■ パーソルキャリア採用サイト
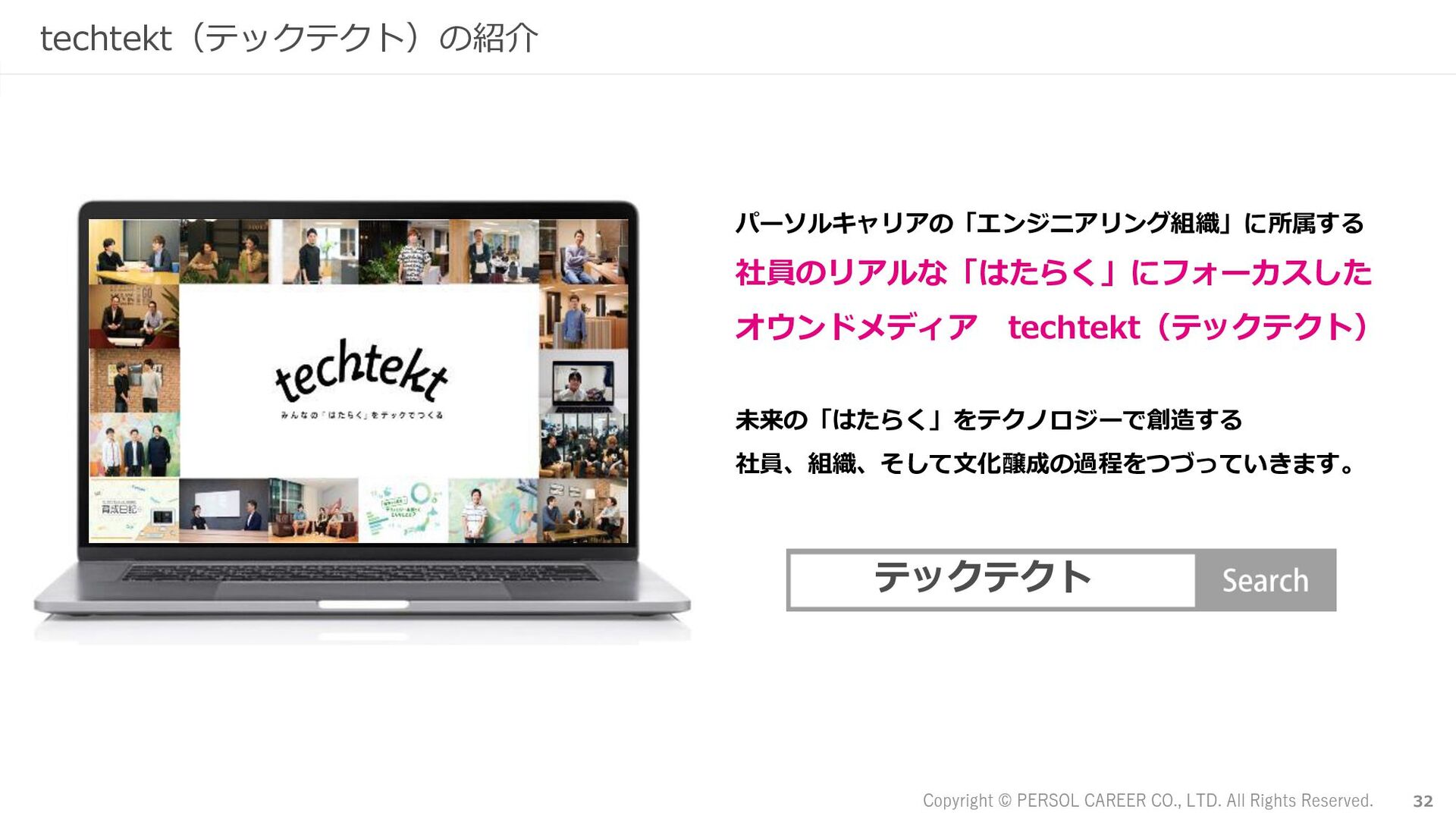
■ techtekt(テックテクト)
パーソルキャリアのエンジニアブログです。“みんなの「はたらく」をテックでつくる”をコンセプトに、技術、組織、学びなど、さまざまな情報を発信しています。
■ NUTION(ニューション)
パーソルキャリアのデザイン組織「NUTION」のブランドサイトです。「デザインの力で、はたらくを変え、社会を変えていく。」をステートメントとし、デザインの価値を広める活動をしています。
■TECH Street
パーソルキャリアが主催する各社の現場で活躍しているITエンジニアやテクノロジー人材から、ITテクノロジーに関するさまざまなテーマの事例や知見が学べる勉強会コミュニティです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}