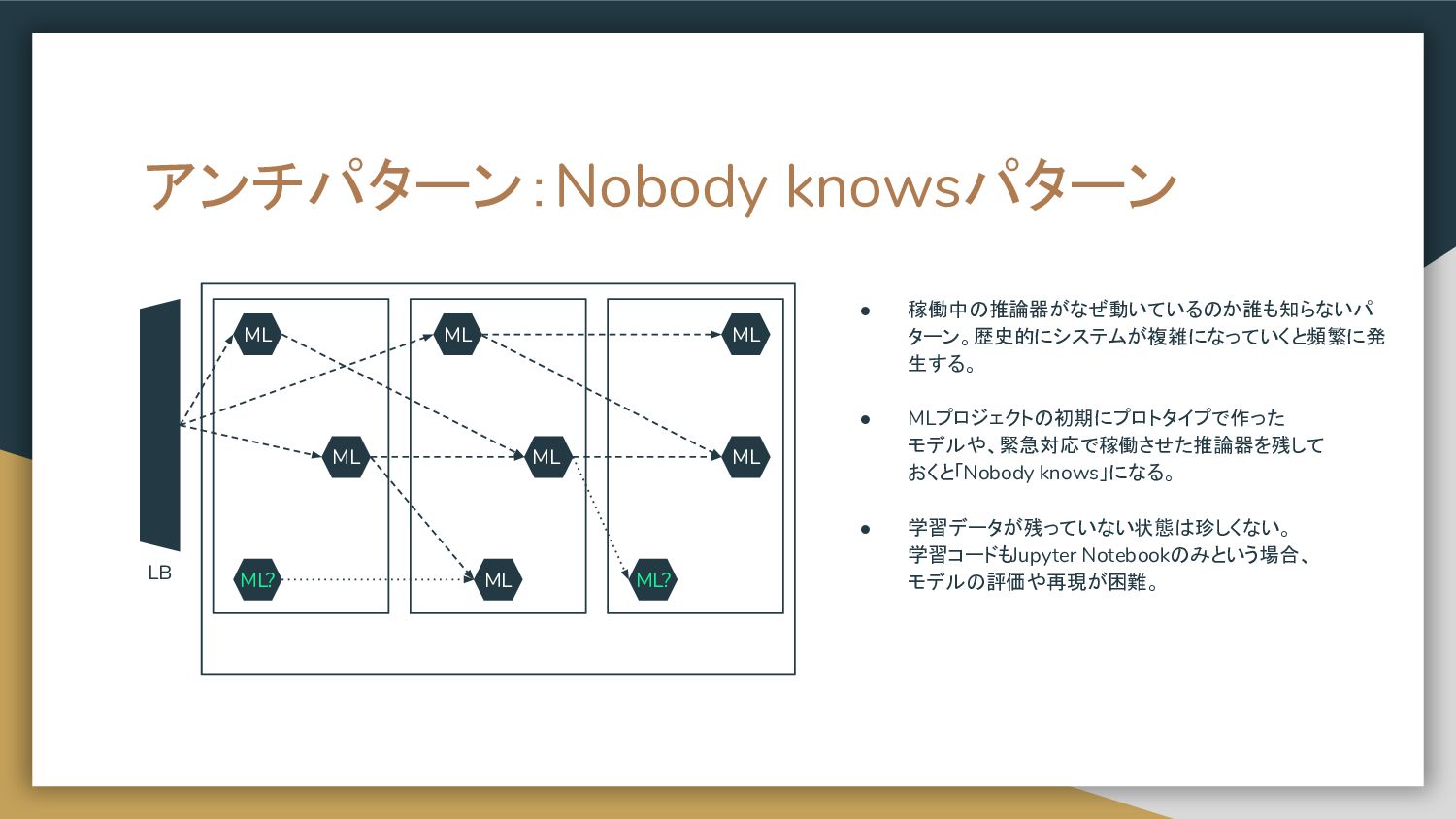
• 推論のインターフェイス(入力データの型と shape、出力データの型とshape、意味)および サンプルデータを定義しておく。 import load local data evaluate retrain define ml train save model git no training data 99.99% ???
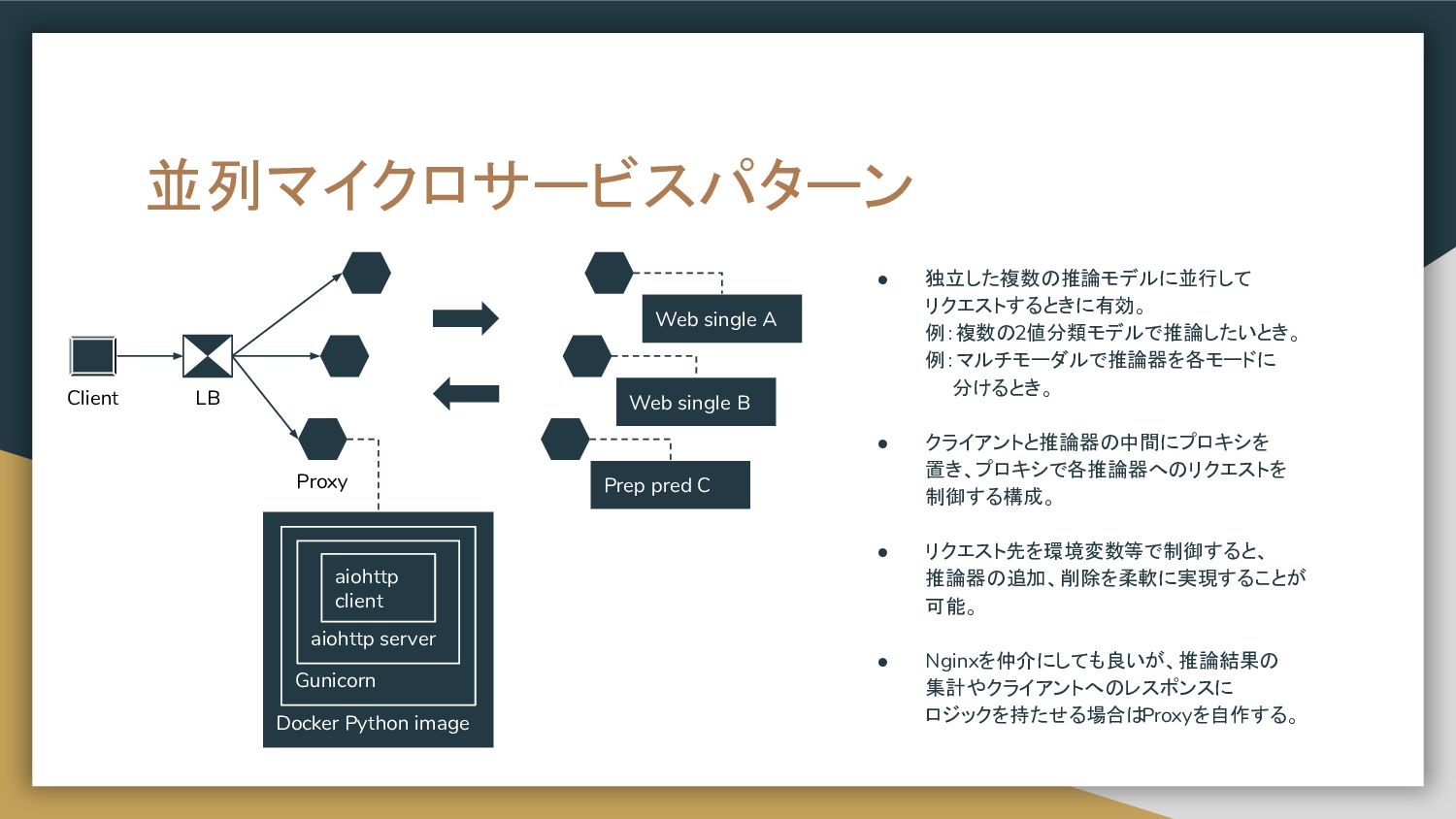
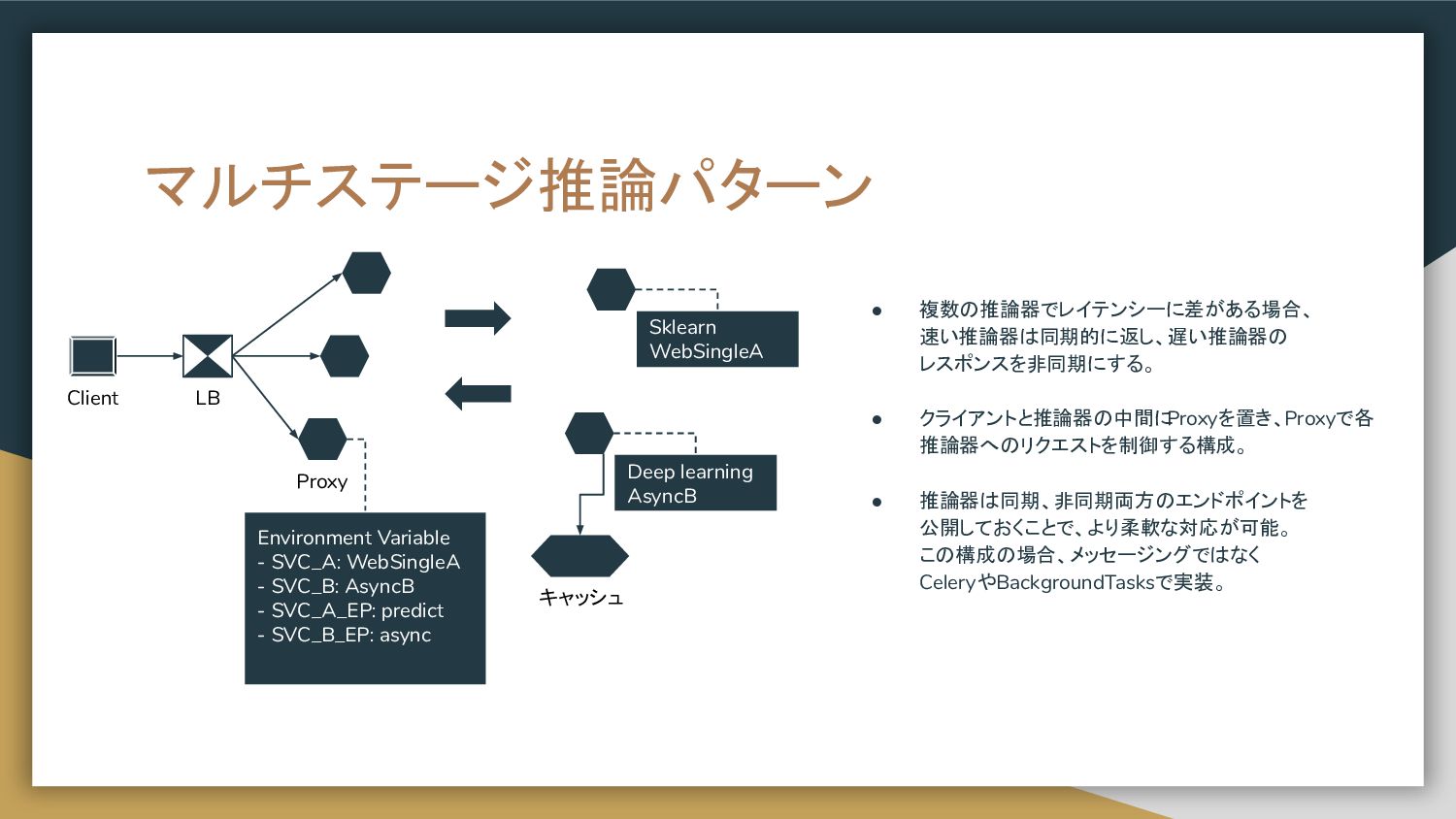
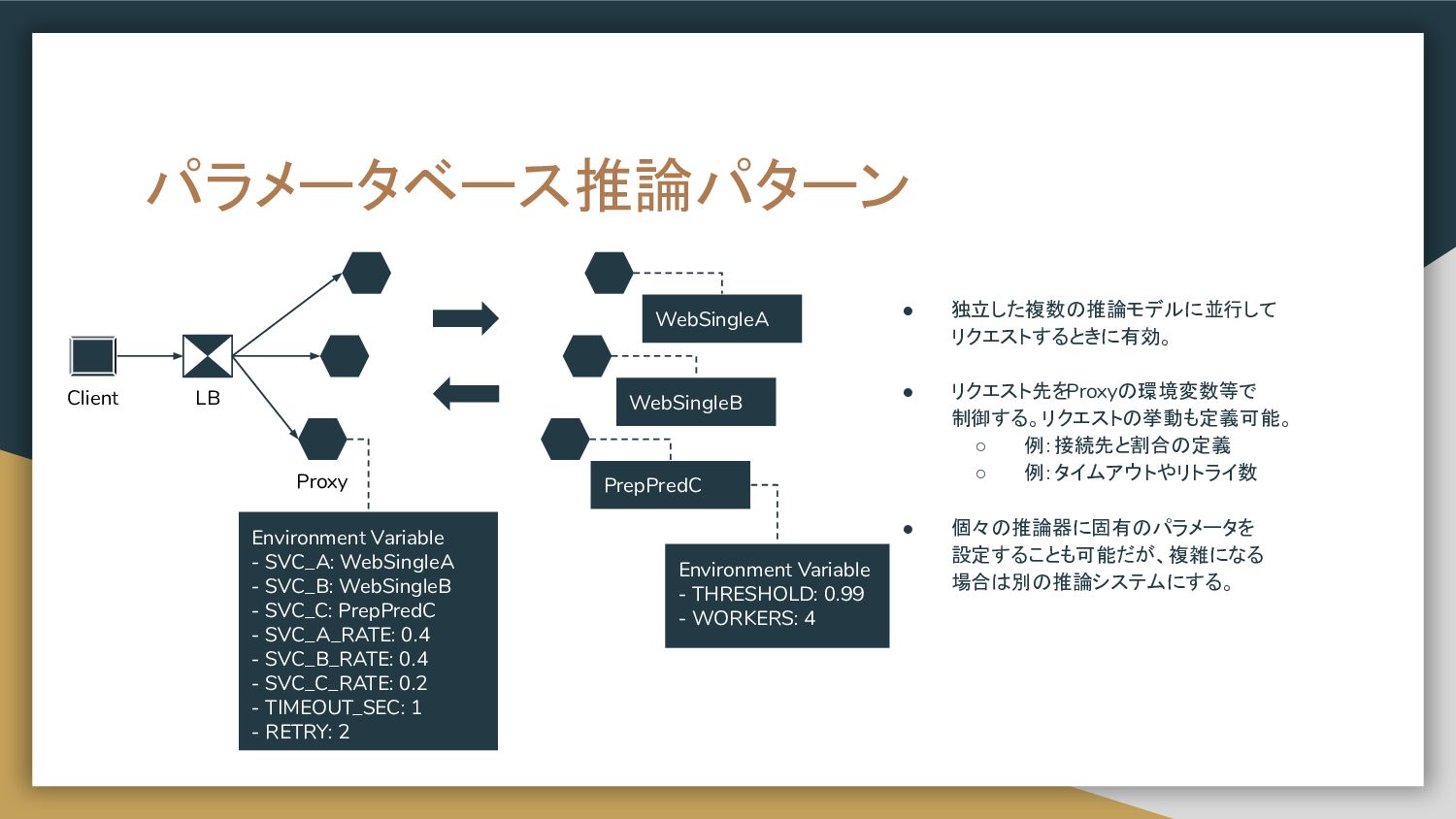
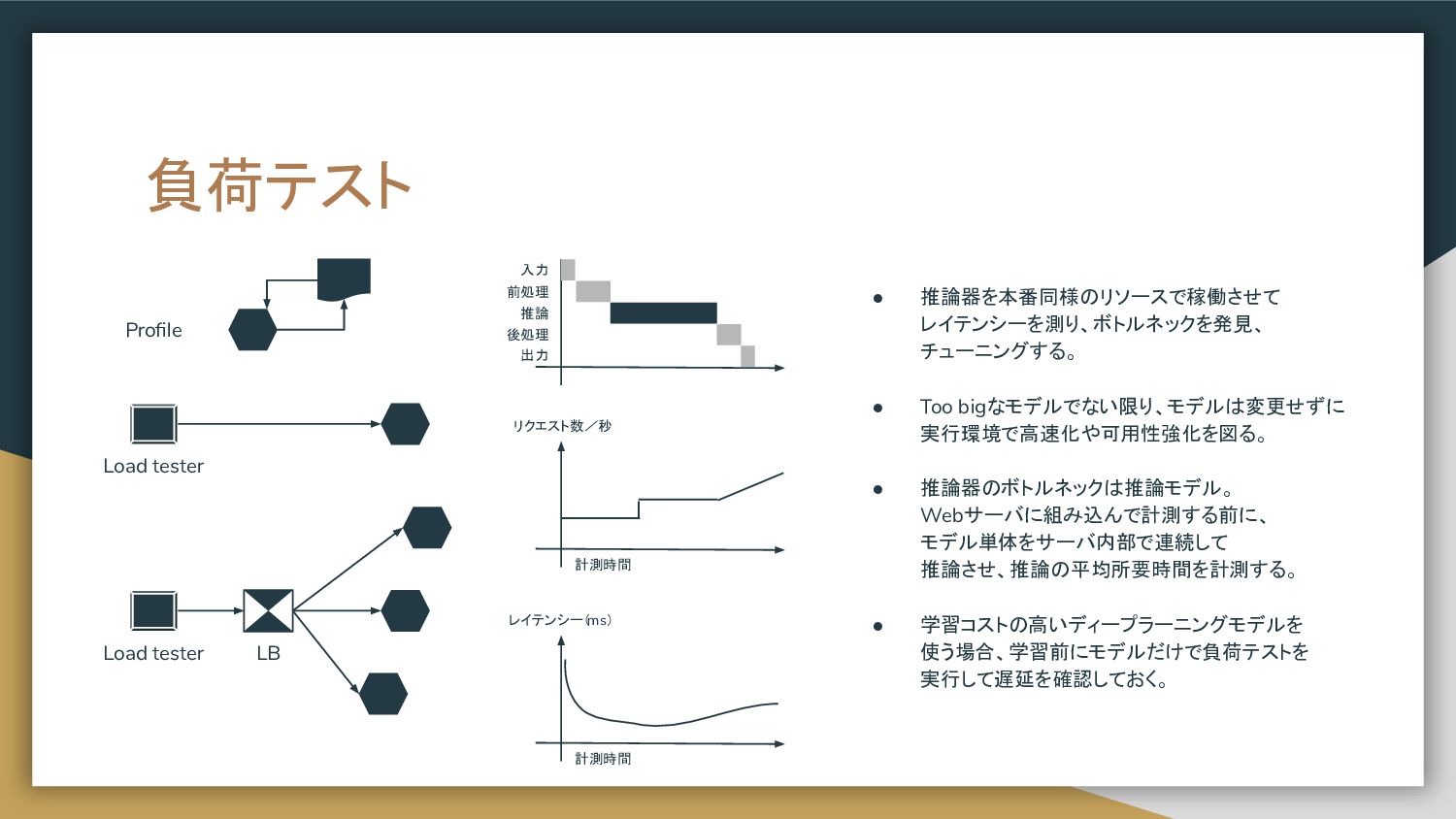
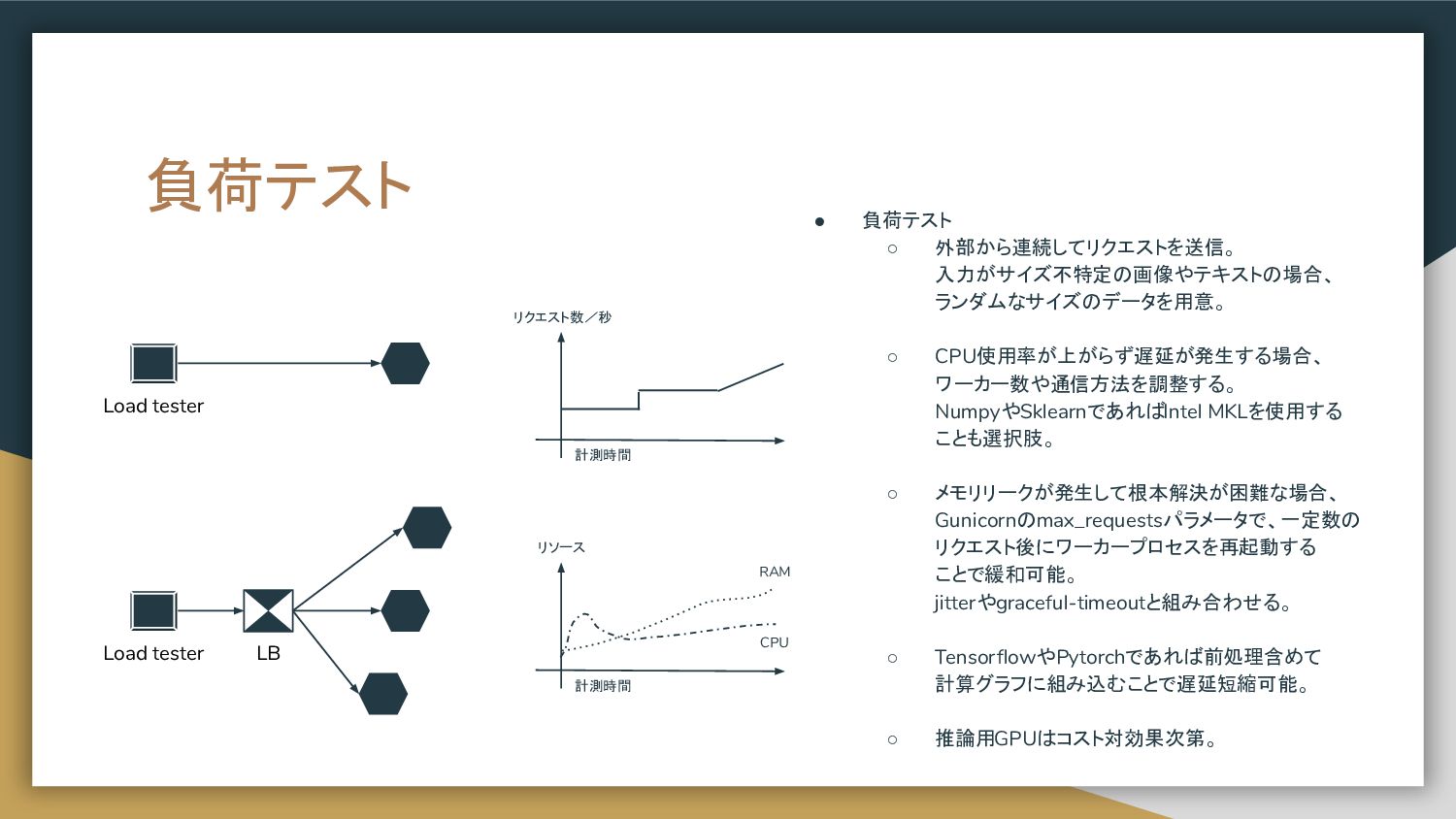
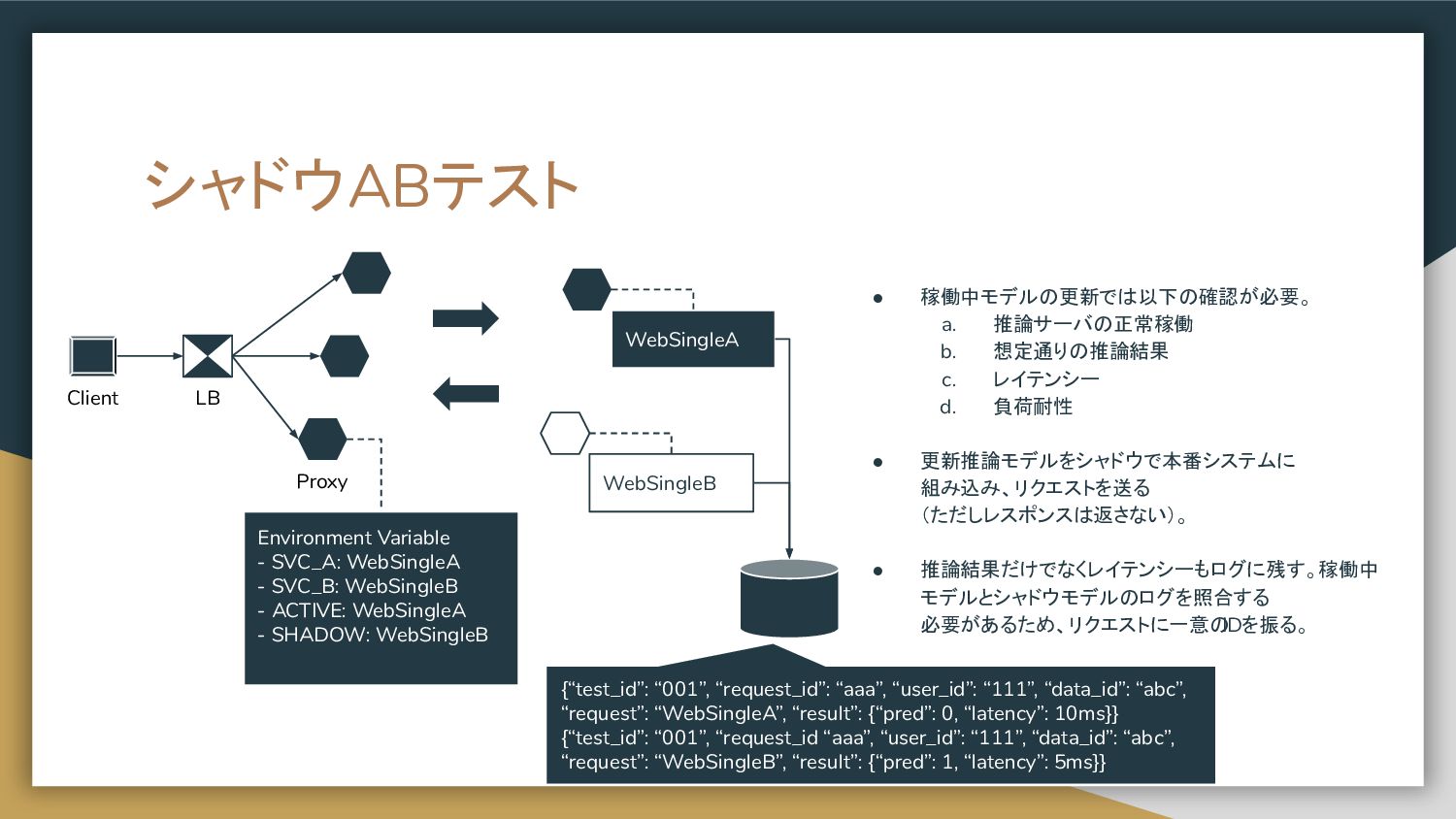
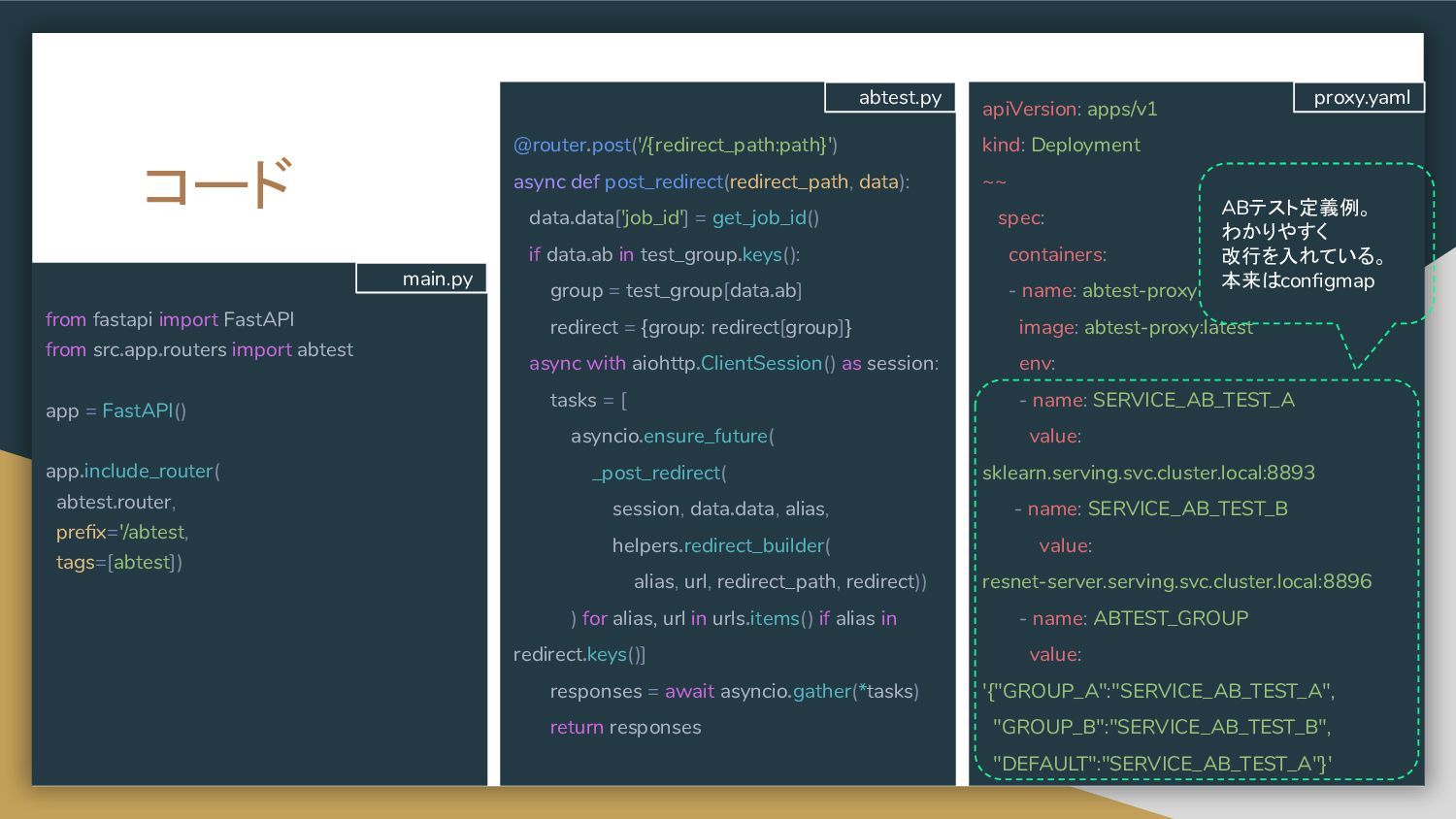
置き、プロキシで各推論器へのリクエストを 制御する構成。 • リクエスト先を環境変数等で制御すると、 推論器の追加、削除を柔軟に実現することが 可能。 • Nginxを仲介にしても良いが、推論結果の 集計やクライアントへのレスポンスに ロジックを持たせる場合は Proxyを自作する。 Docker Python image Gunicorn aiohttp server aiohttp client LB Web single A Prep pred C Web single B Proxy
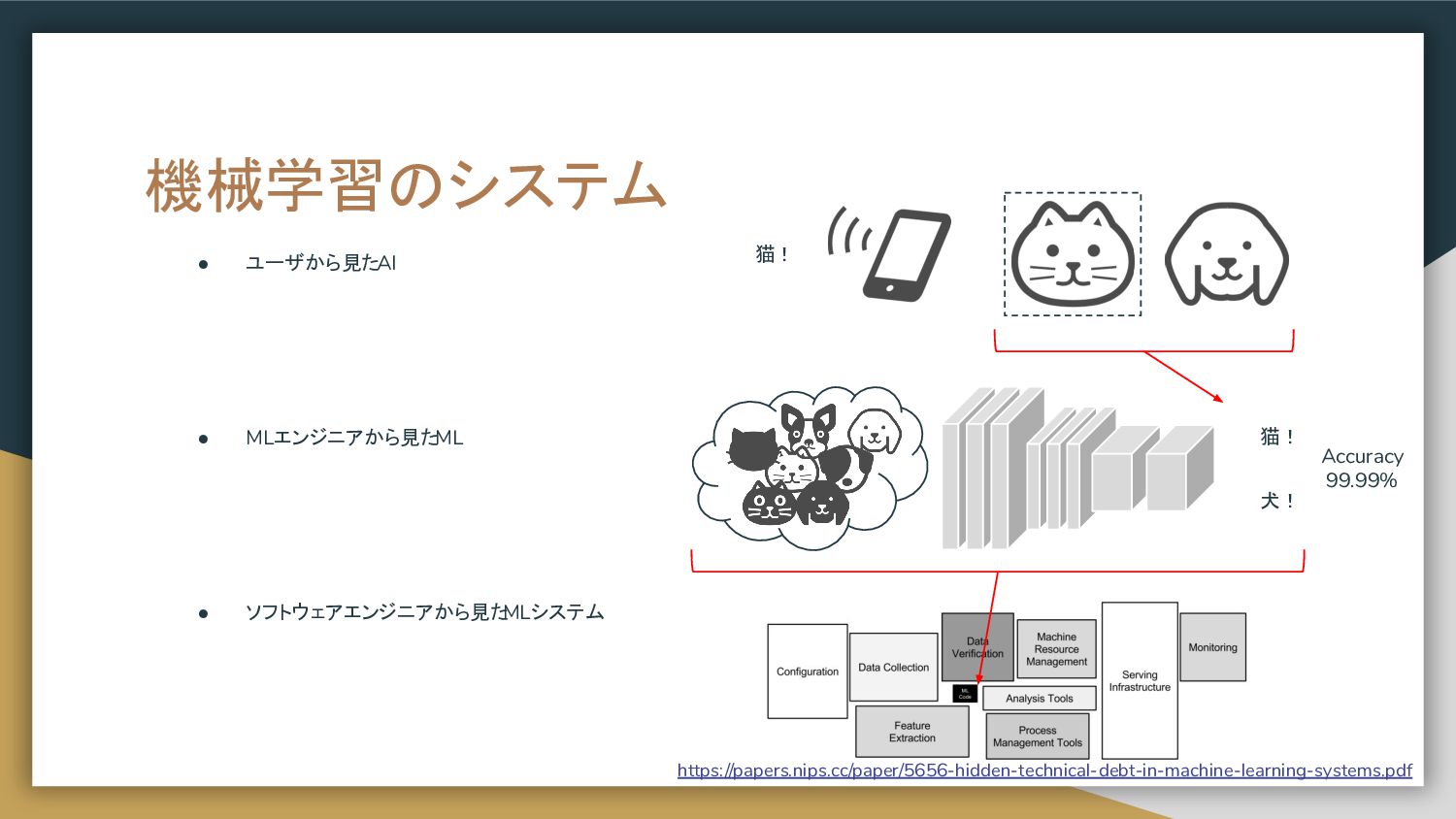
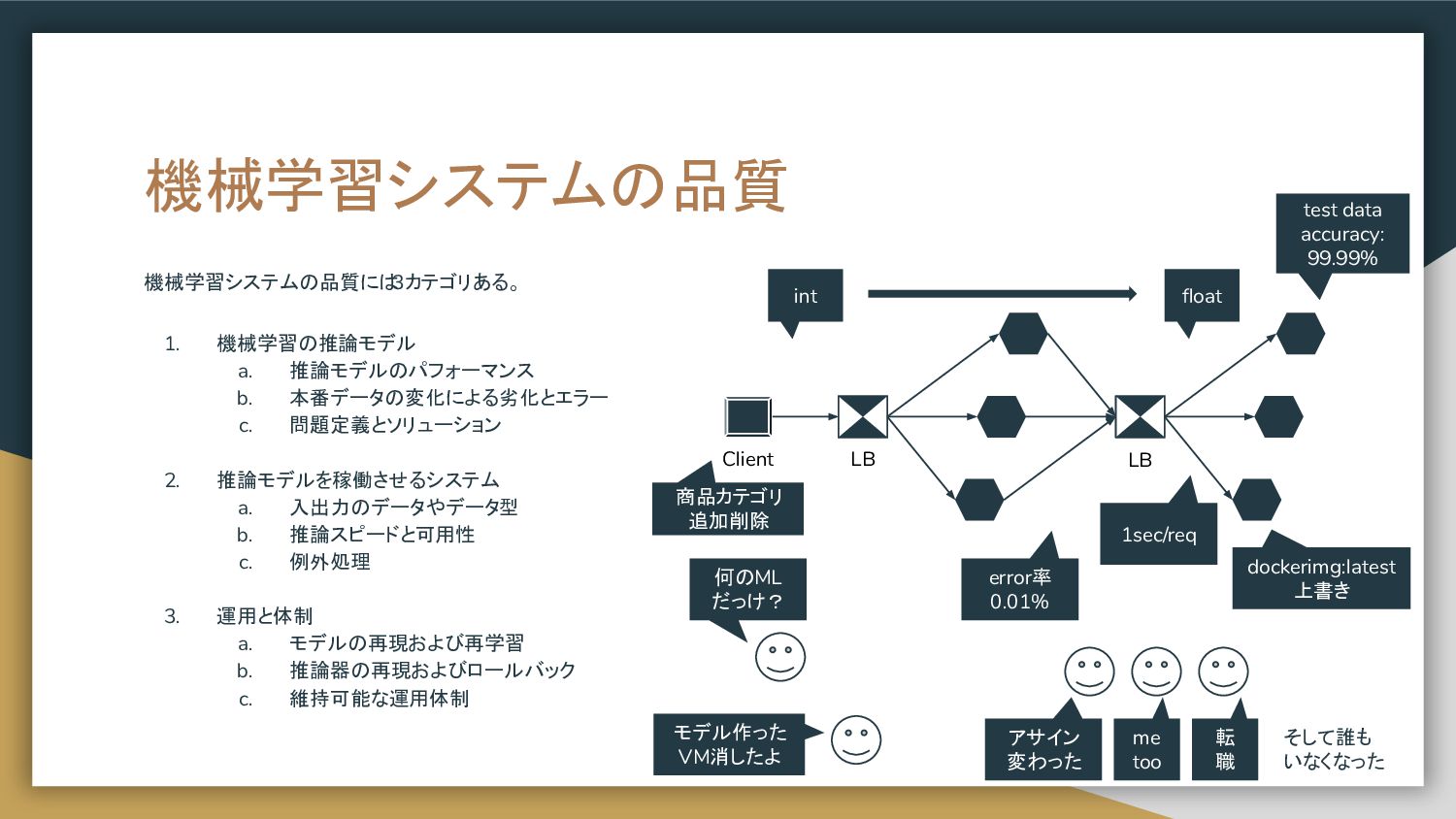
問題定義とソリューション 2. 推論モデルを稼働させるシステム a. 入出力のデータやデータ型 b. 推論スピードと可用性 c. 例外処理 3. 運用と体制 a. モデルの再現および再学習 b. 推論器の再現およびロールバック c. 維持可能な運用体制 Client LB LB int float test data accuracy: 99.99% 何のML だっけ? 1sec/req モデル作った VM消したよ dockerimg:latest 上書き error率 0.01% アサイン 変わった me too 転 職 商品カテゴリ 追加削除 そして誰も いなくなった
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
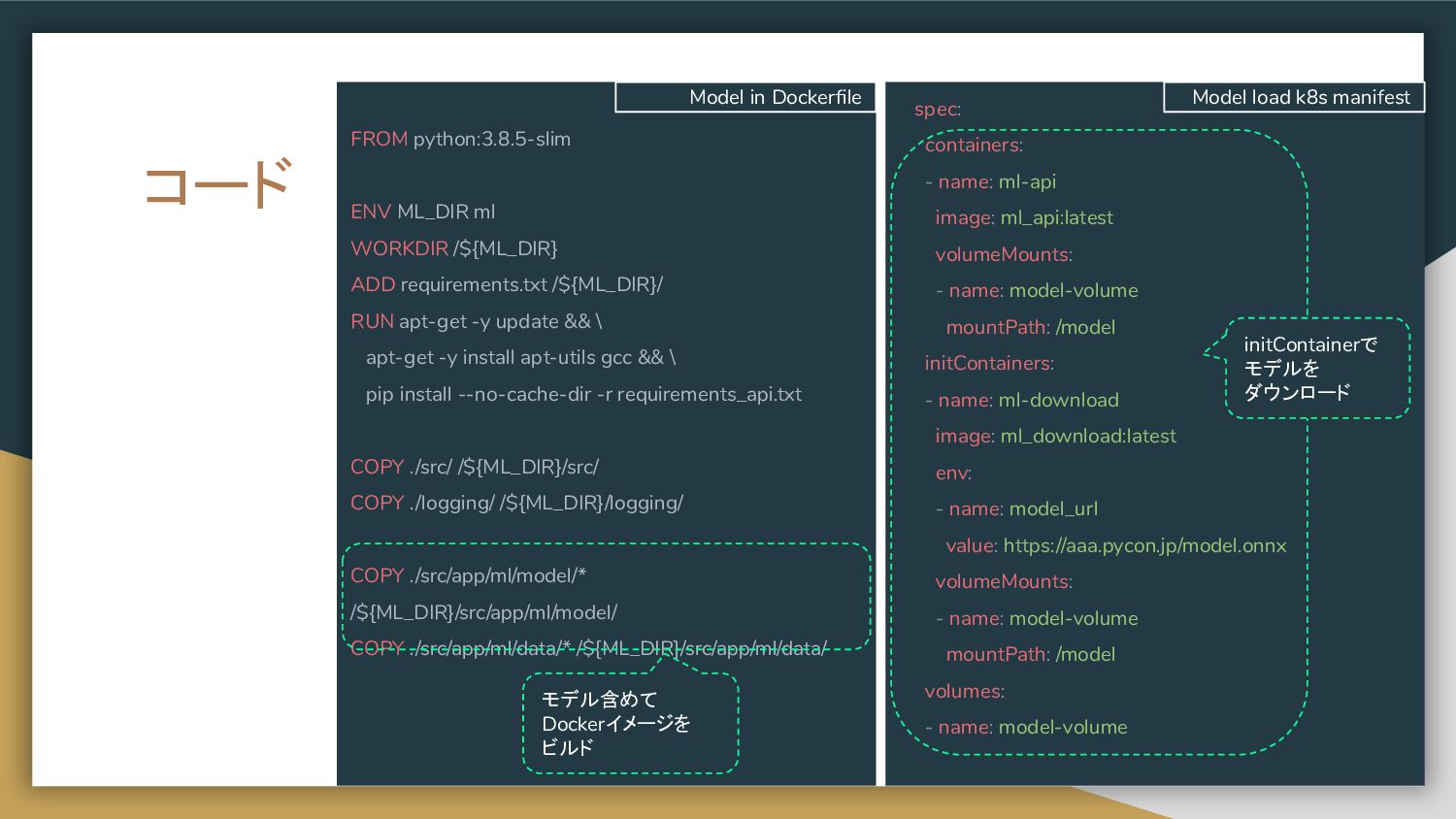{kind=link}
{kind=link}
{kind=link}
{kind=link}
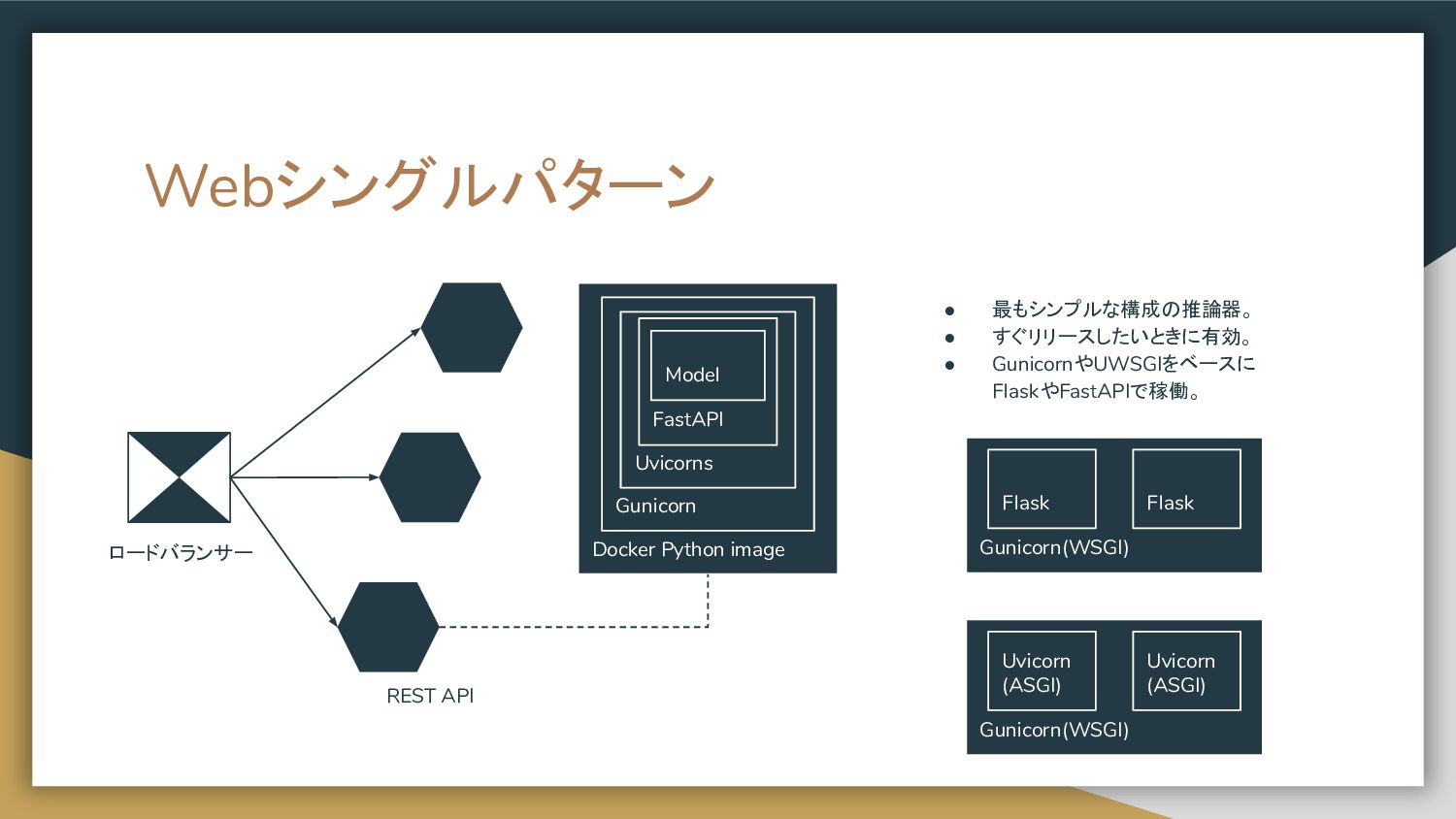{kind=link}
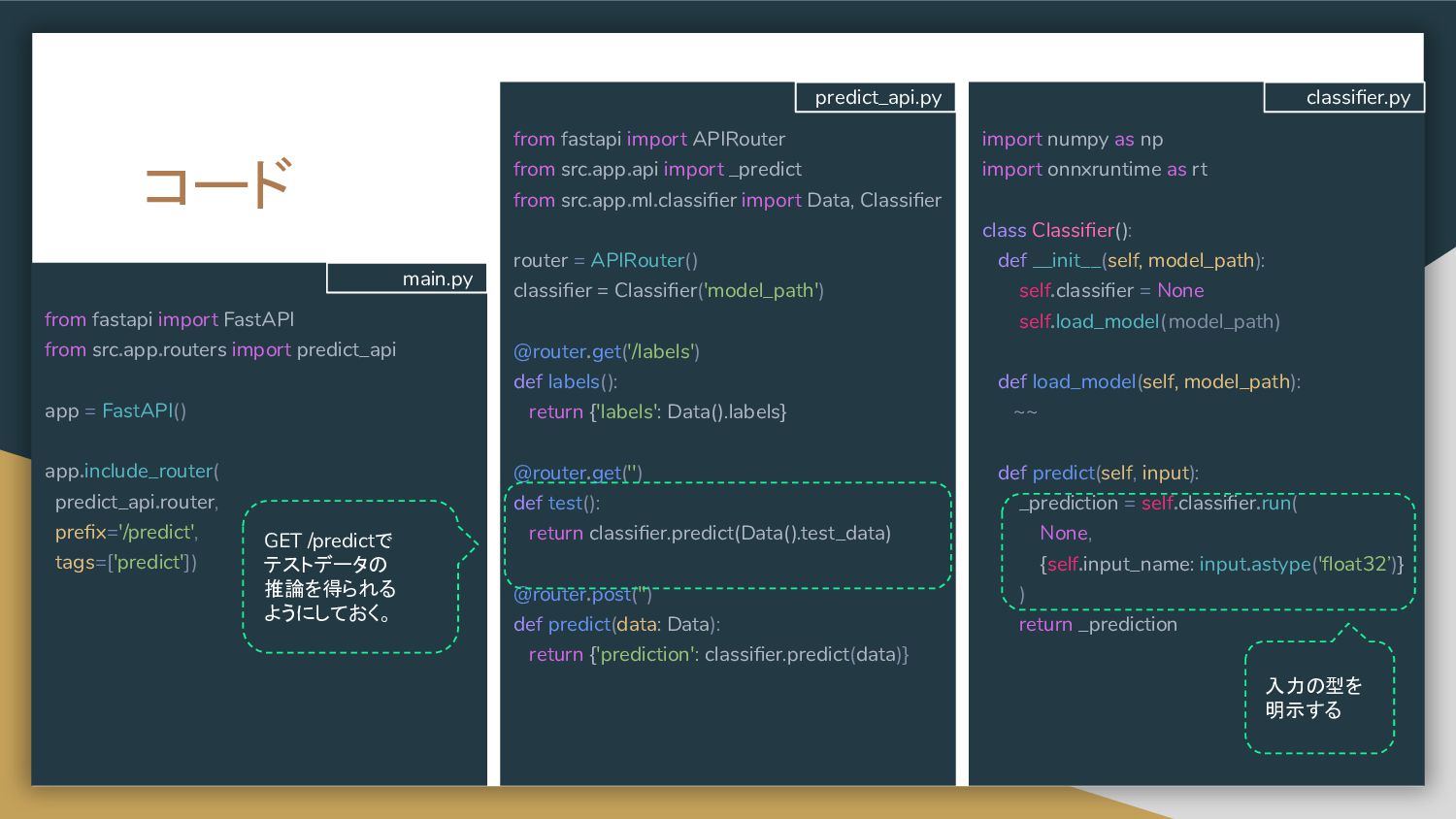{kind=link}
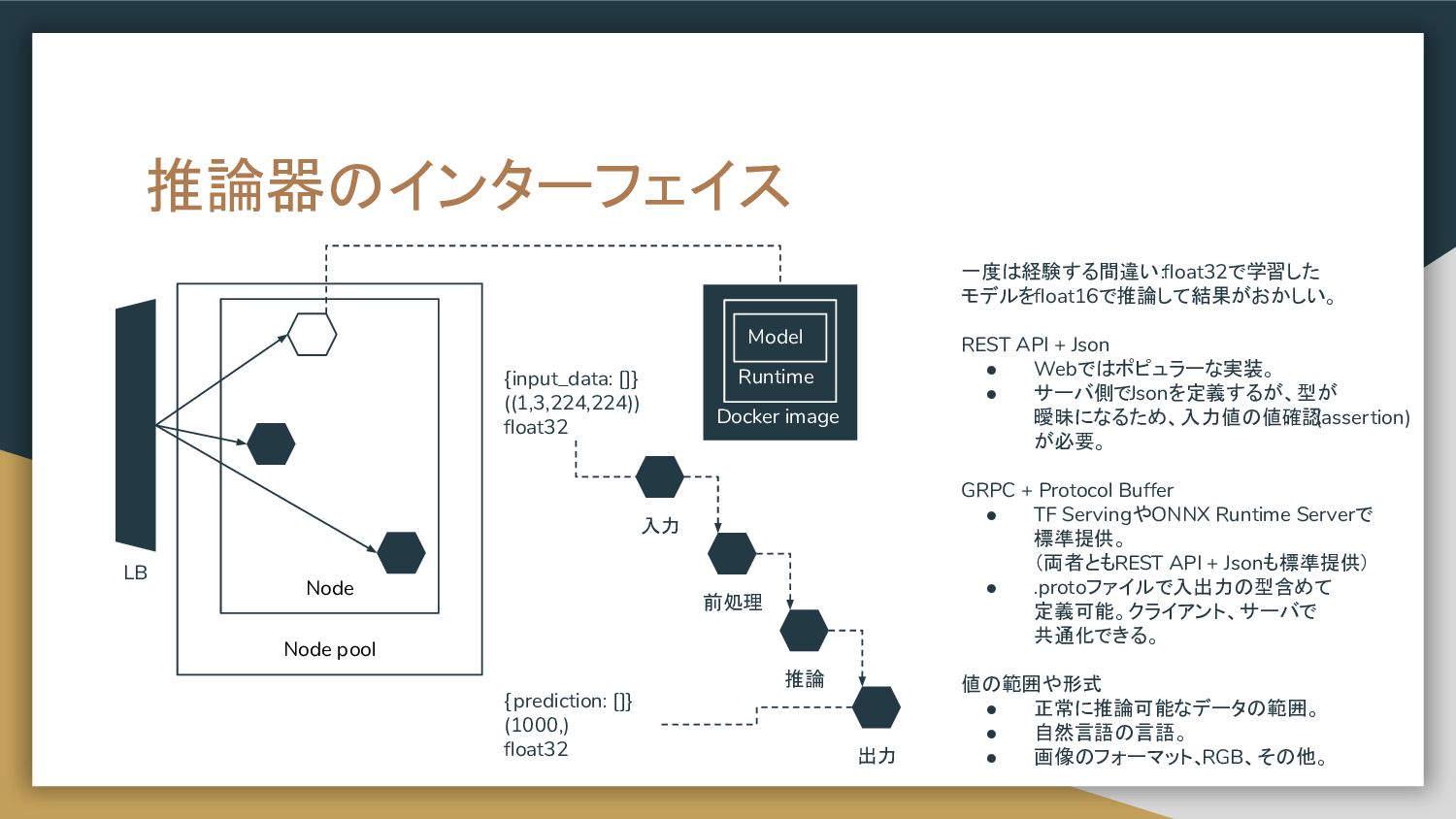{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}