our growth ü Credit Risk Assessment ü Onboarding Funnel Simulation ü Pricing Optimization ü Fraud Identification ü Document Forensics ü Optimized Prospect and Existing Customer Marketing ü Income and Rent Estimation for Affordability Evaluation 5
our growth 6 ü Credit Risk Assessment ü Onboarding Funnel Simulation ü Pricing Optimization ü Fraud Identification ü Document Forensics ü Optimized Prospect and Existing Customer Marketing ü Income and Rent Estimation for Affordability Evaluation
our growth 7 How we did get here? What were our challenges and learnings? ü Credit Risk Assessment ü Onboarding Funnel Simulation ü Pricing Optimization ü Fraud Identification ü Document Forensics ü Optimized Prospect and Existing Customer Marketing ü Income and Rent Estimation for Affordability Evaluation
to produce ML models that were: § Rapidly generated § Easily vettable § Highly predictive § Easily deployable Several considerations: n Common codebase or personal choice of tools? n Buy or build? n Which language? Which package? Created by Alekksall - Freepik.com
§ Rapidly generated § Easily vettable § Highly predictive § Easily deployable Several considerations: n Common codebase or personal choice of tools? n Buy or build? n Which language? Which package? Systematizing Machine Learning at Zopa (2014) Common codebase
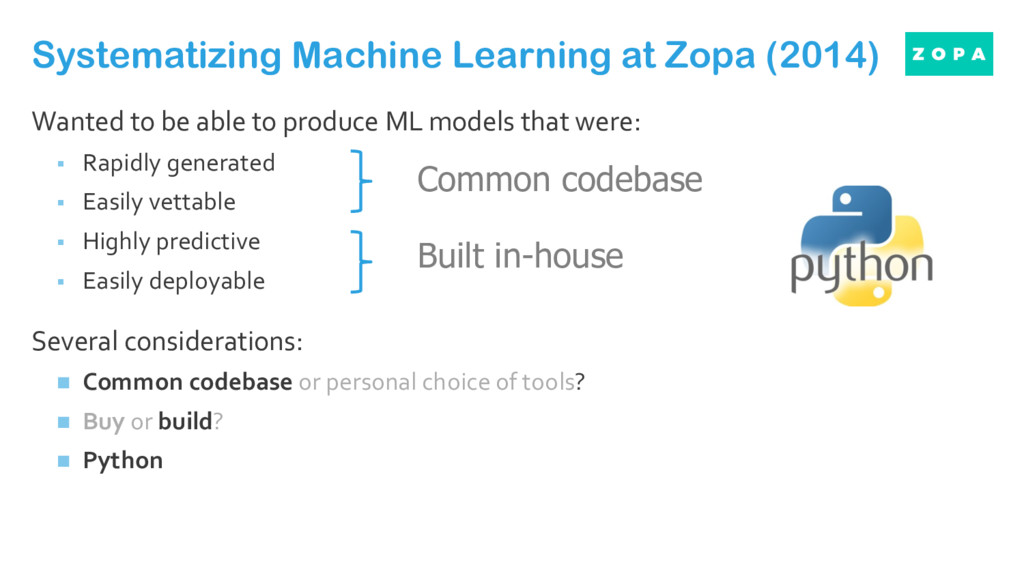
Wanted to be able to produce ML models that were: § Rapidly generated § Easily vettable § Highly predictive § Easily deployable Several considerations: n Common codebase or personal choice of tools? n Buy or build? n Which language? Which package?
§ Rapidly generated § Easily vettable § Highly predictive § Easily deployable Several considerations: n Common codebase or personal choice of tools? n Buy or build? n Python Systematizing Machine Learning at Zopa (2014) Common codebase Built in-house
Data Scientists and in Production √ No “Model Translation” Overhead √ No restrictions on which ML techniques can be used n Training n Needs unprocessed data and a simple config file n Driven via CLI, interacting with Python codebase, or Jupyter GUI n Querying Mode n Driven by all of the above + n rest API (Flask-based microservice) in Production, <1—2 s/ call
ML √ Methodology √ Deployment √ Features √ Competitive advantage, selling point to DSs. √ One day we will open source à Brand boost Ø Need to maintain at least 2 people familiar with the code base Ø Need to keep improving it – otherwise we’ll miss latest developments
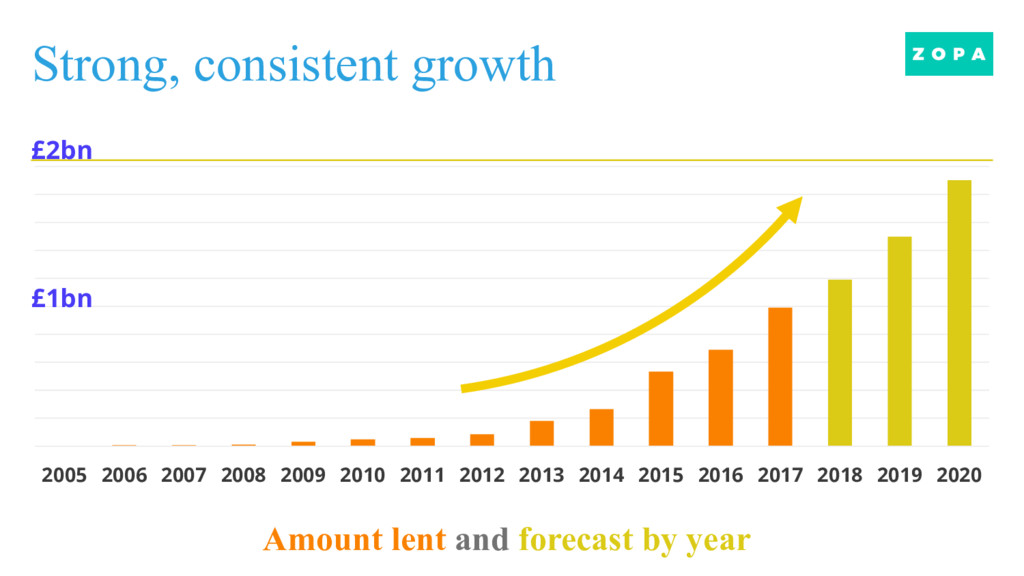
assess >£2billion worth of loans since 2015 n Production: credit and fraud risk assessment, affordability evaluation n Offline: Pricing and marketing optimization n Future: Operational efficiency for Underwriting, Collections, Customer Services n Techniques we have been using n Neural Networks, n Bagged logistic regressions and Multivariate Adaptive Regression Splines n Gradient Boosted Trees, and Random Forests
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}