Takeaways:
– What is dimensional reduction and how/why you should use it;
– How t-SNE and PCA work as two distinct ML methods;
– Witness some amazing results using t-SNE!
needed? 7 • Nowadays data is very high dimensional • Many features are highly correlated • Manual feature selection is often impossible • Visualising data requires 2D representations • Most models break down in high dimensions! 1-D Data occupies ⇠ ✓ 1 10 ◆2 of space Data occupies ⇠ ✓ 1 10 ◆n of space Data occupies ⇠ 1 10 of space 2-D n-D Curse of dimensionality
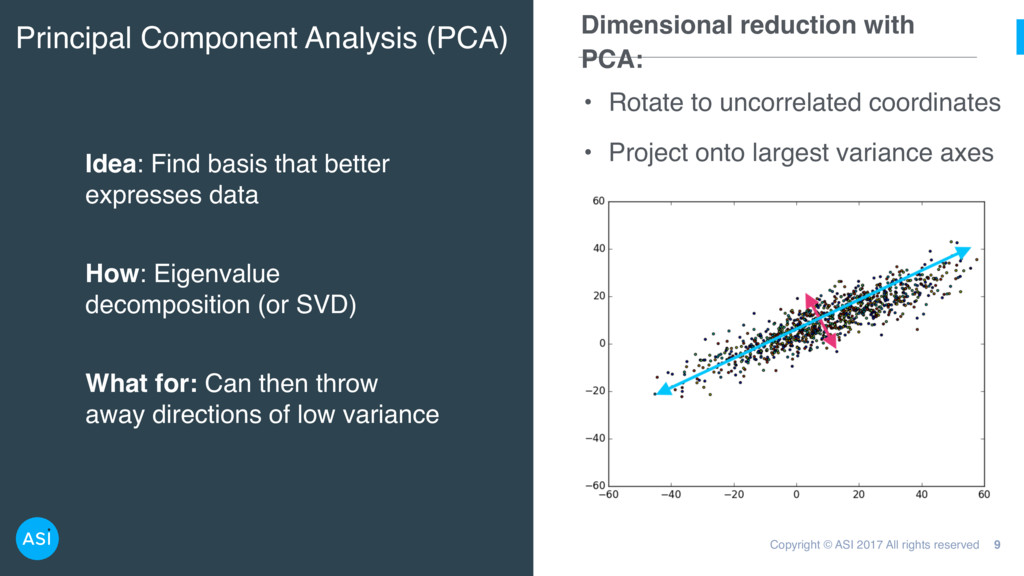
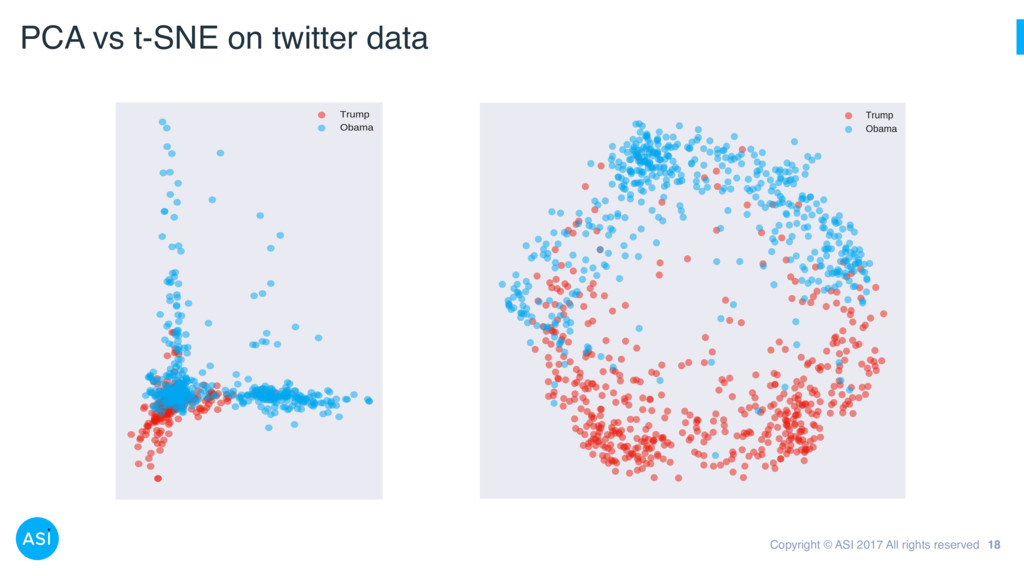
(PCA) 9 Idea: Find basis that better expresses data How: Eigenvalue decomposition (or SVD) What for: Can then throw away directions of low variance • Rotate to uncorrelated coordinates • Project onto largest variance axes Dimensional reduction with PCA:
13 “t-distributed stochastic neighbour embedding” Step 1: Construct a distribution in the high- dimensional space based on pair-wise distance Step 2: Construct a similar distribution (but with wider tails) in the low-dimensional space Step 3: Make the two distributions as similar as possible by minimising their KL divergence pj|i = exp ||xi xj ||2/2 2 i P k6=i exp ||xi xk ||2/2 2 i pij = 1 2N pi|j + pj|i qij = 1 + ||yi yj ||2 1 P k6=` 1 + ||yk y` ||2 1 {y⇤ i } = argmin yi n KL P||Q o = argmin yi ⇢ X j6=k pjk log pjk qjk 1 2 3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}