In Mexico, the electoral authority,organizes a quick count the same night of the election, we present the model we developed for the 2018 elections.
This model estimates have some advantages and some drawbacks in comparison to traditional survey sampling estimation methods (in this case, ratio estimation). Advantages include a consistent and principled treatment of missing data in samples (which is unavoidable in this setting), more consistent behaviour when monitoring partial samples as they are recorded during the election process, and better interval coverage properties when the sample data has serious missing data problems (including biases in observed data from designed samples, which also naturally appear in this setting). Drawbacks include a much larger computation effort and time to obtain results (in the case of the model presented here, around five minutes vs less than seconds), and a considerably larger modelling effort which requires extensive checks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
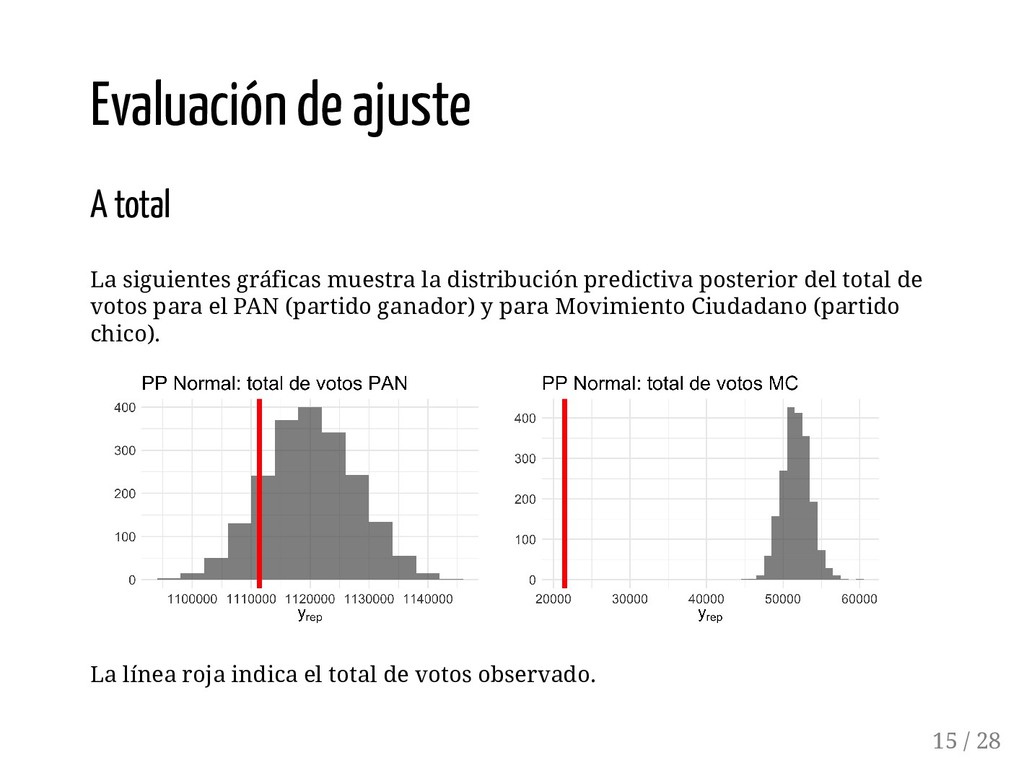{kind=link}
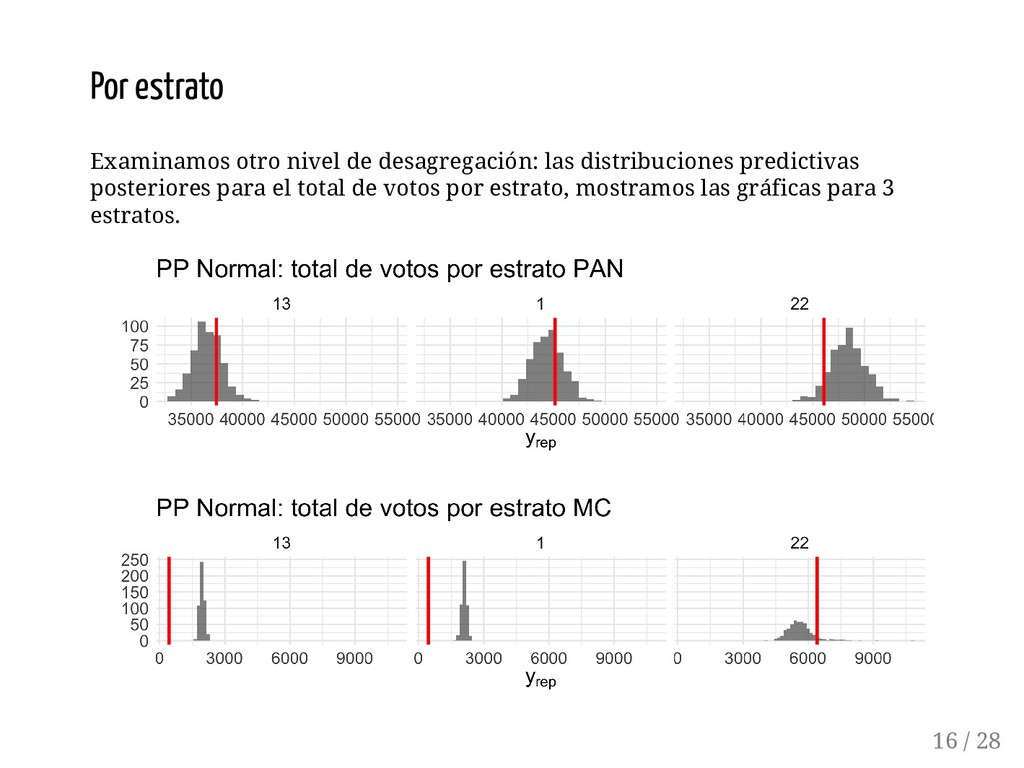{kind=link}
{kind=link}
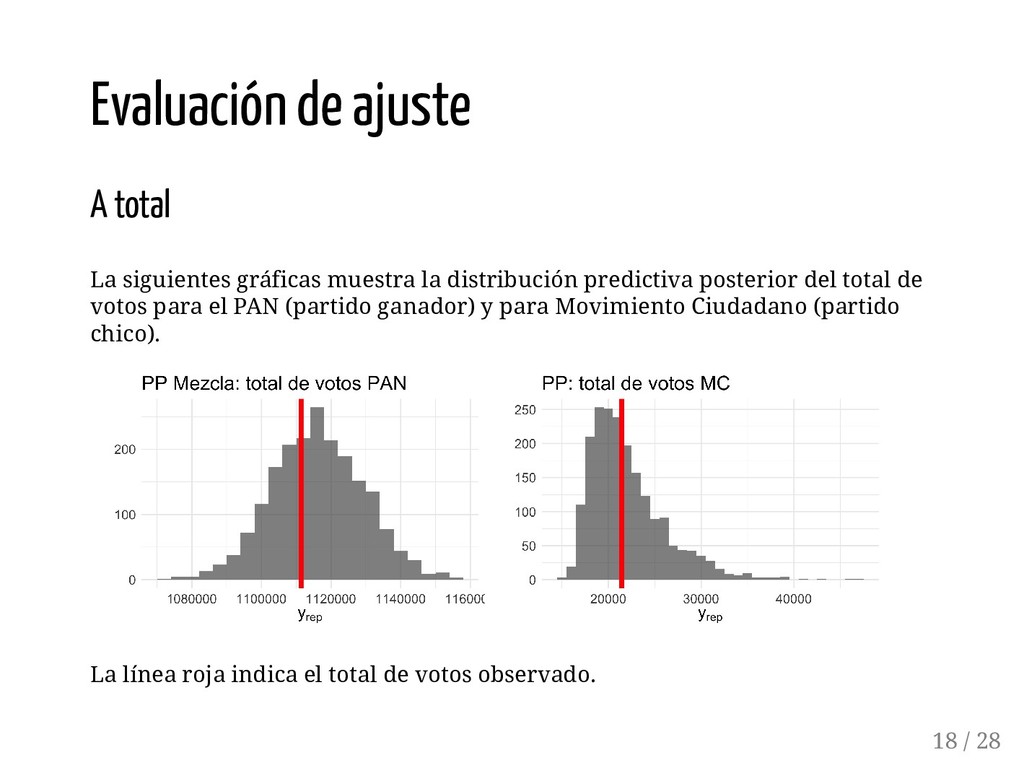{kind=link}
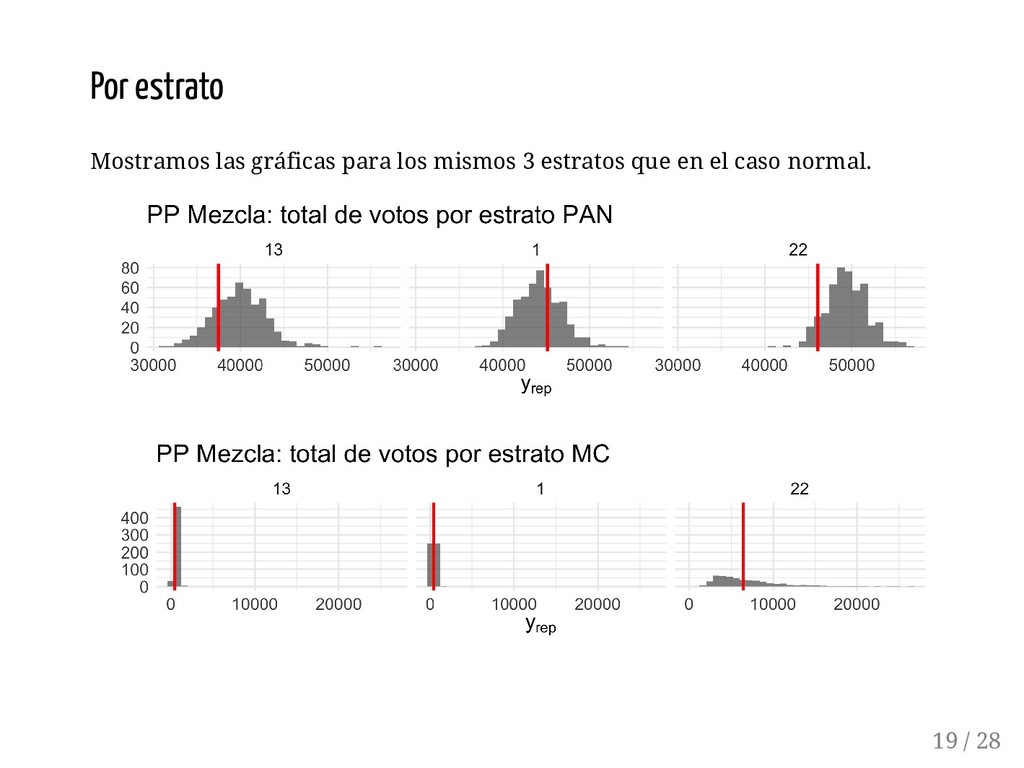{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}