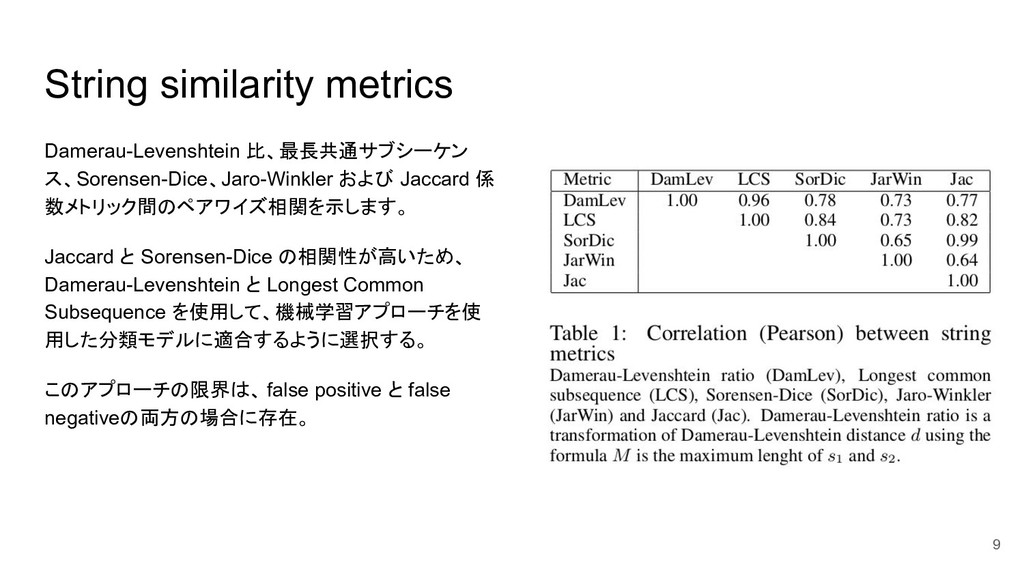
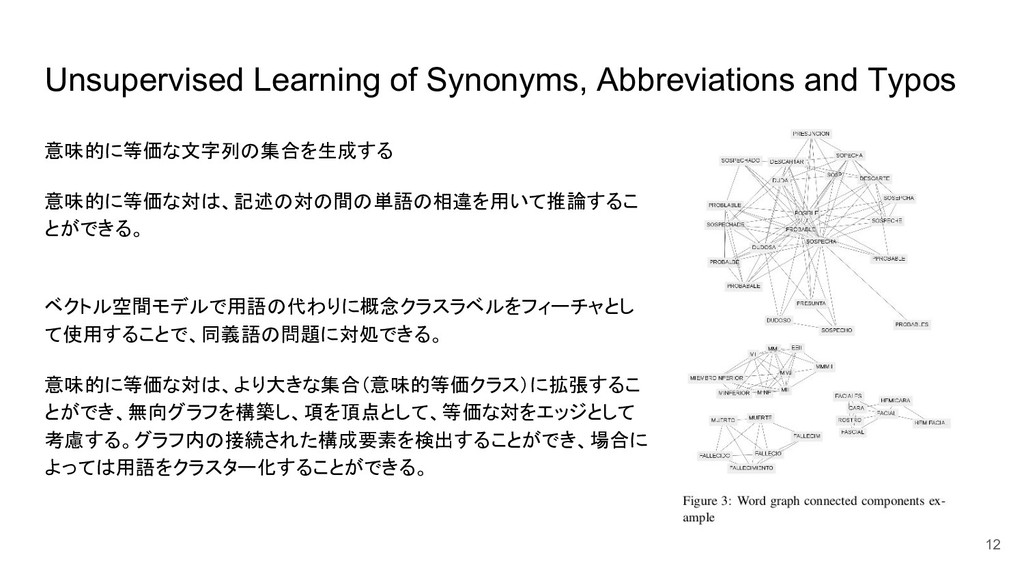
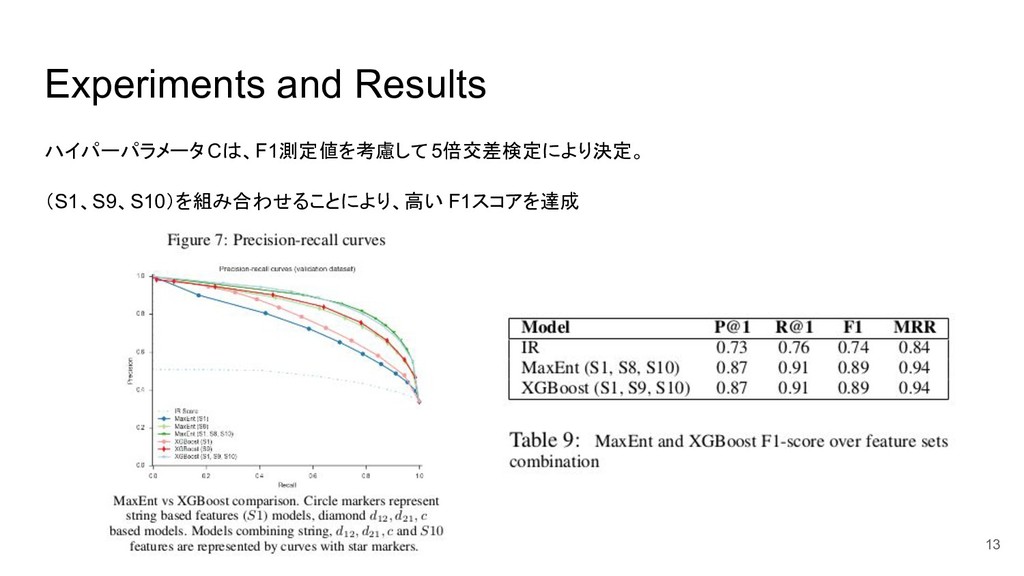
Approach to Clinical Terms Normalization José Castaño, Hernán Berinsky, Hee Park, David Pérez, Pilar Ávila, Laura Gambarte, Sonia Benı́tez, Daniel Luna, Fernando Campos and Sofı́a Zanetti Proceedings of the 15th Workshop on Biomedical Natural Language Processing, pages 1–11, 2016 Association for Computational Linguistics 長岡技術科学大学 自然言語処理研究室 多田 太郎
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}