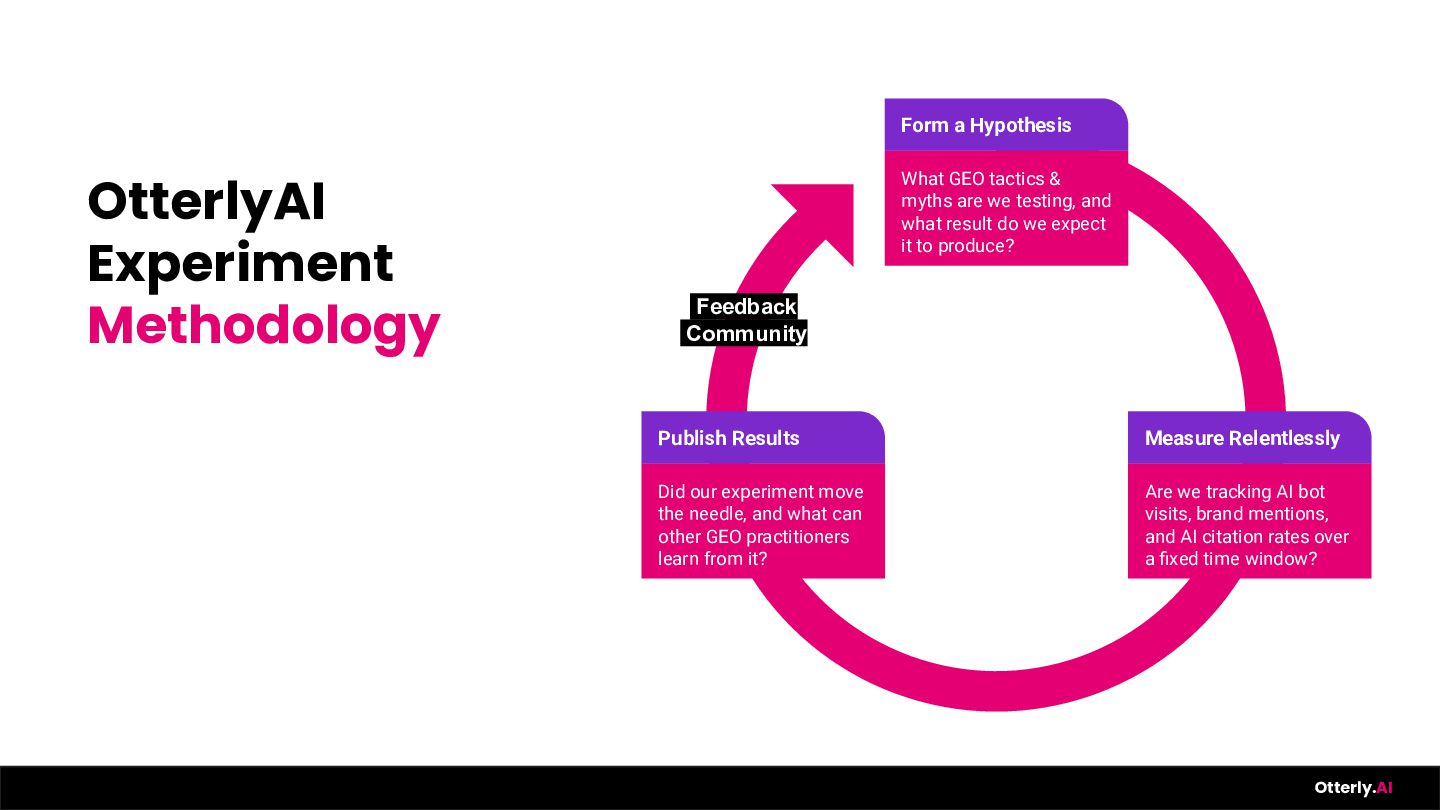
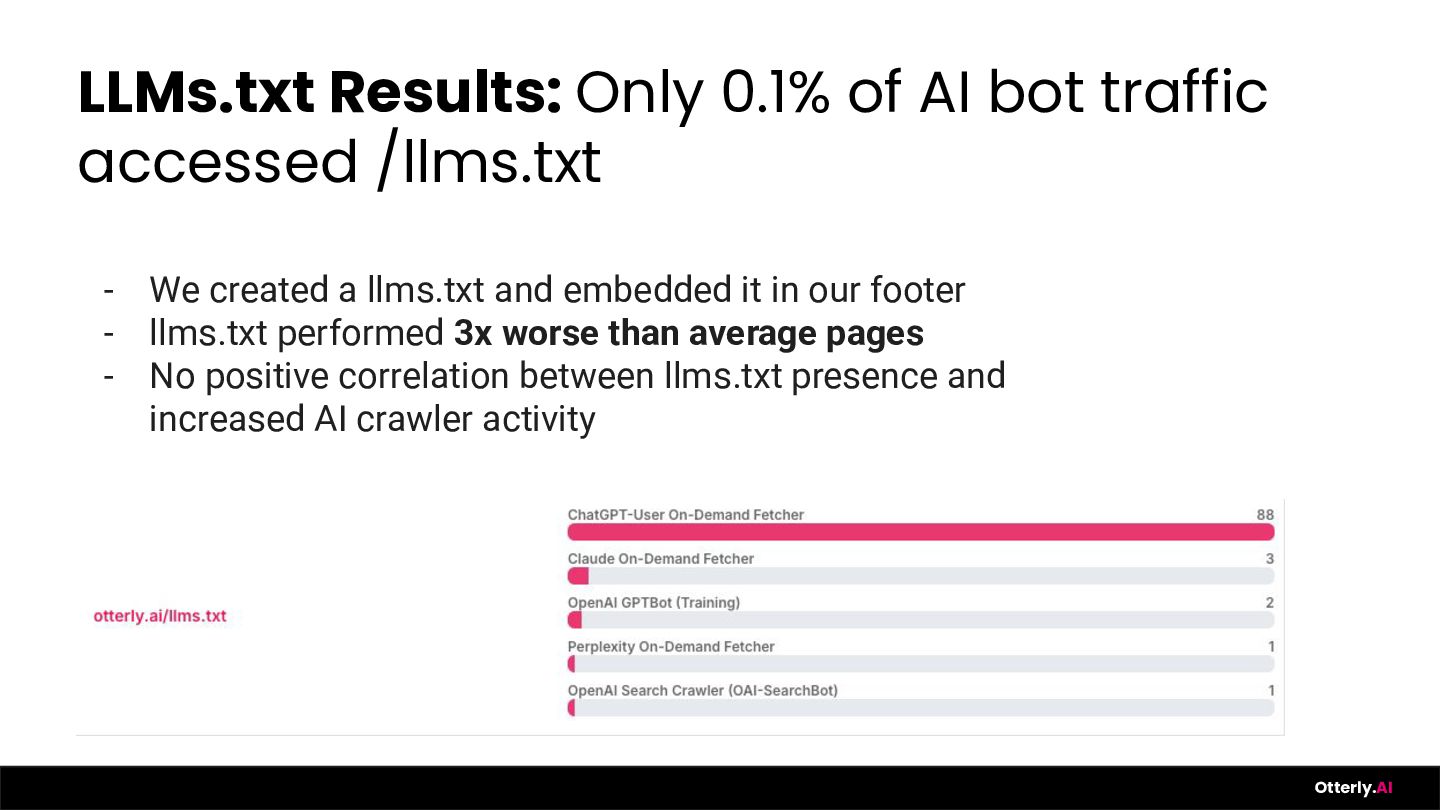
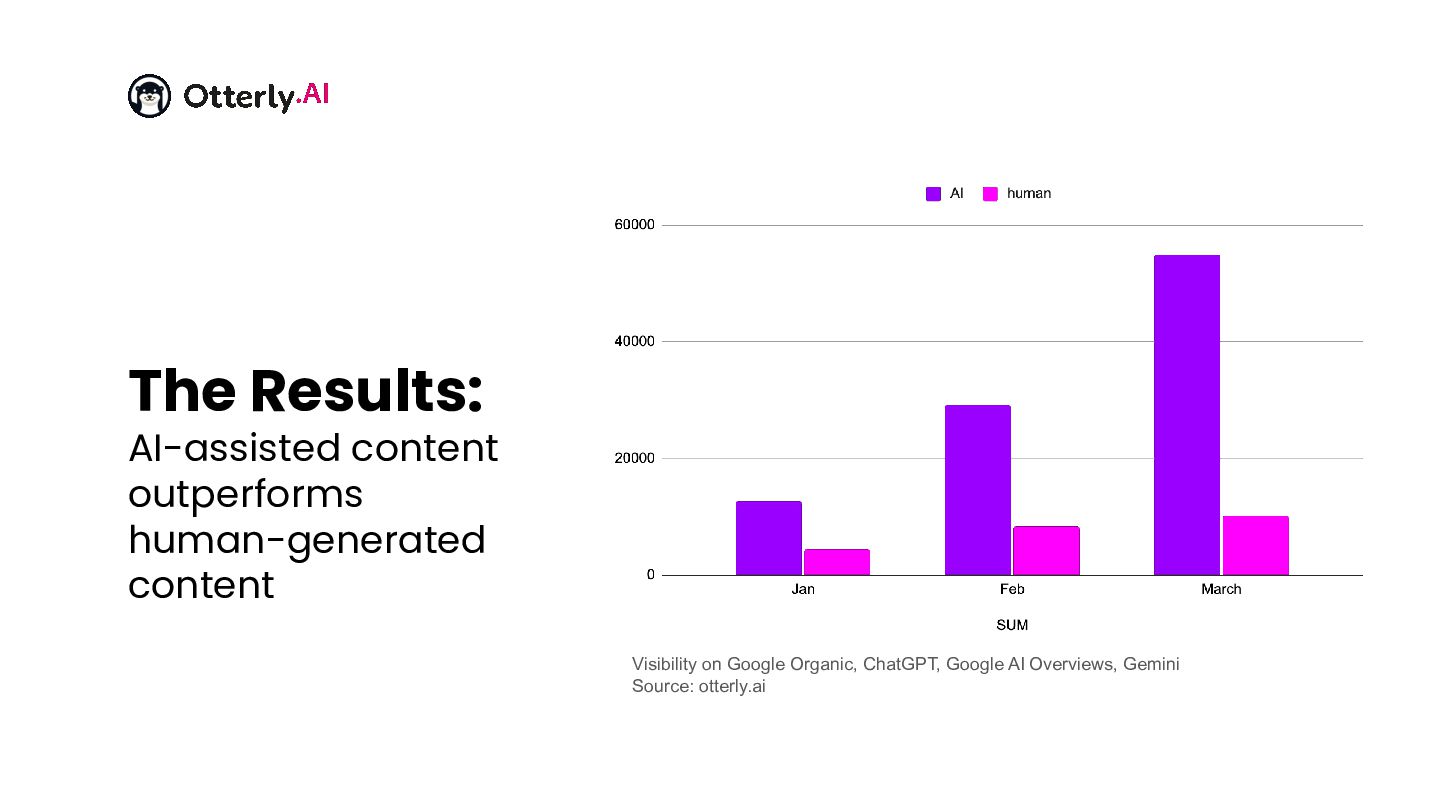
Everyone has opinions about Generative Engine Optimization. We have data. Over the past year, the OtterlyAI team ran dozens of controlled experiments - testing llms.txt, Schema Markup, AI-generated vs. human-written content, YouTube citation patterns, earned media outreach, and much more - tracking real outcomes across the largest AI Search platforms. Some results confirmed our hunches. Others completely surprised us. In this session, Thomas Peham walks through what worked, what flopped (looking at you, llms.txt), and the one experiment that got otterly.ai cited on ChatGPT within 24 hours. Expect raw data, honest failures, and a repeatable experimentation methodology you can take back to your team on Monday.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
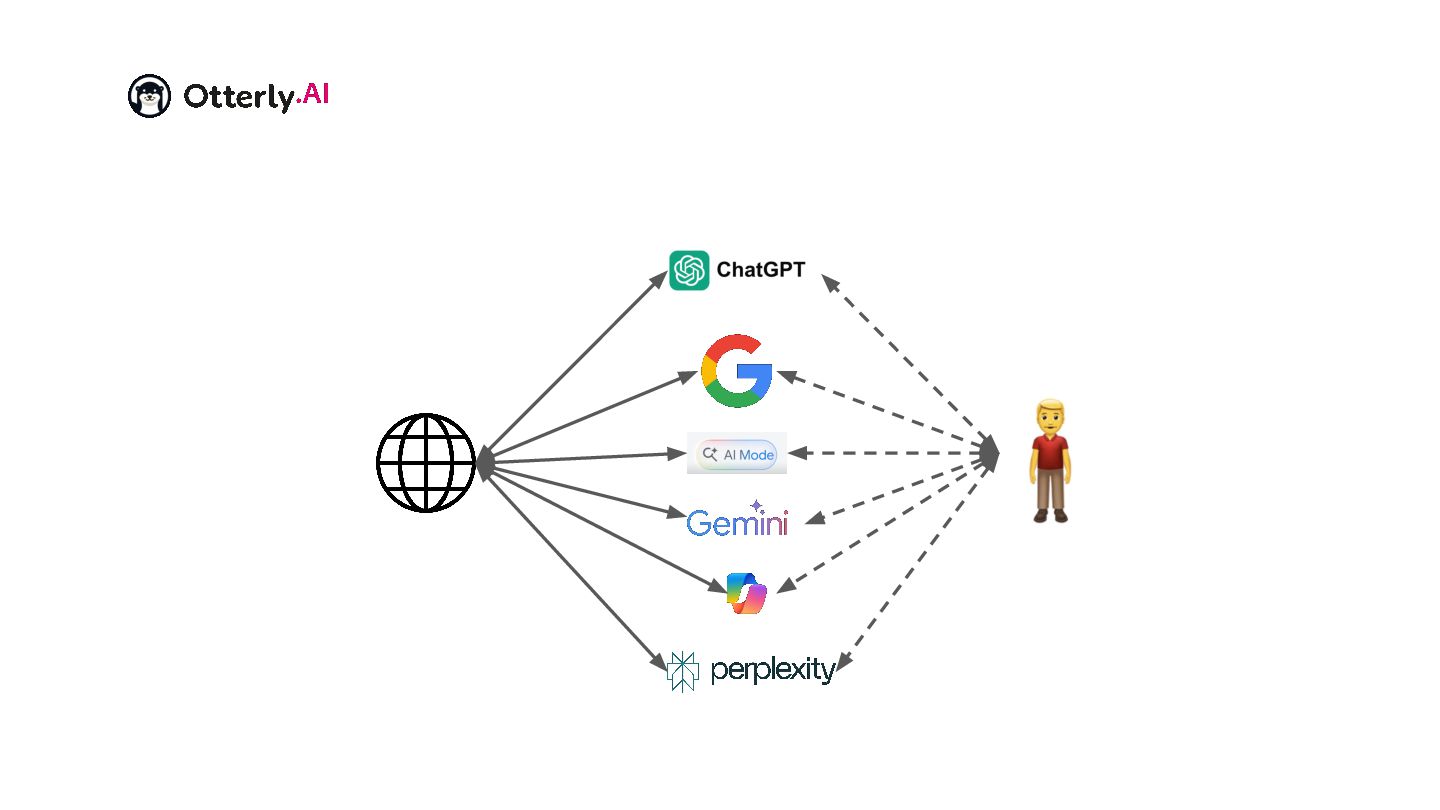{kind=link}
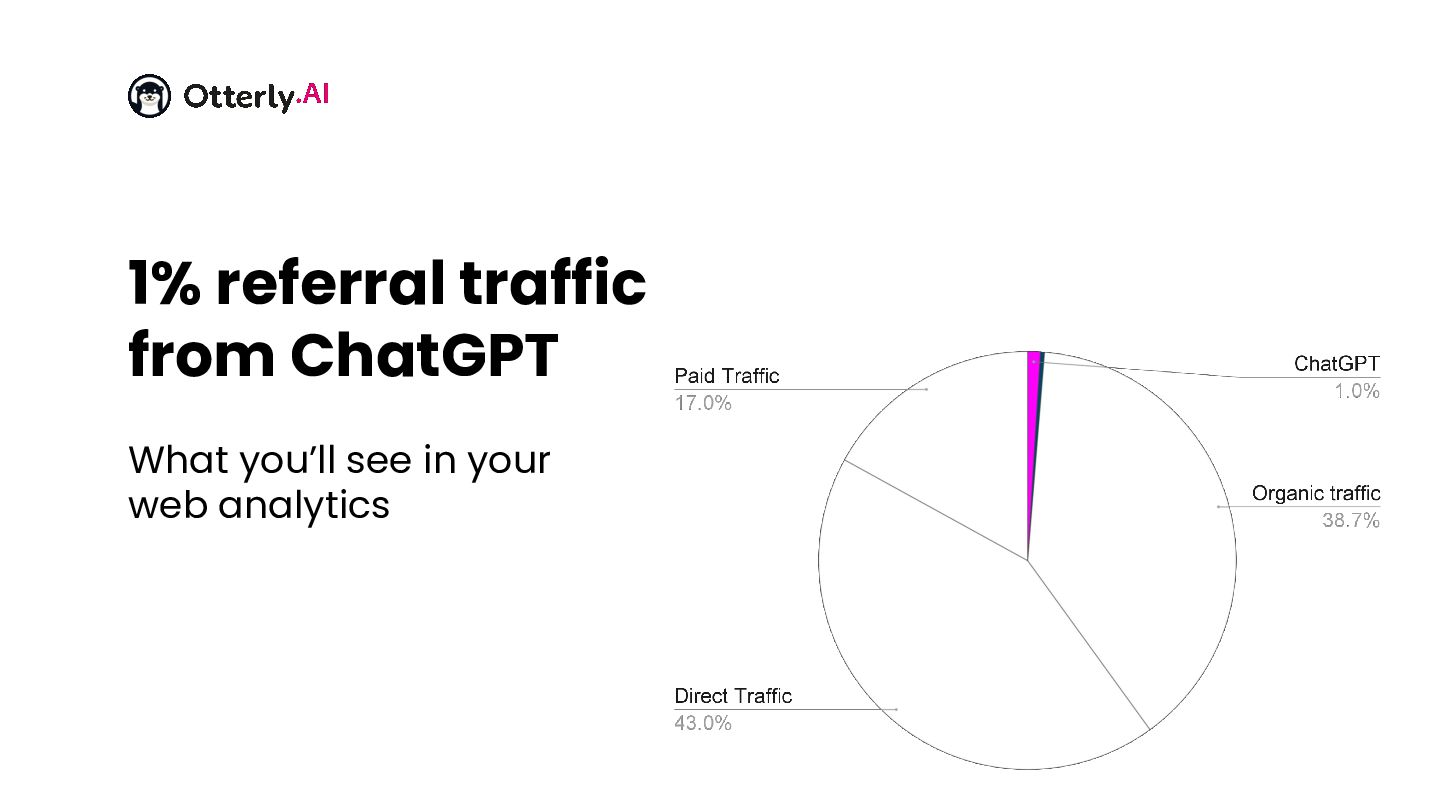{kind=link}
{kind=link}
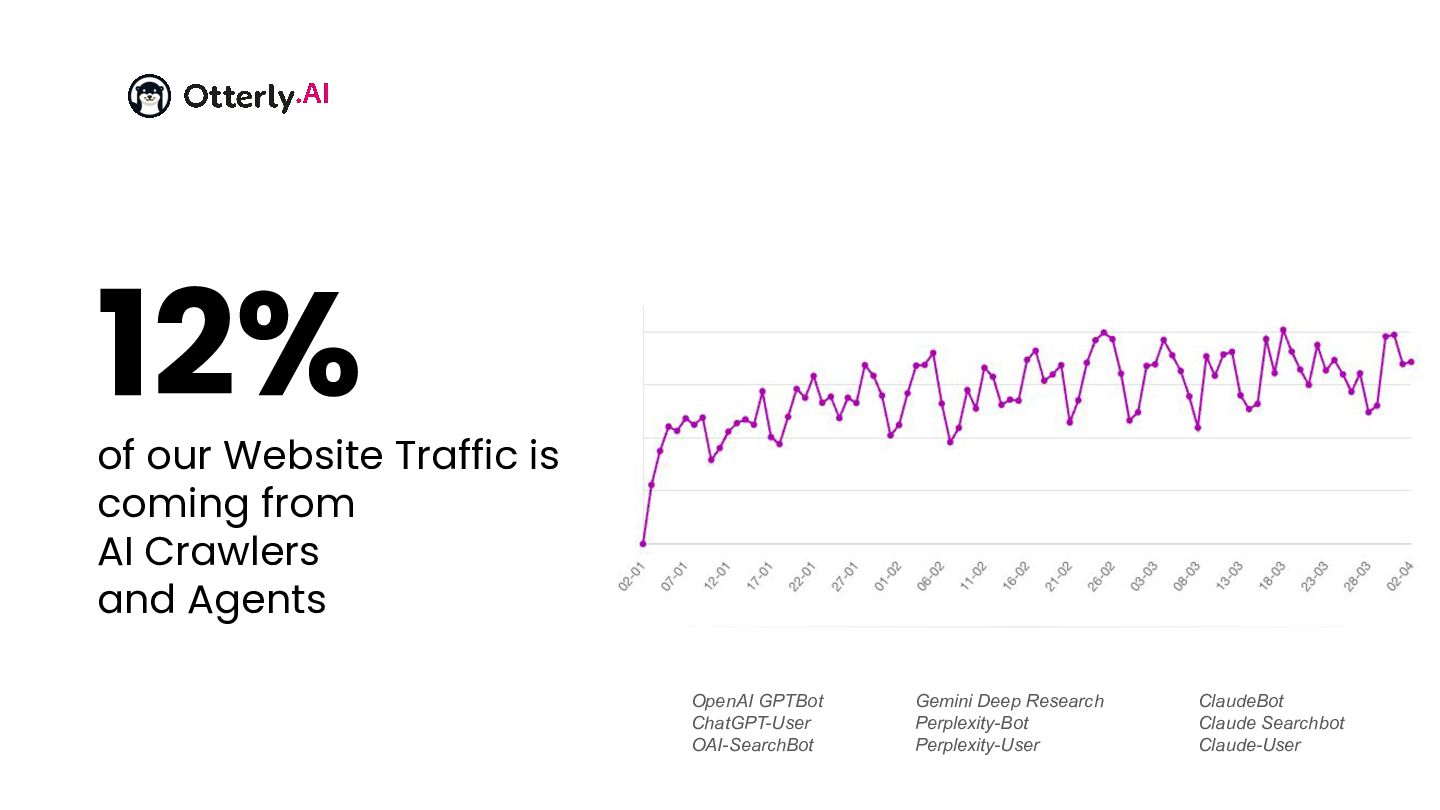{kind=link}
{kind=link}
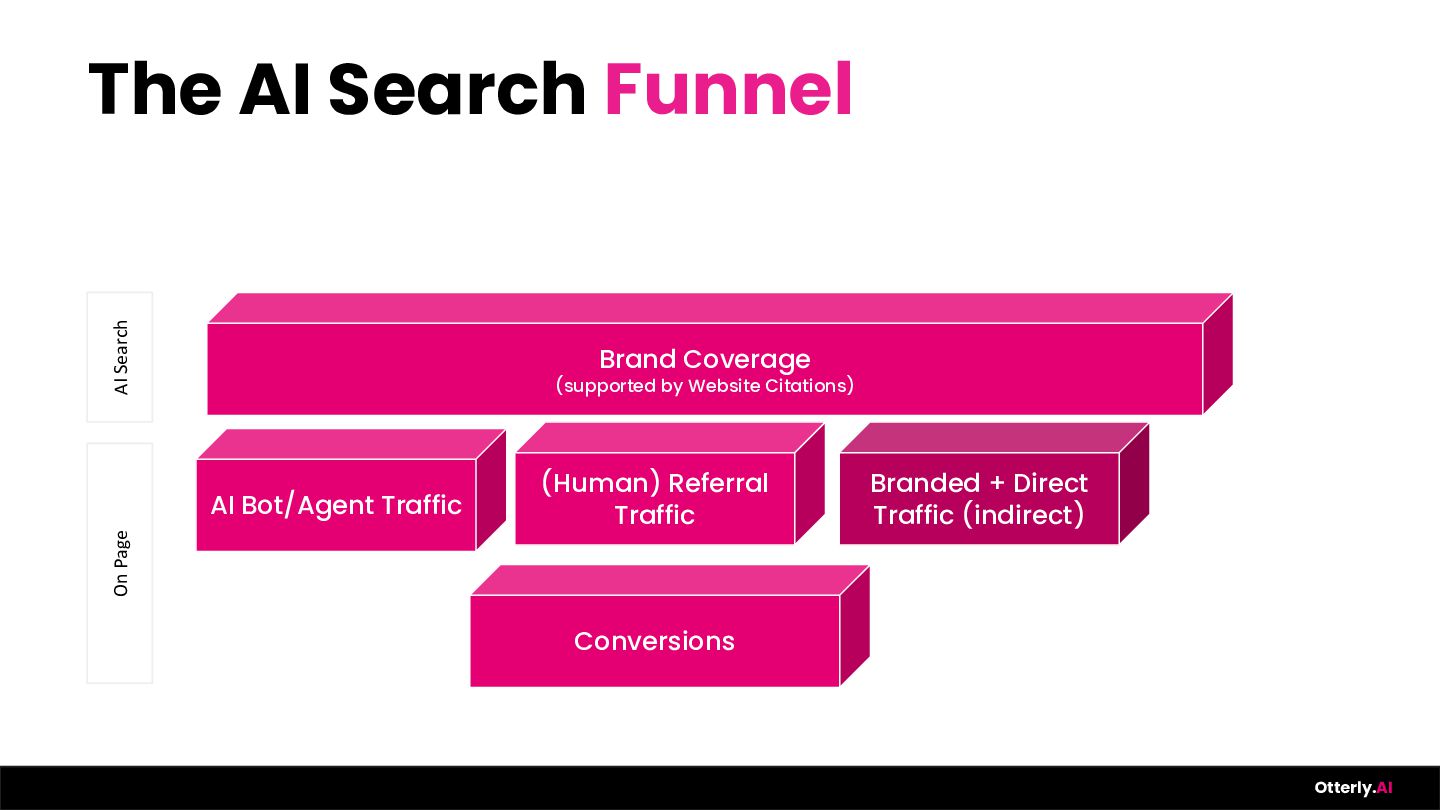{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
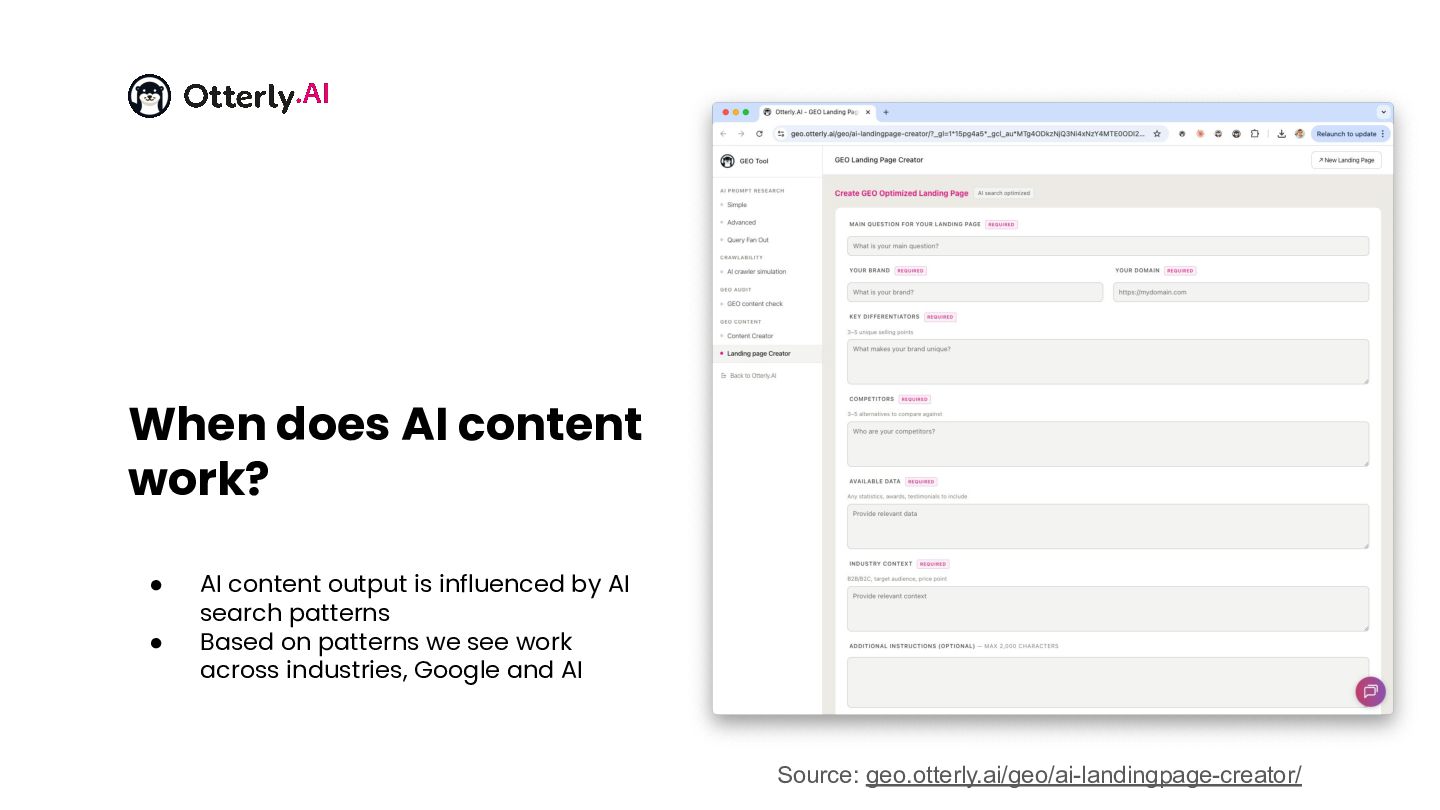{kind=link}
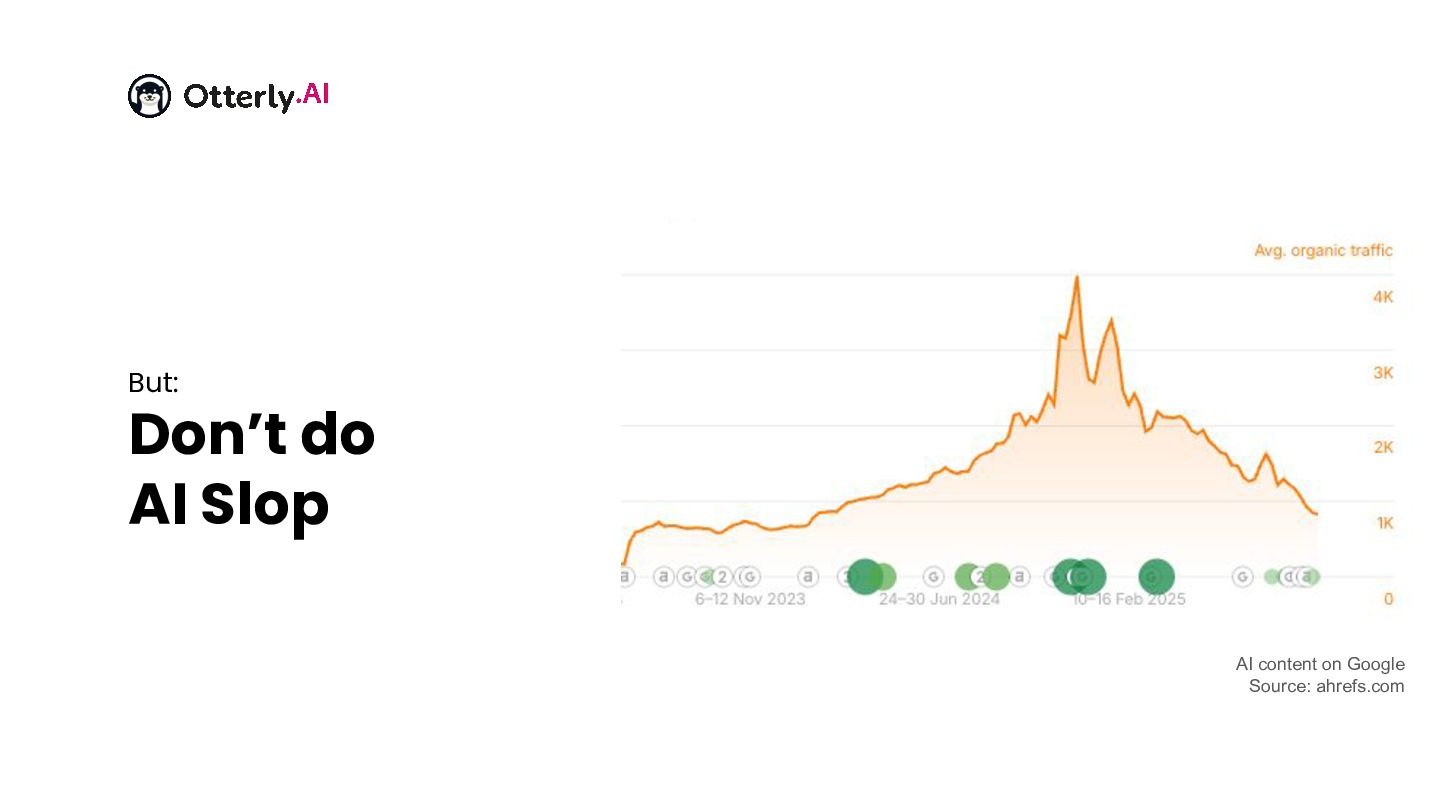{kind=link}
{kind=link}
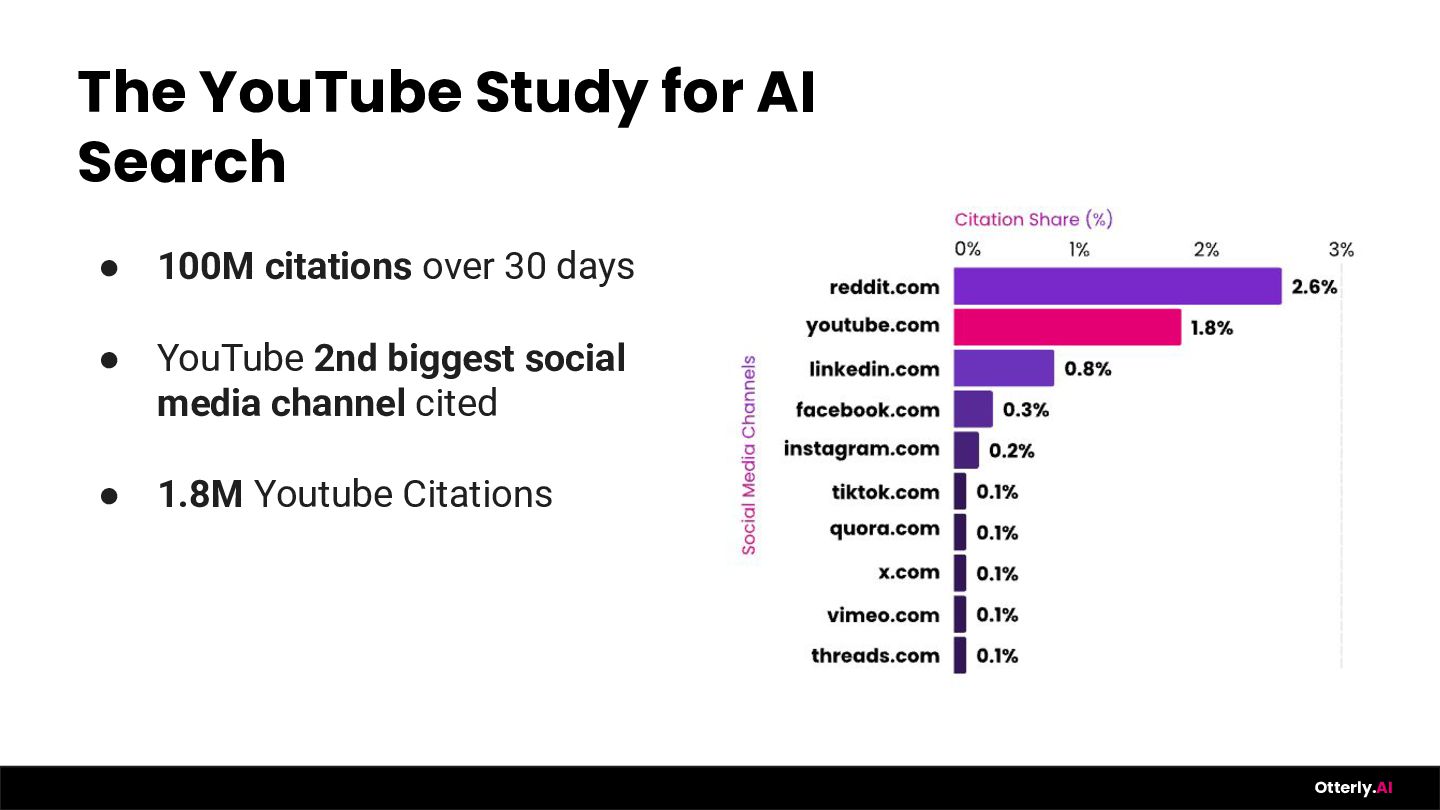{kind=link}
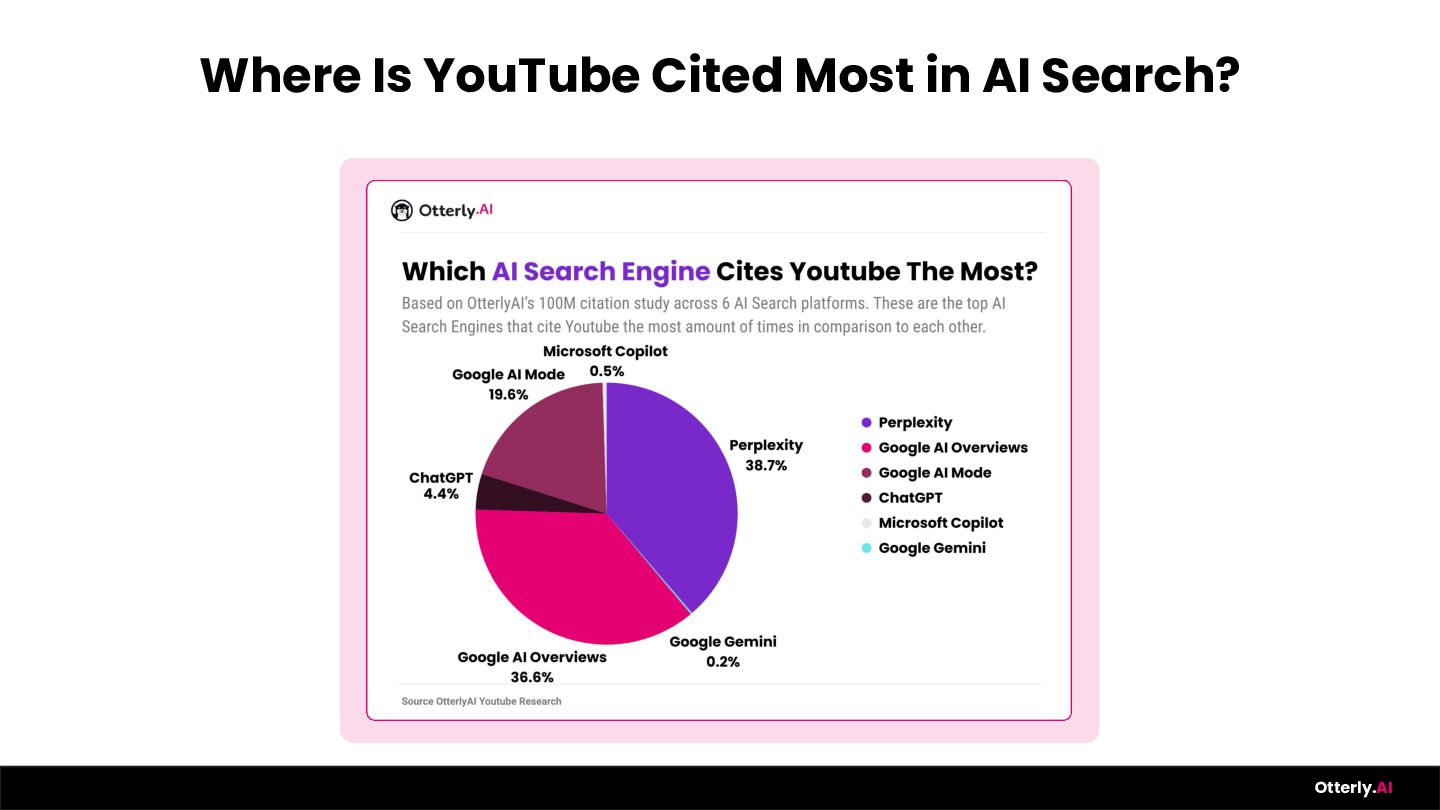{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}