failure CPU stress Memory stress Disk stress Network Latency EKS Pod Delete CPU stress Memory stress Disk stress Network Latency Multi-AZ / Region AZ Power Interruption AZ Application Slowdown Cross-AZ Traffic Slowdown Cross-Region Connectivity EBS Sustained Latency Increasing Latency Intermittent Latency Decreasing Latency primeNumber Inc. 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
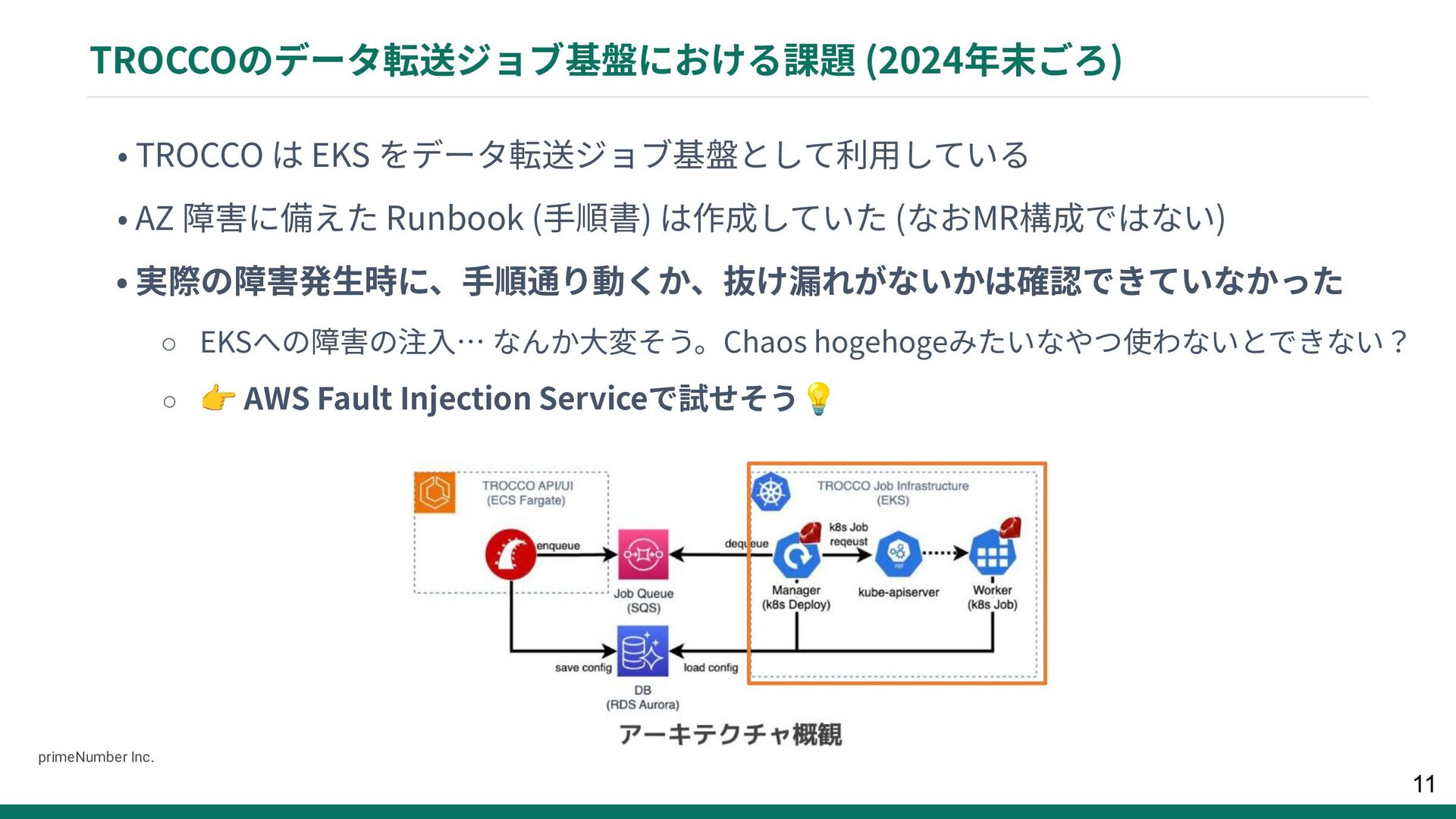{kind=link}
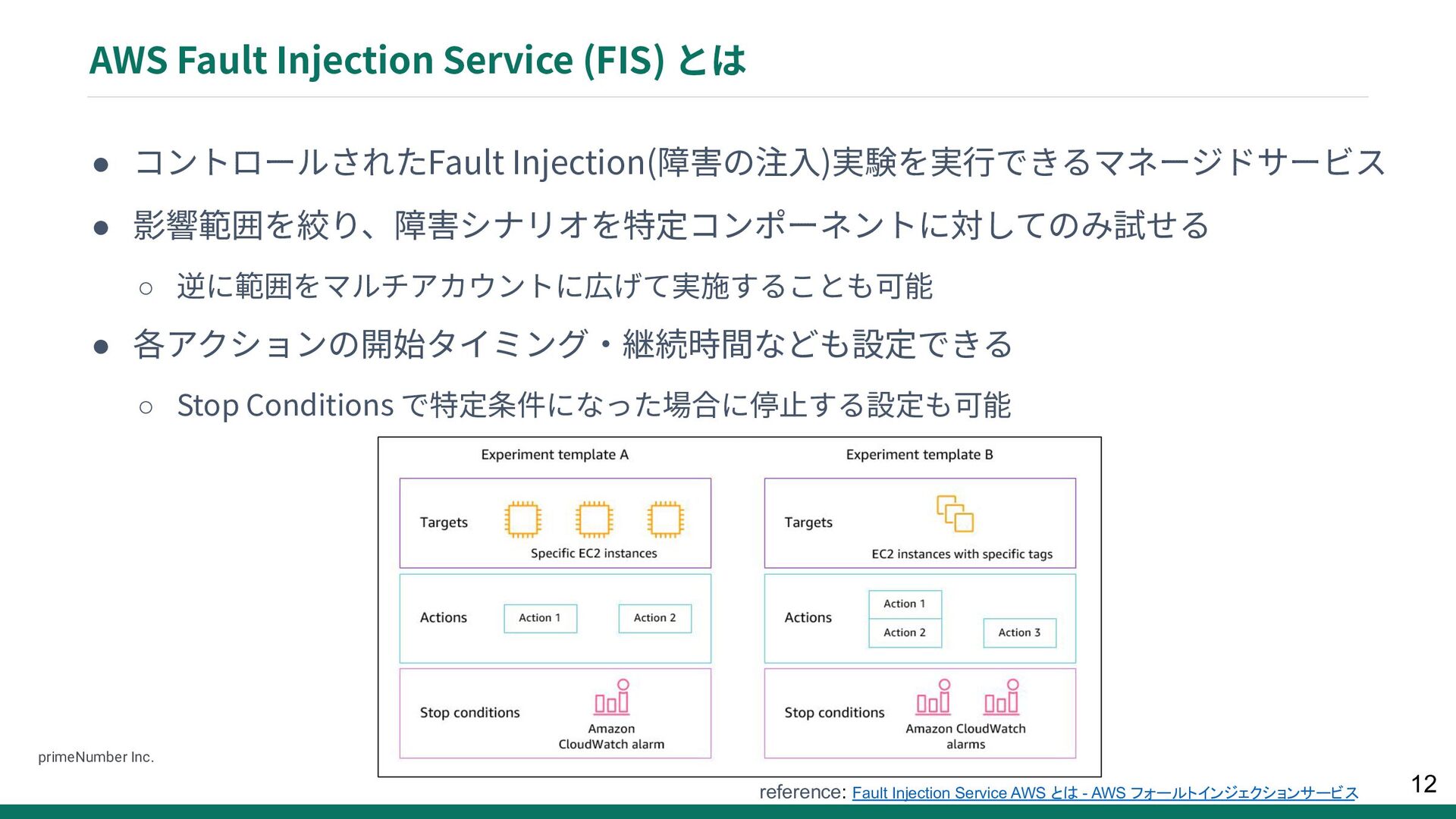{kind=link}
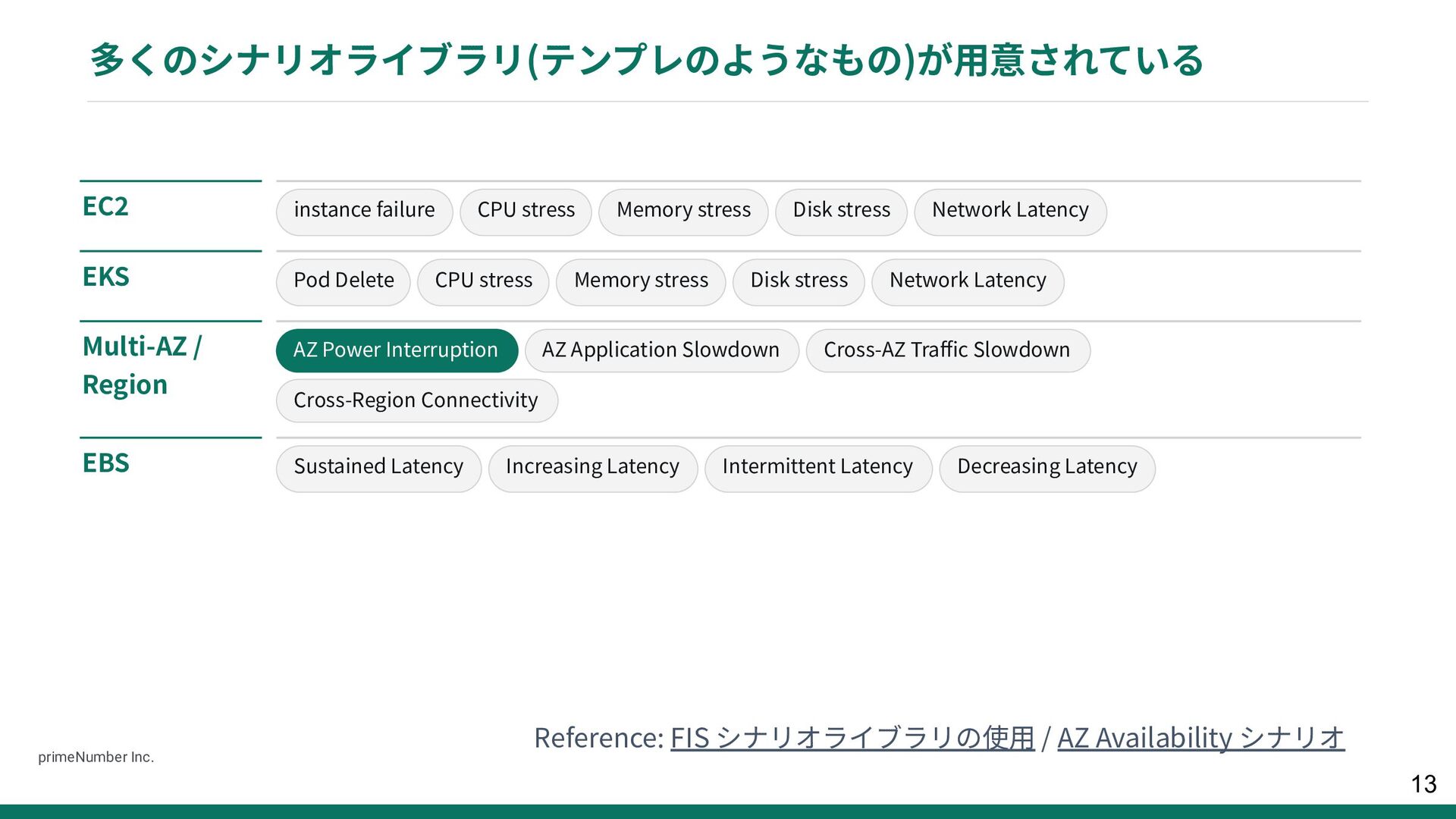{kind=link}
{kind=link}
{kind=link}
{kind=link}
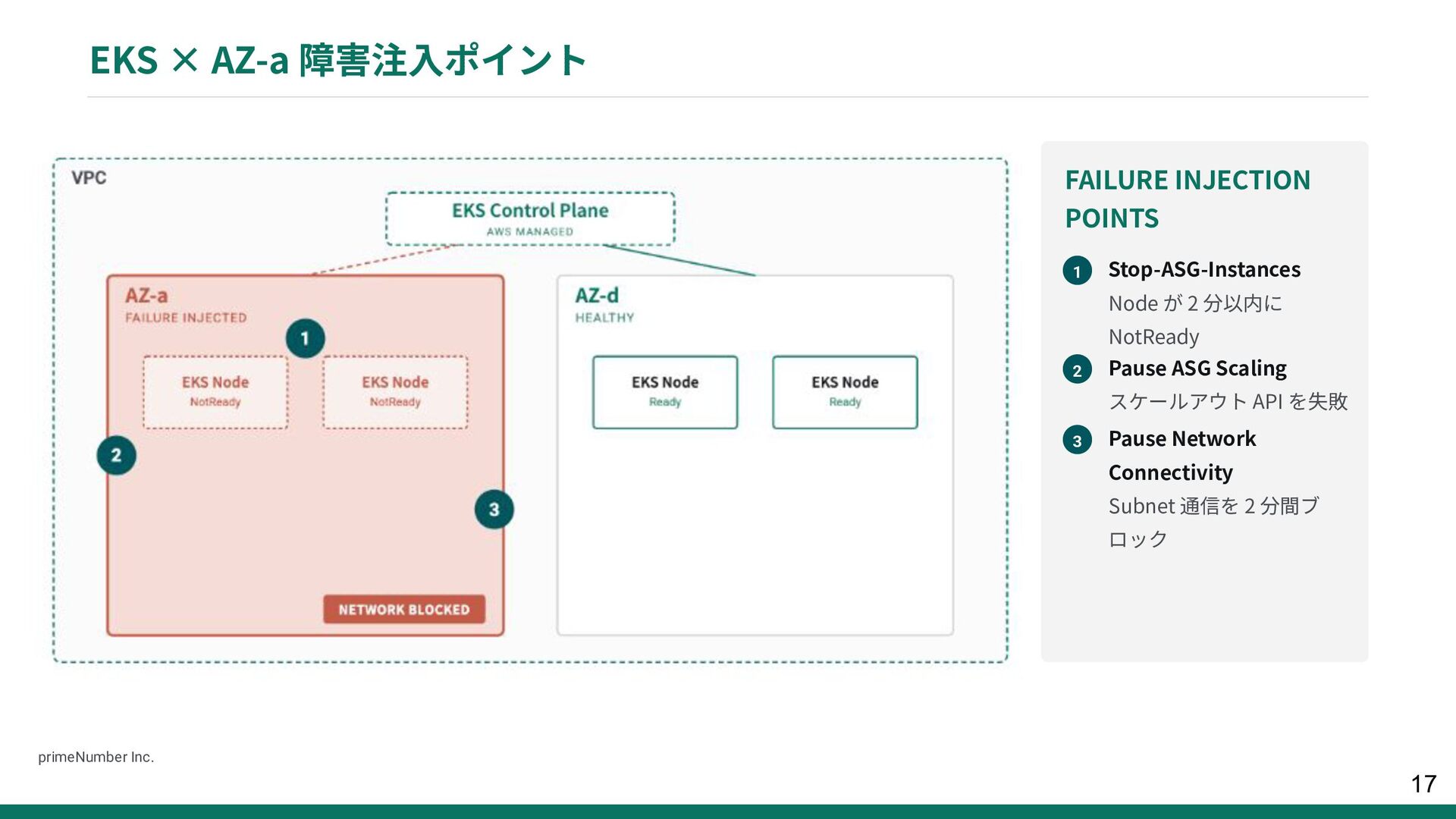{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}