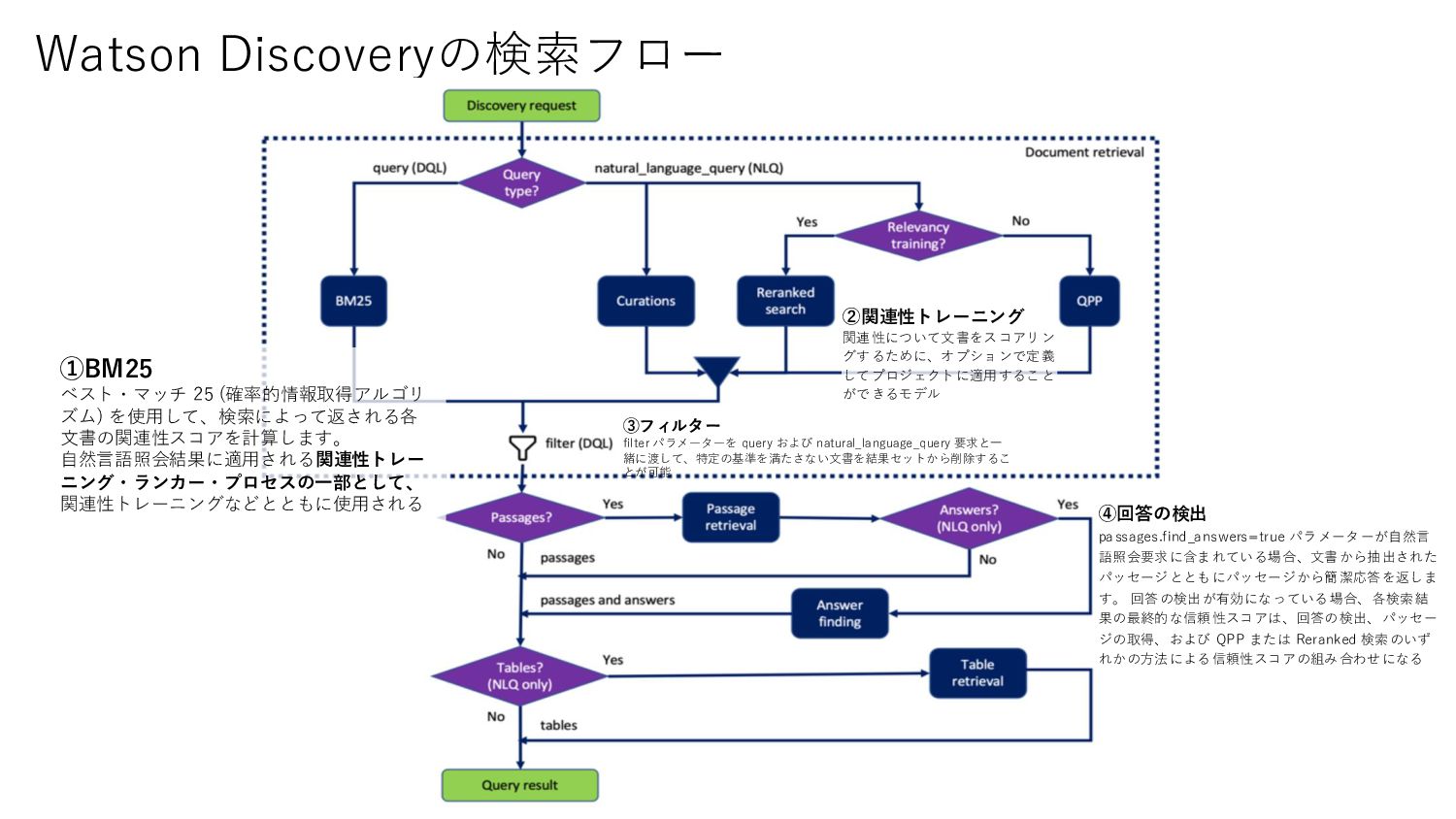
関連性が高い情報だけLLMに投入することで、「Lost in the middle」問題を 軽減(生成AIが入力コンテキストから必要な情報を見つけ、それを用いて質問 に答えるタスクにおいて、長文コンテキストの真ん中に重要情報がある場合に それを見逃す問題) 低コストで効果的に精度を向上させることが可能!
Red Hat? ✓ パッセージ: “IBM closed its $34 billion acquisition of Red Hat in July of 2019." 例) “IBMの2022年の売上はいくらか? ” IBMの2022年の売上がいくらか書いてある文書があれば、正しい答えを得ることが できます。 しかし、IBMの2022年の各四半期の収益が記載された文書があったと しても、それらを合計して合計を出すことは行いません。 パッセージ 回答 1. ユーザーが自然言語で質問を入力 2. 文書群から文書を検索 3. 回答を含むパッセージ(文節)を検索 4. [新規部分] パッセージの中から、さらに回答の箇所を検索
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}