OCR) is the conversion of images of handwritten or printed text into a machine-encoded text. ▪ The usage can vary from reading a business card to automated address tagging on the postal packages to reading number plates. The possibilities are huge.
written in the Latin script ▪ Ottaksharas are disconnected from the parent character and thus can be easily ignored by segmentation algorithms, thereby causing loss of data ▪ Ottaksharas are located diagonally below the parent character
to reduce image data. • Calculate binary threshold using Otsu optimization. Prevent manual calculation using trial and error. • Perform binary thresholding using the threshold. This reduces the image to a binary matrix.
2. RETR_EXTERNAL returns only the outermost contours and thus ignores the minor inner contours that arise due to uneven ink or poor scanning. 3. CHAIN_APPROX_NONE returns a list of co-ordinates along the contours. 4. Sort the list of contours in descending order of area. 5. Select the contour with the largest area. 6. Iterate over the co-ordinates to find the one with the lower y value. 7. Crop the part of the image below this point. 8. The cropped image contains the ottaksharas.
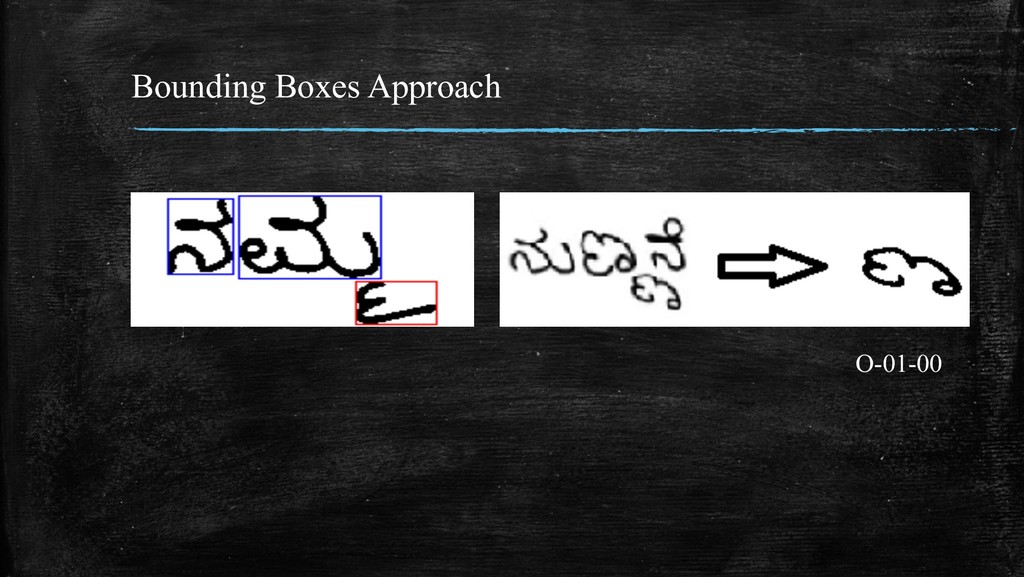
bounding boxes are each contour. 3. Ignore boxes with area less than 5% of the image area. 4. Extract corner co-ordinates of remaining boxes. 5. The bounding boxes whose top co-ordinate below half the height of the image contain an ottaksharas. 6. Since the image is parsed left-to-right, the ottaksharas can be mapped to the previous parsed character.
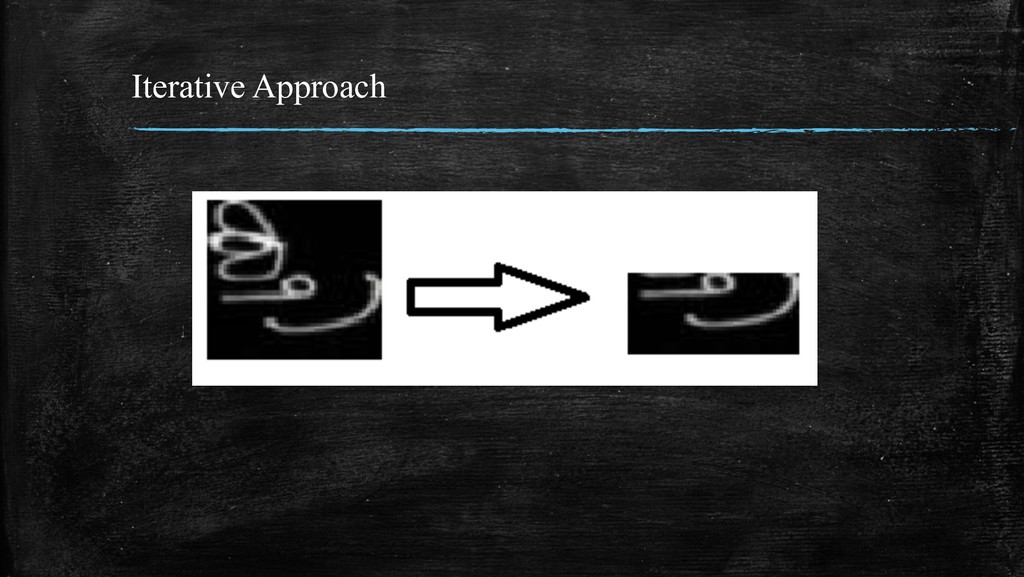
get the contours of the individual ottaksharas from the cropped image. Using the co-ordinates from the contours, they can drawn on a blank canvas, thus giving us images of single ottaksharas.
ottakshara, the time taken by the scripts (in seconds) are Iterative Approach Bounding Boxes Approach 0.0515 0.0081 This is expected as the time complexity of the Iterative Approach is O(n2) while that of the Bounding Boxes Approach is O(n).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}