H. J. (2013). Random effects structure for con f irmatory hypothesis testing: Keep it maximal. Journal of memory and language, 68(3), 255 – 278. • Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2015). Parsimonious Mixed Models. https://arxiv.org/abs/1506.04967v2 • Brauer, M., & Curtin, J. J. (2018). Linear mixed-effects models and the analysis of nonindependent data: A uni f ied framework to analyze categorical and continuous independent variables that vary within-subjects and/or within-items. Psychological Methods, 23(3), 389 – 411. https://doi.org/10.1037/met0000159 • Brysbaert, M., & Stevens, M. (2018). Power Analysis and Effect Size in Mixed Effects Models: A Tutorial. Journal of Cognition, 1(1), 9. https:// doi.org/10.5334/joc.10 • Burnham, K. P., & Anderson, D. R. (2004). Multimodel Inference: Understanding AIC and BIC in Model Selection. Sociological Methods & Research, 33(2), 261 – 304. https://doi.org/10.1177/0049124104268644 • Frossard, J., & Renaud, O. (2019). Choosing the correlation structure of mixed effect models for experiments with stimuli. https://arxiv.org/ abs/1903.10766v3 • Gries, S. T. (2021). (Generalized Linear) Mixed-Effects Modeling: A Learner Corpus Example. Language Learning, 71(3), 757 – 798. https:// doi.org/10.1111/lang.12448 • Hou, X. (2021). Learning two syntactic constructions simultaneously: A case of overshadowing. Language and Cognition, 13(3), 467 – 493. https://doi.org/10.1017/langcog.2021.10 • Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., & Bates, D. (2017). Balancing Type I error and power in linear mixed models. Journal of Memory and Language, 94, 305 – 315. https://doi.org/10.1016/j.jml.2017.01.001 • Meteyard, L., & Davies, R. A. I. (2020). Best practice guidance for linear mixed-effects models in psychological science. Journal of Memory and Language, 112, 104092. https://doi.org/10.1016/j.jml.2020.104092 • Murakami, A. (2016). Modeling Systematicity and Individuality in Nonlinear Second Language Development: The Case of English Grammatical Morphemes: Modeling Individual Nonlinear Development. Language Learning, 66(4), 834 – 871. https://doi.org/10.1111/lang.12166 • RPubs—Reduction of Complexity of Linear Mixed Models with Double-Bar Syntax. (n.d.). Retrieved November 3, 2021, from https:// rpubs.com/Reinhold/22193 • RPubs—The Correlation Parameter in the Random Effects of Mixed Effects Models. (n.d.). Retrieved November 3, 2021, from https:// rpubs.com/yjunechoe/correlationsLMEM • Schad, D. J., Vasishth, S., Hohenstein, S., & Kliegl, R. (2020). How to capitalize on a priori contrasts in linear (mixed) models: A tutorial. Journal of Memory and Language, 110, 104038. https://doi.org/10.1016/j.jml.2019.104038 • Scherbaum, C. A., & Ferreter, J. M. (2009). Estimating Statistical Power and Required Sample Sizes for Organizational Research Using Multilevel Modeling. Organizational Research Methods, 12(2), 347 – 367. https://doi.org/10.1177/1094428107308906 • Should we f it maximal linear mixed models? | R-bloggers. (2014, November 25). https://www.r-bloggers.com/2014/11/should-we- f it-maximal- linear-mixed-models/ • ৽Ҫֶ, & Roland D. (2016). ݴޠཧղݚڀʹ͓͚Δ؟ٿӡಈσʔλٴͼಡΈ࣌ؒσʔλͷ౷ܭੳ. ౷ܭཧ, 64(2), 201 – 231. ࢀߟจݙ 77
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“[T]here is no single correct way to implement an LMM,](https://files.speakerdeck.com/presentations/e48f6ebd486844ebb588c55aee16d892/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
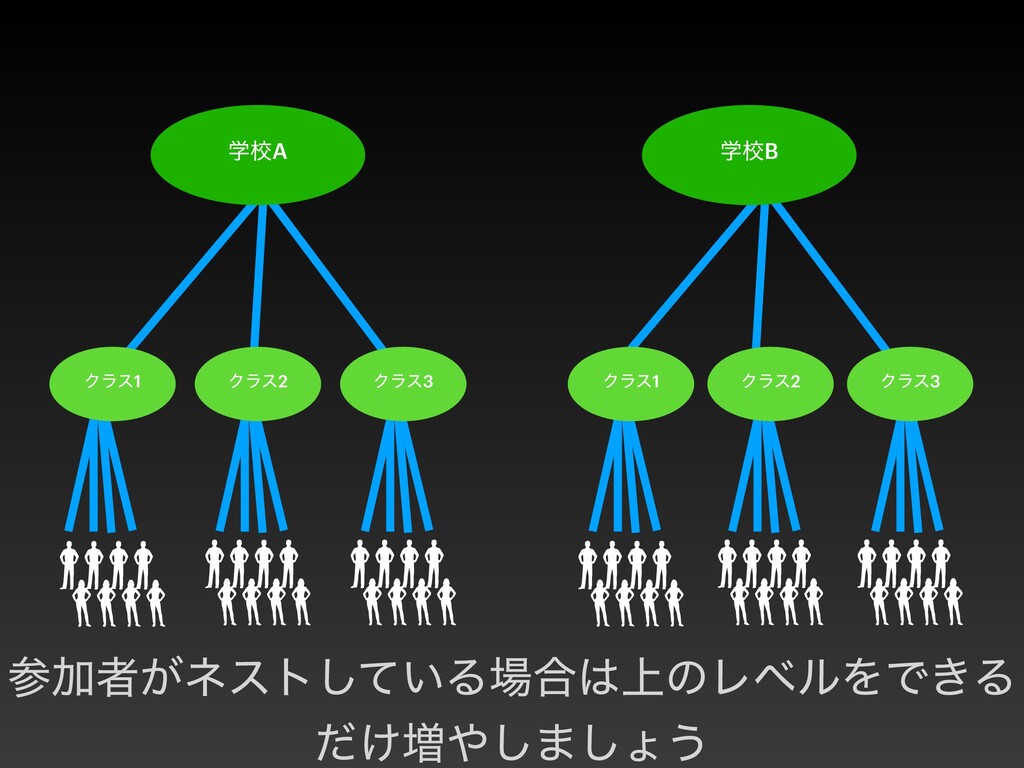{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
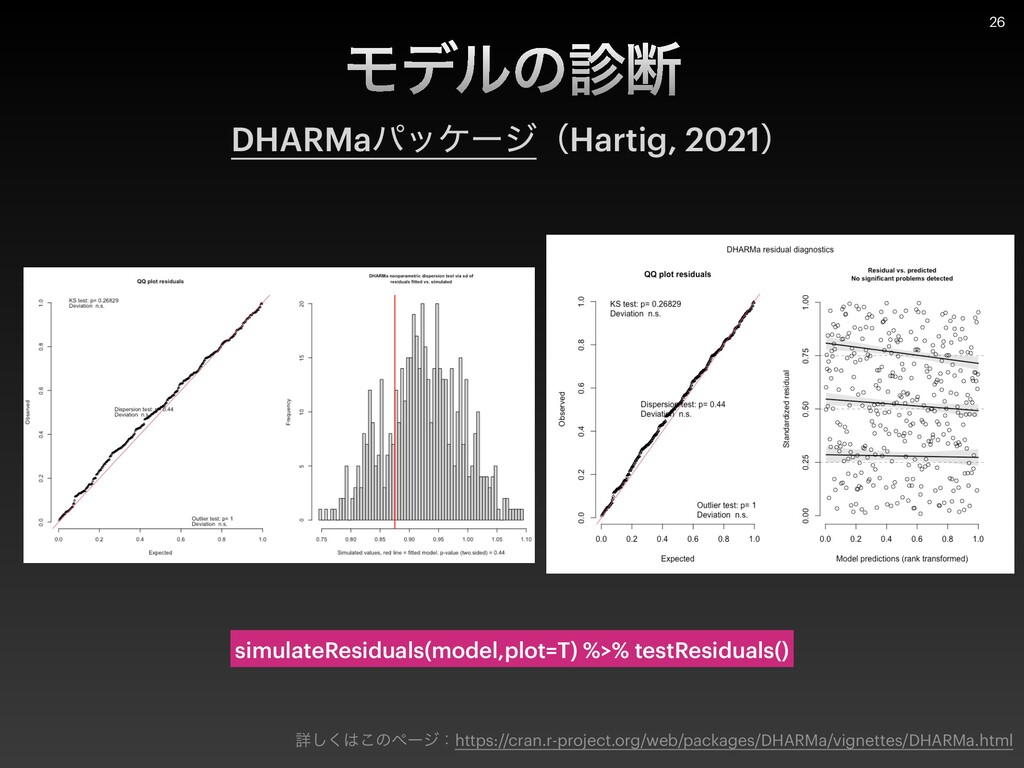{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
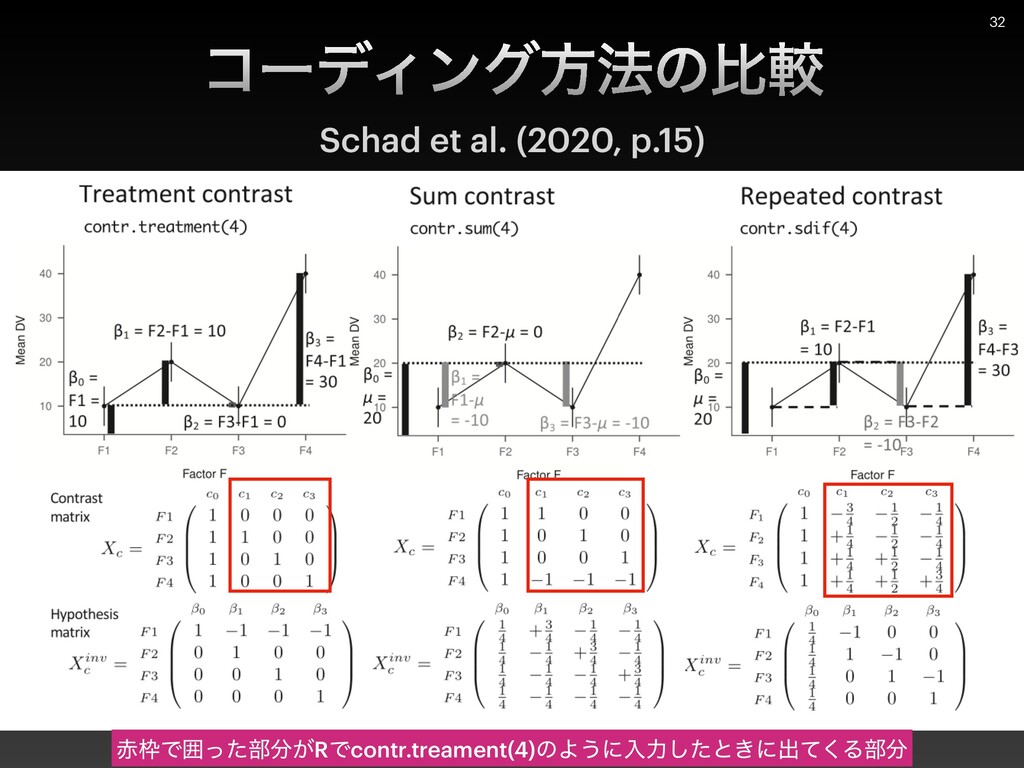{kind=link}
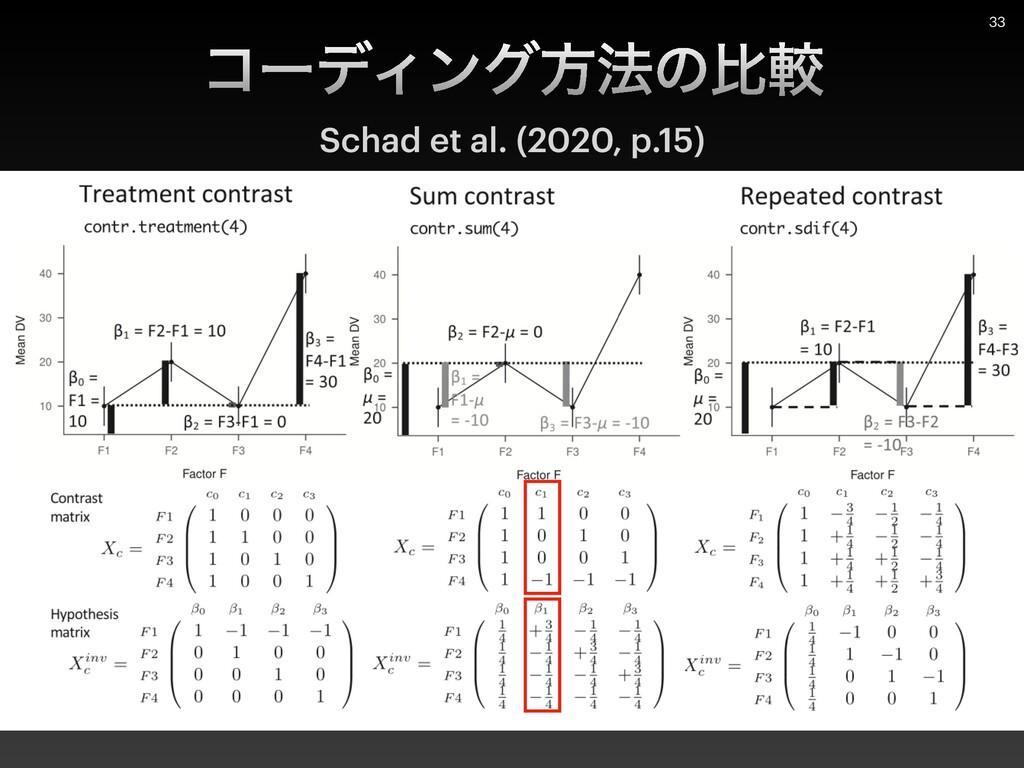{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“[W]hile the maximal model indeed performs well as far as](https://files.speakerdeck.com/presentations/e48f6ebd486844ebb588c55aee16d892/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
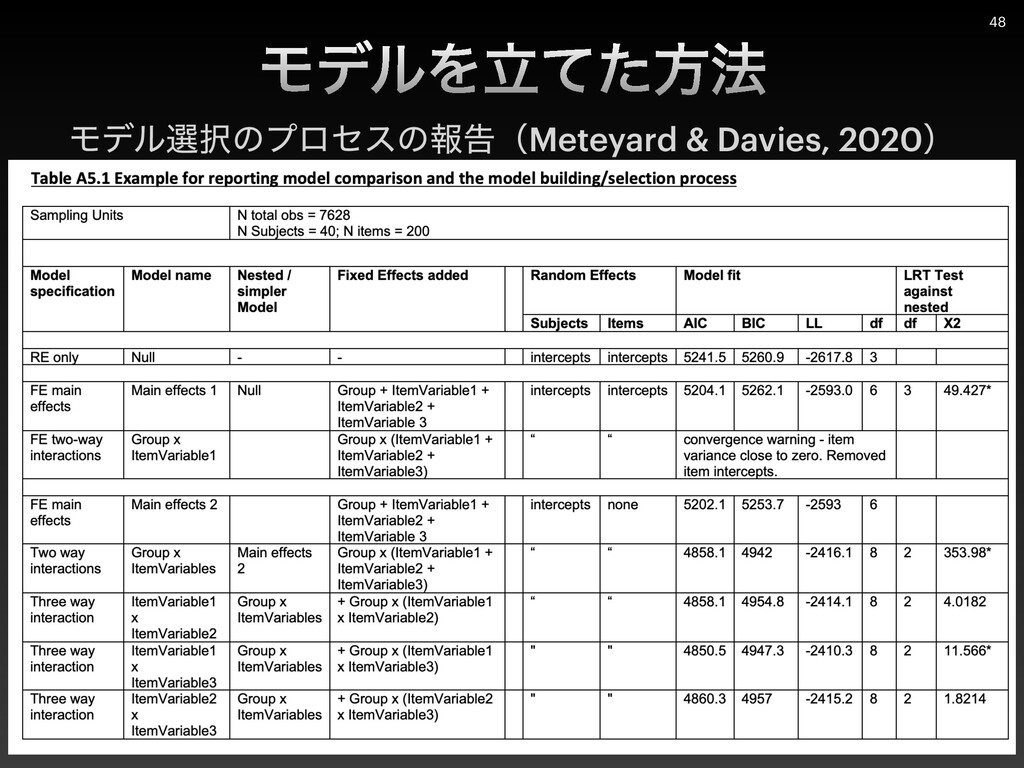{kind=link}
{kind=link}
{kind=link}
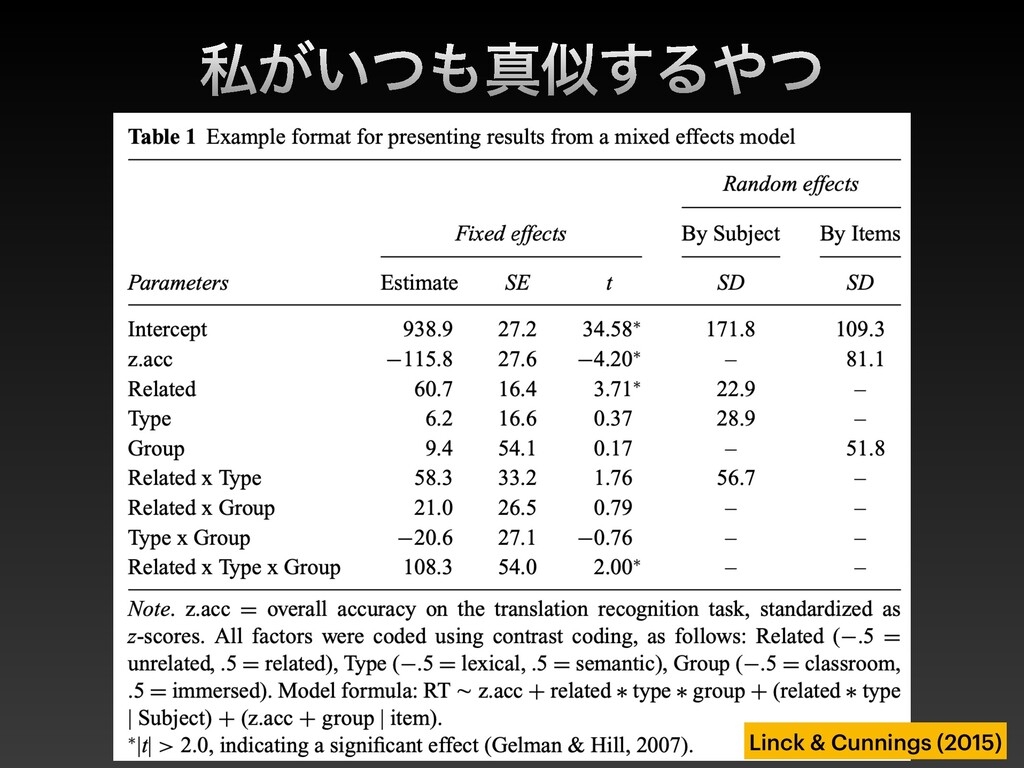{kind=link}
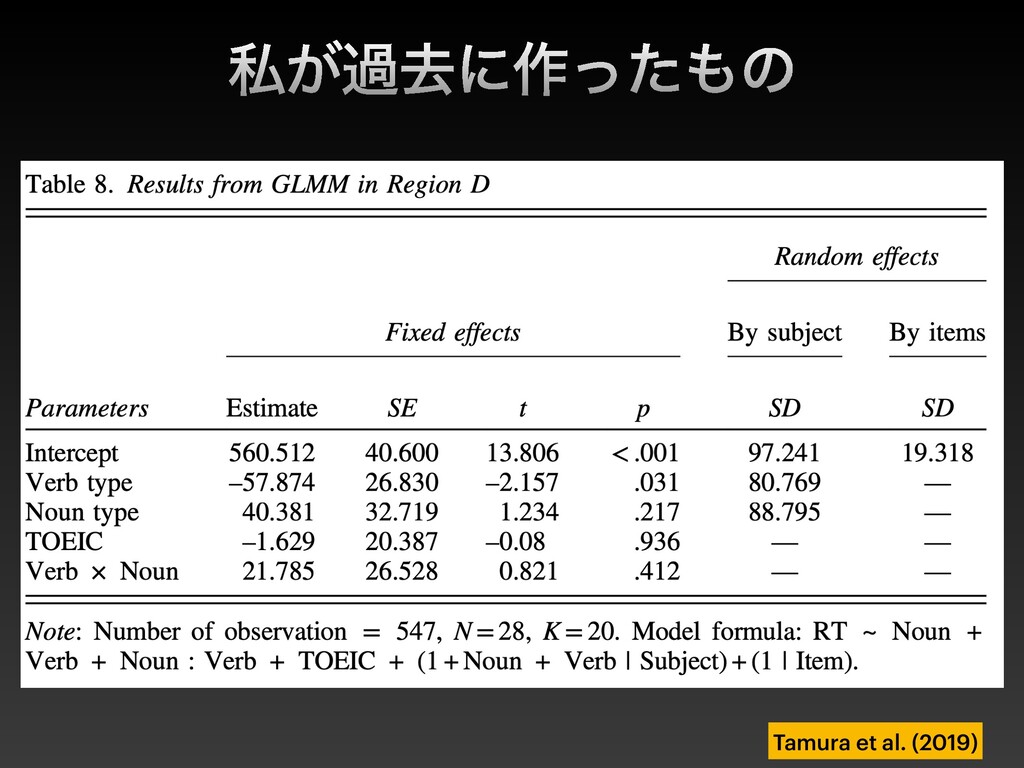{kind=link}
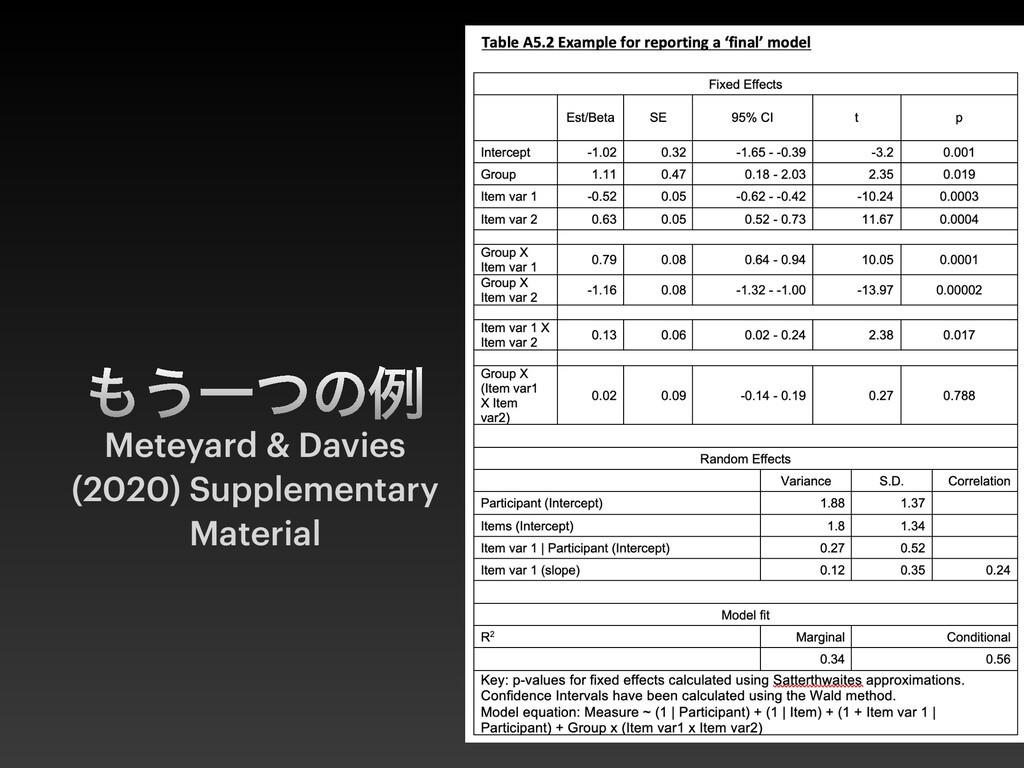{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
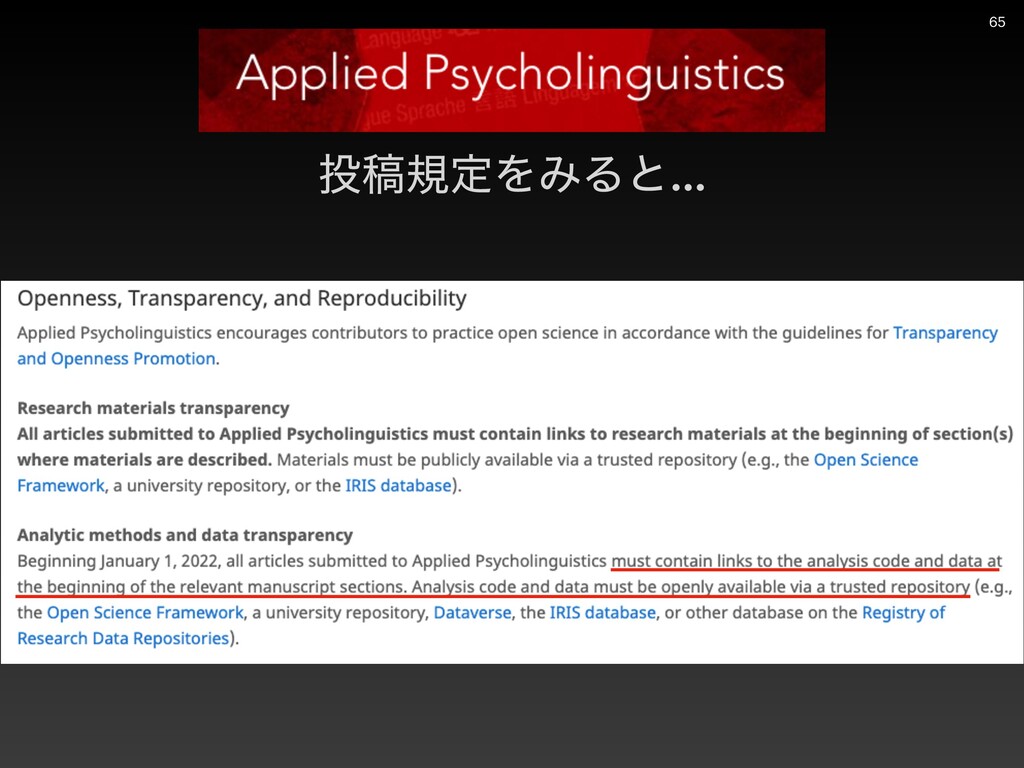{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
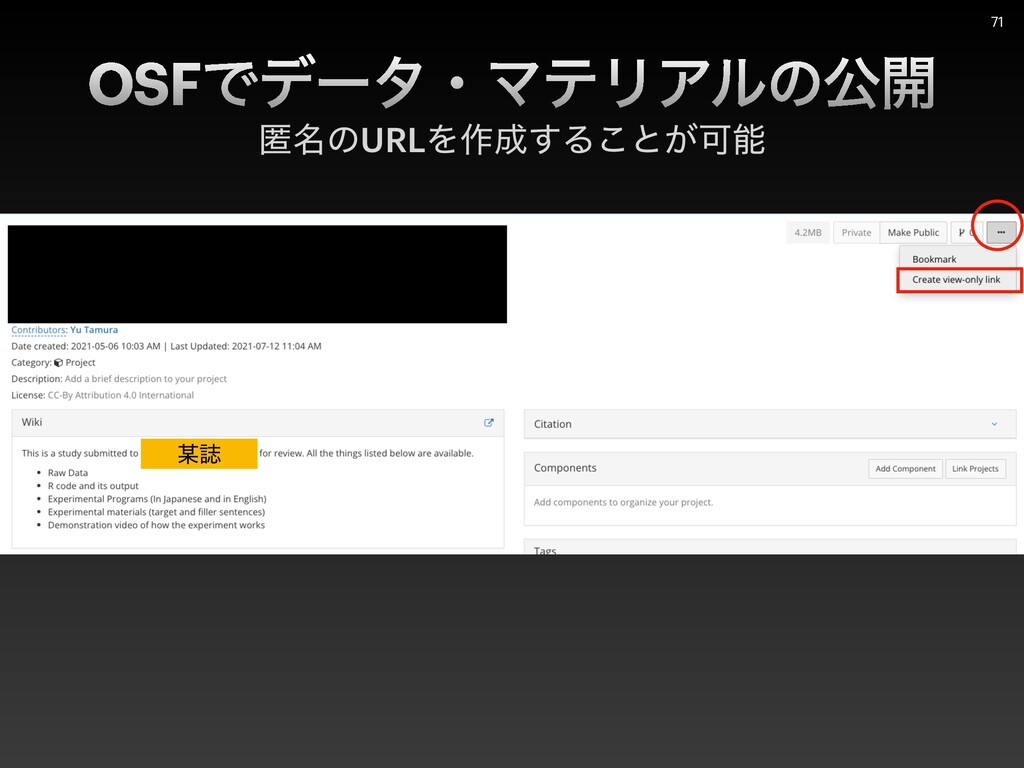{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}